SPEAKER DIARIZATION WITH SESSION-LEVEL SPEAKER EMBEDDING REFINEMENT USING GRAPH NEURAL NETWORKS - Unpaywall
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
SPEAKER DIARIZATION WITH SESSION-LEVEL SPEAKER EMBEDDING REFINEMENT
USING GRAPH NEURAL NETWORKS
Jixuan Wang1,2∗ , Xiong Xiao3 , Jian Wu3 , Ranjani Ramamurthy3 , Frank Rudzicz1,2 , Michael Brudno1,2
1
University of Toronto, Canada 2 Vector Institute, Canada 3 Microsoft, USA
1,2
{jixuan, frank, brudno}@cs.toronto.edu 3 {xioxiao, jianwu, ranjanir}@microsoft.com
arXiv:2005.11371v1 [eess.AS] 22 May 2020
ABSTRACT
Deep speaker embedding models have been commonly used
as a building block for speaker diarization systems; however,
the speaker embedding model is usually trained according to
a global loss defined on the training data, which could be sub-
optimal for distinguishing speakers locally in a specific meeting
session. In this work we present the first use of graph neural
networks (GNNs) for the speaker diarization problem, utilizing
a GNN to refine speaker embeddings locally using the struc-
tural information between speech segments inside each session.
The speaker embeddings extracted by a pre-trained model are
remapped into a new embedding space, in which the different
speakers within a single session are better separated. The model
is trained for linkage prediction in a supervised manner by min-
imizing the difference between the affinity matrix constructed
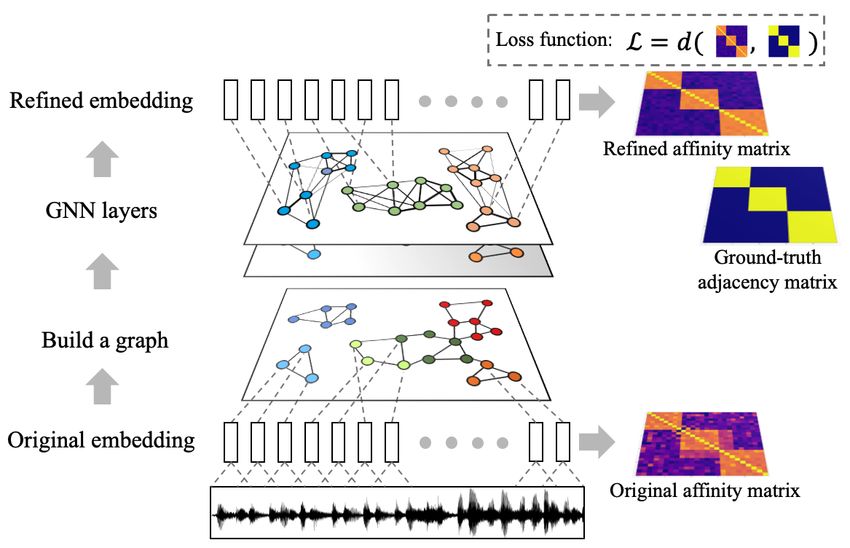
by the refined embeddings and the ground-truth adjacency ma- Fig. 1. Overview of the proposed method. A graph is con-
trix. Spectral clustering is then applied on top of the refined structed for each session using speaker embeddings extracted
embeddings. We show that the clustering performance of the by a pre-trained speaker embedding model. A GNN model is
refined speaker embeddings outperforms the original embed- applied to remap the original embedding into another embed-
dings significantly on both simulated and real meeting data, and ding space which is trained according to a loss function defined
our system achieves the state-of-the-art result on the NIST SRE by the difference between the refined affinity matrix and the
2000 CALLHOME database. ground-truth adjacency matrix.
Index Terms— Speaker diarization, graph neural networks,
deep speaker embedding.
(AHC) [15], spectral clustering (SC) [16] and affinity propaga-
tion [17]. Although deep learning methods driven by large scale
1. INTRODUCTION datasets have dominated the fields of speaker and speech recog-
nition, it is still non-trivial to design an end-to-end objective
Speaker diarization is the problem of “who spoke when”. A typ-
function for the speaker diarization problems which is permu-
ical speaker diarization system usually contains multiple steps.
tation invariant in terms of both the speaker order and speaker
First, the non-speech parts are filtered out by voice activity de-
number. Most recently there have been several end-to-end ap-
tection (VAD). Second, the speech parts are split into small ho-
proaches that either utilize a factored generative model [13] or
mogeneous segments either uniformly or according to the de-
are trained according to a permutation-free loss [18].
tected speaker change points. Third, each segment is mapped
In this paper, we consider a task upstream of speaker di-
into a fixed dimensional embedding, such as i-vector [1], x-
arization. We suggest that the speaker diarization models could
vector [2] or d-vector [3, 4, 5, 6, 7]. Finally clustering methods
be further improved by locally refining the speaker embedding
or end-to-end approaches are applied to generate the diariza-
for each session. The speaker embedding models are usually
tion results [8, 9, 10, 11, 12, 13]. Usually a classifier needs
designed to generalize well across a large range of speakers
to be trained for similarity scoring for i-vectors and x-vectors,
with different characteristics. However, speaker diarization is a
while similarities between d-vectors can usually be measured
simpler task compared with speaker recognition in the perspec-
by simple distance metrics, e.g. cosine or Euclidean distance.
tive of distinguishing speakers: we only care about separating
Commonly-used clustering methods for speaker diarization
several speakers for each session.
include K-means [14], agglomerative hierarchical clustering
Our approach is to refine speaker embeddings by improving
∗ Initial work by first author done as an intern at Microsoft. their performance for similarity measurement between speechsegments. Obviously, if we could correctly predict for each pair mulated as the prediction of yi for each segment embedding xi
of speech segments whether they belong to the same speaker such that yi is equal to yj if and only if xi and xj belong to the
or not, the diarization problem would be solved. Our method same speakers, i, j ∈ {1, 2, . . . , N }.
utilizes local structural information existing among the speaker
embedding spaces for each session. The structural information
2.2. Graph neural networks
is expressed by a graph built upon the speech segments for each
session. The task of predicting similarities between pairs of We apply several variants of GNNs falling into the framework
nodes is analogous to the link prediction task on graphs. Our of message passing neural networks (MPNNs) [25]. Under the
model can be seen as a neural link predictor [19, 20, 21] con- MPNN framework, the convolutional operator is expressed as a
sisting of an encoding component and a scoring component. message passing scheme:
The encoding component includes GNN [22, 23, 24, 25] lay-
ers to map speaker embeddings into another embedding space. x0i = γΘ xi , j∈N (i) φΘ (xi , xj , ei,j )
(1)
Fully connected layers or cosine similarity is used as the scor-
ing component. To train the model, a loss function is defined where xi is the feature of node i in the current layer with dimen-
as the difference between the affinity matrix constructed by the sion D, x0i is the node feature in the next layer with dimension
refined embeddings and the ground-truth adjacency matrix. By D0 , ei,j is the edge feature from node i to node j , γ(·) and φ(·)
minimizing this loss the model will be able to refine the original are the update function and message function, respectively, pa-
embeddings so that different speakers could be better separated rameterized by Θ, and denotes the aggregation function, e.g.,
within each session. sum, mean, max, etc.
Very recently (and in parallel to this work), Lin et al. [26] One GNN variant we apply is the graph convolutional net-
proposed the use of LSTMs to improve similarity measurement work (GCN) described by [24] in which the function cor-
for speaker diarization. Unlike their work, we utilize the struc- responds to taking a certain weighted average of neighboring
tural information in the embedding space instead of utilizing nodes. The updating scheme between two layers is:
the temporal information in label sequences. Also our model
not only outputs better similarity measurement but also refined X
speaker embeddings, which could be potentially fed into non- x0i = σ W Lij xj , (2)
clustering-based methods. Our model also achieves better per- j
formance with the same experimental setup. Experiments on
both simulated and real meeting data show that the performance where L = D̂−1/2 ÂD̂−1/2 is the normalized affinity matrix
of speaker number detection and speaker diarization with the added by self connection, Â = A + IN , D̂ denotes the degree
0
refined embeddings outperforms the original embeddings sig- matrix of Â, W ∈ RD ×D is a layer-specific trainable weight
nificantly, and our system achieves the state-of-the-art result on matrix, and σ(·) is a nonlinear function.
the NIST SRE 2000 CALLHOME database.
2.3. Model design
2. GRAPH BASED SPEAKER DIARIZATION
Our model consists of two components: an encoding compo-
2.1. Building graphs of speech segments nent and a scoring component. GNN layers are applied as
the encoding component. No nonlinear functions are applied
A graph is built for each session using the pretrained speaker between the GNN layers. Because the speaker embeddings are
embeddings. Each node represents an audio segment which already well trained, adding nonlinearity may lose informa-
could be word-level, utterance-level, or extracted by a sliding tion inside the original embeddings and result in worse results.
window with a fixed sliding step. Speaker embedding of each The encoding component generates the refined embeddings,
segment is extracted as the node features. The weight of edges of which every pair are concatenated as inputs to the scoring
between nodes is represented by the PLDA scores or cosine component.
similarities between the corresponding x-vectors and d-vectors, Due to the distinct nature of x-vectors and d-vectors, differ-
respectively. We only keep edges of weight larger than a thresh- ent scoring components are designed. For d-vectors, it is com-
old, which is treated as a hyperparameter. mon to leave the complexity to the model and use a simple dis-
Formally, each meeting session can be represented as a tance metric, e.g. cosine distance. Since the original d-vectors
graph G(V, E, A), where V is the set of nodes (speech seg- are trained for being comparable by a simple distance metric,
ments), E is the set of edges, and A ∈ N × N is the affinity we keep using this distance metric for scoring the refined em-
matrix with Aij > 0 if edge eij = (vi , vj ) ∈ E and Aij = 0 beddings. For x-vectors, on the other hand, an additional classi-
otherwise. The matrix of d-vectors X ∈ RN ×D can be treated fier, e.g. PLDA, is usually trained to measure the similarity. In
as node features for graph G , where N is the total number our model, we add fully connected layers with nonlinear func-
of segments and D is the dimension of the embedding space. tions after the GNN layers, which is actually a classifier on top
The features of each node vi are represented by a d-vector xi , of the refined embeddings. This classifier is trained together
i ∈ 1, 2, . . . , N . The goal of speaker diarization can be for- with the GNN layers.2.4. Loss function by a sigmoid function. The GCN layers are implemented with
the PyTorch Geometric library [32].
We train the GNN model w.r.t. a loss function that is defined
Similar to previous work [13, 26], we conducted 5-fold
as the difference between the affinity matrix constructed by the
cross validation. The dataset contains 500 sessions in total,
refined embedding and the ground-truth adjacency matrix. This
which is uniformly split into 5 subsets of 100 sessions for eval-
is actually a binary classification of linkage for all pairs of seg-
uation. In each turn, the model is trained for 50 epochs on
ments inside each session. For the x-vector based system, we
400 sessions with an initial learning rate of 0.001 reduced by a
simply applied the binary cross entropy (BCE) loss on all pairs
factor of 10 after 40 epochs. The optimal threshold for speaker
of segments for each session.
number detection on the training set is used for evaluation on
However, this simple loss function does not work for d-
the testing set. A graph is built for each session on which we
vectors. Due to the simplicity of the distance metric used, the
connect a pair of nodes if their PLDA score is higher than 0.2.
gradient would be very noisy if training the model w.r.t. the ex-
The model is trained in a session-by-session fashion that each
act match between the cosine similarities and ground-truth 1s
batch contains a single graph constructed from one session. All
or 0s. Instead we applied the following loss function:
the hyperparameters are tuned on a validation set split from the
training set for each turn. Results are shown in Table 1 and
L = hist loss(A, Agt ) + α · kA − Agt knuclear , (3)
summarized in the following section.
in which hist loss corresponds to the histogram loss [27],
k·knuclear is the nuclear norm between A and the ground-truth Table 1. DER (%) on the NIST SRE 2000 CALLHOME
adjacency matrix Agt , and α is a scalar value hyperparameter. dataset. SC refers to spectral clustering and AHC to agglom-
Histogram loss tries to ensure the distance between pairs of seg- erative hierarchical clustering.
ments belonging to different speakers is larger than the distance
between those belonging to the same speakers. The nuclear Method DER(%)
norm, which is the sum of singular values of a matrix [28] x-vector + PLDA + AHC (5-fold) 8.64
depends on the rank match between A and Agt , instead of Baseline
x-vector + PLDA + SC (5-fold) 8.05
an exact match. The combination of these two loss functions Wang et al. [12] 12.0
achieves similarity scores that stay in a reasonable range. Sell et al. [33] 11.5
Recent
Romero et al. [34] 9.9
Work
2.5. Spectral clustering Zhang et al. [13] (5-fold) 8.5
Lin et al. [26] (5-fold) 7.73
We use spectral clustering as our backend method and follow
Ours GNN based (5-fold) 7.24
the standard steps described in [16]. However, to detect the
speaker number, we first perform eigen-decomposition on the
refined affinity matrix and then determine the speaker number
by the number of eigenvalues that are larger than a threshold, 3.2. Speaker diarization results
which we treat as a tunable parameter. As shown in Section 4.2,
this method outperforms the commonly used method based on We compare speaker diarization error rate (DER) of our model
maximal eigengap. with several recent works. We achieve state-of-the-art perfor-
mance resulting in a DER of 7.24%, which outperforms both
the baselines and all recent works. For fairness, we only include
3. EXPERIMENTS WITH X-VECTORS
the results without system fusion of [26]. We only include the
result with in-domain training of [13]. The DER of [13] with
3.1. Datasets and implementation details
external data is 7.6% which is still worse than our result. Also
To compare our x-vector-based systems with other meth- the speaker embedding model of [13] was trained on a much
ods, we follow the evaluation steps described in the call- larger dataset than the one we are using, which may also influ-
home diarization/v2 receipe of Kaldi [29]. We used the pre- ence the results.
trained x-vector model and PLDA scoring model trained on
augmented Switchboard and NIST SRE datasets [30]. Results
4. EXPERIMENTS WITH D-VECTORS
on the commonly used dataset NIST SRE 2000 CALLHOME
(LDC2001S97) Disk 8 are reported. 4.1. Datasets and implementation details
Our model architecture includes two GCN [24] layers fol-
lowed by two fully connected layers. Input x-vector is 128- For d-vector-based system, we trained the model on simulated
dimensional. The dimension of output embedding from the conversations and evaluated it on real meetings. The d-vector
GCN layers is 64, of which every pair is concatenated as a 128- extraction model is trained and fake meetings are simulated
dimensional input to the following fully connected layers. The from the VoxCeleb2 dataset [35]. For each simulated meeting,
first fully connected layers is 64-dimensional with the ELU acti- we randomly select 2-15 speakers from the training set of Vox-
vation function [31] and the last layer has 1 dimension followed Celeb2 as the meeting participants. And for each speaker, 2-60speech segments with duration of 1.5s are sampled. Moreover, mance of the threshold-based method with original embeddings
we use 45 sessions of in-house real meetings as another test- degrades on the out-of-domain (in-house meeting) dataset. This
ing set. On average, each meeting contains 6 speakers, ranging is likely because original embeddings are less robust with re-
from 2 to 16. The average duration of meeting sessions is about spect to the threshold, while the refined embeddings are robust
30 minutes. even with a threshold tuned on a different dataset. Conse-
To build the graphs, we only connect a pair of speech seg- quently the threshold-based method with refined embeddings
ments if the cosine similarity between their d-vectors is larger significantly outperforms other approaches on both in-domain
than a threshold 0.2, which is tuned on the validation set. Our and out-of-domain datasets.
model contains two GCN layers, of which the hidden dimension
and output dimension are both equal to the input dimension of
Table 2. Mean error of speaker number detection (first two
128. We used 150 bins for the histogram loss. The DER re-
rows) and DER (last row) for the eigengap-based (gap) method
ported only includes speaker confusion.
and the threshold-based method (thred) using original (O) and
refined (R) embeddings, respectively. The last line shows DER
4.2. Speaker number detection results improvement relative to O-gap.
We first evaluate the refined embedding for speaker number
Dataset O-gap O-thred R-gap R-thred
detection. We search for the optimal threshold for this task
VoxCeleb2 Test 4.77 1.56 2.64 1.03
through simulated conversations on the validation set. The
In-house meetings 3.23 4.39 2.86 1.20
threshold which achieves the lowest mean speaker number
In-house meetings
detection error across all simulated sessions is chosen for eval- 0% -116.7% 16.3% 73.7%
(Rel. DER reduction)
uation on testing set. As shown in Figure 2, the minimal error
achieved by the refined embeddings is lower than the original
embeddings with a threshold of 3.0 and 2.0, respectively. The
curved slope of the refined embeddings after the optimal thresh-
4.3. Speaker diarization results
old is lower than the original embeddings, which indicates that
speaker number detection with the refined embedding is more We compare the performance of spectral clustering on speaker
robust. diarization using both original and refined embeddings. The re-
sults in Table 2 are consistent with the results on speaker num-
ber detection. Here again using the threshold-based model us-
ing the original embeddings actually performs worse than the
eigengap-based method for the out-of-domain dataset. How-
ever the model using refined embeddings and the threshold-
based method for speaker number detection achieves a 73.7%
relative DER reduction compared to the model with the original
embeddings. This indicates that our system should be general-
izable to real world applications.
5. CONCLUSION
Fig. 2. Mean error of speaker number detection by different In this paper, we present the first use of GNNs for speaker di-
thresholds. The dashed line (original) refers to results with arization. A graph of speech segments is built for each meeting
the original speaker embeddings, while the solid line (refined) session and a GNN model is trained to refine the speaker em-
refers to results with the refined speaker embeddings. bedding utilizing the structural information in the graph. Our
model achieves the state-of-the-art performance on a public
dataset, while experiments on both simulated and real meetings
With the optimal threshold tuned on the validation set we
show that spectral clustering based on the refined embeddings
evaluate the performance of speaker number detection on two
can achieve much better performance than original embeddings
test sets: fake conversations simulated from the testing set
in terms of speaker number detection and clustering.
of VoxCeleb2 and an in-house meeting dataset, which are in-
domain and out-of-domain datasets respectively. As shown
in Table 2, the performance with refined embeddings outper- 6. ACKNOWLEDGEMENT
forms the original embeddings on both datasets with both the
eigengap-based method [12] and the threshold-based method. The authors would like to thank Tianyan Zhou and Yong Zhao
Intriguingly, while the threshold-based methods with orig- for providing the d-vector extraction model, and Chun-Hao
inal and refined embeddings outperform the eigengap-based Chang and Zhuo Chen for helpful discussions. Rudzicz is a
methods on the in-domain dataset (VoxCeleb2 Test), the perfor- CIFAR Chair in AI.7. REFERENCES [18] Yusuke Fujita, Naoyuki Kanda, Shota Horiguchi, Kenji Nagamatsu,
and Shinji Watanabe, “End-to-end neural speaker diarization with
[1] Najim Dehak, Patrick J Kenny, Réda Dehak, Pierre Dumouchel, and permutation-free objectives,” Proc. Interspeech 2019, pp. 4300–4304,
Pierre Ouellet, “Front-end factor analysis for speaker verification,” 2019.
IEEE Transactions on Audio, Speech, and Language Processing, vol. [19] Thomas N Kipf and Max Welling, “Variational graph auto-encoders,”
19, no. 4, pp. 788–798, 2010. arXiv preprint arXiv:1611.07308, 2016.
[2] David Snyder, Daniel Garcia-Romero, Gregory Sell, Daniel Povey, [20] Muhan Zhang and Yixin Chen, “Link prediction based on graph neural
and Sanjeev Khudanpur, “X-vectors: Robust dnn embeddings for networks,” in Advances in Neural Information Processing Systems,
speaker recognition,” in 2018 IEEE International Conference on 2018, pp. 5165–5175.
Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp.
[21] Maximilian Nickel, Kevin Murphy, Volker Tresp, and Evgeniy
5329–5333.
Gabrilovich, “A review of relational machine learning for knowledge
[3] Ehsan Variani, Xin Lei, Erik McDermott, Ignacio Lopez Moreno, and graphs,” Proceedings of the IEEE, vol. 104, no. 1, pp. 11–33, 2015.
Javier Gonzalez-Dominguez, “Deep neural networks for small foot-
[22] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi
print text-dependent speaker verification,” in 2014 IEEE International
Zhang, and Philip S Yu, “A comprehensive survey on graph neural
Conference on Acoustics, Speech and Signal Processing (ICASSP).
networks,” arXiv preprint arXiv:1901.00596, 2019.
IEEE, 2014, pp. 4052–4056.
[23] Hongyun Cai, Vincent W Zheng, and Kevin Chen-Chuan Chang, “A
[4] Hervé Bredin, “Tristounet: triplet loss for speaker turn embedding,”
comprehensive survey of graph embedding: Problems, techniques, and
in 2017 IEEE international conference on acoustics, speech and signal
applications,” IEEE Transactions on Knowledge and Data Engineer-
processing (ICASSP). IEEE, 2017, pp. 5430–5434.
ing, vol. 30, no. 9, pp. 1616–1637, 2018.
[5] Li Wan, Quan Wang, Alan Papir, and Ignacio Lopez Moreno, “Gen-
[24] Thomas N. Kipf and Max Welling, “Semi-supervised classification
eralized end-to-end loss for speaker verification,” in 2018 IEEE In-
with graph convolutional networks,” in 5th International Conference
ternational Conference on Acoustics, Speech and Signal Processing
on Learning Representations, ICLR 2017, Toulon, France, April 24-
(ICASSP). IEEE, 2018, pp. 4879–4883.
26, 2017, Conference Track Proceedings. 2017, OpenReview.net.
[6] Jixuan Wang, Kuan-Chieh Wang, Marc T Law, Frank Rudzicz, and
[25] Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals,
Michael Brudno, “Centroid-based deep metric learning for speaker
and George E Dahl, “Neural message passing for quantum chem-
recognition,” in ICASSP 2019-2019 IEEE International Conference
istry,” in Proceedings of the 34th International Conference on Machine
on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019,
Learning-Volume 70. JMLR. org, 2017, pp. 1263–1272.
pp. 3652–3656.
[26] Qingjian Lin, Ruiqing Yin, Ming Li, Hervé Bredin, and Claude Barras,
[7] Tianyan Zhou, Yong Zhao, Jinyu Li, Yifan Gong, and Jian Wu, “Cnn
“LSTM based Similarity Measurement with Spectral Clustering for
with phonetic attention for text-independent speaker verification,” in
Speaker Diarization,” 2019, HAL CCSD.
Proc. IEEE Workshop on Automatic Speech Recognition and Under-
standing, 2019. [27] Evgeniya Ustinova and Victor Lempitsky, “Learning deep embeddings
with histogram loss,” in Advances in Neural Information Processing
[8] Sylvain Meignier and Teva Merlin, “Lium spkdiarization: an open
Systems, 2016, pp. 4170–4178.
source toolkit for diarization,” 2010.
[28] Benjamin Recht, Maryam Fazel, and Pablo A Parrilo, “Guaranteed
[9] Stephen H Shum, Najim Dehak, Réda Dehak, and James R Glass, minimum-rank solutions of linear matrix equations via nuclear norm
“Unsupervised methods for speaker diarization: An integrated and it- minimization,” SIAM review, vol. 52, no. 3, pp. 471–501, 2010.
erative approach,” IEEE Transactions on Audio, Speech, and Lan-
guage Processing, vol. 21, no. 10, pp. 2015–2028, 2013. [29] “callhome diarization/v2 receipe of Kaldi,” https://github.
com/kaldi-asr/kaldi/tree/master/egs/callhome_
[10] Gregory Sell and Daniel Garcia-Romero, “Speaker diarization with diarization/v2, Accessed: 2019-10-15.
plda i-vector scoring and unsupervised calibration,” in 2014 IEEE
Spoken Language Technology Workshop (SLT). IEEE, 2014, pp. 413– [30] “SRE16 Xvector Model,” http://kaldi-asr.org/models/
417. m6, Accessed: 2019-10-15.
[11] Daniel Garcia-Romero, David Snyder, Gregory Sell, Daniel Povey, [31] Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter, “Fast
and Alan McCree, “Speaker diarization using deep neural network and accurate deep network learning by exponential linear units (elus),”
embeddings,” in 2017 IEEE International Conference on Acoustics, in 4th International Conference on Learning Representations, ICLR,
Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 4930–4934. 2016.
[12] Quan Wang, Carlton Downey, Li Wan, Philip Andrew Mansfield, and [32] Matthias Fey and Jan Eric Lenssen, “Fast graph representation learn-
Ignacio Lopz Moreno, “Speaker diarization with lstm,” in 2018 IEEE ing with pytorch geometric,” arXiv preprint arXiv:1903.02428, 2019.
International Conference on Acoustics, Speech and Signal Processing [33] G. Sell and D. Garcia-Romero, “Diarization resegmentation in the
(ICASSP). IEEE, 2018, pp. 5239–5243. factor analysis subspace,” in 2015 IEEE International Conference on
[13] Aonan Zhang, Quan Wang, Zhenyao Zhu, John Paisley, and Chong Acoustics, Speech and Signal Processing (ICASSP), April 2015, pp.
Wang, “Fully supervised speaker diarization,” in ICASSP 2019-2019 4794–4798.
IEEE International Conference on Acoustics, Speech and Signal Pro- [34] D. Garcia-Romero, D. Snyder, G. Sell, D. Povey, and A. McCree,
cessing (ICASSP). IEEE, 2019, pp. 6301–6305. “Speaker diarization using deep neural network embeddings,” in 2017
[14] Stuart Lloyd, “Least squares quantization in pcm,” IEEE transactions IEEE International Conference on Acoustics, Speech and Signal Pro-
on information theory, vol. 28, no. 2, pp. 129–137, 1982. cessing (ICASSP), March 2017, pp. 4930–4934.
[15] Lior Rokach and Oded Maimon, “Clustering methods,” in Data min- [35] Joon Son Chung, Arsha Nagrani, and Andrew Zisserman, “Voxceleb2:
ing and knowledge discovery handbook, pp. 321–352. Springer, 2005. Deep speaker recognition,” in Proc. Interspeech 2018, 2018, pp. 1086–
1090.
[16] Ulrike Von Luxburg, “A tutorial on spectral clustering,” Statistics and
computing, vol. 17, no. 4, pp. 395–416, 2007.
[17] Brendan J Frey and Delbert Dueck, “Clustering by passing messages
between data points,” science, vol. 315, no. 5814, pp. 972–976, 2007.You can also read

















































