Leadership AI Computing - Mike Houston, Chief Architect - AI Systems
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Leadership AI Computing Mike Houston, Chief Architect - AI Systems

AI Impact On Science
2
AI SUPERCOMPUTING DELIVERING SCIENTIFIC BREAKTHROUGHS
7 of 10 Gordon Bell Finalists Used NVIDIA AI Platforms
AI-DRIVEN MULTISCALE SIMULATION DOCKING ANALYSIS DEEPMD-KIT SQUARE KILOMETER ARRAY
Largest AI+MD Simulation Ever 58x Full Pipeline Speedup 1,000x Speedup 250GB/s Data Processed End-to-End
EXASCALE AI SCIENCE CLIMATE (1.12 EF) GENOMICS (2.36 EF) NUCLEAR WASTE REMEDIATION (1.2 EF) CANCER DETECTION (1.3 EF) LBNL | NVIDIA ORNL LBNL | PNNL | Brown U. | NVIDIA ORNL | Stony Brook U.

FUSING SIMULATION + AI + DATA ANALYTICS
Transforming Scientific Workflows Across Multiple Domains
PREDICTING EXTREME WEATHER EVENTS SimNet (PINN) for CFD RAPIDS FOR SEISMIC ANALYSIS
5-Day Forecast with 85% Accuracy 18,000x Speedup 260X Speedup Using K-Means
FERMILAB USES TRITON TO SCALE
DEEP LEARNING INFERENCE IN
HIGH ENERGY PARTICLE PHYSICS
GPU-Accelerated Offline Neutrino
Reconstruction Workflow
400TB Data from Hundreds of Millions of Neutrino Events
17x Speedup of DL Model on T4 GPU Vs. CPU
Triton in Kubernetes Enables “DL Inference” as a Service
Expected to Scale to Thousands of Particle Physics Client Nodes
Neutrino Event Classification from Reconstruction
EXPANDING UNIVERSE OF SCIENTIFIC COMPUTING
DATA
ANALYTICS SIMULATION
SUPERCOMPUTING
EDGE APPLIANCE
NETWORK
EDGE VISUALIZATION
STREAMING
EXTREME IO
CLOUD AI
THE ERA OF EXASCALE AI SUPERCOMPUTING
AI is the New Growth Driver for Modern HPC
HPL VS. AI PERFORMANCE AI
10000
Leonardo
Perlmutter
Summit
JUWELS
Sierra
PFLOPS
Fugaku
1000
HPL
100
2017 2018
2018 2019
2019 2020 2021
2021 2022
HPL: Based on #1 system in June Top500
AI: Peak system FP16 FLOPS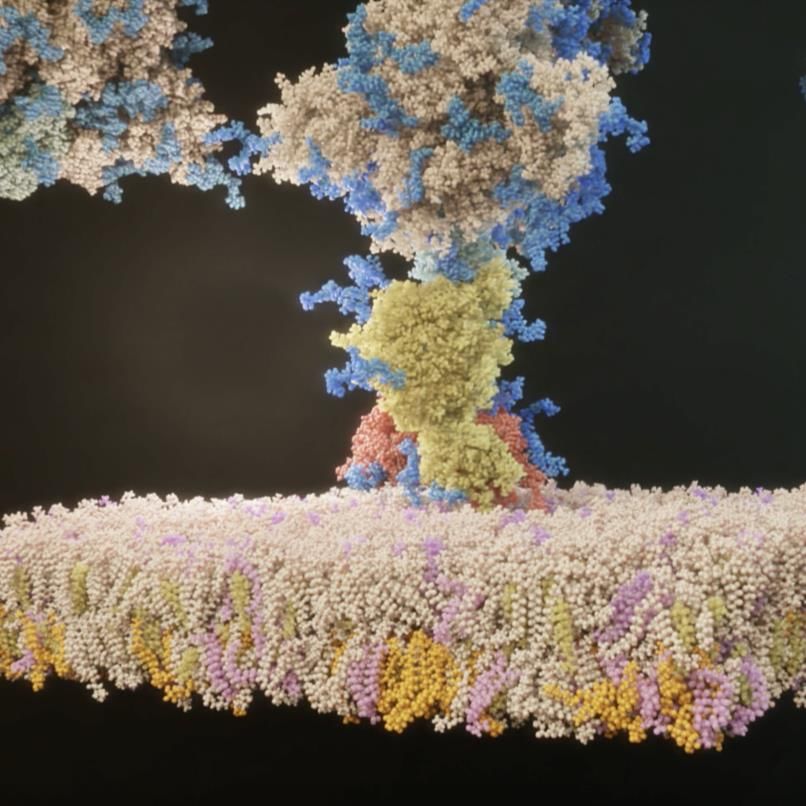
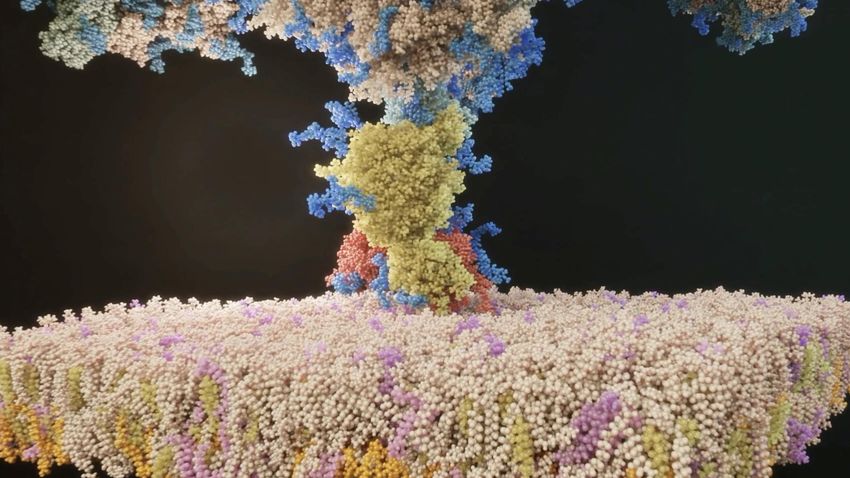
FIGHTING COVID-19 WITH SCIENTIFIC COMPUTING
$1.25 Trillion Industry | $2B R&D per Drug | 12 ½ Years Development | 90% Failure Rate
SEARCH
O(1060)
Chemical Compounds
O(109)
GENOMICS STRUCTURE DOCKING SIMULATION IMAGING
Biological Drug
Target O(102) Candidate
NLP
Literature Real World DataFIGHTING COVID-19 WITH NVIDIA CLARA DISCOVERY
SEARCH
O(1060)
Chemical Compounds
RAPIDS
O(109)
GENOMICS STRUCTURE DOCKING SIMULATION IMAGING
Biological Drug
Target O(102) Candidate
Schrodinger
Clara Parabricks CryoSPARC, Relion AutoDock Clara Imaging
NAMD, VMD, OpenMM
RAPIDS AlphaFold RAPIDS MELD MONAI
NLP
Literature Real World Data
BioMegatron, BioBERTEXPLODING DATA AND MODEL SIZE
GPT-3
175 Bn 175
Zettabytes
# Parameters (Log scale)
Turing-NLG
17 Bn 393 TB 287 TB/day
COVID-19 Graph Analytics ECMWF
GPT-2 8B
8.3 Bn
58
Zettabytes
BERT
340 M
Transformer
65 M
16 TB/sec 550 TB
2017
2017 2018
2018 2019
2019 2020
2020 2021 2010 2015 2020 2025
SKA NASA Mars Landing Sim.
EXPLODING MODEL SIZE BIG DATA GROWTH GROWTH IN SCIENTIFIC DATA
Driving Superhuman Capabilities 90% of the World’s Data in last 2 Years Fueled by Accurate Sensors & Simulations
Source for Big Data Growth chart: IDC – The Digitization of the World (May, 2020)AI SUPERCOMPUTING NEEDS EXTREME IO
System Memory System Memory System Memory
CPU CPU CPU RTX HPC RAPIDS AI CLARA METRO DRIVE ISAAC AERIAL
PCIe Switch 200GB/s PCIe Switch PCIe Switch 200GB/s Storage
CUDA-X
NIC NIC NIC
GPU GPU GPU
CUDA
8X 8X 8X
NODE A NODE B NODE A MAGNUM IO
IN-NETWORK
STORAGE IO NETWORK IO IO MANAGMENT
COMPUTE
GPUDIRECT RDMA GPUDIRECT STORAGE
IB Network
∑ NODE 0-15 REDUCTIONS 2X DL Inference Performance
10X IO Performance | 6X Lower CPU Utilization
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
NODES 0-15
SHARP IN-NETWORK COMPUTINGIO OPTIMIZATION IMPACT
1.54X 3.8X
2.9X
1.24X 2.4X
1X
1X
1X
MPI NCCL NCCL+P2P NUMPY DALI DALI+GDS WITHOUT GDS WITH GDS
IMPROVING SIMULATION OF PHOSPHORUS SEGMENTING EXTREME WEATHER REMOTE FILE READS AT PEAK
MONOLAYER WITH LATEST NCCL P2P PHENOMENA IN CLIMATE SIMULATIONS FABRIC BANDWIDTH ON DGX A100DATA CENTER
ARCHITECTURE
15SELENE
DGX SuperPOD Deployment
#1 on MLPerf for commercially available systems
#5 on TOP500 (63.46 PetaFLOPS HPL)
#5 on Green500 (23.98 GF/watt) - #1 on
Green500 (26.2 GF/W) - single scalable unit
#4 on HPCG (1.6 PetaFLOPS)
#3 on HPL-AI (250 PetaFLOPS)
Fastest Industrial System in U.S. — 3+ ExaFLOPS AI
Built with NVIDIA DGX SuperPOD Architecture
• NVIDIA DGX A100 and NVIDIA Mellanox IB
• NVIDIA’s decade of AI experience
Configuration:
• 4480 NVIDIA A100 Tensor Core GPUs
• 560 NVIDIA DGX A100 systems
• 850 Mellanox 200G HDR IB switches
• 14 PB of all-flash storage
16LESSONS LEARNED
How to Build and Deploy HPC Systems
with Hyperscale Sensibilities
Speed and feed matching
Thermal and power design
Interconnect design
Deployability
Operability
Flexibility
Expandability
17DGX-1 PODs
NVIDIA DGX-1 – original layout DGX-1 Multi-POD
RIKEN RAIDEN NVIDIA DGX-1 – new layout
18DGX SuperPOD with DGX-2
19A NEW DATA CENTER
DESIGN
20DGX SUPERPOD
Fast Deployment Ready - Cold Aisle Containment Design
21DGX SuperPOD Cooling / Airflow
22A NEW GENERATION OF SYSTEMS
NVIDIA DGX A100
GPUs 8x NVIDIA A100
GPU Memory 640 GB total
Peak performance 5 petaFLOPS AI | 10 petaOPS INT8
NVSwitches 6
System Power Usage 6.5kW max
Dual AMD Rome 7742
CPU
128 cores total, 2.25 GHz(base), 3.4GHz (max boost)
System Memory 2TB
8x Single-Port Mellanox ConnectX-6 200Gb/s HDR
Infiniband (Compute Network)
Networking
2x Dual-Port Mellanox ConnectX-6 200Gb/s HDR
Infiniband (Storage Network also used for Eth*)
OS: 2x 1.92TB M.2 NVME drives
Storage
Internal Storage: 15TB (4x 3.84TB) U.2 NVME drives
Software Ubuntu Linux OS (5.3+ kernel)
System Weight 271 lbs (123 kgs)
Packaged System Weight 315 lbs (143 kgs)
Height 6U
Operating temp range 5°C to 30°C (41°F to 86°F)
* Optional upgrades
2324
MODULARITY: RAPID DEPLOYMENT
Compute: Scalable Unit (SU) Compute Fabric Storage
and Mgmt
25DGX SUPERPOD
Modular Architecture
GPU
1K GPU SuperPOD Cluster POD
• 140 DGX A100 nodes (1,120 GPUs) in a GPU POD
• 1st tier fast storage - DDN AI400x with Lustre 1K GPU POD
• Mellanox HDR 200Gb/s InfiniBand - Full Fat-tree
• Network optimized for AI and HPC
Distributed Core Switches Distributed Core Switches
DGX A100 Nodes
• 2x AMD 7742 EPYC CPUs + 8x A100 GPUs Spine Switches Storage Spine Switches
• NVLINK 3.0 Fully Connected Switch
• 8 Compute + 2 Storage HDR IB Ports
Leaf Switches Storage Leaf Switches
A Fast Interconnect …
• Modular IB Fat-tree
• Separate network for Compute vs Storage
DGX A100
#1
… DGX A100
#140
Storage
• Adaptive routing and SharpV2 support for offload
26GPU
POD
DGX SUPERPOD GPU
POD
GPU
POD
Extensible Architecture
GPU
POD to POD POD
• Modular IB Fat-tree or DragonFly+
• Core IB Switches Distributed Between PODs 1K GPU POD
• Direct connect POD to POD
Distributed Core Switches Distributed Core Switches
Spine Switches Storage Spine Switches
Leaf Switches Storage Leaf Switches
…
DGX A100
#1
… DGX A100
#140
Storage
27MULTI NODE IB COMPUTE
The Details
Distributed Core Switches
Designed with Mellanox 200Gb HDR IB network
Separate compute and storage fabric
8 Links for compute
2 Links for storage (Lustre)
Both networks share a similar fat-tree design
Modular POD design
140 DGX A100 nodes are fully connected in a SuperPOD
SuperPOD contains compute nodes and storage
All nodes and storage are usable between SuperPODs
Sharpv2 optimized design
Leaf and Spines organized in HCA planes
For a SuperPOD, all HCA1 from 140 DGX-2 connect to a
HCA1 Plane fat-tree network
Traffic from HCA1 to HCA1 between any two nodes in a
POD stay either at the Leaf or Spine level
Only use core switches when
- Moving data between HCA planes (e.g. mlx5_0 to
mlx5_1 in another system)
- Moving any data between SuperPODs
28DESIGNING FOR PERFORMANCE
In the Data Center
All design is based on a radix optimized approach for
Sharpv2 support and fabric performance and to align
with design of Mellanox Quantum switches.
Scalable Unit (SU)
29SHARP
HDR200 Selene Early Results
128 NVIDIA DGX A100
(1024 GPUs, 1024 InfiniBand Adapters
NCCL AllReduce Performance Increase with SHARP
3.0
Performance Increase Factor
2.0
1.0
0.0
Message Size
30STORAGE
Parallel filesystem for perf and
NFS for home directories
Per SuperPOD:
Fast Parallel FS: Lustre (DDN)
- 10 DDN AI400X Units
- Total Capacity: 2.5 PB
- Max Perf Read/Write: 490/250 GB/s
- 80 HDR-100 cables required
- 16.6KW
Shared FS: Oracle ZFS5-2
- HA Controller Pair/768GB total
- 8U Total Space (4U per Disk Shelf, 2U per controller)
- 76.8 TB Raw - 24x3.2TB SSD
- 16x40GbE
- Key features: NFS, HA, snapshots, dedupe
- 2kW
31STORAGE HIERARCHY
• Memory (file) cache (aggregate): 224TB/sec - 1.1PB (2TB/node)
• NVMe cache (aggregate): 28TB/Sec - 16PB (30TB/node)
• Network filesystem (cache - Lustre): 2TB/sec - 10PB
• Object storage: 100GB/sec - 100+PB
32SOFTWARE OPERATIONS
33SCALE TO MULTIPLE NODES
Software Stack - Application
• Deep Learning Model:
• Hyperparameters tuned for multi-node scaling
• Multi-node launcher scripts
• Deep Learning Container:
• Optimized TensorFlow, GPU libraries, and multi-node
software
• Host:
• Host OS, GPU driver, IB driver, container runtime engine
(docker, enroot)
34SCALE TO MULTIPLE NODES
Software Stack - System
• Slurm: User job scheduling & management
• Enroot: NVIDIA open-source tool to convert traditional container/OS images into unprivileged sandboxes
• Pyxis: NVIDIA open-source plugin integrating Enroot with Slurm
• DeepOps: NVIDIA open-source toolbox for GPU cluster management w/Ansible playbooks
NGC model containers (Pytorch, Tensorflow from 19.09)
Slurm controller Pyxis Enroot | Docker DCGM
Login nodes DGX Pod: DGX Servers w. DGX base OS
35INTEGRATING CLUSTERS IN
THE DEVELOPMENT WORKFLOW
Supercomputer-scale CI (Continuous integration internal at NVIDIA)
• Integrating DL-friendly tools like GitLab, Docker w/ HPC
systems
Kick off 10000’s of GPU hours of tests with a single
button click in GitLab
… build and package with Docker
… schedule and prioritize with SLURM
… on demand or on a schedule
… reporting via GitLab, ELK stack, Slack, email
Emphasis on keeping things simple for users while
hiding integration complexity
Ensure reproducibility and rapid triage
36LINKS
37RESOURCES
Presentations
GTC Sessions (https://www.nvidia.com/en-us/gtc/session-catalog/) :
Under the Hood of the new DGX A100 System Architecture [S21884]
Inside the NVIDIA Ampere Architecture [S21730]
CUDA New Features And Beyond [S21760]
Inside the NVIDIA HPC SDK: the Compilers, Libraries and Tools for Accelerated Computing [S21766]
Introducing NVIDIA DGX A100: the Universal AI System for Enterprise [S21702]
Mixed-Precision Training of Neural Networks [S22082]
Tensor Core Performance on NVIDIA GPUs: The Ultimate Guide [S21929]
Developing CUDA kernels to push Tensor Cores to the Absolute Limit on NVIDIA A100 [S21745]
HotChips:
Hot Chips Tutorial - Scale Out Training Experiences – Megatron Language Model
Hot Chips Session - NVIDIA’s A100 GPU: Performance and Innovation for GPU Computing
Pyxis/Enroot https://fosdem.org/2020/schedule/event/containers_hpc_unprivileged/
38RESOURCES
Links and other doc
DGX A100 Page https://www.nvidia.com/en-us/data-center/dgx-a100/
Blogs
DGX SuperPOD https://blogs.nvidia.com/blog/2020/05/14/dgx-superpod-a100/
DDN Blog for DGX A100 Storage https://www.ddn.com/press-releases/ddn-a3i-nvidia-dgx-a100/
Kitchen Keynote summary https://blogs.nvidia.com/blog/2020/05/14/gtc-2020-keynote/
Double Precision Tensor Cores https://blogs.nvidia.com/blog/2020/05/14/double-precision-tensor-cores/
39You can also read

















































