Using Machine Translation to Generate Chinese Duilian
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Using Machine Translation to
Generate Chinese Duilian
By
LU Zhongqi
Advised by
Prof. YANG Qiang
Submitted in partial fulfillment
Of the requirement for COMP398H
Department of Computer Science and Engineering
The Hong Kong University of Science and Technology
2010-2011
Page 1 of 24
Table of Contents
ABSTRACT ............................................................................................................................................ 5
1 INTRODUCTION .............................................................................................................................. 5
1.1 OVERVIEW ................................................................................................................................. 5
1.2 OBJECTIVES ............................................................................................................................... 6
1.3 CRITICAL REVIEW.................................................................................................................... 7
2 DESIGN ............................................................................................................................................... 7
2.1 DUILIAN GENERATION AS A TRANSLATION PROBLEM .................................................. 8
2.2 PHRASE-BASED SMT APPROACH – AN OVERVIEW .......................................................... 9
2.3 THE SMT APPROACH – IN DETAIL ........................................................................................ 9
2.3.1 The N-gram Language Model ............................................................................................... 9
2.3.2 The Phrase-based Translation Model .................................................................................. 10
2.3.3 The Core Algorithm for The Decoder ................................................................................. 10
2.3.4 Future Cost Estimation For Decoder ................................................................................... 11
2.3.5 N-Best Lists Generation ...................................................................................................... 11
2.3.6 Evaluation Functions........................................................................................................... 11
2.3.7 Limitations of The System .................................................................................................. 12
2.4 SOURCES OF DATA ................................................................................................................. 12
3 IMPLEMENTATION....................................................................................................................... 12
3.1 DATA COLLECTION ................................................................................................................ 12
3.1.1 Crawler ................................................................................................................................ 12
3.1.2 Methods .............................................................................................................................. 13
3.1.3 Sample of Duilian Data ....................................................................................................... 13
3.2 APPLY SMT ............................................................................................................................... 14
3.2.1 Baseline SMT...................................................................................................................... 14
3.2.2 Language Model for Duilian ............................................................................................... 15
3.2.3 Phrase Model Training ........................................................................................................ 15
3.2.4 Model Weight Optimization & Parameter Tuning .............................................................. 16
4 TESTING .......................................................................................................................................... 17
4.1 METHODS OF TESTING ......................................................................................................... 17
4.2 SAMPLE OF RESULTS............................................................................................................. 17
5 EVALUATION .................................................................................................................................. 18
5.1 AUTOMATIC EVALUATION METHOD ................................................................................. 18
5.2 HUMAN EVALUATION ........................................................................................................... 18
5.3 OVERALL PERFORMANCE ................................................................................................... 19
Page 2 of 246 DISCUSSION.................................................................................................................................... 19
6.1 CHINESE WORD SEGMENTATION ....................................................................................... 19
6.2 HANDLING UNKNOWN PHRASES IN TRANSLATION ..................................................... 19
6.3 DATA SOURCES ....................................................................................................................... 20
6.4 EXTENSION OF THE DUILIAN SYSTEM ............................................................................. 20
7 CONCLUSION ................................................................................................................................. 20
8 REFERENCES ................................................................................................................................. 21
APPENDIX A: PROJECT PLANNING ............................................................................................ 23
APPENDIX B: HARDWARE & SOFTWARE ................................................................................. 24
APPENDIX C: WORK LOG .............................................................................................................. 25
Page 3 of 24ABSTRACT
A duilian is a pair of Chinese sentences usually seen on the sides of
doors leading to people’s house. A good duilian is ideally profound yet
concise, using one character per word in the style of Classical Chinese. This
project targets at generating the second sentence of duilian by an innovative
machine translation method. This report gives details of our design,
implementation, results, testing etc. and evaluates the performance of our
approach.
1 INTRODUCTION
1.1 OVERVIEW
Considered to be an important cultural heritage and a traditional
Chinese literary format, duilians or poetic Chinese couplets have a history of
more than a thousand years and remain an enduring aspect of Chinese
culture. Dueling couplets, also called duilian, is a popular word game with
Chinese speakers and is considered to be a good test of one’s literary
accomplishment. To play the game, one person first challenges the other with
a first sentence (FS for short in the rest of this article). Then the other person
replies with a second sentence (SS), which is similar to the FS in terms of
word segmentation and semantic, syntactic and lexical relatedness.
Here is an example of a duilian:
Figure 1. An example of duilian
Page 4 of 24A good SS must adhere to five basic linguistic rules, but in the game it
is often difficult to satisfy all five. Thus, one’s prowess is demonstrated by his
or her degree of adherence to the rules. The five rules are: [1]
i. Both lines must have the same number of Chinese characters.
ii. The lexical category of each character must be the same as its
corresponding character.
iii. The tone pattern of one line must be the inverse of the other. This
generally means if one character is of a level tone, its corresponding
character in the other line must be of an oblique tone, and vice versa.
iv. The last character of the first line should be of an oblique tone,
which forces the last character of the second line to be of a level tone.
v. The meaning of the two lines need to be related, with each pair of
corresponding characters having related meanings too.
The task is viewed as a difficult problem in AI and has been
researched by Microsoft Research Asia (MSRA) recently [2]. The generation
of SSs in duilian can be treated as a translation process because of the close
correlation between the FS and SS, as shown in the example above.
In this project, we utilize the machine learning techniques to discover
a systematic, generic and machine-based method of duilian generation.
1.2 OBJECTIVES
Given the FS of a couplet, generating the SS is still an open challenge
in this area of research because of the diverse forms (similar in meaning or
opposed in meaning), tones, parts of speech, coherence, etc.
Our objective is to advance current research on Chinese couplets by
accomplishing the following:
Based on online resources, design and build a duilian system that
provides satisfactory responses (i.e. SSs) for common duilian
challenges by humans (i.e. FSs).
Study how much training data is needed to generate a credible
system.
Analyze the factors that affect the performance of the system.
Page 5 of 241.3 CRITICAL REVIEW
The generation of duilian can be viewed as finding the second line of
a special type of poetry, given the first line and the five basic rules to follow.
Therefore, automatic poetry generation is considered to be the most closely
related research area. However, temporal pattern recognition is also quite
relevant.
MSRA is probably the best-known researcher in the area of duilian
generation. They have made some significant progress and have set up a
demo on the Internet [3].
As can be seen from their online demo, their application provides a
set of reasonable candidates for users to select. The results satisfy most of
the five basic rules for duilian in most cases, although sometimes there are
foibles in the semantics. MSRA seems to pay much attention to the five
linguistic rules of duilian. They do a good job in character repetition,
pronunciation repetition, character decomposition and phonetic harmony, etc.
2 DESIGN
The design phase included four aspects:
i. Duilian generation as a translation problem.
ii. Phrase-based SMT in duilian generation – an overview.
iii. The SMT approach – in detail.
iv. Source of data.
2.1 DUILIAN GENERATION AS A TRANSLATION PROBLEM
First, we review the basis of Statistical Machine Translation (SMT) [4].
SMT generates translations by statistical models based on bilingual text
corpora. A sentence is translated according to the probability distribution
P(target language | source language), and the translation that gives the
highest probability is chosen as the best one.
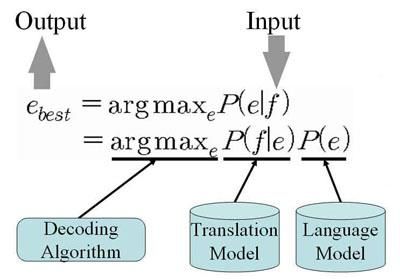
As illustrated in Figure 2, given the source language f, in order to find
the most desirable translation ebest, one intuitive approach is to apply the
Page 6 of 241
Bayes Theorem, that is , where the translation model
p(f | e) is the probability that the source string f is the translation of the target
string e, and the language model p(e) is the probability of using the target
sting e. This decomposition is attractive, because it splits the problem of p(e |
f) into 2 sub-problems, so that instead of calculating p(e | f) directly, we can
2
work on p(f | e) .
Figure 2. Statistical models for SMT
The SMT method has been proven to be effective and widely used
nowadays.
Next, if we go a few steps from a baseline SMT system, we can do
naïve duilian generation. Intuitively, duilian generation is a translation from an
FS (source language) to an SS (target language). Therefore, in this project,
instead of using bilingual text corpora, we use a set of existing Chinese
couplets is used to train our translation models. Then, when we apply our
duilian generation model to an FS, we get a few candidates for an SS.
2.2 PHRASE-BASED SMT APPROACH – AN OVERVIEW
As illustrated in the previous sub-section, duilian generation is easy to
accomplish based on phrase-based SMT.
Although it is almost impossible to ensure the quality of semantic
1
Notice that p(f) is independent of e, and it is dropped out when we maximize over e.
2
The reason we do not want to calculate p(e | f) directly is because during the calculation of p(f | e),
the asymmetric assumption, which says the source sentence f is usually well formed, is made, whereas
a similar assumption about the target translation is not valid, because we can not predict the result of
translation.
Page 7 of 24consistency when a normal translation is done entirely based on phrases, our
new approach to duilian generation has a build-in consistency safeguard, that
is the five basic linguistic rules of duilian. Given an FS, each phrase or word in
the generated results (i.e. an SS) must correspond to those in the FS and
therefore it ensures consistency.
2.3 THE SMT APPROACH – IN DETAIL
In section 1.1, Figure 1 shows an example of a duilian. The FS is
segmented into a number of sequences of consecutive words. Each phrase is
then translated into a corresponding phrase in the SS.
In this section, we define the models formally. We use Bayes rule to
reformulate the translation probability for translating the FS f into the SS s.
The most desirable SS can be denoted as:
sbest = argmaxs p(s|f) = argmaxs p(f|s) p(s).
Where p(s) is the language model and p(f|s) is the translation model.
The system is divided into language model, translation model,
decoder and evaluation functions.
2.3.1 The N-gram Language Model
In the N-gram language model, the probability P(W 1,…,Wm) of
observing the sentence W 1…Wm is approximated as
Here, it is assumed that the probability of observing the ith word W i in the
context history of the preceding i-1 words can be approximated by the
probability of observing it in the shortened context history of the
preceding n-1 words. And the conditional probability can be calculated
from n-gram frequency counts:
For example, in a 3-gram language model, the probability of the
sentence W 1 W 2 W 3 W4 W 5 is approximated as
Page 8 of 24P(W1 ,W2 ,W3 ,W4 ,W5) = P(W1| , )P(W2 | , W1)P(W3 | W1,
W2)P(W4 | W2, W3)P(W5 | W3, W4)
2.3.2 The Phrase-based Translation Model
A translation table is created from the duilian corpus.
To estimate the phrase translation probability φ(f|s), we process
the corpus, one FS f at a time. For each translation si for f,
φ(fi|s) = COUNT(fi) / COUNT(s).
We also use lexical weighting [4] Pw to validate the quality of a
phrase translation pair. We define the lexical weighting
Pw (f|s) = ∑φ(fi|s)
Finally, the translation model is given by
p(f|s) = ∏φ(fi|s) Pw (f|s)^λ
where λ defines the strength of lexical weight.
2.3.3 The Core Algorithm for The Decoder
The phrase-based decoder for the phrase translation model
employs a beam search algorithm, similar to the one used by Jelinek for
speech recognition. The SS is generated from left to right in form the of
hypotheses (search states).
We begin the search in an initial state where no word in the SS
has been generated. New states are created by extending the SS with a
phrasal translation of that covers some of the FS input that has not yet
been translated.
Each search state is represented by
i. A back link to the best previous state
ii. The FS words covered so far
iii. The cost so far
iv. An estimate of the future cost
Final states in the search are hypotheses that cover all foreign
words. Among these, the hypothesis with the lowest cost (highest
Page 9 of 24probability) is selected as the best translation.
2.3.4 Future Cost Estimation For Decoder
Future cost is tied to FS words that are not yet translated. For our
future cost estimate, we consider translation and language model costs.
Because we do not know the preceding SS for a translation operation,
we approximate this cost by computing the language model score for the
generated SS alone. That is, if only one SS word is generated, we take
its unigram probability; if two are generated, we take the unigram
probability of the first word and the bi-gram probability of the second
word, and so on.
2.3.5 N-Best Lists Generation
To provide more choices for users, we are interested in a list of
good candidates in the duilian generation. A common method is to first
use the generation system, such as the decoder above, as a base model
to generate a set of candidate translations for each input sentence.
Then, additional features (the 5 basic linguistic rules in section 1.1) can
be used to re-rank these translations.
2.3.6 Evaluation Functions
Evaluation and ranking of the outputs are based on the score /
probability obtained when doing translation.
Because a good duilian should always follows the rules mentioned
in section 1.1, it is necessary to also take constricts like word pattern etc
into consideration when ranking the outputs.
2.3.7 Limitations of The System
There are a few limitations of our current design.
First, we didn’t take the lexical category into consideration when
generating SSs.
Second, the tone of FSs and SSs may not match in some cases.
Third, in extreme cases when the phrases in FSs have ambiguous
meanings / tones, the system may not handle well.
Page 10 of 242.4 SOURCES OF DATA
We have chosen four sources for the Chinese couplet data:
a. 3rd and 4th sentences/5th and 6th sentences of eight-sentence
Tang poetry.
b. Clustered duilian corpus from a few duilian websites [6].
c. Sparse duilian corpus on the web.
d. A Chinese character pronunciation dictionary [7] to solve the
tone issue.
3 IMPLEMENTATION
The implementation phase follows the design discussed in section 2.1,
and it is organized into two modules: collect data and apply SMT.
3.1 DATA COLLECTION
3.1.1 Crawler
In order to collect the sparse duilian corpora from the Internet, a
generic crawler was used. Because most open source crawlers can only
be applied to English web pages, but the duilian data is all in Chinese, a
crawler for Chinese web pages has been implemented as an auxiliary
tool for the project.
3.1.2 Methods
As mentioned in section 2.1.4, there are four sources for the
Chinese couplet data. The data from Tang poetry and clustered duilian
corpora was easy to collect manually, but it was not enough. Therefore,
additional Chinese couplet data was collected with the help of a search
engine.
The sparse Chinese couplet data was collected and categorized
in the following steps:
a. Use the collected data as “seeds” to query via the search
engine.
Page 11 of 24b. Parse the top-100 search results and select the valid Chinese
couplets.
c. Insert the valid couplet data into the data set if it is not
already there.
d. Keep searching until enough data is collected or until all the
possible key phrases are exhausted.
Altogether, around 30,000 Chinese couplets were collected for the
experiment.
3.1.3 Sample of Duilian Data
The duilian data are stored in standard XML format and
categorized by the number of characters. An example of the duilian data
is shown in Figure 3:
Figure 3. Sample of duilian (word length 5) in XML format
3.2 APPLY SMT
3.2.1 Baseline SMT
First, we followed the regular Moses [5] procedures to get the
baseline SMT system:
a. Install Moses support libraries
Page 12 of 24b. Install Moses & supplement scripts
c. Build the language model using SRILM [8] (This step can be
bypassed by using any existing language model for bilingual
translation, because we do not focus on the bilingual translation. The
system is setup only for testing purposes.)
d. Test the baseline SMT
Because the baseline SMT system is the basis of our system, we
need to make sure it is functional so that we can proceed. A test and
evaluation of the SMT system is necessary at this point.
3.2.2 Language Model for Duilian
We use the collected data to train the language model for Chinese
couplets. We adopted a 5-gram language model in this implementation.
Much talented work has already been done on language
modeling. We chose SRILM [8], the SRI Language Modeling Toolkit, to
generate our language model. An example of our duilian language model
is shown in Figure 4.
Figure 4. Part of our language model for duilian
3.2.3 Phrase Model Training
It took almost 5 hours to train our phrase model on a Linux box
with Intel Core2 Duo CPU T7500 @ 2.20GHz.
Page 13 of 24Figure 5. Part of the Translation Table
Here is a sample of the translation table as shown in Figure 5.
The columns represent SS, FS, φ(f|e), Pw (f|e), φ(e|f), Pw (e|f), which are
defined in section 2.3.2.
3.2.4 Model Weight Optimization & Parameter Tuning
After our models, i.e. the language model, translation model, were
built, we optimized the parameters for each model in order to get the
best performance. The most important parameters that affect the
performance of our duilian system are the weights for the language
model and the translation model. Changing these two parameters can
have significantly influence on the results, as shown in Table 1.
Weight for LM Weight for TM First candidate of SSs
0.05 0.025 (*the best so far)
0.2 0.025
0.05 0.1
Table 1. The results for different weights, given FS -
Table 1 gives an example on how the weights could affect the
output. Intuitively, the translation model ensures the patterns of the FS
Page 14 of 24and the SS match, while the language model guarantee the SS is
lexically smooth. A good set of parameters usually compromise between
the significance of the language model and the significance of the
translation model.
One way to measure the quality of duilian translation is to count
how many words or phrases can be matched with the existing duilian.
Thus, the training data was used in the tuning process as the criterion for
effective translation.
Tuning the full set of parameters usually takes hours or even days
to run on our large phrase tables. In the tuning process, we mainly focus
on the weights for the language model and the translation model.
4 TESTING
4.1 METHODS OF TESTING
Testing was carried out during the entire development process (mainly
during the implementation phase). At each milestone, we tested our
implementation as discussed in the implementation section above.
The testing to this project was conducted with both black box and
white box testing based on human evaluation. The following test sets were
used:
a. Use some existing FSs as input. Compare the out put with existing
SSs.
b. Use random Chinese character combinations as FSs. Exam the
resulting SSs to check if the five basic linguistic rules have been
followed.
c. Use some non-existing FSs i.e. the newly made FSs as input. Check
if the system can handle the general cases.
4.2 SAMPLE OF RESULTS
Figure 6 shows a few good duilian generated by our system.
Page 15 of 24Figure 6. Sample of good duilian generated by our system
The most time consuming part is to load the phrase table and
language model into the memory. Once we cache the data in the memory
(200MB), a translation usually costs less than 0.5 second.
5 EVALUATION
5.1 AUTOMATIC EVALUATION METHOD
BLEU [9] is a widely used method for automatic evaluation of machine
translation. Because the duilian generation process can be viewed as a
special case of machine translation (as discussed in section 1.4), this method
was applied to evaluating the Sss during the implementation.
5.2 HUMAN EVALUATION
In addition to the BLEU evaluation, human evaluation was also
important. One way to quantify the quality of SSs was to manually count the
number of good results in the top-n candidates of the system.
Page 16 of 245.3 OVERALL PERFORMANCE
Above all, we summarized both the machine evaluation and human
evaluation and analyzed the effects of each critical point in the system, for
example, the utility of the language model, the decoding algorithm, etc.
Finally, we set the parameters based on the feedback of overall
evaluation. We claim that our system can provide proper results in most of the
cases.
6 DISCUSSION
6.1 CHINESE WORD SEGMENTATION
Chinese word segmentation is a central concern for most of foreign
language - Chinese translation process. But in our settings of the problem,
Chinese word segmentation is safely avoided.
Given a FS, the candidates of the second sentence is given by two
models, namely language model and translation model. The translation model
ensures the correspondence of a FS and a SS, while the language model
evaluates the relativeness between words in the SS. When assigning proper
weights for the language model and the translation model, the word
segmentation of SS should follow its corresponding FS in most cases.
Therefore, given the FS to be a proper sentence, the SS should also be fine.
6.2 HANDLING UNKNOWN PHRASES IN TRANSLATION
It is inevitable to see unknown phrases when dueling duilian. But we
still have chances to find a proper SS, because for the unknown phrases in
FS, we can fill SS with words that is lexically smooth based on the language
model. Although the system may not always provides ideal answers, it usually
gives very good hints for human beings' composition.
However, notice that the system can not recognize and learn unknown
words / symbols. Currently, the default action for the unknown words /
symbols is to repeat them in the results.
Page 17 of 246.3 DATA SOURCES
In our preliminary tests, we use the dataset of 20,000 pairs of Chinese
duilian couplets to train both the translation model and the language model.
The system could handle most common duilian at that stage. But when
people challenged the system with doggerels, its responds often seemed to
be too priggish.
Later, we tried to train the language model with both duilian samples
and general Chinese articles. It turned out that the new language model can
make the second sentence more lexically meaningful and smooth.
In order to further improve the system, many more Chinese couplets
and Chinese articles will be needed.
6.4 EXTENSION OF THE DUILIAN SYSTEM
Duilian is a basic literal form and it is the foundation for lots of
Chinese literal work, like poetry, Song Ci etc. Given our duilian system, a
natural step forward would be the generation of Chinese poetry.
As far as we are concerned, the process of poetry generation can be
divided into two steps: 1. Based on the topic words, generate the first
sentence of a poetry; 2. Utilize the translation method that is similar to our
duilian system to generate the rest of the sentences in the poetry.
We expect to use a series of language models and translation models
for each subject and generate different sentences of a poetry using different
language models and translation models.
7 CONCLUSION
In this project, we utilized the machine translation techniques to
discover a systematic and generic method of duilian generation. We mainly
focused on designing and building a duilian system that provided satisfactory
responds for common challenges from human beings. We successfully
demonstrated that machines could be as talent as human beings in terms of
literal accomplishment.
In the future, we will explore any possible improvements of the quality
of the machine generated duilian and we may extend the existing duilian
system to compose Chinese poetries.
Page 18 of 248 REFERENCES
[1] Duilian - Wikipedia [online]
General introduction to duilian.
Available: http://en.wikipedia.org/wiki/Duilian
[2] Long Jiang; Ming Zhou. (2008). Generating Chinese Couplets using
a Statistical MT Approach. In Proc. of the 22nd International Conference
on Computational Linguistics, pages 377-384.
Available: http://portal.acm.org/citation.cfm?id=1599129
[3] MSRA Duilian system [online]
The online version of duilian system by MSRA.
Available: http://couplet.msra.cn/
[4] P Koehn; FJ Och; D Marcu. (2003). Statistical Phrase-based
Translation. In Proc. of the 2003 Conference of the North American
Chapter of the Association for Computational Linguistics on Human
Language Technology, pages 48-54.
Available: http://portal.acm.org/citation.cfm?id=1073445.1073462
[5] The Moses Project (2010) [online]
Statistical Machine Translation System
Available: http://www.statmt.org/moses/
[6] Chiense Duilian Collection (Chinese) [online]
Available: http://www.edu3g.com/duilian/chun.html
[7] HANDIAN, Chinese Pinyin dictionary (2006) [online]
A collection of Chinese Pinyin.
Available: http://www.zdic.net/zd/py/
Page 19 of 24[8] SRILM Project (2009) [online]
The SRI Language Modeling Toolkit
Available: http://www.speech.sri.com/projects/srilm/
[9] K Papineni; S Roukos; T Ward; WJ Zhu. (2002). BLEU: a method for
automatic evaluation of machine translation. In Proc. of the 40th Annual
Meeting on the Association for Computational Linguistics, pages 311-
318.
Available: http://portal.acm.org/citation.cfm?id=1073083.1073135
[10] GIZA++ Project (2001) [online]
Part of the SMT Toolkit EGYPT. A freely available implementation of the
IBM model 4.
Available: http://www.fjoch.com/GIZA++.html
Page 20 of 24APPENDIX A: PROJECT PLANNING
The project has been divided into 5 phrases as follows: (and please
refer to the GANTT CHART in Figure 7 for detailed time lines)
Phase1a: Collect Chinese couplet data from the internet.
Phase1b: Get familiar with a baseline statistical MT system and
HMM.
Phase2: Implement the system of Duilian generation.
Phase3: Evaluate and analyze the results in Phase2. On one hand,
the bad results should be filtered out. On the other hand, the evaluation
can provide a guidance to improve the system.
Phase4: Because this is an open ended research. We are trying our
best to improve the system in both theory and engineering. And after the
basic Duilian system was done, we explored some related issues, such
as how many data are needed to construct a credible Duilian system and
the possible methods to improve the Duilian generation.
Figure 7. Time Line of the project
Page 21 of 24APPENDIX B: HARDWARE & SOFTWARE
1 HARDWARE
Operating System --- Linux X86
Hard disk --- 3GB or above
Memory --- 2GB or above
2 SOFTWARE
SRI language modeling toolkit
GIZA++ statistical translation models toolkit [10]
Moses: a statistical machine translation system
Java SE Development Kit
gcc4.1 or above
Page 22 of 24APPENDIX C: WORK LOG
Selected from my HKUST blog
1. Date: Jan. 27, 2011
Log:
The following is wrong:
When tuning param for moses using mert-moses.pl, you should create
the two folder mert/ and extractor/ first. Otherwise, you will got
error by line 303 or 304 in mert-moses.pl .
If you get errors like
Exit code: 127
Failed to do extraction of statistics. at XXX/scripts-YYYYMMMDD-
XXXX/training/mert-moses.pl line 662.
set –mertdir = XXX/moses/mert/, which contains extractor etc.
2. Date: Jan. 20, 2011
Log:
If you encounter problems like buffer overflow or stack smashing when
using GIZA++ in 2010 ~ early 2011, you should have a look at this
page:
http://www.mail-archive.com/moses-support@mit.edu/msg01542.html
Abstract:
As per the google code page for GIZA++, under "Issue 11", comment 3,
I changed the size of time_stmp in file file_spec.h (in GIZA++) from
17 char's to 37 (pseudo-randomly selected (larger) number), rebuilt
things, and had stuff start to work (without using an older g++).
3. Date: Sept. 29, 2010
Log:
To install moses on ubuntu10.04, you have to install additional
packages that are not shipped with the OS. Here is a summary of the
missing packages. Hope it can help you.
A. When installing SRILM:
csh
tcl8.5
tcl8.5-dev
dpkg-awk
B. When installing Moses:
zlib1g-dev
boost (optional)
Page 23 of 244. Date: Sept. 19, 2010
Log:
When compiling moses on ubuntu, it may give error message like “_gzf
was not declared in this scope”.
This is because the missing of “zlib1g-dev” package.
5. Date: Sept. 18, 2010
Log:
In order to use Moses, I want to install SRILM.
http://hi.baidu.com/wit_yd/blog/item/6b6681272c8ed206918f9dbe.html
http://weiqk.spaces.live.com/Blog/cns!2115755AE5F9E79!221.entry
These resources help me a lot. Highly recommend to those Ubuntu
users.
Page 24 of 24You can also read

















































