NAACL-HLT 2021 Natural Language Processing for Medical Conversations The Proceedings of the Second Workshop - Association for Computational ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

NAACL-HLT 2021
Natural Language Processing for Medical Conversations
The Proceedings of the Second Workshop
June 6, 2021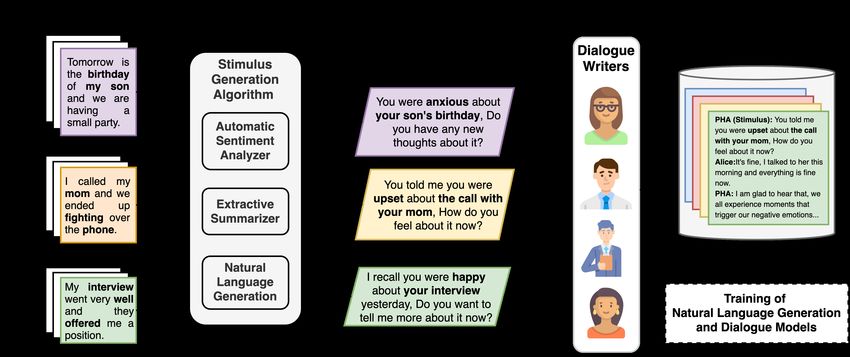
©2021 The Association for Computational Linguistics
Order copies of this and other ACL proceedings from:
Association for Computational Linguistics (ACL)
209 N. Eighth Street
Stroudsburg, PA 18360
USA
Tel: +1-570-476-8006
Fax: +1-570-476-0860
acl@aclweb.org
ISBN 978-1-954085-24-4
ii
Introduction
Welcome to the second workshop on natural language processing for medical conversations.
Technological advancements have been transforming healthcare rapidly in the past several years. This
has been further catalyzed by the COVID-19 pandemic. Several policy changes have been made by the
government with added flexibility to enable remote treatment of patients. COVID-19, its symptoms, and
medications are being widely discussed on social media. These discussions are also being analyzed by
researchers from various perspectives. Moreover, with the availability of wearable fitness devices, these
interactions are not limited to a pandemic but go much further. While medical discussions on public
forums were prevalent in the past, their prevalence is now highlighted due to the scale of the pandemic.
To address healthcare consumers, Electronic Health Record (EHR) companies have been working to
make health data of patients easily available to patients. More recently, technology companies are also
stepping in. Healthcare providers are also making use of automatic speech recognition (ASR) and natural
language understanding to understand doctor-patient conversations and generate medical documentation
automatically. Finally, smart speakers are now common in households and users interact with them about
personal and public health issues.
While applying NLP to open domain is getting increasingly popular, medical conversations present
unique challenges and opportunities for impact. After our successful event last year, we are excited
to continue the cross-pollination between NLP researchers and medical practitioners. The goal of this
workshop is to discuss state-of-the-art approaches in conversational AI, as well as share insights and
challenges when applied in healthcare. This is critical in order to bridge existing gaps between research
and real-world product deployments, this will further shed light on future directions.
We received 19 submissions this year, and accepted 9 reviewed papers in the proceedings of the
workshop. This will be a one-day workshop including keynotes, spotlight talks, posters, and panel
sessions.
iii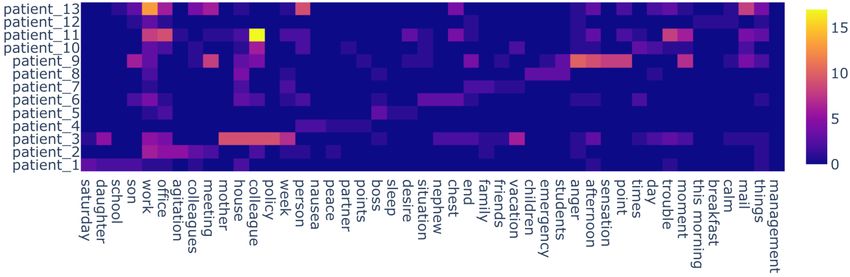

Organizing Committee
• Chaitanya Shivade (Amazon)
• Rashmi Gangadharaiah (Amazon)
• Spandana Gella (Amazon)
• Sandeep Konam (Abridge)
• Shaoqing Yuan (Amazon)
• Yi Zhang (Amazon)
• Parminder Bhatia (Amazon)
• Byron Wallace (Northeastern University)
v
Table of Contents
Would you like to tell me more? Generating a corpus of psychotherapy dialogues
Seyed Mahed Mousavi, Alessandra Cervone, Morena Danieli and Giuseppe Riccardi . . . . . . . . . . . 1
Towards Automating Medical Scribing : Clinic Visit Dialogue2Note Sentence Alignment and Snippet
Summarization
Wen-wai Yim and Meliha Yetisgen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
Gathering Information and Engaging the User ComBot: A Task-Based, Serendipitous Dialog Model for
Patient-Doctor Interactions
Anna Liednikova, Philippe Jolivet, Alexandre Durand-Salmon and Claire Gardent. . . . . . . . . . . . .21
Automatic Speech-Based Checklist for Medical Simulations
Sapir Gershov, Yaniv Ringel, Erez Dvir, Tzvia Tsirilman, Elad Ben Zvi, Sandra Braun, Aeyal Raz
and Shlomi Laufer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
Assertion Detection in Clinical Notes: Medical Language Models to the Rescue?
Betty van Aken, Ivana Trajanovska, Amy Siu, Manuel Mayrdorfer, Klemens Budde and Alexander
Loeser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
Extracting Appointment Spans from Medical Conversations
Nimshi Venkat Meripo and Sandeep Konam . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Building blocks of a task-oriented dialogue system in the healthcare domain
Heereen Shim, Dietwig Lowet, Stijn Luca and Bart Vanrumste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
Joint Summarization-Entailment Optimization for Consumer Health Question Understanding
Khalil Mrini, Franck Dernoncourt, Walter Chang, Emilia Farcas and Ndapa Nakashole . . . . . . . . 58
Medically Aware GPT-3 as a Data Generator for Medical Dialogue Summarization
Bharath Chintagunta, Namit Katariya, Xavier Amatriain and Anitha Kannan . . . . . . . . . . . . . . . . . . 66
viiConference Program
Sunday, June 6, 2021
9:00 – 9:15 Opening Remarks
9:15 – 9:50 Invited Talk 1
10:00 – 10:15 Paper Presentation: Gathering Information and Engaging the User ComBot: A
Task-Based, Serendipitous Dialog Model for Patient-Doctor Interactions
Anna Liednikova, Philippe Jolivet, Alexandre Durand-Salmon and Claire Gar-
dent
10:15 – 10:30 Paper Presentation: Automatic Speech-Based Checklist for Medical Simulations
Sapir Gershov, Yaniv Ringel, Erez Dvir, Tzvia Tsirilman, Elad Ben Zvi, Sandra
Braun, Aeyal Raz and Shlomi Laufer
10:30 – 11:00 Break
11:00 – 11:35 Invited Talk 2
11:45 – 12:00 Paper Presentation: Assertion Detection in Clinical Notes: Medical Language
Models to the Rescue?
Betty van Aken, Ivana Trajanovska, Amy Siu, Manuel Mayrdorfer, Klemens
Budde and Alexander Loeser
12:00 – 12:15 Paper Presentation: Medically Aware GPT-3 as a Data Generator for Medical
Dialogue Summarization
Bharath Chintagunta, Namit Katariya, Xavier Amatriain and Anitha Kannan
12:15 – 13:15 Lunch Break
13:15 – 13:50 Spotlight Talk Sponsor 3M
14:00 – 15:00 Poster Session
15:00 – 15:30 Break
15:30 – 16:05 Invited Talk 3
16:15 – 16:30 Best Paper Awards
ixWould you like to tell me more?
Generating a corpus of psychotherapy dialogues
Seyed Mahed Mousavi1 , Alessandra Cervone2∗, Morena Danieli1 , Giuseppe Riccardi1
1
Signals and Interactive Systems Lab, University of Trento, Italy
2
Amazon Alexa AI
{mahed.mousavi, giuseppe.riccardi}@unitn.it
Abstract The major reasons for such limitations are the
complexity of conversations, the lack of dialogue
The acquisition of a dialogue corpus is a key
step in the process of training a dialogue data and domain knowledge. The conversations
model. In this context, corpora acquisitions about mental state issues are very complex be-
have been designed either for open-domain in- cause they usually encompass personal feelings,
formation retrieval or slot-filling (e.g. restau- user-specific situations, different spaces of entities,
rant booking) tasks. However, there has been and emotions. In this domain, the state-of-the-art
scarce research in the problem of collecting data-driven frameworks are not applicable and do-
personal conversations with users over a long
main knowledge is very scarce. The two main ap-
period of time. In this paper we focus on the
types of dialogues that are required for men- proaches to collect dialogue data for the purpose of
tal health applications. One of these types developing data-driven dialogue agents are either
is the follow-up dialogue that a psychothera- acquiring user interaction data via user simulators
pist would initiate in reviewing the progress and hand-designed policies (Li et al., 2016), or to
of a Cognitive Behavioral Therapy (CBT) in- collect large sets of human-human conversations
tervention. The elicitation of the dialogues is in different user-agnostic settings (Budzianowski
achieved through textual stimuli presented to et al., 2018; Gopalakrishnan et al., 2019; Zhang
dialogue writers. We propose an automatic al-
et al., 2018). These approaches have been used for
gorithm that generates textual stimuli from per-
sonal narratives collected during psychother- goal-oriented agents (e.g. reservations of restau-
apy interventions. The automatically gener- rants) or open-domain agents answering questions
ated stimuli are presented as a seed to dialogue about a finite set of topics (e.g. news, music,
writers following principled guidelines. We weather, games etc.). However, neither of the above
analyze the linguistic quality of the collected approaches can address the need for personal con-
corpus and compare the performances of psy- versations which include user-specific recollections
chotherapists and non-expert dialogue writers.
of events, objects, entities and their relations. Last
Moreover, we report the human evaluation of
a corpus-based response-selection model. but not least, state-of-the-art conversational agents
cannot carry out engaging and appropriate single-
1 Introduction user multi-session conversations. However, per-
sonal conversations’ requirements include the abil-
The idea of developing conversational agents
ity of carrying out multi-session conversations over
as Personal Healthcare Agents (PHA) (Riccardi,
several weeks or months.
2014) has gained growing attention in recent years
for various domains including mental health (Fitz- In this paper, we propose a novel methodology
patrick et al., 2017; Abd-alrazaq et al., 2019; Ali to collect corpora of follow-up dialogues for the
et al., 2020). Most of the conversational agents in mental health domain (or domains with the sim-
the mental health domain are created using rule- ilar characteristics). Psychotherapists deliver in-
based and simple predefined tree-based dialogue terventions over a long period of time and need
flows, resulting in limited understanding of the user to monitor or react to patients’ input. In this do-
input and repetitive responses by the agent. These main, dialogue follow-ups are a critical resource
limitations lead to shallow conversations and weak for psychotherapists to learn about the life events
user engagement (Abd-Alrazaq et al., 2021). of the narrator as well as his/her corresponding
∗
The work was done while at the University of Trento, thoughts and emotions in a timely manner. In Fig-
prior to joining Amazon Alexa AI. ure 1 we describe the proposed workflow for the
1
Proceedings of the Second Workshop on Natural Language Processing for Medical Conversations, pages 1–9
July 6, 2021. ©2021 Association for Computational LinguisticsFigure 1: The workflow for the elicitation of follow-up dialogues starting from the personal narratives collected
during psychotherapy (left-hand side) interventions. The stimulus generation algorithm creates a textual stimulus
from personal narratives as a seed to dialogue writers. Dialogue writers use the textual stimulus and principled
guidelines to generate the follow-up dialogues (right-hand side). The dialogue follow-ups may be used to train
dialogue models, response-selection models and natural language generators.
acquisition of personal dialogue data aimed at train- sequence of personal narratives and recollec-
ing dialogue models. We first collect a dataset of tions, with a similar structure that psychother-
personal narratives written by the users who are apists use when reviewing the progress with
receiving Cognitive Behavioral Therapy (CBT) to the patient.
handle their personal distress more effectively1 . In
• We evaluate the collected dialogue corpus in
the next step, the narratives are used to generate
terms of the quality of the obtained data, as
stimuli for the follow-up conversations with an au-
well as the impact of domain expertise on writ-
tomatic algorithm. The first part of the stimulus,
ing the follow-up dialogues.
the common-ground statement, contains the sum-
mary of the narrative the user has previously left • We investigate the suitability of the collected
and the associated emotions and the second part is corpus for developing conversational agents
a follow-up question aimed at reviewing the users in the mental health domain by automatic
life events. In the last step, the stimuli are pre- and human evaluation of a baseline response-
sented to writers and they are asked to generate selection model.
a conversation based on the provided stimulus by
impersonating themselves as both sides of the con- 2 Literature Review
versation, an approach introduced firstly by Krause
et al. (2017), where in our setting the sides are the Knowledge grounded dialogue corpora Previ-
PHA and the patient. ously published research have addressed the prob-
lem of collecting dialogue data starting from world
The main contributions of this paper can be sum-
knowledge facts or predefined persona descrip-
marized as follows:
tions. In this regard, Zhang et al. (2018) collected
• We present a methodology for data collection a dataset of conversations conditioned on synthetic
and elicitation of follow-up dialogues in the persona descriptions for each side of the dialogue
mental health domain. using Amazon Mechanical Turk (AMT) workers.
Gopalakrishnan et al. (2019) collected a dataset of
• We present an algorithm for automatically dialogues grounded in world knowledge by pair-
generating conversation stimuli for follow-up ing AMT workers to have a conversation based
dialogues in the mental health domain from a on selected reading sets from Wikipedia and The
1
This data collection has been approved by the Ethical Washington Post over various topics. Furthermore,
Committee of the University of Trento. Rashkin et al. (2019) have crowdsourced a dataset
2of conversations with implied user feelings in the
context, using AMT workers where a worker writes
a personal situation associated to an emotion and
in the next step is paired with another worker to
have a conversation about the mentioned situation.
While useful for chitchat and open-domain con-
versations, unfortunately these resources are not a
good fit to address the needs of the mental health
support domain.
Mental health support dialogue corpora The
research in this domain is very recent and resources
are scarce. “Counseling and Psychotherapy Tran-
scripts” published by Alexander Street Press2 is a
dataset of 4000 therapy session transcriptions on
various topics, used as a resource for therapists-
in-training. Pérez-Rosas et al. (2016) collected a
dataset of 277 Motivational Interviewing (MI) ses-
sion videos and obtained the transcriptions for each
session either directly from the data source, or by
recruiting AMT workers. Guntakandla and Nielsen
(2018) conducted a data collection process of thera-
peutic dialogues in Wizard of Oz manner where the
therapists were impersonating a Personal Health-
Figure 2: The user interface of the mobile applica-
care Agent. The authors recorded 324 sessions of tion designed for collecting personal narratives (En-
therapeutic dialogues which were then manually glish translations). The patients were asked to describe
transcribed. Furthermore, in the physical health events, persons, situations that explained their emo-
coaching domain, Gupta et al. (2020) collected a tional arousal while answering the ABC questions de-
dataset of conversations where the expert imperson- signed by psychotherapists.
ates a PHA that engages the users into a healthier
life style. For this purpose, a certified health coach
interacted with 28 patients using a messaging ap- asked to write notes about the daily events that acti-
plication. vated their emotional state. CBT is a psychotherapy
technique based on the intuition that it is not the
3 Dialogue Follow-Up Generation events that directly generate certain emotions but
Methodology how these events are cognitively processed and
evaluated and how irrational or dysfunctional be-
The type of dialogues that we aim at obtaining is liefs influence this process (Oltean et al., 2017). A
different from what has been reported in the litera- technique commonly used in CBT treatment is the
ture. While previous works attempted to collect in- ABC (Antecedent, Belief, Consequences). In this
the-field therapeutic interactions and convert them technique, the psychotherapist tends to identify the
into dialogue datasets, we present an elicitation event that has caused the patient a certain emotion
methodology to generate a dataset of follow-up di- by a set of questions to define A) what, when and
alogues in the mental health domain, grounded in where the event happened, B) the patient’s thoughts
the personal narratives and with the same conver- and beliefs about the event and C) the emotion the
sational structure that the psychotherapists use in patient has experienced regarding the event. Once
order to review the events with the patients in a dysfunctional thoughts are identified, the patient is
timely manner. guided on how to change them or find more rational
3.1 Collection of Personal Narratives and/or functional thoughts (Sarracino et al., 2017).
We recruited 20 users who would meet with their
A group of 20 Italian native speakers who were re-
human psychotherapists one session a week and
ceiving Cognitive Behavioral Therapy (CBT) were
asked them to write notes about the day-life events
2
https://alexanderstreet.com/ that caused them an emotional arousal between one
3Figure 3: The heat-map of frequent nouns used by the patients in collected personal narratives (English transla-
tions). The x-axis represents the nouns extracted from the 5-most frequent list used by each user while the y-axis
and z-axis represent the users and the noun frequency, respectively.
session and the following one. For this purpose, used in the narratives are user-specific. Figure 3
a mobile application was designed that the users plots the recurrence of the 5 most frequent nouns
could interact with for a period of three months, to used by each user in the notes, translated into En-
answer the questions designed by the psychothera- glish. As the figure shows, each word has been
pists for the ABC technique, and assign an emotion used frequently by one user and seldom by other
to the note if possible. The emotions could be se- users, indicating the personal space of entities and
lected from a predefined set, equal for all users, characteristics of the conversations in the mental
including the six basic emotions used in psycho- health domain since the topic of these conversa-
logical experiments (Happiness, Anger, Sadness, tions, i.e. the life events and situations, varies from
Fear, Disgust and Surprise) (Ekman, 1992), and one patient to the other.
two other complex emotional states (Embarrass-
ment and Shame) that were considered relevant for 3.2 Generation of Personal Stimuli
this setting. Figure 2 shows the user interface of We extracted one sentence from each of the 92
the application designed for this purpose. selected narratives using an out-of-the-shelf extrac-
By the end of this step, 224 ABC notes were ob- tive summarizer4 , and under the supervision of the
tained from 20 users of which 92 notes (written by psychotherapists, designed 5 templates to convert
13 different subjects) are complete, i.e. the users each summary and its assigned emotion or automat-
has answered all the questions completely, and are ically detected sentiment into a coherent stimulus
selected for the generation of the stimuli. Consider- consisting of a common ground and a follow-up
ing the fact that each note, that is the answers to the question. For each 18 one-line narrative summaries
ABC questions, is about a unique real-life event, [Summary] with an assigned emotion [Emotion] by
we concatenate the answers in each note under the the user, two templates are defined as;
psychotherapists’ supervision to convert the notes
into personal narratives of one piece. Out of the 92 In the notes you left previously, I read [Sum-
complete narratives, 18 narratives are assigned an mary]. You told me you felt [Emotion] for that.
emotion by the user, and 74 notes are not labeled Do you still feel [Emotion]?
by any emotions. A lexicon-based sentiment ana- I remember you told me that you felt [Emo-
lyzer developed by The OpeNER project3 is used tion] because of [Summary]. How do you feel
to detect the polarity of the 74 narratives without now?
any expressed emotions, which labeled 61 narra-
tives as either negative or positive and 13 of them while, for the 61 one-line narrative summaries with
as neutral. automatically determined polarity [Sentiment], two
Lexical analysis on the selected narratives templates are defined as;
demonstrates that the language and vocabulary
4
sumy Automatic text summarizer,
3
https://www.opener-project.eu/ https://pypi.org/project/sumy/
4Previously, you had a [Sentiment] feeling Total
Stimulus Type Category Count
about what I read in your note [Summary]. Count
How do you feel about it now? Fear 2
I remember you had a [Sentiment] feeling Happiness 9
about what I read in your note [Summary]. Sadness 10
with Emotion 32
Do you have any new thoughts or considera- Anger 7
tions about it now? Disgust 2
Surprise 2
and, for the 13 one-line narrative summaries with- Positive 57
with Valence 107
out any assigned emotion or determined polarity, Negative 50
one template is defined as; Neutral - - 11
I read in your note about [Summary]. Do you Table 1: The distribution of the stimuli used for follow-
want to tell me more about it now? up dialogue collection, obtained by the automatic ag-
gregation of extracted one-line summaries, the tem-
Using this methodology, we obtained 171 stim- plates and the assigned emotion or automatically de-
tected sentiment valence.
uli from the 92 selected narratives, of which 150
stimuli are used as the grounding and conversation
context for follow-up dialogue generation while PHA. The closure turn is an important part of the
21 stimuli (approximately equal to 10% of the set) generated dialogue because these sentences play
are selected by stratified sampling, as a reserved the role of the acknowledgment and grounding of
subset. Table 1 shows the statistics regarding the the dialogue between the user and the PHA, and at
distribution of the stimuli type used for the dialogue the same time may increase the user willingness to
generation process. use the PHA. The number of turns for the dialogues
was not fixed. However, the dialogue writers were
3.3 Generation of Dialogue Follow-Ups suggested to write 4 dialogue turns for each stimu-
Two dialogue writer groups were recruited for the lus, resembling 2 turns for the user and 2 turns for
dialogue generation. The first group included 4 the PHA (excluding the stimulus) with the last turn
psychotherapists experienced in ABC therapy tech- as the closure by the PHA. Furthermore, in order
nique, and the second group included 4 non-expert to minimize cognitive workload, the writers were
writers. Each writer was presented with a detailed suggested to distribute the work by taking a break
guideline including the task description as well as after each 10 stimuli.
several examples of correct and incorrect annota- Initially, 10 stimuli were selected by stratified
tion outcomes. For each provided stimulus, the sampling as the Qualification Batch and were pro-
writers were asked to firstly review and validate vided to all the writers for the purpose of training
the stimulus for possible “Grammatical Error” or and resolving possible misunderstandings. The out-
“Inter-sentence Incoherence” and in case of an in- come of the Qualification Batch was then manually
valid stimulus, to apply necessary modifications controlled and few adjustments were made with 2
to correct it. Following the validation, the writ- of the writers. Afterwards, the rest of the stimuli
ers were asked to write a short dialogue follow-up were distributed such that 30% of the stimuli are
based on the stimulus, assuming that the stimulus annotated by all 8 writers and the rest of the stim-
was asked by a Personal Healthcare Agent (PHA) uli are annotated by two psychotherapists and two
to a user about his/her previous narrative. non-expert writers.
The writers were asked to respect three manda-
tory requirements while generating the dialogues as 4 Evaluation
1) The conversation must be based on and consis- Using the introduced elicitation methodology, we
tent with the stimulus; 2) The flow of the conversa- collected a corpus of follow-up conversations from
tion must be such that the user elaborates about the the two writer groups5 . We then performed an anal-
event introduced in the stimulus and provides more ysis on the obtained conversations to evaluate the
information about the event and its objects (person, 5
We are currently applying for further funds to anonymize
location etc.) or his/her emotion to the PHA; and 3) the corpus and publish a version of the corpus that respects
The conversation must contain a closure turn by the patients’ privacy and deontological requirements.
5Non-Experts Therapists Dialogue Act Non-Experts Therapists
# Dialogues 400 400 inform 1487 1777
# Turns 1714 1494 answer 768 925
# Unique Tokens 3146 4251 auto-positive 591 333
Avg. Turns question 396 452
4.2 3.7
per Dialogue request 217 194
suggest 162 167
Table 2: The statistics of the collected corpus of follow- offer 117 26
up dialogues using the proposed elicitation methodol-
confirm 65 36
ogy per each writer group, non-experts and psychother-
apists. disconfirm 56 63
address-suggest 40 17
address-request 2 9
elicitation methodology and to investigate the im- other 77 11
pact of domain expertise on the collected dialogues
by comparing the performances of psychotherapists Table 3: The distribution of the Dialogue Acts in
and non-expert writers. the generated follow-up conversations by each writer
group using ISO standard DA tagging in Italian (Roc-
4.1 Validation of the Generated Stimuli cabruna et al., 2020). Less frequent DAs to the task
as accept-apology, apology, promise, accept-offer, and
In the first subtask, while 34.2% of the provided Feedback dimension DAs auto-negative, allo-negative
stimuli to the non-expert writers were labeled as and allo-positive are presented as "other" in the Table
invalid, this percentage by the psychotherapist (Bunt et al., 2010).
group was 44.5%. Furthermore, the inter-annotator
agreement measured by Fleiss κ coefficient (Fleiss,
1971) was higher in the latter group (0.26) as op- extracted summary and detected polarity. The mod-
posed to the non-expert group (0.06). This dis- ifications on the summary sentence included refac-
crepancy in the validation subtask suggests that the toring the structure, re-positioning sections of the
assessment of the stimuli by each writer is affected summary or restoring the punctuation. As for the
by their level of competence in the domain and a modifications on the detected sentiment, while the
more precise assessment of the stimuli as an effect modifications done by the non-expert writers were
of domain expertise. Therefore, domain expertise about changing negative and positive polarity with
seems to be an important requirement for the qual- one another, the experts tended to be more con-
ity of validation annotation in the mental health servative in expressing a sentiment for the stimuli
domain. Nevertheless, by representing each writer as they mostly changed the stimuli with detected
group by their consensus vote over the subset of sentiment to neutral ones without any polarity.
stimuli for which we have a consensus decision, the In less than 10% of the cases the writers, mostly
inter-group agreement over this subset of 27 stim- the psychotherapists, modified the template and
uli was 0.6639, measured by Cohen’s κ coefficient specifically the follow-up question. In these cases,
(Cohen, 1960), suggesting that even though domain the questions were changed to a more summary-
knowledge and expertise results in a fine-grained specific ones such as "...What was the distorted
assessment, it is still feasible to obtain a course- thought that came to your mind?".
grained validation over the generated stimuli with a
group of non-expert writers with appropriate guide- 4.2 Analysis of the Dialogue Data Collection
lines. As the result of elicitation process, we collected a
While the expert group labeled 60% of the in- dataset of follow-up dialogues in the mental health
valid stimuli due to “Inter-sentence Incoherence” domain, presented in Table 2, consisting of 800 dia-
with respect to the automatic generation and com- logues written by both groups. The number of turns
bination of the stimuli elements (the summary, the and the number of unique tokens for each group
sentiment, and the template), “Grammatical Error” indicate that the experts tended to write shorter
was the assigned error in most of the stimuli labeled conversations while they used a wider range of vo-
as invalid, 69%, by the non-expert group. Regard- cabulary in writing the conversations compared to
ing the corrections applied to the invalid stimuli, the non-expert group. Regarding the length of the
modifications were mostly about the automatically generated dialogues, in 627 conversations the writ-
6Figure 4: The heat-map of frequent nouns used by the dialogue writers in the generated conversations (English
translations). The x-axis represents the nouns extracted by merging the lists of 20 most frequent nouns used per
each writer. The y-axis and z-axis represent the writers and the noun frequency per each writer respectively.
ers respected the suggestion of writing 4 turns per question, request and suggest), there is a diversity
dialogue, with exceptions of 90 dialogues written in in the type and the frequency of the DAs used by
two turns where the user replies to the stimulus and non-expert group (such as offer, address-suggest
the PHA ends the conversation with a closure turn, and other less relevant DAs to the domain) with
and 83 dialogues where the user and the PHA dis- respect to the professionals, suggesting that the pro-
cuss further about the event and the user’s thoughts fessionals hold a more structured conversation with
before ending the conversation. respect to the other group.
4.2.1 Linguistic Analysis 4.2.2 Response-Selection Baseline
In order to gain insights about the differences in the We investigated the appropriateness of the col-
dialogues written be each group, we looked into lected dialogue corpus for developing conversa-
the vocabulary of the nouns and entities used by tional agents in the mental health domain by train-
each writer. Figure 4 shows the frequency heat- ing a TF-IDF response-selection baseline model.
map of the 20 most frequent nouns used by each The model was trained on 90% of the collected con-
writer in generated dialogues, translated into En- versations with a similar training setting to Lowe
glish. The results indicate that the language and et al. (2015), and evaluated on the remaining 10%
vocabulary used in the expert group is specific for of the data as test set using Recall@k family of
each therapist and varies from one expert to the metrics, presented in Table 4. The model was then
other, while non-expert writers have a more com- integrated in the application introduced in subsec-
bined vocabulary with less inter-annotator novelty tion 3.1 to select the correct PHA response for each
in lexicon, suggesting that the domain expertise has user turn. 10 test users were recruited to inter-
an influence on language and the use of vocabulary act with our application and write narratives about
in generating conversations for the mental health their life events by answering the ABC questions
domain. for 50 days. Each narrative was then automatically
Furthermore, we developed a Dialogue Act tag- converted to a personal dialogue stimuli after one
ger to compare the conversations by their set of day, using the introduced methodology in subsec-
Dialogue Acts (DA). For this purpose, we anno- tion 3.2, to initiate a follow-up dialogue with the
tated 370 of the collected dialogue follow-ups test user for two exchanges (4 turns) with natural
(1514 turns, approximately equal to 45% of the language responses from the users and retrieved re-
dataset) with the ISO standard DA tagging in Ital- sponses from the system. Regarding the evaluation
ian (Roccabruna et al., 2020) and trained an en- of the dialogues, we asked the test users to assess
coder–decoder model (Zhao and Kawahara, 2019) the appropriateness and coherence of each system
to segment each turn to its functional units and label turn (including the stimulus) during the conversa-
them by their DAs. The results, presented in Table tion with thumbs-up (appropriate) or thumbs-down
3, show that despite the similarity in the use of the (inappropriate) for each turn, and to evaluate the
top 6 frequent DAs (inform, answer, auto-positive, quality of the conversation as-a-whole by voting
7TF-IDF Through an analysis of the collected resource
1 in 2 R@1 0.49 following our proposed methodology, it emerged
1 in 10 R@1 0.21 that the task of validating responses and generat-
1 in 10 R@2 0.36 ing dialogues in the mental healthcare domain can
1 in 10 R@5 0.55 be performed both by using psychotherapists and
1 in 50 R@1 0.14 non-expert dialogue writers. Therefore, it suggests
1 in 50 R@2 0.18 the possibility of training a larger number of non-
1 in 50 R@5 0.26 expert dialogue writers using appropriate guide-
lines to obtain a valid dataset with less cost while
Table 4: The performance of the response-selection ensuring consistency in the results.
baseline on the collected dialogue follow-ups for dif-
Furthermore, we investigated the appropriate-
ferent recall metrics.
ness of the collected corpus for developing conver-
Count sational agents in the mental health domain. We re-
ported automatic and human evaluation of a corpus-
# Dialogues 217
based response-selection baseline. We found that
# 5-star 130 (60%)
the test users who interacted with the model over a
# 4-star 26 (12%)
long-term period (50 days) considered on average
# 3-star 41 (19%)
91% of system turns as appropriate and coherent,
# 2-star 8 (3%)
resulting into 72% of dialogues with acceptable
# 1-star 12 (6%)
quality.
# PHA Turns 651
We believe the proposed methodology can be
# Thumps-Up 594 (91%)
used to tackle the problem of resource scarcity
# Thumps-Down 57 (9%)
in the mental health domain. In particular, our
Table 5: The results of human evaluation of the methodology can be used to obtain corpora of dia-
response-selection model in follow-up dialogues. The logues grounded in personal recollections for devel-
users rated each response on a binary scale (Thumbs- oping dialogue models in the mental health domain.
Up and Thumbs-Down) as well as the whole dialogue
with 1-5 star score. Acknowledgements
The research leading to these results has received
from 1-star (very bad) to 5-stars (very good) for funding from the European Union – H2020 Pro-
each dialogue. gramme under grant agreement 826266: COAD-
The results of human evaluation on the baseline APT.
dialogue model, shown in Table 5, indicate that
91% of the system turns were considered appro-
priate and coherent by the test users, resulting in References
more than 70% of the dialogues with acceptable Alaa A Abd-alrazaq, Mohannad Alajlani, Ali Abdal-
quality, thus suggesting the usefulness and suitabil- lah Alalwan, Bridgette M Bewick, Peter Gardner,
ity of the generated dialogues using the proposed and Mowafa Househ. 2019. An overview of the
features of chatbots in mental health: A scoping re-
methodology for developing PHAs in the mental
view. International Journal of Medical Informatics,
health domain. 132:103978.
5 Conclusions Alaa A Abd-Alrazaq, Mohannad Alajlani, Nashva Ali,
Kerstin Denecke, Bridgette M Bewick, and Mowafa
In this work, we address the need for suitable dia- Househ. 2021. Perceptions and opinions of patients
logue corpora to train Personal Healthcare Agents about mental health chatbots: Scoping review. Jour-
nal of Medical Internet Research, 23(1):e17828.
in the mental health domain. We present an elicita-
tion methodology for dialogues in the mental health Mohammad Rafayet Ali, Seyedeh Zahra Razavi, Raina
domain grounded in personal recollections. Using Langevin, Abdullah Al Mamun, Benjamin Kane,
the proposed methodology, we collected a dataset Reza Rawassizadeh, Lenhart K. Schubert, and
Ehsan Hoque. 2020. A virtual conversational agent
of follow-up dialogues that psychotherapists would for teens with autism spectrum disorder: Experimen-
hold with the patients to review the personal events tal results and design lessons. In Proceedings of the
and emotions during a CBT intervention. 20th ACM International Conference on Intelligent
8Virtual Agents. Association for Computing Machin- Xiujun Li, Zachary C Lipton, Bhuwan Dhingra, Lihong
ery. Li, Jianfeng Gao, and Yun-Nung Chen. 2016. A
user simulator for task-completion dialogues. arXiv
Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang preprint arXiv:1612.05688.
Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ra-
madan, and Milica Gasic. 2018. Multiwoz-a large- Ryan Lowe, Nissan Pow, Iulian Serban, and Joelle
scale multi-domain wizard-of-oz dataset for task- Pineau. 2015. The Ubuntu dialogue corpus: A large
oriented dialogue modelling. In Proceedings of the dataset for research in unstructured multi-turn dia-
2018 Conference on Empirical Methods in Natural logue systems. In Proceedings of the 16th Annual
Language Processing, pages 5016–5026. Meeting of the Special Interest Group on Discourse
and Dialogue, pages 285–294. Association for Com-
Harry Bunt, Jan Alexandersson, Jean Carletta, Jae- putational Linguistics.
Woong Choe, Alex Chengyu Fang, Koiti Hasida,
Kiyong Lee, Volha Petukhova, Andrei Popescu- Horea-Radu Oltean, Philip Hyland, Frédérique Val-
Belis, Laurent Romary, Claudia Soria, and David lières, and Daniel Ovidiu David. 2017. An empir-
Traum. 2010. Towards an iso standard for dialogue ical assessment of rebt models of psychopathology
act annotation. Seventh conference on International and psychological health in the prediction of anxiety
Language Resources and Evaluation (LREC’10). and depression symptoms. Behavioural and cogni-
tive psychotherapy, 45(6):600–615.
Jacob Cohen. 1960. A coefficient of agreement for Verónica Pérez-Rosas, Rada Mihalcea, Kenneth Resni-
nominal scales. Educational and psychological mea- cow, Satinder Singh, and Lawrence An. 2016. Build-
surement, 20(1):37–46. ing a motivational interviewing dataset. In Proceed-
ings of the Third Workshop on Computational Lin-
Paul Ekman. 1992. Are there basic emotions? Psycho- guistics and Clinical Psychology, pages 42–51.
logical Review, 99(3):550–553.
Hannah Rashkin, Eric Michael Smith, Margaret Li, and
Kathleen Kara Fitzpatrick, Alison Darcy, and Molly Y-Lan Boureau. 2019. Towards empathetic open-
Vierhile. 2017. Delivering cognitive behavior ther- domain conversation models: A new benchmark and
apy to young adults with symptoms of depression dataset. In Proceedings of the 57th Annual Meet-
and anxiety using a fully automated conversational ing of the Association for Computational Linguis-
agent (woebot): a randomized controlled trial. JMIR tics, pages 5370–5381. Association for Computa-
mental health, 4(2):e19. tional Linguistics.
Joseph L Fleiss. 1971. Measuring nominal scale agree- Giuseppe Riccardi. 2014. Towards healthcare per-
ment among many raters. Psychological bulletin, sonal agents. In Proceedings of the 2014 Workshop
76(5):378. on Roadmapping the Future of Multimodal Interac-
tion Research including Business Opportunities and
Karthik Gopalakrishnan, Behnam Hedayatnia, Challenges, pages 53–56.
Qinglang Chen, Anna Gottardi, Sanjeev Kwatra,
Anu Venkatesh, Raefer Gabriel, Dilek Hakkani-Tür, Gabriel Roccabruna, Alessandra Cervone, and
and Amazon Alexa AI. 2019. Topical-chat: Towards Giuseppe Riccardi. 2020. Multifunctional iso
knowledge-grounded open-domain conversations. standard dialogue act tagging in italian. Seventh
In INTERSPEECH, pages 1891–1895. Italian Conference on Computational Linguistics
(CLiC-it).
Nishitha Guntakandla and Rodney Nielsen. 2018. An-
notating reflections for health behavior change ther- Diego Sarracino, Giancarlo Dimaggio, Rawezh
apy. In Proceedings of the Eleventh International Ibrahim, Raffaele Popolo, Sandra Sassaroli, and
Conference on Language Resources and Evaluation Giovanni M Ruggiero. 2017. When rebt goes
(LREC 2018). difficult: applying abc-def to personality disorders.
Journal of Rational-Emotive & Cognitive-Behavior
Itika Gupta, Barbara Di Eugenio, Brian Ziebart, Therapy, 35(3):278–295.
Aiswarya Baiju, Bing Liu, Ben Gerber, Lisa Sharp, Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur
Nadia Nabulsi, and Mary Smart. 2020. Human- Szlam, Douwe Kiela, and Jason Weston. 2018. Per-
human health coaching via text messages: Corpus, sonalizing dialogue agents: I have a dog, do you
annotation, and analysis. In Proceedings of the 21th have pets too? In Proceedings of the 56th Annual
Annual Meeting of the Special Interest Group on Dis- Meeting of the Association for Computational Lin-
course and Dialogue, pages 246–256. guistics (Volume 1: Long Papers), pages 2204–2213.
Association for Computational Linguistics.
Ben Krause, Marco Damonte, Mihai Dobre, Daniel
Duma, Joachim Fainberg, Federico Fancellu, Em- Tianyu Zhao and Tatsuya Kawahara. 2019. Joint dialog
manuel Kahembwe, Jianpeng Cheng, and Bonnie act segmentation and recognition in human conver-
Webber. 2017. Edina: Building an open domain sations using attention to dialog context. Computer
socialbot with self-dialogues. 1st Proceedings of Speech & Language, 57:108–127.
Alexa Prize (Alexa Prize 2017).
9Towards Automating Medical Scribing : Clinic Visit Dialogue2Note
Sentence Alignment and Snippet Summarization
Wen-wai Yim Meliha Yetisgen
Augmedix Inc University of Washington
wenwai.yim@augmedix.com melihay@uw.edu
Abstract note
She declines the
dialogue
[QA-1] Doctor: Have you had a pneumonia vaccine?
pneumonia vaccine. [QA-1] Patient: No, I don’t think so.
Medical conversations from patient visits are [QA-2] Doctor: Alright, do you want one?
routinely summarized into clinical notes for [QA-2] Patient: No.
documentation of clinical care. The automatic
creation of clinical note is particularly chal- Table 1: Alignment example
lenging given that it requires summarization
over spoken language and multiple speaker
turns; as well, clinical notes include highly injected with structured information, e.g. labs. Fi-
technical semi-structured text. In this paper, nally, parts of clinical notes may be transcribed
we describe our corpus creation method and from dictations; or clinicians may issue commands
baseline systems for two NLP tasks, clinical to adjust changes in the text, e.g. “change the tem-
dialogue2note sentence alignment and clinical
dialogue2note snippet summarization. These
plate”, “nevermind disregard that.”
two systems, as well as other models created In earlier work (Yim et al., 2020), we introduced
from such a corpus, may be incorporated as a new annotation methodology that aligns clinic
parts of an overall end-to-end clinical note gen- visit dialogue sentences to clinical note sentences
eration system. with labels, thus creating sub-document granular
1 Introduction snippet alignments between dialogue and clinical
note pairs (e.g. Table 1, 2). In this paper, we extend
As a side effect of widespread electronic medi- this annotation work on a real corpus and provide
cal record adoption spurred by the HITECH Act, the first baselines for clinic visit dialogue2note au-
clinicians have been burdened with increased doc- tomatic sentence alignments. Much like machine
umentation demands (Tran et al.). Thus for each translation (MT) bitext corpora alignment is in-
visit with a patient, clinicians are required to input strumental to the progress in MT; we believe that
order entries and referrals; most importantly, they dialogue2note sentence alignment will be a critical
are charged with the creation of a clinical note. A driver for AI assisted medical scribing. In the dia-
clinical note summarizes the discussions and plans logue2note snippet summarization task, we provide
of a medical visit and ultimately serves as a clinical our baselines for generating clinical note sentences
communication device, as well as a record used for from transcript snippets. Technology developed
billing and legal purposes. To combat physician from these tasks, as well as other models gener-
burnout, some practices employ medical scribes ated from this annotation, can contribute as part of
to assist in documentation tasks. However, hiring a larger framework that ingests automatic speech
such assistants to audit visits and to collaborate recognition (ASR) output from clinician-patient
with medical staff for electronic medical record visits and generates clinical note text end-to-end
documentation completion is costly; thus there is (Quiroz et al., 2019).
great interest in creating technology to automati-
cally generate clinical notes based on clinic visit 2 Background
conversations.
Not only does the task of clinical note creation Table 2 depicts a full abbreviated clinical note with
from medical conversation dialogue include sum- marked associated dialogue transcript sentences.
marizing information over multiple speakers, often To understand the challenges of alignment
the clinical note document is created with clinician- (creation of paired transcript-note input-output)
provided templates; clinical notes are also often and generation (creation of the note sentence from
10
Proceedings of the Second Workshop on Natural Language Processing for Medical Conversations, pages 10–20
July 6, 2021. ©2021 Association for Computational Linguisticsnote dialogue annotations
0 | Chief Complaint : 0 | Doctor: alright enlarged tonsils.
1 | Evaluation of tonsil hypertrophy .. | ... note[1] → STATEMENT2SCRIBE[0]
2 | HPI : 6 | Doctor: okay so tell me about your throat. note[5] → GROUP
.. | ... 7 | Patient: my tonsils they stay pretty big and they have tonsil stone and - [ STATEMENT[6],
.. | ... .. | ... STATEMENT[7],
5 | Reports enlarged tonsils, tonsil stones and sore throat. 9 | Patient: um like this once on this side specifically it’s actually swollen- STATEMENT[9,10] ]
6 | Symptoms have been present for several years but have 10 | Patient: and a couple weeks ago it was so swollen that it was like bleeding. note[6] → GROUP
worsened over the past several months. 11 | Patient: I wake up in the mornings and I feel like I’m going to be sick. [ QA[18,19],
.. | ... QA[20,21],
.. | ...
18 | She wakes up in the morning with nausea. STATEMENT[22,23] ]
18 | Doctor: so you had this for a long time? INCOMPLETE
19 | She has frequent tonsil infections, 3-4 infections per year.
19 | Patient: yeah
.. | ... note[18] → STATEMENT[11]
20 | Doctor: wait how old are you?
.. | ... note[19] → QA[32,33]
21 | Patient: twenty two.
26 | Physical Exam note[29] → INFFERRED-OUTSIDE
22 | Doctor: and you’ve had tonsil infections since high school?
.. | ... note[33] → DICTATION[48]
23 | Patient: mhm.
28 | Turbinates :
.. | ... note[68] → COMMAND[147]
29 | Normal size and symmetrical bilaterally.
24 | Doctor: sore throats?
.. | ...
26 | Patient: yeah.
.. | Tonsil :
.. | ...
33 | 3+ cryptic
32 | Patient: do you think it happens more than three times in a year?
.. | ...
33 | Patient: probably at least three.
.. | ...
.. | ...
62 | Assessment & Plan :
48 | Doctor: tonsils three plus cryptic .
.. | ...
.. | ...
68 | [Risk and benefits template for tonsillectomy]
.. | ...
.. | ...
147 | Doctor: please insert the risks and benefits template for tonsillectomy.
Table 2: Example annotations (right) for corresponding clinical note (left) and dialogue (middle). The same colors indicate
matched associations.
the dialogue snippet), it is important to consider versation, it may appear across multiple turns many
several differences in textual mediums: sentences apart with contextually inferred subjects.
Semantic variations between spoken dia- Order of appearance between source and tar-
logue and written clinical note narrative. get are not consistent. The order of information
Spoken language in clinic visits have vastly and organization of data in a clinical note may not
different representations than in highly technical match the order of discussion in a clinic visit dia-
clinical note reports. Dialogue may include logue. This provides additional challenges in the
frequent use of vernacular and verbal expressions, alignment process. Table 2 shows corresponding
along with disfluencies, filler words, and false note and dialogue information with the same color.
starts. In contrast, clinical note text is known to use Content incongruency. Relationship-building is
semi-structured language, e.g. lists, and is known a critical aspect of clinician-patient visits. There-
to have a much higher degree of nominalization. fore visit conversations may include discussion un-
Moreover, notes frequently contain medical related to patient health, e.g. politics and social
terminology, acronyms, and abbreviations, often events. Conversely, not all clinical note content
with multiple word senses. necessarily corresponds to a dialogue content. In-
Information density and length. Whereas clin- formation may come from a clinical note template
ical notes are highly dense technical documents, or various parts of the electronic medical record.
conversation dialogue are much longer than clini-
Clinical note creation from conversation amal-
cal notes. In fact, in our data, dialogues were on
gamates interweaving subtasks. Elements in a
average three times the note length. Key informa-
clinic visit conversation (or accompanying speech
tion in conversations are regularly interspersed.
introduction) are intended to be recorded or acted
Dialogue anaphora across multiple turns is per- upon in different ways. For example, some spoken
vasive. Anaphora is the phenomenon in which language may be directly copied to the clinical note
information can only be understood in conjunction with minor pre-determined edits, such as in a dic-
with references to other expressions. Consider in tation, e.g. “three plus cryptic” will be converted
the dialogue example : “Patient: I have been having to “3+ cryptic”. However some language is meant
swelling and pain in my knee. Doctor: How often to express directives, pertaining to adjustments to
does the knee bother you?” It’s understood that the the note, e.g. “please insert the risks and benefits
second reference of “knee” pertains to the knee- template for tonsillectomy.” Some information is
related swelling and pain. A more complex exam- meant to be interpreted, e.g. “the pe was all nor-
ple is shown in Table 2 note line 6. While anaphora mal” would allow a note sentence “CV: normal
occurs in all naturally generated language, in con- rhythm” as well as “skin: intact, no lacerations”.
11Finally, there are different levels of abstractive sum- Clinical Language Generation from Conversa-
marization over multiple statements, questions and tion (Finley et al., 2018) produced dictation parts
answers as shown in the Table 2 examples. of a report, measuring performance both on gold
standard transcripts and raw ASR output using sta-
3 Related Work tistical MT methods. In (Liu et al., 2019), the
authors labeled a corpus of 101K simulated con-
Clinical Conversation Language Understand- versations and 490 nurse-patient dialogues with
ing Language understanding of clinical conversa- artificial short semi-structured summaries. They
tion can be traced to a plethora of historical work experimented with different LSTM sequence-to-
in conversation analysis regarding clinician-patient sequence methods, various attention mechanisms,
interactions (Byrne and Long, 1977; Raimbault pointer generator mechanisms, and topic informa-
et al., 1975; Drass, 1982; Cerny, 2007; Wang et al., tion additions. (Enarvi et al., 2020) performed sim-
2018). More recent work has additionally included ilar work with sequence-to-sequence methods on a
classification of dialogue utterances into seman- corpus of 800K orthopaedic ASR generated tran-
tic categories. Examples include classifying dia- scripts and notes; (Krishna et al., 2020) on a corpus
logue sentences into either the target SOAP sec- of 6862 visits of transcripts annotated with clinical
tion format or by using abstracted labels consis- note summary sentences. Unlike most of previous
tent with conversation analysis (Jeblee et al., 2019; works, our task generates clinical note sentences
Schloss and Konam, 2020; Wang et al., 2020). The from labeled transcript snippets, which are at times
work of (Lacson et al., 2006) framed identifying overlapping and discontinuous. (Krishna et al.,
relevant parts of hemodialysis 118 nurse-patient 2020)’s CLUSTER2SENT oracle system does use
phone conversations as an extractive summariza- gold standard transcript “clusters”, though differ-
tion task. There has also been numerous works ent from our setup, outputs entire sections. While
related to identifying topics, entities, attributes, and this strategy presupposes an upstream conversation
relations from clinic visit conversation – using var- topic segmentation system1 as well as some extrac-
ious schemas (Jeblee et al., 2019; Rajkomar et al., tive summarization, generation based on smaller
2019; Du et al., 2019). Though clinic conversa- text chunks can lead to more controllable and accu-
tion language understanding is not explored in this rate natural language generation, critical character-
work, our automatic or manual sentence alignments istics in health applications.
methods produce the language understanding labels
that may to used to (a) model dialogue relevance, 4 Corpus Creation
(b) cluster dialogue topics, and (c) classify speak-
ing mode, e.g. dictation versus question-answers. Data The data set was constructed from clinical
encounter visits from 500 visits and 13 providers.
Clinic Visit Dialogue2note Sentence Alignment The data for each visit consisted of a visit audio
Creating a corpus of aligned clinic visit conversa- and clinical note. For each visit audio, speaker
tion dialogue sentences with corresponding clinical roles (e.g. clinician patient) were segmented and
note sentences is instrumental for training language labeled. Automatically generated speech to text for
generation systems. Early work in this domain in- each audio was manually corrected by annotators.
cludes that of (Finley et al., 2018), which uses Table 3 gives the summary statistics of the extracted
an automated algorithm based on some heuristics, visit audio. For all specialties, the average number
e.g. string matches, and merge conditions, to align of turns and sentences for transcript was 175 ±
dictation parts of clinical notes. In (Yim et al., 111 and 341 ± 214, for a total of 87725 turns and
2020), we annotated manual alignments between 170546 sentences. The number of sentences for
dialogue sentences and clinical note sentences for clinical note was 47 ± 24, for a total of 23421
the entire visit; however, the dataset was small and sentences. Table 4 shows the number of turns and
artificial (66 visits). Here we utilize this approach sentences per different types of speakers.
on real data and additionally provide an automatic We also combined our data with external data,
sentence alignment baseline system. To our knowl- the mock patient visit (MPV) dataset, from (Yim
edge, this is the first work to propose an automated
sentence alignment system for entire clinic visit 1
A system that divides conversations into segments accord-
dialogue and note pairs. ing to topics
12et al., 2020) to create a total of 566 visits.2
specialty providers visits duration speakers
ENT 1 68 10 ± 4 4±1
HAND 1 43 10 ± 4 3±1
ORTHO 1 27 11 ± 5 4±1
PODIATRY 4 174 7±4 3±1
Figure 1: Annotation match tree
PRIMARY 6 188 17 ± 9 4±1
TOTAL 13 500 12 ± 8 4±1
Table 3: Source audio statistics
“it lasted about a week.”
QA: Questions and answers spoken by any
Annotations Each annotation is based on a participant in a clinic visit in natural conversation,
clinical note sentence association with multiple e.g. “how long has the runny nose lasted? about a
transcript sentences. A note sentence can be week.”
associated with zero transcript sentences and an INFERRED-OUTSIDE: Clinical note sentences
INFERRED-OUTSIDE label for default template for which information comes from a known tem-
values, e.g. “cv: normal”. One may also be plate’s default value rather than the conversation,
associated with sets of transcript sentences and e.g.“skin: intact.”
a set tag, e.g. DICTATION or QA (described
below). Finally, when multiple sets have anaphoric If after applying all possible associations and still
references, they may be tied together using a there is information in the note sentence not avail-
GROUP label. Given this hierarchy, the annotation able from the transcript, then an INCOMPLETE
related to a single note sentence can be represented tag is added. A note sentence is left unmarked if
as a tree as shown in Figure 1. no information can be found from the transcript.
Table 2 shows label annotations with color coding
Set labels for a full abbreviated transcript-note pair.
COMMAND: Spoken by the clinician to the scribe To measure interannotaor agreement, we cal-
to make a change to the clinical note structure, e.g. culated the triple, path, and span metrics intro-
“add skin care macro.” duced in (Yim et al., 2020), briefly described
DICTATION: Spoken by the clinician to the scribe again here. The triple, path, and span metrics
where the output text is expected to be almost were defined based on instances constructed from
verbatim, though with understood changes in the annotation tree representation. Specifically,
abbrevations, number expressions, and language for the triple metric, which measures unlabeled
formatting commands, e.g. “return in four to five note to dialogue sentence match, instances are
days period.” defined by note sentence id and transcript sen-
STATEMENT2SCRIBE: Spoken by the clinician tence id per visit, e.g. ‘visitid_01|note_0|3’. The
to the scribe where information is communicated second metric, similar to the leaf-ancestor met-
informally, e.g. “okay so put down heart and lungs ric used in parsing, takes into account the full
were normal” path from one note sentence to one dialogue sen-
STATEMENT: Statements spoken by any partici- tence, e.g. ‘visitid_01|note_0|GROUP|QA|3’. The
pant in a clinic visit in natural conversation, e.g. span metric, similar to that of PARSEVAL, mea-
2
To normalize for annotation differences between the
sures a node-level labeled span of dialogue sen-
Mock Patient Visits (MPV) and our corpus, we removed tences, e.g. for the top group node would be
INFERRED-DIALOGUE labels, reattached REPEATS to a ‘visitid_01|note_0|GROUP|[10,12,13,14]’ (Samp-
higher node, and moved all GROUP labels to the highest node.
son and Babarczy, 2003). When testing agreement,
labels for each annotator are decomposed to these
speaker sentences turns instance collections; true positive, false positive,
clinician_primary 99421 42480 and false negatives may be counted by the matches
patient 56052 36059
other 15073 9186 and mismatches between annotators. F1 score is
TOTAL 170546 87725 calculated as usual. The different definitions allow
both relaxed (triple) and stricter (path and span)
Table 4: Speaker statistics agreement measurements.
13You can also read

















































