PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
PLATO: Pre-trained Dialogue Generation Model with
Discrete Latent Variable
Siqi Bao ∗, Huang He ∗, Fan Wang and Hua Wu
Baidu Inc., China
{baosiqi, hehuang, wangfan04, wu hua}@baidu.com
Abstract This pre-training and fine-tuning paradigm also
Pre-training models have been proved effec- sheds interesting light on the tasks of natural lan-
tive for a wide range of natural language guage generation, like dialogue generation. How-
arXiv:1910.07931v1 [cs.CL] 17 Oct 2019
processing tasks. Inspired by this, we pro- ever, previous study demonstrates that there are
pose a novel dialogue generation pre-training some deficiencies on the performance to apply di-
framework to support various kinds of con- rect fine-tuning of BERT on small conversation
versations, including chit-chat, knowledge datasets (Rashkin et al., 2019; Wolf et al., 2019),
grounded dialogues, and conversational ques-
where possible reasons might be three-fold: 1)
tion answering. In this framework, we adopt
flexible attention mechanisms to fully lever- the underlying linguistic patterns in human con-
age the bi-directional context and the uni- versations can be highly different from those in
directional characteristic of language genera- general text, resulting in a large gap of knowl-
tion. We also introduce discrete latent vari- edge or data distributions; 2) the training mode
ables to tackle with the natural born one-to- of uni-directional dialogue generation is also dis-
many mapping problem in response genera- tinct with that of bi-directional natural language
tion. Two reciprocal tasks of response gener- understating as applied in BERT; 3) unlike most of
ation and latent act recognition are designed
the general NLP tasks, there is a one-to-many re-
and carried out simultaneously within a shared
network. Comprehensive experiments on three lationship existing in dialogue generation, where
publicly available datasets verify the effective- a piece of context often has multiple appropriate
ness and superiority of the proposed frame- replies.
work. In this paper, we propose a new method to
1 Introduction tackle the above challenges, aiming to obtain a
high-quality pre-training model for dialogue gen-
Dialogue generation is a challenging task due to eration. First of all, to reduce the gap between data
the limited corpus of human conversations, com- distributions, large-scale Reddit and Twitter con-
plex background knowledge, and diverse relation- versations are further utilized to pre-train the gen-
ships between utterances. Recently, pre-trained eration model (upon the basis of language models
large-scale language models, such as BERT (De- pre-trained with general text). Secondly, to mit-
vlin et al., 2019) and XL-Net (Yang et al., 2019), igate the difference of training modes, a flexible
have achieved prominent success in natural lan- paradigm integrating uni- and bi-directional pro-
guage processing. Such models are usually con- cessing is employed in this work, which is inspired
structed based on a massive scale of general text by the latest unified language modeling (Dong
corpora, like English Wikipedia or BooksCorpus et al., 2019). Thirdly, a discrete latent variable is
(Zhu et al., 2015), where distributed representa- introduced to model the one-to-many relationship
tions can be learned automatically from the raw among utterances in conversations.
text. By further fine-tuning these representations, Each value of the latent variable corresponds
breakthroughs have been continuously reported to the particular conversational intent of one re-
for various downstream tasks, especially those of sponse, denoted as latent speech act. Distinct with
natural language understanding, such as question those controllable dialogue generation based on
answering, natural language inference and so on. explicit labels (including emotion, keywords, do-
∗
Equal contribution. main codes and so on) (Huang et al., 2018; Keskar$()|", #) $()|", #)
" exempted!
et al., 2019), our latent variable gets " !
from the restriction of human annotations and can
be learned automatically from the corpus in an un-
supervised way. To pre-train the$(#|", !) #for dia-
model $(#|", !) #
logue generation, two tasks are introduced in this
work – response generation and latent act recog- Figure 1: Graphical illustration of response genera-
nition. Both tasks are carried out simultaneously tion (gray lines) and latent act recognition (dashed blue
under the unified network architecture with shared lines).
parameters. Conditioned on the context and la-
tent variable, the generation task tries to maxi- • The response r is one piece of appropriate reply
mize the likelihood of the target response. At the towards the given context.
same time, the recognition task aims to estimate • The latent variable z is one K-way categori-
the latent variable w.r.t. given context and target cal variable z ∈ [1, K], with each value cor-
response. Apparently, the accurate estimation of responds to a particular latent speech act in the
latent variable is a key factor to boost the quality response.
of response generation. The probabilistic relationships among these ele-
We conducted experiments on three different ments are elaborated as follows (graphical illustra-
kinds of conversation tasks: chit-chat, knowledge tion shown in Figure 1). Given a context c, there
grounded conversation, and conversational ques- are multiple appropriate speech acts for replies
tion answering. Experimental results verify the (represented by the latent variable z). Condi-
effectiveness and superiority of our pre-trained tioned on the context and one chosen latent speech
model as compared with the other state-of-the-art act, the response is produced as p(r|c, z) (gray
methods. Our pre-trained models and source code lines). Given a pair of context and response, the
have been released at GitHub, hoping to facilitate latent speech act behind them can be estimated as
further research progress in dialogue generation.1 p(z|c, r) (dashed blue lines). As such, our pre-
training of dialogue generation contains the fol-
2 Dialogue Generation Pre-training lowing two tasks – response generation and la-
Given a piece of context, there exist multiple ap- tent act recognition.
propriate responses, leading to diverse conversa- We propose a unified infrastructure for the
tion flows. It is widely recognized that the capa- joint learning of both tasks, shown as Figure 2.
bility of modeling one-to-many relationship is cru- The backbone of our infrastructure is inspired by
cial for dialogue generation system (Zhao et al., the transformer blocks in (Dong et al., 2019),
2017; Chen et al., 2019). To this end, we pro- which supports both bi-directional encoding and
pose to encode discrete latent variables into trans- uni-directional decoding flexibly via specific self-
former blocks for one-to-many relationship mod- attention masks. Both two tasks of response gen-
eling, where two reciprocal tasks of response gen- eration and latent act recognition are carried out
eration and latent act recognition are collabora- under the unified network with shared parameters.
tively carried out. Their detailed implementations are discussed as
follows.
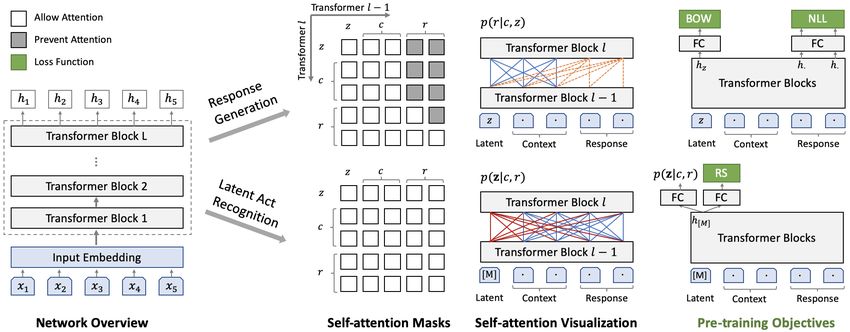
2.1 Model Architecture Given the context c and a specific speech act z,
the response generation can be estimated as
In our model, there are the following three ele-
ments: dialogue context c, response r and latent p(r|c, z) = ΠTt=1 p(rt |c, z, rFigure 2: Architecture of dialogue generation with discrete latent variable.
Latent Context Response
Input [!] do you have a pet ? [EOS] i have a cute dog . [EOS] [BOS] that is great . [EOS]
Token E[!] Edo Eyou Ehave Ea Epet E? E[EOS] Ei Ehave Ea Ecute Edog E. E[EOS] E[BOS] Ethat Eis Egreat E. E[EOS]
Embeddings
Role EA EA EA EA EA EA EA EB EB EB EB EB EB EB EA EA EA EA EA EA
Embeddings
Turn E[-2] E[-2] E[-2] E[-2] E[-2] E[-2] E[-2] E[-1] E[-1] E[-1] E[-1] E[-1] E[-1] E[-1] E[0] E[0] E[0] E[0] E[0] E[0]
Embeddings
Position E0 E1 E2 E3 E4 E5 E6 E0 E1 E2 E3 E4 E5 E6 E0 E1 E2 E3 E4 E5
Embeddings
Figure 3: Input representation. The input embedding is the sum of corresponding token, role, turn and position
embeddings.
context and target response in the training data. • The input is the concatenation of latent vari-
The latent act recognition shares network param- able, dialogue context and response. A special
eters with response generation, but has separate end-of-sentence [EOS] token is appended to the
self-attention masks for bi-directional encoding. end of each utterance for separation. Another
As shown in Figure 2, with a special mask sym- begin-of-sentence [BOS] token is added at the
bol [M] as input, it keeps collecting information beginning of the response, whose final hidden
from the context and target response (red lines). In state (i.e., output of the last transformer block)
this way, the corresponding speech act for the tar- is used to predict next token during generation.
get response can be recognized as z ∼ p(z|c, r), • Given that z is one K-way categorical variable,
where p(z|c, r) is the estimated posterior distribu- its token embedding E[z] is mapped from the la-
tion over discrete latent values. tent embedding space Ez ∈ RK×D . For the rest
tokens in the vocabulary, they are warmed up
2.2 Input Representation using BERT’s WordPiece embeddings.
For multi-turn conversation modeling, elaborate • Role embeddings are employed to differentiate
designs have been made on the input represen- the characters evolved in the conversation. The
tation in this work. The network input includes role embedding EA is added for the response,
the latent variable, dialogue context and response. as well as dialogue utterances generated by the
Following the pre-processing of BERT (Devlin same character in the context. And role embed-
et al., 2019), the input text is tokenized with Word- ding EB is used for the other character. (For
Piece (Wu et al., 2016). For each token, its in- knowledge grounded conversation, EC is used
put embedding is the sum of corresponding token, as the role embedding of background knowl-
role, turn and position embeddings. One visual edge.)
example is shown in Figure 3 and details of the • In the interactive conversation, there are multi-
embeddings are described as follows:turn utterances and we employ relative order in variables:
the assignment of turn embeddings. The turn
T
embedding for the response is set to E[0] , and X
LBOW = −Ez∼p(z|c,r) log p(rt |c, z)
the turn embedding of its last utterance is E[−1] ,
t=1
and etc. Our utilization of relative turn embed- (4)
T
dings instead of absolute ones enables the model
X efrt
= −Ez∼p(z|c,r) log P
to assign turn embedding E[0] to the response v∈V efv
t=1
consistently and helps response generation ex-
empt from the disturbance of its round number where V refers to the whole vocabulary and f is a
within the dialogue. function that tries to predict the words within the
• Position embeddings are added according to the target response in a non-autoregressive way:
token position in each utterance. Note that for
the special token of latent variable, its corre- f = softmax(W2 hz + b2 ) ∈ R|V | (5)
sponding role, turn and position embeddings are
all set to empty. where hz is the final hidden state of the latent vari-
able and |V | is the vocabulary size. frt denotes
2.3 Pre-training Objectives the estimated probability of word rt . As compared
with NLL loss, the BOW loss discards the order of
We design three kinds of loss functions for di- words and forces the latent variable to capture the
alogue generation pre-training : negative log- global information of the target response.
likelihood (NLL) loss, bag-of-words (BOW) loss
and response selection (RS) loss. Brief illustration 2.3.2 Response Selection
is shown in the last column of Figure 2 and de- Response selection helps distinguish whether the
tailed descriptions will be provided in this section. response is relevant with the dialogue context and
consistent with the background knowledge. Mean-
2.3.1 Response Generation while, its score can be regarded as an indicator of
coherence during dialogue generation, helping to
In our model, the response is generated condi- select the most coherent one from multiple candi-
tioned on the latent variable and the context. The date responses.
widely adopted NLL loss is employed in the pre- Particularly, the training of response selection is
training: carried out together with the bi-directional encod-
ing network of latent act recognition. The positive
LN LL = −Ez∼p(z|c,r) log p(r|c, z) training samples come from the dialogue context
T
X and corresponding target response (c, r), with la-
= −Ez∼p(z|c,r) log p(rt |c, z, r2.4 Pre-training Procedure 2) Response Selection
Our pre-training model contains 12 transformer – Calculate the probability for each response
blocks, with its network parameters initialized us- p(lr = 1|c, r) and select the one with highest
ing BERTBASE . Large-scale conversation datasets value as the final response
– Twitter (Cho et al., 2014) and Reddit (Zhou It is worth to note that the above fine-tuning and
et al., 2018; Galley et al., 2019) are employed for inference procedures are set up for the dialogue
pre-training, which result in 8.3 million training generation without any specific objectives. If there
samples in total. For each training sample of con- exists a specific objective within the conversation,
text and target response (c, r), it needs to pass such as letting both participants know more about
through the network twice to accomplish the tasks each other (Bao et al., 2019), the fine-tuning can
of latent act recognition and response generation. proceed to maximize the pre-defined rewards with
And the pre-training steps are summarized as fol- reinforcement learning (RL). Under such circum-
lows: stances, our latent discrete variable can be natu-
1) Latent Act Recognition rally treated as action within RL, and thus the re-
– Given a pair of context and target response, sponse selection can be straightforwardly solved
estimate the posterior distribution p(z|c, r) by selecting the action that results in the maximum
– Randomly select r− and calculate LRS reward.
2) Response Generation
3 Experiments
– With the sampled latent value z ∼ p(z|c, r),
calculate LN LL and LBOW 3.1 Settings
3) Optimization 3.1.1 Datasets
– Sum up to obtain L, and update network pa-
To evaluate the performance of our proposed
rameters with back-propagation
method, comprehensive experiments have been
The hyper-parameters used in pre-training are
carried out on three publicly available datasets.
listed as follows. The maximum sequence length
• Persona-Chat (Zhang et al., 2018) provides both
of context and response is set to 256 and 50, re-
manually annotated conversations and corre-
spectively. The number of transformer blocks in
sponding persona profiles (background knowl-
our model L is 12 and the hidden embedding di-
edge), where two participants chat naturally and
mension D is 768. The batch size is set to 64
try to get to know each other.
and K is set to 20 for the discrete latent vari-
• Daily Dialog (Li et al., 2017) is a chit-chat
able. Adam optimizer (Kingma and Ba, 2015)
dataset, which contains high-quality human
is employed for optimization with a learning rate
conversations about daily life.
of 5e-5. The pre-training of dialogue generation
• DSTC7-AVSD (Alamri et al., 2019), short
was carried out on 8 Nvidia Telsa V100 32G GPU
for Audio Visual Scene-aware Dialog of the
cards for 3.5M steps, taking approximately two
DSTC7 challenge, is a conversational question
weeks to reach convergence.
answering dataset. In DSTC7-AVSD, the sys-
2.5 Fine-tuning and Inference tem need to generate an answer given dialogue
context and background knowledge. There are
Our pre-trained model is flexible enough to sup- two available options of knowledge utilization:
port various kinds of dialogues, including chit- 1) using single-modal information of text only,
chat, knowledge grounded conversations, conver- including video’s caption and summary; 2) rely-
sational question answering and so on. The fine- ing on multi-modal information, including text,
tuning on small conversation datasets can be car- audio and visual features. The single-modal op-
ried out following the training objectives defined tion is adopted by our method in the experi-
in Equation (8). As the fine-tuning process reaches ments.
convergence, the response towards the given con- The descriptions and statistics of these datasets are
text can be obtained through the following infer- summarized in Table 1.
ence procedure:
1) Candidate Response Generation 3.1.2 Compared Methods
– Conditioned on each latent value z ∈ [1, K], The following models have been compared in the
generate corresponding candidate response r experiments.Baseline. Sequence to sequence with attention where WG and WK refers to the set of non-
(Seq2Seq) (Vinyals and Le, 2015) is employed as stop words in the generated responses and back-
the baseline for the experiments on Persona-Chat ground knowledge respectively.
and Daily Dialog. DSTC7-AVSD has provided a • In DSTC7-AVSD, the MSCOCO platform
baseline system, which is built upon hierarchical (Chen et al., 2015) is employed for evaluation.
recurrent encoders with multi-modal features. It compares the generated response with six
State of the art. The Persona-Chat dataset is ground truth responses, using metrics of BLEU,
also utilized in the ConvAI2 challenge (Dinan METEOR, ROUGH-L and CIDEr.
et al., 2019a), where the team of Lost in Con- In human evaluation, we randomly select 100
versation (LIC) (Golovanov et al., 2019) obtains dialogue contexts and generate responses with
the best performance. LIC is also one transformer compared methods. Three crowd-sourcing work-
based generation method and fine-tuned upon the ers are asked to score the response quality on a
pre-trained model of GPT (Radford et al., 2018). scale of [0, 1, 2] from four aspects – fluency, co-
For the dataset of Daily Dialog, its best results herence, informativeness and overall. The higher
are reported by the recently developed method – score, the better. Details about the criteria are
iVAEMI (Fang et al., 2019), which generates di- given as follows.
verse responses with sample-based latent repre- • Fluency measures whether the generated sen-
sentation. In DSTC7-AVSD, the team of CMU tence is smooth and grammatically correct.
(Sanabria et al., 2019) obtains the best perfor- • Coherence evaluates whether the generated re-
mance across all the evaluation metrics. sponse is relevant with the context and consis-
Our method. To better analyze the effects of la- tent with the expressed information or back-
tent discrete variable in our method, we also com- ground knowledge.
pare to the version without latent variable (Our • Informativeness assesses the information con-
w/o Latent), under the same training settings.1 tained in the generated response.
• Overall represents the general evaluation, where
3.1.3 Evaluation Metrics 0 indicates a bad response, 1 corresponds to a
Both automatic and human evaluations are em- normal response and 2 stands for a good re-
ployed to assess the performance of compared sponse.
methods. In automatic evaluation, the following After collecting the assessments from three crowd-
metrics are included: sourcing workers, the response’s final score is de-
• BLEU (Chen and Cherry, 2014) measures the termined via majority voting. The average Fleiss’s
n-gram overlap between generated response and kappa (Fleiss and Cohen, 1973) on Persona-Chat
the target response. and Daily Dialog is 0.515 and 0.480 respec-
• Distinct-1/2 (Li et al., 2016) measures the gen- tively, indicating annotators have reached moder-
eration diversity, which is defined as the number ate agreement.
of distinct uni- or bi-grams divided by the total
amount of generated words. 3.2 Experimental Results
• Knowledge R/P/F1 (Dinan et al., 2019b) mea-
sures the degree of informativeness w.r.t. back- The experimental results on Persona-Chat and
ground knowledge, defined as: Daily Dialog with automatic and human evalua-
tions are summarized in Table 2. During auto-
|WG ∩ WK | matic evaluation, BLEU-1/2 measures the over-
Recall = lap between generated response and ground truth,
|WK |
|WG ∩ WK | Distinct-1/2 assesses the diversity of words in gen-
Precision = (9) eration and Knowledge R/P/F1 evaluates the infor-
|WG |
mation expression w.r.t. background knowledge.
Recall × Precision
F1 = 2 × However, the results demonstrate that no method
Recall + Precision
can consistently outperform the others under auto-
1
Our w/o latent’s network parameters are also first initial- matic evaluation. As shown in the empirical study
ized with BERTBASE . The pre-training is then carried out on (Liu et al., 2016), there is a weak correlation be-
Reddit and Twitter, with the objective to minimize NLL loss.
The fine-tuning follows the same objective as pre-training on tween automatic metrics and human judgments in
down-stream datasets. open-domain dialogue generation. As such, it isDataset Type Knowledge # Train # Valid # Test
Chit-chat 8,939 dialogues 1,000 dialogues 968 dialogues
Persona-Chat Persona profiles
with persona 131,438 turns 15,602 turns 15,024 turns
11,118 dialogues 1,000 dialogues 1,000 dialogues
Daily Dialog Chit-chat N/A
87,170 turns 8,069 turns 7,740 turns
Video caption 7,659 dialogues 1,787 dialogues 1,710 dialogues
DSTC7-AVSD Conversational QA
& summary 153,180 turns 35,740 turns 13,490 turns
Table 1: Summary of datasets used in the experiments.
Automatic Evaluation Human Evaluation
Dataset Model
BLEU-1/2 Distinct-1/2 Knowledge R/P/F1 Fluency Coherence Informativeness Overall
Seq2Seq 0.448 / 0.353 0.004 / 0.016 0.004 / 0.016 / 0.006 1.82 0.37 0.85 0.34
Persona- LIC 0.405 / 0.320 0.019 / 0.113 0.042 / 0.154 / 0.064 1.95 1.34 1.09 1.29
Chat Our w/o Latent 0.458 / 0.357 0.012 / 0.064 0.085 / 0.263 / 0.125 1.98 1.36 1.04 1.30
Our Method 0.418 / 0.324 0.014 / 0.081 0.162 / 0.542 / 0.242 1.99 1.51 1.70 1.50
Dataset Seq2SeqModel 0.336 / 0.268
BLEU-10.030 /BLEU-2
0.128 BLEU-3
- BLEU-4
1.85 METEOR
0.37 ROUGH-L
0.44 CIDEr
0.33
iVAE Baseline 0.626 0.485
0.309 / 0.249 0.029 / 0.250 0.383
- 0.309
1.53 0.215
0.34 0.487
0.59 0.746
0.30
Daily MI
Dialog CMU 0.405 / 0.322
Our w/o Latent 0.718 0.046 / 0.246
0.584 0.478
- 0.394
1.91 0.267
1.58 0.563
1.03 1.094
1.44
Our w/o
Our Method Latent 0.780 0.638
0.352 / 0.275 0.045 / 0.253 0.530
- 0.441
1.97 0.293
1.57 0.607
1.23 1.235
1.48
DSTC7-AVSD
Our Method 0.784 0.637 0.525 0.435 0.286 0.596 1.209
Our Method
Table 2: Experimental results on Persona-Chat and Daily Dialog with automatic and human evaluations, with
0.925 0.843 0.767 0.689 0.361 0.731 1.716
Upperin
highest value written Bound
bold.
Dataset Model BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR ROUGH-L CIDEr
Baseline 0.626 0.485 0.383 0.309 0.215 0.487 0.746
CMU 0.718 0.584 0.478 0.394 0.267 0.563 1.094
DSTC7-AVSD Our Method 0.784 0.637 0.525 0.435 0.286 0.596 1.209
Our Method
0.925 0.843 0.767 0.689 0.361 0.731 1.716
Upper Bound
Table 3: Experimental results on DSTC7-AVSD with automatic evaluation, with highest value written in bold.
Context breaking news on the presidential race that could change your vote
i m not voting for hillary i m voting for trump
i can t believe this is happening
Generated Responses it would be interesting to see the results of this election
trump is a role model that the news media mafia hides
i will be voting for hillary
Context i plan on walking into the appalachian mountains and never coming back .
i've been to the appalachian mountains a few times . it's a beautiful place .
i've never been to the appalachian mountains , but i've heard it's nice .
Generated Responses i wouldn't want to live there .
don't worry , you'll come back .
that sounds like a good plan .
Context that from 2004-2012 five people died just from consuming monster energy drinks .
monster energy drinks are disgusting .
i've been drinking monster energy drinks since i was a kid .
Generated Responses that's a lot of people .
i've never heard of this .
[ relevant ] ( http : / / en . wikipedia . org / wiki / monster _ energy _ drink )
Table 4: Examples of response generation with our pre-trained model.Persona Profiles [P2] Context
[P2] hi , do you like bbq ?
[P1] hello yes i love bbq
[P2] i love restaurants with bbq , they are a lot of fun .
i love trying barbeque restaurants . [P1] my poor toes are so webbed
i am an administrative assistant . [P2] really ? afterwards , i go and play racquetball to loose some calories .
i am looking forward to retiring in five years . [P1] cool i like to paint
i like ot play racquetball . [P2] what do you do as a profession ? i work as administrative assistant
[P1] i dig in people trash for things to build
[P2] sounds unique but that is more of a hobby instead of a profession
[P1] true . i paint for a living
Seq2Seq that sounds like a lot of work . do you have a job ?
LIC yeah it is a lot of fun
Our w/o Latent do you have any hobbies ?
Our Method that is cool , i am looking forward to retiring in 5 years
Table 5: Case analysis of response generation on Persona-Chat.
suggested to treat these automatic evaluations as a answer. The results in Table 3 demonstrate that
reference and put emphasis on human evaluations. our method has brought a new breakthrough for
During human evaluations, it is shown that our DSTC7-AVSD. Additionally, the upper bound of
method obtains consistently better performance our method is also reported, under the ideal sce-
across all the metrics on Persona-Chat and Daily nario that the optimal candidate answer can be se-
Dialog. The scores of fluency almost approach lected.2 The incredible results validate the great
the upper bound, revealing that our generated re- potential of our approach.
sponses are very fluent. The informativeness as-
3.3 Discussions
sessments indicate that the information in our gen-
erated responses is significantly richer, as com- 3.3.1 Case Analysis
pared with the baseline methods. Our responses To further dissect the quality of our pre-trained
are coherent with the context and favored most by model, several examples of generated responses
crowd-sourcing workers. The ablation study with are provided in Table 4. For each piece of con-
our method and our w/o latent also suggests that text, our model can produce multiple responses by
through the incorporation of discrete latent vari- assigning distinct values to the latent variable and
ables, remarkable improvements can be achieved five candidate responses are selected for display
for dialogue generation. Besides, it can be ob- in the table. It shows that our pre-trained model is
served that the generation quality of transformed- able to generate diverse and appropriate responses.
based approaches (LIC and our method) is sig- Interestingly, as the training corpus includes con-
nificantly better than that of RNN-based methods versations from Reddit threads, some URLs may
(Seq2Seq and iVAEMI ).1 interweave with dialogue utterances. It seems that
The experimental results on DSTC7-AVSD this pattern has been captured by the latent vari-
with automatic evaluation are provided in Table able and sometimes our model generates related
3. Distinct with the above chit-chat datasets, Wikipedia links as the reply.
there are six ground truth responses in DSTC7- In Table 5, it provides the cases of our method
AVSD, which makes the automatic evaluation be- and compared approaches on Persona-Chat, where
come more effective and align better with human two participants chat with each other according to
judgments. In the experiments, our response se- their personas. As shown in the example, partic-
lection is strengthened with an extra ranking step, ipant P2 needs to produce a response towards the
which ranks the candidates according to the auto- given dialogue context, conditioned on his/her per-
matic scores and selects the top one as the final sona profile. The baseline Seq2Seq tends to gener-
1
ate common replies with low informativeness and
It is a normal phenomenon that the performance of our
2
w/o latent is close to that of LIC. Both of them initialize Given a dialogue context and background knowledge,
network parameters with pre-trained language models, con- our model is able to generate K diverse responses. Each of
tinue training with large-scale conversation data as Reddit, them will be evaluated and the one obtaining the best score
and adopt NLL-related objectives. will be treated as the optimal candidate answer.BERT Fine-tuning 58.466 31.891 18.044
GPT-2 Fine-tuning 28.390 19.182 14.359
Our Method 14.180 12.541 10.930
# Training Dialogues 4 Related Work
Model
1k 5k 11k
Seq2Seq 169.668 80.535 44.183
Related work contains pre-trained language mod-
els and one-to-many modeling in dialogue gener-
BERT Fine-tuning 58.466 31.891 18.044
ation.
GPT-2 Fine-tuning 28.390 19.182 14.359
Our Method 14.210 12.634 11.598
Pre-trained Language Models. Pre-trained lan-
guage models, which are trained with large-scale
Table 6: Perplexity of different pre-trained models on general text, have brought many breakthroughs on
Daily Dialog, with best value written in bold. various NLP tasks. These models can be roughly
divided into two categories according to their at-
tention mechanisms. GPT (Radford et al., 2018)
poor coherence. LIC and Our w/o Latent are able and GPT-2 (Radford et al., 2019) are representa-
to produce some coherent responses, whereas de- tive uni-directional language models, where one
ficient on informativeness. In comparison, the re- token is only allowed to attend its previous tokens
sponse by our method is not only coherent with and the objective is to maximize left-to-right gen-
the context, but also expressive of the background eration likelihood. BERT (Devlin et al., 2019) and
personas. XL-Net (Yang et al., 2019) are bi-directional lan-
guage models, where bi-directional context atten-
tion is enabled for token prediction. The latest uni-
3.3.2 Comparison of Pre-trained Models fied language model UniLM (Dong et al., 2019)
is able to support both uni- and bi-directional at-
To further analyze the effectiveness of our pre- tention with flexible self-attention mask designs.
trained model, ablation studies have been con- Recently, some attempts (Golovanov et al., 2019;
ducted on Daily Dialog. The compared methods Wolf et al., 2019) have been made to adapt gen-
include the baseline Seq2Seq, direct fine-tuning erative language models GPT or GPT-2 for dia-
of BERT, GPT-2 (Radford et al., 2019) and our logue generation. Whereas the special issues of
pre-trained model. And there are three different conversations, such as impacts from background
sizes of training dialogues: 1k, 5k and 11k (total knowledge and problems of one-to-many relation-
training data). The experimental results measured ship, are not fully considered and tackled in these
with perplexity are summarized in Table 6. These adaptations.
results demonstrate that our method outperforms One-to-many Modeling. Given one piece of con-
the baseline and other pre-training models consis- text, there exists multiple appropriate responses,
tently with lower perplexity across different train- which is know as the one-to-many mapping prob-
ing sets. Even with the low-resource data of 1k lem. To model this one-to-many relationship,
conversations, our model can still obtain promi- CVAE (Zhao et al., 2017) employs Gaussian dis-
nent performance. tribution to capture the discourse-level variations
Several interesting conclusions can be also of responses. To alleviate the issue of posterior
drawn from these results. Firstly, the compari- collapse in VAE, some extension approaches are
son between BERT and GPT-2 fine-tuning indi- further developed, including conditional Wasser-
cates that uni-directional pre-trained models are stein auto-encoder of DialogWAE (Gu et al., 2019)
more suitable for dialogue generation. Secondly, and implicit feature learning of iVAEMI (Fang
our method obtains better performance than GPT- et al., 2019). Besides the continuous representa-
2, which may result from three aspects: 1) our pre- tion in VAE, discrete categorical variables are also
training is carried out with the datasets of Reddit utilized for interpretable generation (Zhao et al.,
and Twitter, which are closer to human conversa- 2018). Additionally, multiple mapping modules
tions as compared with general text; 2) in the pre- as latent mechanisms are introduced for diverse
training, we adopt more flexible attention mecha- generation (Chen et al., 2019), where accurate
nisms to fully leverage the bi-directional and uni- optimization is carried out via posterior mapping
directional information within the context and re- selection. However, due to the small scale of
sponse. 3) our model has effectively modeled the annotated conversation data and limited capacity
one-to-many relationship with discrete latent vari- of generation network, it remains challenging for
able, whose effect has been verified in Table 2. these methods to balance the diversity and fluencyduring response generation. Joint Conference on Artificial Intelligence, pages
4918–4924.
5 Conclusion Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakr-
A novel pre-training model for dialogue gener- ishna Vedantam, Saurabh Gupta, Piotr Dollár, and
C Lawrence Zitnick. 2015. Microsoft coco captions:
ation is introduced in this paper, incorporated Data collection and evaluation server. arXiv preprint
with latent discrete variables for one-to-many re- arXiv:1504.00325.
lationship modeling. To pre-train our model, two
Kyunghyun Cho, Bart van Merrienboer, Caglar Gul-
reciprocal tasks of response generation and la- cehre, Dzmitry Bahdanau, Fethi Bougares, Holger
tent recognition are carried out simultaneously on Schwenk, and Yoshua Bengio. 2014. Learning
large-scale conversation datasets. Our pre-trained phrase representations using rnn encoder–decoder
model is flexible enough to handle various down- for statistical machine translation. In Proceedings of
the 2014 Conference on Empirical Methods in Nat-
stream tasks of dialogue generation. Extensive ural Language Processing, pages 1724–1734.
and intensive experiments have been carried out
on three publicly available datasets. And the re- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2019. Bert: Pre-training of
sults demonstrate that our model obtains signifi- deep bidirectional transformers for language under-
cant improvements over the other state-of-the-art standing. In Proceedings of the 2019 Conference of
methods. the North American Chapter of the Association for
Our work can be potentially improved with Computational Linguistics: Human Language Tech-
nologies, pages 4171–4186.
more fine-grained latent variables. We will also
explore to boost the latent selection policy with re- Emily Dinan, Varvara Logacheva, Valentin Malykh,
inforcement learning and extend our pre-training Alexander Miller, Kurt Shuster, Jack Urbanek,
Douwe Kiela, Arthur Szlam, Iulian Serban, Ryan
to support dialogue generation in other languages. Lowe, et al. 2019a. The second conversational
intelligence challenge (convai2). arXiv preprint
Acknowledgments arXiv:1902.00098.
We would like to thank Chaotao Chen, Junkun Emily Dinan, Stephen Roller, Kurt Shuster, Angela
Chen, Tong Wu and Wenxia Zheng for their gener- Fan, Michael Auli, and Jason Weston. 2019b. Wiz-
ous help. This work was supported by the National ard of wikipedia: Knowledge-powered conversa-
tional agents. International Conference on Learning
Key Research and Development Project of China Representations.
(No. 2018AAA0101900), and the Natural Science
Foundation of China (No.61533018). Li Dong, Nan Yang, Wenhui Wang, Furu Wei,
Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming
Zhou, and Hsiao-Wuen Hon. 2019. Unified
language model pre-training for natural language
References understanding and generation. arXiv preprint
Huda Alamri, Vincent Cartillier, Abhishek Das, Jue arXiv:1905.03197.
Wang, Anoop Cherian, Irfan Essa, Dhruv Batra, Le Fang, Chunyuan Li, Jianfeng Gao, Wen Dong, and
Tim K Marks, Chiori Hori, Peter Anderson, et al. Changyou Chen. 2019. Implicit deep latent vari-
2019. Audio visual scene-aware dialog. In Pro- able models for text generation. arXiv preprint
ceedings of the IEEE Conference on Computer Vi- arXiv:1908.11527.
sion and Pattern Recognition, pages 7558–7567.
Joseph L Fleiss and Jacob Cohen. 1973. The equiva-
Siqi Bao, Huang He, Fan Wang, Rongzhong Lian, lence of weighted kappa and the intraclass correla-
and Hua Wu. 2019. Know more about each other: tion coefficient as measures of reliability. In Educa-
Evolving dialogue strategy via compound assess- tional and psychological measurement, pages 613–
ment. In Proceedings of the 57th Annual Meeting 619.
of the Association for Computational Linguistics,
pages 5382–5391. Michel Galley, Chris Brockett, Xiang Gao, Jianfeng
Gao, and Bill Dolan. 2019. Grounded response gen-
Boxing Chen and Colin Cherry. 2014. A systematic eration task at dstc7. In AAAI Dialog System Tech-
comparison of smoothing techniques for sentence- nology Challenge Workshop.
level bleu. In Proceedings of the 9th Workshop on
Statistical Machine Translation, pages 362–367. Sergey Golovanov, Rauf Kurbanov, Sergey Nikolenko,
Kyryl Truskovskyi, Alexander Tselousov, and
Chaotao Chen, Jinhua Peng, Fan Wang, Jun Xu, and Thomas Wolf. 2019. Large-scale transfer learning
Hua Wu. 2019. Generating multiple diverse re- for natural language generation. In Proceedings of
sponses with multi-mapping and posterior mapping the 57th Annual Meeting of the Association for Com-
selection. In Proceedings of the 28th International putational Linguistics, pages 6053–6058.Xiaodong Gu, Kyunghyun Cho, Jung-Woo Ha, and Oriol Vinyals and Quoc Le. 2015. A neural conversa-
Sunghun Kim. 2019. Dialogwae: Multimodal tional model. arXiv preprint arXiv:1506.05869.
response generation with conditional wasserstein
auto-encoder. International Conference on Learn- Thomas Wolf, Victor Sanh, Julien Chaumond, and
ing Representations. Clement Delangue. 2019. Transfertransfo: A
transfer learning approach for neural network
Chenyang Huang, Osmar Zaiane, Amine Trabelsi, and based conversational agents. arXiv preprint
Nouha Dziri. 2018. Automatic dialogue genera- arXiv:1901.08149.
tion with expressed emotions. In Proceedings of the
2018 Conference of the North American Chapter of Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V
the Association for Computational Linguistics: Hu- Le, Mohammad Norouzi, Wolfgang Macherey,
man Language Technologies, pages 49–54. Maxim Krikun, Yuan Cao, Qin Gao, Klaus
Macherey, et al. 2016. Google’s neural ma-
Nitish Shirish Keskar, Bryan McCann, Lav Varsh- chine translation system: Bridging the gap between
ney, Caiming Xiong, and Richard Socher. 2019. human and machine translation. arXiv preprint
CTRL: A Conditional Transformer Language Model arXiv:1609.08144.
for Controllable Generation. arXiv preprint
arXiv:1909.05858. Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Car-
bonell, Ruslan Salakhutdinov, and Quoc V Le.
Diederik P Kingma and Jimmy Ba. 2015. Adam: A 2019. Xlnet: Generalized autoregressive pretrain-
method for stochastic optimization. In International ing for language understanding. arXiv preprint
Conference on Learning Representations. arXiv:1906.08237.
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur
and Bill Dolan. 2016. A diversity-promoting objec- Szlam, Douwe Kiela, and Jason Weston. 2018. Per-
tive function for neural conversation models. In Pro- sonalizing dialogue agents: I have a dog, do you
ceedings of the 2016 Conference of the North Amer- have pets too? In Proceedings of the 56th Annual
ican Chapter of the Association for Computational Meeting of the Association for Computational Lin-
Linguistics: Human Language Technologies, pages guistics, pages 2204–2213.
110–119.
Tiancheng Zhao, Kyusong Lee, and Maxine Eskenazi.
Yanran Li, Hui Su, Xiaoyu Shen, Wenjie Li, Ziqiang 2018. Unsupervised discrete sentence representa-
Cao, and Shuzi Niu. 2017. Dailydialog: A manually tion learning for interpretable neural dialog gener-
labelled multi-turn dialogue dataset. In Proceedings ation. In Proceedings of the 56th Annual Meeting
of the 8th International Joint Conference on Natural of the Association for Computational Linguistics,
Language Processing, pages 986–995. pages 1098–1107.
Chia-Wei Liu, Ryan Lowe, Iulian Serban, Mike Nose- Tiancheng Zhao, Ran Zhao, and Maxine Eskenazi.
worthy, Laurent Charlin, and Joelle Pineau. 2016. 2017. Learning discourse-level diversity for neural
How not to evaluate your dialogue system: An em- dialog models using conditional variational autoen-
pirical study of unsupervised evaluation metrics for coders. In Proceedings of the 55th Annual Meet-
dialogue response generation. In Proceedings of the ing of the Association for Computational Linguis-
2016 Conference on Empirical Methods in Natural tics, pages 654–664.
Language Processing, pages 2122–2132.
Hao Zhou, Tom Young, Minlie Huang, Haizhou Zhao,
Alec Radford, Karthik Narasimhan, Tim Salimans, and Jingfang Xu, and Xiaoyan Zhu. 2018. Com-
Ilya Sutskever. 2018. Improving language under- monsense knowledge aware conversation generation
standing by generative pre-training. Technical re- with graph attention. In Proceedings of the 27th
port, OpenAI. International Joint Conference on Artificial Intelli-
gence, pages 4623–4629.
Alec Radford, Jeff Wu, Rewon Child, David Luan,
Dario Amodei, and Ilya Sutskever. 2019. Language Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhut-
models are unsupervised multitask learners. Techni- dinov, Raquel Urtasun, Antonio Torralba, and Sanja
cal report, OpenAI. Fidler. 2015. Aligning books and movies: Towards
story-like visual explanations by watching movies
Hannah Rashkin, Eric Michael Smith, Margaret Li, and and reading books. In Proceedings of the IEEE In-
Y-Lan Boureau. 2019. Towards empathetic open- ternational Conference on Computer Vision, pages
domain conversation models: A new benchmark and 19–27.
dataset. In Proceedings of the 57th Annual Meet-
ing of the Association for Computational Linguis-
tics, pages 5370–5381.
Ramon Sanabria, Shruti Palaskar, and Florian Metze.
2019. Cmu sinbads submission for the dstc7 avsd
challenge. In AAAI Dialog System Technology Chal-
lenge Workshop.You can also read

















































