Data Challenges and Strategies for Large Pulsar Projects - UBC Ingrid Stairs + many others
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Data Challenges and Strategies
for Large Pulsar Projects
Ingrid Stairs
UBC
+ many others
Oct. 6, 2014
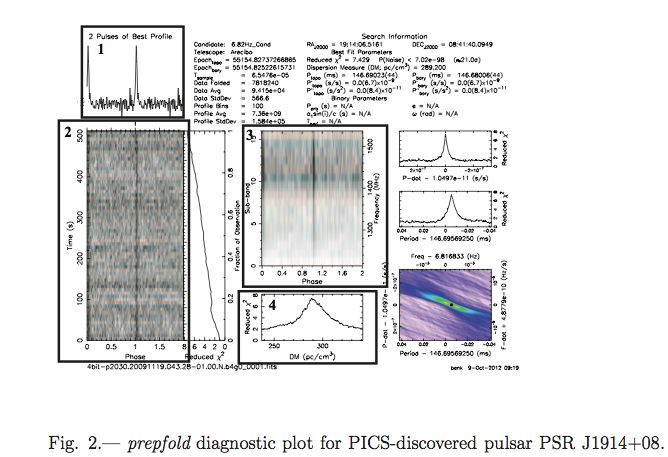
Pulsar Timing in a Nutshell Standard Measure Observed profile offset profile Record the start time of the observation with the observatory clock (typically a hydrogen maser). The offset to the standard profile gives us a Time of Arrival (TOA) for the observed pulse. Transform all TOAs to the Solar System Barycentre, enumerate each rotation of the pulsar and fit its parameters: spin, spin-down rate, position, binary parameters...
Two classes of pulsars – “Young” and
“Millisecond” or “Recycled”
Young
pulsars
Millisecond
pulsars
(MSPs)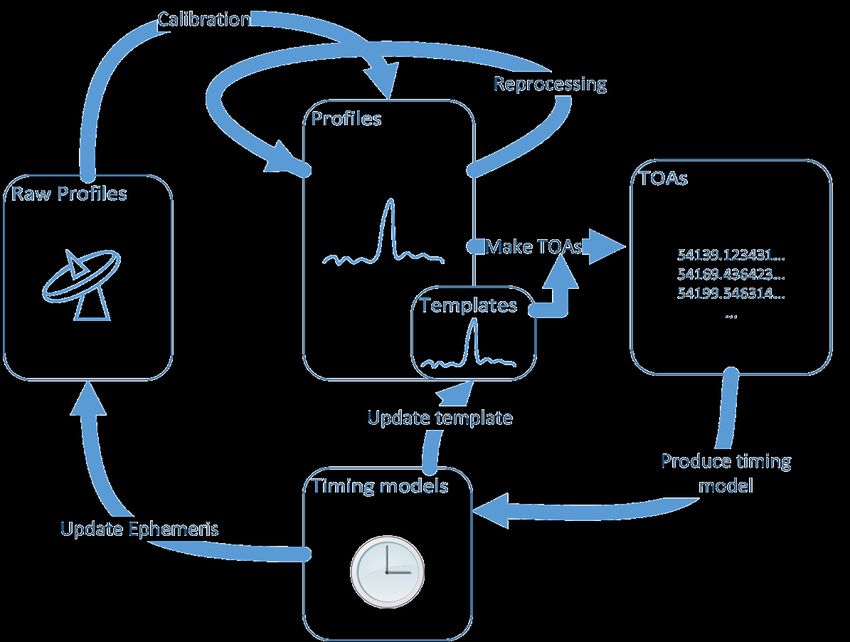
Young pulsars
are mostly found
in the disk of the
Galaxy, often
along spiral arms.
Millisecond pulsars
are more evenly
spread across
the sky.
Kramer, Parkes Multibeam Survey
Pulsar distance estimated from Dispersion Measure (DM): column density of electrons in the interstellar medium. This causes smearing of the pulse following DM / f2.
Pulsar search parameters:
Dispersion
Acceleration
Periodicity
This takes a few CPU cycles!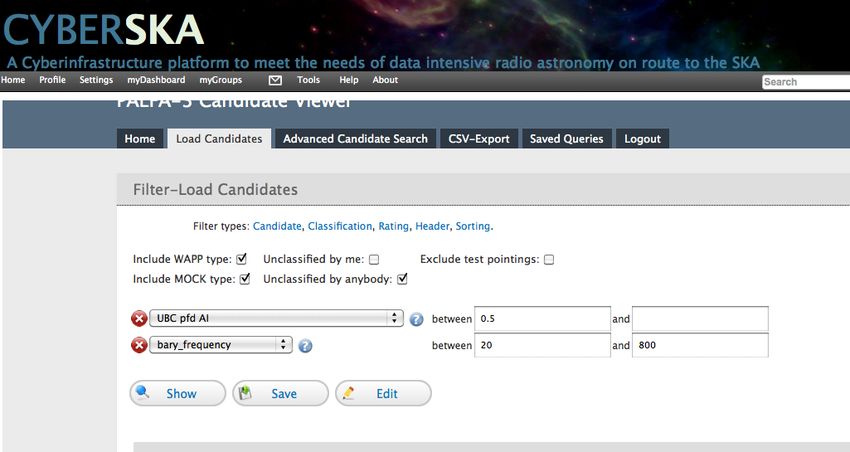
PALFA Survey Large survey of the Galactic Plane using the 7-beam ALFA receiver (built by ATNF) on the Arecibo telescope. Main aim is to find young pulsars, and millisecond pulsars out to large distances.

Data Rates and Amounts To complete the intended survey of the Inner Galaxy: ~20000 pointings or 140000 beams, each sampled at 64 µsec and with 960 frequency channels. (We have switched instruments and are redoing previously observed parts of the sky, as well as reprocessing a couple of times…) To date we have accumulated 245 TB of data, just under 25000 pointings. We have saved these with 4-bit samples, compressed down from the 16 bits provided by the instruments (originally the WAPP ACS, now the Mock Spectrometers) – that’s one sacrifice (in time, money and risk!) due to Big Data.
PALFA processing pipeline
Cornell
Standard pipeline
Einstein@Home
CyberSKA
Adam Brazier
PALFA data flow
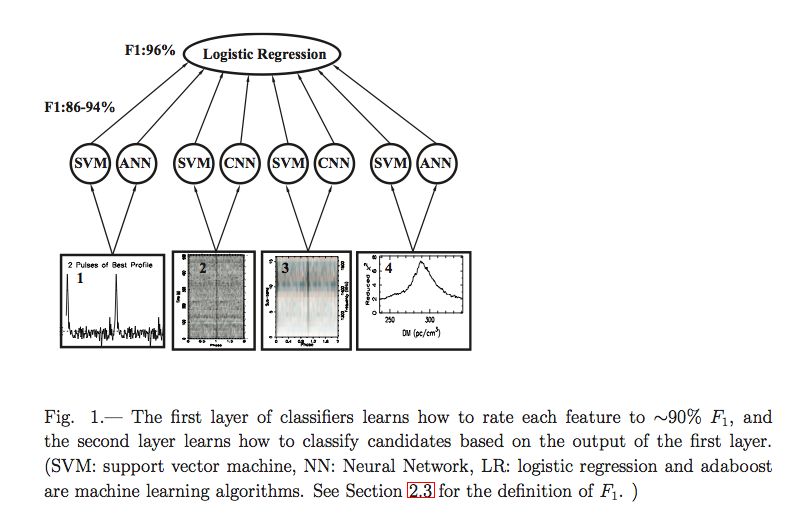
Adam BrazierThe current pipeline (v3) has produced over 11 million candidates – even with the use of radio-frequency-interference zapping in the raw data and a further set of common RFI frequencies that is used to eliminate candidates. Even with armies of undergrads and highschool students helping out, it’s not feasible to example them all well. But we do start with human rankings and also compute several heuristic ratings (eg goodness of gaussian fit to profile, persistence in time and frequency, etc.). Humans can go through candidates and “rank” them as: Candidates of class 1, 2 or 3 RFI (class 4) “Not a pulsar” (class 5) Previously known pulsars (class 6) or harmonics thereof (class 7)
Choosing good candidates on CyberSKA
Classes 6+7 and classes 4+5 are used along with the ratings to
train a machine-learning code developed at UBC. This examines
the image panels on the candidate plots and uses several different
ML algorithms as well as multiple layers of inspection:
Zhu et al 2014The PICS AI provides a single parameter output which can be used to select candidates on CyberSKA. In a test on an independent survey, PICS ranked 100% of pulsars in the top 1% of its ranked list, and 80% of pulsars were ranked higher than any noise or interference. PICS has discovered several pulsars. Zhu et al 2014 – code at https://github.com/zhuww/ubc_AI
Another pulsar project with Big Data (in spirit if
not in volume) is the use of millisecond pulsars
in an array on the sky to constrain or detect
the passage of gravitational waves. Three
major collaborations are in co-opetition to
accomplish this.
Umbrella organization: the
International Pulsar Timing Array
http://www.ipta4gw.orgNanohertz GW sources:
“Monochromatic”
MBH-MBH
binaries of >107
solar mass.
PTA Sources
Stochastic MBH background (Jaffe & Backer
2003, Sesana et al 2008, ...)
Resolved (nearby and massive) MBH sources
(Sesana et al 2009, Boyle & Pen 2010, ...)
Cosmic strings, other exotica (also produce
bursts)…An illustration of a single-source
non-detection:
Top: simulated residuals for PSR
B1855+09 given GW emission
from the claimed (Sudou et al
2003) BH-binary 3C66B (Jenet et
al 2004, Hobbs et al 2009).
Bottom: actual residuals (Kaspi et
al 1994, Hobbs et al 2009).
We have continuous-wave
pipelines for unknown sources
(e.g. Arzoumanian et al. 2014).
Hobbs et al 2009Other types of sources: • “Burst” sources, eg inspirals with GW duration much less than the pulsar observing timescale. With a PTA, these should be detectable and even localizable if the signal is strong enough (Finn & Lommen 2010). • “Memory” events: the merger of an SMBH pair permanently changes the metric and and induces observed frequency jumps in pulsars. Again, a PTA can in principle detect this (van Haasteren & Levin 2010).
For a stochastic (and
isotropic) background,
GWs near Earth would
produce correlations in
timing residuals with a
roughly quadrupolar
dependence on
angular separation. The
goal is to detect this curve
with good significance. Hobbs et al 2009: correlation expectation from
Hellings & Downs 1983, plus simulated data.
Baseline requirement:
~20 pulsars over 5—10 years with
100ns timing precision (Jenet et al 2005).For each ~20-minute observation, we save data that have been • split into several tens of channels • coherently dedispersed within each channel • folded modulo the best known ephemeris for typically 10 seconds at a time. Modern instruments record the data in PSRFITS format, a standard (finally!) agreed on by the pulsar community. Each observation therefore results in a few tens of GB and the overall data volumes are around 1 TB or so. Then there are calibration files, observing logs, etc. Observations happen every ~3 weeks at Arecibo and GBT, and weekly on a few strategic pulsars (to increase our sensitivity to individual sources).
Pulsar timing flowchart
Adam BrazierThe NANOGrav database serves TOAs and profiles for the pulsars in the Demorest et al. 2013 5-year timing paper. The database (and in particular the web interface) is still a work in progress but is used within our collaboration. We also maintain another copy of the timing dataset on a server at UBC. Eventually there will also be an IPTA database. Right now, our most effective transmission of data actually occurs via posted tarballs of TOAs from our released data set(s). Go to data.nanograv.org to download data.
Tarballs aren’t really adequate in the long term! We are attempting to do really groundbreaking science and outsiders will need to be able to reproduce our results through the whole analysis sequence. Recording provenance is key! Some examples of processing decisions that can make a difference: • What were the instrument parameters used? • What ephemeris was used for folding? • Were any channels or integrations in the raw data zapped? • Calibration – flux, Mueller-matrix, none? What are the corresponding cal files? • Which continuum-calibrator source and files were used? • Were the data realigned using an improved ephemeris? • Which standard profile was used for TOA computation? • What algorithm was used? • Were any TOAs discarded, using a fixed cut-off, or by eye? The NANOGrav database has fields for this information, and much of it is recorded, but often with manual effort.
We have also started doing (obvious?) things like using git repositories for iterations of TOAs and ephemerides as we work toward the “release” versions, and having our timing program print out its git hash as part of its output… Other PTAs are also working on the provenance problem, creating automatically-logging analysis pipelines (eg TOASTER in the EPTA) and working on long-term storage description (eg through the CSIRO Data Access Portal in the PPTA). In many ways we’re still limited by the collaborations consisting mostly of scientists who just want to get the data reduced, understood and published, with only part-time help from software/ data experts who actually put thought into long-term preservation and functionality.
Conclusions Pulsar survey data volumes are only going to get larger, with correspondingly large numbers of candidate signals. The infrastructure developed for PALFA (storage, processing, candidate filtering, tied together by CyberSKA) can provide a structure to build on for future surveys. Precision pulsar timing data volumes are also growing, but will remain much smaller unless we decide it is essential to start storing baseband (or at least much more finely-grained) data. Still, the complexity of the timing workflow and the need for reproducibility are driving the development of careful logging and long-term data storage.
You can also read

















































