The brief view on Google Translate Machine
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
1
The brief view on Google Translate Machine
Omid Karami, Student of Vienna University of Technology
A. Rule-Based MT
Abstract—I have tried to describe briefly about
Rule-Based Machine Translation (RbMT) systems use
Google machine translate history and some of the
large collections of rules, manually developed over time
methods are used in it. In the following paper, I have
described RbMT and SMT strategy, which are two by human experts, which map structures from the source
major Machine translate technique. One of to the target language.
modeling translate is presented in naïve way and also The software parses text and creates a transitional
two decoding algorithms. I have also mentioned some representation from which the text in the target language
basic formulas which are used widely on statistical is generated. This process requires extensive lexicons
method. with morphological, syntactic, and semantic
information, and large sets of rules. The software uses
these complex rule sets and then transfers the
Index Terms— Google MT, Machine translate, grammatical structure of the source language into the
MT, RbMT, SMT. target language.
Translations are built on gigantic dictionaries and
sophisticated linguistic rules. Users can improve the out-
I. INTRODUCTION of-the-box translation quality by adding their
HE Machine translation (MT) is automated terminology into the translation process. They create
Ttranslation. It is the process by which computer user-defined dictionaries which override the system’s
software is used to translate a text from one natural default settings.
language (like English) to another (like Germany). In most cases, there are two steps: an initial investment
To process any translation, human or automated, the that significantly increases the quality at a limited cost,
meaning of a text in the original (source) language must and an ongoing investment to increase quality
be fully restored in the target language. However this incrementally. While rule-based MT brings companies
seems straightforward, it is really complex. Translation to the quality threshold and beyond, the quality
is not a just word-for-word substitution. A translator improvement process may be long and expensive.
must interpret and analyze all of the elements in the text
B. Statistical MT
and know how each word may influence another. This
requires extensive expertise in grammar, syntax Statistical Machine Translation (SMT) systems use
(sentence structure), semantics (meanings), etc., in the computer algorithms that explore millions of possible
source and target languages, as well as familiarity with ways of putting smaller pieces of text together, in an
each local region. effort to produce a translation that looks best. It utilizes
The challenge between Human and machine statistical translation models whose parameters stem
translation is to improve quality of machine translation from the analysis of monolingual and bilingual corpora.
to produce publishable quality translations, quality Building statistical translation models is a quick process,
translations.. but the technology relies heavily on existing
There are three common machine translation multilingual corpora. A minimum of 2 million words for
technologies in commercial use today: a specific domain and even more for general language
are required. Theoretically it is possible to reach the
quality threshold but most companies do not have such
large amounts of existing multilingual corpora to build
the necessary translation models. Additionally,
Omid Karami, Student of Vienna University of Technology; e-mail: statistical machine translation is CPU intensive and
e1129944@ student.tuwien.ac.at).
requires an extensive hardware configuration to run2
translation models for average performance levels. translation accuracy will sometimes vary across
languages [1].
C. Hybrid MT
The history of Google translate machine start from 2001
In order to address both quality and time-to-market based on rule-based MT at first It contain just six
limitations, many rule-based machine translation language English, France, German, Italian, Portuguese
developers are augmenting their core technology with and Spanish. (English to others). Then from 2004
statistical machine translation technology in what is Chinese, Japanese and Korean are added. In
referred to as ‘Hybrid’ machine translation. development time since 2006 Google is decided to
Rule-based MT provides good out-of-domain quality Statistic MT and start to add new languages Arabic and
and is by nature predictable. Dictionary-based Russian by this model. Furthermore since 2006, Google
customization guarantees improved quality and Translate has used proprietary, in-house technology
compliance with corporate terminology. But translation based on statistical machine translation instead. Since
results may lack the fluency readers expect. In terms of 2007, from the result of SMT molding decided to
investment, the customization cycle needed to reach the replace all of rule-based engine with statistic version
quality threshold can be long and costly. The and now all of language use SMT.
performance is high even on standard hardware. The core algorithm to make 'Google Translate - Machine
Translation' works is statistical machine translation
Statistical MT provides good quality when large and (SMT). SMT uses statistical model to determine the
word translation. This basic method doesn't follow any
qualified corpora are available. The translation is fluent,
language translation rules.
meaning it reads well and therefore meets user
To make statistical model, we need bilingual text
expectations. However, the translation is neither
corpora/corpus. Bilingual text corpus is a database of
predictable nor consistent. Training from good corpora
source sentences and target sentences. For example if
is automated and cheaper. But training on general we want to build statistical model for English to Spain
language corpora, meaning text other than the specified translation, we need a database of English sentences and
domain, is poor. Furthermore, statistical MT requires Spain translated sentences. The more sentences the
significant hardware to build and manage large better statistical model we have.
translation models.
Computer will be trained to calculate probability word
distribution statistic from above sentences. For example
II. GOOGLE TRANSLATE MACHINE if word AAA has probability 80% to be translated into
Google Translate (GT) is a popular translation service BBB, then we confident that AAA can be translated into
provided by Google to translate a word, a phrase, a BBB.
section of text or an entire web page into one of 51 Since it doesn't rely on any linguistic rule, SMT can be
languages mentioned below. Google translator cannot used to make translation any pair languages. Although it
only translate words and sentences, but also translate need times to make bilingual language corpora, but the
pages, books, and even an entire website. result is much better than ruled-based translation.
The stated goal of Google Translate is to make
information universally accessible and useful, regardless
of the language in which it's written. When Google
Translate generates a translation, it looks for patterns in
hundreds of millions of documents to help decide on the
best translation. By detecting patterns in documents that
have already been translated by human translators,
Google Translate can make intelligent guesses as to
what an appropriate translation should be. This process
of seeking patterns in large amounts of text is called
"statistical machine translation". Since the translations
are generated by machines, not all translation will be
perfect. The more human-translated documents that
Google Translate can analyze in a specific language, the
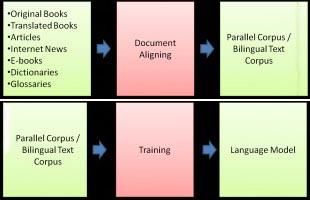
Figure 1 - basic of creating SMT language model
better the translation quality will be. This is why3
From Figure1, first step is collecting many documents Arabic, and Urdu, have different words other than
from many sources. Then system will align sentences English, but their words may sound like certain terms in
and create database of pair sentences (bilingual text English.
corpus).
System will be trained using that corpus. It will analyze
the statistic of word distribution in each sentence. The
output of this training is language model. Each pair III. STATISTICAL MACHINE TRANSLATION
translation has their own language model. Language
model will be updated each time the system learn new
Statistical machine translation is based on a channel
corpus.
model. Given a sentence T in one language (German) to
Using this language model we can translate other
sentences. be translated into another language (English), it
considers T as the target of a communication channel,
A. Bilingual text corpus and its translation S as the source of the channel. Hence
We know that Google Translate supports many pair the machine translation task becomes to recover the
language translations. Google gathers bilingual text source from the target. Basically every English sentence
corpus from many documents. They scan the original is a possible source for a German target sentence. If we
version books and the translated version. They crawl assign a probability P(S|T) to each pair of sentences (S,
websites which have two or more language versions. T), then the problem of translation is to find the source S
Sometimes they hire translators to translate from one for a given target T, such that P(S|T) is the maximum.
language to other language. According to Bayes rule,
After they have bilingual documents, Google do word
alignment. They have software that can align source P( S ) P(T | S )
sentences and translated sentences. This software p(S | T ) = (1)
P(T )
creates database pair of source sentences and translated
sentences.
Since the denominator is independent of S,
Sˆ = arg max P( S ) P(T | S ) (2)
B. Benefit of SMT S
SMT have benefits over traditional translation method Therefore a statistical machine translation system
(e.g: rule based translations): must deal with the following three problems:
• Generally SMT translator is not tailored to support • Modeling Problem: How to depict the process
specific languages. It builds to support many pair of generating a sentence in a source language,
of languages so SMT have better use of resources. and the process used by a channel to generate
It means building SMT translator is cheaper than a target sentence upon receiving a source
traditional method. sentence? The former is the problem of
• Depending on the number of bilingual of corpus, language modeling, and the latter is the
SMT translator gives more natural translations. problem of translation modeling. They
The more bilingual corpus it has, the more provide a framework for calculating P(S) and
translator trained with new bilingual corpus, the P(T|S) in (2) [4].
more natural translation it has. • Learning Problem: Given a statistical language
model P(S) and a statistical translation model
P(T|S), how to estimate the parameters in
While there are many machine translation software on these models from a bilingual corpus of
the internet, Google translator is clearly in the front of sentences?
the pack. One of Google automatic translator’s clear • Decoding Problem: With a fully specified
advantages is the phonetic typing. (framework and parameters) language and
Google translator allow user to translate more than translation model, given a target sentence T,
just Latin based languages by enabling a web based how to efficiently search for the source
phonetic keyboard right on the translator. Many sentence that satisfies (2).
languages such as Russian, Greek, Hindu, Serbian,4
Some of the most important modeling and learning l m
issues are used in a statistical machine translate like P( g | e) = ε ∑ ... ∑∏ t ( g i | eaj )a(a j | a j | j , l , m)
a1= 0 am = 0 j =1
Google Translate mentioned as follow: it starts with
m l
basic Probability and continue with sums and products, = ε ∏∑ t ( g i | ei )a (i | j , l , m) (5)
the noisy channel, Bayesian Reasoning, word j =1 i = 0
Reordering, word choice, language modeling, N-grams,
Smoothing, Evaluating models, Perplexity, log IV. DECODING
probability arithmetic, translation modeling, translation
Decoding algorithm in statistical machine translation
as string rewriting, model 2 (language model), model 3,
is a crucial part. Its performance directly affects the
models parameters, word to word alignments, estimating
quality and efficiency of translation. Without a good and
parameter values for w-t-w alignments, bootstrapping,
efficient decoding algorithm, a statistical machine
all passible alignments, collecting fractional counts,
translation system may miss the best translation of an
alignment probabilities, decoding, efficient model
input sentence even if it is perfectly predicted by the
training and some so on, in this paper I have chosen a
model.
few of these methods and tried to describe them in naïve
way.
A. Stack decoders
A. Model 2 Stack decoders are widely used in speech recognition
systems. The basic algorithm can be described as
At this model, it receives a source English sentence e
following:
= e =e 1 e
,..., l the channel generates a German
sentence g= g ,..., g at the target end in the 1) Initialize the stack with a null hypothesis.
1 m 2) Pop the hypothesis with the highest score off the
following way: stack, name it as current-hypothesis.
1. With a distribution P(m|e), randomly choose the 3) if current-hypothesis is a complete sentence, output
length m of the German translation g. In model it and terminate.
2, the distribution is independent of m and e: 4) Extend current-hypothesis by appending a word in
P ( m | e) = ε (3) the lexicon to its end. Compute the score of the
new hypothesis and insert it into the stack. Do this
where e is a small, fixed number. for all the words in the lexicon.
5) Go to (2).
2. For each position i (0 < i ≤ m) in g, find the
corresponding position ai in e according to an B. Scoring the hypotheses
alignment distribution
In stack search for statistical machine translation, a
P(ai | i, a1i −1 , m, e) . Hypothesis H includes (a) the length l of the source
sentence, and (b) the prefix words in the sentence. Thus
In model 2, the distribution only depends on i, ai and a hypothesis can be written as H = l : e1 e2 ...ek , which
the length of the English and German sentences:
postulates a source sentence of length l and its first k
P(ai | i, a1i −1 , m, e) = a(ai | i, m, l ) (4) words. The score of H, fit, consists of two parts: the
prefix score g H for e1e2 ...ek , and the heuristic score
3. Generate the word gi at the position i of the German
hH for the part ek +1ek + 2 ...el that is yet to be appended
sentence from the English word eai at the aligned
position ai of gi, according to a translation to H to complete the sentence. From (3) can be used to
assess a hypothesis. Although it was obtained from the
distribution P ( g i | aim , g1i −1 , e) = t ( g i | eai ) . The
alignment model, each word ei in the hypothesis
distribution here only depends on gi and eai. contributes the probability of the target sentence word.
For each hypothesis, we use SH(j) to denote the
Therefore, P(g | e) is the sum of the probabilities of probability mass for the target word gl contributed by the
generating g from e over all possible alignments A, in words in the hypothesis:
which the position i in the target sentence g is aligned to
the position ai in the source sentence e [4]:5
k
Each foreign phrase g in g1I is translated into an
S H ( j ) = ε ∑ t ( g i | ei )a (i | j , l , m) (6)
i =0 English phrase ei. The English phrases may be
reordered.
To guarantee an optimal search result, the heuristic Phrase translation is modeled by a probability
function must be an upper-bound of the score for all distribution ϕ ( g i | ei ) .
e e ...e Recall that due to the Bayes rule, the translation
possible extensions k +1 k + 2 l of a hypothesis. In
other words, the benefit of extending a hypothesis direction is inverted from a modeling standpoint.
should never be underestimated. Otherwise the search Reordering of the English output phrases is modeled
algorithm will conclude prematurely with a non-optimal by a relative distortion probability distribution
hypothesis. d (ai − bi − 1), where ai denotes the start position of the
On the other hand, if the heuristic function
foreign phrase that was translated into the ith English
overestimates the merit of extending a hypothesis too
much, the search algorithm will waste a huge amount of phrase, and bi − 1 denotes the end position of the foreign
time after it hits a correct result to safeguard the phrase translated into the (i-1)th English phrase.
optimality. In all our experiments, the distortion probability
Due to physical space limitation, we cannot keep all distribution d(.) is trained using a joint probability
hypotheses alive. There is a possibility to set a constant model. Alternatively, there is also possibility to use a
M, and whenever the number of hypotheses exceeds M,
simpler distortion model d (a i − bi − 1) = a |ai −bi −1 −1| with
the algorithm will prune the hypotheses with the lowest
scores. In an experiments the authors decided to set M = an appropriate value for the parameter α.
20,000. In order to calibrate the output length, we introduce a
There was time limitation too. It was of little practical factor W for each generated English word in addition to
interest to keep a seemingly endless search alive too the trigram language model PLM. This is a simple means
long. to optimize performance. Usually, this factor is larger
Since the heuristic function overestimates the merit of than 1, biasing longer output.
extending a hypothesis, the decoder always prefers
In summary, the best English output sentence g best
hypotheses of a long sentence, which have a better
given a foreign input sentence according to our model is:
chance to maximize the likelihood of the target words.
The decoder will extend the hypothesis with large I first, ebest = arg max e p (e | g )
and their children will soon occupy the stack and push ebest = arg max e p ( g | e) p LM (e) w legth ( e )
the hypotheses of a shorter source sentence out of the
stack. If the source sentence is
a short one, the decoder will never be able to find it, for wehre p(g|e) is decomposed into
I
the hypotheses leading to it have been pruned p( g1I | e1I ) = ∏ ϕ ( g i | ei )d (a i − bi −1 ) (8)
permanently. i =1
V. PHRASE TRANSITION
The phrase translation model is based on the noisy VI. PHRASE DECODER
channel model. We use Bayes rule to reformulate the The phrase-based decoder employs a beam search
translation probability for translating a foreign sentence algorithm, similar to the one by [6]. The English output
into English e as sentence is generated left to right in form of partial
translations (or hypotheses).
arg max e p(e | g ) = arg max e p( g | e) p(e) ( 7) It starts with an initial empty hypothesis. A new
hypothesis is expanded from an existing hypothesis by
This allows for a language model p(e) and a separate the translation of a phrase as follows: A sequence of
translation model p(g|e). untranslated foreign words and a possible English
phrase translation for them is selected. The English
During decoding, the foreign input sentence g is
phrase is attached to the existing English output
segmented into a sequence of I phrases g1I . A uniform sequence. The foreign words are marked as translated
probability distribution over all possible segmentations and the probability cost of the hypothesis is updated.
can be assume.6
The cheapest (highest probability) final hypothesis with technique is efficient and easier to implement but in
no untranslated foreign words is the output of the such case like Google MT, which is Support large
search. Varity of languages. There is ability to use large amount
The hypotheses are stored in stacks. The stack of data as train data for different language, It’s trivial to
s m contains all hypotheses in which m foreign words use SMT as engine method. Actually In this area Google
have been translated. Then recombine search hypotheses research are very active and we can see the acceptable
as done by [7]. While this reduces the number of result of Google MT. I think in near feature we can
hypotheses stored in each stack somewhat, stack size is higher accuracy in Google MT.
exponential with respect to input sentence length. This
makes an exhaustive search impractical. REFERENCES
Thus, we prune out weak hypotheses based on the cost [1] http://translate.google.com/about/intl/en_ALL/.
they incurred so far and a future cost estimate. For each [2] http://www.statmt.org/.
stack, it can be keep only a beam of the best n [3] http://cseweb.ucsd.edu/~dkauchak/mt-tutorial/.
hypotheses. [4] Brown et al, “The Mathematics of Statistical
Since the future cost estimate is not perfect, this leads to Machine Translation”, Computational Linguistics,
search errors. Our future cost estimate takes into account 1993.
the estimated phrase translation cost, but not the [5] http://www.systransoft.com.
expected distortion cost. [6] Jelinek, F . "Statistical Methods for Speech
It computes this estimate as follows: For each possible Recognition" The MIT Press 1998.
phrase translation anywhere in the sentence, we multiply [7] Och, F . J., Ueffing, N., and Ney , H. "An efficient
its phrase translation probability with the language A* search algorithm for statistical machine
model probability for the generated English phrase. As translation" In DataDriven MT Workshop 2001.
language model probability can be use the unigram [8] .M. Collins. 1999. Head-driven Statistical Models
probability for the first word, the bigram probability for for Natural Language P arsing. Ph.D. thesis,
the second, and the trigram probability for all following University of Pennsylvania, Philadelphia.
words.
Given the costs for the translation options, it can
compute the estimated future cost for any sequence of
consecutive foreign words by dynamic programming.
During translation, future costs for uncovered foreign
words can be quickly computed by consulting this table.
If a hypothesis has broken sequences of untranslated
foreign words, we look up the cost for each sequence
and take the product of their costs.
The beam size, e.g. the maximum number of hypotheses
in each stack, is fixed to a certain number. The number
of translation options is linear with the sentence length.
Hence, the time complexity of the beam search is
quadratic with sentence length, and linear with the beam
size.
VII. CONCLUSION
I have tried to discover topic about Google machine
translate, which is contained a large area of research in
Artificial intelligence. I consider two major technique
which are used to implement an engine of a MT. each
technique has its advantages and disadvantages.
Regarding Latin’s language or languages which are
simple in their linguistic and rules, the rule-baseYou can also read