Algorithmic Adaptations to Extreme Scale Computing - David Keyes, Applied Mathematics & Computational Science Director, Extreme Computing Research ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Algorithmic Adaptations to
Extreme Scale Computing
David Keyes, Applied Mathematics & Computational Science
Director, Extreme Computing Research Center (ECRC)
King Abdullah University of Science and Technology
david.keyes@kaust.edu.sa
A good player plays where the ball is, while a great player plays to where the ball is going to be. Giorgio Chiellini 2010 laurea Università di Torino
Aspiration for this talk
To paraphrase hockey great Wayne Gretzsky:
“Algorithms for where
architectures are going to be”
Needed: an agile algorithmic
infrastructure that can trade
! flops vs. Bytes,
! flops vs. messages,
! flops vs. accuracy, etc.
… because computer architecture is an action sport!
My fellow “players” at Euro-Par, 2012-2018
Hatem Ltaief, Senior
Research Scientist, ECRC
Batched Tile Low-Rank
GEMM on GPUs
Friday 11:30am, D4
first job offers from on the market for post-docs former
Jack Dongarra 2019 res sci
Parallel universes of numerical linear algebra
Flat Hierarchical
* Local indices *
* Global indices *
c/o Instageeked.com for matrix blocks (k,l)
do i {
do i {
do j {
do j {
for (i,j) in S do op
for (i,j) in Sk,l do op
}
}
}
}
Some open HIERARCHICAL COMPUTATIONS ON MANYCORE ARCHITECTURES
in NVIDIA cuBLAS in Cray LibSci
A QDWH-Based SVD So=ware Framework on Distributed-Memory Manycore Systems
source The Hierarchical Computations on Manycore Architectures (HiCMA) library aims to redesign existing dense linear algebra The KAUST SVD (KSVD) is a high performance software framework for computing a dense SVD on distributed-memory
software
libraries to exploit the data sparsity of the matrix operator. Data sparse matrices arise in many scientific problems (e.g., manycore systems. The KSVD solver relies on the polar decomposition using the QR Dynamically-Weighted Halley
in statistics-based weather forecasting, seismic imaging, and materials science applications) and are characterized by algorithm (QDWH), introduced by Nakatsukasa and Higham (SIAM Journal on Scientific Computing, 2013). The
low-rank off-diagonal tile structure. Numerical low-rank approximations have demonstrated attractive theoretical bounds, computational challenge resides in the significant amount of extra floating-point operations required by the QDWH-based
both in memory footprint and arithmetic complexity. The core idea of HiCMA is to develop fast linear algebra SVD algorithm, compared to the traditional one-stage bidiagonal SVD. However, the inherent high level of concurrency
computations operating on the underlying tile low-rank data format, while satisfying a specified numerical accuracy and associated with Level 3 BLAS compute-bound kernels ultimately compensates the arithmetic complexity overhead and
leveraging performance from massively parallel hardware architectures. makes KSVD a competitive SVD solver on large-scale supercomputers.
TILE LOW-RANK ALGORITHMS CHOLESKY FACTORIZATION SOFTWARE STACK The Polar Decomposition QDWH Algorithm Advantages
Ø A = UpH, A in Rmxn (m≥n) , where Up is Ø Backward stable algorithm for computing the Ø Performs extra flops but nice flops
orthogonal Matrix, and H is symmetric QDWH-based SVD Ø Relies on compute intensive kernels
positive semidefinite matrix Ø Based on conventional computational kernels, Ø Exposes high concurrency
@ github
i.e., Cholesky/QR factorizations (≤ 6 iterations Ø Maps well to GPU architectures
Application to SVD for double precision) and GEMM Ø Minimizes data movement
Ø A = U pH Ø The total flop count for QDWH depends on Ø Weakens resource synchronizations
= Up(VΣVT) = (UpV)ΣVT = UΣVT the condition number of the matrix
dense tiles Performance Results KSVD 1.0
Cholesky: O(n3)
Ø QDWH-based Polar Decomposition
Ø Singular Value Decomposition
tile low rank Ø Double Precision
Cholesky: O(kn2)
Ø Support to ELPA Symmetric Eigensolver
Ø Support to ScaLAPACK D&C and MR3
released by
Symmetric Eigensolvers
Ø ScaLAPACK Interface / Native Interface
Ø ScaLAPACK-Compliant Error Handling
GEOSPATIAL STATISTICS HiCMA 0.1.0 CURRENT RESEARCH Ø ScaLAPACK-Derived Testing Suite
N = 20000, NB = 500, acc=109, 2D problem sq. exp. • Matrix-Matrix Multiplication • LU Factorization/Solve Ø ScaLAPACK-Compliant Accuracy
• Cholesky Factorization/Solve • Schur Complements
• Double Precision • Preconditioners State-of-the-Art
• Task-based Programming Models • Hardware Accelerators
• Shared and Distributed-Memory • Support for Multiple Precisions
Environments • Autotuning: Tile Size, Fixed Accuracy and
• Support for StarPU Dynamic Fixed Ranks
Runtime Systems • Support for OpenMP, PaRSEC and Kokkos
KAUST’s
• Testing Suite and Examples • Support for HODLR, H, HSS and H2
PERFORMANCE RESULTS CHOLESKY FACTORIZATION – DOUBLE PRECISION – CRAY XC40 WITH TWO-SOCKET, 16-CORE HSW
Current Research
Ø Asynchronous, Task-Based QDWH
Ø Dynamic Scheduling meleon 1.9
Ø Cha
Hardware Accelerators
ECRC*
Ø Distributed Memory Machines
Ø Asynchronous, Task-Based
QDWH-SVD
Ø QDWH-based Eigensolver
(QDWH-EIG)
Ø Integration into PLASMA/
MAGMA
DOWNLOAD THE SOFTWARE AT http://github.com/ecrc/hicma Download the software at http://github.com/ecrc/ksvd
A collaboration of With support from Sponsored by A collaboration of With support from Sponsored by
Centre de recherche
BORDEAUX – SUD-OUEST Centre de recherche
BORDEAUX – SUD-OUEST
further dev @ Intel PARALLEL HIGH PERFORMANCE UNIFIED FRAMEWORK FOR GEOSTATISTICS ON MANY-CORE SYSTEMS
A HIGH PERFORMANCE STENCIL FRAMEWORK USING Software for Testing Accuracy, Reliability and A HIGHyour
Place PEFORMANCE
text here MULTI-OBJECT ADAPTIVE OPTICS FRAMEWORK
WAFEFRONT DIAMOND TILING Scalability of Hierarchical computations FOR GROUND-BASED ASTRONOMY
The Girih framework implements a generalized multi-dimensional intra-tile parallelization scheme for shared-cache STARS-H is a high performance parallel open-source package of Software for Testing Accuracy, Reliability and Scalability The Exascale GeoStatistics project (ExaGeoStat) is a parallel high performance unified framework for computational The Multi-Object Adaptive Optics (MOAO) framework provides a comprehensive testbed for high performance
multicore processors that results in a significant reduction of cache size requirements for temporally blocked stencil of Hierarchical computations. It provides a hierarchical matrix market in order to benchmark performance of various libraries geostatistics on many-core systems. The project aims at optimizing the likelihood function for a given spatial data to provide an computational astronomy. In particular, the European Extremely Large Telescope (E-ELT) is one of today’s most challenging
codes.. It ensures data access patterns that allow efficient hardware prefetching and TLB utilization across a wide range for hierarchical matrix compressions and computations (including itself). Why hierarchical matrices? Because such matrices efficient way to predict missing observations in the context of climate/weather forecasting applications. This machine learning projects in ground-based astronomy and will make use of a MOAO instrument based on turbulence tomography. The
of architectures. Girih is built on a multicore wavefront diamond tiling approach to reduce horizontal data traffic in favor of arise in many PDEs and use much fewer memory, while requiring less flops for computations. There are several hierarchical framework proposes a unified simulation code structure to target various hardware architectures, from commodity x86 to GPU MOAO framework uses a novel compute-intensive pseudo-analytical approach to achieve close to real-time data processing
locally cached data reuse. The Girih library reduces cache and memory bandwidth pressure, which makes it amenable to data formats, each one with its own performance and memory footprint. STARS-H intends to provide a standard for assessing accelerator-based shared and distributed-memory systems. ExaGeoStat enables statisticians to tackle computationally on manycore architectures. The scientific goal of the MOAO simulation package is to dimension future E-ELT instruments
current and future cache and bandwidth-starved architectures, while enhancing performance for many applications. accuracy and performance of hierarchical matrix libraries on a given hardware architecture environment. STARS-H currently challenging scientific problems at large-scale, while abstracting the hardware complexity, through state-of-the-art high and to assess the qualitative performance of tomographic reconstruction of the atmospheric turbulence on real datasets.
supports the tile low-rank (TLR) data format for approximation on shared and distributed-memory systems, using MPI, OpenMP performance linear algebra software libraries.
STENCIL COMPUTATIONS MULTI-DIMENSIONAL INTRA-TILE PARALLELIZATION and task-based programming models. STARS-H package is available online at https://github.com/ecrc/stars-h. THE MULTI-OBJECT ADAPTIVE OPTICS TECHNIQUE
• Hot spot in many scientific codes a)"Threads'"block"decomposition"per"time"step b)"Cache"block ExaGeoStat Dataset Generator ExaGeoStat Maximum Likelihood Estimator
• Appear in finite difference, element, and volume Matrix Kernels Heatmap of ranks (2D problem) STARS-H 0.1.0 • Generate 2D spatial Locations using uniform • Maximum Likelihood Estimation (MLE) learning function:
discretizations of PDEs • Electrostatics (one over distance): • Data formats: Tile Low-Rank (TLR). distribution.
1""""2"""3"…"N
= ' '
• E.g., 3D wave acoustic wave equation: Z Y T Y 1 • Operations: approximation, matrix- • Matérn covariance function: ℓ $ = − >?@ (A − >?@ ∑ $ − 42 ∑ $ B' 4
X Z $%& = $' " $* "
( ( (
1""""""""""""2"""""""""""""3"""""…""""L
)%& vector multiplication, Krylov CG solve. ! "; $ = . $*
(($*+') -($* ) $( $(
c)"Regular"wavefront"blocking d)"Diamond"view
• Electrodynamics (cos over distance): • Synthetic applications in a matrix-free Where C $ is a covariance matrix with entries
.".". 1 1 .".". 2 2 .".". N ! 1 2
.".". 1 1 .".". 2 2 .".". N ! 1 1 2 2
cos(.)%& ) form: random TLR matrix, Cauchy C7D = ! E7 − ED ; $ , 7, D = ', … , =
• Cholesky factorization of the covariance matrix:
.".".
.".".
1 1 .".". 2 2 .".". N !
1 1 .".". 2 2 .".". N ! 1
1
1
1
1
1
1
2
2
2
2
2
2 2 $%& = matrix. ∑ $ = 0 . 02
T
.".". 1 1 .".". 2 2 .".". N !
T
1 1 1 2 2 2 )%&
Z
.".".
.".".
1 1 .".". 2 2 .".". N !
1 1 .".". 2 2 .".". N !
Y
1 1
1
2
2
2
• Spatial statistics (Matern kernel): • Real applications in a matrix-free High res. map of the quality of
i form: electrostatics, electrodynamics, • Measurement vector generation (Z): Single conjugate AO concept Open-Loop tomography concept Observing the GOODS South
2234 )%& 4 )%& Figure: Two different examples of real datasets (wind speed dataset in the middle east region
cosmological field with MOAO
turbulence compensation obtained
e)"FixedFexecutionFtoFdata"wavefront"blocking """f)"Block"decomposition"along"X
$%& = 26 94 26 spatial statistics. 4 = 0 . 5, 57 ~9(:, ') and soil moisture dataset coming from Mississippi region, USA). with MOAO on a cosmological field
k
.".". 1 .".". 2 .".". N N 1 ! 1 1 .".". 2 2 .".". L L
Γ 6 8 8
.".". 2 .".". N N 1 1 ! 1 1 .".". 2 2 .".". L L
• Programming models: OpenMP, MPI
1.0
.".". 2 .".". N N 1 1 .".". !
.".". .".". .".". .".". .".". .".". .".". .".". .".". .".". .".". .".". .".". .".". .".". !
1
1
1
1
.".".
.".".
2
2
2
2
.".".
.".".
L
L
L
L • And many other kernels … THE PSEUDO-ANALYTICAL APPROACH MOAO 0.1.0
.".". N N 1 1 .".". 2 .".". ! 1 1 .".". 2 2 .".". L L and task-based (StarPU). Figure: An example of 400
0.8
j T .".". N 1 1 .".". 2 .".". N ! T 1 1 .".". 2 2 .".". L L points irregularly distributed in
ToR computation
• Solve for the • Tomographic Reconstructor Computation
Z .".". 1 1 .".". 2 .".". N N !
X 1 1 .".". 2 2 .".". L L
Sample Problem Setting • Approximation techniques: SVD, space, with 362 points (ο) for • Dimensioning of Future Instruments
0.6
Spatial statistics problem for a quasi RRQR, Randomized SVD. maximum likelihood estimation System tomographic
Y
matcov Cmm Ctm ToR R
7-point stencil 25-point stencil Thread assignment in space-time dimensions Parameters • Real Datasets
0.4
uniform distribution in a unit square TLR Approximation of 2D problem on a two-socket
and 38 points (×) for prediction reconstructor R:
Roadmap of STARS-H validation.
R x Cmm = Ctm • Single and Double Precisions
0.2
SOFTWARE INFRASTRUCTURE GIRIH 1.0.0 CURRENT RESEARCH (2D) or cube (3D) with exponential shared-memory Intel Haswell architecture
• Extend to other problems in a matrix- • Shared-Memory Systems
kernel:
0.0
• MPI + OpenMP • Matrix power kernels 3; , • Support HODLR, HSS, ℋ and ℋ "
X Turbulence matcov Cmm Ctm BLAS Cee BLAS Cvv • Dynamic Runtime Systems
Stencil) 8ling)
256 ExaGeoStat 0.1.0 Current Research ExaGeoStat Predictor Figure: Mean square error for predicting
Parameters
Ctt • Hardware Accelerators
Kernels)
• Autotuning • GPU hardware accelerators: where 8 = 0.1 is a correlation length data formats. large scale synthetic dataset.
Time, seconds
+) MPI)comm.) Inter-
Specs.)
• OpenACC / CUDA
128
• Implement other approximation • Large-scale synthetic geo- • ExaGeoStat R-wrapper • MLE prediction problem
wrappers)
• Short and long stencil ranges in parameter and )%& is a distance
sample
0.10
4' I' J J'( Observing sequence
CURRENT RESEARCH
space and time • Out-of-core algorithms between B-th and C-th spatial points.
64 schemes (e.g., ACA). spatial datasets generator package ~ 9GH= ( I , '' )
0.08
Mean Square Error (MSE)
4( ( J(' J((
Run8me)system) Auto%tuning)
• Constant/variable coefficients • Dynamic runtime systems 32 • Port to GPU accelerators. • Maximum Likelihood • Tile Low Rank (TLR) • Compute the tomographic error: • Distributed-Memory Systems
0.06
SVD
• Apply other dynamic runtime systems Estimation (MLE) approximation With J'' ∈ LG×G, J'( LG×=, J(' ∈ L=×G, Cee = Ctt - Ctm RT – R CtmT + R Cmm RT • Hierarchical Matrix Compression
Girih system components • LIKWID support for profiling • Extension to CFD applications 16 RRQR
0.04
RSVD and programming models (e.g., - Synthetic and real datasets and J(( ∈ L=×= • Compute the equivalent phase map: • Machine Learning for Atmospheric Turbulence
PERFORMANCE RESULTS 8TH ORDER IN SPACE AND 2ND ORDER IN TIME – DOUBLE PRECISION • NetCDF format support
0.02
8
4 8 16 32 PARSEC). • The associated conditional distribution Cvv = D Cee DT • High Resolution Galaxy Map Generation
• Domain size: 512 x 512 x 512 Diamond tiling versus Spatial Blocking on SKL Diamond tiling performance across Intel x86 generations Number of physical cores • A large-scale prediction tool where 4' represents a set of unknown •
0.00
for unknown measurements
• PaRSEC runtime system • Generate the point spread function image Extend to other ground-based telescope projects
• # of time steps: 500 measurements :
20K 40K 60K
Spatial Locations (n)
80K 100K
• 25-point star stencil 3D problem on different two-socket shared- 3D problem on a different amount of nodes (from 64 up to 6084) of a distributed-memory on known locations • In-situ processing 4' |4( ~ 9G(I' + J'( J(( B' 4( − I( , J'' − J'( J((B' J(' )
• Dirichlet boundary conditions memory Intel x86 architectures CRAY XC40 system for a different error threshold #
PERFORMANCE RESULTS TOMOGRAPHIC RECONSTRUCTOR COMPUTATION – DOUBLE PRECISION
Two-socket 18-core Intel HSW – 64-core Intel KNL – 8 NVIDIA GPU P100s (DGX-1)
• Two-socket systems (Mem./L3): Performance Results (MLE)
6 45
6 700
# of nodes # of nodes DGX-1 DGX-1 peak
- 8-core Intel SNB (64GB/20MB) 5 64 1024 600
KNL 40 DGX-1 perf
102 5 Two-socket shared memory Intel x86 architectures Intel two-socket Haswell + NVIDIA K80 Cray XC40 with two-socket, 16 cores Haswell Haswell KNL perf
- 16-core Intel HSW (128GB/40MB) 256 4096 35 Haswell perf
Time in seconds, log2
Time in seconds, log2
4 500 1200
500
- 28-core Intel SKL (256GB/38MB) 1024 6084 1200 ) 450
Time in seconds
30
4 ( ) ) 1000
3 400
• Intel compiler suite v17 with 1000
400 This is one tomographic
TFlops/s
25
time(s)
() 350
800
Time (secs)
Time (secs)
Time (secs)
AVX512 flag enabled 2
3
800
( )
300
250 600 300
reconstructor every 25 20
101 Sandy Bridge 600
• Memory affinity with numatcl 1
400
( 200
400
seconds! 15
Ivy Bridge 3
150
200
command Haswell 0 ⌧ = 10
6
2 200
( 100
50
200 10
⌧ = 10
• Thread binding to cores with Broadwell -1
⌧ = 10 12 ⌧ = 10 9
0 0 0
100
5
Skylake 1
sched_affinity command 100 -2 Spatial Locations (n) Spatial Locations (n) Spatial Locations (n)
0 0
125 343 1000 2744 729 1331 2197 4096 9261 10000 20000 30000 40000 50000 60000 70000 80000 90000 100000110000 10000 20000 30000 40000 50000 60000 70000 80000 90000 100000110000
20 40 60 80 100 120 140 160 180 200
DOWNLOAD THE SOFTWARE AT http://github.com/ecrc/girih Matrix size, thousands
Matrix size, thousands Matrix size, thousands
DOWNLOAD THE LIBRARY AT http://github.com/ecrc/exageostat matrix size
DOWNLOAD THE SOFTWARE AT h6p://github.com/ecrc/moao matrix size
In collaboration with With support from Sponsored by
A collaboration of With support from Sponsored by A collaboration of With support from Sponsored by A collaboration of With support from Sponsored by
Centre de recherche
BORDEAUX – SUD-OUEST Centre de recherche
Centre de recherche
BORDEAUX – SUD-OUEST
BORDEAUX – SUD-OUEST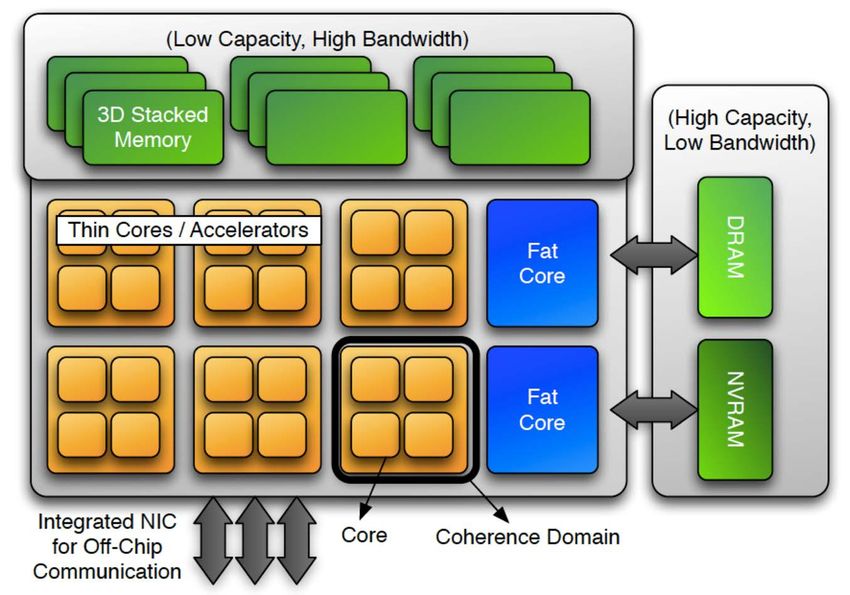
Outline
n Four architectural and applications trends
◆ limitations of our current software infrastructure for
numerical simulation at exascale
n Four algorithmic imperatives
◆ for extreme scale, tomorrow and today
n Four sets of “bad news, good news”
n Four widely applicable algorithmic strategies
n Sample “points of light”
◆ contributions to a new algorithmic
infrastructure chess-timer keynote
Four architectural trends
● Clock rates cease to increase while arithmetic
capability continues to increase through
concurrency (flooding of cores)
● Memory storage capacity increases, but fails to
keep up with arithmetic capability per core
● Transmission capability – memory BW and
network BW – increases, but fails to keep up
with arithmetic capability per core
● Mean time between hardware errors shortens
è Billions of
$£€¥
of scientific software worldwide hangs in the
balance until our algorithmic infrastructure
evolves to span the architecture-applications
gap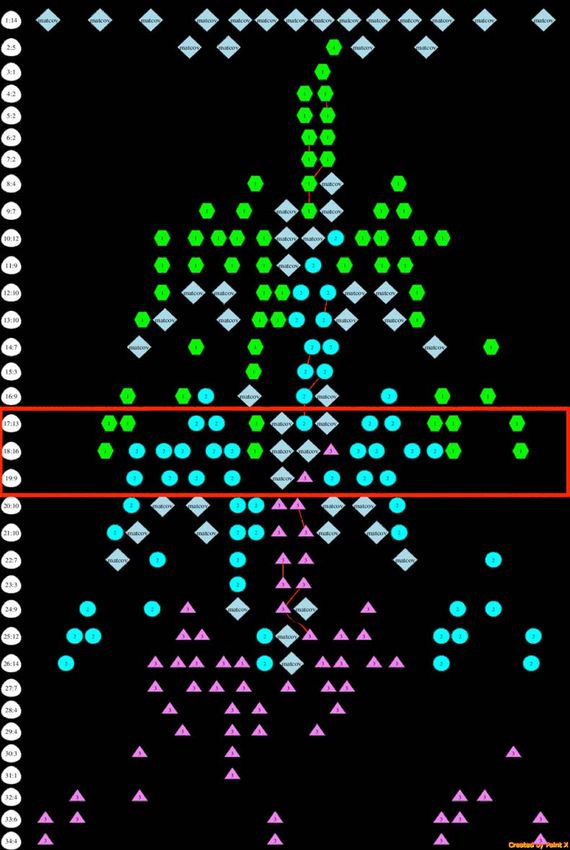
Architectural background
www.exascale.org/iesp
ROADMAP 1.0
The International Exascale
Software Roadmap
J. Dongarra, P. Beckman, et
Jack Dongarra Alok Choudhary Sanjay Kale Matthias Mueller Bob Sugar
al., International Journal of
Pete Beckman Sudip Dosanjh Richard Kenway Wolfgang Nagel Shinji Sumimoto
Terry Moore
Patrick Aerts
Thom Dunning
Sandro Fiore
David Keyes
Bill Kramer
Jesus Labarta
Hiroshi Nakashima
Michael E. Papka
Dan Reed
William Tang
John Taylor
Rajeev Thakur
High Performance Computer
Giovanni Aloisio Al Geist
Jean-Claude Andre
David Barkai
Jean-Yves Berthou
Bill Gropp
Robert Harrison
Mark Hereld
Alain Lichnewsky
Thomas Lippert
Bob Lucas
Mitsuhisa Sato
Ed Seidel
John Shalf
Anne Trefethen
Mateo Valero
Aad van der Steen
Applications 25:3-60, 2011.
Taisuke Boku Michael Heroux Barney Maccabe David Skinner Jeffrey Vetter
Bertrand Braunschweig Adolfy Hoisie Satoshi Matsuoka Marc Snir Peg Williams
Franck Cappello Koh Hotta Paul Messina Thomas Sterling Robert Wisniewski
Barbara Chapman Yutaka Ishikawa Peter Michielse Rick Stevens Kathy Yelick
Xuebin Chi Fred Johnson Bernd Mohr Fred Streitz
SPONSORSUptake from IESP meetings
n While obtaining the next order of magnitude of performance,
we need another order of performance efficiency
◆ target: 50 Gigaflop/s/W, today typically ~ 5 Gigaflop/s/W
n Processor clocks may be slowed and speeded
◆ may be scheduled, based on phases with different requirements,
or may be dynamic, from power capping or thermal monitoring
◆ makes per-node performance rate unreliable
n Required reduction in power per flop and per byte may make
computing and moving data less reliable
◆ circuit elements will be smaller and subject to greater physical
noise per signal, with less space redundancy and/or time
redundancy for resilience in the hardware
◆ more errors may need to be caught and corrected in software0
2
4
6
8
10
12
14
16
18
20
1
5
9
13
17
21
25
29
33
37
41
45
49
53
57
5 GF/s/W
61
65
69
73
77
81
85
89
Most efficient > 18 GFs/W
93
97
101
105
109
113
117
121
125
129
133
137
141
145
149
153
157
161
165
169
173
177
181
185
189
193
Power efficiencies
197
from June 2018 Top 500 list
201
205
209
213
217
About half of the systems report GF/s/W
221
225
229
233
237
241
245
249
253
257
261
Least efficient < 0.18 GFs/WTop 10 supercomputer trends, 2010-2018 c/o Keren Bergman (Columbia, ISC’18) QEERI, 14 Apr 2015
Top 10 supercomputer trends, 2010-2018
Sunway TaihuLight (Nov 2017) B/F = 0.004; 8x deterioration in
Summit HPC (June 2018) B/F = 0.0005 last 6 months
c/o Keren Bergman (Columbia, ISC’18) QEERI, 14 Apr 2015It’s not just bandwidth; it’s energy
● Access SRAM (registers, cache) ~ 10 fJ/bit
● Access DRAM on chip ~ 1 pJ/bit
● Access HBM/MCDRAM (few mm) ~ 10 pJ/bit
● Access DDR3 (few cm) ~ 100 pJ/bit
~ 104 advantage in energy for staying in cache!
similar ratios for latency as for bandwidth and
energy
QEERI, 14 Apr 2015Power costs in perspective
A pico (10-12) of something done exa (1018)
times per second is a mega (106)-somethings
per second
u 100 pJ at 1 Eflop/s is 100 MW (for the flop/s only!)
u 1 MW-year costs about $1M ($0.12/KW-hr × 8760
hr/yr)
§ We “use” 1.4 KW continuously, so 100MW is
71,000 people
QEERI, 14 Apr 2015Why exa- is different
Dennard’s MOSFET scaling (1972) ends
before Moore’s Law (1965) ends
Robert Dennard, IBM
(inventor of DRAM, 1966)
Eventually processing is
limited by transmission,
as known for 4.5 decades
QEERI, 14 Apr 2015Our heterogeneous future
ML/DL Quantum Neuromorphic
accelerator accelerator accelerator
after J. Ang et al. (2014), Abstract Machine Models and Proxy Architectures for Exascale ComputingArchitectural resources to balance
n Processing cores
◆ heterogeneous (CPUs, MICs, GPUs, FPGAs,…)
n Memory
◆ hierarchical (registers, caches, DRAM, flash,
stacked, …)
◆ partially reconfigurable For performance
tuning:
n Intra-node network
Which resource
◆ nonuniform bandwidth and latency is limiting, as a
n Inter-node network function of
time?
◆ nonuniform bandwidth and latencyWell established resource trade-offs
n Communication-avoiding algorithms
◆ exploit extra memory to achieve theoretical
lower bound on communication volume
n Synchronization-avoiding algorithms
◆ perform extra flops between global reductions
or exchanges to require fewer global operations
n High-order discretizations
◆ perform more flops per degree of freedom
(DOF) to store and manipulate fewer DOFsNode-based “weak scaling” is routine;
thread-based “strong scaling” is the game
n An exascale configuration: 1 million 1000-way 1GHz nodes
n Expanding the number of nodes (processor-memory units)
beyond 106 would not be a serious threat to algorithms that
lend themselves to well-amortized precise load balancing
◆ provided that the nodes are performance reliable
n Real challenge is usefully expanding the number of cores
sharing memory on a node to 103
◆ must be done while memory and memory bandwidth per node expand
by (at best) ten-fold less (basically “strong” scaling)
◆ don’t need to wait for full exascale systems to experiment in this
regime – the contest is being waged on individual shared-memory
nodes todayThe familiar
Blue
Taihu
Waters
Light Shaheen
Sequoia KThe challenge ARMv8 NVIDIA QualComm P100 Centric 2400 IBM Intel Power8 Knights Landing
#1-ranked “Summit” by IBM-NVIDIA (ORNL)
122.3 PF/s HPL 3.3 ExaOp/s peak
187.7 PF/s peak 1.88 ExaOp/s GB
2,282,544 processor cores in 4,608 “supernodes”
each: 2 ✕ 22-core IBM Power9 6 ✕ NVIDIA Volta
(each node is 40.7 TF/s or 716 TeraOp/s peak)Don’t need to wait for full exascale
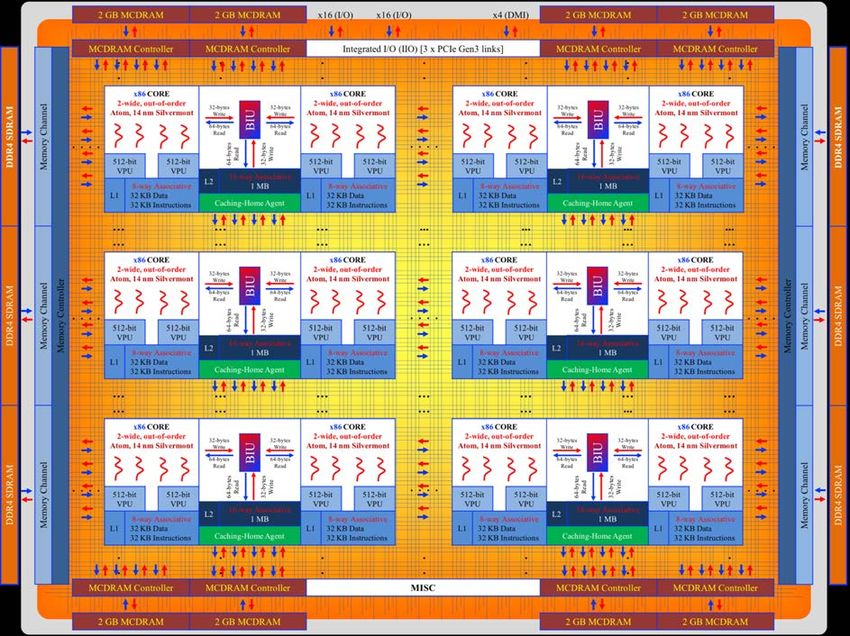
systems to experiment in this regime…
Schematic of Intel
Xeon Phi KNL by
M. Farhan, KAUST
The main contest is already being waged on individual
shared-memory nodesTwo decades of evolution
1997 2017
ASCI Red at Sandia Cavium ThunderX2
1.3 TF/s, 850 KW ~ 1.1 TF/s, ~ 0.2 KW
3.5 orders of
magnitudeSupercomputer in a node
System Peak DP Peak Power Power Eff.
TFlop/s KW GFlop/s/Watt
ASCI Red 1.3 850 0.0015
US DOE
ThunderX2 1.1 0.20 5.5*
Cavium
Knights Landing 3.5 0.26 14
Intel
P100 Pascal 5.3 0.30 18
NVIDIA
Taihu Light 125,436 15,371 6.1
CAS
Summit 187,659 8,806 13.9
US DOE
Exascale System 1,000,000 20,000 50
(~2021)
* 8 memory channels in Cavium ARM vs. 6 for Intel KNLSupercomputer in a node
System Peak DP Peak Power Power Eff.
TFlop/s KW GFlop/s/Watt
ASCI Red 1.3 850 0.0015
US DOE
ThunderX2 1.1 0.20 5.5*
Cavium
Knights Landing 3.5 0.26 14
Intel
P100 Pascal 5.3 0.30 18
NVIDIA
Taihu Light 125,436 15,371 6.1
CAS
Summit 187,659 8,806 13.9
US DOE
Exascale System 1,000,000 20,000 50
(~2021)
* 8 memory channels in Cavium ARM vs. 6 for Intel KNLHow are most scientific simulations
implemented at the petascale today?
n Iterative methods based on data decomposition and
message-passing
◆ data structures are distributed
◆ each individual processor works on a subdomain of the original
◆ exchanges information with other processors that own data with
which it interacts causally, to evolve in time or to establish
equilibrium
◆ computation and neighbor communication are both fully
parallelized and their ratio remains constant in weak scaling
n The programming model is BSP/SPMD/CSP
◆ Bulk Synchronous Programming Three decades of
◆ Single Program, Multiple Data stability in
◆ Communicating Sequential Processes programming modelBulk Synchronous Parallelism Leslie Valiant, F.R.S., N.A.S. 2010 Turing Award Winner Comm. of the ACM, 1990
BSP parallelism w/ domain decomposition
W3
W2
W1
rows assigned
to proc “2” A21 A22 A23
Partitioning of the grid
induces block structure on
the system matrix
(Jacobian)BSP has an impressive legacy
By the Gordon Bell Prize, performance on real applications (e.g.,
mechanics, materials, petroleum reservoirs, etc.) has improved
more than a million times in two decades. Simulation cost per
performance has improved by nearly a million times.
Gordon Bell
Prize: Peak
Gigaflop/s Gordon Bell
Prize: Price
Cost per
Performance
delivered to Performance
delivered
Year applications Year Gigaflop/s
1988 1 1989 $2,500,000
1998 1,020 1999 $6,900
2008 1,350,000 2009 $8Riding exponentials
n Proceeded steadily for decades from giga- (1988)
to tera- (1998) to peta- (2008) with
◆ same BSP programming model
◆ same assumptions about who (hardware, systems
software, applications software, etc.) is responsible for
what (resilience, performance, processor mapping,
etc.)
◆ same classes of algorithms (cf. 25 yrs. of Gordon Bell
Prizes)
n Scientific computing now at a crossroads with
respect to extreme scaleExtrapolating exponentials eventually fails
n Exa- is qualitatively different and looks more
difficult
◆ but we once said that about message passing
n Core numerical analysis and scientific
computing will confront exascale to maintain
relevance
◆ potentially big gains in colonizing exascale for science
and engineering
◆ not a “distraction,” but an intellectual stimulus
◆ the journey will be as fun as the destination JMain challenge going forward for BSP
n Almost all “good” algorithms in linear algebra,
differential equations, integral equations, signal
analysis, etc., like to globally synchronize – and
frequently!
◆ inner products, norms, pivots, fresh residuals are “addictive”
idioms
◆ tends to hurt efficiency beyond 100,000 processors
◆ can be fragile for smaller concurrency, as well, due to
algorithmic load imbalance, hardware performance variation,
etc.
n Concurrency is heading into the billions of cores
◆ already 10 million on the most powerful system todayEnergy-aware BSP generation generation
Applications background
www.exascale.org/bdec
Big data and Extreme-scale
Computing: Pathways to
Convergence – Toward a
Shaping Strategy for a Future
Software and Data Ecosystem
for Scientific Inquiry, M.
Asch, et al., 2018,
International Journal of High
Performance Computing
Applications 32:435-479.
(downloadable at URL above)
Successor to The International
Exascale Software Roadmap, by
many of the same authors and
new authors from big dataChallenge for applications: merging software for 3rd and 4th paradigms c/o Reed & Dongarra, Comm. ACM, July 2015
Interactions between application archetypes
Increasingly, there is scientific opportunity in pipelining
è Convergence is ripe
To Simulation To Analytics To Learning
Simulation
3rd provides −
Analytics
4th provides −
(a)
Learning
4th provides −
(b)Interactions between application archetypes
Increasingly, there is scientific opportunity in pipelining
è Convergence is ripe
To Simulation To Analytics To Learning
Simulation
3rd provides −
Analytics Steering in high
4th provides dimensional
−
(a) parameter space;
In situ processing
Learning Smart data
4th provides compression;
Replacement of −
(b) models with learned
functionsInteractions between application archetypes
Increasingly, there is scientific opportunity in pipelining
è Convergence is ripe
To Simulation To Analytics To Learning
Simulation Data for
3rd provides − Physics-based
“regularization”
training,
augmenting
real-world data
Analytics Steering in high
4th provides dimensional
−
(a) parameter space;
In situ processing
Learning Smart data
4th provides compression;
Replacement of −
(b) models with learned
functionsInteractions between application archetypes
Increasingly, there is scientific opportunity in pipelining
è Convergence is ripe
To Simulation To Analytics To Learning
Simulation Data for
3rd provides − Physics-based
“regularization”
training,
augmenting
real-world data
Analytics Steering in high
4th provides dimensional
− Feature vectors
(a) parameter space; for training
In situ processing
Learning Smart data
Imputation of
4th provides compression;
Replacement of
missing data;
−
(b) Detection and
models with learned
classification
functionsFour algorithmic imperatives
n Reduce synchrony (in frequency and/or span)
n Reside “high” on the memory hierarchy
◆ as close as possible to the processing elements
n Increase SIMT/SIMD-style shared-memory
concurrency
n Build in resilience (“algorithm-based fault
tolerance” or ABFT) to arithmetic/memory
faults or lost/delayed messages1 Bad news/good news
● Must explicitly control more of the data
motion
u carries the highest energy and time cost in the exascale
computational environment
● More opportunities to control the vertical
data motion
u horizontal data motion under control of users already
u but vertical replication into caches and registers was
(until recently) mainly scheduled and laid out by
hardware and runtime systems, mostly invisibly to users2 Bad news/good news
● Use of uniform high precision in nodal bases on dense grids
may decrease, to save storage and bandwidth
u representation of a smooth function in a hierarchical basis or on
sparse grids requires fewer bits than storing its nodal values, for
equivalent accuracy
● We may compute and communicate “deltas” between states
rather than the full state quantities
u as when double precision was once expensive (e.g., iterative correction
in linear algebra)
u a generalized “combining network” node or a smart memory
controller may remember the last address and the last value, and
forward just the delta
● Equidistributing errors properly to minimize resource use
will lead to innovative error analyses in numerical analysis3 Bad news/good news
● Fully deterministic algorithms may be regarded as too
synchronization-vulnerable
u rather than wait for missing data, we may predict it using various
means and continue
u we do this with increasing success in problems without models
(“big data”)
u should be fruitful in problems coming from continuous models
u “apply machine learning to the simulation machine”
● A rich numerical analysis of algorithms that make use of
statistically inferred “missing” quantities may emerge
u future sensitivity to poor predictions can often be estimated
u numerical analysts will use statistics, signal processing, ML, etc.4 Bad news/good news
● Fully hardware-reliable executions may be regarded as too
costly
● Algorithmic-based fault tolerance (ABFT) will be cheaper
than hardware and OS-mediated reliability
u developers will partition their data and their program units into
two sets
§ a small set that must be done reliably (with today’s standards for
memory checking and IEEE ECC)
§ a large set that can be done fast and unreliably, knowing the
errors can be either detected, or their effects rigorously bounded
● Many examples in direct and iterative linear algebra
● Anticipated by Von Neumann, 1956 (“Synthesis of reliable
organisms from unreliable components”)Algorithmic philosophy
Algorithms must span a widening gulf …
adaptive
algorithms
ambitious austere
applications architectures
A full employment program
for algorithm developers JWhat will exascale algorithms look like?
n For weak scaling, must start with algorithms with
optimal asymptotic order, O(N logp N)
n Some optimal hierarchical algorithms
◆ Fast Fourier Transform (1960’s)
◆ Multigrid (1970’s)
◆ Fast Multipole (1980’s)
◆ Sparse Grids (1990’s)
◆ H matrices (2000’s)
◆ Randomized algorithms (2010’s)
“With great computational power comes great algorithmic
responsibility.” – Longfei Gao, PhD KAUST, 2013Required software
Model-related Development-related Production-related
◆ Geometric modelers u Configuration systems u Dynamic resource
◆ Meshers u Source-to-source management
◆ Discretizers translators u Dynamic performance
◆ Partitioners optimization
u Compilers
◆ Solvers / integrators
u Simulators u Authenticators
◆ Adaptivity systems
◆ Random no. generators u Messaging systems u I/O systems
◆ Subgridscale physics u Debuggers u Visualization systems
◆ Uncertainty u Profilers u Workflow controllers
quantification
u Frameworks
◆ Dynamic load balancing High-end computers come
with little of this. Most is
u Data miners
◆ Graphs and
combinatorial algs. contributed by the user u Fault monitoring,
◆ Compression community. reporting, and recoveryRecapitulation of algorithmic agenda
n New formulations with
◆ reduced synchronization and communication
■ less frequent and/or less global
◆ reside high on the memory hierarchy
■ greater arithmetic intensity (flops per byte moved into and out of
registers and upper cache)
◆ greater SIMT/SIMD-style thread concurrency for
accelerators
◆ algorithmic resilience to various types of faults
n Quantification of trades between limited resources
n Plus all of the exciting analytical agendas that exascale is
meant to exploit
◆ “post-forward” problems: optimization, data assimilation,
parameter inversion, uncertainty quantification, etc.Four widely applicable strategies
n Exploit data sparsity of hierarchical low-
rank type
◆ meet the “curse of dimensionality” with the “blessing of
low rank”
n Employ dynamic runtime systems based on
directed acyclic task graphs (DAGs)
◆ e.g., ADLB, Argo, Charm++, HPX, kokkos, Legion,
OmpSs, OpenMP, PaRSEC, STAPL, StarPU AL4SAN
n Employ high-order discretizations
n Code to the architecture,
but present an abstract APIFour widely applicable strategies
n Exploit data sparsity of hierarchical low-
rank type
◆ meet the “curse of dimensionality” with the “blessing of
low rank”
n Employ dynamic runtime systems based on
directed acyclic task graphs (DAGs)
◆ e.g., ADLB, Argo, Charm++, HPX, kokkos, Legion,
OmpSs, OpenMP, PaRSEC, STAPL, StarPU Desynchronized
solvers
n Employ high-order discretizations
n Code to the architecture,
but present an abstract APIHierarchically low-rank operators
n Advantages
◆ shrink memory footprints to live higher on the
memory hierarchy
■ higher means quick access
◆ reduce operation counts
◆ tune work to accuracy requirements
■ e.g., preconditioner versus solver
n Disadvantages
◆ pay cost of compression
◆ not all operators compress wellKey tool: hierarchical matrices • [Hackbusch, 1999] : off-diagonal blocks of typical differential and integral operators have low effective rank • By exploiting low rank, k , memory requirements and operation counts approach optimal in matrix dimension n: – polynomial in k – lin-log in n – constants carry the day • Such hierarchical representations navigate a compromise – fewer blocks of larger rank (“weak admissibility”) or – more blocks of smaller rank (“strong admissibility”)
Example: 1D Laplacian
Recursive construction of an H-matrix c/o W. Boukaram & G. Turkiyyah (KAUST)
“Standard (strong)” vs. “weak” admissibility
strong admissibility weak admissibility
After Hackbusch, et al., 2003Hierarchically low-rank renaissance c/o Rio Yokota (Tokyo Tech/KAUST)
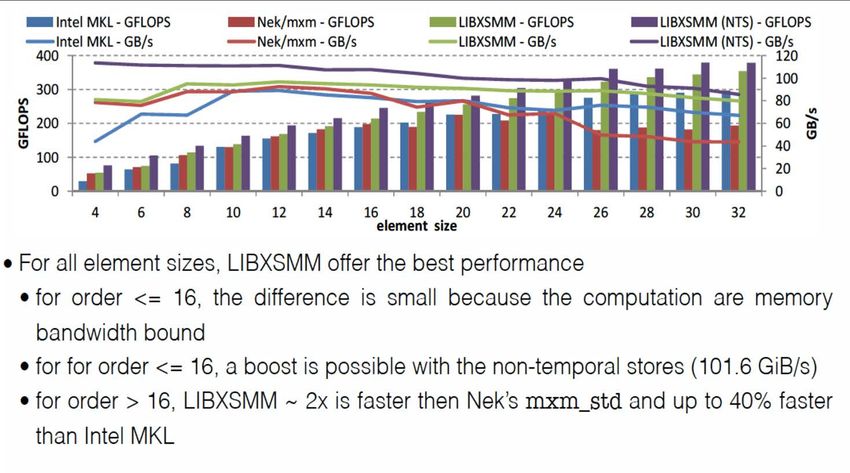
Tile Low Rank (TLR) is a compromise between optimality and complexity c/o Hatem Ltaief (KAUST)
Tile low-rank vs. Intel MKL
on single shared memory node
Geospatial statistics (Gaussian kernel) to accuracy 1.0e-8
Red arrows:
speedups from
hardware,
same algorithm
Green arrows:
classical speedups from
algorithm,
same hardware
tile low rank
Blue arrow:
From both
c/o Hatem Ltaief (KAUST)Performance evolution of dense Cholesky
(first factor based on tiling;
successive factors, 2007-2017, based on Top500 hardware generations)
c/o Hatem Ltaief (KAUST)Performance evolution of dense Cholesky c/o Hatem Ltaief (KAUST)
Taskification based on DAGs
n Advantages
◆ remove artifactual synchronizations in the form
of subroutine boundaries
◆ remove artifactual orderings in the form of pre-
scheduled loops
◆ expose more concurrency
n Disadvantages
◆ pay overhead of managing task graph
◆ potentially lose some memory localityReducing over-ordering and synchronization through dataflow, ex.: generalized eigensolver
Loop nests and subroutine calls, with their
over-orderings, can be replaced with DAGs
● Diagram shows a 1:1
2:4
dataflow ordering of the 3:9
4:4
steps of a 4×4 symmetric 5:11
6:8
generalized eigensolver
7:6
8:5
9:7
● Nodes are tasks, color- 10:4
11:4
coded by type, and edges 12:2
13:2
are data dependencies 14:3
15:3
16:1
● Time is vertically 17:2
18:1
downward 19:1
20:1
Wide is good; short is
21:1
● 22:1
good
23:1
24:1Loops can be
overlapped
in time
Green, blue and magenta
symbols represent tasks in
separate loop bodies with
dependences from an
Zooming-in…
adaptive optics
computation
c/o H. Ltaief (KAUST) & D. Gratadour (OdP)DAG-based safe out-of-order execution
Tasks from 3 loops of optical
“reconstructor” pipeline are
executed together
c/o H. Ltaief (KAUST) & D. Gratadour (OdP)High-order discretizations
n Advantages
◆ shrink memory footprints to live higher on the
memory hierarchy
■ higher means shorter latency
◆ increase arithmetic intensity
◆ reduce operation counts
n Disadvantages
◆ high-order operators less suited to some solvers
■ e.g., algebraic multigrid, H-matrices*
* but see Gatto & Hesthaven, Dec 2016, on H for hp FEMPerformance effects of order in CFD
Helmholtz solve in spectral element code for
incompressible Navier-Stokes
fourth order thirty-second
order
c/o Hutchinson et al. (2016) ISC’16Runtime effects of order in CFD
Accuracy versus execution time as a function of order
Single-mode Rayleigh-Taylor instability
c/o Hutchinson et al. (2016) ISC’16Coding to the architecture
n Advantages
◆ tiling and recursive subdivision create large
numbers of small problems suitable for batched
operations on GPUs and MICs
■ reduce call overheads
■ polyalgorithmic approach based on block size
◆ non-temporal stores, coalesced memory accesses,
double-buffering, etc. reduce sensitivity to memory
n Disadvantages
◆ code is more complex
◆ code is architecture-specific at the bottom“Hourglass” model for algorithms
(traditionally applied to internet protocols)
applications
algorithmic
infrastructure
architecturesAmdahl asks: where do the cycles go?
n Dominant consumers in applications that occupy
major supercomputer centers are:
◆ Linear algebra on dense symmetric/Hermitian matrices
■ Hamiltonians (Schroedinger) in chemistry/materials
■ Hessians in optimization
■ Schur complements in linear elasticity, Stokes & saddle points
■ covariance matrices in statistics
◆ Poisson solves
■ highest order operator in many PDEs in fluid and solid
mechanics, E&M, DFT, MD, etc.
■ diffusion, gravitation, electrostatics, incompressibility,
equilibrium, Helmholtz, image processing – even analysis of
graphsMapping algorithms to drivers PhD thesis topics in the Extreme Computing Research Center at KAUST must address at least one of the four algorithmic drivers
Examples being developed at KAUST’s
Extreme Computing Research Center
n QDWH-SVD, a 4-year-old SVD algorithm that performs more flops but
beats state-of-the-art on MICs and GPUs and distributed memory systems
n HBLAS, a hierarchically low-rank matrix library that reduces memory
footprints and arithmetic complexity for dense matrix kernels
n KBLAS, a library that improves upon or fills holes in L2/L3 dense BLAS
for GPUs and MICs, including batching, especially for symmetric kernels
n BDDC, a linear preconditioner that performs extra local flops on interfaces
for low condition number guarantee in high-contrast elliptic problems
n FMM(ε), a 31-year-old O(N) solver for potential problems, used in low
accuracy as a FEM preconditioner and scaled out on MICs and GPUs
n ACR(ε), a new spin on 52-year-old cyclic reduction that recursively uses H
matrices on Schur complements to reduce O(N2) complexity to O(N log2N)
n M/ASPIN, nonlinear preconditioners that replace most of the globally
synchronized steps of Newton iteration with asynchronous local problemsAudience participation
branch…
chess-timer keynote
In the (new) Euro-Par philosophy of a chess-
time talk, at this point in the lecture, we
pause for questions or invite “audience
steering” based on interest on a “short deep
dive” into any of the algorithmic topics on
the previous slide, with the time remaining…Conclusions
n Plenty of ideas exist to adapt or substitute for
favorite solvers with methods that have:
◆ reduced synchrony (in frequency and/or span)
◆ higher residence on the memory hierarchy
◆ greater SIMT/SIMD-style shared-memory concurrency
◆ built-in resilience (“algorithm-based fault tolerance” or ABFT)
to arithmetic/memory faults or lost/delayed messages
n Programming models and runtimes may have to be
stretched to accommodate
n Everything should be on the table for trades,
beyond disciplinary thresholds è “co-design”Thanks to:
CENTER OF EXCELLENCEThank you!
ﺷﻛرا
for the slides write me at:
david.keyes@kaust.edu.saYou can also read

















































