Entwicklung, Einführung und Evaluation von IT-Plattformen zur Unterstützung der biomedizinischen Datenintegration und -analyse
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Entwicklung, Einführung und Evaluation
von IT-Plattformen zur Unterstützung der
biomedizinischen Datenintegration und -analyse
Institut für Medizininformatik, Biometrie und Epidemiologie
Lehrstuhl für Medizinische Informatik
der Medizinischen Fakultät
der Friedrich-Alexander-Universität
Erlangen-Nürnberg
zur
Erlangung des Doktorgrades Dr. rer. biol. hum.
vorgelegt von
Jan Christoph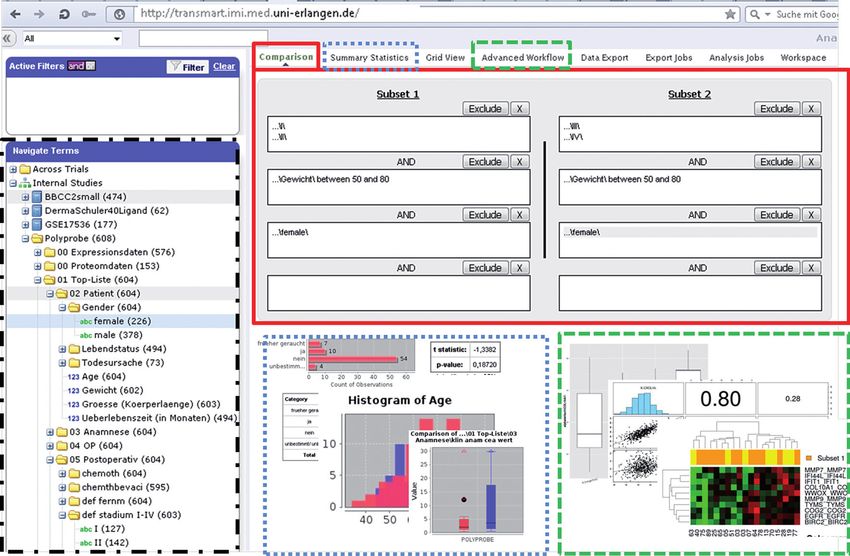
Als Dissertation genehmigt
von der Medizinischen Fakultät
der Friedrich-Alexander-Universität Erlangen-Nürnberg
Tag der mündlichen Prüfung: 16.4.2019
Vorsitzender des Promotionsorgans: Prof. Dr. Dr. h.c. Jürgen Schüttler
Gutachter/in: • Herr Prof. Dr. Hans-Ulrich Prokosch
• Herr Prof. Dr. Volkhard Helms
• Herr Prof. Dr. Dr. Michael Stürzl
• Frau Prof. Dr. Leila Taher
Der Autor der vorliegenden Arbeit erklärt, dass an einigen Stellen im Text aus Gründen der bes-
seren Lesbarkeit die männliche Form als grammatisch anerkannte Form des generischen Masku-
linums gewählt wurde. Die Angaben beziehen sich jedoch auf Angehörige beider Geschlechter,
sofern nicht ausdrücklich auf ein Geschlecht Bezug genommen wird.
Inhaltsverzeichnis
1 Abstract..............................................................................................................................................1
1.1 Background and Objectives.....................................................................................................1
1.2 Methods.....................................................................................................................................1
1.3 Results and Observations........................................................................................................2
1.4 (Practical) Conclusions............................................................................................................3
2 Zusammenfassung...........................................................................................................................5
2.1 Hintergrund und Ziele.............................................................................................................5
2.2 Methoden...................................................................................................................................5
2.3 Ergebnisse und Beobachtungen..............................................................................................6
2.4 (Praktische) Schlussfolgerungen.............................................................................................7
3 Einleitung...........................................................................................................................................9
3.1 Problemstellung......................................................................................................................10
3.2 Zielsetzungen..........................................................................................................................10
3.3 Fragestellungen.......................................................................................................................11
3.4 Architektur und Gesamtüberblick........................................................................................12
4 Einordnung in den fachwissenschaftlichen Kontext..................................................................13
4.1 Freitexterschließung im Rahmen der Sekundärnutzung..................................................13
4.1.1 Sekundärnutzung und Datenschutz..........................................................................13
4.1.2 Framework zur institutionsübergreifenden Erschließung von Freitexten...........14
4.2 Forschungsplattformen..........................................................................................................15
4.2.1 Forschungsplattformen i2b2 und tranSMART........................................................17
4.2.2 Forschungsplattform cBioPortal................................................................................18
4.3 Usability und deren Evaluation.............................................................................................19
4.4 Forschungsplattformen in der Lehre....................................................................................20
4.5 Molekulare Tumorboards......................................................................................................21
5 Abschließende Diskussion und Ausblick.....................................................................................23
III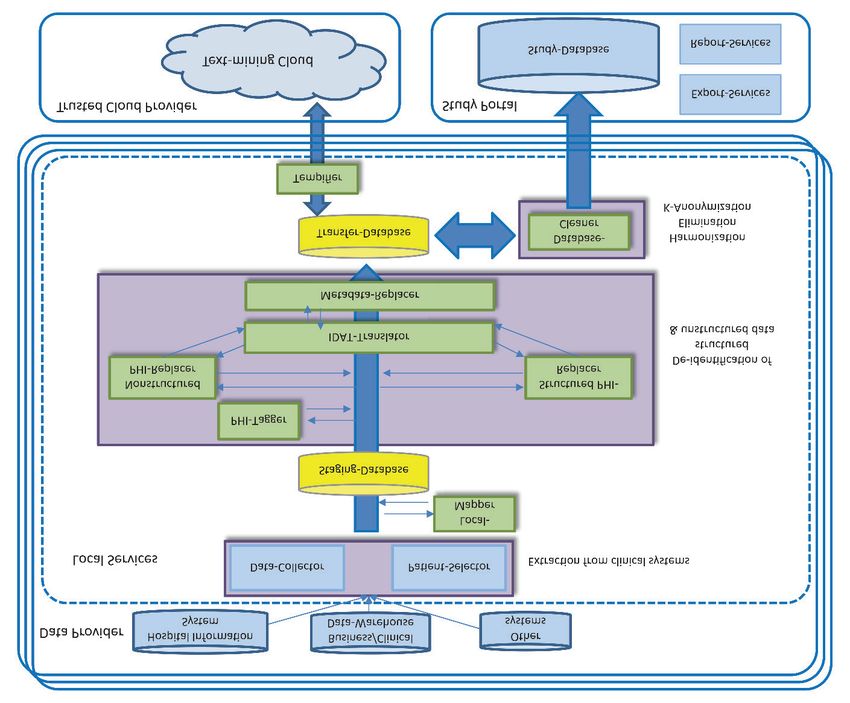
6 Publikationen..................................................................................................................................27
Publikation-1: Secure Secondary Use of Clinical Data with Cloud-based
NLP Services. Towards a Highly Scalable Research Infrastructure.................29
Publikation-2: Two Years of tranSMART in a University
Hospitalfor Translational Research and Education...........................................37
Publikation-3: Developing interactive plug-ins for tranSMART
using the SmartR framework workwork: The case of survival analysis..........47
Publikation-4: Usability and Suitability of the omics-integrating analysis
platform tranSMART for Translational Research and Education....................55
Publikation-5: Supporting Molecular Tumor Boards
in Molecular-guided Decision-making –
the Current Status of Five German University Hospitals..................................67
Publikation-6: Implementing Pharmacogenomic
Clinical Decision Support into German Hospitals............................................75
Literaturverzeichnis............................................................................................................................81
Abkürzungsverzeichnis......................................................................................................................89
Verzeichnis der Veröffentlichungen des Autors..............................................................................91
IV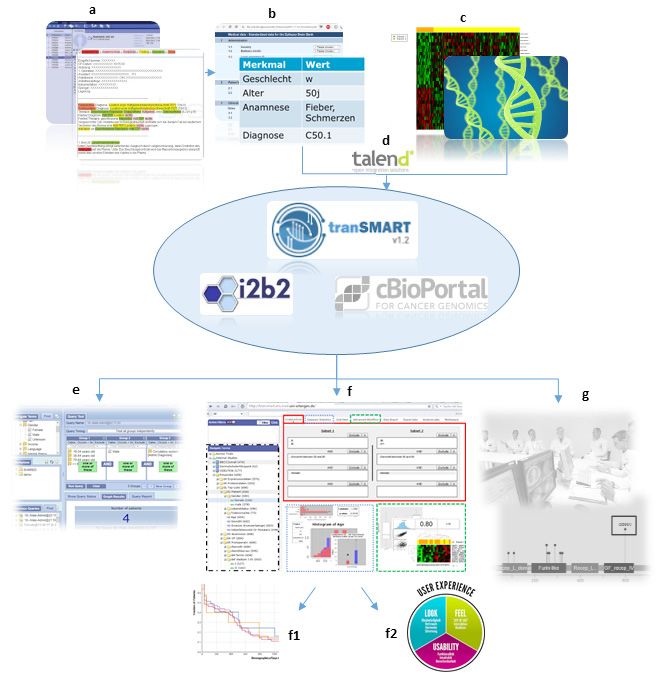
1 Abstract
1.1 Background and Objectives
The increasing digitalization of our society brings along a growing number of electronically
supported processes in the health care system – in particular in the hospital environment – which,
in turn, causes an increase in the quantity and the heterogeneity of the produced data. The utili-
zation and the reuse of this data for translational medical research is considered to be one of the
major challenges in biomedical informatics. Free text as it might come up in a physician´s letter
in the context of medical treatment contains, among others, valuable information for research.
For later secondary purposes such as the exploration of data, the generation of hypotheses or the
validation of hypotheses, however, this free text can often only be used in a structured form. Many
analyses in the fields of translational research also require the inclusion of the results of molecular
biological examinations so that medical researchers need an integrated view of the structured data
with its different types and sources. This need, which has not been sufficiently met so far, has been
addressed in this thesis with regard to the following four objectives:
• The extraction of free text and the transformation of its results into structured data for the pur-
pose of secondary use – including the conceptualization and the development of an IT frame-
work which makes this process available both across institutes and by the use of cloud struc-
tures.
• The provision of the „classic“ clinical data, which, for example, might have been extracted from
free text, in a structured manner and the provision of molecular biological data on a research
platform that can be extended as required.
• The evaluation of such a platform with regard to its qualification and its usability in research
and teaching as well as
• An initial estimation of the need for such platforms on the part of the molecular tumor board as
a use case between research and health care.
1.2 Methods
Together with experts on data protection, text mining and cloud computing an architecture was
developed in order to extract free text and the prototype of the architecture was implemented in
the cloud4health project. The architecture transforms free text into structured data by means of
1
text mining – with the transformation beeing carried out in a cloud and according to the regula-
tions of data protection. The architecture has been made available to the researchers on a cross-
institute platform. For the additional integration of molecular biological data qualified research
partners and platforms were made out and tranSMART – the final candidate – was tested for three
years in four use cases of translational research as well as in teaching. It has been established at the
University Hospital of Erlangen (Universitätsklinikum Erlangen, UKER) and at the Medical Fac-
ulty of the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU). Moreover, the option for
the extensibility of this platform was analyzed and implemented in a prototype. In order to evalu-
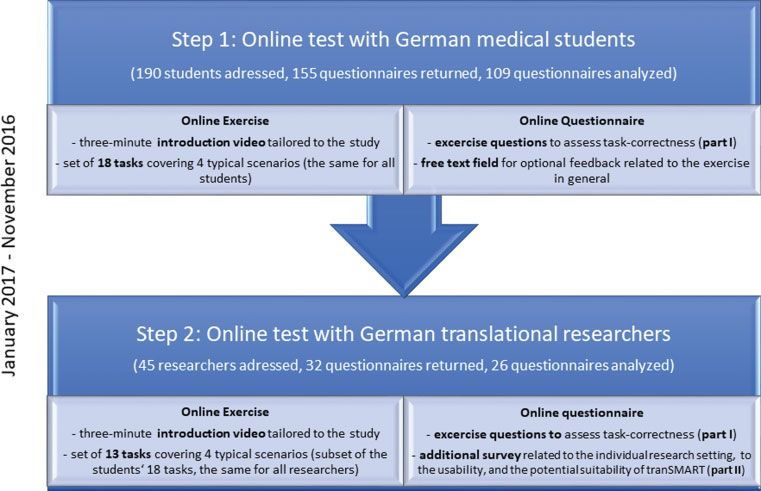
ate tranSMART, 109 students and 26 researchers were familiarized with tranSMART by means of
the screen shot of a video and an online test which comprised tasks that reflected typical research
scenarios. Afterwards, the students´ and the researchers´ ability to solve problems was rated. In
a further interview of medical researchers the usability of tranSMART was ascertained by means
of the „System Usability Scale“ (SUS). Furthermore, the researchers were interviewed with regard
to their needs for such a platform as well as with regard to their views on the qualification of
tranSMART to fulfill these needs. In order to estimate the need for such platforms on part of the
molecular tumor board, semi-structured interviews were conducted at five university hospitals to
make out the involved processes and the possibilities for an IT-related support.
1.3 Results and Observations
It turned out that neither the extraction of free text nor the establishment of a research platform
could be achieved by a single software application alone but that a sequence of IT processes had to
be connected within an overall architecture.
The prototype for the extraction of free text across institutes, which consists of several ele-
ments of the fields of data warehouse, text recognition and cloud computing, has been successfully
tested in three clinical use cases with several hundreds of patients and with over half a million
documents. The structured results of these tests were made available for analyses on the research
platform i2b2. For the purpose of data protection three appropriate models have been developed
(anonymous / with a local pseudonymization / with a cross-institute pseudonymization) – depending
on the question and the informed consent form.
TranSMART was successfully introduced at the UKER/FAU about four years ago – mid 2014 –
and has since been used in four translational research projects as well as in the context of lectures
and theses. The modelling of the data was one of the major tasks in the provision of tranSMART
and required a basic understanding of the respective domain, which might be more crucial to the
success of tranSMART in terms of its acceptance and its use on part of the researchers than the
choice of the platform. The extensibility of tranSMART has been successfully demonstrated by
taking the example of an interactively usable analysis of overall survival.
The evaluation of the qualification and the usability of tranSMART showed that both students
and researchers were able to handle the platform well and that they could solve the tasks of the
four tested scenarios – cohort identification, data exploration, generation of hypotheses and vali-
dation of hypotheses – with a rate of correctness of at least 82 % each. More than 72% of the re-
searchers involved in teaching considered tranSMART to be potentially useful for teaching. 84.6%
of the researchers consider tranSMART to be potentially (very) helpful for their daily work and
2
65.4% regard the lack of such a platform as one of the main obstacles to their research work. Ac-
cording to the “System Usability Scale“, the usability of tranSMART was “acceptable” – with a
score of 70.8 of 100 points.
The interviews regarding the processes at the molecular tumor board showed that both the
moleculogenetic diagnoses / treatment recommendations and the individual presentations of the
cases for the meetings of the molecular tumor boards are for the most part manually written
free text and have still been created without the use of a dedicated software platform such as
tranSMART or cBioPortal, which is functionally related to tranSMART. According to the results
of this thesis, however, these platforms could be very helpful for the integration and the visualisa-
tion of molecular biological and clinical data when it comes to the creation of treatment recom-
mendations.
1.4 (Practical) Conclusions
Although there are still some technical limitations, especially in terms of data modelling, which
restrict the purpose of tranSMART for some applications and although the issues of version con-
trol and data provenance continue to be a challenge, the evaluation of this platform showed that
tranSMART can be a very helpful tool both for research and for teaching. It offers an accept-
ably intuitive and graphical user guidance and provides a number of important functions for data
analysis in the fields of exploration, cohort identification, generation of hypotheses and validation
of hypotheses.
There are very positive responses on part of the researchers (“TranSMART opens new and im-
mense perspectives for us in research! Many thanks!!”) and on part of the students (”The task showed
you that it isn´t all that difficult to analyze data effectively if you have the right tool at hand and
if you know how to do it.”). Hence, the already current solution makes the continuation and the
extension of the solution with an additional amplification for molecular tumor boards to a reason-
able objective.
3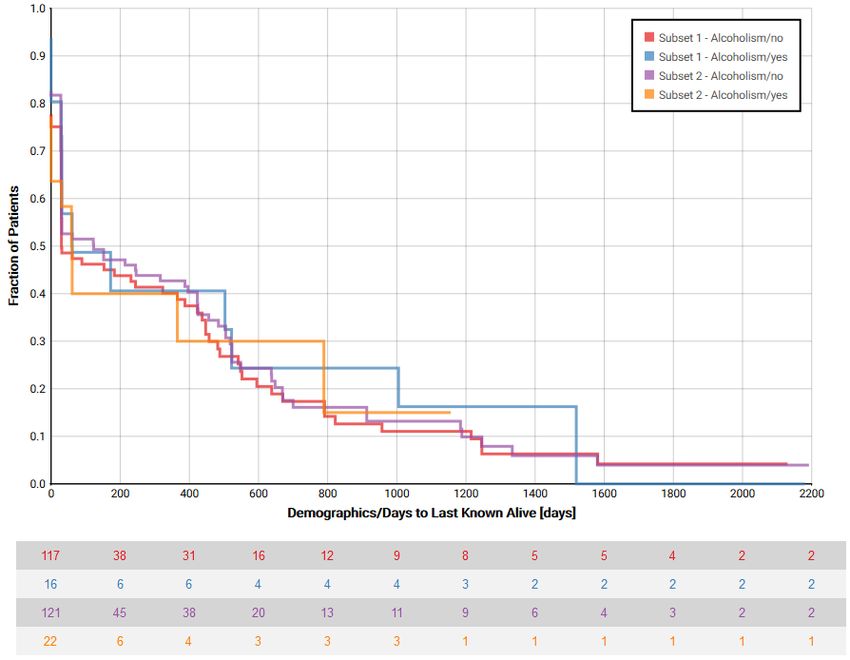
2 Zusammenfassung
2.1 Hintergrund und Ziele
Die zunehmende Digitalisierung kommunikativer Inhalte und Formen unserer Gesellschaft
führt dazu, dass auch im Gesundheitswesen und speziell im Krankenhaus eine wachsende An-
zahl an Prozessen elektronisch unterstützt werden. Natürlicherweise steigen damit auch die anfal-
lenden Datenmengen sowie deren Heterogenität. Die Wiederverwertung und Nutzbarmachung
dieser Daten für die translationale medizinische Forschung wird als eine der großen Herausforde-
rungen der biomedizinischen Informatik betrachtet. Freitexte, wie sie z. B. im Arztbrief im Rah-
men der Behandlung entstehen, enthalten unter anderem für die Forschung wertvolle Informa-
tionen, die jedoch oft nur in strukturierter Form für nachgelagerte sekundäre Zwecke wie z. B.
der Datenexploration, Hypothesengenerierung oder -validierung verwendet werden können. Für
viele Analysen im Bereich der translationalen Forschung müssen zusätzlich Ergebnisse moleku-
larbiologischer Untersuchungen einbezogen werden. Medizinische Forscher benötigen dadurch
eine integrierte Sicht auf strukturierte Daten verschiedener Quellen und Typen. Dieser bislang
nicht hinreichend gedeckte Bedarf wurde in vorliegender Arbeit in Bezug auf folgende vier Ziele
adressiert:
• Die Erschließung von Freitexten in strukturierte Daten zur Sekundärnutzung inklusive der
Konzeption und Entwicklung eines IT-Frameworks, welches dies auch institutionsübergreifend
und unter Nutzung von Cloud-Strukturen ermöglicht,
• die Bereitstellung von (z. B. aus Freitexten erschlossenen) strukturierten „klassischen“ klini-
schen Daten zusammen mit molekularbiologischen Daten integriert in einer flexibel erweiter-
baren Forschungsplattform,
• die Evaluation einer solchen Plattform in Bezug auf Eignung und Nutzbarkeit für Forschung
und Lehre sowie
• eine erste Abschätzung des Bedarfs an solchen Plattformen für das Molekulare Tumorboard als
Anwendungsfall zwischen Forschung und Versorgung.
2.2 Methoden
Zur Erschließung der Freitexte wurde im Projekt cloud4health mit Experten für Datenschutz,
Text-Mining und Cloud-Computing eine Architektur konzipiert und prototypisch umgesetzt. Da-
bei wurden die Freitexte datenschutzkonform in einer Cloud durch Text-Mining in strukturierte
5Daten transformiert und in einer institutionsübergreifenden Plattform Forschern zugänglich ge-
macht. Zur zusätzlichen Integration molekularbiologischer Daten wurde nach Identifikation ge-
eigneter Forschungspartner und –plattformen der finale Kandidat tranSMART ausgewählt. Dieser
wurde über drei Jahre lang in vier Anwendungsfällen der translationalen Forschung sowie in der
Lehre erprobt und dabei am Universitätsklinikum Erlangen (UKER) bzw. an der Medizinischen
Fakultät der Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) etabliert. Außerdem
wurde die Möglichkeit der Erweiterbarkeit dieser Forschungsplattform analysiert und prototy-
pisch umgesetzt. Zur Evaluation von tranSMART wurden 109 Studenten und 26 Forscher, deren
überwiegender Teil diese Plattform vorher noch nicht gekannt hatte, in einer Studie mit einem
Bildschirmvideo sowie einem Online-Test mit Aufgaben aus typischen Forschungsszenarien mit
tranSMART vertraut gemacht und anschließend die Fähigkeit des Problemlösens gemessen. In
einer weitergehenden Befragung von medizinischen Forschern wurde die Gebrauchstauglichkeit
(engl. Usability) gemäß des „System Usability Scale“ (SUS) erhoben. Die Forscher wurden weiter-
hin in Bezug ihres Bedarfs an einer solchen Plattform sowie ihrer Wahrnehmung bezüglich der
Eignung von tranSMART zur Deckung desselben befragt. Zur Bedarfsabschätzung solcher Platt-
formen für das Molekulare Tumorboard wurden semi-strukturierte Interviews an fünf Universi-
tätsklinika zur Erhebung der daran beteiligten Prozesse und Möglichkeiten der IT-Unterstützung
durchgeführt.
2.3 Ergebnisse und Beobachtungen
Es zeigte sich, dass sowohl die Erschließung der Freitexte als auch die Etablierung einer For-
schungsplattform nicht durch nur ein einzelnes Software-Programm erreicht werden konnten,
sondern dass eine Abfolge von IT-Prozessschritten in einer Gesamtarchitektur verknüpft werden
musste.
Der aus mehreren Komponenten der Bereiche Data-Warehouse, Texterkennung und Cloud-
Computing zusammengesetzte Prototyp zur institutionsübergreifenden Freitexterschließung
wurde in drei klinischen Anwendungsfällen mit mehreren hundert Patienten und über einer hal-
ben Million Dokumenten erfolgreich erprobt und die so erzielten strukturierten Ergebnisse in der
Forschungsplattform i2b2 für Analysen bereit gestellt. Für den Datenschutz wurden drei Modelle
entwickelt; jeweils passend zu Fragestellung und Patienteneinwilligung (anonym, lokal pseudony-
misiert, institutionsübergreifend pseudonymisiert).
TranSMART wurde vor knapp vier Jahren Mitte 2014 erfolgreich am Universitätsklinikum Er-
langen sowie der Medizinischen Fakultät der FAU eingeführt und seitdem in vier translationalen
Forschungsprojekten sowie im Kontext von Vorlesungen und Studien-/Abschlussarbeiten genutzt.
Die Datenmodellierung war eine der wichtigsten Aufgaben in der Bereitstellung von tranSMART
und erforderte ein grundlegendes Verständnis der jeweiligen Domäne, was ggf. entscheidender
für das Gelingen bzgl. Nutzen, Akzeptanz und Nutzung durch die Forschenden ist als die Wahl
der Plattform selbst. Am Beispiel einer interaktiv bedienbaren Überlebenszeitanalyse wurde die
Erweiterbarkeit von tranSMART prototypisch erfolgreich demonstriert.
Die Evaluation der Eignung und Usability von tranSMART in der Studie mit – mehrheitlich
mit dieser Plattform vorher nicht vertrauten – Testpersonen zeigte, dass sowohl Studenten als
auch Forscher mit der Plattform gut umgehen und die Aufgaben der vier getesteten Szenarien
6(Kohortenidentifikation, Datenexploration, Hypothesengenerierung und Hypothesenvalidierung)
mit einer Korrektheit von jeweils mindestens 82% lösen konnten. Etwa drei Viertel der auch leh-
renden Forscher schätzten tranSMART als potentiell nützlich für ihre Lehre ein. Für ihre tägliche
Arbeit betrachten über vier Fünftel der Forscher tranSMART als potentiell (sehr) hilfreich und
etwa zwei Drittel betrachten das Fehlen einer solchen Plattform für ihre Arbeit als eines ihrer
wesentlichen Hemmnisse für ihre Forschung. Die Usability von tranSMART wurde gemäß der
„System Usability Scale“ mit 70,8 von 100 Punkten als „akzeptabel“ eingeschätzt.
Die Interviews bzgl. der Prozesse beim Molekularen Tumorboard ergaben, dass sowohl die sich
auf molekulargenetischen Daten stützende Therapieempfehlungen als auch die einzelnen Fallprä-
sentationen für die Sitzung des Molekularen Tumorboards mehrheitlich manuell freitextlich und
allesamt noch ohne Unterstützung einer dedizierten Software-Plattform wie tranSMART oder –
dem mit diesem funktionell verwandten – cBioPortal erstellt werden. Gemäß den Erkenntnissen
der vorliegenden Dissertation könnten Plattformen wie diese jedoch bei der Integration und Visu-
alisierung molekularbiologischer und klinischer Daten für die Erstellung der Therapieempfehlung
sehr hilfreich sein.
2.4 (Praktische) Schlussfolgerungen
Obwohl manche technischen Limitationen, insbesondere bei der Datenmodellierung, den Ein-
satzzweck von tranSMART für einige Anwendungen noch einschränken sowie die Themen Ver-
sionskontrolle und Data Provenance weiterhin bestehende Herausforderungen darstellen, zeigte
die Evaluation dieser Plattform, dass sie sowohl für Forschung als auch Lehre ein sehr nützliches
Werkzeug darstellen kann. Dieses bietet bei akzeptabler intuitiver und grafischer Benutzerfüh-
rung einige wichtige Funktionen zur Datenanalyse für die Bereiche Exploration, Kohortenidenti-
fikation, Hypothesengenerierung und -validierung.
Die sehr positiven Rückmeldungen zur bereits aktuell geschaffenen Lösung sowohl seitens der
sich damit in ihren Projekten intensiv beschäftigten Forscher („TranSMART ermöglicht für uns in
der Forschung außerordentlich große neue Perspektiven! Besten Dank!!“) als auch die der Studenten
(„Die Übung hat einem gezeigt, dass es gar nicht so schwer ist, Daten effektiv auszuwerten, wenn
man das richtige Werkzeug an der Hand hat und weiß wie.“) lassen eine Verstetigung und Ausbau
derselben für die translationale Forschung sowie eine Ausweitung der Anwendung auf das Mole-
kulare Tumorboard sinnvoll erscheinen.
73 Einleitung
Wie in der Förderinitiative Medizininformatik „Daten vernetzen – Gesundheitsversorgung
verbessern“ des Bundesministeriums für Bildung und Forschung sehr treffend beschrieben, „[er-
fasst der Trend zur Digitalisierung] zunehmend auch das Gesundheitswesen. Heute sind immer
mehr medizinische Daten – z. B. Röntgenbilder, Arztbriefe oder Blutwerte – elektronisch verfüg-
bar. Gleichzeitig werden in der biomedizinischen Forschung immer größere Datenmengen er-
hoben. Zusammen haben diese Daten das Potential, die Diagnose und Therapie von Krankhei-
ten entscheidend zu verbessern“ [1]. Genau wie in jenem mit 150 Millionen Euro dotierten und
deutschlandweiten Förderprogramm ist in dieser Promotion – nur in sehr viel kleinerem und le-
diglich prototypischem Rahmen – das Ziel „die Verbesserung von Forschungsmöglichkeiten und
Patientenversorgung durch innovative IT-Lösungen. Diese sollen den Austausch und die Nutzung
von Daten aus Krankenversorgung, klinischer und biomedizinischer Forschung über die Grenzen
von Institutionen und Standorten hinweg ermöglichen.“ [1]
Anlass dieser Arbeit ist, dass in einem Universitätsklinikum sowohl im Behandlungszusam-
menhang als auch bei der Forschung sehr viele Daten entstehen. Diese unterscheiden sich unter
anderem in:
• dem Zweck und dem Zusammenhang der Erhebung, z. B. im Rahmen von Behandlung, Ab-
rechnung oder Forschung,
• dem Grad der Strukturierung von rein freitextlich („Herr Müller ist 60 Jahre alt, wiegt 72kg, die
Diagnose lautet akute Blinddarmentzündung“) über semi-strukturiert bis vollständig struktu-
riert (Nachname: Müller | Alter: 60 Jahre | Gewicht: 72kg | ICD-10: K35),
• der Quelle, wie z. B. Microsoft Access/Excel, Klinisches Arbeitsplatzsystem (KAS), electronic
data capture system (EDC-System), Data-Warehouse (DWH) etc. und
• dem Inhalt / Semantik: „klassisch“ (Diagnosen, Prozeduren u.ä.), Zeitreihen (Laborwerte, Vital-
parameter), Bilder (Röntgen, CT, MRT, Ultraschall) und molekularbiologische „Omics“-Daten
(Genomsequenzen, Methylierungen, Genexpressionen, Proteine, Metabolite).
Obwohl die Erhebung, Aufbereitung und Analyse dieser Daten mehrheitlich schon lange elek-
tronisch erfolgt, ist die IT-Unterstützung für die (bio)medizinische translationale Forschung zur
Analyse dieser Daten ausbaufähig. Dafür gibt es mindestens die folgenden, in dieser Arbeit adres-
sierten, Gründe.
93.1 Problemstellung
P1: Freitextfelder eignen sich für die schnelle Dokumentation und sind für die reine Behandlung
ausreichend gut nutzbar, können aber für die Forschung ohne geeignete IT-Unterstützung
nur mit großem manuellem Aufwand verwendet werden [2]. In vielen Fällen sind die Fall-
zahlen pro Standort für eine statistisch belastbare Analyse zu gering und es fehlen die Mög-
lichkeiten und Werkzeuge, Daten über mehrere Institutionen datenschutzkonform zusam-
menzuführen.
P2: Unabhängig vom System der Datenerfassung, erfolgt die Auswertung bei vielen Forschern
auf Basis von Excel-Tabellen, was eine Vielzahl von Problemen mit sich bringt, z. B.:
• Excel ist dafür bekannt, durch automatische Typen-Erkennung beim Import die ursprüng-
lich korrekten Ausgangsdaten zu korrumpieren [3].
• Die Möglichkeiten, Datenmodelle jenseits einer „flachen Tabelle“ abzubilden, sind be-
grenzt, sodass relationale 1:N Beziehungen meist nicht adäquat abgebildet oder analysiert
werden (können).
• Es ist nicht praktikabel, zu vorhandenen klinischen Daten zusätzliche molekularbiologi-
sche Daten zu integrieren oder auszuwerten.
• Die Analysemöglichkeiten von Excel sind stärker beschränkt, als es viele Forscher benöti-
gen, insbesondere wenn molekularbiologische Daten betrachtet werden sollen.
P3: Es gibt international grundsätzlich mehrere Forschungsplattformen, die in Bezug auf Pro-
blemstellung P2 Abhilfe zu schaffen versprechen [4–6], jedoch sind diese in Deutschland
bisher wenig bekannt und waren nach meinem Kenntnisstand bis zu Beginn dieser Arbeit
hierzulande nirgends im Einsatz; inzwischen läuft tranSMART zumindest am Universitäts-
klinikum Göttingen im Pilotbetrieb [7]. Für alle betrachteten Forschungsplattformen galt,
dass deren Usability bislang in keinem Kontext evaluiert worden war.
P4: Die Ausbildung der Medizinstudierenden (und damit eines Teils der späteren translationalen
Forscher) geht bislang noch nicht oder nur sehr wenig auf diese Forschungsplattformen ein:
Es gab bislang noch keine Untersuchung, inwiefern diese Plattformen für die Lehre genutzt
werden könnten.
P5: Im sehr jungen Feld der molekularbiologisch-genetisch gestützten Therapieentscheidung
(z. B. im Rahmen eines Molekularen Tumorboards), bei welchem sich der Übergang von
Forschung und Versorgung besonders fließend darstellt, ist die IT-Unterstützung noch sehr
schwach ausgeprägt und bislang nicht einmal der konkrete Bedarf analysiert.
3.2 Zielsetzungen
Im Rahmen dieser Arbeit sollen für o.g. Problemstellungen Lösungsmöglichkeiten durch Errei-
chen folgender Ziele aufgezeigt werden:
Z1: Institutionsübergreifende Erschließung von Freitexten als eine Form der Datenaufbereitung
zur Sekundärnutzung in einem prototypischen Framework: In diesem sollen strukturier-
te Daten datenschutzkonform institutionsübergreifend zusammengeführt werden können,
10wobei die ursprünglich in Freitexten liegenden Informationen mittels Cloud- und Natural-
Language-Processing-Technologien erschlossen werden.
Z2: Bereitstellen einer Forschungsplattform: Diese soll (z. B. aus Freitexten erschlossene) struk-
turierte, klinische Daten mit molekularbiologischen Daten (z. B. aus Genexpressionen, Mu-
tationen etc.) integrieren und auf diesen zusammengeführten Daten statistische Analyseme-
thoden anbieten.
Z3: Evaluation der Nutzbarkeit dieser Plattform für Forschung und Lehre sowie ihrer Usability.
Z4: Erste Einschätzung über den Bedarf und die Eignung solcher Plattformen im Kontext der
Präzisionsmedizin (hier speziell für Molekulare Tumorboards).
3.3 Fragestellungen
Zum Erreichen oben genannter Ziele wurden folgende Fragestellungen durch entsprechende
Publikationen beantwortet:
Im Vorfeld dieser Arbeit mit Beteiligung des Promovenden:
F1: Welche Cloud-Technologien gibt es derzeit, insbesondere im Rahmen und für die Nutzung
im Gesundheitswesen? [8]
F2: Wie können Daten bei einer angedachten Sekundärnutzung aus den Quellsystemen extra-
hiert und in eine Forschungsplattform importiert werden? [9]
F3: Wie können strukturierte klinische Daten institutionsübergreifend zusammengeführt und in
einer zentralen Plattform bereitgestellt werden? [10]
In dieser Arbeit des Promovenden als Erst- oder Seniorautor:
F4: Wie kann eine datenschutzkonforme Architektur aussehen und prototypisch umgesetzt wer-
den, bei der strukturierte Daten sowie Freitexte aus dem Behandlungszusammenhang für die
Forschung bereit gestellt werden? Publikation-1 [11]
F5: Wie kann eine Forschungsplattform zur Datenintegration und -analyse an einem Universitäts-
klinikum für die translationale Forschung etabliert werden? Publikation-2 [12]
F6: Wie kann man diese Forschungsplattform an individuelle Anforderungen anpassen bzw. um
neue Funktionalitäten erweitern? Publikation-3 [13]
F7: Wie kann man neue Nutzer für diese Plattform gewinnen und in deren Anwendung schulen?
Wie bewerten sie diese Plattform in Bezug auf ihre Anforderungen und die Usability?
Publikation-4 [14]
F8: Wie sehen die Prozesse beim Molekularen Tumorboard aus – mit Fokus auf die Unterstüt-
zung durch solch eine Plattform für den molekularbiologisch versierten Arzt/Forscher, der
den Patienten für die Vorstellung im MTB vorbereitet, sowie auf den zu beachtenden Daten-
schutz im Hinblick auf Keimbahnmutationen und das Gendiagnostikgesetz? Publikati-
on-5 [15] und Publikation-6 [16]
113.4 Architektur und Gesamtüberblick
Abbildung 1: Überblick über beteiligte Komponenten und Prozesse dieser Dissertation (Quelle: eigene Darstel-
lung). In der Praxis mindestens prototypisch umgesetzte Punkte: farbig. Bislang noch in der Konzeptphase: grau.
a) Freitexte werden – de-identifiziert in der Cloud – in strukturierte Daten erschlossen (Publikation-1 [11]).
b) Diese erschlossenen und/oder andere bereits vorher strukturierten Daten sowie – falls vorhanden –
c) molekularbiologische (Genexpressionen, Mutationen) Daten werden mittels eines
d) ETL –Prozesses auf Basis des Frameworks Talend Open Studio [9] in mindestens eine der drei folgenden For-
schungsplattformen überführt:
e. i2b2 (z. B. zur Proben-/Kohortenidentifikation [10])
f. tranSMART (z. B. für translationale Analysen für Forschung und Lehre (Publikation-2 [12]) vgl. auch
f1) Erweiterung um ein Plugin zur Überlebenszeitanalyse (Publikation-3 [13]) und
f2) Online-Test mit Usability-Evaluation (Publikation-4 [14])
g. cBioPortal (z. B. zur Unterstützung des Molekularen Tumorboards (Publikation-5 [15] und
Publikation-6 [16])
124 Einordnung in den fachwissenschaftlichen Kontext
Weder die Erschließung der Freitexte noch die Etablierung einer Forschungsplattform kann
durch ein einzelnes Software-Programm erreicht werden: Dafür bedarf es stattdessen einer Abfol-
ge von IT-Prozessschritten, die in einer Gesamtarchitektur datenschutzkonform verknüpft werden
müssen (siehe Abbildung 1 auf S. 12). Im Folgenden werden sowohl die wesentlichen Themenbe-
reiche dieser Arbeit in ihrem fachwissenschaftlichen Kontext als auch in ihrem Zusammenhang
untereinander in der Reihenfolge der zu beantwortenden Fragestellungen (F1-F8) dargelegt.
4.1 Freitexterschließung im Rahmen der Sekundärnutzung
4.1.1 Sekundärnutzung und Datenschutz
Die zunehmende Menge an Patientendaten und deren Verfügbarkeit in der elektronischen
Krankenakte (EKA) des jeweiligen Klinischen Arbeitsplatzsystems (KAS) der Krankenhäuser bie-
tet für die ursprünglich im Behandlungszusammenhang erhobenen Informationen viele Möglich-
keiten im Rahmen der nachgelagerten Sekundärnutzung, z. B. für Zwecke des Qualitätsmanage-
ments, Leistungsvergleichs („Benchmarking“) oder der translationalen Forschung [17]. Deswegen
gab es in den letzten Jahren viele Forschungsprojekte, die die Sekundärnutzung adressieren, z. B.
zum Zwecke der IT-unterstützten Patientenrekrutierung [18] oder einem institutionsübergrei-
fenden Forschungs-Data-Warehouse (DWH) [19–21]. Die meisten Ansätze dazu wurden in den
USA entwickelt und haben folglich einen Fokus auf die dortigen IT-Systeme und Regularien des
„Health Insurance Portability and Accountability Act“ (HIPAA) [22]. Aufgrund der föderalen
Struktur in Europa hängen die genauen datenschutzrechtlichen Bestimmungen mindestens vom
Bundesland und je nach Detail vom jeweiligen Datenschutzbeauftragten des beteiligten Klini-
kums ab [23]. Das schränkt den direkten Transfer derartiger Projektentwicklungen auf deutsche
Verhältnisse ein. Der prophylaktische Datenexport (wie in [24, 25]) in ein Data-Warehouse ist
zum Beispiel typischerweise nicht erlaubt, sodass jede Studie einzeln bewilligt werden muss, bevor
ein Kerndatensatz aus dem Krankenhaus in eine institutionsübergreifende zentrale Datenbank
exportiert werden darf.
Regulatorisch (in Bezug auf Patienteneinwilligung / Datenschutz) am einfachsten sind struk-
turierte anonyme Patientendaten zu handhaben. Das sind Daten, bei welchen kein Rückschluss
auf einen einzelnen Patienten gezogen werden kann. Hier bestehen die niedrigsten Hürden, die
13Daten aus dem Krankenhaus exportieren und zentral aggregieren zu dürfen, um anschließend
darauf Analysen durchzuführen. Um jedoch zu verhindern, dass aus einer Vielzahl an verknüpf-
ten, vermeintlich anonymen Daten letztlich doch bei entsprechendem Vorwissen auf Einzelper-
sonen geschlossen werden kann (z. B. bei Kenntnis einer seltenen Diagnose, Postleitzahl und weit
überdurchschnittlicher Körpergröße), müssen vor dem Export ggf. statistische Verfahren wie k-
Anonymisierung [26] oder L-Diversität [27] zur Vergröberung der Daten angewendet werden
(was allerdings deren Nutzbarkeit für wissenschaftliche Auswertungen mindern kann). Dies ist
methodenbedingt jedoch nur bei strukturierten Daten möglich, während die hinreichend gesi-
cherte Anonymisierung von Freitexten (insbesondere unter Beibehaltung ihres wissenschaftlichen
Informationsgehalts [28]) oder deren Überführung in strukturierte Daten eine besondere Heraus-
forderung darstellt.
4.1.2 Framework zur institutionsübergreifenden Erschließung von Freitexten
Unter den von Hersh et al. publizierten sieben Herausforderungen für die sekundäre Nutzung
der elektronischen Krankenakte für die Forschung [17] wird explizit genannt, dass Freitexte, z. B.
aus Entlassbriefen, nicht wie bereits strukturierte Daten für weitere Analysen verwendet werden
können. Aus diesem Grund wurde die Überführung von Freitexten in strukturierte Daten mittels
sogenannter „natural language processing“ (NLP)-Software schon mehrfach adressiert [29, 30].
Mutmaßlich erstmalig wurde im Rahmen dieser Arbeit im Projekt cloud4health [11] die Kom-
bination aus Extraktion bereits bestehender strukturierter und kodierter klinischer Daten aus ih-
ren Quellsystemen (z. B. OPS-codierte Prozeduren/Operationen aus dem DWH) zusammen mit
NLP-Algorithmen zur Anreicherung zusätzlich aus Freitexten erschlossener Informationen in ei-
ner flexibel erweiterbaren Architektur gezeigt. In diesem Framework sind alle an diesem Prozess
beteiligten Komponenten in einer datenschutzgerechten Pipeline miteinander verknüpft.
NLP gilt zudem als aufwändig in Bezug auf benötigte Rechenkapazität [31] oder die Pflege der
enthaltenen Algorithmen oder Datengrundlage (z. B. Updates integrierter Wörterbücher) [22].
Deswegen war ein weiteres Ziel, den Herausforderungen zu begegnen, die entstehen, wenn diese
Technologie als möglicher Cloud-Dienst, z. B. „Software as a Service“ [32], integriert werden soll,
um sowohl Flexibilität in Hinsicht der Rechenkapazitäten als auch bezüglich der Zentralisierung
der Wartung zu erreichen (siehe Fragestellung F1). Neben Cloud-spezifischen, technischen Fra-
gen (Verbindungsaufbau, Sitzungsmanagement) oder Details zur Datensicherheit (Authentifizie-
rung, Verschlüsselung) galt es vor allem, den bei medizinischen Daten besonders strengen und
national sowie bundeslandspezifischen Datenschutz ([23, 33, 34]) zu gewährleisten. Dies wurde
u.a. durch eine spezielle Komponente („protected health information tagger (PHI-Tagger)“) er-
reicht, welche die Freitexte semi-automatisch von allen Daten bereinigt, die potentiell Patienten
identifizierend sind, ehe diese derart prozessierten Freitexte zur weiteren NLP-Verarbeitung in die
Cloud außerhalb des geschützten Klinikumbereichs gesendet werden. Dieses Verfahren wurde in
Bezug auf seine Korrektheit (Sensitivität und Spezifität) nach seiner Implementierung evaluiert
[35], worin gezeigt wurde, dass es nach einer Trainingsphase im Wesentlichen gleichwertige Er-
gebnisse zu einer manuellen Annotation der fraglichen Textfragmente liefert.
144.2 Forschungsplattformen
Große europäische Projekte wie TRANSFORM [36], EU-ADR [37] und EHR4CR [38] zielten
bei Beginn dieser Arbeit darauf ab, inter-institutionelle Forschungsplattformen zu etablieren, um
verschiedene Szenarien der Prozesse für klinische Studien (z. B. Abschätzung der Machbarkeit1,
Patientenrekrutierung, Datenakquise oder Erkennung von unerwünschten Arzneimittelwirkun-
gen2 zu unterstützen. Im Gegensatz zum Projekt cloud4health wurde die Freitexterschließung
dabei jedoch höchstens nachrangig betrachtet und anstelle des Quellcode-offenen i2b2 [39] vor-
wiegend auf proprietäre Plattformen gesetzt. Vor allem wurden in keinem dieser Projekte mole-
kularbiologische Daten integriert.
Aufgrund der stetig fallenden Kosten für molekularbiologische Laboranalysen [40] gibt es je-
doch insbesondere im Bereich Genexpression und Sequenzierung eine schnell ansteigende Ver-
fügbarkeit solcher Genom-, Transkriptom- und Proteomdaten (auch „-omics“ genannt), die z. B.
aus entsprechenden Laboranalysen von Proben aus Tumorgewebebanken stammen. Dies erhöht
für translationale Forscher den Bedarf an einer Integration dieser Daten mit klinischen Daten in
einer vereinigten Sicht und der Verfügbarkeit passender statistischer Auswertemethoden [41]. Als
Beispiel einer typischen Fragestellung sei die Untersuchung der Bedeutung von Mutationen eines
Gens und dessen Expression in der Zelle für einen klinischen Parameter wie (krankheitsfreies)
Überleben genannt [42]. Im Folgenden ist mit einer Forschungsplattform zur Datenintegration
und -analyse im Einklang mit der Literatur [7] eine Software gemeint, die genau den oben be-
schriebenen Bedarf deckt, in dem sie mindestens zwei Komponenten enthält:
• eine Datenbank mit einer Struktur, die sowohl klinische als auch molekularbiologische Daten
eines Patienten miteinander verknüpft modellieren und speichern kann und
• eine möglichst intuitive – auch für Nicht-Informatiker bedienbare – Benutzeroberfläche (heut-
zutage meist eine Webanwendung, die mittels des Browsers angesteuert wird) zur „spieleri-
schen“ Exploration dieser vereinigten Daten, Kohortenidentifikation, Biomarkersuche, Hypo-
thesengenerierung und -validierung.
Dies kann auch die Sekundärverwertung von bereits für einen anderen Zweck erhobenen Da-
ten erleichtern bzw. überhaupt erst ermöglichen und damit Kosten senken sowie die Forschungs-
effizienz erhöhen [43].
Reviews, die solche Plattformen untereinander vergleichen [44, 45], zeigen, dass es aktuell ca.
zehn solcher öffentlich verfügbarer Softwarelösungen gibt, zu denen u.a. tranSMART und cBio-
Portal [46] gehören. Letztere werden in den beiden folgenden Kapiteln näher beschrieben, da sie
im Rahmen dieser Arbeit konkret für die translationale Forschung eingesetzt und evaluiert (i2b2/
tranSMART) oder konzeptionell für das Molekulare Tumorboard ins Auge gefasst (cBioPortal)
wurden.
Von der Kernfunktionalität der Datenspeicherung inklusive des Datenbeladens durch einen
Extraktion-Transformation-Laden-Prozess ist eine solche Forschungsplattform mit einem klini-
schen Data-Warehouse (DWH, [47]) vergleichbar, bei welchem die zu importierenden Daten als
1 engl.: feasibility study
2 engl.: adverse drug events
15erstes durch einen „Extrakt“-Prozess aus ihren Quellsystemen (z. B. aus der Datenbank des KAS
oder aus Excel-Tabellen) herausgeholt, dann in der „Transformations“-Phase in die für den Anwen-
der nutzbare strukturierte Form gebracht und letztlich im „Laden“-Prozessschritt in die Ziel-Da-
tenbank des DWH bzw. der Forschungsplattform importiert werden. DWHs bieten unter anderem
anwenderspezifisch vordefinierbare Reports oder Analysemethoden des Drill-Down durch Online
Analytical Processing (OLAP)-Würfel an, mit welchem man z. B. Einblicke folgender Art erhalten
kann: Eine umfangreiche tabellarische Liste aller behandelten Tumorentitäten eines Klinikums in
Spalte 1, das dazugehörende durchschnittliche Diagnosealter in Spalte 2, die Anzahl der dazu durch-
geführten Prozeduren in Spalte 3 etc. Außerdem können beim Drill-Down in z. B. das Lungenkar-
zinom Fragestellungen der folgenden Art beantwortet werden: „Welche Medikationen wurden bei
Patienten mit diesem Tumor angeordnet?“, „Wie war bei diesen die durchschnittliche Liegedauer?“ etc.
Diese Reports müssen in der Regel von einem IT-Experten vordefiniert werden und eignen sich
folglich vor allem für häufig wiederkehrende Fragestellungen wie etwa im Bereich Controlling.
Dagegen bieten die in dieser Arbeit betrachteten Forschungsplattformen anstelle der relativ star-
ren Reports etwas flexiblere Analysemöglichkeiten für individuelle und sich voneinander stärker
unterscheidende Fragestellungen wie z. B.:
• „Wie viele männliche Patienten mit Lungenkarzinom zwischen 30 und 50 Jahren gibt es an unserer
Klinik, die erst eine Chemotherapie erhielten und anschließend bestrahlt wurden?“ (z. B. in i2b2
zur Kohortenidentifikation / Studien-Machbarkeitsabschätzung),
• Die Genexpression welchen Gens zeigt die größte Korrelation mit der Überlebenszeit?“ (z. B. in
tranSMART zur Hypothesengenerierung) oder „Sterben weibliche Raucher früher als männliche
Nichtraucher?“ (z. B. in tranSMART zur Hypothesenvalidierung).
Dafür werden vordefinierte Analysemethoden wie z. B. t-Test, Kaplan-Meier-Schätzer, Cluster-
Algorithmen oder Heatmaps angeboten. Trotzdem setzen auch diese Methoden dem Anwender
mehr oder minder enge Grenzen im Vergleich zu einer für statistische Analysen optimierten Pro-
grammiersprache wie R. Aus diesem Grunde bietet z. B. tranSMART eine R-Schnittstelle an, mit der
es möglich ist, dass der Forscher mit seinem fundierten (bio-)medizinischen Hintergrundwissen
über die Weboberfläche von tranSMART in der Hypothesengenerierung Ansätze für einen Sachver-
halt findet, die der Biometriker über die R-Schnittstelle auf genau denselben Daten und mit seinen
Methoden validieren kann.
Während kommerzielle DWHs wie z. B. Cognos von IBM [48] auch den ETL-Prozess unter-
stützen, ist dies bei den Forschungsplattformen selten – und falls doch, dann nur sehr rudimentär.
Daher ergab sich auch die in Kapitel 3.3 gestellte Frage F2, wie „Daten bei einer angedachten Se-
kundärnutzung aus den Quellsystemen extrahiert und in die Forschungsplattform [i2b2] impor-
tiert werden“ können. Hierfür wurden im Projekt Integrated Data Repository Toolkit (IDRT) un-
ter Mitwirkung des Promovenden entsprechende Werkzeuge entwickelt und publiziert [9]. Diese
konnten in angepasster Form in später folgenden Projekten wie „Klinische Datenintelligenz“ [49]
für die Datenbeladung von tranSMART genutzt werden.
Dass mittels i2b2 strukturierte klinische Daten institutionsübergreifend zusammengeführt
werden können, um z. B. die Anzahl benötigter Bioproben für eine Studie abzuschätzen, wurde
bereits in früheren Arbeiten des Autors zur Etablierung eines Biobanken IT-Frameworks (siehe
F3 [10]) gezeigt. Auf diesen Vorarbeiten konnte aufgesetzt werden, als im Projekt cloud4health
16als Forschungsplattform i2b2 eingesetzt wurde (F4 Publikation-1 [11]). Darin fand das Zusam-
menführen von – bereits aus anderen Quellen – strukturiert vorliegenden Daten statt mit solchen,
die erst durch NLP-Verfahren aus Freitexten gewonnenen wurden.
4.2.1 Forschungsplattformen i2b2 und tranSMART
Das ursprünglich durch die National Institutes of Health (NIH) geförderte und von der Har-
vard Medical School in Boston seit den Anfängen 2004 entwickelte i2b2 [39] hatte als originären
Zweck die Unterstützung der Forschung durch Abschätzung vorhandener Fallzahlen und Iden-
tifizierung geeigneter Kohorten für Studien. Dafür speichert es in seiner Datenbank klinische
Daten in einem flexibel um neue Merkmale erweiterbaren Entity-Attribute-Value (EAV) Schema
[50]. Darauf aufbauend bietet ein Applikationsserver dem Anwender über eine Weboberfläche die
Möglichkeit, den patientenzentrierten Datenbestand intuitiv abzufragen. 2012 begann die Phar-
mafirma Johnson & Johnson in Partnerschaft mit der Firma Recombinant Data die Software i2b2
in einer eigenen Version namens tranSMART [4] für die Suche nach Biomarkern weiterzuent-
wickeln. Dazu übernahm es von i2b2 das Datenbankschema für die klinischen Daten und fügte
weitere relationale Tabellen für die molekularbiologischen Daten hinzu. Auch die Weboberfläche
lehnte sich von manchen Konzepten an i2b2 an, wurde jedoch basierend auf moderneren Web-
technologien neu entwickelt und um deutlich umfangreichere Analysemethoden erweitert. Diese
ermöglichen insbesondere den Vergleich zweier Kohorten miteinander, was die Datenexploration,
Hypothesengenerierung und Hypothesenvalidierung auf Datenbeständen erlaubt, in denen kli-
nische und molekularbiologische Daten zusammengeführt wurden. Die seit 2017 existente i2b2
tranSMART Foundation arbeitet – mit einer aktiven und für jeden offenen Community – daran,
die inzwischen beide als Open Source verfügbaren Plattformen wieder näher zusammen zu brin-
gen, um idealerweise die Stärken von beiden in einer integrierten Version zu vereinen [51]:
• von i2b2 die mächtigere Modellierung von klinischen Daten sowie die Einbeziehung von zeitli-
chen Abhängigkeiten und
• von tranSMART die Integration molekularbiologischer Daten und die umfangreicheren Analy-
semethoden.
In vor und während dieser Promotion erschienenen Veröffentlichungen wurde die Nutzung von
tranSMART für klinische Studien gezeigt [52], dessen Aufbau und Architektur beschrieben [4, 53],
seine Bedeutung in IT-Infrastrukturen skizziert [7, 41, 43] sowie in Verbindung mit anderen Plattfor-
men wie Galaxy, Minerva oder Genedata Analyst [54, 55] bzw. mit anderen Technologien wie NoSQL-
Datenbanken und HL7-Anbindungen [56, 57] geschildert. Im Gegensatz zu dieser Dissertation wurde
allerdings in keiner dieser Arbeiten die Etablierung an einem Universitätsklinikum (F5 Publikati-
on-2) [12], die Erweiterbarkeit um eigene Analysemethoden (F6 Publikation-3) [13], eine Evaluati-
on seiner Usability oder die Nutzung in der Lehre (F7 Publikation-4) [14] thematisiert.
Dies ergab sich dadurch, dass am Universitätsklinikum Erlangen und an der Medizinischen
Fakultät der FAU molekularbiologische Hochdurchsatzanalyseverfahren [58] ein integraler Be-
standteil der Forschung, insbesondere im Bereich der Onkologie, geworden sind. Interdisziplinä-
re Gruppen von Biometrikern, Molekularbiologen und Ärzten analysieren inzwischen klinische
Daten genauso wie molekularbiologische Daten in beträchtlichem Umfang und über mehre-
re Ebenen hinweg, z. B. „single nucleotide variants“ (SNV) vom Genom, Genexpressionen vom
17Transkriptom und qualitative Signale bzgl. der Existenz bestimmter Proteine vom Proteom. Der
Lehrstuhl für Medizinische Informatik wurde mit steigender Frequenz nach einer Unterstützung
dieser Teams in Bezug auf die Speicherung, Abfrage und Analyse solcher Daten gefragt. Die For-
scher äußerten ihren Bedarf für:
1. Sekundärnutzung von Daten aus den Routinesystemen,
2. die Integration klinischer und molekularbiologischer Daten in einer zusammengeführten Sicht,
3. ein graphisches und einfach zu benutzendes Analyse-Werkzeug,
4. eine Kollaborationsplattform zum Austausch ihres Wissens und Daten zwischen Klinikern und
Biometrikern sowie
5. einer Weiterbildungsmöglichkeit für sich selbst und den studentischen Nachwuchs.
Daraufhin identifizierten wir tranSMART als geeignetes Werkzeug für diese Anforderungen
und begannen, es ab September 2014 als einen Service für die Forscher zu etablieren, es gemäß
den im Rahmen der Nutzung entstehenden aufkommenden Anforderungen weiter zu entwickeln
und die Nutzbarkeit für Forschung und Lehre zu evaluieren.
4.2.2 Forschungsplattform cBioPortal
Das Memorial Sloan Kettering Cancer Center (MSK) in New York entwickelt seit mindestens
2012 die Plattform cBioPortal [46], um es in der translationalen Forschung und Versorgung im
onkologischen Bereich zu nutzen. Während i2b2 und tranSMART ihre Stärken in der kohorten-
Abbildung 2: Im fotomontierten tranSMART-Screenshot befindet sich auf der linken Seite der Navigationsbaum
(schwarz kurz-lang gestrichelt). Im rechten Bereich zeigen sich nach gewähltem Button (oben rechts umrandet) ent-
weder die Auswahlmaske zur Kohortendefinition (rote durchgehende Linie), deskriptive Statistikergebnisse (blau
kurz gestrichelt) oder die Ergebnisse weiterführender Analysen (grün lang gestrichelt) (Quelle: eigene Darstellung)
18zentrierten Sicht haben und letzteres Kohorten miteinander vergleichen kann, bietet cBioPortal
(neben einer ebenfalls existenten kohortenzentrierten Sicht, die allerdings keine Kohortenver-
gleiche erlaubt) in einer patientenzentrierten Ansicht dem Anwender auf einen Blick abnorme
Expressionswerte sowie genetische Veränderungen. Für diese sind Annotationen verfügbar, die
aus öffentlichen und internen Datenbanken stammen (z. B. kontextsensitiv bei einer Mutation
im Patienten ein für diese Tumorentität von der amerikanischen Food and Drug Administrati-
on (FDA) zugelassenes Medikament, siehe OncoKB [59]). Da sich in cBioPortal auch zu einem
Patienten gehörende klinische Informationen, Schnittbilder und Pathologiereports abspeichern
lassen, scheint es nach der Analyse der beim Molekularen Tumorboard ablaufenden Prozesse
und Rahmenbedingungen (vgl. F8 Publikation-5&6) [15, 16] als Plattform zur Unterstützung
der Erstellung einer Therapieempfehlung und ggf. auch -dokumentation grundsätzlich geeignet
zu sein (ggf. nach entsprechenden Anpassungen). Da cBioPortal einen sehr starken Fokus auf
die molekularbiologischen Daten legt und ohne deren Vorliegen kaum Visualisierungen oder
Analysen anbieten kann, was bei i2b2/tranSMART durchaus der Fall ist, ergänzen sich die bei-
den Plattformtypen und können in den meisten Anwendungsfällen nicht gegenseitig ersetzt
werden.
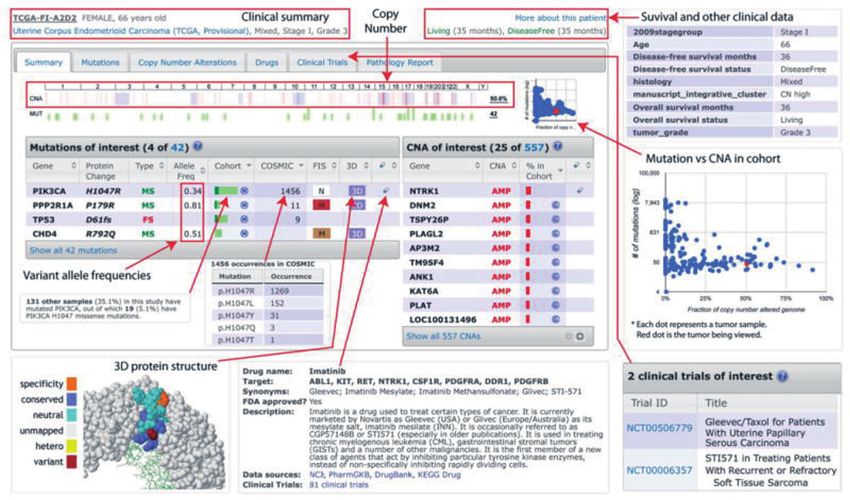
Abbildung 3: Patientenzentrierte Sicht, die „als Beispiel die relevanten genomischen Veränderungen und kli-
nischen Daten eines Patienten mit Endometriumkarzinom zeigt, kombiniert mit der Histologie einer TCGA-
Studie“ (Quelle: [46]).
4.3 Usability und deren Evaluation
Der englische Fachausdruck Usability wird am treffendsten mit Gebrauchstauglichkeit oder Be-
nutzerfreundlichkeit übersetzt und ist nach DIN EN ISO 9241 definiert als „das Ausmaß, in dem
ein Produkt, System oder Dienst durch bestimmte Benutzer in einem bestimmten Anwendungskon-
19text genutzt werden kann, um bestimmte Ziele, effektiv, effizient und zufriedenstellend zu erreichen“
[60]. Die Norm zeigt folgende Qualitätskriterien für die Dialoggestaltung auf:
1. Aufgabenangemessenheit (geeignete Funktionalität, Minimierung unnötiger Interaktionen)
2. Selbstbeschreibungsfähigkeit (Verständlichkeit durch Hilfen / Rückmeldungen)
3. Steuerbarkeit (Steuerung des Dialogs durch den Benutzer)
4. Erwartungskonformität (Konsistenz, Anpassung an das Benutzermodell)
5. Fehlertoleranz (unerkannte Fehler verhindern nicht das Benutzerziel, erkannte Fehler sind leicht
zu korrigieren)
6. Individualisierbarkeit (Anpassbarkeit an Benutzer und Arbeitskontext)
7. Lernförderlichkeit (Minimierung der Erlernzeit, Metaphern, Anleitung des Benutzers)
In der von uns für tranSMART durchgeführten Usability-Evaluation [14] wurden o.g. Punkte
unter anderem durch die „System Usability Skala“ (SUS) [61] erhoben, die von 0 (minimale Usa-
bility) bis 100 (maximale Usability) Punkte reichend einen Anhaltspunkt für die Gebrauchstaug-
lichkeit gibt.
Offensichtlich scheint eine gute Usability bei jeder Software erstrebenswert. Sie ist jedoch umso
wichtiger, je weniger IT-Erfahrung der angestrebte Nutzerkreis hat, um Defizite des Programms
bei der Gebrauchstauglichkeit kompensieren zu können. Obwohl tranSMART und andere transla-
tionale Forschungsplattformen eine zusätzliche Programmierschnittstelle (API) für Programmie-
rer und Statistiker anbieten, zielen sie auf eine Bedienung über die Weboberfläche durch Forscher
mit eingeschränkten IT-Kenntnissen. Folglich ist die Usability ein entscheidender – wenngleich
häufig vernachlässigter – Faktor bei der Etablierung und dem sachgemäßen Umgang mit solchen
Plattformen. Während die Evaluation der Usability in der Gesundheits-IT inzwischen einige Be-
achtung erfährt, gibt es bislang nur sehr wenige Studien, die Forschungsplattformen adressieren:
Mathew et al. zum Beispiel ermittelten einen SUS-Wert von 67 für eine kollaborative Forschungs-
plattform [62] und Wozney et al. gaben einen Wert von 70 für ihre „Intelligent Research and In-
tervention Software”, die psychosoziale Interventionen in einer klinischen Umgebung liefert [63],
an. Gemäß eigener Literaturrecherche gab es jedoch keine Usability-Untersuchung, die sich mit
translationalen Forschungsplattformen wie tranSMART oder cBioPortal beschäftigte: Obwohl
diese von sich selbst behaupten, dass sie nutzerfreundlich seien (z. B. “[tranSMART] can be used
by users […] without any expertise in computer science.” [41]), stand ein wissenschaftlicher Beleg
hierfür aus. Die Ergebnisse unserer Studie [14] schlossen diese Lücke: Mit einer SUS von 70,8
(Kategorie akzeptabel nach Bangor et al. [64]) reiht sie sich von der Größenordnung in o.g. Werte
ein. Der Wert zeigt, dass die meisten Forscher mit der Usability zufrieden sind, es jedoch auch
noch Potential für Verbesserungen in diesem Bereich gibt, für die unsere Untersuchung konkrete
Empfehlungen ableiten konnte.
4.4 Forschungsplattformen in der Lehre
Neben der Verfügbarkeit von nutzerfreundlicher Software, bedarf es jedoch auch entsprechend
ausgebildeter Anwender (“the promise of data in medicine and biology will not be realized wit-
hout a new generation of students, researchers, and developers who are trained with state-of-the-art
20You can also read

















































