Towards Knowledge Graphs Validation through Weighted Knowledge Sources
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Towards Knowledge Graphs Validation through
Weighted Knowledge Sources
Elwin Huaman1 ID
, Amar Tauqeer2 , Geni Bushati2 , and Anna Fensel1,3 ID
1
Semantic Technology Institute (STI) Innsbruck, Department of Computer Science,
arXiv:2104.12622v1 [cs.DB] 26 Apr 2021
University of Innsbruck, Austria
elwin.huaman@sti2.at
2
Department of Computer Science, University of Innsbruck, Austria
amar.tauqeer@student.uibk.ac.at, geni.bushati@student.uibk.ac.at
3
Wageningen University & Research, the Netherlands
anna.fensel@wur.nl
Abstract. The performance of applications, such as personal assistants,
search engines, and question-answering systems, rely on high-quality
knowledge bases, a.k.a. Knowledge Graphs (KGs). To ensure their quality
one important task is Knowledge Validation, which measures the degree
to which statements or triples of a Knowledge Graph (KG) are correct.
KGs inevitably contains incorrect and incomplete statements, which may
hinder the adoption of such KGs in business applications as they are not
trustworthy. In this paper, we propose and implement a validation ap-
proach that computes a confidence score for every triple and instance in
a KG. The computed score is based on finding the same instances across
different weighted knowledge sources and comparing their features. We
evaluated the performance of our Validator by comparing a manually
validated result against the output of the Validator. The experimental
results showed that compared with the manual validation, our Validator
achieved as good precision as the manual validation, although with cer-
tain limitations. Furthermore, we give insights and directions toward a
better architecture to tackle KG validation.
Keywords: Knowledge graph validation · Knowledge graph curation ·
Knowledge assessment.
1 Introduction
Over the last decade, creating and especially maintaining knowledge bases have
gained attention, and therefore large knowledge bases, also known as knowl-
edge graphs (KGs), have been created, either automatically (e.g. NELL), semi-
automatically (e.g. DBpedia), or through crowdsourcing (e.g. Freebase). Today,
open (e.g. Wikidata4 ) and proprietary (e.g. Knowledge Vault5 ) KGs provide in-
formation about entities like hotels, places, restaurants, as well as statements
4
https://wikidata.org
5
https://ai.google/research/pubs/pub456342 E. Huaman et al.
about them, e.g. address, phone number, and website. With the increasing use
of KGs in personal assistant and search engine applications, the need to en-
sure that statements or triples in KGs are correct arises [4,7,15]. For exam-
ple, Google shows the fact (Gartenhotel Maria Theresia GmbH, phone, 05223
563130 ), which might be wrong because the phone number of the Gartenhotel
is 05223 56313, moreover, there will be cases where the phone number is not
up-to-date or is missing [9].
To face this challenge, we developed an approach to validate a KG against
different knowledge sources. Our approach involves (1) mapping the different
knowledge sources to a Domain Specification6 (DS) which are design patterns
for annotating data based on Schema.org7 , (2) instance matching that ensures
that we are talking about the same entity across the different knowledge sources,
(3) confidence measurement, which computes a confidence score for each triple
and instance in the KG, and (4) visualization that offers an interface to interact
with. Furthermore, we describe use cases where our approach can be used.
There have been a few approaches proposed to validate KGs. In this paper,
we do a literature review of methods, tools, and benchmarks for knowledge
validation. However, most of them focus on validating knowledge against the
Web or Wikipedia. For example, the approaches measure the degree to which
a statement (e.g. Paris is the capital of France) is true based on the number
of occurrences of the statement in sources such as Wikipedia, websites, and/or
textual corpora. Therefore, we propose a weighted approach that validates a
KG against a set of weighted knowledge sources, which have different weight (or
degree of importance) for different application scenarios. For example, users can
define the degree of importance of a knowledge source according to the task at
hand. We validate a KG by finding the same instances across different knowledge
sources, comparing their features, and scoring them. The score ranges from 0 to
1, which indicates the degree to which an instance is correct.
This paper is structured as follows. Section 2 presents related state-of-the-art
methods, tools, and benchmarks. Section 3 describes our validation approach. We
evaluate our approach and show its results in Section 4. Furthermore, in Section
5 we list use cases where our approach may be needed. Finally, we conclude with
Section 6, providing some remarks and future work plans.
2 Literature Review
Knowledge Validation (KV), aka fact checking, refers to determine whether a
given fact or statement is true and correct [5,10,16,18,21]. There are currently
several state-of-the-art methods and tools available that are suitable for KV.
One of the prior works on automating this task focuses on analysing trustwor-
thiness factors of web search results (e.g. the trustworthiness of web pages based
on topic majority, which computes the number of pages related to a query) [13].
6
https://ds.sti2.org/
7
https://schema.org/Title Suppressed Due to Excessive Length 3
Another approach is proposed by [27]. Here, the authors define the trustworthi-
ness of a website based on the confidence of facts provided by the website, for
instance, they propose an algorithm called TruthFinder. Knowledge Vault [2] is a
probabilistic knowledge base that combines information extraction and machine
learning techniques to compute the probability that a statement is correct. The
computed score is based on knowledge extracted from the Web and corrobora-
tive paths found on Freebase. However, the Web can yield noisy data and prior
knowledge bases may be incomplete. Therefore, we propose an approach, which
can complement the existing probabilistic approaches. We surveyed methods for
validating statements in KGs and we distinguish them according to the data
used by them, a) internal approaches use the knowledge graph itself as input
and b) external approaches use external data sources (e.g. Freebase, Wikipedia)
as input.
Internal approaches These approaches rely on statements or triples that exist
within a KG. For instance, some methods identify triples as pieces of evidence to
support a particular triple [8,11,17,18,21]. Moreover, there exist approaches that
use outlier detection techniques to evaluate whether a property value is out of the
assumed distribution [21,23,26] and approaches that use embedding models [12].
Furthermore, we can mention some tools, like COPAAL8 and KGTtm9 that
evaluate possible interesting relationship between entity pairs (subject,object)
within a KG.
External approaches The external approaches use external sources like the
Freebase source to validate a statement. For instance, there are approaches that
use websites information [2,6,19], Linked Open Data datasets [20], Wikipedia
pages [3,14], DBpedia knowledge base [16], and so on. Furthermore, there are
methods that use topic coherence [1] and information extraction [19] techniques
to validate knowledge. Obviously, there is not only one approach or ideal solution
to validate KGs. The proposed tools –DeFacto10 , Leopard11 , FactCheck12 , and
FacTify13 – rely on the Web and/or external knowledge sources like Wikipedia.
In the context of this paper, we only consider the approaches that use external
knowledge sources for validating statements. The current Web-based approaches
can effectively validate knowledge that is well disseminated on the web, e.g.
Albert Einstein’s date of birth is March 14, 1879. Furthermore, the confidence
score is based on the number of occurrences of a statement in a knowledge
source. Alas, these approaches are also prone to spamming [22]. Therefore, a
new approach is necessary to further improve KG validation. In this paper, we
propose a KG validation approach, which computes a confidence score for each
triple and instance of KGs.
8
https://github.com/dice-group/COPAAL
9
https://github.com/TJUNLP/TTMF
10
https://github.com/DeFacto/DeFacto
11
https://github.com/dice-group/Leopard
12
https://github.com/dice-group/FactCheck
13
http://qweb.cs.aau.dk/factify/4 E. Huaman et al.
Furthermore, an evaluation of validation approaches is really important,
therefore, we also surveyed knowledge validation benchmarks that have been
proposed, however, there are currently a limited number of them. [25] and [3]
released labeled claims in the political domain, [24] released FEVER14 that
is a dataset containing 185K claims about entities which were verified using
Wikipedia articles. FactBench15 (Fact Validation Benchmark) provides a mul-
tilingual (i.e. English, German and French) benchmark that describes several
relations (e.g. Award, Birth, Death, Foundation Place, Leader, Publication Date
of books, and Spouse) of entities.
An interesting finding is that the reviewed approaches are mostly focused
on validating well disseminated knowledge than factual knowledge, furthermore,
benchmarks are built for validating specific tools or to be used during contests
like FEVER. Another interesting observation is that Wikipedia is the most fre-
quently used by external approaches. Last but not least, to make future works
on knowledge graph validation comparable, it would be useful to have a common
selection of benchmarks.
3 Approach
In this section, we present the conceptualization of our knowledge graph valida-
tion approach. First, we give an overview of the knowledge validation process
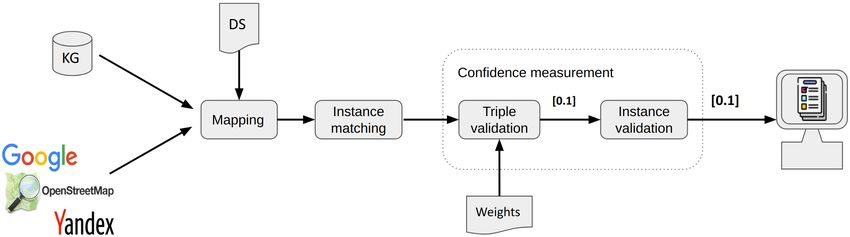
(see Fig. 1). Second, we state the input needed for our approach in Section 3.1.
In Section 3.2, we describe the need for a common attribute space between
knowledge sources. Then, in Section 3.3, we explain the instance matching pro-
cess we applied. Afterwards, confidence measurement of instances are detailed in
Section 3.4. Finally, in Section 3.5, we describe the output of our implemented
approach.
Fig. 1: Knowledge graph validation process overview.
At first, users are required to set their knowledge graph (KG) and domain
specification (DS) to the Validator. It requires a SPARQL endpoint where to
14
https://github.com/sheffieldnlp/fever-naacl-2018
15
https://github.com/DeFacto/FactBenchTitle Suppressed Due to Excessive Length 5
fetch the data from and a DS that defines the mapping between the knowledge
sources to a common format. Internally, the Validator has been configured to
retrieve data from three external sources which are also mapped to the common
format. After the mapping process has been done, the instance matching is
used to find the same instances across the KG and external sources. Then, the
confidence measurement process is triggered and the features of same instances
are compared with each other, for example, we compare the name value of an
instance of the KG against the name value of the same instance in Google places,
OpenStreetMaps, and Yandex. We repeat this process for every triple of an
instance and we compute a triple confidence score, the triple confidence scores
are later added to an aggregated confidence score for the instance. The computed
scores are normalized according to the weights given to each knowledge source.
We consider the quality of the external sources subjective, therefore, we provide
a graphical user interface that allows users to weight each knowledge source.
3.1 Input
At first step, a user is required to set a knowledge graph to be validated and a
domain specification. For this, the user has to set the SPARQL endpoint of his
or her KG (e.g. Tirol Knowledge Graph16 ) and a DS which defines the instance
type (e.g. Hotel) and features (e.g. email, name, phone) of instances to be vali-
dated. Internally, the Validator has been set to fetch data from Google Places,
OpenStreetMaps, and Yandex Places.
3.2 Mapping
Based on the DS defined in the input, the validator maps the input KG and the
external sources to a common format17 , e.g. a telephone number of a hotel can
be stored with different property names across the knowledge sources: phone,
telephone, or phone number. The validator provides a mapping feature to map
the input KG and external data sources to a common attribute space. In the
end, it facilitates the validation of the same properties across knowledge sources.
3.3 Instance Matching
So far, we map knowledge to a common attribute space. However, a major chal-
lenge is to match instances across these knowledge sources. For that, we use the
name and geo-coordinates values to search for places within a specified area.
We use the built-in feature provided by the external sources (e.g. Google places:
Nearby Search18 ) to search for an instance with the same name within a specific
area. The resulting matched instance is returned to the Validator and processed
to measure its confidence.
16
http://graphdb.sti2.at/repositories/TirolGraph-Alpha
17
DSs restrict and extend Schema.org for domain and task-specific needs.
18
https://developers.google.com/maps6 E. Huaman et al.
3.4 Confidence Measurement
Computing a confidence value can get complicated as the number of instances
and their features can get out of hand quickly. Therefore, a means to automat-
ically validate knowledge graphs is desirable. In order to compute a confidence
value for an instance, the confidence value for each of its triples has to be eval-
uated first.
Triple validation calculates a confidence score of whether a property value
on various external sources matches the property value in the user’s KG. For
example, the user’s KG contains the Hotel Alpenhof instance and statements
about it; Hotel Alpenhof ’s phone is +4352878550 and Hotel Alpenhof ’s address
is Hintertux 750. Furthermore, there are another sources, like Google and Yandex
Places, that also contain the Hotel Alpenhof instance and assertions about it.
The confidence score of (Hotel Alpenhof, phone, +4352878550) triple is com-
puted by comparing the phone property value +4352878550 against the same
property value of the same instance in Google Places. Then it is compared against
Yandex Places, and so on. Every similarity comparison returns a confidence value
that later is added to an aggregated score for the triple.
Given a set of knowledge sources S = {s1 , . . . , sm }, si ∈ S with 1 ≤ i ≤ m.
The user’s KG g consists of a set of instances that will be validated against the
set of knowledge sources S. A knowledge source si consists of a set of instances
E = {e1 , . . . , en }, ej ∈ E with 1 ≤ j ≤ n and an instance ej consists of a set of
attribute values P = {p1 , . . . , pM }, pk ∈ P for 1 ≤ k ≤ M .
Furthermore, sim is a similarity function used to compare attribute pair k for
two instances. We compute the similarity of an attribute value of two instances
a, b. Where a represents an instance in the user’s KG g, denoted g(a), and b
represents an instance in the knowledge source si , denoted si (b).
m
X
tripleconf idence (apk , S, sim) = sim(g(apk ), si (bpk )) (1)
i=1
Next, users have to set an external weight for each knowledge source si ,
W = {ω1 , . . . , ωm } is a set of weights over the knowledge sources, such as ωi
defines a weight of importance for si , 0 ≤ i ≤ m, ωi ∈ W with ωi ∈ [0, 1]
where 0 is the minimum degree of importance Pm and a value of 1 is the maximum
degree. For the sum of weights wsum = i=1 ωi = 1 has to hold. We compute
the weighted triple confidence as follows:
m
1 X
tripleconf idence (apk , S, sim, W ) = sim(g(apk ), si (bpk ))wi (2)
wsum i=1
The weighted approach aims to model the different degrees of importance of
different knowledge sources. None of the parameters can be taken out of their
context, thus a default weight has to be given whenever a user does not set
weights for external source. The Validator assigns an equivalent weight for each
1
source: ωi = m .Title Suppressed Due to Excessive Length 7
Instance validation computes the aggregated score from the attribute space
of an instance. Given an instance a that consists of a set of attribute values
P = {p1 , . . . , pM }, pk ∈ P for 1 ≤ k ≤ M :
M
1 X
instanceconf idence (apk , S, sim, W ) = tripleconf idence (apk , S, sim, W )
M
k=1
(3)
The instance confidence measures the degree to which an instance is correct
based on the triple confidence of each of its attributes. The instance confidence
score is compared against a threshold19 t ∈ [0, 1]. If instanceconf idence > t
indicates its degree of correctness.
3.5 Output
The computed scores for triples and instances are shown by a GUI, see Fig. 2.
The interface provides many features: it allows users to select multiple properties
(e.g. address, name, and phone number) to be validated, users can assign weights
to external sources, it shows instance information from user’s KG and external
sources. For example, the Validator shows information of the Hotel Alpenhof
instance from all sources. It also shows the triple confidence score for each triple,
e.g. the triple confidence for the address property is 0.4, because the address value
is confirmed only by Google places.
Fig. 2: Screenshot of the Validator Web interface.
Tools & Technologies. We implemented our approach in the Validator tool20 ,
which has been implemented in JavaScript21 for retrieving data remotely, and
Bootstrap22 for the user interface.
19
The default threshold is defined to 0.5
20
https://github.com/AmarTauqeer/graph-validation
21
https://developer.mozilla.org/en-US/docs/Web/JavaScript
22
https://getbootstrap.com/8 E. Huaman et al.
4 Evaluation
In this section, we describe our evaluation approach for the Validator. Therefore,
we start detailing a KG to be used as input for the Validator, afterwards, we
perform the validation of a subset of the KG a) manually and b) using the
Validator. Afterwards, we show the results.
4.1 Dataset
As a showcase, we validate a subset of the Tirol Knowledge Graph (TKG). The
TKG contains ∼ 15 Billion statements about hotels, places, resorts, and more,
of the Tirol region. The data inside the TKG are static (e.g name, phone num-
ber) and dynamic (e.g. availability of rooms, prices) and are based on Schema.org
annotations, which are collected from different sources such as Destination Man-
agement Organization (DMO) and Geographical Information Systems (GIS).
Benchmark. During the literature review, we found some relevant benchmarks
to evaluate knowledge validation approaches, however they were created for spe-
cific tasks and contests. Real-world data is preferable over synthetic data, as it
is difficult to simulate all types of errors that might contain a dataset. we have
created a benchmark dataset of 50 Hotel instances23 fetched from the TKG. The
process of creating the dataset involved manual checking of the correctness of all
instances and their attribute values. Fig. 3 shows whether address, name, and
phones values have been found across the different knowledge sources.
4.2 Validation
For our evaluation approach, we carried out a i) manual validation of 50 hotel in-
stances of the TKG against knowledge sources, and ii) semi-automatic validation
of the 50 hotel instances by means of the Validator.
Address Name Phone
Google OSM Yandex Google OSM Yandex Google OSM Yandex
50 50 50
40 40 40
30 30 30
20 20 20
10 10 10
0 0 0
Found Not Found Incorrect Found Not Found Incorrect Found Not Found Incorrect
Fig. 3: Results of the manual validation of 50 hotel instances.
Manual validation. During this evaluation, 50 hotel instances from the TKG
are manually searched and compared to the results coming from each of the ex-
ternal knowledge sources: Google Places, OpenStreetMaps, and Yandex Places.
The instance attributes to be compared are the address, name, and phone. The
23
https://github.com/AmarTauqeer/graph-validation/tree/master/dataTitle Suppressed Due to Excessive Length 9
Fig. 3 shows that Google and Yandex places outperform, by large, the number of
found property values. Furthermore, OpenStreetMaps returns just a few values.
Finally, incorrect values indicates the amount of returned property values that
do not correspond to the instance we are looking for.
Semi-automatic validation. We conducted a semi-automatic validation, the
same 50 hotel instances from the TKG are automatically validated by using the
Validator, which compares and computes a confidence score for each triple. The
results are presented in Fig. 4. On one hand, it shows that Yandex and Google
Places slightly differ in results, on the other hand, OpenStreetMaps mostly does
not return any value, except for the name attribute.
4.3 Results
We found out that for the Yandex Places case, the total number of found in-
stances with their respective address, name, and phone values are almost the
same as the obtained through the manual validation, for the Google Places case,
the results show slightly lower performance, and for the OpenStreetMaps case,
the results were found to be the lowest. In other words, the Validator performs
well, especially with Google and Yandex Places, but not so well with Open-
StreetMaps, e.g., the success rate of Google Places, OpenStreetMaps, and Yan-
dex Places are 0.83%, 0.17%, and 0.86% respectively. The success rate indicates
the degree to which an external source returned the correct property values.
Address Name Phone
Google OSM Yandex Google OSM Yandex Google OSM Yandex
50 50 50
40 40 40
30 30 30
20 20 20
10 10 10
0 0 0
Found Not Found Incorrect Found Not Found Incorrect Found Not Found Incorrect
Fig. 4: Results of the semi-automatic validation of 50 hotel instances.
5 Use Cases
Our approach described in Section 3, aims to validate KGs by finding the same
instances across different knowledge sources and comparing their features. Later
on, based on the compared features our approach computes a confidence score
for each triple and instance, the confidence score ranges from 0 to 1 and indicates
the degree to which an instance is correct. Our approach may be used in a variety
of use cases, involving fact validation, evaluation of knowledge sources accuracy,
and more. In the following, we list some of them:
– It can be used to validate the semantic correctness of a triple. For instance,
a user could want to validate if the phone number of a hotel is the correct
one based on different knowledge sources.10 E. Huaman et al.
– It can be used to link instances with knowledge sources. For example, a user
could link an instance of his or her KG with the matched instance in Google
places.
– It can be used to find out incorrect data on different knowledge sources. For
instance, suppose that the owner of a hotel wants to validate whether the
information of his or her hotel provided by Google Places, OpenStreetMaps,
and Yandex are correct and up-to-date.
– It can be used to validate static data24 [4], for example, to check whether
the addresses of hotels are still valid given a period of time.
There are more possible use cases where our validation approach may be
needed. Here, we just presented some of them to give an idea about how useful
and necessary is to have a validated KG (i.e. a correct and reliable KG).
6 Conclusion and Future Work
In this paper, we presented the conceptualization of a new knowledge graph val-
idation approach and a first prototypical implementation thereof. Our approach
measures the degree to which every instance in a KG is correct. It evaluates the
correctness of instances based on Google Places, OpenStreetMaps, and Yandex
Places. An experiment was conducted on the Tirol Knowledge Graph. The re-
sults confirm its effectiveness and are promising great potential. In future work,
we will improve our approach and overcome its limitations. Here, we give a short
overview of them.
– Automation of the setting process. It is desirable to allow users to create
a Domain Specification (DS) and set it up. Furthermore, a user may want
to add more external knowledge sources.
– Cost-sensitive methods. The current version of the Validator relies on pro-
prietary services like Google, which can lead to important costs when vali-
dating large KGs.
– Dynamic data are fast-changing information that also needs to be vali-
dated, e.g. the price of a hotel room. Temporal validation of knowledge may
be needed. The scope of this paper only comprises the validation of static
data.
– Mapping external sources to a common format are not a straightforward
task, for instance, the heterogeneous scheme of OpenStreetMaps has caused
low performance of the Validator (see Section 4.3). Yet, manual validation
has not had the greatest result.
– Scalability is a critical point when we want to validate KGs. KGs are very
large semantic networks that can usually contain billion of statements.
Above, we pointed out some future research directions and improvements that
one can implement on the development of future validation tools.
Acknowledgments. This work has been partially funded by the project
WordLiftNG within the Eureka, Eurostars Programme of the European Union.
24
Static data is rarely changing informationTitle Suppressed Due to Excessive Length 11
References
1. Aletras, N., Stevenson, M.: Evaluating topic coherence using distributional se-
mantics. In: Proceedings of the 10th International Conference on Computational
Semantics, (IWCS2013), Potsdam, Germany, March 19-22, 2013. pp. 13–22. The
Association for Computer Linguistics (2013)
2. Dong, X., Gabrilovich, E., Heitz, G., Horn, W., Lao, N., Murphy, K., Strohmann,
T., Sun, S., Zhang, W.: Knowledge vault: a web-scale approach to probabilis-
tic knowledge fusion. In: The 20th ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining, KDD ’14, New York, NY, USA - August
24 - 27, 2014. pp. 601–610. ACM (2014)
3. Ercan, G., Elbassuoni, S., Hose, K.: Retrieving textual evidence for knowledge
graph facts. In: Proceedings of the 16th European Semantic Web Conference
(ESWC 2019), Portorož, Slovenia, June 2-6, 2019. Lecture Notes in Computer
Science, vol. 11503, pp. 52–67. Springer (2019)
4. Fensel, D., Simsek, U., Angele, K., Huaman, E., Kärle, E., Panasiuk, O., Toma,
I., Umbrich, J., Wahler, A.: Knowledge Graphs - Methodology, Tools and Selected
Use Cases. Springer (2020)
5. Gad-Elrab, M.H., Stepanova, D., Urbani, J., Weikum, G.: Tracy: Tracing facts
over knowledge graphs and text. In: Proceedings of the 19th World Wide Web
Conference (WWW2019), San Francisco, USA, May 13-17, 2019. pp. 3516–3520.
ACM (2019)
6. Gerber, D., Esteves, D., Lehmann, J., Bühmann, L., Usbeck, R., Ngomo, A.N.,
Speck, R.: Defacto - temporal and multilingual deep fact validation. Journal of
Web Semantics 35, 85–101 (2015)
7. Huaman, E., Kärle, E., Fensel, D.: Knowledge graph validation. CoRR
abs/2005.01389 (2020)
8. Jia, S., Xiang, Y., Chen, X., Wang, K., E, S.: Triple trustworthiness measure-
ment for knowledge graph. In: Proceedings of The World Wide Web Conference,
(WWW2019), San Francisco, USA, May 13-17, 2019. pp. 2865–2871. ACM (2019)
9. Kärle, E., Fensel, A., Toma, I., Fensel, D.: Why are there more hotels in tyrol than
in austria? analyzing schema.org usage in the hotel domain. In: Information and
Communication Technologies in Tourism 2016, ENTER 2016, Proceedings of the
International Conference in Bilbao, Spain, February 2-5, 2016. pp. 99–112. Springer
(2016)
10. Lehmann, J., Gerber, D., Morsey, M., Ngomo, A.N.: Defacto - deep fact validation.
In: Proceedings of the 11th International Semantic Web Conference (ISWC2012),
Boston, MA, USA, November 11-15, 2012. Lecture Notes in Computer Science,
vol. 7649, pp. 312–327. Springer (2012)
11. Li, H., Li, Y., Xu, F., Zhong, X.: Probabilistic error detecting in numerical linked
data. In: Database and Expert Systems Applications - 26th International Con-
ference, DEXA 2015, Valencia, Spain, September 1-4, 2015, Proceedings, Part I.
Lecture Notes in Computer Science, vol. 9261, pp. 61–75. Springer (2015)
12. Li, Y., Li, X., Lei, M.: Ctranse: An effective information credibility evalua-
tion method based on classified translating embedding in knowledge graphs. In:
Database and Expert Systems Applications - 31st International Conference, DEXA
2020, Bratislava, Slovakia, September 14-17, 2020, Proceedings, Part II. Lecture
Notes in Computer Science, vol. 12392, pp. 287–300. Springer (2020)
13. Nakamura, S., Konishi, S., Jatowt, A., Ohshima, H., Kondo, H., Tezuka, T.,
Oyama, S., Tanaka, K.: Trustworthiness analysis of web search results. In: Pro-
ceedings of the 11th European Conference on Research and Advanced Technology12 E. Huaman et al.
for Digital Libraries (ECDL2007), Budapest, Hungary, September 16-21, 2007.
Lecture Notes in Computer Science, vol. 4675, pp. 38–49. Springer (2007)
14. Padia, A., Ferraro, F., Finin, T.: SURFACE: semantically rich fact validation with
explanations. CoRR abs/1810.13223 (2018)
15. Paulheim, H.: Knowledge graph refinement: A survey of approaches and evaluation
methods. Semantic Web 8(3), 489–508 (2017)
16. Rula, A., Palmonari, M., Rubinacci, S., Ngomo, A.N., Lehmann, J., Maurino, A.,
Esteves, D.: TISCO: Temporal scoping of facts. Journal of Web Semantics 54,
72–86 (2019)
17. Shi, B., Weninger, T.: Discriminative predicate path mining for fact checking in
knowledge graphs. Knowledge-Based Systems 104, 123–133 (2016)
18. Shiralkar, P., Flammini, A., Menczer, F., Ciampaglia, G.L.: Finding streams in
knowledge graphs to support fact checking. In: Proceedings of the IEEE Interna-
tional Conference on Data Mining (ICDM2017), New Orleans, USA, November
18-21, 2017. pp. 859–864. IEEE Computer Society (2017)
19. Speck, R., Ngomo, A.N.: Leopard - A baseline approach to attribute prediction and
validation for knowledge graph population. Journal of Web Semantics 55, 102–107
(2019)
20. Syed, Z.H., Röder, M., Ngomo, A.N.: Factcheck: Validating RDF triples using
textual evidence. In: Proceedings of the 27th ACM International Conference on
Information and Knowledge Management, (CIKM2018), Torino, Italy, October 22-
26, 2018. pp. 1599–1602. ACM (2018)
21. Syed, Z.H., Röder, M., Ngomo, A.N.: Unsupervised discovery of corroborative
paths for fact validation. In: Proceedings of the 18th International Semantic Web
Conference (ISWC2019), Auckland, New Zealand, October 26-30, 2019. Lecture
Notes in Computer Science, vol. 11778, pp. 630–646. Springer (2019)
22. Tan, C.H., Agichtein, E., Ipeirotis, P., Gabrilovich, E.: Trust, but verify: predicting
contribution quality for knowledge base construction and curation. In: Seventh
ACM International Conference on Web Search and Data Mining, WSDM 2014,
New York, NY, USA, February 24-28, 2014. pp. 553–562. ACM (2014)
23. Thorne, J., Vlachos, A.: An extensible framework for verification of numerical
claims. In: Proceedings of the 15th Conference of the European Chapter of the
Association for Computational Linguistics (EACL2017), Valencia, Spain, April 3-
7, 2017. pp. 37–40. Association for Computational Linguistics (2017)
24. Thorne, J., Vlachos, A., Christodoulopoulos, C., Mittal, A.: FEVER: a large-scale
dataset for fact extraction and verification. In: Proceedings of the 2018 Conference
of the North American Chapter of the Association for Computational Linguistics:
Human Language Technologies (NAACL-HLT2018), New Orleans, USA, June 1-6,
2018. pp. 809–819. Association for Computational Linguistics (2018)
25. Vlachos, A., Riedel, S.: Fact checking: Task definition and dataset construction.
In: Proceedings of the Workshop on Language Technologies and Computational
Social Science (ACL2014), Baltimore, USA, June 26, 2014. pp. 18–22. Association
for Computational Linguistics (2014)
26. Wienand, D., Paulheim, H.: Detecting Incorrect Numerical Data in DBpedia. In:
Proceedings of the 11th International European Semantic web Conference (ESWC
2014), Anissaras, Greece, May 25-29, 2014. Lecture Notes in Computer Science,
vol. 8465, pp. 504–518. Springer (2014)
27. Yin, X., Han, J., Yu, P.S.: Truth discovery with multiple conflicting information
providers on the web. IEEE Trans. Knowl. Data Eng. 20(6), 796–808 (2008)You can also read

















































