Predicting the Semantic Orientation of Emoticons
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Journal of Computational Information Systems 9: 6 (2013) 2391–2398
Available at http://www.Jofcis.com
Predicting the Semantic Orientation of Emoticons
Fei WANG 1 , Yifeng XU 1 , Yunfang WU 1,∗, Xueqiang LV 2
1 Institute of Computational Linguistics, Peking University, Beijing 100871, China
2 Beijing Key Laboratory of Internet Culture and Digital Dissemination Research, Beijing Information
Science and Technology University, Beijing 100192, China
Abstract
Emoticons are widely used in blogs, instant messages and social networks, which often imply some
positive, negative or neutral semantic orientation, and so are widely exploited in sentiment analysis. In
this paper, we take a pictographic view on emoticons, and propose symbol-pair method and substring
method to automatically predict the semantic orientation of out of vocabulary emoticons. The experime-
ntal results are promising, achieving an accuracy of 78%.
Keywords: Emoticons; Sentiment Orientation; Symbol-pairs; Pair-based Method; Substring Method
1 Introduction
With the popularity of microblogging services like Twitter, microblog is now considered as the
intersection of blog, instant message and social network. It provides considerable data for business
and political organizations to track public opinions. Microblog also boosts the development and
popularity of network language, which contains many interesting linguistic phenomena. Among
them, emoticons form notable characteristics of microblog and have attracted the attention of
many researchers in the field of sentiment analysis.
According to Wikipedia1 , there are five types of emoticons, including: (1) Western emoticons2
(ASCII strings like “:)smile ” “>: [f rown ”); (2) Eastern emoticons (pictographic Unicode strings like
“(T T)crying ”); (3) 2 channel emoticons (complicated multiline Unicode blocks); (4) Graph emoti-
cons (widely used in instant messages like ); (5) Unicode emoticons (Unicode characters
like © §). Table [1] gives a detailed description.
According to our investigation in Sina Microblogging3 which is a popular Chinese microblogging
platform, graph emoticons and eastern emoticons are most widely used. Graph emoticons are
∗
Corresponding author.
Email address: wuyf@pku.edu.cn (Yunfang WU).
1
http://en.wikipedia.org/wiki/List of emoticons
2
In this paper, we mark the meaning of an emoticon in the superscript. For example, :)smile tells that :) is an
emoticon and it means smile.
3
http://weibo.com/.
1553–9105 / Copyright © 2013 Binary Information Press
March 15, 20132392 F. Wang et al. /Journal of Computational Information Systems 9: 6 (2013) 2391–2398
Table 1: Types of emoticons
Emoticon Type Examples Characters
smile unhappy f rown
Western Emoticons :) :( >: [ ASCII strings
Eastern Emoticons (T T)crying orzkowtow cheer
Pictographic
somebody wearing a tall hat
2 Channel Emoticons , Stereotypical (multiline),
do it
graphic,complicated
Graph Emoticons Used in MSN, etc.
Unicode Emoticons ©§ Unicode characters
provided by a popup window, from which you can choose one or more emoticon(s). This means
that the number of graph emoticons is fixed. On the contrary, eastern emoticons (like “(T T)”
and “ ” ) can be either provided by an input method or created by users, making it much
more irregular and complex. As a result, eastern emoticons are expanding rapidly, and there are
a lot of out of vocabulary emoticons that need to be assigned with proper polarity tags.
However, there is little work devoting to predicting the semantic orientation (SO) of emoticons
themselves. On Chinese microblogging platforms, new emoticons are produced almost every day,
and consequently there are many emoticons that are out of vocabulary. Therefore, to predict the
SO of unknown emoticons is vital to sentiment analysis as well as social computing in microblog.
In this paper, we will focus on predicting the SO of eastern emoticons as well as a few frequently
used western emoticons like “:-)” and “:-(”. We propose two methods to tackle this task: a
symbol-pair method and a substring method. Given 28 positive and 25 negative emoticons as
seed emoticons, our method achieves an accuracy of 78% , extracting 134 true positive and 158
true negative emoticons. To the best of our knowledge, this is the first work to automatically
predict the SO of emoticons.
2 Related Work
Emoticons are mainly used in two ways: acting as class labels and working as features.
Recently, researchers use emoticons to label a tweet as positive or negative and thus avoid the
labor intense work of annotation. Pak et al. [1] [2] search Twitter using two types of emoticons,
i.e., happy emoticons like :) and sad emoticons like :(, to generate a positive and negative dataset.
Davidov et al. [3] proposes a new method to classify tweets into multiple sentiment categories by
using hashtags and smileys as clues. Yang et al. [4] uses blog posts containing certain emoticons
to form a readily available corpus for emotion classification. Read [5] uses emoticons as indicators
of emotions to automatically classify texts as positive or negative. By utilizing emoticons as
sentiment labels, the framework avoids the need for labor intensive manual annotation, allowing
identification and classification of sentiment/emotion types of texts.
Besides acting as labels, emoticons have also proved to be important features in Twitter senti-
ment analysis [6]. Instead of using a raw word representation, Barbosa[6] creates a more abstractF. Wang et al. /Journal of Computational Information Systems 9: 6 (2013) 2391–2398 2393
representation of tweets, utilizing Meta-features and Tweet Syntax Features. The latter one
includes retweet, hashtag, reply, link, if the tweet contains a link, punctuation, emoticons and
upper cases. What is more, emoticons are employed to predict retweet events and analyze user
behavior. Naveed et al.[7] finds that negative emoticons are supportive to “bad news travel fast”
and can be used in retweet prediction. Rao et al.[8] demonstrates that the presence of certain
kinds of emoticons can be strong indicators of female users when classifying latent user attributes.
Knowing more about the Sentiment Orientation of the emoticons may of greater help in works
above.
3 A Pictographic View on Emoticons
In this paper, we prefer looking at emoticons from a pictographic view. Table 1 explains the
pictographic character of emoticons, where color black denotes eyes; red denotes mouth; purple
denotes face contours; green denotes hands-arms; blue denotes other elements.
Table 2: The pictographic feature of emoticons
Types Emoticons Descriptions
positive smiling eyes, happy face
happy face, waving arms
happy face, pout, kissing
negative weeping eyes, sobbing nose
sweating
Helplessness, shrugged shoulder
From Table [2], we can find out the following characteristics of emoticons.
• An emoticon consists of several symbols, which represent some facial parts or body move-
ments. For instance, consists of nose , eyes , face contour and arms
.
• The symbols are often occurring in parallel pairs. For instance, in , pair
represent two eyes, pair represent face contour, and pair represent two-arms.
• Given an emoticon, we could extract each pair from outside in. For example, given the
emoticon , we extract pair , pair and pair . According to our observation,
we define: the innermost pair as eyes-pair (like ); the symbol between two eyes as mouth-
element (like ); the outmost pair as out-pair that may represent face contour, hands or
others (like ); the remaining elements outside the out-pair as odd-element. When there
is only one pair in an emoticon, we regard it as eyes-pair instead of out-pair. For example,
in emoticon , the eyes-pair is , the mouth-element is , and the odd-element is .
• The SO of emoticons can be computed by the polarities of component symbols. For instance,
according to the waving arms and the happy eyes , we can infer that has
positive meaning. Given the sweat , we could imply that has negative meaning.2394 F. Wang et al. /Journal of Computational Information Systems 9: 6 (2013) 2391–2398
4 Determining Candidate Emoticons
In order to predict the SO of emoticons, we should firstly determine whether a string constitutes
an emoticon or not. For instance, “∼∼!!!” is not an emoticon.
In our experiments, the symbols that ever appear in the seed emoticons are called seed-symbols.
We define candidate emoticons as follows:
(i) emoticon → P (S|P )∗ P
(ii) P → seed-symbols
(iii) S → white-space
What is more, an emoticon should obey the following principles. It should not (1) begin
with ?,!,or ; (2) be longer than 15 Unicode characters; (3) contain too much successive spaces;
(4) contain too many continuously appearance of the same character. Rule (4) is used to filter
noises like “!!!!!!!!”, “∼∼∼!”, “∼ ∼∼”, which are frequently appeared in microblogs but barely
emoticons.
5 Predicting the SO of Emoticons
Following the observation of Section 3 and after the processing of Section 4, we will predict the
SO of emoticons using the following methods.
5.1 Symbol-pair method
The symbol-pair method is designed following our innovation to capture the pair-significant pic-
tographic feature of emoticons. It consists of two steps. Step 1 finds out the SO of seed symbols,
and Step 2 computes the SO of emoticons according to the component seed symbols.
• Step 1. We build a seed emoticon set from Sougou pinyin input method4 , which pro-
vides 108 emoticons at the time of our experiment, including 102 eastern emoticons and 6
western emoticons. We delete the spaces and Chinese characters from each emoticon. For
example, both “ ” and “ ” are transformed to “ ”. We remove duplicate
emoticons after the above transformation, and are left with 80 emoticons. We manually
label each emoticon as positive, negative or neutral. Then we automatically identify the
mouth-element, eyes-pair, out-pair and odd-element from each emoticon. If one pair or ele-
ment exclusively appears in emoticons of only one SO category, we assign the corresponding
SO to that pair or element; otherwise we assign neutral to it. For example, eyes-pair
exclusively appears in positive emoticons, so we assign positive to pair .
• Step 2. For each candidate emoticon, we extract all the symbol pairs from outside in;
identify odd-element, out-pair, eyes-pair and mouth-element, respectively. Then, we com-
pute the SO of each emoticon according to the identified pairs and elements, using a voting
method. It returns neutral when positive and negative get the same vote. If there is no
symbol pair, it returns false, indicating that the candidate emoticon cannot be judged as a
real emoticon.
4
A popular input method in China, can be downloaded from http://pinyin.sogou.com/F. Wang et al. /Journal of Computational Information Systems 9: 6 (2013) 2391–2398 2395
Following the intuition that symbols representing eyes and mouth play a more important role in
determining the SO of emoticons, we use a weighted vote strategy. Let out-pair and odd-element
get weight 1, eyes-pair will get weight 5 and mouth-element will get weight 3.
When dealing with odd-element, we employ partial match instead of exact match, for the
concerns of instances like ‘- -|||’,‘- -|’,‘- -||||||||||’ where all the odd-elements follow the pattern ‘|+ ’
that symbolize sweat. When a partial match occurs, it gets 0.5 times the weight of an exact
match to reduce the impact of noise from the partial match.
5.2 Substring method
The substring method is designed to capture a few frequently used western emoticons like :) and
wink
a few emoticons where pairs are not obvious. For example, emoticon cannot be captured
by the above symbol-pair method, because the symbol representing eyes is not a pair. But
it can be captured by the substring method, finding it quite similar to . This method also
contains two steps.
• Step 1. Compute the similarity between candidate emoticons and each seed emoticon, by
calculating the longest common subsequence (LCS). The similarity score is defined as:
Len(LCS)
similar score = Len(seed emotion)
• Step 2. The SO of the seed emoticon which gets the highest similarity score is then assigned
to the candidate emoticon. The similarity score should be larger than a predefined threshold
(set to 0.6 in our experiment), otherwise it would return false. If more than one seed
emoticons get the highest similarity score, and these have different SO, then the method
returns false.
5.3 Combining method
The symbol-pair and substring method have some complementary properties, so we can combine
them to get better performance. Assuming SO1 and SO2 are SO predicted by two methods, we
use the following matrix to decide the final SO.
Table 3: Decision Matrix
SO2
Positive Negative Neutral False
Positive Positive Neutral Positive Positive
Negative Neutral Negative Negative Negative
SO1
Neutral Positive Negative Neutral Neutral
False Positive Negative Neutral False2396 F. Wang et al. /Journal of Computational Information Systems 9: 6 (2013) 2391–2398
6 Experimental Results
6.1 Data
We downloaded 133,065 microblogs using Sina API. We extracted 3,225 strings following (i)–
(iii), with 1,764 of them filtered by rules (1)–(4) described in Section 4. We applied the three
methods on the remaining 1,461 candidate emoticons and 1,075 of them were finally judged as
real emoticons. Two people separately labeled these 1,075 emoticons with positive, negative and
neutral, and the kappa value of the inter-annotator agreement is κ = 0.743. The third person
labeled the emoticons with disagreement. Finally, three people voted for the final judgment.
When the SO given by three people differed from one another, we assigned neutral to the emoticon.
Figure[1] demonstrates the distribution of positive/negative/neutral emoticons in our labeled
data.
Fig. 1: The distribution of SO types in our labeled emoticons
6.2 Results
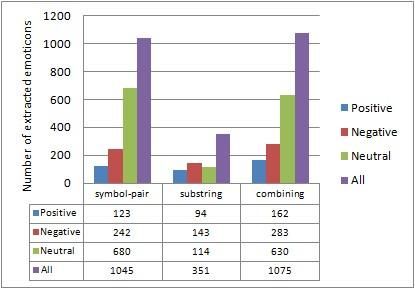
Figure [2] illustrates the number of positive/negative/neutral emoticons extracted by these three
methods. Table [4] lists the contingency table constituted by the number of extracted emoticons
(Ext) against the true answers (Ans), as well as the accuracy of each method. We would like
to mention that among the 162/283/630 positive/negative/neutral emoticons extracted by the
combining method, 51/51/92 of them can be extracted by both methods.
Table 4: The performance of different methods
aa symbol-pair method substring method combining method
a Ext
Ans aaa
a Pos. Neg. Neutral Pos. Neg. Neutral Pos. Neg. Neutral
Pos. 106 5 37 79 1 5 134 5 21
Neg. 2 130 85 0 102 48 2 158 65
Neutral 15 107 558 15 40 61 26 120 544
Accuracy 0.76 0.69 0.78F. Wang et al. /Journal of Computational Information Systems 9: 6 (2013) 2391–2398 2397
Fig. 2: The number of emoticons extracted by different methods
The symbol-pair method extracts more emoticons and obtains higher accuracy than the sub-
string method, and the combining method gets better performance than each isolated approach,
achieving an accuracy of 78%. The symbol-pair method performs better on positive emoticons
with a precision of 86.2%, while the substring-based method performs better on negative emoti-
cons with a precision of 71.3%.
The experimental results are generally promising. There are 28/25 positive/negative emoticons
in our seed set, and the numbers expand to 134/158 after our work. Among all the extracted
emoticons, only 41 emoticons exactly match the ones in the seed, and we correctly predict 251 new
sentiment bearing emoticons. Table [5] gives some examples of new sentiment bearing emoticons
extracted by our method.
Table 5: Some examples extracted by combining method
Positive Examples Negative Examples
(∧ ∼)v ◦∩ ∩◦ ORZZZZZ = =b
Y(∧ ∧)Y (∧ ◦ ∧)/ ∼ T T · ·· - -...
◦(∧ 5 ∧)◦ ;-) >2398 F. Wang et al. /Journal of Computational Information Systems 9: 6 (2013) 2391–2398
wrongly computed as neutral. Both “ ” and “ ” are odd-elements that havent been seen in
the seed set. But these two odd-elements are sentiment bearing, implying “I doubt” or “what
the heck” emotion.
7 Conclusions
This paper attempts to predict the SO of out of vocabulary emoticons. Capturing the pair-
significant pictographic feature of emoticons, we propose two new methods, symbol-pair method
and substring method, to compute the SO of emoticons automatically. The experimental results
are general promising, 251 new sentiment bearing emoticons are correctly predicted.
The sentiment of emoticons and their context are expected to be consistent. In future work,
we would like to employ the sentiment of detected emoticons to promote sentiment analysis of its
containing text, and meanwhile, correct the SO of emoticons within context.
Acknowledgement
This work is supported by 2009 Chiang Ching-kuo Foundation for International Scholarly Ex-
change (under Grant No. RG013-D-09), National High Technology Research and Development
Program of China (863 Program) (No. 2012AA011101) and the Opening Project of Beijing Key
Laboratory of Internet Culture and Digital Dissemination Research(No. ICDD201202).
References
[1] Alexander Pak and Patrick Paroubek, Twitter as a Corpus for Sentiment Analysis and Opinion
Mining. In Proceedings of LREC, 2010.
[2] Alexander Pak and Patrick Paroubek, Twitter Based System : Using Twitter for Disambiguating
Sentiment Ambiguous Adjectives, In Proceedings of the 5th International Workshop on Sentiment
Evaluation, ACL, 2010, pp. 436 – 439.
[3] Dmitry Davidov, Oren Tsur and Ari Rappoport,Enhanced Sentiment Learning Using Twitter
Hashtags and Smileys, In Proceedings of COLING, 2010, pp. 241 – 249.
[4] Changhua Yang, Kevin Hsin-Yih Lin, Hsin-His Chen, Building Emotion Lexicon from Weblog
Corpora, In Proceedings of ACL, 2007, pp. 133 – 136.
[5] Jonathon Read, Using Emoticons to Reduce Dependency in Machine Learning Techniques for
Sentiment Classification, In Proceedings of the ACL, 2005 Student Research Workshop, pp. 43 –
48.
[6] Luciano Barbosa and Julan Feng, Robust Sentiment Detection on Twitter from Biased and Noisy
Data, In Proceedings of COLING, 2010, pp. 36 – 44.
[7] Nasir Naveed, Thomas Gottron, Jérôme Kunegis, Arifah Che Alhadi, Bad News Travel Fast: A
Content-based Analysis of Interestingness on Twitter, In Proceedings of the ACM WebSci, 2011,
pp. 1 – 7.
[8] Delip Rao, David Yarowsky, Abhishek Shreevats, Manaswi Gupta, Classifying Latent User At-
tributes in Twitter, In Proceedings of SMUC, 2010.You can also read