Training Workflows for Faster Self-Driving Results - NetApp
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
White Paper Training Workflows for Faster Self-Driving Results Joint AI Solutions for Autonomous Vehicle Development from NetApp and NVIDIA Sung-Han Lin, NetApp April 2020 | WP-7322 In partnership with Abstract The vision of autonomous vehicles on our roads is likely to become a reality in the near future. However, many challenges need to be explored and resolved before self-driving cars are feasible. NetApp, a leading company in the storage industry, is working with NVIDIA, a leading AI computational company, to build the first industrial reference architecture for the automotive industry (Arnette & Lin, 2020). This white paper introduces the reference architecture proposed by NetApp and NVIDIA and describes the challenges and concerns for building and validating this architecture. It also discusses performance considerations to help new AI teams and their IT colleagues accelerate their research, engineering workflows, and processes.

TABLE OF CONTENTS
1 Overview of the Reference Architecture ............................................................................................ 3
1.1 NetApp AFF Systems .....................................................................................................................................3
2 The Challenge of Building and Validating the Reference Architecture .......................................... 4
2.1 Legalities of the Training Datasets ..................................................................................................................4
2.2 Complexity of the Training Model ....................................................................................................................5
2.3 Transforming the Datasets to the Right Format ..............................................................................................6
3 Performance Considerations for Autonomous Driving Workloads ................................................ 6
3.1 Monitoring Resource Utilization to Help Identify Performance Bottlenecks .....................................................6
3.2 Training with Larger Batch Size to Increase Training Speed ..........................................................................7
4 Conclusion ............................................................................................................................................ 8
4.1 What Makes NetApp ONTAP AI Innovative? ..................................................................................................8
4.2 What’s Next?...................................................................................................................................................9
Bibliography ................................................................................................................................................ 9
LIST OF TABLES
Table 1) Datasets considered for training autonomous driving systems. .......................................................................5
LIST OF FIGURES
Figure 1) ONTAP AI autonomous vehicle solution topology. ..........................................................................................3
Figure 2) NetApp ONTAP FlexGroup volumes. ..............................................................................................................4
Figure 3) Resource allocation from different components of CPU and GPU. .................................................................7
Figure 4) Different precision levels can load different number samples. ........................................................................8
2 Training Workflows for Faster Self-Driving Results © 2020 NetApp, Inc. All Rights Reserved
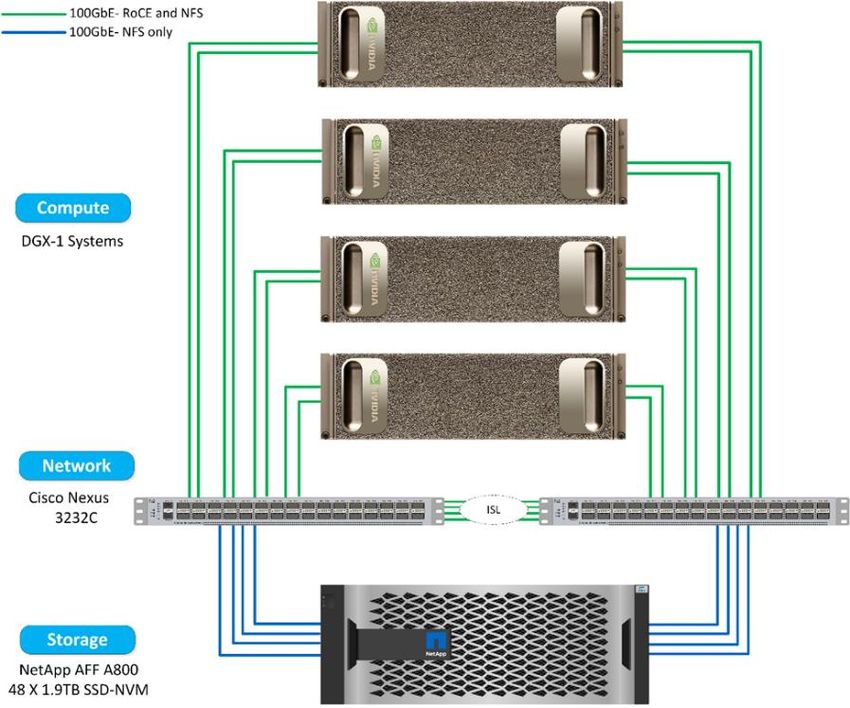
1 Overview of the Reference Architecture At NetApp, our mission is to provide advanced tools that eliminate bottlenecks in computational environments, allowing researchers to concentrate on developing better products. We in the data storage and computational communities have an opportunity to educate the automotive industry and partner ecosystem on the latest optimized hardware and software AI tools for data simulation, testing, and validation. The NetApp® ONTAP® AI architecture, powered by NVIDIA DGX™ systems and NetApp cloud-connected storage systems, was developed and verified by NetApp and NVIDIA. Figure 1 shows the architecture used in our solution design, TR-4799: NetApp ONTAP AI Reference Architecture for Autonomous Driving Workloads. The architecture has one NetApp AFF A800 system, four NVIDIA DGX-1™ systems, and two Cisco Nexus 3232C 100Gb Ethernet (100GbE) switches. Each DGX-1 system is connected to the Nexus switches with four 100GbE connections. These connections perform inter-GPU communications by using remote direct memory access (RDMA) over Converged Ethernet (RoCE). Traditional IP communications for NFS storage access also occur on these links. Each storage controller is connected to the network switches by using four 100GbE links. Even though we demonstrated only four DGX-1 systems in TR-4799, the NetApp AFF A800 storage system has been verified with nine DGX-1 systems and three NVIDIA DGX-2™ systems. Figure 1) ONTAP AI autonomous vehicle solution topology. For detailed information about ONTAP AI with DGX-1 systems, see NetApp Verified Architectures NVA-1121 and NVA-1138. For information about ONTAP AI with DGX-2 systems, see NVA-1135. 1.1 NetApp AFF Systems NetApp AFF state-of-the-art storage systems enable IT departments to meet enterprise storage requirements with industry-leading performance, superior flexibility, cloud integration, and best-in-class data management. Designed specifically for flash, AFF systems help accelerate, manage, and protect business-critical data. The NetApp AFF A800 system is the industry’s first end-to-end NVMe solution. For NAS workloads, a single AFF A800 system supports throughput of 25GB/s for sequential reads and one million IOPS for small random reads at sub-500µs latencies. The next-best NetApp storage system in 3 Training Workflows for Faster Self-Driving Results © 2020 NetApp, Inc. All Rights Reserved
terms of performance is the AFF A700 system, supporting a throughput of 18GB/s for NAS workloads and 40GbE transport. AFF A300 and AFF A220 systems offer sufficient performance for smaller deployments at lower cost points. Customers can start small and grow their systems without interruption while intelligently managing data from the edge to the core to the cloud and back. One requirement for automotive training procedures is to process a collection of potentially billions of files. Files can include text, audio, video, and other forms of unstructured data that must be stored and processed to be read in parallel. The storage system must store a large number of small files and must read those files in parallel for sequential and random I/O. As shown in Figure 2, NetApp AFF systems provide the NetApp ONTAP FlexGroup volume technique which offers a single namespace that is made up of multiple constituent member volumes and that is managed and acts like a NetApp FlexVol ® volume to storage administrators. A FlexGroup volume supports up to 400 billion files in the same namespace, and it supports parallelized operations in NAS workloads across CPUs, nodes, aggregates, and constituent FlexVol volumes. Figure 2) NetApp ONTAP FlexGroup volumes. 2 The Challenge of Building and Validating the Reference Architecture To showcase the capability of the storage and computational systems, it’s necessary to demonstrate the performance of running a representative autonomous vehicle training workload. Generally, an autonomous vehicle must perceive the environment, plan the route, control motion, and respond safely to emergencies. Each of these functionalities belongs to a decision-making component and must be trained separately with specific input data. These components make decisions based on observation from different onboard sources, such as stereo cameras, radar, lidar, ultrasonic sensors, GPS, and internal measurement units (IMUs). The amount of observation data is huge, and it usually needs to be processed first by scene perception training models, including object detection, understanding of urban street scenes in various conditions and locations, and comprehension of the surrounding environment and obstacles. Therefore, for the solution design in TR-4799, we decided to start with scene perception training workloads, particularly object detection and semantic segmentation workloads. This section describes the challenges of identifying the right dataset and exploring meaningful models. 2.1 Legalities of the Training Datasets Using real-world data is a key requirement for testing the autonomous vehicle training workload. NetApp is a storage company and does not have vehicles on the road for data collection. Instead, we decided to 4 Training Workflows for Faster Self-Driving Results © 2020 NetApp, Inc. All Rights Reserved
build the validation with publicly available datasets, which allows customers to easily reproduce our
results.
Table 1 lists four primary datasets that we considered for use in TR-4799. These datasets, collected by
different institutions, vary in size, data format, and sensor setups such as radar, lidar, GPS, cameras, and
IMUs. However, the most important issue in using these datasets is their license agreements. Some
institutions allow the datasets to be used only for research purposes. For TR-4799 we chose to use the
Berkeley BDD100K datasets, because they can be validated by all customers.
Table 1) Datasets considered for training autonomous driving systems.
Dataset Problem Space Sensor Setup Size License
Berkeley BDD100K Object detection, Camera, GPU, IMU 6.5GB BSD 3-Clause
(Fisher Yu, 2018) semantic segmentation (per image)
nuScenes 3D tracking, 3D object Radar, lidar, GPS, 345GB CC BY-NC-SA 3.0
(Caesar, 2019) detection EgoData, IMU, camera
KITTI 3D tracking, 3D object Monocular cameras, 180GB CC BY-NC-SA 3.0
(Geiger, 2013) detection, SLAM IMU, lidar, GPS
Cityscapes Semantic understanding Color stereo cameras 63GB CC BY-NC-SA 3.0
(Cityscapes, 2018)
2.2 Complexity of the Training Model
Unlike choosing the dataset, choosing the right model for testing is not straightforward. From the storage
perspective, choosing the lightweight training model seems to be most reasonable because it can drive
more demands from the storage and demonstrate the advantages of the storage system. However, from
the perspective of targeting the autonomous vehicle community, the fidelity of ground-truth images and a
more complex training model are required.
A convolutional neural network (CNN) is mainly for image classification while an R-CNN, with the R
standing for region, is for object detection. A typical CNN can only tell you the class of the objects but not
where they are located. A method called Mask R-CNN extends R-CNNs by adding a branch for predicting
an object mask in parallel with the existing branch for bounding box recognition (He, 2017).
We chose instance segmentation as our task to demonstrate the performance of the proposed reference
architecture. Instance segmentation is meaningful to the autonomous vehicle because it combines the
tasks of classifying all objects in an image, localizing them with a bounding box (object detection), and
categorizing each pixel in an image into a class (semantic segmentation). To this end, we chose
Mask R-CNN as our primary training model because it is a simple, flexible, and fast system that
outperforms other single-model R-CNNs. Moreover, Mask R-CNN can be extended to estimate human
poses in the same system, which could enable autonomous vehicles to drive safely on the road.
The following hyperparameters could affect the performance of training a Mask R-CNN model:
• Backbone model. The CNN architecture that extracts relevant features from the input images. The
backbone model could be a popular image recognition model, including ResNet-50, InceptionV3, and
VGG-16. This choice provides a trade-off between model accuracy and training time.
• TRAIN_ROIS_PER_IMAGE. The maximum number of regions of interest (ROIs) generated for the
image. This choice affects the size of memory allocation, which affects the training time.
• MAX_GT_INSTANCES. An upper limit on the number of ground-truth (GT) objects that can be
detected in one image. This choice also affects the size of memory allocation, which affects the
training time.
• Level of detection confidence, loss weights, and so on.
5 Training Workflows for Faster Self-Driving Results © 2020 NetApp, Inc. All Rights ReservedIn TR-4799, we choose as our backbone model ResNet-50, which is the model that combines complexity
and popularity. Other hyperparameters are not a primary consideration in TR-4799, so we chose some
values for them and used those values throughout the experiment.
2.3 Transforming the Datasets to the Right Format
After determining the dataset and the training model, we needed to transform the dataset to the most
suitable format for the model. Many semantic segmentation and object detection training models use the
Common Objects in Context (COCO) format (Lin, 2014) because it allows annotating objects with
polygons and records the pixel-level segmentation masks. To follow the standard, we also converted the
Berkeley BDD100K dataset to have the COCO-style metadata.
In addition to the format of the metadata, we also needed to tweak the image itself. We chose to use
70,000 annotated images in the Berkeley BDD100K dataset. In this dataset, each image has a resolution
of 1280x760 pixels, which is large for many image recognition training tasks, but might not be sufficient to
meet the safety demands of autonomous vehicles. To meet the requirements of many cameras and
sensors used for autonomous driving, we scaled the images up to 1920x1080 to reach 2-megapixel
resolution.
With all this preprocessing, we scaled the total dataset size to 40GB. However, from the perspective of
the storage system, 40GB is still too small and can be cached completely in the physical memory of a
DGX-1 system. Thus, to simulate the scenario where the training process is always reading data from the
storage, we duplicated the dataset multiple times to generate a 1.4TB dataset.
3 Performance Considerations for Autonomous Driving Workloads
The primary goal of this white paper is to help data scientists and researchers quickly build and validate
their models. Therefore, the performance described here does not represent the accuracy of a specific
model. Instead, we focus on how to improve the training speed (the number of images processed per
second), which is determined not only by the complexity of the model, but also by the system and
framework configurations. With improved pipeline efficiency, we believe that the autonomous vehicle
development process could be even shorter as more models are trained and tuned.
This section addresses the performance issues we observed in the experiments. For details about the
performance results, see TR-4799.
3.1 Monitoring Resource Utilization to Help Identify Performance Bottlenecks
One major goal of the performance tuning is to train the model faster. People usually look for the issues in
their model, and they try to make their models run more efficiently. This is a preferred method if the
bottleneck happens on the GPUs. However, if the GPUs are already underutilized—for instance, only
60% utilized—reducing the complexity of the model does not improve the training speed. To identify the
bottleneck, it is necessary to monitor system utilization. Here are some of the tools we used to do this
monitoring:
• CPU utilization of DGX-1: top or mpstat (the utilities in sysstat)
• GPU utilization of DGX-1: nvidia-smi
• NetApp AFF A800 storage utilization: perfstat (from NetApp)
With these tools, we can investigate the system resource utilization and identify the bottleneck. For
instance, Figure 3(a) illustrates the resource allocation from one of our experiments. In this figure, we
abstract the amount of resources taken by each component into the size of rectangles. If there is still a
space allowing the rectangles to grow, the resource is not fully utilized. In this case, we observe that the
CPU is the bottleneck. The CPU cannot provide images fast enough, making the GPU idle for 40% of the
training time. (As shown in TR-4799, AFF A800 storage is always underutilized.)
6 Training Workflows for Faster Self-Driving Results © 2020 NetApp, Inc. All Rights ReservedTo improve the training speed, we need to make the CPU process images faster. A simple and straightforward way is to upgrade the CPU; a faster CPU can saturate the GPU. However, this is not always convenient when you use an on-premises box, such as the DGX-1 system shown here. Therefore, we need to find solutions from the software stack. Figure 3) Resource allocation from different components of CPU and GPU. Shifting CPU Workloads to the GPU with the NVIDIA Data Loading Library As illustrated in Figure 3(a), if the CPU is the bottleneck, and the GPU must still have some idle cycles. One solution is to make the GPU take over partial loads from the CPU and make the CPU focus only on specific tasks. To achieve this goal, the NVIDIA® DALI™ data library was developed (DALI, 2020). Figure 3(b) illustrates using the DALI data library in the training. In this case, the GPU helps the CPU preprocess the input data, allowing the CPU to put more computational cycles on fetching and decoding images, thereby increasing the overall training speed. Direct Path Between Storage and GPU Memory Through GPUDirect Storage Another mechanism is to build a direct path between storage and GPU memory with the support of GPUDirect™ RDMA (GPUDirect Storage, 2020). This approach can significantly reduce the overhead of the CPU by directly loading the data into GPU memory. This method can outperform the DALI data library approach, in which the CPU can still be saturated by fetching and decoding images, leaving the GPU with idle cycles. However, one drawback of GPUDirect Storage is due to loading data directly into GPU memory. The issue with bypassing the CPU is the loss of decoding images. Therefore, it’s necessary to decode the image into raw format (which requires a bigger storage space), put it back into storage, and then use GPUDirect Storage to read from storage to GPU memory. NetApp is currently working on supporting GPUDirect Storage and will validate it in the future. 3.2 Training with Larger Batch Size to Increase Training Speed How batch size can affect training speed is always a research problem. From the perspective of stochastic gradient descent (SGD) optimization, using a larger batch size could increase the training time because it might converge slowly or get stuck in a local minimum. Many previous efforts suggest using a smaller batch size and decaying the learning rate during the training. However, a recent effort suggests using an opposite method, which increases the batch size during the training instead of decaying the learning rate (Smith, 2017). Thus, it’s still difficult to conclude how to set the batch size. From the perspective of computation, using a larger batch size might mean a faster training speed. With newer linear algebra libraries that use vectorization for vector and matrix operations, and that have improved GPU technology, computing 10 or 100 images at once might take barely more time than 7 Training Workflows for Faster Self-Driving Results © 2020 NetApp, Inc. All Rights Reserved
computing one image. Moreover, as long as computing more samples does not take a proportionally longer time, a larger batch size reduces the frequency of exchanging updates among GPUs, resulting in shorter training time. As shown in TR-4799, a larger batch size could generate a faster training speed. Automatic Mixed Precision for Loading More Images Even though a larger batch size means a faster training speed, the batch size can’t be increased infinitely. Because of the limitations of GPU memory, only a certain number of images can be computed at once, especially during training on large images with 2-megapixel resolution. By leveraging tensor cores available on NVIDIA Volta™ and NVIDIA Turing™ GPUs, memory allocation can be reduced by using lower precision, such as FP16, allowing more images to be processed simultaneously. Figure 4 illustrates training Mask R-CNN with a scaled Berkeley DeepDrive dataset. 4(a) FP32 can load four images; 4(b) FP16 can load eight images; 4(c) INT8 can load 16 images. However, not all operations can apply lower precision in neural networks. Thus, we chose to use automatic mixed precision (AMP, 2020) to automatically apply lower precision when possible to improve performance, while using FP32 when necessary. Figure 4) Different precision levels can load different number samples. 4 Conclusion With its high-performance, high-speed network fabric, the NetApp AFF A800 system with ONTAP AI is all about reducing the bottlenecks in a deep learning infrastructure; these bottlenecks most commonly occur during the training phase. High I/O bandwidth with massive I/O parallelism is required for sustained high GPU utilization. We have employed just the right balance with state-of-the-art tools and storage expertise for understanding how to monitor for best-in-class utilization of computational autonomous vehicle training workloads. The size and speed of data collection matter. More data means better models and faster time to production. 4.1 What Makes NetApp ONTAP AI Innovative? What sets the AFF A800 apart is its 100GbE network support, which accelerates data movement and fosters balance in the overall training system, because the DGX-1 system supports 100GbE RDMA for cluster interconnect. A single AFF A800 system supports throughput of 25GB/s for sequential reads and one million IOPS for small random reads at sub-500µs latencies. 8 Training Workflows for Faster Self-Driving Results © 2020 NetApp, Inc. All Rights Reserved
What you can expect for your autonomous vehicle training efforts is high-throughput performance while
maintaining a low-latency profile, which helps you build your competitive advantage with AI while cutting
your time to market. Our reference architecture offers a balance of compute, storage, and high-
performance networking to deliver optimal performance. The latest advances from NetApp and NVIDIA in
infrastructure and NVIDIA GPU CLOUD™ software have a significant impact on time to value, rate of
innovation, and discovery.
4.2 What’s Next?
Since we began this autonomous vehicle training journey with NVIDIA, our goal has been to explore how
we can accelerate and improve self-driving vehicle programs, while educating the automotive industry
and partner ecosystem about the latest optimized hardware and software AI tools for data simulation,
testing, and validation.
We encourage you to continue to follow us as we scale our autonomous projects to meet the end-to-end
solution demands of even larger autonomous vehicle GPU-hungry datasets.
Bibliography
AMP. (2020). Retrieved from Automatic Mixed Precision for Deep Learning:
https://developer.nvidia.com/automatic-mixed-precision
Arnette, D., & Lin, S.-H. (2020, January). NetApp ONTAP AI Reference Architecture for
Autonomous Driving Workloads. Retrieved from
https://www.netapp.com/us/media/tr-4799-design.pdf
Caesar, H. a. (2019). nuscenes: A multimodal dataset for autonomous driving. arXiv
preprint arXiv:1903.11027.
Cityscapes. (2018). Retrieved from Cityscapes Data Collection: https://www.cityscapes-
dataset.com/
DALI. (2020). Retrieved from NVIDIA Data Loading Library (DALI):
https://developer.nvidia.com/DALI
Fisher Yu, W. X. (2018). BDD100K: A Diverse Driving Video Database with Scalable
Annotation Tooling. arXiv preprint arXiv:1805.04687.
Geiger, A. a. (2013). Vision meets robotics: The kitti dataset. The International Journal
of Robotics Research, 1231-1237.
GPUDirect Storage. (2020). Retrieved from GPUDirect Storage: A Direct Path Between
Storage and GPU Memory: https://devblogs.nvidia.com/gpudirect-storage/
Grzywaczewski, A. (2017, Oct 9). Training AI for Self-Driving Vehicles: the Challenge of
Scale. Retrieved from NVIDIA Developer Blog:
https://devblogs.nvidia.com/training-self-driving-vehicles-challenge-scale/
He, K. a. (2017). Mask r-cnn. Proceedings of the IEEE international conference on
computer vision, (pp. 2961-2969).
Lin, T.-Y. a. (2014). Microsoft coco: Common objects in context. European conference
on computer vision, 740-755.
Smith, S. L.-J. (2017). Don't decay the learning rate, increase the batch size. arXiv
preprint arXiv:1711.00489.
9 Training Workflows for Faster Self-Driving Results © 2020 NetApp, Inc. All Rights ReservedRefer to the Interoperability Matrix Tool (IMT) on the NetApp Support site to validate that the exact product and feature versions described in this document are supported for your specific environment. The NetApp IMT defines the product components and versions that can be used to construct configurations that are supported by NetApp. Specific results depend on each customer’s installation in accordance with published specifications. Copyright Information Copyright © 2020 NetApp, Inc. and NVIDIA Corporation. All rights reserved. Printed in the U.S. No part of this document covered by copyright may be reproduced in any form or by any means—graphic, electronic, or mechanical, including photocopying, recording, taping, or storage in an electronic retrieval system—without prior written permission of the copyright owner. Software derived from copyrighted NetApp material is subject to the following license and disclaimer: THIS SOFTWARE IS PROVIDED BY NETAPP “AS IS” AND WITHOUT ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE, WHICH ARE HEREBY DISCLAIMED. IN NO EVENT SHALL NETAPP BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. NetApp reserves the right to change any products described herein at any time, and without notice. NetApp assumes no responsibility or liability arising from the use of products described herein, except as expressly agreed to in writing by NetApp. The use or purchase of this product does not convey a license under any patent rights, trademark rights, or any other intellectual property rights of NetApp. The product described in this manual may be protected by one or more U.S. patents, foreign patents, or pending applications. Data contained herein pertains to a commercial item (as defined in FAR 2.101) and is proprietary to NetApp, Inc. The U.S. Government has a non-exclusive, non-transferrable, non-sublicensable, worldwide, limited irrevocable license to use the Data only in connection with and in support of the U.S. Government contract under which the Data was delivered. Except as provided herein, the Data may not be used, disclosed, reproduced, modified, performed, or displayed without the prior written approval of NetApp, Inc. United States Government license rights for the Department of Defense are limited to those rights identified in DFARS clause 252.227-7015(b). Trademark Information NETAPP, the NETAPP logo, and the marks listed at http://www.netapp.com/TM are trademarks of NetApp, Inc. NVIDIA, the NVIDIA logo, and the marks listed at https://www.nvidia.com/en-us/about- nvidia/legal-info/ are trademarks of NVIDIA Corporation. Other company and product names may be trademarks of their respective owners. WP-7322-0420 10 Training Workflows for Faster Self-Driving Results © 2020 NetApp, Inc. All Rights Reserved
You can also read

















































