Machine Learning at Facebook: Understanding Inference at the Edge - Facebook Research
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Machine Learning at Facebook:
Understanding Inference at the Edge
Carole-Jean Wu, David Brooks, Kevin Chen, Douglas Chen, Sy Choudhury, Marat Dukhan,
Kim Hazelwood, Eldad Isaac, Yangqing Jia, Bill Jia, Tommer Leyvand, Hao Lu, Yang Lu, Lin Qiao,
Brandon Reagen, Joe Spisak, Fei Sun, Andrew Tulloch, Peter Vajda, Xiaodong Wang,
Yanghan Wang, Bram Wasti, Yiming Wu, Ran Xian, Sungjoo Yoo∗, Peizhao Zhang
Facebook, Inc.
ABSTRACT 120
Avg. GFLOPS
Peak multi-core CPU GFLOPS
At Facebook, machine learning provides a wide range of 100
capabilities that drive many aspects of user experience
80
including ranking posts, content understanding, object
detection and tracking for augmented and virtual real- 60
ity, speech and text translations. While machine learn-
40
ing models are currently trained on customized data-
center infrastructure, Facebook is working to bring ma- 20
chine learning inference to the edge. By doing so, user
0
experience is improved with reduced latency (inference 2013 2014 2015 2016
time) and becomes less dependent on network connec-
tivity. Furthermore, this also enables many more appli- Figure 1: The distribution of peak performance
cations of deep learning with important features only of smartphone SoCs running Facebook mobile
made available at the edge. This paper takes a data- app exhibit a wide spread. The data samples
driven approach to present the opportunities and de- represents over 85% of the entire market share
sign challenges faced by Facebook in order to enable and are sorted by the corresponding SoC release
machine learning inference locally on smartphones and year. Peak performance can vary by over an
other edge platforms. order of magnitude, increasing the design chal-
lenge of performance optimization.
1. INTRODUCTION
Machine Learning (ML) is used by most Facebook time machine learning at the image capture time. En-
services. Ranking posts for News Feed, content under- abling edge inference requires overcoming many unique
standing, object detection and tracking for augmented technical challenges stemming from the diversity of mo-
and virtual reality (VR) platforms, speech recognition, bile hardware and software not found in the controlled
and translations all use ML. These services run both in datacenter environment.
datacenters and on edge devices. All varieties of ma- While inference is generally less computationally de-
chine learning models are being used in the datacen- manding than training, the compute capabilities of edge
ter, from RNNs to decision trees and logistic regres- systems (both hardware and software) running the Face-
sion [1]. While all of training runs exclusively in the book app limit what is possible. Figure 1 shows the
datacenter, there is an increasing push to transition in- peak performance of edge devices, representing over 85%
ference execution, especially deep learning, to the edge. of the entire market share, over the corresponding re-
Facebook makes over 90% of its advertising revenue lease year of a System on a Chip (SoC). The figure shows
from mobile [2] and has focused on providing its over a wide variation in performance that must be considered
2 billion monthly active users the best possible experi- to enable efficient, real-time inference across all edge
ence [3]. In addition to minimizing users network band- devices. Trends emerge over time to tell another story:
width and improving response time, executing inference while the average theoretical performance of SoCs is im-
on the edge makes certain deep learning services possi- proving over time, there is a consistent, widespread peak
ble, for example, Instagram features that involve real- performance regardless the release year of the SoCs. To
∗
Sungjoo Yoo is a Professor at Seoul National University. A provide the best user experience despite limited perfor-
large part of this work was performed during his sabbatical mance scaling Facebook has been proactive in develop-
leave at Facebook. ing tools and optimizations to enable all models/servicesto execute across the observed performance spectrum. • System diversity makes porting code to co-processors,
Optimizations include techniques for model architec- such as DSPs, challenging. We find it more effec-
ture search, weight compression, quantization, algorith- tive to provide general, algorithmic level optimiza-
mic complexity reduction, and microarchitecture spe- tions that can target all processing environments.
cific performance tuning. These optimizations enable When we have control over the system environ-
edge inference to run on mobile CPUs. Only a small ment (e.g., Portal [4] or Oculus [5] virtual reality
fraction of inference currently run on mobile GPUs. platforms) or when there is little diversity and a
This is no small feat considering the computational com- mature SW stack (e.g., iPhones), performance ac-
plexity of state-of-the-art deep learning models and that celeration with co-processors becomes more viable.
most CPUs are relatively low-performance. In our dataset,
an overwhelming majority of mobile CPUs use in-order • The main reason to switch to an accelerator/co-
ARM Cortex-A53 and Cortex-A7 cores. While a great processor is power-efficiency and stability in exe-
deal of academic work has focused on demonstrating cution time. Speedup is largely a secondary effect.
the potential of co-processors (GPUs/DSPs) and accel-
erators, as we will show, in the field the potential per- • Inference performance variability in the field is much
formance benefits of mobile GPUs vs. CPUs for the worse than standalone benchmarking results. Vari-
Android market are not great. Considering theoretical ability poses a problem for user-facing applications
peak FLOP performance, less than 20% of mobile SoCs with real-time constraints. To study these effects,
have a GPU 3× more powerful than CPUs and, on a there is a need for system-level performance mod-
median mobile device, GPUs are only as powerful as eling.
CPUs. Inference sees limited co-processor use today as Facebook expects rapid growth across the system stack.
a result of close performance between CPU clusters and This growth will lead to performance and energy effi-
GPUs as well as an immature programming environ- ciency challenges, particularly for ML mobile inference.
ment. While today we have focused on optimizing tools and
In this paper we detail how Facebook runs inference infrastructure for existing platforms we are also explor-
on the edge. We begin by reviewing the hardware and ing new design solutions to enable efficient deep learning
software system stack the Facebook app is run on (Sec- inference at the edge.
tion 2). This highlights the degree of device diversity
and divergence of software, presenting many design and
optimization challenges. Next, we review the machine 2. THE LAY OF THE LAND: A LOOK AT
learning frameworks and tool sets including PyTorch 1.0 SMARTPHONES FACEBOOK RUNS ON
and the execution flow for mobile inference (Section 3). Facebook’s neural network engine is deployed on over
To understand the optimization techniques Facebook one billion mobile devices. These devices are comprised
has implemented to improve the performance and ef- of over two thousand unique SoCs1 running in more
ficiency of inference we present two case studies. For than ten thousand smartphones and tablets2 . In this
horizontally integrated devices (e.g., smartphones) we section we present a survey of the devices that run Face-
show how general optimizations including quantization book services to understand mobile hardware trends.
and compression can be used across all devices (Sec-
tion 4). Vertically integrated solutions enable control 2.1 There is no standard mobile chipset to op-
over the hardware-software stack. In the case of the timize for
Oculus virtual reality (VR) platform, we show how in- Figure 2 shows the cumulative distribution function
ference can easily be ported to run on DSPs to improve (CDF) of the SoC market share. The data paints a clear
energy efficiency, execution time predictability, and per- picture: there is no “typical” smartphone or mobile SoC.
formance (Section 5). The degree of performance vari- The most commonly-used SoC accounts for less than 4%
ance found in inference on the same device is presented of all mobile devices. Moreover, the distribution shows
in Section 6–this is a problem for applications with real- an exceptionally long tail: there are only 30 SoCs with
time constraints. Finally, we conclude by discussing the more than 1% market share and their joint coverage is
ramifications of our findings and provide our take on only 51% of the market.
what it means for potential research directions in archi- In production, smartphone hardware is extremely frag-
tecture and systems (Section 7). mented. This diversity comes from a combination of the
This paper makes the following key observations: multiple IP blocks in a SoC which may include CPU(s),
GPU clusters, shared caches, memory controllers, image
• Nearly all mobile inference run on CPUs and most 1
Some of the SoCs are different by connectivity modules.
deployed mobile CPU cores are old and low-end. 2
SoC information is widely accessible through Android
In 2018, only a fourth of smartphones implemented system properties and Linux kernel mechanisms, such as
CPU cores designed in 2013 or later. In a median /proc/cpuinfo file and sysfs filesystem. Android devel-
Android device, GPU provides only as much per- opers commonly use SoC information to optimize perfor-
mance. To allow developers to optimize ML-based applica-
formance as its CPU. Only 11% of the Android tion performance, we developed cpuinfo library to decode
smartphones have a GPU that is 3 times more per- SoC specification and open sourced it at https://github.
formant than its CPU. com/pytorch/cpuinfo.1.0 95%
0.8 2011
65%
2012
CDF of SoCs
0.6 15.6%
225 54.7%
50
SoCs
1.8% 2005-2010
0.4 SoCs
23.6%
0.2
4.2%
2015+
0.0
0 250 500 750 1000 1250 1500 1750 2000
Unique SoCs 2013-2014
Figure 2: There is no standard mobile SoC Figure 3: The most commonly-used mobile pro-
to optimize for. The top 50 most common SoCs cessors, Cortex A53, are at least six years old. In
account for only 65% of the smartphone market. 2018, only a fourth of smartphones implemented
CPU cores designed in 2013 or later.
processors, a digital signal processor (DSP), and even
10
SoC GPU flops/CPU flops
a specialized neural network accelerator (NPU). There
are over 25 mobile chipset vendors which each mixes and 8
matches its own custom-designed components with IP
blocks licensed from other companies. The fragmenta- 6
tion of hardware is particularly acute on Android, where 4
the Facebook app runs on over two thousand of differ-
ent SoCs compared to a little more than a dozen SoCs 2
on iOS. 0
0.0 0.2 0.4 0.6 0.8 1.0
2.2 Mobile CPUs show little diversity Marketshare
The general availability and programmability of CPUs Figure 4: The theoretical peak performance dif-
make them the default option for mobile inference. Thus, ference between mobile CPUs and GPUs is nar-
we pay close attention to the CPU microarchitecture row. In a median Android device, GPU provides
differences between mobile SoCs. Figure 3 shows a only as much performance as its CPU. Only 11%
breakdown of the year smartphone CPU cores were de- of the smartphones have a GPU that is 3 times
signed or released. 72% of primary CPU cores being more performant than its CPU.
used in mobile devices today were designed over 6 years
ago. Cortex A53 represents more than 48% of the entire
mobile processors whereas Cortex A7 represents more of energy-efficient cores. Only a small fraction include
than 15% of the mobile processors. When looking at three clusters of cores. Cores in the different clusters
more recent CPUs, the distribution is much more di- may differ in microarchitectures, frequency settings, or
verse without dominating microarchitectures. The im- cache sizes. A few SoCs even have two clusters consist-
plication of the dominant Cortex A7 and Cortex A53 ing of identical cores. In nearly all SoCs, cores within
IPs for machine learning is that most of today’s edge in- the same cluster have a shared cache, but no cache
ference runs on in-order (superscalar) mobile processors level is shared between cores in the different clusters.
with only one to four cores per cluster. Furthermore, The lack of a shared cache imposes a high synchroniza-
this view of the world poses a new, real challenge for tion cost between clusters. For this reason, Facebook
systems and computer architecture researchers – pro- apps target the high-performing cluster by, for exam-
posed mobile hardware optimizations and accelerators ple, matching thread and core count for neural network
need to consider the long IP lifetime. inference.
We observe a similar multi-core trend as desktop and
server chips in mobile. 99.9% of Android devices have 2.3 The performance difference between a mo-
multiple cores and 98% have at least 4 cores. We find bile CPU and GPU/DSP is narrow
distinct design strategies between Android and iOS smart- High-performance GPUs continue to play an impor-
phones – iOS devices tend to use fewer, more powerful tant role in the success of deep learning. It may seem
cores while Android devices tend to have more cores, natural that mobile GPUs play a similar part for edge
which are often less powerful. A similar observation was neural network inference. However, today nearly all
made in 2015 [6]. To optimize a production application Android devices run inference on mobile CPUs due to
for this degree of hardware diversity, we optimize for the the performance limitations of mobile GPUs as well as
common denominator: the cluster of most performant programmability and software challenges.
CPU cores. Figure 4 shows the peak performance ratio between
About half of the SoCs have two CPU clusters: a CPUs and GPUs across Android SoCs. In a median de-
cluster of high-performance cores and another cluster vice, the GPU provides only as much theoretical GFLOPSperformance as its CPU. 23% of the SoCs have a GPU of Android devices ship with a broken OpenCL driver.
at least twice as performant as their CPU, and only 11% In the worst case, 1% of the devices crash when the
have a GPU that is 3 times as powerful than its CPU. app tries to load the OpenCL library. The instability of
This performance distribution is not a historical artifact OpenCL’s library and driver makes it unreliable to use
but a consequence of the market segmentation: mid- at scale.
end SoCs typically have CPUs that are 10-20% slower OpenGL ES has proved to be a viable alternative.
compared to their high-end counterparts. The perfor- OpenGL ES is a trimmed variant of the OpenGL API
mance distribution corresponds to a wider gap for the specifically for mobile and embedded systems. Being a
GPUs in SoCs targeted for different performance tiers— graphics API, OpenGL ES is not tailored to GPGPU
the performance gap for mobile GPUs is two to four programming. However recent versions of the API pro-
times. Realizable mobile GPUs performance is further vide sufficient capabilities to program neural network
bottlenecked by limited memory bandwidth capacities. computations. Different versions dictate what we can
Unlike high-performance discrete GPUs, no dedicated do with mobile GPUs and there are several versions of
high-bandwidth memory is available on mobile. More- the OpenGL ES API on the market.
over, mobile CPUs and GPUs typically share the same
memory controller, competing for the scarce memory • OpenGL ES 2.0 is the first version of the API
bandwidth. with a programmable graphics pipeline. All mobile
devices running Facebook apps on Android sup-
2.4 Available co-processors: DSPs and NPUs port this version. With OpenGL ES 2.0 it is pos-
Compute DSPs are domain-specific co-processors well- sible to implement neural network operators via
suited for fixed-point inference. The motivation at Face- the render-to-texture technique, but inherent lim-
book to explore co-processor performance acceleration itations of the API make computations memory
opportunities is for the increased performance-per-watt bound. All computations have to happen inside a
efficiency benefit (higher performance with lower power fragment shader which can write only 16 bits3 of
consumption). However DSPs face the same challenge output. Therefore, multi-channel convolution or
GPUs do – “compute” DSPs are available in only 5% of matrix-matrix multiplication would require read-
the Qualcomm-based SoCs the Facebook apps run on. ing the same inputs multiple times. The compu-
Most DSP do not yet implement vector instructions. tation patterns are similar to matrix-matrix mul-
While all vendors are adding vector/compute DSPs, it tiplication on CPU using a dot product function.
is likely to take many years before we see a large market • OpenGL ES 3.0 (or newer) is supported on 83% of
presence. Android devices. It is the first version of OpenGL
The regularity in the computational patterns of many ES that is practical for neural network implemen-
DNN workloads makes NPUs exceptionally amenable to tations. Similar to 2.0, all computations need to
hardware acceleration. Many academic research projects, be implemented in fragment shaders, but OpenGL
startups, and companies have proposed solutions in this ES 3.0 supports several features for efficiency. For
space (Section 7 offers a thorough treatment). The most example, each invocation of a fragment shader can
notable deployed NPU is the Cambricon 1A in the Kirin write up to 128 bits of data into each of the (up
970 SoC [7] and the Neural Engine in the Apple A12 to 8) textures while also using uniform buffers to
Bionic SoC [8]. While relatively few NPUs exist today, load constant data (e.g., weights).
and fewer programmable by third parties, we may be
reaching an inflection point. • OpenGL ES 3.1 (or newer) is supported on 52%
of the Android devices. It introduces compute
2.5 Programmability is a primary roadblock shaders that provide similar functionalities avail-
for using mobile co-processors able in OpenCL 1.x and early versions of CUDA.
The major APIs used to program neural networks on For example, important compute features such as,
mobile GPUs are OpenCL, OpenGL ES, and Vulkan on launching kernels on GPU with reduced overhead
Android and Metal on iOS. for the graphics pipeline, fast synchronization within
OpenCL was designed to enable general-purpose pro- a work-group, access to local memory shared by
grams to run on programmable co-processors. Thus, threads in a work-group, and arbitrary gather and
OpenCL does not provide graphics specific functional- scatter operations with random-access buffers, be-
ity, e.g., 3D rendering. Focusing on general-purpose come available.
computations helps: OpenCL’s API and intrinsic func-
Figure 5(b) shows how over the past year the pro-
tions as well as support for memory address space man-
grammability of mobile GPUs on Android devices has
agement, and efficient thread synchronization make it
steadily improved. Today, a median Android device has
easier to express computations compared to graphics-
the support of GPGPU programming with OpenGL ES
oriented APIs like OpenGL. However while most An-
3.1 compute shaders.
droid devices ship with OpenCL drivers, OpenCL is not
Vulkan is a successor to OpenGL and OpenGL ES.
officially a part of the Android system, and they do not
It provides similar functionality to OpenGL ES 3.1, but
go through the same conformance tests as OpenGL ES
3
and Vulkan. As shown in Figure 5(a), a notable portion 32 bits with OES rgb8 rgba8 extensionNo No GPU No library
library/device 100
Loading
fails OpenGL 3.2
80
Loading
crashes
OpenCL 2.0 60 OpenGL 3.1
40
OpenGL 3.0
No device
20
OpenCL 1.1 OpenGL 2.0
OpenCL 1.2 0 Vulkan 1.0
Aug 17 Nov 17 Feb 18 Jun 18
(a) OpenCL Support (b) OpenGL ES Support (c) Vulkan Support
Figure 5: Mobile GPUs have fragile usability and poor programmability.
with a new API targeted at minimizing driver overhead. 3.1 Machine learning models and frameworks
Looking forward, Vulkan is a promising GPGPU API. We developed several internal platforms and frame-
Today, early adoption of Vulkan (see Figure 5(c)) is lim- works to simplify the task of bringing machine learning
ited, being found on less than 36% of Android devices. into Facebook products. As an example, FBLearner
Metal is Apple’s GPU programming language. Mo- is an ML platform that automates many tasks such as
bile GPUs on iOS devices paint a very different picture. training on clusters and is the tool of choice by many
Because Apple chipsets with the A-series mobile pro- teams experimenting and developing custom ML at Face-
cessors are vertically-designed, the system stack is more book. In addition to production tooling, ML develop-
tightly integrated for iPhones. Since 2013 all Apple mo- ment at Facebook has been underpinned by Caffe2 and
bile processors, starting with A7, support Metal. Metal PyTorch, as set of distinct deep learning frameworks
is similar to Vulkan but with much wider market share both of which are open source. Caffe2 is optimized for
and more mature system stack support. 95% of the iOS production scale and broad platform support while Py-
devices support Metal. Moreover the peak performance Torch was conceived with flexibility and expressibility
ratio between the GPU and the CPU is approximately in mind allowing researchers to fully express the de-
3 to 4 times, making Metal on iOS devices with GPUs sign space. Caffe2 provides cutting-edge mobile deep
an attractive target for efficient neural network infer- learning capabilities across a wide range of devices and
ence. Guided by this data and experimental perfor- is deployed broadly through the Facebook application
mance validation, Facebook apps enable GPU-powered family. In particular, it is deployed to over one bil-
neural network inference on iOS for several models. lion devices, of which approximately 75% are Android
In summary, Facebook takes a data-driven design ap- based, with the remainder running iOS. Caffe2, in par-
proach: the heterogeneity of SoCs makes it inordinately ticular, is built with optimized mobile inference in mind
challenging to perform fine-grained, device/SoC-specific to deliver the best experience possible for a broad set
optimization. Diverse SoCs pose significant programma- of mobile devices.
bility challenge. It is difficult to deploy performance At the 2018 F8 Developer Conference, Facebook an-
optimization techniques to SoC that are implemented nounced the road map for a new unified AI framework
with different versions of device drivers, scopes of mem- – PyTorch 1.0 [9]. Pytorch 1.0 combines the production
ory granularities, and consistency models. scale of Caffe2 and the research flexibility of PyTorch.
It supports the ONNX specification for ecosystem in-
3. MACHINE LEARNING AT FACEBOOK teroperability. With this, Facebook aims to accelerate
Facebook puts in significant engineering efforts into AI innovation by streamlining the process of transition-
developing deep learning features for mobile platforms. ing models developed through research exploration into
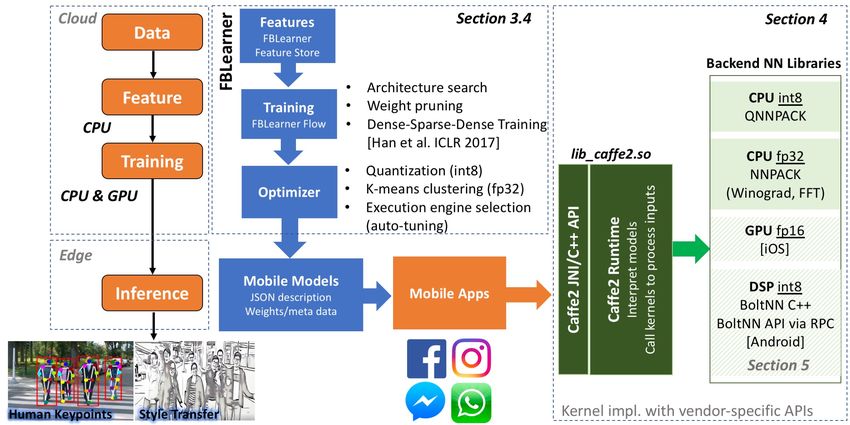
Figure 6 illustrates the execution flow of machine learn- production scale with little transition overhead.
ing, where a product leverages a series of inputs to PyTorch 1.0 adopts the ONNX specification for ecosys-
build a parameterized model, which is then used to tem interoperability. In addition to being able to ex-
create a representation or a prediction. Hazelwood et port the ONNX model format, PyTorch 1.0 leverages
al. presented the major products and services leverag- ONNX’s Interface for Framework Integration (ONNX-
ing machine learning that run on Facebook customized IFI) as a stable interface for external backend integra-
datacenter infrastructure [1]. To ensure reliable, high- tion. ONNXIFI enables PyTorch 1.0 to leverage exter-
performance, and high-quality training, this phase gen- nal software libraries and hardware accelerators without
erally happens offline in the cloud. On the other hand, requiring redundant integration work for each new back-
an inference phase that makes real-time predictions on end and also supports embedded edge devices. We are
pre-trained models runs either in the cloud or on mobile also collaborating with mobile OS ecosystem partners
platforms. This paper focuses on mobile inference— such as Android to include a similar level of function-
making real-time predictions locally at the edge. ality, natively within the OS-specific machine learningFigure 6: Execution flow of Facebook’s machine learning for mobile inference.
accelerator APIs. mance is key for edge inference; thus, performance op-
timization is critical for mobile. However, performance
3.2 DNN Inference at the Edge characterization and analysis is far more complicated
Smartphones are capable of realizing deep learning for mobile than cloud because of fragmentation of the
in real time without relying on the cloud but there are mobile ecosystem (Section 2).
also limitations. While smartphones have improved sig- Performance is far more limited with wider perfor-
nificantly in computation performance in recent years, mance variance for mobile than cloud. Most cloud in-
these mobile platforms also have various resource con- ference runs on server-class CPUs with theoretical com-
straints, such as power, memory, and compute capabil- putation capability of up to several TFLOPS. On the
ities. Putting all aspects of SoC components together other hand, mobile SoCs are orders of magnitude less
leads to the landscape of a widely diverse set of SoCs, capable, and deliver between single-digit GFLOPS in
as presented in Section 2. As a result, mobile presents the ultra low-end to few hundred of GFLOPS on the
both an opportunity and, at the same time, a challenge very high-end.
for machine learning. Depending on the application and Furthermore, model and code sizes are imperative for
product domains, Facebook takes different approaches. mobile because of the limited memory capacity of a few
Here we review how inference works today by review- GBs. Techniques, such as weight pruning, quantiza-
ing the mobile workflow. We then provide two case tion, and compression, are commonly used to reduce
studies that provide details into how we optimize for the model size for mobile. Code size is a unique design
commodity devices (i.e., mobile SoCs) and vertically in- point for mobile inference. For good deployment experi-
tegrated, custom solutions (i.e., Oculus VR platforms). ence, the amount of new code pushed into the app needs
to be incremental. Several methods are available for ap-
3.3 Important Design Aspects for Mobile In- plication code size management and are potentially vi-
ference and Potential Approaches able. First option is to compile applications containing
ML models to platform-specific object code using, for
To develop mobile applications for the wild west of
example, Glow [10], XLA [11], or TVM [12]. This often
mobile SoCs, a simple approach is to target applica-
leads to larger model sizes (as the model now contains
tion development for the lowest common denominator,
machine codes but enables a smaller interpreter.). Sec-
in this case, mobile CPUs. This, however, optimizes
ond option is to directly use vendor-specific APIs, such
for ubiquity and programmability while sacrificing effi-
as iOS CoreML [13], from operating system vendors.
ciency.
Another approach is to deploy a generic interpreter,
To fully harvest potential performance benefits for
such as Caffe2 or TF/TFLite, that compiles code us-
edge inference, there are several important design trade-
ing optimized backend. The first approach is compiled
offs that we consider. Iteration speed from an idea to
execution which treats ML models as code whereas the
product deployment takes weeks–order of magnitude
later approach is interpreted execution which treats ML
longer than the deployment cycle for cloud. Perfor-models as data. Techniques are chosen depending on tion. In addition, tuning of spatial resolution that con-
design tradeoff suitable in different usage scenarios. trols the processing time of middle layers is particularly
useful for mobile. We also apply commonly-used tech-
3.4 Mobile Inference Workflow niques, such as pruning and quantization, to aggres-
Facebook develops a collection of internal platforms sively cut down the size of DNN models while main-
and toolkits to simplify the tasks of leveraging ma- taining reasonable quality [17].
chine learning within its products. FBLearner offers In addition, to maintain certain performance levels
this ecosystem of machine learning tools, enabling work- for good user experience, quantization is used for edge
flow execution and management (FBLearner Flow), reg- inference. The use of quantization is a standard in-
istry of pointers to data sources, features, and models dustry practice with support in e.g., Google’s GEMM-
for training and inference (FBLearner Feature Store), LOWP [18] and Qualcomm’s neural processing SDK [19].
optimal configurations for experiments (FB Learner Au- A floating point tensor is linearly quantized into 8 or
toML), real-time prediction service (FBLearner Predic- fewer bits and all nodes in the data flow graph operate
tor), among many others [1]. on this quantized tensor value. To efficiently quantize
Figure 6 depicts the execution flow for applying ma- node outputs, we need to precompute good quantiza-
chine learning for edge inference. First, features are tion parameters prior to inference time. There are two
collected and selected for any ML modeling tasks from approaches here. One is to modify the graph at training
FBLearner Feature Store. The Feature Store is essen- time to learn the quantization directly–quantization-
tially a catalog of feature generators, that is hosted on aware training [20]. The other is to add a stage af-
Facebook’s data centers. Then, a workflow describing ter training to compute appropriate quantizers–post-
architectures of a model and steps for the model train- training quantization. More advanced quantization tech-
ing and evaluation is built with FBLearner Flow. After niques at the execution front-end is under investiga-
model training and evaluation, the next step is to export tion [21, 22, 23].
and publish the model so it can be served in one of Face- To make the best possible use of limited comput-
book’s production inference tiers. Before models are de- ing resources, Caffe2 Runtime integrates two in-house
ployed for edge inference, optimization techniques, such libraries, NNPACK [24] and QNNPACK [25], which
as quantization, can be applied in the Optimizer. provide optimized implementation of convolution and
In general, to improve model accuracy, three approaches other important CNN operations, and contain platform-
are used iteratively: increasing training data, refining specific optimizations tailored for mobile CPUs.
feature sets, and changing model architectures, by e.g. NNPACK (Neural Networks PACKage) per-
increasing the number of layers or sharing embeddings forms computations in 32-bit floating-point precision
for features. For performance and memory requirement and NCHW layout, and targets high-intensity convo-
reasons, we often quantize portions of models. One ex- lutional neural networks, which use convolutional oper-
ample is to reduce the precision of a large multi-GB ators with large kernels, such as 3x3 or 5x5. NNPACK
embedding table from 32-bit single precision float to 8- implements asymptotically fast convolution algorithms,
bit integers. This process takes place after we verify based on either Winograd transform or Fast Fourier
that there is little or no measurable impact to model transform, which employ algorithmic optimization to
accuracy. Then, for edge inference, to improve compu- lower computational complexity of convolutions with
tational performance while maximizing efficiency, tech- large kernels by several times. With algorithmic advan-
niques, such as quantization, k-means clustering, exe- tage and low-level microarchitecture-specific optimiza-
cution engine selection, are employed to create mobile- tions, NNPACK often delivers higher performance for
specific models. Once the model is deployed to a mo- direct convolution implementation.
bile platform, Caffe2 Runtime interprets models and QNNPACK (Quantized NNPACK) on the other
call kernels to process inputs. Depending on the hard- hand performs computations in 8-bit fixed-point pre-
ware architecture and the system stack support, back- cision and NHWC layout. It is designed to augment
end neural network libraries are used by Caffe2 Runtime NNPACK for low-intensity convolutional networks, e.g.
for additional optimization. neural networks with large share of 1x1, grouped, depth-
wise, or dilated convolutions. These types of convolu-
4. HORIZONTAL INTEGRATION: MAKING tions do not benefit from fast convolution algorithms,
INFERENCE ON SMARTPHONES thus QNNPACK provides a highly efficient implementa-
tion of direct convolution algorithm. Implementation in
Mobile inference is primarily used for image and video QNNPACK eliminates the overhead of im2col transfor-
processing. Therefore, inference speed is typically mea- mation and other memory layout transformations typ-
sured as the number of inference runs per second. An- ical for matrix-matrix multiplication libraries. Over a
other commonly-used metric is inference time, particu- variety of smartphones, QNNPACK outperforms state-
larly for latency sensitive applications. To exploit per- of-the-art implementations by approximately an aver-
formance optimization opportunities before models are age of two times.
deployed onto mobile platforms and to ensure fast model The choice of two mobile CPU backends help Caffe2
transmission to the edge, Caffe2 implements specific Runtime deliver good performance across a variety of
features, such as compact image representations and mobile devices and production use-cases. In the next
weight [14, 15], channel pruning [16], and quantiza-section we present the relative performance compari- 7
son of three state-of-the-art DNN models running on 6 Low-end Mid-end High-end
FPS (Normalized)
QNNPACK with quantization compared to running on
NNPACK in floating-point representation. 5
4 ShuffleNet
4.1 Performance optimization versus accuracy 3 Mask-RCNN
tradeoff
The primary performance benefits with reduced pre-
2
cision computation come from–(1) reduced memory foot- 1
print for storage of activations, (2) higher computation 0
Gen-1
Gen-2
Gen-3
Gen-4
Gen-1
Gen-2
Gen-1
Gen-2
Gen-3
Gen-4
efficiency, and (3) improved performance for bandwidth
bounded operators, such as depthwise convolutions and
relatively small convolutions. Reduced precision com- Figure 7: Performance comparison over several
putation is beneficial for advanced model architectures. generations of low-end, mid-end, and high-end
This inference time speedup is, however, not received smartphones for two image-based DNN mod-
equally well when the technique is applied directly onto els, ShuffleNet [27] and Mask-RCNN [28]. The
all models. smartphone performance tier does not always
We compare the inference time speedup of the re- correspond to inference performance. The per-
duced precision computation with 8-bit fixed-point over formance of DNN models respond to hardware
the baseline FP32 implementation (under acceptable resources differently.
accuracy tradeoff). First, the UNet-based Person Seg-
mentation model [26] that relies on 3x3 convolutions
with relatively small spatial extent experiences perfor- a better use of quantization that offers more consistent
mance regression in the quantized version. This re- performance improvement.
gression is caused by inability to leverage NNPACK’s While this section represents the way designs are cur-
highly optimized Winograd-based convolution for both rently done today, as more hardware and better (co-
the low- and the high-end Android smartphones. Fur- )processors (e.g., CPUs/GPUs/DSPs) make their way
thermore, for the quantized models, additional instruc- onto mobile devices we will take advantage of the addi-
tions are needed to extend elements from 8 to 16 bits for tional computation performance by using more accurate
computation4 , leading to additional performance over- models. Next we present two approaches for enabling
head compared to the FP32 version, which can imme- mobile inference at Facebook. First is the horizontal in-
diately use loaded elements in multiply-add operations. tegration that enables Facebook Apps to run efficiently
For style transfer models, a network with a relatively across a variety of mobile platforms. Second is the ver-
small number of channels and large spatial resolution tical integration for the VR application domain.
is used with 3x3 convolutions. We start seeing much
better performance response to QNNPACK-powered re- 4.2 An augmented reality example
duced precision computation. The efficiency reduction Smart cameras are designed to add intelligence to
from losing Winograd is compensated by reduced mem- cameras, i.e., processing images directly on an edge de-
ory bandwidth for these large spatial domain convolu- vice. This feature improves user experience by reduc-
tion. ing latency and bandwidth usage. In addition to image
Finally, when we look at a custom architecture de- classification models, advanced machine learning tech-
rived from ShuffleNet [27], which leverages grouped 1x1 niques are applied to estimate and improve the quality
convolutions and depthwise 3x3 convolutions for the of photos and videos for various Facebook services, to
bulk of the model computation, we see substantial in- understand digital contents locally, directly on smart-
ference performance improvement from reduced mem- phones.
ory bandwidth consumption for the depthwise convo- The challenges with smart cameras are large com-
lutions. Reduced precision computation on QNNPACK putational demands for delivering real-time inference.
improves inference performance for the depthwise-separable To enable smart cameras on mobile platforms running
models that are increasingly popular in mobile and em- the Facebook App, we train mobile specific models,
bedded computer vision applications. compress weights for transmission, and execute quan-
However, in order to maximize performance benefit, tized models. We design a collection of image clas-
we have to consider both algorithmic and quantization sification models tailored for smartphones. To lessen
optimization. Currently, using algorithmic optimization the transmission cost, models can be compressed us-
with e.g. Winograd algorithm for CNNs can disallow ing a Deep Compression-like pipeline. As previously
quantization. Therefore, if the benefit from Winograd discussed, quantization is also considered. Finally, to
transformation is greater than that of quantization, we improve inference performance, some of the models are
see a relative slowdown for quantized models, calling for processed using an 8-bit fixed point datatype for the
4
This inefficiency is not inherent to 8-bit fixed-point convo- weights. Additionally, models shipped with the k-means
lutions, but is caused by restrictions of the NEON instruc- quantization method typically use 5 or 6 bits for the
tion set. weights.DNN features DNN models MACs Weights
Hand Tracking U-Net [29] 10x 1x
Image Model-1 GoogLeNet [30] 100x 1x
Image Model-2 ShuffleNet [27] 10x 2x
Pose Estimation Mask-RCNN [28] 100x 4x
Action Segmentation TCN [31] 1x 1.5x
Table 1: DNN-powered features for Oculus.
4.3 DNN model performance across a wide spec- CPU
trum of smartphones 103 DSP
Inferences per second
Figure 7 illustrates the performance of two important
Facebook DNN models, i.e., classification and human
pose estimation, across multiple generations of smart-
phones in the different performance tiers. The x-axis 102
represents multiple generations of smartphones in the
low-end, mid-end, and high-end performance tiers whereas
the y-axis plots the normalized inference time speedup
over the first smartphone generation in the low-end tier.
tracking
classification M1
classification M2
estimation
segmentation
First, we observe that the performance tier does not al-
Hand
Pose
Action
ways directly correspond to inference performance. The
Image
Image
newest generation of smartphones in the low-end tier
offer competitive inference performance as that in the
mid-end tier for both DNN models.
Furthermore, the performance of DNN models re- Figure 8: Inference time performance compari-
spond to different degree of hardware resources differ- son between CPU and DSP.
ently. For example, the DNN model used for human
bounding box and keypoint detection (Mask-RCNN [28])
demands much higher compute and memory resource and video performance requirements. Moreover, head-
capacities. Thus, when comparing the inference time sets include multiple cameras to cover a wide field of
speedup between the latest generation of smartphones view. This puts the performance requirements of VR
between the low-end and high-end performance tiers, platforms on the order of many hundreds of inference
we see a much higher performance speedup for smart- per second. This presents a significant challenge for
phones equipped with more abundant resources–5.62 embedded devices as all processing has to be performed
times speedup for Gen-4/High-End over 1.78 times speedup on-device with high performance delivery. To overcome
for Gen-4/Low-End. Although we still see higher infer- the particular design challenges in the VR design space,
ence time speedup in the latest generation of high-end for mobile inference, Facebook takes a vertical design
smartphones, the speedup is less pronounced for the approach. In the case of Oculus, we explore and assess
DNN model used for classification (ShuffleNet [27]). the suitability of Qualcomm Hexagon DSPs for DNN
This model-specific inference time comparison projects models by offloading the most computationally demand-
the performance of realistic DNN models onto the di- ing DNNs and compare performance across used models
verse spectrum of smartphone platforms described in running on DSPs and CPUs.
Section 2. In addition to the previously-shown peak
performance analysis for the deployed smartphones in 5.1 DNN models and hardware used for VR
the wild, Figure 7 shows how different generations of platforms
smartphones across the different performance tiers re- The Oculus VR platform explores many state-of-the-
act to two realistic DNN models. It is important to art DNN models. Models are programmed in PyTorch
continue strong performance scaling for the remaining 1.0 and the weights are quantized with PyTorch 1.0’s
smartphones in the entire market for higher product int8 feature for mobile inference. Table 1 shows some of
penetration. the key DNN models explored by Oculus: Hand Track-
ing, Image Classification Model-1, Image Classification
5. VERTICAL INTEGRATION: PROCESS- Model-2, Pose Estimation, and Action Segmentation.
For mobile inference, the DNN models are offloaded
ING VR INFERENCE FOR OCULUS using PyTorch 1.0’s CPU and Facebook ’s BoltNN DSP
Oculus platforms create new forms of interactions by inference backends. The CPU model utilizes a big.LITTLE
running multiple DNNs for tasks including hand, face, core cluster with 4 Cortex-A73 and 4 Cortex-A53 and
and body tracking. To provide a high-quality user ex- a Hexagon 620 DSP. All CPU cores are set to the max-
perience the models must run at a steady frame rate of imum performance level. The four high-performance
30 to 60 FPS, three times greater than mobile image CPU cores are used by the DNN models. The DSPlife and for ergonomic requirement of platform temper-
FPS 20 ature. We compare the performance, power, and tem-
perature of the post estimation model running on the
10 CPU versus the DSP. Figure 9 shows that the CPU im-
plementation consumes twice as much power as that of
the DSP in the beginning. Then, thermal throttling
Power (W)
5.0 kicks in so the power consumption of the CPU imple-
mentation drops while still using 18% more power than
2.5 the DSP. The thermal throttling has a significant ef-
50 fect on performance, degrading the FPS performance to
10 frames-per-second. For lower platform power con-
Temp (C)
sumption and operating temperature, Facebook takes
40 the vertical-designed approach to offload DNN models
CPU DSP using the BoltNN DSP backend for its VR platforms.
0 100 200 300 400 500 Despite higher performance, lower power consump-
Time (Sec) tion and operating temperature, the DSP implementa-
Figure 9: Inference frames-per-second perfor- tion comes with significantly higher programming over-
mance, power, and temperature comparison for head. First, because most DSP architectures support
a vision model for Oculus. Thermal throttling fixed-point data types and operations, DNN models need
(marked with dotted lines) prevents CPU from to be quantized. Depending on the application do-
operating at an acceptable FPS performance main and models, this may cause substantial accuracy
level. loss. It also requires developers to port model operators
to fixed-point implementation; otherwise, this can eas-
ily become the performance bottleneck for light-weight
shares the same memory space with the mobile CPU
operations. Furthermore, developers must pay addi-
cores and has a separate layer of caches, making it con-
tional attention to optimize memory layout; otherwise
venient to program but also isolated enough to prevent
the memory hierarchy can become a contentious re-
cache thrashing for other concurrent processes running
source, leading to additional delay.
on the mobile CPU. As we will later see in Section 6,
Last but not least, an important, yet less explored
dependable, stable execution is an important feature to
and understood factor to determine where DNN mod-
have to guarantee user experience.
els should be run at—CPU versus accelerators—is in-
5.2 DSP evaluation results and analysis ference time variation. Even if one can hand optimized
CPU implementation such that the inference time meets
Figure 8 compares the FPS of the DSP and CPUs for the application-specific performance target, and the power
all models. DSP clearly outperforms CPU for all the and temperature results are competitive, offloading ML
models that come with various complexity and archi- models to accelerators may still be more desirable, de-
tectures, achieving an average speedup of 1.91x, rang- spite the higher programming overhead. We next in-
ing from 1.17 to 2.90 times. The highest speedup comes troduce the role of performance variability for mobile
from models with simple convolution operations, such inference.
as in the Hand Tracking and the Image Classification
Models.
When intensive memory-bound operations are involved, 6. MAKING INFERENCE IN THE WILD:
such as depth-wise convolutions in the ShuffleNet-based PRACTICAL CONSIDERATIONS FOR PRO-
image classification and pose estimation models, the
speedup of DSP over CPU becomes less pronounced. CESSING ON MOBILE DEVICES
This is because the memory load-store operations are at Performance variability is a practical concern for Face-
the granularity of the vector width or coarser, e.g., more book because it is challenging to make guarantees on
than 128B in Hexagon DSPs. Thus, additional mem- quality of service. Real time constraints and model ac-
ory transformation is needed, introducing extra perfor- curacy are often competing objectives: higher-quality
mance overhead. Furthermore, for memory-bound lay- models take longer to process but provide more ac-
ers, such as grouped convolutions or depth-wise con- curacy. For example, we might conservatively use a
volutions, extra computations are required to optimize smaller, less computationally expensive model to meet
the memory layout of activations and filters, in order to a 95% performance target across all devices and all
fully take advantage of the SIMD units. Finally, across App instances. However, if we had a better way to
all models, additional system overhead can come from model and predict performance variability we could put
remote procedure calls that flush the L2 cache on the tighter bounds and could use different models tuned
chipset. to maximize accuracy while meeting real-time perfor-
In addition to using the amount of performance speedup mance/FPS metrics to provide the best user experience
to determine where a DNN model should be executed, (FPS) and service (model accuracy). In this section we
designs for AR/VR wearables must consume as little show how much performance can vary and suggest a
power consumption as possible for prolonged battery simple way to model it.50 A11
A10
Inference time (ms)
105 A9
40
Percentage
30
104 20
10
103
A6 A7 A8 A9 A10 A11 0
0.0
1.0
2.0
3.0
4.0
5.0
6.0
7.0
8.0
9.0
10.0
11.0
12.0
13.0
14.0
15.0
16.0
Chipset
Figure 10: The inference time performance im- Inference time
proves over generations of iPhones. However, Figure 11: The inference time follows an approx-
within each generation, significant inference per- imate Gaussian distribution with the mean cen-
formance variability is observed with a large tered at 2.02ms and the standard deviation of
number of outliers. 1.92ms.
scenarios. Finally, process variation and battery aging
6.1 Performance variability observed in the pro- also contribute to performance variability. To have rep-
duction environment resentative performance results and analysis, it is im-
To arrive at an optimal design point, we perform rig- portant to perform in-field studies for machine learning
orous evaluations for Facebook services and use the per- designs and performance evaluation in the mobile space.
formance characterization results to drive better solu-
tions. A key observation we derive from the perfor- 6.2 Do the performance variability character-
mance data is that mobile inference performance ex- istics follow certain trends or statistical dis-
hibits significant variability, even across the same device tributions?
running the same software stack. Figure 10 shows the It is clear that inference performance on smartphones
inference time performance of the most time-consuming is non-deterministic and follows a wide distribution. This
convolutional neural network layer of a key model across is highly undesirable as the non-deterministic inference
several generations of iPhone SoCs (x-axis). As ex- time translates directly into varied quality of user expe-
pected, we see that the inference time (y-axis) is the rience. If we were able to model and predict variability,
lowest for the most recent generation of iPhones, i.e., we could optimize designs by, for example, customiz-
Apple A-11 processors. Somewhat less intuitive is the ing networks to best suit different mobile platforms and
observed wide performance variability of inference per- users depending on situations. In-field functionality and
formance – even within the same generations of iPhone performance evaluation is an important part of our it-
SoCs. erative model fine-tuning process.
We examine the inference performance results inter- Figure 11 illustrates the histogram for the inference
nally using our small-scale smartphone benchmarking time of the key machine learning layer across three dif-
lab. While we see a general trend of performance vari- ferent generations of iPhone mobile SoCs. In particu-
ability across key machine learning models, the degree lar, the inference time for A11 follows an approximate
of performance variability is much less pronounced, usu- Gaussian distribution with the mean centered at 2.02ms
ally less than 5%. This presents a challenge as ideally and the standard deviation of 1.92ms. A recent work
we would benchmark new models under the exact con- by Gaudette et al. [35] shares similar observations for
ditions we expect the models to run. From our obser- mobile applications in general and proposes modeling
vations this undertaking seems impractical as it would techniques to predict the non-determinism in perfor-
require a fleet of devices. mance with general forms of Gaussian. The follow-on
The much higher performance variability in the pro- work [36] takes a data-driven approach with the use of
duction environment is likely due to higher system ac- arbitrary polynomial chaos expansions which approxi-
tivities in deployed smartphones and the environment mates stochastic systems by a set of orthogonal polyno-
the smartphones are in (e.g., the ambient temperature mial bases, without any assumption of workload/system
or how many Apps a user allows to run concurrently). statistical distribution. With the ability to model per-
Concurrent processes or background activities cause re- formance variability, a certain level of inference perfor-
source contention, leading to performance perturbation [32]. mance can be guaranteed, leading to overall better qual-
Furthermore, the performance of mobile processors is ity of user experience.
not only limited by processor junction temperature but In summary, the significant performance variability
also smartphone surface temperature for ergonomic re- observed for mobile inference introduces varied user ex-
quirements [33, 34]. This means that, depending on perience. If taking a classic approach to modeling and
how and where smartphones are used, the likelihood of evaluating ML model performance and energy efficiency
thermal throttling is potentially much higher in the pro- with an average value of experimental runs, designers
duction environment, representing more realistic usage risk the chance for delivering the required level of per-formance quality. Thus, particularly for mobile infer- scale of Facebook . DSPs have more robust software
ence benchmarking, it is critical to describe how severe stacks. However, porting code still takes a long time
performance variability is for a design. One option is as the implementation must be signed and whitelisted
to represent evaluation results (for e.g., inference time by DSP vendors. The story for Apple devices is bet-
performance) with the information of average, maxi- ter, partially because there is so much less variety of
mum, minimum, and standard deviation of experimen- devices and software. Metal also plays a large role as
tal measurement values. Furthermore, our observation it is relatively straightforward to use. Therefore, many
here also pinpoints the importance of in-field studies for iPhone inference are run on mobile GPUs. With the
machine learning designs. introduction of Vulkan and DSP engineering efforts, in-
ference are making their way into co-processors. Look-
7. DISCUSSION AND FUTURE DIRECTIONS ing forward, more research and engineering effort put
into making existing mobile GPU and DSP hardware
This section discusses the implications from the re- more amenable to processing DNN inference has a high
sults shown in this paper which influence the important impact to ML adoption at the edge.
design decisions within Facebook. We also highlight the Co-processors and accelerators are used for
research directions for the years to come. power and stable performance; speedup is of-
The majority of mobile inference run on CPUs. ten secondary. The main reason mobile inference are
Given all the engineering efforts put into accelerating ported to a co-processor is for improved efficiency and
DNN inference with co-processors and accelerators, it dependable, predictable execution time. While there
is somewhat counterintuitive that inference on Android are applications that require specialized hardware for
devices are processed on mobile CPUs. The reality is performance, we suspect this finding is not a Facebook
that it is currently too challenging to maintain code or DNN-specific phenomenon. Because our main focus
bases optimized to perform well across the wide range is end-user usability, unless the performance gain is sig-
of Android devices (Section 2). Moreover, as illustrated nificant (e.g., 50x) and achieved using better tools and
in Figure 1, even if we did port all inference to run infrastructure, it is unlikely most of these accelerators
on co-processors, the performance gains would not be will actually be utilized when found on mobile devices.
substantial enough to justify the implementation effort. Accuracy is a priority, but it must come with
Most inference run on CPUs that are at least a reasonable model size. The accuracy of a DNN
six years old. Future facing research is important, but model can be tied directly to user experience [1]. It is
the reality is that having large-scale, global impact on also generally true that larger models result in higher
smartphones may be further off than what we think. accuracy. When it comes to mobile, it is important to
As presented in Section 2, most inference are made on maximize accuracy while keeping model sizes reason-
processors released in 2011 and 2012, respectively. This able. Facebook focuses on model architecture optimiza-
isn’t just a case of old smartphones that are still being tion to identify highly-accurate models while minimiz-
out there or being left on. A major portion of these ing the number of parameters and MACs. Trained mod-
smartphones are sold in the recent one to two years. els are then further refined for efficiency with aggressive
To provide the same experience to all Facebook users, quantization and weight/channel pruning. Looking for-
substantial software optimization efforts are targeted in ward, methods to improve architecture search, includ-
optimizing inference for these CPUs—ones that repre- ing techniques, such as BayesOpt [37, 38], AutoML [39]
sent the largest market share. and [40], are of important interest.
The performance difference between a mobile There is also a big push for generally applicable opti-
CPU and GPU/DSP is not 100×. Given the per- mizations. Recent work on hardware for machine learn-
formance gap between server CPUs and GPUs is usually ing and efficient training and inference has substantially
60-100×, one might suspect that a similar trend is found advanced the state-of-the-art [41, 42, 43, 44, 45, 46, 47,
on the mobile side. However, this is not the case. Mo- 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62,
bile GPUs, and even DSPs, are less than 9 × faster than 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77].
mobile CPUs. Similar finding is found in [6]. This is Many of the ideas being published in the top architec-
largely because mobile GPUs were not designed to pro- ture conferences are custom hardware specific and not
cess the same class of high-resolution graphics render- applicable to general-purpose existing SoCs.
ing that discrete GPUs are. Mobile GPUs help offload Performance variability is a real problem. An
image processing in a relatively low-end environment. often overlooked issue in the architecture research com-
DSPs are slightly more promising–mobile inference are munity is performance variability, which results in a
slowly transitioning to execute on DSPs. Furthermore, serious concern for real-time and user-facing systems.
many mobile CPUs come with a decently provisioned Optimizing designs for the average case risks user ex-
SIMD unit, which when properly programmed provides perience for a large portion of the market share while
sufficient performance for vision-based inference. targeting designs for all mobile devices in the market
Programmability is a primary roadblock to us- implies conservative design decisions. It is important to
ing mobile co-processors/accelerators. As seen in present performance results taking into account perfor-
Section 2, one of the main challenges with using GPUs mance distribution, particularly for mobile inference.
and DSPs is programmability. For Android smartphones, Researchers need to consider full-picture and
OpenCL is not reliable enough for a business at theYou can also read

















































