Realizing One Big Switch Performance Abstraction using P4 - Jeongkeun "JK" Lee Principal Engineer, Intel Barefoot Petr Lapukhov Network Engineer ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Realizing One Big Switch
Performance Abstraction
using P4
Jeongkeun “JK” Lee
Principal Engineer, Intel Barefoot
Petr Lapukhov
Network Engineer, FacebookAgenda
• Need for high-performance cluster for ML training
• Vision: One Big Switch with Distributed VoQ
• Problem: network congestion
• Switch-side building blocks and P4 constructs
• Contributions from
• Anurag Agrawal, Jeremias Blendin, Andy Fingerhut, Grzegorz Jereczek, Yanfang Le, Georgios
Nikolaidis, Rong Pan, Mickey Spiegel
2A Training Cluster Primer
Storage BE – Backend
Fabric FE – Frontend
ToR – Top of Rack
FE FE
ToR ToR
NIC1 NIC4 NIC1 NIC4
… …
CPU1 CPU4 CPU1 CPU4
…
Accel1 Accel2 Accel8 Accel1 Accel2 Accel8
… …
RNIC1 RNIC2 RNIC8 RNIC1 RNIC2 RNIC8
BE BE
ToR ToR
Compute
Fabric
3Distributed ML training
• Combines data & model parallelism
• Bulk-synchronous parallel realization (BSP)
• Collective-style communications
• All trainers arrive to a barrier in each cycle
Ref: https://arxiv.org/pdf/2104.05158.pdf
4The problem statement
• Synchronous training cycle = [Compute + Network]
• Network Collectives: All-to-all, All-Reduce,…
• Collective produces a combination of flows
• Objective: min(collective completion time)
• Large messages – O(1MB)
5What’s the challenge?
• Accelerators require HW offloaded transport
• All-to-all is bisection BW hungry
• All-reduce may cause incast; flow entropy varies
• Large Clos fabric requires tuning with RoCE
• Small scale is fine – single large crossbar switch
6Vision: One Big Switch with Distributed VoQ
• “Network as OBS” model has been used in Hose model Non-blocking
fabric
• SDN for network-wide control plane and policy program
• OVS/OVN network virtualization BX BZ Hose
BY bandwidth
• Service Mesh for uServices
X Y Z
• OBS performance model = hose model
• Non-blocking fabric
• Congestion only at network egress (output queue)
• Distributed VoQ (Virtual Output Queue)
• VoQ reflects egress congestion & BW towards receivers
• Move queueing from egress to ingress
• OBS ingress = 1st-hop switches or senders
7 Source: http://lib.cnfolio.com/Reality: Congestions in DC CLOS
• Uplink/core ç challenge for non-blocking fabric
• Cause: ECMP/LAG hash collision
• Worse at oversubscribed networks
• Incast ç challenge for VoQ
• Cause: many-to-one traffic pattern
• Congestion surge at the last-hop
• Slows down e2e signal loop
• Receiver NIC ç challenge for VoQ
• Cause: slow software/CPU, PCIe bottleneck
8Switch-side building blocks
1. Provide rich congestion, BW metrics
è for applications to acquire available BW asap while controlling congestion
2. Fine-grained load-balancing w/ minimal or no out-of-order delivery
è For non-blocking, full-bisection fabric
3. Cut-payload signaling to receivers
è For NDP-style receiver pulling
4. Sub-RTT signaling back to senders
è Sudden change of congestion/BW state
5. React to rx NIC congestion
è Leverage switch programmability where smart NIC is not available or applicable
91. Provide Congestion and BW metrics
• Goal: switch provides rich info, for sender/receiver to consume and control
• For whom: incoming data pkts, control pkts (RTS/CTS solicitation)
• What to provide: queue depth, drain time, TX rate or avail BW, arrival rate
(incast rate), # of flows, congestion locator (node/port/Q IDs)
• How: in-band on forwarding pkts, separate signal pkt back to sender, or signal
pkt receiver
• Where: last-hop or core switch, ingress or egress
• When: threshold crossing, bloom-filter suppression, when switch metric is off
from in-pkt metric, when NIC sends PFC, upon pkt drops, …
10P4 Primitives (w/ PSA/TNA/T2NA)
• For whom: incoming data pkts, control pkts (RTS/CTS solicitation)
è P4 parser
• What to provide: queue depth, drain time, per-port or -q TX rate, arrival rate (incast rate), # of flows, congestion
locator (node/port/Q IDs)
è standard/intrinsic metadata, register with HW reset, meter or LPF extern
• How: in-band on forwarding pkts, separate signal pkt back to sender, or signal pkt receiver (at high-priority like
NDP cut-payload)
è modify, mirror, recirculate, multicast actions
• Where: last-hop or core switch, ingress or egress, depending on use case
è T2NA: ingress visibility of egress queue status (P4 Expert Round Table 2020)
• When: threshold crossing, bloom-filter suppression, when switch metric is off from in-pkt metric, when NIC sends
PFC, upon pkt drops, …
è register, meter, P4 processing of RX PFC frame, TNA: Deflect on Drop
112. Fine-grained Load Balancing
• For non-blocking fabric
• Sender NIC may spray packets by changing L4 src port number (e.g., AWS SRD)
• Pros: ECMP switch doesn’t need to change; better handle brownfield w/ path tracking at NIC
• Cons: transport & congestion control change; 5tuple connection ID may alter
• Switch alternative 1: flowlet switching (e.g., Conga)
• Pros: no change to transport, no OOO delivery
• Cons: flow scale is limited
• Switch alternative 2: DRR (Deficit Round Robin) packet spraying
• Pros: DRR minimizes load imbalance, hence OOO delivery window; DRR possible in P4
• Cons: need greenfield (at least ToR layer); need packet re-ordering at RX NIC/host
123. Cut-Payload to Receiver
• Signal last-hop switch congestion & drop events to receiver at high-priority
• NDP P4 design by Correct Networks and Intel, using
• ingress meter + mirror
• deflect-on-drop + multicast
• on Tofino1
• P4 source will be posted soon at https://github.com/p4lang/p4-applications
Check out “NDP with SONiC-PINS: A low latency and high performance data-
center transport architecture integrated into SONiC.“ by Rong P. and Reshma S.
134. Sub-RTT, L3 Signaling back to sender
• Edge-to-Edge signaling of congestion info
• 5. able to carry rcv NIC congestion signal (e.g., NIC-to-switch PFC) to sender hosts
• Senders can use the signal (VoQ) in various ways, e.g., instant flow control to ‘flatten the curve’
• Example below: SFC (Source Flow Control) = new L3 switch-to-switch signaling + PFC as existing flow control at
sender NIC. (No PFC btw switches)
• Future work: fine-grained per-receiver VoQ at sender
Last-hop
1st-hop Switch Switch
Rcv
host 1 Port 1 2. Congestion signal Ingress Egress
host
q1 3. PFC q1 [IP reversed, pause time] q1 7. ACK q1
q2 q2 q2 q2
1. Incast traffic q3 6. ECN q3
q3 q3 Agg + Core
cache after q
[dstIP: pause time] switches delay
host 2 Port 2 …
q1 q1
q2 5. PFC q2
q3 q3
14SFC: System Demo
5 6
swc swc victim
16 ia- ia-
H0 0 an an
sm
0
sm
flo
100 16 ws
w
s ta ta flo
G
G 160 flows 25
G SW5 100G SW6 25G
100 s
flow 640 flows 80
160 flow 0
H1 s
100G
normal
0G
flows
160
10
H3
H2
0G
10
H4
0G
10
Each host issues 160 flows (RDMA Reliable Connection).
H5
15Flow Completion Time
1.00 PFC
SFC
0.75
CDF
0.50
0.25
0.00
0 5000 10000 15000 20000 25000 30000
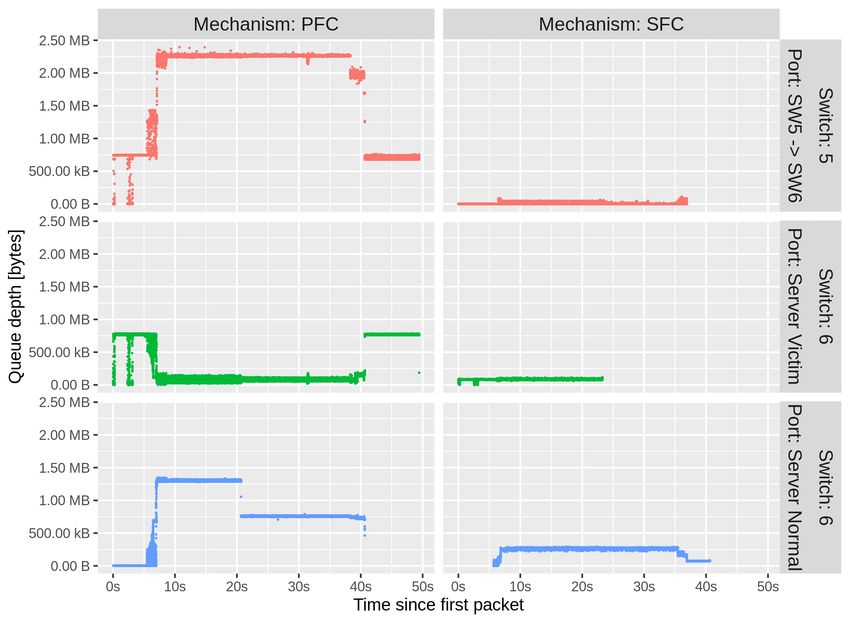
Flow Completion Time (ms)Queue Depth
victim
10
H0 0G
G
25
SW5 100G SW6
H1
25
G
100G
H3
normal
H4 H2
100G
H5Summary
• True One-Big-Switch with performance is possible
• P4 primitives can build
• non-blocking CLOS fabric
• sub-RTT signaling of congestion & BW metrics
• Research questions
• What is the scope of OBS; granularity of distributed VoQ
• From last-hop switch queue to rxNIC port to service node (ML worker or µService)
• Should consider major incast bottleneck point and VoQ scale
• NIC-side building blocks to enable distributed VoQ at senders
• How QoS infra and congestion control benefit from VoQ
18Thank You jk.lee@intel.com petr@fb.com
Simulation setup Custer: 3-tier, 320 servers, full bisection, 12us base RTT Switch buffer: 16MB, Dynamic Threshold Congestion control: DCQCN+window, HPCC SFC Parameters • SFC trigger threshold = ECN threshold = 100KB, SFC drain target = 10KB Workload: RDMA writes • 50% Background load: shuffle, msg size follows public traces from RPC, Hadoop, DCTCP • 8% incast bursts: 120-to-1, msg size 250KB, synchronized starts within 145us Metrics • FCT slowdown: FCT normalize to the FCT of same-size flow at line rate • Goodput, switch buffer occupancy
Simulation with RPC-inspired msg size dist.
7R5-3)C )uOO-3)C 7R5-6)C-2 12-3)C
50% )C7 sORwGRwn
95% )C7 sORwGRwn
99% )C7 sORwGRwn
10
2
10
3
10
3 1.0 1.0
Better
0.8 0.8
2 2
10 10 0.6 0.6
CD)
CD)
1
10
0.4 Better 0.4
10
1
10
1
Better
0.2 0.2
0 0 0
10 0 1 2 3 4 5 6 7 10 0 1 2 3 4 5 6 7 10 0 1 2 3 4 5 6 7 0.0 0.0
10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 0 4 8 12 16 0 20 40 60 80
6ize (%ytes) 6ize (%ytes) 6ize (%ytes) %uffer RFFuSDnFy (0%) GRRGSut (GbSs)
DCQCN+Window
7R5-3)C )uOO-3)C 7R5-6)C-2 12-3)C
50% )C7 sORwGRwn
95% )C7 sORwGRwn
99% )C7 sORwGRwn
10
2
10
3
10
3 1.0 1.0
Better
0.8 0.8
2 2
10 10 0.6 0.6
CD)
CD)
10
1
0.4 Better 0.4
10
1
10
1
Better
0.2 0.2
0 0 0
10 0 1 2 3 4 5 6 7 10 0 1 2 3 4 5 6 7 10 0 1 2 3 4 5 6 7 0.0 0.0
10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 0 4 8 12 16 0 20 40 60 80
6ize (%ytes) 6ize (%ytes) 6ize (%ytes) %uffer RFFuSDnFy (0%) GRRGSut (GbSs)
HPCCYou can also read

















































