SMS based FAQ Retrieval for Hindi, English and Malayalam
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
SMS based FAQ Retrieval for Hindi, English and Malayalam
Anwar Dilawar Shaikh Rajiv Ratn Shah Rahis Shaikh
Department of Computer School of Computing Department of Computer
Science and Engineering National University of Science and Engineering
Delhi Technological University Singapore Vellore Institute of Technology
Delhi, India Singapore, Singapore Vellore, India
anwardshaikh@gmail.com rajiv@comp.nus.edu.sg rais137123@gmail.com
ABSTRACT Keywords
This paper presents our approach for the SMS-based FAQ FAQ retrieval, SMS query, SMS processing, TF-IDF, simi-
Retrieval monolingual task in FIRE 2012 and FIRE 2013. larity score, proximity score, length score
Current approach predicts the matching of an SMS and
FAQs more accurately as compared to our previous solu- 1. INTRODUCTION
tion for this task which was submitted in FIRE 2011. We
Short Message Service (SMS) is the one of the easiest,
provide solution for SMS and FAQs matching in Malayalam
fastest and most popular way of communication in mod-
language (an Indian language) in addition to Hindi and En-
ern era due to ubiquitous availability of mobile devices. The
glish this time. In order to perform a matching between SMS
number of mobile subscriptions increasing rapidly and reaches
queries and FAQ database, we introduce enhanced similar-
close to seven billion users in the world [23]. Total mobile
ity score, proximity score, enhanced length score and an an-
subscribers in India and China alone consists of one-third
swer matching system. We introduce the stemming of terms
mobile subscribers of the world but majority of them still us-
and consider the effects of joining adjacent terms in SMS
ing normal phones without internet connectivity. Moreover,
query and FAQ to improve the similarity score. We pro-
the internet penetration on mobile devices (smart-phones)
pose a novel method to normalize FAQ and SMS tokens to
is also not good in India and China as compared to the
improve the accuracy for Hindi language. Moreover, we sug-
high number of mobile subscribers due to high internet data
gest a few character substitutions to handle error in the SMS
charges. Therefore, information access on move is not fea-
query. We demonstrate the effectiveness of our approach by
sible to these users. However, these users can be benefited
considering many real-life FAQ-datasets provided by FIRE
from SMS services on mobile devices due to its cheap com-
from a number of different domains such as Health, Tele-
munication and ubiquitous availability. Moreover, any user
com, Insurance and Railway booking. Experimental results
who is connected to internet can also utilize this SMS-based
confirm that our solution for the SMS-based FAQ Retrieval
FAQ Retrieval for free using any freely available applications
monolingual task is very encouraging and among the top
such as whatsapp, viber, wechat and others, since, due to
submissions which performed very well for English, Hindi
technical advancement in mobile devices and wireless com-
and Malayalam. The Mean Reciprocal Rank (MRR) scores
munications these instant messaging applications allow peo-
for our approach are 0.971, 0.973 and 0.761 respectively for
ple to instantly communicate with others. Therefore, smart-
English, Hindi and Malayalam SMS-based FAQ Retrieval
phone users do not need to browse a number of web pages
monolingual task in FIRE 2012. Furthermore, our solution
to find the answer for any specific queries which they can
topped the task for Hindi language with MRR score equal
instantly and accurately receive using our SMS-based FAQ
to 0.971 in FIRE 2013. Our approach performs very well for
Retrieval system. This inspire us to think that SMS-based
English language as well in FIRE 2013 despite transcripts
FAQ Retrieval system is useful to all kind of users irrespec-
of the speech queries are included in test dataset along with
tive of smart-phone or normal phone user.
the normal SMS queries.
The system presented in this paper is our solution to the
FIRE 2012 and 2013 monolingual task on SMS-based FAQ
Categories and Subject Descriptors Retrieval. In SMS-based FAQ Retrieval monolingual task
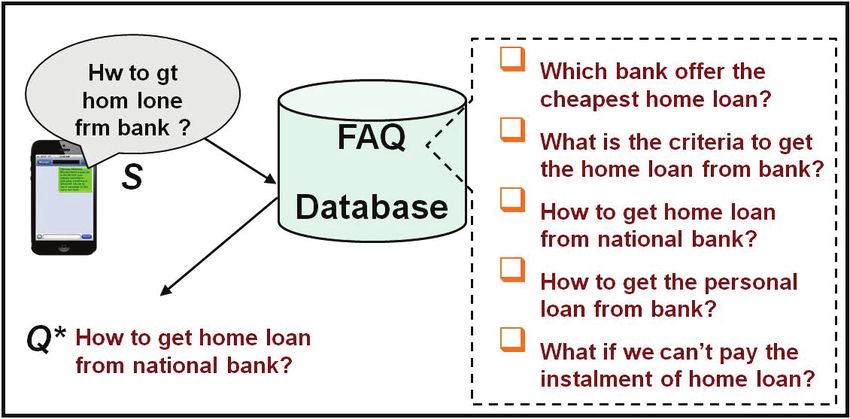
H.3.3 [Information Storage and Retrieval]: Information (see Figure 1), the language of query SMS (or transcribed
Search and Retrieval speech query) and language of FAQ database are same. The
goal is to find the best matching FAQ question (Q⋆ ) from
FAQ database for a query S (see Figure 2). Therefore, once
Permission to make digital or hard copies of all or part of this work for the system correctly predicts the question asked by the user
personal or classroom use is granted without fee provided that copies are not
made or distributed for profit or commercial advantage and that copies bear then a correct answer can be sent to the mobile user.
this notice and the full citation on the first page. Copyrights for components In order to find the matching FAQ for a query, our sys-
of this work owned by others than ACM must be honored. Abstracting with tem first do the pre-processing on query by removing all
credit is permitted. To copy otherwise, or republish, to post on servers or to stop-words and convert digits to their English words. In
redistribute to lists, requires prior specific permission and/or a fee. Request next step, we construct the candidate set (C) of FAQs from
permissions from Permissions@acm.org. different dictionary variant of tokens of query. Furthermore,
FIRE ’13, December 04–06, 2013, New Delhi, India
Copyright 2013 ACM 978-1-4503-2830-2/13/12 ...$15.00 we calculate the score comprising of similarity score, proxim-
http://dx.doi.org/10.1145/2701336.2701642. ity score and length score for each FAQ in the the candidate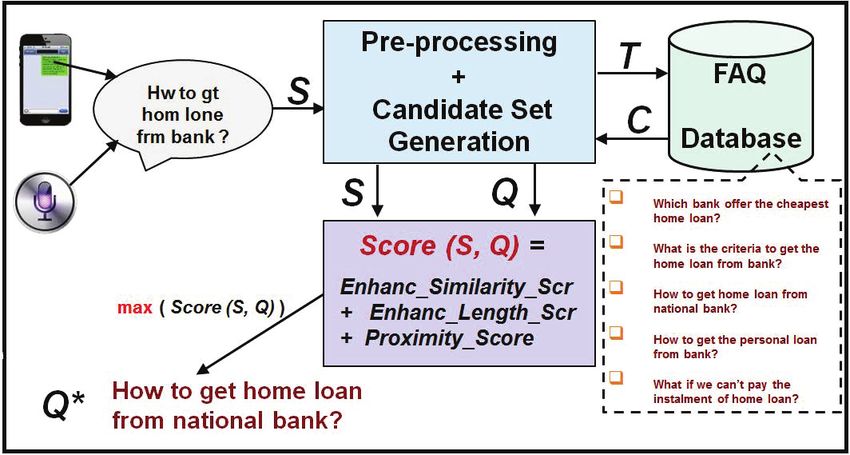
predict and provide solution to all such scenarios, since it is
a very subjective problem and change from person to per-
son. Contractor et al. [6] has introduced SMS-based FAQ
Retrieval task in FIRE 2011, 2012 and 2013 to get state-of-
the-art solutions for this problem. Many earlier work [10, 17,
20] have used SMSes to retrieve the information but their
Figure 1: SMS-based FAQ Retrieval Monolingual
limitation was that they work only for some pre-defined for-
task for Hindi, English and Malayalam languages.
mat of SMSes. Several earlier work [3, 9, 13, 14] suggested
Query SMS and FAQs are in the same language.
that N-gram based language model is very useful in text in-
formation retrieval. Hence, N-gram based matching between
an SMS and FAQs is useful in SMS-based FAQ retrieval sys-
tem [9]. In a recent work, Shah et al. [18] introduces the AT-
LAS system, which uses N-gram based language model to
determine the automatic temporal segmentation and anno-
tation of lecture videos. Many earlier work [11, 12, 19, 21]
have tried to solve this problem by introducing the meth-
ods to calculate the similarity between an SMS and a FAQ.
The FAQ having highest similarity with the SMS is consid-
ered as the matching FAQ for the SMS. Contractor et al. [5]
has proposed methods to handle noisy queries in cross lan-
guage FAQ retrieval environment. Many solutions [2, 8, 19]
Figure 2: Q* is the best matching question in the were proposed for SMS-based FAQ Retrieval task in FIRE
FAQ database for the Query S. 2011 but none of them performed very well for both in-
domain and out-of-domain queries. Several earlier work [1,
set. We calculate the enhanced similarity score with re- 4, 21, 22] have attempted to apply this system to appli-
spect to stemmed FAQ token and original FAQ token, and cations such as Final Exam Information Retrieval System,
consider the maximum similarity score. We employed the HIV/AIDS FAQ Retrieval System and others. However the
Porter Stemmer [16] to perform the stemming of English limitation of the most of the existing work is that they have
tokens. We also consider the concatenation of consecutive not considered the cross and multi language SMSes in their
terms while calculating the similarity score. Moreover, we evaluation, therefore, their solution might not be scalable.
also revised the length score formula of our previous work
for better matching of query and FAQs. We consider the
skippedFAQtokens (i.e. the words skipped during the cal- 3. SYSTEM OVERVIEW
culation of similarity score) in our enhanced length score Our system has several novel components which together
formula. To improve the matching accuracy of Hindi mono- form its innovative contributions. Figure 3 shows the overall
lingual task, we introduce the normalization of FAQs and a system framework with its main processing steps as follows:
query SMS. We replace some of the Hindi characters with
the similar characters to make them similar, since, these 1. Pre-processing is performed on an SMS query S.
characters does not change the meaning of the word (see Fig-
ure 4). To handle the noise in the SMS query in Hindi, we 2. Determine a ranked list of dictionary variants of token
perform the substitutions of few characters (see Figure 10). for each token Si ∈ S
Moreover, we perform the stemming of Hindi tokens using
Hindi Light Stemmer [7]. We also consider the Hindi Word- 3. Determine a Candidate Set C of FAQs
net [15] to find the synonyms to perform better matching.
For the monolingual task for Malayalam language, we up- 4. Calculate the Score(S, Q) for each Q ∈ C
date the stop word list and consider the enhanced similarity
score only in score calculation. The experimental results in 5. FAQ Q⋆ having the highest Score(S, Q) is considered
FIRE 2012 and 2013 have confirmed that our system find as matching FAQ for the SMS query S
the matching FAQ for a query very accurately.
The paper is organized as follows. In Section 2, we review We define the Score(S, Q) by the following equation in
the related work and Section 3 describes the working of our our previous work [19].
system. In Section 4, we present evaluation of our approach
and describe the experimental results. Finally, we conclude Score(S, Q) = W1 ∗ Similarity Score
the paper with conclusion in Section 5. +W2 ∗ Length Score
+W3 ∗ P roximity Score
2. RELATED WORK
Automatic SMS-based FAQ retrieval is a challenging task, where W1 , W2 and W3 are real valued weights such that
since incoming SMS has many misspellings, abbreviations, W1 + W2 + W3 = 1.
grammatical errors and may have cross and multi language
text. Moreover, many users are habitual of writing in En- In the current work, we propose methods to enhance the
glish language however the pronunciation of these terms Similarity Score and Length Score significantly to improve
have meaning in their local language and no meaning or the SMS and FAQ matching accuracy. Therefore, we define
different meaning in English dictionary. It is very hard to the Enhanced Score by the following equation.
study the effect of joining two consecutive terms in the SMS
Query and FAQ. Moreover we also apply stemming on FAQ
tokens to improve the Similarity Score(S, Q).
Two consecutive terms are concatenated in two stages.
First, during the preprocessing of the SMS text, join two
consecutive SMS words and perform matching with the sin-
gle FAQ word. Furthermore, match two consecutive FAQ
words with single SMS word and measure the similarity
(see Algorithm 1). For example, if an SMS query is ”Wat
r symptms of smll pox ?”, then after joining SMS terms,
it becomes ”Wat r symptms of smllpox ?”.
Algorithm 1 Joining words while performing similarity cal-
culation
Figure 3: System Overview: Q* having the high- 1: procedure JoinWordsInSMSPreProcessing(J1)
est score(S, Q) among all FAQ questions for an 2: INPUT: Two terms Si and Si+1 of an SMS S
SMS/speech transcribed query S. 3: OUTPUT: Join Si and Si+1 if applicable
4: for each SMS token Si do
5: if [ ! termExists(Si ) || ! termExists(Si+1 )] && [
Enhanced Score(S, Q) = W1 ∗ Enhanced Similarity Score termExists(concat( Si , Si+1 )) ] then
6: Si = concat( Si , Si+1 ))
+W2 ∗ Enhanced Length Score 7: end if
+W3 ∗ P roximity Score 8: end for
9: end procedure
3.1 Preprocessing
As described in our previous work [19], first we do pre- In the second stage, words are concatenated during the
processing of the FAQ database. We construct a domain process of matching an SMS with FAQ. For example, if an
and synonym dictionary from the FAQ database by con- SMS query is ”Hw to get home loan frm bank ?” and the
sidering both the questions and answers. Moreover, while corresponding FAQ is ”How to obtain homeloan from any
constructing the domain dictionary we do not consider the bank ?”. In this example, during preprocessing the words
stop-words from FAQs. We index the questions as well as home and loan are not joined together because both terms
the answers of the FAQ database for fast retrieval of FAQs home and loan are valid (these terms exists in the domain
from the database. We use the Lucene1 to index the token dictionary). Therefore, we calculate their weight by the fol-
of FAQs. We use the English Wordnet2 to construct the lowing equation.
synonym dictatory.
In the preprocessing of SMS query, first we remove all
stop-words. Furthermore, we convert the digits to corre- wi = α1 (Si + Si+1 , Fi ) ∗ idf (Fi )
sponding English words (e.g. 1, 2day, others to one, twoday
and others). wi = α1 (home + loan, homeloan) ∗ idf (homeloan)
Other case is also possible when concatenation of two
3.2 English Monolingual Task FAQ words match with single SMS term. For example,
We compute the Enhanced Length Score, P roximity Score if an SMS query is ”Hw to get homeloan frm bank ?” and
and Enhanced Similarity Score of Enhanced Score(S, Q) the corresponding FAQ is ”How to obtain home loan from
in the Sections 3.2.1, 3.2.2 and 3.2.3. any bank ?”. In this example, the SMS term homeloan
is formed by concatenation of two FAQ terms home loan,
3.2.1 Similarity Score Therefore it is necessary to join two FAQ terms and match
In our previous work [19], we use the Similarity Score as it with single SMS term. We calculate their weight by the
it is defined by Kothari et al. [11]. They define Similarity Score following equation.
by the following equation.
wi = α2 (Si , Fi + Fi+1 ) ∗ [idf (Fi ) + idf (Fi+1 )]/2
∑
n
Similarity Score(S, Q) = max w(t, si )
i=1 t∈Q and t∼si wi = α2 (homeloan, home + loan) ∗ [idf (home) + idf (loan)]/2
We take the average of the IDF of the ith FAQ term and
where w(t, si ) = α(t, si ) ∗ idf (t) (i+1)th to calculate the weight. So, while performing match
between SMS token and FAQ token, we consider these words
We observe that oftentimes many terms in an SMS have
together to find the best possible match (see Algorithm 2).
independent meaning but joining them gives another term
To further improve the matching between an SMS and
with similar or different meaning. Therefore, a word obtain
FAQ, we perform stemming using Porter Stemmer [16] be-
from joining two consecutive terms of SMS may match with
fore matching FAQ words and SMS words. We take the max-
the single FAQ word or viceversa. This motivates us to
imum similarity calculated w.r.t. stem FAQ token and non-
1
http://www.lucene.apache.org stem FAQ token. We define the Enhanced Similarity Score
2
http://www.wordnet.princeton.edu by the following equation.Algorithm 2 Joining words while performing similarity cal-
culation
1: procedure JoinWords(J2)
2: INPUT: An SMS S and a FAQ F
3: OUTPUT: A Similarity Score(S, F )
4: for each SMS token Si do
5: for each FAQ token Fi do
6: α1 = α(Si + Si+1 , Fi )
7: idf1 = idf (Fi )
8: α2 = α(Si , Fi + Fi+1 )
9: idf2 = [ idf (Fi ) + idf (Fi+1 ) ] / 2
10: if α1 > α2 then
11: wi = α1 ∗ idf1
12: else
13: wi = α2 ∗ idf2 Figure 4: Suggested replacement for Hindi task.
14: end if
15: end for
16: end for
17: end procedure
∑
n
Enhanced Similarity Score(Q, S) = max w(t, si )
i=1 t∈Q and t∼si
where w(t, si ) = max(α(t, si ) ∗ idf (t), α(tstem , si ) ∗ idf (t))
3.2.2 Length Score Figure 5: Example SMS queries from FIRE 2012
In our previous work [19], the Length Score is mainly de- test dataset.
pendent on the number of matched token between an SMS
and FAQ. It is defined by the following equation. totalF AQT oken
is the number of terms in FAQ question, totalSM ST oken is
the number of terms in SMS and matchedT oken stands for
number of SMS terms which matched from terms of FAQ matchedT okens
P roximity Score(S, Q) =
question. ((distance + 1) ∗ totalF aqT okens)
Length Score(S, Q) =
where totalF aqT okens = number of tokens in FAQ,
(totalF AQT oken − matchedT oken matchedT oken= number of matched token of SMS in FAQ.
1 + totalSM ST oken − matchedT oken
To calculate the Enhanced Length Score accurately we
consider the skippedF AQtoken in the new equation. The set ∑
n
skippedF AQtoken are the words skipped during the calcu- distance = d
lation of similarity score. These words are different from the k=1
stop-words. For example, what, when, where, which, while,
who, whom, why, will, with, would, yet, you, your and oth-
where d is the absolute difference between adjacent
ers are skippedF AQtoken Whereas some of the stop-words
are a, an, and, are, as, at, be, but, by, for, of, on, or, etc.) token pairs in SMS and corresponding pair in FAQ
Enhanced Length Score(S, Q) = and n = number of matched adjacent pairs in SMS
2 ∗ matchedT oken
totalSmsT oken + totalF aqT oken − 2 ∗ skippedF AQtoken 3.3 Hindi Monolingual Task
To improvement the monolingual SMS based retrieval task,
we introduce the normalization of FAQ and SMS. We re-
where, skippedF AQtoken are the words
place the some Hindi characters with the similar characters
skipped during the calculation of similarity score. to make them similar since in many cases these characters
do not change the meaning of the word (e.g. see Figure 4).
Figure 5 shows the example SMS queries provided in FIRE
3.2.3 Proximity Score 2012 dataset and Figure 6 shows the output of normalization
In the current work, we use same P roximity Score as de- and substitution step for these SMS queries. We describe the
fined in our previous work [19]. We define P roximity Score process of SMS and FAQ matching for Hindi language in the
by the following equation. following Sections 3.3.1, 3.3.2 and 3.3.3.Figure 8: Hindi vowels.
Figure 9: Hindi characters which are removed.
ming on Hindi terms. The stemmer removes number, gender
Figure 6: Examples of normalization and substa-
and case suffixes from nouns and adjectives (see Figure 11).
tions of Hindi SMS queries.
Moreover, we use Hindi Wordnet [15] to find the synonyms
of Hindi terms.
The final Enhanced Score(S, Q) for Hindi monolingual
task calculated similar to that of English monolingual task.
We use the same equation to compute P roximity Score,
Enhanced Length Score and Enhanced Similarity Score.
3.4 Malayalam Monolingual Task
For the Malayalam monolingual task, we only consider the
Figure 7: Pair of characters with similar meaning.
Enhanced Similarity Score while calculating total score.
We updated the stop-word list for Malayalam language while
SMS and FAQ preprocessing. Moreover, we have not used
3.3.1 Normalization of FAQ and SMS stemming and dictionary for this task.
There are pair of characters which have nearly similar pro-
nunciation in Hindi language. Therefore, we try to keep only 4. EVALUATION
one of such character to handle noise in the SMS queries,
since in many cases these characters do not change the mean- 4.1 Dataset and Experimental Settings
ing of the word. For example, characters of pairs in Figure 7 FIRE organizers have provided the FAQ dataset in Hindi,
are considered as same character. Furthermore, we group English and Malayalam languages (see Table 1). For the
similar vowels of Hindi together (see Figure 8). We also re- SMS-based FAQ Retrieval monolingual task, organizers have
moved a few character during normalization (see Figure 9). provided queries which have noisy spellings, poor grammar,
During the preprocessing of the FAQ, all these normal- slang, limited space, ambiguity. Each participants of the
ization rules are applied. The normalized FAQs are then task are run their solution on these test queries. FIRE 2011
stored in the FAQ INDEX. Similarly the SMS query is also and 2012 test queries only have SMS queries, however, FIRE
normalized before calculating any similarity score. 2013 test queries have normal SMS queries as well as the
speech transcribed queries having speech transcription er-
3.3.2 Substitution of Characters rors due to different accents, background noise, vocabulary,
We substitute a few characters and vowels as depicted in limited context and others (see Table 2).
Figure 10 to handle noise in the SMS query. Substitution is
done while performing match between an SMS token and a 4.2 RESULTS
FAQ token. If S1 is the SMS token and F1 is FAQ token, To evaluate the effectiveness of our approach, we run the
then, first, a match between S1 and F1 is performed. In the test queries provided by FIRE. In FIRE 2011, our earlier ap-
next step, substitution of characters in S1 and F1 is done as proach worked very well for in-domain queries but failed to
per the mapping given in Figure 10. perform well for out-domain queries. Our current approach
for FIRE 2012 and 2013 solves this problem and perform
S2 = Substitution(S1 )
F2 = Substitution(F2 )
Table 1: FIRE FAQ Dataset Description.
In the next step, we perform the matching between S2 FAQs Language # FAQs
and F2 . Maximum result out of two matches performed is
Hindi 1994
considered as the final similarity score between these tokens.
English 7251
3.3.3 Enhanced Score Computation for Hindi Malayalam 681
We use the Hindi light stemmer [7] to perform the stem- FAQ dataset for FIRE 2010, 2012 and 2013Table 2: SMS Test Queries Dataset Description.
FIRE SMS # SMS # SMS
Year Language In-domain Out-domain
Hindi 200 124
FIRE 2011
English 704 2701
Hindi 200 379
FIRE 2012 English 726 1007
Malayalam 69 11
Hindi 46 45
FIRE 2013
English 392 148
FIRE 2013 has speech queries for English language
as part of test queries. There are total 192 and 49
respectively in-domain and out-domain queries as
a subset of overall test queries.
Table 3: FIRE 2012 task results by our approach.
Monolingual In-domain Out-domain MRR
Task Correct Correct Score
English 686 / 726 986 / 1007 0.971
Hindi 186 / 200 376 / 379 0.973
Figure 10: Suggested substitution for Hindi task.
Malayalam 44 / 69 10 / 11 0.761
Figure 11: Example of Hindi terms stemming.
Table 4: FIRE 2013 task results by our approach.
Monolingual In-domain Out-domain MRR
Task Correct Correct Score
very well both in-domain and out-domain queries.
In FIRE 2012, organizers have given different set of SMS English 189 / 392 125 / 148 0.794
queries for Hindi, English and Malayalam language. Our Hindi 34 / 46 45 / 45 0.971
approach performed very well for Hindi and English mono- Accuracy of English is reduced for every team in FIRE
lingual task and performed well for Malayalam task (see Ta- 2013 due to introduction of speech transcribed queries
ble 3). The reason for relatively lower score for Malayalam which were VERY noisy as described by organizers.
task is due to not availability of any API for dictionary and
no knowledge about Malayalam language.
In FIRE 2013, organizers have introduced speech tran-
scribed queries along with normal SMS test queries from dif-
ferent domains. Our approach performed very well for Hindi
monolingual task and significantly well for English monolin-
gual task despite noise from speech transcription added to Table 5: Comparison of our approach with other
the test queries (see Table 4). teams for English monolingual task.
Figure 12 shows the performance of our approach and it’s Team In Out Team Team
comparison with other team’s solution for Hindi monolingual Name domain domain Score MRR
SMS-based FAQ Retrieval task in FIRE 2013. Our approach ISI-Calcutta 187 / 392 146 / 148 0.616 0.970
perform the best among all team’s solution, hence, our solu- DTU/TCS/BVP 179 / 392 105 / 148 0.526 0.930
tion is the state-of-the-art for Hindi monolingual SMS-based DTU/NUS/VIT 189 / 392 125 / 148 0.584 0.794
FAQ Retrieval system. ISM-Dhanbad_B 175 / 392 95 / 148 0.500 0.670
Figure 13 shows the performance of our approach and it’s DTU 177 / 392 85 / 148 0.485 0.630
comparison with other team’s solution for English monolin- ISM-Dhanbad_C 177 / 392 0 / 148 0.328 0.470
gual SMS-based FAQ Retrieval task in FIRE 2013. Our ap-
proach perform very well in this task as well and among the
top performing team for this task. For in-domain queries,handle errors in the SMS query for Hindi language, which
led our system to perform the best among all teams. Exper-
imental results confirm that our solution is the state-of-the-
art for SMS-based FAQ Retrival task for English and the
Indian languages such as Hindi and Malayalam, and can be
easily extended to work for other Indian languages. More-
over, it has potential to work for any language of the world
with a very little modification. As part of the future work,
we are extending our system such that only one system can
accurately match an SMS of any Indian languages by auto-
matically detecting the language in the SMS and exploit the
corresponding domain and synonym dictionary.
Figure 12: Our result represented in yellow and ACKNOWLEDGMENT
other team’s result in blue for Hindi monolingual
We are thankful to FIRE organizers for organizing SMS-
task in FIRE 2013.
based FAQ Retrieval task. We provide our sincere thanks
to Dr L Venkata Subramaniam and Dr Danish Contractor
for their continuous support and encouragement to complete
this task.
6. REFERENCES
[1] R. Ahmad, A. Sarlan, K. Maulod, E. M. Mazlan, and
R. Kasbon. Sms-based final exam retrieval system on
mobile phones. In International Symposium in Information
Technology (ITSim), volume 1, pages 1–5. IEEE, 2010.
[2] S. Bhattacharya, H. Tran, and P. Srinivasan. Data-driven
methods for sms-based faq retrieval. In Multilingual
Information Access in South Asian Languages, pages
104–118. Springer, 2013.
[3] W. Cavnar. Using an n-gram-based document
representation with a vector processing retrieval model.
NIST SPECIAL PUBLICATION SP, pages 269–269, 1995.
[4] J. Chen, L. Subramanian, and E. Brewer. Sms-based web
search for low-end mobile devices. In the sixteenth annual
International Conference on Mobile Computing and
Networking, pages 125–136. ACM, 2010.
[5] D. Contractor, G. Kothari, T. A. Faruquie, L. V.
Subramaniam, and S. Negi. Handling noisy queries in cross
Figure 13: Our result represented in yellow and language faq retrieval. In Conference on Empirical Methods
in Natural Language Processing, pages 87–96. ACL, 2010.
other team’s result in blue for English monolingual
[6] D. Contractor, L. V. Subramaniam, P. Deepak, and
task in FIRE 2013. A. Mittal. Text retrieval using sms queries: Datasets and
overview of fire 2011 track on sms-based faq retrieval. In
Multilingual Information Access in South Asian Languages,
pages 86–99. Springer, 2013.
our solution predicted the highest number of correct FAQs [7] L. Dolamic and J. Savoy. Comparative study of indexing
and for out-domain queries, our solution predicted the 2nd and search strategies for the hindi, marathi, and bengali
highest number of correct FAQs for this task (see Table 5). languages. ACM Transactions on Asian Language
Therefore, our solution is the one of the state-of-the-art for Information Processing (TALIP), 9(3):11, 2010.
English monolingual SMS-based FAQ Retrieval task as well. [8] D. Hogan, J. Leveling, H. Wang, P. Ferguson, and
C. Gurrin. Dcu@ fire 2011: Sms-based faq retrieval. In third
Workshop of the Forum for Information Retrieval
5. CONCLUSION Evaluation, FIRE, pages 2–4, 2011.
The proposed system provides a novel and time-efficient [9] M. JAIN. N-Gram Driven SMS Based FAQ Retrieval
way to automatically determine the matching FAQs for an System. PhD thesis, DELHI COLLEGE OF
ENGINEERING DELHI, 2012.
input SMS in English, Hindi and Malayalam languages. We
[10] S. K. Kopparapu, A. Srivastava, and A. Pande. Sms based
introduce similarity score, proximity score, length score, an natural language interface to yellow pages directory. In
answer matching system, stemming of terms and joining ad- fourth International Conference on Mobile Technology,
jacent terms in SMS query and FAQ for accurate matching Applications, and Systems and the first International
between the SMS and FAQs. The accuracy of our SMS- Symposium on Computer Human Interaction in Mobile
based FAQ retrieval system for Hindi language is the best Technology, pages 558–563. ACM, 2007.
among all teams with the MMR score 0.971. Moreover, the [11] G. Kothari, S. Negi, T. A. Faruquie, V. T. Chakaravarthy,
and L. V. Subramaniam. Sms based interface for faq
accuracy of our SMS-based FAQ retrieval system for En- retrieval. In the Joint Conference of the 47th Annual
glish and Malayalam languages is among the top performing Meeting of the ACL and the 4th International Joint
teams. We propose a novel method to normalize FAQ and Conference on Natural Language Processing of the
SMS tokens, and suggest a few character substitutions to AFNLP: Volume 2-Volume 2, pages 852–860. ACL, 2009.[12] J. Leveling. On the effect of stopword removal for
sms-based faq retrieval. In Natural Language Processing
and Information Systems, pages 128–139. Springer, 2012.
[13] P. Mcnamee and J. Mayfield. Character n-gram
tokenization for european language text retrieval.
Information Retrieval, 7(1-2):73–97, 2004.
[14] M. Morita and Y. Shinoda. Information filtering based on
user behavior analysis and best match text retrieval. In
Seventeenth annual International ACM SIGIR Conference
on Research and Development in Information Retrieval,
pages 272–281. Springer-Verlag New York, Inc., 1994.
[15] D. Narayan, D. Chakrabarty, P. Pande, and
P. Bhattacharyya. An experience in building the indo
wordnet-a wordnet for hindi. In First International
Conference on Global WordNet, Mysore, India, 2002.
[16] M. Porter. Snowball: A language for stemming algorithms,
2001.
[17] R. Schusteritsch, S. Rao, and K. Rodden. Mobile search
with text messages: designing the user experience for google
sms. In CHI’05 extended abstracts on Human Factors in
Computing Systems, pages 1777–1780. ACM, 2005.
[18] R. R. Shah, Y. Yu, A. D. Shaikh, S. Tang, and
R. Zimmermann. ATLAS: Automatic Temporal
Segmentation and Annotation of Lecture Videos Based on
Modelling Transition Time. 2014.
[19] A. D. Shaikh, M. Jain, M. Rawat, R. R. Shah, and
M. Kumar. Improving accuracy of sms based faq retrieval
system. In Multilingual Information Access in South Asian
Languages, pages 142–156. Springer, 2013.
[20] E. Sneiders. Automated question answering using question
templates that cover the conceptual model of the database.
In Natural Language Processing and Information Systems,
pages 235–239. Springer, 2002.
[21] E. Thuma, S. Rogers, and I. Ounis. Evaluating bad query
abandonment in an iterative sms-based faq retrieval
system. In tenth Conference on Open Research Areas in
Information Retrieval, pages 117–120. LE CENTRE DE
HAUTES ETUDES INTERNATIONALES
D’INFORMATIQUE DOCUMENTAIRE, 2013.
[22] E. Thuma, S. Rogers, and I. Ounis. Detecting missing
content queries in an sms-based hiv/aids faq retrieval
system. In Advances in Information Retrieval, pages
247–259. Springer, 2014.
[23] Wikipedia. List of countries by number of mobile phones in
use.
http://en.wikipedia.org/wiki/List_of_countries_by_number_of_mobile_phones_in_use,
2014. [Online; accessed 1-July-2014].You can also read

















































