Optics for disaggregating Datacenters and disintegrating Computing - ONDM 2019
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Optics for disaggregating Datacenters and
disintegrating Computing
N.Terzenidis, M.Moralis-Pegios, S. Pitris, G.Mourgias-Alexandris, A. Tsakyridis,
C. Vagionas, K. Vyrsokinos, T. Alexoudi, C. Mitsolidou, N. Pleros
ARISTOTLE UNIV. OF THESSALONIKI Wireless and Photonics Systems and Networks (WinPhos) Lab
Dept. of Informatics, Aristotle Univ. of Thessaloniki,
Center for Interdisciplinary Research & Innovation (CIRI), Greece
The energy problem: World’s No. 1 HPC
No.#1: IBM Summit (top500.org Nov. 2018 List)
200 Pflops (20%
of Exascale target)
10MW (50% of the
20MW limit)
Energy in DataCenters (% of global power) :
1.6% >3%(420TWh) ~20%
2014 2016 2025
Nikos Pleros
The energy efficiency problem
Intel Whitepaper, 2015
High diversity of workloads with different resource requirements
up to 50% underutilized resources..impacting cost and energy !
Nikos Pleros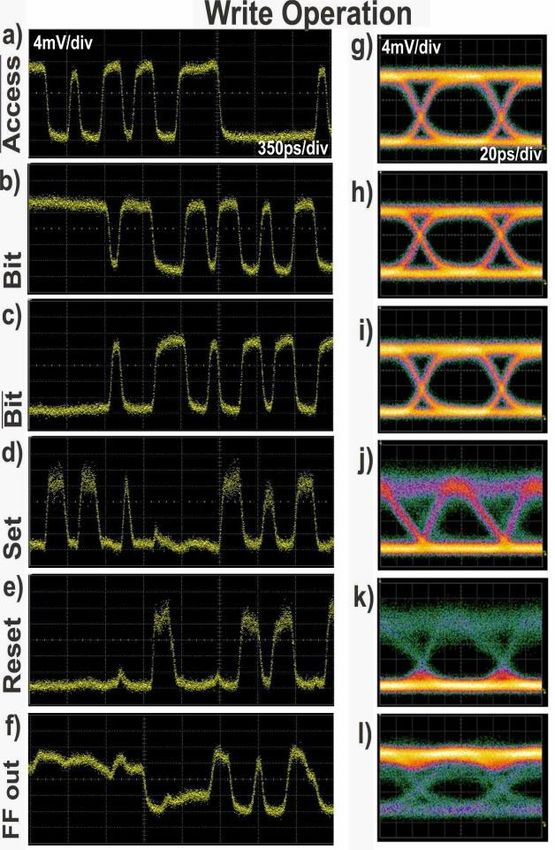
The way-out
Energy Resource utilization
Technology Architecture
Photonics Disaggregation
Nikos Pleros
Challenges across the hierarchy
hierarchy
>2μsec latency in < 8-node connectivity Non-modular settings with
high-port switches in p2p QPI-based >40% on-die caches
Energy increases High-latency in non- Energy dominated by
with capacity p2p switched-based memory access
Nikos Pleros
Our work
T. Alexoudi et al, “Optics in Computing: from Photonic Network-on-Chip to Chip-to-Chip Interconnects and Disintegrated Architectures “, JLT 2019
disaggregate at rack-level…
down to disintegration at
chip-level
hierarchy
Hipoλaos Optical Packet On-board Optical Static RAM 1.48 cm
Switch disaggegration with technology
Test
structures
18 SOAs
>8 sockets in p2p
44 I/O
1024x1024 ports, 10T Disintegrate via off-
capacity scalable to >40T Low-energy, low- chip high-speed
sub-μsec latency latency with Si-Pho optical caches
Nikos Pleros
The Hipoλaos Optical Packet Switch
1024x1024 -port Multicasting Si-integration ?
N. Terzenidis et al, ECOC, Sept. 2018 N. Terzenidis et al, IEEE PTL, pp. 1535- M. Moralis-Pegios et al, IEEE PTL
1538, Sept. 2018 pp. 712-715, April, 2018
N. Terzenidis et al, ONDM 2019 to demonstrate performance in a 256-
node network
Nikos Pleros
Disaggregate at board-level
Beating QPI: a p2p board-
level optical interconnect
for >8 sockets
Nikos Pleros
The inner-anatomy: board-level
Switch-based Direct P2P - High-End Servers
CISC processors INTEL (x86)
Intel® Xeon®
processor E5-4600
• PCIe
INTEL QPI, AMD HyperTransport, IBM POWER8 SMP
• RapidIO Links, Oracle SPARK Coherence links, NVIDIA NVlink
Unlimited connectivity Low-latency, low-power
Increased latency, power, Limited connectivity
cost, size
Nikos Pleros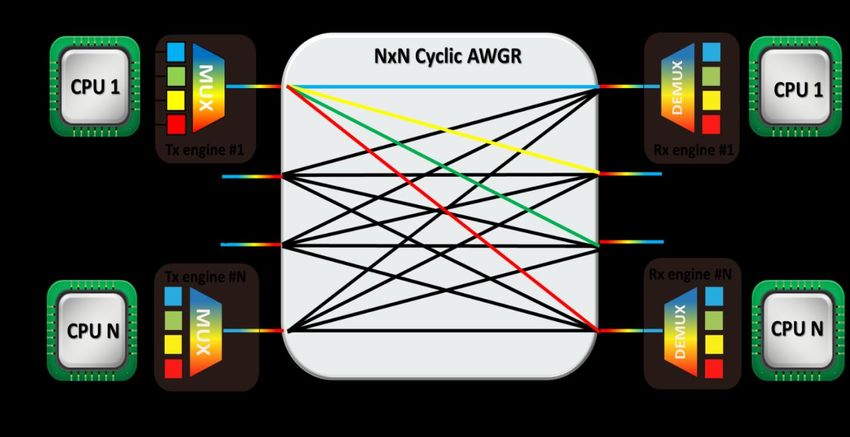
QPI
102.4Gb/s
4s-“glueless”
…the dominant P2P link
architecture
4 sockets P2P connected
9.6 Gb/s line rate 8s- “glueless”
38.4 GB/s BW (307.2 Gb/s architecture
up to 2-hop
or 102.4 Gb/s /direction)
Increased latency
60ns-240ns Latency
16 pJ/bit TxRx power
efficiency
Intel Xeon E7-8800v4: 1st Intel Processor to support
up to 8-socket ! (released June 2016)
Nikos PlerosGoing beyond 8 sockets?
Bixby (BX) switches
January 2017
Price/performance drastically decreases as #processors increases
Latency increases
65% of QPI Bandwidth wasted for cache coherency updates
Nikos PlerosThe ICT-STREAMS O-band technology
www.ict-streams.eu
16x50Gb/s WDM
TxRx SiP O-band
16x16 AWGR- O-band
1300nm SM EOPCB with 50G RF Nikos PlerosThe ICT-STREAMS p2MP architecture
Strictly non-blocking High bandwidth optical links
All-to-All connectivity No O/E/O conversions
Suitable for broadcasting/multicasting Passive (no power consumption)
High number of ports (up to 32) Time of flight latency
Nikos PlerosSTREAMS vs QPI
QPI STREAMS gain
Sockets/
Up to 8 >16 x2
nodes
#hops up to 2 1 ÷2
Line rate 9.6 Gb/s 50 Gb/s x 10
Link BW 307.2 Gb/s 16x50 Gb/s x 2.6
Throughput 2.45 Tb/s 12.8 Tb/s x 5.2
Power
16 pj/bit < 3.5 pj/bit ÷4
efficiency
Nikos PlerosThe on-board routing platform
8×8 O-band Si-AWGR
S. Pitris et al., Opt. Express 26(5), 2018
Nikos PlerosSi-based 8x8 O-band AWGR technology
S. Pitris et. al., OFC 2018
S. Pitris et. al., OpEx 2018
10nm ch. spacing
channel crosstalk : 11 dB
3-dB bandwidth 5.7nm
non-uniformity : 3.5 dB loss,
insertion losses: 2.5 dB loss
Nikos PlerosSi-AWGR on board
AWGR chip
18mm
30mm
Si-AWGR onto an EOPCB for on-board routing
Testing currently on-going
Nikos PlerosMultisocket routing @40Gb/s
40 Gb/s O-band RM 8×8 O-band Si-AWGR 40G PD & BICMOS TIA
S. Pitris et al., IEEE PJ 2018 S. Pitris et al., Opt. Express, 2018. S. Pitris et al., PJ 2018
Nikos Pleros8x40Gb/s multi-socket Tx/Rx/routing
S. Pitris et al., IEEE Photon. J., Oct. 2018
RM: 1.7pJ/bit @40Gbps
TIA: 4 pJ/bit @40Gbps
5.7pJ/bit for Tx/Rx link
(incl. thermal tuning)
Nikos PlerosThe WDM Transceiver engine
4ch Si-pho WDM TxRx
S. Pitris et al., OFC 2019
Nikos Pleros4x40Gb/s O-band Si WDM transmitter
S. Pitris et. al., OFC 2019
Mask Layout
ER = 4.4 dB ER = 4.1 dB ER = 4 dB ER = 4.2 dB
Tx1 Tx2 Tx3 Tx4
2mV 10ps/div
λ1=1310.25 nm λ2=1303.23 λ3=1317.28 nm λ4=1324.59 nm
Nikos Pleros4x50Gb/s on-board WDM transmitter
4-channel 55nm BiCMOS DR Tx out 1 @ 50 Gb/s NRZ
(λ=1314.9 nm)
High Speed TX RF traces
ER = 4.3 dB
HF 4mV-10ps/div
Board DC traces RM-driving voltage = 1.9 Vpp
EE=1.525pJ/bit/RM +
0.8 pJ/bit (tun)
Rx TIA out 1 @ 30 Gb/s NRZ
(λ=1318.4 nm)
High Speed RX RF traces
4-channel 55nm BiCMOS TIA
10mV-20ps/div
All 4-channels capable of >50G operation TIA output voltage = 120 mVpp
PCTIA=130mW/ch
Nikos Pleros1-Volt 50Gb/s x 52km transmission
FDSOI CMOS DR H. Ramon et al., IEEE PTL 30, 2018.
Micro-ring Modulator M. Moralis-Pegios et al., OECC/PSC 2019
BER measurements @ 40 Gb/s
1V-driven 50 Gb/s NRZ operation &
transmission at 52 km through SMF
EE = 0.8 pJ/bit @ 50 Gb/s
Record-high BxL
= 2600 Gb-km/s
Power penalty = 0.2 dB @10-9
Nikos PlerosThe energy-latency gain
Power
Device Ref. EE@40Gb/s EE@50Gb/s
consumtpion
LD [1] 6.1 dBm 1 pJ/bit 0.8 pJ/bit
RM DRIVER +
This work 40 mW + 40 mW 2 pJ/bit 1.6 pJ/bit
TUNING
PD TIA This work 130 mW 3.25 pJ/bit 2.6 pJ/bit
SerDes [2] 11.6 mW 0.29 pJ/bit 0.232 pJ/bit
1 S. Pitris et al, PJ 2018
2 V. Stojanovic, OPEX 2018 Totals 6.54 pJ/bit 5.23 pJ/bit
%Reduction to QPI ~60% ~68%
~68% energy savings compared to QPI
with >4-node direct connectivity !
Nikos PlerosDisintegrate at chip-level
Optical RAMs: disintegrate
via off-chip optical caching
Nikos PlerosWhy to disintegrate?
Yigit Demir et al, “Galaxy: A High-Performance Energy-Efficient ORACLE, Pranay Koka et al, “Silicon-Photonic Network Architectures
Multi-Chip Architecture Using Photonic Interconnects”, ICS 2014 for Scalable, Power-Efficient Multi-Chip Systems”, ISCA 2010
Smaller dies (chiplets) interconnected through optics
Relieve from area & power constraints – ease scaling to many-core
>2x speed-up in512-core (Oracle) and 4k-core (Galaxy) settings
Nikos PlerosOn-chip caches and memory bandwidth
Evolution of on-die caches
40%
[Source: S. Borkar and A.A.Chien, Com. ACM, 2011] [Source] INTEL
Memory speed-up mainly through hierarchical levels
Large and complex two or three level cache hierarchies
Up to 40% of chip real-estate consumed by caches and X-bar
StillOur goal
Now!
CMP:
cores p-NoC
only! o/e o/e
optical
cache
Modular and granular setting with cache-free cores and a unified,
shared pool of cache resources
Needs an ultra-fast optical cache for time-sharing between lower-
clock cores Nikos Pleros10 Gbps Optical RAM
A. Tsakyridis et
al, CLEO 2019 First to exceed electronics
2x the Speed: 10Gbps
Up to 5GHz RAM speed
Fail to exceed electronics
Give up access times for
lower footprint/power
Nikos Pleros10 Gbps Optical RAM
10 Gb/s monolithic InP Flip-Flop
Packaged Optical Memory
BER penalties: Write 6.2 dB, Read 0.4 dB
A. Tsakyridis et al, CLEO 2019, A. Tsakyridis et al, OSA Optics Letters 2019
Nikos Pleros10 Gbps Optical RAM
Nikos PlerosConclusions
hierarchy
Hipoλaos Switch On-board p2p >8 sockets 10GHz Optical SRAM: 2x
5.2pJ/bit link @50Gb/s the speed of electronics
1024x1024-port
Synergy between Si-based RAM layout +
sub-μsec latency
technology+architecture: Optical cache design
Scalable to 10Tbps
68% energy save over QPI Modular, granular, flexible
with 113pJ/bit
Nikos Pleroswww.ict-streams.eu
Contacts:
Prof. Nikos Pleros : npleros@csd.auth.gr
Dr. Theoni Alexoudi : theonial@csd.auth.gr
Nikos PlerosBack-up slides
Nikos PlerosThe Si-based Optical SRAM
Hybrid PhC-based laser Flip Flop with only 13fJ/bit
*In collaboration with F. Raineri and R. Raj, C2N/CNRS
Lowest power consumption FF
Switching energy 6.4 fJ/bit@ 5 GHz 3.2 fJ/bit@ 10 GHz
Input
*T. Alexoudi et al, JSTQE (2016)
* D. Fitsios et al, Optics Express, (2016)
6.2μm2 footprint Output
The first optical cache design
* P. Maniotis et.al., "Optical Buffering for Chip Multiprocessors: A 16GHz Optical Cache Memory Architecture,” JLT, pp.4175-4191, 2013
Optical cache simulations @ 16GHz Optical RAM
Peripheral Circuits
WDM Row Access Gate +
Access Gate + Col. Decoder
optical Column Decoder
memory Row Decoder Row Decoder
address Tag Comparator
Experiments @10Gb/s
Tag Comparator
WDM
optical
word / Fast Optical RAM cell:
data
design+theory > 40GHz
experiment @10GHz
Record-low power
Nikos PlerosCaching with light at 16Gbps
VPI simulations with exp.verified SOA model
Write operation
Write to row “00”: Only when both λ1,λ2=0 &
RW=0 (green area) the FF contents follow the
Bit contents (blue area)
average ER 6.2 dB
average AM 1.9 dB
close to experimental values!
Nikos PlerosAnd compare…
CONVENTIONAL TOPOLOGY OPTICAL TOPOLOGY
8 cores, 2GHz clock 8 cores, 2GHz clock
Dedicated L1 16GHz cache clock
Shared L2=8xL1 Off-die shared L1 – no L2
Nikos PlerosExecution times for PARSEC L1 Conventional
L1+L2 Conventional
2xN GHz Optical
MEAN 63.4 62.7
*P. Maniotis et al."High-Speed Optical Cache Memory as Single-Level Shared
19.4 10.7
Cache in Chip-Multiprocessor architectures," in Proceedings of HIPEAC15, 19-21 January, 2015
Nikos PlerosYou can also read

















































