Methodology for identifying homogeneous consumer groups based on qualitative data
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

IOP Conference Series: Earth and Environmental Science
PAPER • OPEN ACCESS
Methodology for identifying homogeneous consumer groups based on
qualitative data
To cite this article: G S Gabidinova 2021 IOP Conf. Ser.: Earth Environ. Sci. 677 022012
View the article online for updates and enhancements.
This content was downloaded from IP address 46.4.80.155 on 28/09/2021 at 16:00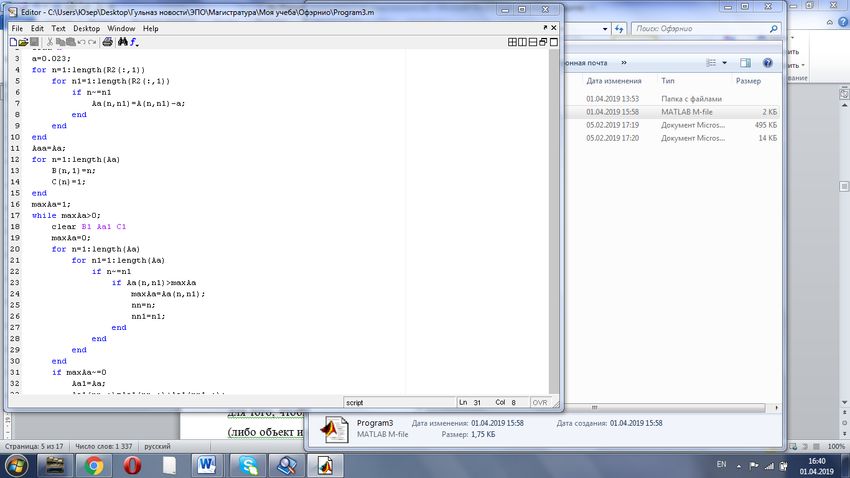
AGRITECH-IV-2020 IOP Publishing
IOP Conf. Series: Earth and Environmental Science 677 (2021) 022012 doi:10.1088/1755-1315/677/2/022012
Methodology for identifying homogeneous consumer groups
based on qualitative data
G S Gabidinova
Naberezhnye Chelny Institute (branch) of Kazan Federal University, 68/19, Mira
prospect, Naberezhnye Chelny, Republic of Tatarstan, 423812, Russia
E-mail: gab-gul@yandex.ru
Abstract. In this article, the author proposes a method for identifying homogeneous consumer
groups based on qualitative data. The problem is that when researching the end-user market,
information is often presented not in quantitative but in qualitative form. The random variables
with which mathematical statistics deal are usually assumed to be numeric. Therefore, among
researchers there is an opinion that achieving at least an interval level of measurement is always
desirable, since it expands the researcher capabilities, giving him grounds to use data
mathematical and statistical analysis traditional methods. Sociologists, on the other hand,
emphasize the qualitative data enormous role in the respondents' study. The presented
methodology is based on cluster analysis, differs from the applied market segmentation methods
in that it uses cluster analysis algorithms developed concerning qualitative indicators, and
involves a proximity measure use that allows one to determine the natural weights between
clustering variables. Also, the technique provides for the optimal partition determination based
on the changes' graph in the average internal communication, depending on the selected clusters'
number. The optimal among the partitions set is considered to be a partition in which the average
internal connection increases sharply in comparison with the previous partition. Provided that
the clusters' number in each subsequent partition in comparison with the previous one is greater
by one. Thus, the methodology allows identifying the existing market structure.
1. Introduction
Our task was to segment the smoked sausages market in Naberezhnye Chelny (Tatarstan).
Based on the secondary data analysis results, it was found that the smoked sausages consumers
behaviour is influenced by many factors, namely cultural, socio-economic, personal, psychological, and
organizational.
To take into account these factors, the following market segmentation variables were selected: age,
gender, occupation, education level, nationality, marital status, income level, the reason for making a
purchase, consumption intensity, brand loyalty degree, the purchased product description, the purchased
product price, goods purchase place, consumer status.
When choosing the most suitable method, we considered many market segmentation methods: one-
parameter method, segmentation grid, AID method, methods with a multi-stage approach (Hayley
Russell model, Peter Dixon model), a priori method, flexible segmentation, component-wise
segmentation, cluster method, self-organizing Kohonen maps.
To carry out market segmentation, we have chosen a cluster analysis algorithm that allows us to find
natural market segments based on a variables' variety measured in qualitative scales.
Content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution
of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
Published under licence by IOP Publishing Ltd 1AGRITECH-IV-2020 IOP Publishing
IOP Conf. Series: Earth and Environmental Science 677 (2021) 022012 doi:10.1088/1755-1315/677/2/022012
2. Methodology
The method proposed by the authors assumes cluster analysis using the Mirkin proximity measure. This
proximity measure belongs to the associativity coefficients category. In addition to associativity
coefficients, correlation coefficients, distance measures and probabilistic similarity coefficients are also
distinguished.
Mirkin's proximity measure differs from other coefficients in that it is obtained not simply as a
meaningful explanation, but as a classification process, certain theoretical premises result as a whole [4,
5]. Determined by the formula:
m
kij = pijl , (1)
l =1
1/ nl , if xl (i) = xl ( j ) = s,
where pijl = s l
0, if x (i) x ( j ),
l
n sl - the objects' number for which l-th characteristic took the value s.
This indicator value depends on two factors:
• the matching answers number from respondents;
• the respondents' number who chose the same answer option.
The more coinciding answers the two surveyed respondents have, and the fewer the respondents who
chose similar answers, the greater proximity' measure value between them.
To identify consumers, homogeneous groups, we have chosen Mirkin algorithm "unification" [5].
When choosing this cluster analysis algorithm, we proceeded from the fact that:
• the population volume subjected to clustering is more than 1,000 objects;
• each object is described by many features (more than three);
• the clusters' number is to be determined;
• there is no a cluster formal definition;
• the objects' number in a cluster can be any;
• it is required to determine the clusters, ideal representatives;
• clustering criterion is not specified.
The "unification" algorithm is one of the hierarchical algorithms a group agglomerative algorithms.
In addition to hierarchical algorithms, there are also iterative algorithms, algorithms such as matrix
ordering, algorithms such as cutting a graph.
The unification algorithm starts with a trivial partition, i.e. partitioning in which each object is
considered as a separate cluster. When implementing this algorithm, we maximize the partition
following quality index:
z
F ( R, a ) = (k ij − a) , (2)
c =1 i , jRc
where R - is the original partition;
kij - coefficient defining the objects' proximity measure i and j;
c - cluster number;
z - clusters number;
Rc - objects included set in c-th cluster;
a - threshold, i.e. the number with which the objects' proximity measure is compared to determine
whether the considered two objects (either an object and a cluster, or two clusters) can be attributed to
one common cluster.
2AGRITECH-IV-2020 IOP Publishing
IOP Conf. Series: Earth and Environmental Science 677 (2021) 022012 doi:10.1088/1755-1315/677/2/022012
This indicator expresses the total internal communication in the breakdown R taking into account the
threshold a. We propose to select the threshold value so that the selected homogeneous groups' number
varies from 2 to 10.
Then we carry out the following steps:
• We build the communication matrix A = a , where a
ij ij = kij − a, aii = 0 .
• Find the matrix maximum positive element a = max aij . Therefore, we combine the classes Rα
and Rβ.
• We summarize the rows and columns with numbers α and β.
• Repeat steps 2-3 until the matrix all elements, except for the diagonal ones, are negative.
• Having performed the last union, we obtain the final partition, which is optimal.
To check the partition quality, the so-called the partition quality indicator concept, defined on the all
possible partitions set, is often introduced into the cluster analysis problem statement. Then the best
partition is understood as the partition on which the selected quality indicator extremum is achieved.
We propose to take [4,5] an average internal link in the original partition as a criterion for the partition
quality:
1 z 1
= kij ;
z c=1 nc (nc − 1) i , jRc , i j
(3)
This indicator is determined for each partition. The change in the average internal connection value
depending on the selected segments number is presented in a graph form. We find the partition at which
the average internal communication indicator value increases sharply in comparison with others. This
will be the desired optimal partition.
3. Results
The smoked sausages market was segmented in the city of Naberezhnye Chelny (Tatarstan), namely the
smoked sausages end consumers totality, including real and potential consumers.
For this, a structured questionnaire was drawn up. The questions were arranged in a specific order.
Answer options were offered for most of the questions. The respondents, depending on the question
specifics, were allowed to choose one or several answer options.
All variables, except for the variable "age", are measured in qualitative scales, namely in nominal,
dichotomous and ordinal scales. When processing the data, the variable "age" values were also
transferred to an ordinal scale by determining the age intervals.
After the survey, the selected data was encoded. The coding was performed as follows. A matrix of
X was compiled, where each question was assigned as many columns as required to display all possible
answers that carry useful information. Those options such as “don't know” or “doesn't matter” were not
considered. This coding was chosen because there were questions to which it was allowed to choose
several answers.
Thus, all personal data were brought together in a single matrix consisting of Boolean columns, i.e.
columns with "zero" and "one" values:
X = xil , (4)
where i is the respondent's number;
l - feature number.
For the first ten objects, the matrix part looks like this:
3AGRITECH-IV-2020 IOP Publishing
IOP Conf. Series: Earth and Environmental Science 677 (2021) 022012 doi:10.1088/1755-1315/677/2/022012
Table 1. Matrix part.
1
i
1 2 3 4 5 6 7 8 9 10 11 12 13 14
1 0 0 1 0 0 0 1 0 0 0 0 0 1 0
2 0 1 0 0 0 0 0 1 0 0 0 0 1 0
3 0 0 1 0 0 0 1 0 0 0 0 0 1 0
4 0 1 0 0 0 0 0 1 0 0 0 0 1 0
5 0 0 1 0 0 0 0 1 0 0 0 0 1 0
6 0 1 0 0 0 0 0 0 0 0 0 0 1 0
7 0 0 1 0 0 0 0 1 0 0 0 1 0 0
8 0 0 1 0 0 0 1 0 0 0 0 0 1 0
9 0 0 0 1 0 0 0 1 0 0 0 0 1 0
10 0 0 1 0 0 0 0 1 0 0 0 0 0 1
… … … … … … … … … … … … … … …
nl 208 473 634 169 26 21 533 512 62 10 8 205 736 143
Further, homogeneous consumer groups were identified. When using the cluster analysis algorithm
chosen by the author, the Mirkin proximity measure is applied, which is determined by formula 1.
Because the research objects number is more than a thousand and the calculations' volume is so large
that it is almost impossible to calculate everything manually, a program was developed in the MATLAB
system (figure 1) with which help all the calculations for this research were made.
Figure 1. Program in MATLAB system.
4AGRITECH-IV-2020 IOP Publishing
IOP Conf. Series: Earth and Environmental Science 677 (2021) 022012 doi:10.1088/1755-1315/677/2/022012
We calculate the proximity measure between two different objects. As a result, we get the matrix
K = kij :
Table 2. Matrix K = kij .
i j
1 2 3 4 5 6 7 8 9 10 …
1 0 0.020 0.020 0.015 0.022 0.025 0.022 0.040 0.020 0.012 …
2 0.020 0 0.011 0.014 0.023 0.027 0.019 0.027 0.017 0.013 …
3 0.020 0.011 0 0.006 0.029 0.013 0.013 0.015 0.011 0.014 …
4 0.015 0.014 0.006 0 0.010 0.017 0.015 0.018 0.020 0.023 …
5 0.022 0.023 0.029 0.010 0 0.028 0.019 0.017 0.012 0.020 …
6 0.025 0.027 0.013 0.017 0.028 0 0.022 0.019 0.018 0.036 …
7 0.022 0.019 0.013 0.015 0.019 0.022 0 0.019 0.031 0.021 …
8 0.040 0.027 0.015 0.018 0.017 0.019 0.019 0 0.024 0.012 …
9 0.020 0.017 0.011 0.020 0.012 0.018 0.031 0.024 0 0.016 …
10 0.012 0.013 0.014 0.023 0.020 0.036 0.021 0.012 0.016 0 …
… … … … … … … … … … … …
This "unification" algorithm starts with a trivial partition, i.e. partitions, where each object represents
a separate class. We build a communication matrix A = aij between classes. For a trivial partition,
aij = kij − a Therefore, for a = 0,023 we have:
Table 3. Matrix a = 0,023 .
t 1 2 3 4 5 6 7 8 9 10 …
= 3R4 = 4R5 = 5R6 = 6R7 = 7R8 = 8R9 = 9R10 = 10
c
R1 = 1 R2 = 2R3 …
1 R1 0 -0.003 -0.003 -0.008 -0.001 0.002 -0.001 0.017 -0.003 -0.011 …
2 R2 -0.003 0 -0.012 -0.009 0.000 0.004 -0.004 0.004 -0.006 -0.010 …
3 R3 -0.003 -0.012 0 -0.017 0.006 -0.010 -0.010 -0.008 -0.012 -0.009 …
4 R4 -0.008 -0.009 -0.017 0 -0.013 -0.006 -0.008 -0.005 -0.003 0.000 …
5 R5 -0.001 0.000 0.006 -0.013 0 0.005 -0.004 -0.006 -0.011 -0.003 …
6 R6 0.002 0.004 -0.010 -0.006 0.005 0 -0.001 -0.004 -0.005 0.013 …
7 R7 -0.001 -0.004 -0.010 -0.008 -0.004 -0.001 0 -0.004 0.008 -0.002 …
8 R8 0.017 0.004 -0.008 -0.005 -0.006 -0.004 -0.004 0 0.001 -0.011 …
9 R9 -0.003 -0.006 -0.012 -0.003 -0.011 -0.005 0.008 0.001 0 -0.007 …
10 R10 -0.011 -0.010 -0.009 0.000 -0.003 0.013 -0.002 -0.011 -0.007 0 …
… … … … … … … … … … … … …
With a given matrix A, select the maximum value act , i.e max act . In our matrix
max act = a18 = 0,017 , as you can see, the matrix maximum element is positive, therefore, we combine
objects 1 and 8 into one class. To do this, we summarize rows with numbers 1 and 8, as well as columns
1 and 8, we get a new matrix A:
Table 4. Matrix A.
t 1 2 3 4 5 6 7 8 9 …
= 3R4 = 4R5 = 5R6 = 6R7 = 7R8 = 9 R9 = 10
c
R1 = 1,8 R2 = 2R3 …
1 R1 0.034 0.001 -0.011 -0.013 -0.007 -0.002 -0.005 -0.002 -0.022 …
2 R2 0.001 0 -0.012 -0.009 0.000 0.004 -0.004 -0.006 -0.010 …
5AGRITECH-IV-2020 IOP Publishing
IOP Conf. Series: Earth and Environmental Science 677 (2021) 022012 doi:10.1088/1755-1315/677/2/022012
3 R3 -0.011 -0.012 0 -0.017 0.006 -0.010 -0.010 -0.012 -0.009 …
4 R4 -0.013 -0.009 -0.017 0 -0.013 -0.006 -0.008 -0.003 0.000 …
5 R5 -0.007 0.000 0.006 -0.013 0 0.005 -0.004 -0.011 -0.003 …
6 R6 -0.002 0.004 -0.010 -0.006 0.005 0 -0.001 -0.005 0.013 …
7 R7 -0.005 -0.004 -0.010 -0.008 -0.004 -0.001 0 0.008 -0.002 …
8 R8 -0.002 -0.006 -0.012 -0.003 -0.011 -0.005 0.008 0 -0.007 …
9 R9 -0.022 -0.010 -0.009 0.000 -0.003 0.013 -0.002 -0.007 0 …
… … … … … … … … … … … …
Let us find the maximum positive element of the new matrix A max act = a69 = 0,013 . Therefore,
we combine classes 6 and 9 into one group. We continue the calculations until all a ct ( c t ) are
negative. The matrix and gives the summary links between the classes, and the classes themselves are
determined by the summing operations sequence.
Such clustering was carried out at different values of the threshold value a, and partitions were
obtained where the clusters' number varied from 2 to 10. For each split, the average internal link was
determined using formula 3.
The change in the average internal connection depending on the selected clusters' number is shown
in the graph (figure 2).
As you can see from the graph, the average internal connection has increased sharply compared to
the previous one when the objects were divided into seven clusters. This is the desired optimal partition.
As a research clustering 1,534 objects result, this algorithm identified seven natural clusters: cluster
1, which includes 149 objects; cluster 2, including 226 objects; cluster 3, including 285 objects; cluster
4, including 343 objects; cluster 5, including 195 objects; cluster 6, including 200 objects; cluster 7,
including 136 objects.
0,04
Average internal connection in the
0,03
0,02
partition
0,01
0
1 2 3 4 5 6 7 8 9 10 11
Сlusters' number in the partition
Figure 2. Graph of changes in the average internal connection depending on the
allocated clusters' number.
4. Discussion
Based on the obtained segments each analysis results, it was concluded that the market segmentation
was successful. The following market segments were identified:
• Ritualists. Men and women over 25, family, with an average income level. They consume
traditional semi-smoked pork and beef sausages in natural packaging, they have established
tastes. Consume on average at least once a week. They are purchased mainly in the
manufacturer's branded kiosks and the markets.
6AGRITECH-IV-2020 IOP Publishing
IOP Conf. Series: Earth and Environmental Science 677 (2021) 022012 doi:10.1088/1755-1315/677/2/022012
• Pensioners. Elderly people with low income. They consume inexpensive semi-smoked and
boiled-smoked pork and beef sausages on average once or twice a month. Buy for the holiday
and when there is money. They are purchased mainly in markets and nearby stores.
• Amateurs. All ages people, with middle and high-income levels. Consumed often, almost every
day. They give preference to quality products. There is no attachment to smoked sausages any
type, they are ready to try new non-traditional varieties. The price doesn't matter. They prefer
to buy in supermarkets.
• Young people. Non-family people are usually young. Not often consumed two to three times a
month. They have no pronounced preferences. They buy spontaneously usually the highest
grade semi-smoked sausages, as a rule, in supermarkets, nearby stores, and branded kiosks.
• Forced consumers. Working townspeople with lower middle income, mostly women. They
are rarely consumed, once or twice a month. When there is a quick snack need at work, on the
road or at home. Preference is given to semi-smoked sausages made from pork.
• Elite consumers. Citizens over 35 years old, family, with a high level of income. Consume high
quality proven products, at least once a week. Preference is given to semi-smoked, boiled-
smoked and uncooked smoked sausages. Buy in supermarkets and brand kiosks.
• Muslims. People adhering to Muslim traditions. Consumed very rarely or not consumed at all.
We are ready to consume more often, provided that smoked sausages are made according to
Muslim traditions and sold in specialized Muslim stores. They prefer semi-smoked and cooked-
smoked beef and horse meat sausages without lard in natural packaging.
For each of these segments, it is necessary to develop its marketing complex. With the successful
development of a marketing mix for each of the selected segments, the company can increase sales and
strengthen its position within each market segment.
5. Conclusion
Thus, to conduct market segmentation, we have developed a cluster analysis method, which allows
conducting research based on many variables; consider variables as equivalent, without requiring a
relations hierarchy establishment between them; proceed from the fact that the market structure is
unknown, and we cannot set the potential consumers' profiles in advance; find natural market segments
based on a variety of variables measured on qualitative scales.
References
[1] Istomin P O 2016 Market segmentation Modern science theory and practice 6-1(12) 533
[2] Karasev A P 2014 Consumer markets segmentation (Yaroslavl, Russia: Avers Plus)
[3] Kutserubov A E 2017 Modern approaches to market segmentation Proc. Sayapin readings. The
round table materials collection (Tambov, Russia: Tambov State University) p 165
[4] Mandel I D 1988 Cluster analysis (Мoscow, Russia: Finance and Statistics)
[5] Mirkin B G 1980 Qualitative features and structures analysis (Мoscow, USSR: Finance and
Statistics)
[6] Rolbina E S 2013 The consumer market preliminary segmentation VEPS 1 93
7You can also read

















































