Decrypting Cryptic Crosswords: Semantically Complex Wordplay Puzzles as a Target for NLP
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Decrypting Cryptic Crosswords:
Semantically Complex Wordplay Puzzles as a Target for NLP
Josh Rozner Christopher Potts Kyle Mahowald
{rozner,cgpotts}@stanford.edu
mahowald@ucsb.edu
Abstract
Cryptic crosswords, the dominant English-
language crossword variety in the United King-
dom, can be solved by expert humans using
arXiv:2104.08620v1 [cs.CL] 17 Apr 2021
flexible, creative intelligence and knowledge
of language. Cryptic clues read like fluent nat-
ural language, but they are adversarially com-
posed of two parts: a definition and a wordplay
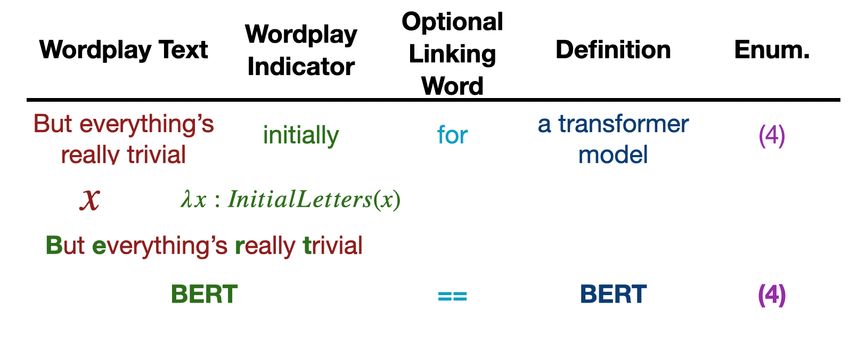
Figure 1: Illustration of how the cryptic crossword clue
cipher requiring sub-word or character-level
“But everything’s really trivial, initially, for a trans-
manipulations. As such, they are a promising
former model” is parsed. The word “initially” is an in-
target for evaluating and advancing NLP sys-
dicator to apply an initialism function to the string “But
tems that seek to process language in more cre-
everything’s really trivial,” taking the first letter of each
ative, human-like ways. We present a dataset
word to get BERT. The word “for” is an optional link-
of cryptic crossword clues from a major news-
ing word (which connects the wordplay and the defini-
paper that can be used as a benchmark and
tion). The definition part is “a transformer model,” for
train a sequence-to-sequence model to solve
which a valid answer is BERT. Because this matches
them. We also develop related benchmarks
the wordplay part and fits the enumeration (which indi-
that can guide development of approaches to
cates 4 letters), it is a valid answer.
this challenging task. We show that perfor-
mance can be substantially improved using a
novel curriculum learning approach in which domains. Just as complex games mastered by hu-
the model is pre-trained on related tasks in- man experts, such as chess, Go, and video games,
volving, e.g, unscrambling words, before it have proved a fertile ground for developing more
is trained to solve cryptics. However, even flexible AI, (Silver et al., 2018, 2016; Mnih et al.,
this curricular approach does not generalize to 2015), we propose that creative language games
novel clue types in the way that humans can,
and so cryptic crosswords remain a challenge
are a rich area for developing more flexible NLP
for NLP systems and a potential source of fu- models. In particular, we argue that linguistic tasks
ture innovation.1 involving meta-linguistic reasoning (i.e., reasoning
about language qua language) pose an important
1 Introduction and significant challenge for state-of-the-art com-
Modern computational models have made great putational language systems.
progress at handling a variety of natural language One such domain is cryptic crossword puzzles.
tasks that require interpreting the rich syntactic and Cryptics are the most popular style of crossword
semantic structures (Devlin et al., 2018; Radford in the United Kingdom and appear in major news-
et al., 2019; Manning et al., 2020; Rogers et al., papers like The Times and The Guardian. They
2020). However, in NLP (Bender and Koller, 2020; differ from American-style crossword puzzles in
Marcus, 2020; Bisk et al., 2020) as in other areas that they have both definition and wordplay com-
of AI (Lake et al., 2016), machines still lag humans ponents. Consider this NLP-centric cryptic cross-
on tasks that require flexible problem solving, rapid word clue: “But everything’s really trivial, initially,
learning of unseen tasks, and generalization to new for a transformer model (4).” The wordplay part
1
is “But everything’s really trivial, initially.” The
Code to download (from theguardian.com), clean, and
process the dataset is publicly available at https:// word initially in this context is used as an indica-
github.com/jsrozner/decrypt tor, which tells the solver to take the initial letterClue type Clue example Explanation for this example
Anagram: An anagram indicator indicates Confused, Bret makes a Rearrange the letters of “Bret” to get
the letters must be scrambled. language model (4) BERT.
Initialism: An initialism indicator indicates But everything’s really Take the first letters of “everything’s really
one must take the first letters of a phrase trivial, at first, for a lan- trivial”
guage model (4)
Container: A container indicator indicates Language model in Extract the word BERT from the phrase
the answer is hidden within a larger phrase. somber text (4) “somber text.”
Charade: For a charade clue, each part of A language model exist? “exist” becomes BE. A standard abbrevia-
the answer is clued sequentially. Right time! (4) tion for “right” is R. A standard crossword
abbreviation for “time” is T.
Double definition: In a double definition Model Sesame Street Bert is a valid answer for “Sesame Street
clue, two synonyms or phrases appear next character (4) character”, and it is also a model.
to each other, each of which can refer to the
answer.
Table 1: Sample of 4 common clue types in cryptic crosswords, all demonstrating clues for the answer: “BERT”.
of each of the preceding words (but everything’s important challenge for modern NLP.
really trivial) to get the answer word: “BERT”. The
definition part of the clue is “a transformer model,” In this paper, we first present a dataset
which is a semantically valid description of BERT. of cryptic crosswords clues taken from
Because both the wordplay and the definition com- theguardian.com, consisting of 142,380
ponents lead to the same 4-letter word (which is cleaned clues from 5,518 puzzles over 21 years.
what the enumeration calls for), we can be rea- Second, we present a series of computational
sonably confident that BERT is the correct answer. benchmarks, along with a sequence to sequence
Many clues require the application of multiple, po- approach that uses the pretrained T5 model, to
tentially composed functions (i.e. the result of one characterize the problem space—and to illustrate
transformation, like taking a synonym, becomes why cryptic crosswords pose a particular challenge
the input to the next), with multiple indicators, to for existing NLP approaches. Finally, we present
solve the wordplay. a curriculum learning approach, in which our
While cryptic crosswords pose a challenge to system is first trained on related tasks (e.g., an
novice solvers, expert solvers draw on a combina- augmented word descrambling task) before being
tion of world knowledge, domain-specific cryptic unleashed on real cryptic crossword clues. This
crossword knowledge, linguistic knowledge, and approach meaningfully improves on our standard
general problems solving. Expert solvers know the T5 sequence-to-sequence approach and on the best
rules that govern cryptic crosswords, but they also performing model in Efrat et al. 2021—concurrent
reason about them flexibly and apply them to solve work that presents a similar dataset and baseline
novel clues. In the psychology literature, it has T5 approach.
been claimed that cryptic crosswords depend on
domain-general intelligence (Friedlander and Fine, While we show that our sequence to sequence
2020). Moreover, Friedlander and Fine (2018) cite approach can learn interesting features of the prob-
cryptic crosswords as an ideal domain for studying lem space, including learning some meta-linguistic
the “aha moment” in humans because they can be facts about word length, fully solving cryptic cross-
solved by experts with high accuracy (but often words remains a challenge for NLP. In particular,
not at first glance), can be easily created by expert we show that the Transformer-based approach suf-
humans, and require drawing on a diverse range of fers significantly when the test set is constructed so
cognitive abilities. as to avoid having answer words that also appear in
Therefore, we believe that cryptic crosswords are the training set. Moreover, although we introduce
an excellent domain for developing computational a novel method that considerably improves T5’s
language systems that “learn and think like humans” performance, we are still far below expert human
(Lake et al., 2016). In particular, we argue that performance. To that end, we hope that this dataset
cryptic crossword clues pose an interesting and will serve as a challenge for future work.2 Background and Related Work 3 Dataset
2.1 Cryptic Crosswords We present a cleaned dataset of cryptic cross-
Standard cryptic crossword clues generally have word clues drawn from puzzles published in The
two parts: a definition part and a wordplay part. Guardian between July 23, 1999, and October 8,
What makes cryptics hard is that there is huge va- 2020.2
riety in the kind of wordplay that can occur. In 3.1 Preprocessing
the introduction, we discussed a type of cryptic
clue that requires extracting the initial letters of a To produce the clean dataset, we remove 15,360
sequence of words. Another common type of word- clues that interact with other clues in the same
play is the anagram clue type, where a sequence of puzzle, as well as 231 clues that are ill-formatted
letters needs to be scrambled to find a new word. (e.g., have a solution length not matching the length
Anagrams are usually indicated by words like con- enumeration, unparsed HTML characters, etc.).
fused, drunk, mixed up, or any other word in the We further remove 1,611 exact duplicates, which
semantic space of motion, confusion, alteration, are clues with identical answers and clue strings.
accident, etc. (It would be difficult to construct a Code to fully replicate our data download and pre-
list of all possible anagram indicators, but expert processing pipeline is available in our project code
solvers learn to identify indicators of this type.) repository.
Clues also have an enumeration which says how 3.2 Dataset Properties
many words and letters are in the answer. For in-
The cleaned dataset has 142,380 cryptic crossword
stance the enumeration “(8, 4)” means the answer
clues from 5,518 puzzles. Clues in our dataset
consists of two words, the first word being 8 letters
have answers consisting of one to six words, with
long and the second word being 4 letters long. Ta-
97.4% having one or two-word answers; the major-
ble 1 shows a variety of possible cryptic clues for
ity (83.3%) have one-word answers. The dataset
the word BERT. These represent only a subset of
has 55,783 unique answers and 50,525 unique an-
the many possible types of cryptic clues.
swers up to plural inflection, giving a mean fre-
2.2 Prior Work quency of 2.55 clues per unique answer (2.82 up to
plural inflection).
While there is an existing literature on puns and
wordplay in NLP (He et al., 2019; Kao et al., 2013; 3.3 Dataset Splits
He et al., 2019; Luo et al., 2019) as well as on solv-
We consider three splits for experimental work and
ing American-style crosswords (Ginsberg, 2011;
model assessment:
Littman et al., 2002; Shazeer et al., 1999), there
has been relatively little prior work using NLP Naive split A simple 60/20/20 split into train,
methods on cryptic crosswords. Hart and Davis dev, and test.
(1992) laid out a computational framework for solv-
Disjoint split A split that ensures that all clues
ing the problem, and Hardcastle (2001, 2007) pro-
with the same answer appear in only one of the
posed some rule-based solutions. The app Cross-
three sets. That is, if all clues for which the answer
word Genius, created by William Tunstall-Pedoe,
word is BERT appear in the training set, then no
solves cryptic crossword clues and gives human-
clues for which the answer is BERT will appear in
understandable explanations, but it is proprietary
the test set or dev set.
and not available for testing. Deits (2015) offers a
rule-based solution, which can also output explana- Word-initial disjoint split A split designed to
tions, and which we test on our dataset. Most re- make the training, eval, and test sets maximally
cently, in work concurrent to ours and not known to distinct by avoiding having similar words (e.g. in-
us until shortly before completing our paper, Efrat flections) in the same set. To construct this set, we
et al. (2021) released a dataset of cryptic cross- enforce the rule that all clues with answers that
word clues along with a T5-based solution. In Sec- start with the same two letters will appear in the
tion 7.4, we provide results demonstrating that our same set. For example, all clues that have answers
curricular approach improves on their results us- 2
Each puzzle can be accessed at https://www.
ing the same model (T5-large) on their Cryptonite theguardian.com/crosswords/cryptic/
dataset. puzzle_idstarting with ‘ab’ like “abacus,” “abaci,” “abdicate,” LemmInflect (Jascob, 2019) to get all inflections of
“abdicates,” “abdicated,” “abdication” will occur in the words in the initial output.
a single split. We provide an upper bound for this method
by noting that, when including synonyms and hy-
4 Metrics ponyms/hypernyms up to depth 3, and inflecting
Our primary goal is to produce the correct answer all outputs, our definition sets contains the correct
to each cryptic clue. Given that each cryptic clue in answer 22% of the time. However, since this model
a puzzle has a hard length constraint in the form of lacks a mechanism to effectively rank outputs, we
the puzzle grid and answer-length enumeration, we obtain the best performance on this model restrict-
take as our primary metric whether the top-ranked ing our reverse lookup to synonyms, hyponyms to
output is correct, after filtering to outputs of the depth 1, not adding inflected forms, and ranking
correct length. by character-level overlap. Using this approach,
Since cryptic clues are written to be solved as we achieve accuracies of 2.6% (for the correct an-
part of a larger puzzle, human solvers typically swer being the one produced by the model) and
rely on information from other, interlocking an- 10.7% (for the correct answer appearing in the top
swers (i.e. overlap with clues that they have al- 10 candidates) on our test set metrics.
ready solved) to come up with the correct answers While this approach achieves some success, it is
for trickier clues. While we do not make such infor- inherently limited, since it cannot handle clues in
mation available to our solver (instead formulating which the definition part is multiword or phrasal.
the task as solving clues in isolation), we also in- 5.2 KNN BoW
clude the following as a metric: the proportion of
the time that the answer is contained in the top 10 Our second baseline is the KNN BoW. The logic
outputs (after filtering to answers of the correct of this approach is, for each clue, to identify the
length). This is a useful heuristic, since if we were clue in the training set most similar to that clue in
to introduce information from elsewhere in the an- lexical space. To implement this baseline, we use
swer grid, solvers would likely be able to identify scikit learn’s (Pedregosa et al., 2011) CountVector-
the correct answer word if it appeared in the list of izer and KNeighborsClassifier. We find that model
10 candidates. For instance, the best-performing performance is best with 1-grams and degrades
crossword solver for American-style (non-cryptic) if longer n-grams are used in the vectorizer. We
crosswords relies heavily on satisfying grid con- test with and without appending the length speci-
straints (Ginsberg, 2011). fication to the clue. Without lengths, we achieve
performance of 5.6% and 10.1% on test set metrics;
5 Baseline Models and Results with lengths we achieve 6.1% and 11.3%.
To characterize how relatively straightforward so- 5.3 Rule-based
lutions do on this dataset, we test three non-neural For another baseline on our dataset, we use the
baselines: a WordNet-based heuristic model, a k- rule-based approach from Deits (2015). This solver
nearest-neighbor bag of words model (KNN BoW), implements anagrams, initialisms, substrings (ini-
and a rule-based model (Deits, 2015). tial, middle, final), insertions, and reversals in a
5.1 WordNet rule-based way. 3
While the rule-based version includes a number
Our first baseline takes advantage of the fact that of common clue types, an inherent limitation of this
the definition part of a cryptic clue always appears approach is that it is difficult to enumerate all possi-
at the beginning or end of the clue. For instance, bilities. For instance, the Deits (2015) solver does
in the clue for BERT in Table 1, “Model Sesame not include charade-type clues, nor does it include
Street character,” the word “model” appears at the double definitions. The rule-based solver uses
beginning and is a definition (in this case, a hyper- WordNet’s (Fellbaum, 1998)’s word similarity func-
nym) for the answer “BERT”. tionality to rank outputs, meaning that, in general,
Taking advantage of this fact, we use WordNet
3
(Fellbaum, 1998), a large database of English word Deits (2015) has a more recently implemented solver in
Julia that was used by Efrat et al. (2021). We use the Python
meanings, to build a reverse dictionary via the syn- version, which may have small differences from the Julia
onym, hyponym, and hypernym graphs. We use version.Random split Fully disjoint split
Model Top correct Top 10 contains Top correct Top 10 contains
dev test dev test dev test dev test
WordNet 2.8 2.6 10.8 10.7 2.6 2.6 10.6 10.5
Rule-based 7.2 7.3 14.8 14.7 7.4 7.3 14.9 14.5
KNN (no lengths) 5.6 5.6 9.9 10.1 0.0 0.0 0.0 0.0
KNN (lengths) 6.0 6.1 11.2 11.3 0.0 0.0 0.0 0.0
T5 (no lengths) 15.3 15.6 29.4 30.0 0.9 1.0 4.8 5.1
T5 (lengths) 16.0 16.3 33.1 33.9 1.1 1.1 5.6 5.8
T5: ACW + ACW-descramble 21.5 21.8 42.2 42.4 6.1 6.5 18.9 20.0
Table 2: Results for the WordNet baseline, KNN model, T5-base, and T5-base with curriculum learning, in percent
of correct answers produced for the naive split (dev set and test set) and for the word-initial disjoint split (dev and
test set), restricted to outputs of correct length.
it will fail on clues that have phrasal definitions. testing Transformer-based approaches on a task
Another limitation is that the rule-based model is like this one, which requires not just linguistic
slow. We set a timeout of 120 seconds (timed- reasoning but meta-linguistic reasoning, for exam-
out clues usually still return some answers) and ple about features like word lengths and anagrams.
report an average time to solve a clue of roughly Whether massive pre-trained transformer models
40 seconds. This results in a total time to evaluate can learn this sort of information is an open ques-
on 28,476 clues of approximately 300 CPU hours, tion in NLP (one explored by Brown et al. (2020)
substantially slower than the 1–2 minutes needed for GPT-3), and we believe our results can be infor-
for the WordNet baseline and the ≈5 minutes for mative in this regard.
KNN BoW. The rule-based solver achieves 7.3%
and 14.7% on test set metrics, outperforming our 6.1 Data and Task Formulation
KNN and WordNet baselines. To fine-tune T5 to our task, we translate each
clue into input and target of the following form
6 T5 Models and Results (i.e. appending length enumeration to the clue
string), and setting as target the answer. =>
We present two main sequence-to-sequence solu- separates input from target. For instance, a
tions to the cryptics task. The first is a straightfor- training instance for our BERT clue would
ward sequence-to-sequence approach, fine-tuning look like the following: But everything’s
the Transformer-based (Vaswani et al., 2017) T5- really trivial, initially, for a
model (Raffel et al., 2020) on our cryptic cross- transformer model (4) => bert
word training set. The second builds upon this ap- Starting from pre-trained embeddings, we fine-
proach by introducing a novel curriculum-learning tune T5 to produce the target answer for each input.
paradigm that first trains the model on related prob- We evaluate on the dev split, using beam-search
lems before training on full cryptic clues. generation with five beams, for each dev example.
Our motivation for using Transformer-based For test evaluation, we use the model with the high-
models is twofold. First, rule-based approaches est number of dev set clues whose top ranked beam
are inherently limited to clues of the sort that have generation is correct (i.e. exact character match
been seen before, whereas human solvers can flexi- of output with target, after removing whitespace).
bly understand new clue types with novel indicator During test evaluation, we generate 100 outputs for
words and novel definitions. Pre-trained contextual each input (100 beams with 100 output sequences).
embedding models are a promising candidate for After filtering to the outputs that have the correct
this type of flexibility, in that they have a strong no- length (removing any whitespace characters), we
tion of semantic similarity and access to positional report the percentage of test-set clues whose top
information. answer is correct and whose top 10 outputs contain
Second, we believe there is inherent value in the answer.Percent correct our training set does not include all possible cross-
Curricular dataset full dev set anagram subset word answers, and any puzzle is likely to contain
Baseline (no curricular) 15.7 13.7 some novel answer words.
ACW 18.3 14.4 To ameliorate these issues, we use a curricular
ACW-descramble 13.1 21.4 approach. Broadly, the approach consists of two
ACW + ACW-descramble 20.2 24.0 steps. First, we take the pre-trained T5 model and
ACW + ACW-descramble-word 17.8 18.3
ACW + anagram 17.1 19.1 train it on a supplementary task (or set of tasks).
Second, we train on the primary dataset of crytpic
ACW + ACW-descramble + ana- 20.1 27.1
gram (7:6 ratio of pretrain exs.) clues. During the latter step, we intermittently show
batches from the initial training set, in order to
Table 3: Results for various curricular approaches prevent catastrophic forgetting (French, 1999). We
(9.6m pretrain examples) on the random split. Metrics tune the following hyperparameters: the number of
are percent of correct answers (without length filter, 5 curricular epochs, whether the Adafactor optimizer
beams) in the entire dev set and in the subset of the dev
is reset before primary training (only affects non-
set that are anagram clue types.
constant LR training regime), and the frequency of
curricular subtask review during primary training.
6.2 Vanilla seq2seq Approach
We use T5-base, which can be fine-tuned to con- 6.3.1 Curricular Datasets
vergence on a single GeForce RTX 3090 GPU For our curricular training, we create four supple-
in roughly 100 minutes. We start with Hugging mentary data sets, all built from a public dataset of
Face’s (Wolf et al., 2020) pretrained models, and 6.3m American crossword clues (Pwanson, 2021,
optimize with Adafactor (Shazeer and Stern, 2018) henceforth ACW for American Crossword). Amer-
using the relative step and warmup initialization op- ican crossword clues are typically synonyms or
tions, as implemented in the Hugging Face library. definitions and thus correspond to the “definition”
We use a batch size of 256 sequences with per- part of cryptic clues.
batch truncation-to-longest (via Hugging Face’s From ACW, we first produce a cleaned set of
T5FastTokenizer). clue/answer pairs, consisting of 2.5 million clues
We train with a patience of 15 epochs and select (removing roughly 3 million exact duplicates and
the best model according to dev set performance, roughly 800k clues that are unlikely to be syn-
based on whether the top answer (over 5 beam onyms or paraphrases, such as fill-in-the-blank
search generations) is correct. clues). We use this cleaned ACW set to gener-
For our naive split: If we take just the top an- ate our four supplement datasets: ACW, ACW-
swer, the T5-base solver solves 16.3% of the clues descramble, ACW-descramble-word, and anagram.
(16.0% on dev). For 33.9% of clues (33.1% for Each dataset has its own task label, which is passed
dev), the correct answer appears in the top 10 an- to the model as part of the string.
swers. As can be seen in Table 2, this outperforms
all non-neural baselines. ACW ACW is the set of straightforward
American-style crossword clues, prepending
6.3 Curriculum Learning
“phrase:” as a task label, as done by Raffel et al.
The problem of solving cryptic crossword clues is (2020) in their original presentation of T5. For ex-
fundamentally different from the ordinary natural ample, a clue for which the answer is “petal” is
language context on which T5 is pre-trained. Thus, phrase: flower part (7).
one possible impediment to the performance of our
model is that it has to learn many sub-parts of the ACW-descramble We synthesize ACW-
cryptic clue problem simultaneously: how to look descramble, in which we randomly choose
up definitions, how to identify wordplay indicators, to prepend or append scrambled answer let-
how to perform wordplay operations, etc. Each of ters to the paraphrase. We use the task label
these steps is challenging. “descramble.” For example, we can scramble
A second challenge is that the model needs to be “petal” and randomly place it at the beginning
able to output answers that it has not seen in train- (descramble: etalp flower part
ing. This is especially important for the disjoint (7)) or end (descramble: flower part
split, but also relevant to our random split, since etalp (7)) of a clue.ACW-descramble-word This supplementary of 6 curricular batches for every 20 primary task
dataset omits the phrasal definition (i.e., the clue) batches.
and instead simply asks the model to descramble a
word, with length enumeration given. We use “de- We find that, when training on multiple tasks (i.e
scramble word” as the task label: descramble when we are in the curricular setting), using task
word: etalp (7). labels improves performance. We include length
enumeration in all curricular tasks since we ob-
Anagrams Finally, we synthesize an anagram served that doing so improves performance.
dataset with an anagram (a scrambled version
In order to reasonably compare across the dif-
of a word which is itself also a valid word) and
ferent curricular datasets, we set the number of
an anagram indicator (e.g., “mixed up,” “drunk”,
training examples to be the same for each approach.
“confusingly”) of the sort that are typically used
Since 4 epochs of the ACW set involves 9.6m ex-
in cryptic crosswords. An example of a clue in
amples, we match to this number. Thus, for the
this dataset for is anagram: confusingly
experiments with two supplementary datasets (e.g.,
plate (5) (rearrange the letters of ‘plate’
ACW + ACW-descramble), we train for 2 epochs,
to get ’petal’). This last type of clue (in the
each with twice as many examples.
anagram dataset) simulates the anagram type
of wordplay in cryptic clues, omitting the the We train with a patience of 10 epochs (reduced
definition part, whereas clues in the ACW datset since the model converges faster than without cur-
simulate the definitional part of cryptic clues ricular training), and select the best model accord-
(without wordplay). ing to dev set performance, based on whether the
top answer (over 5 beam search generations) is cor-
The logic of this approach is to guide our rect. We use the best method based on these metrics
model on these sub-parts before building up to for our final curricular evaluation and report results
fully compositional cryptic crossword clues. in Table 3.
Descrambling and anagramming are only a sub-
set of the wordplay operations available in crytpic Our results show that pretraining on the ACW set
crosswords, but the same approach could be ex- always improves performance. Although training
tended to other types of wordplay. on a combination ACW + ACW-descramble further
improves performance, training solely on the ACW-
6.3.2 Methods descramble seems to degrade performance relative
Using the supplemental datasets we constructed to baseline.
for curriculum learning, we tested our curricu-
In order to explore whether the subtask pretrain-
lum learning approach by supplementing the full
ing improves performance across the board or just
cryptic training set with curricular pre-training
on the clue types directly involved (e.g., anagrams),
on the ACW and ACW-descramble supplemen-
we used a simple heuristic to search for and label
tary data sets, as well as selected combinations
anagram clue types in the cryptic crossword set
of the supplementary data sets. In Table 3, we
and explored performance on just this set (the “ana-
report results for our curricular approach train-
gram subset” column in Table 3). Mixing in the
ing on the following supplementary datasets and
anagram subtask produces nearly the same overall
combinations: ACW, ACW-descramble, ACW +
performance as with ACW + ACW-descramble, but
ACW-descramble, ACW + ACW-descramble-word,
does improve performance on the subset of the data
ACW + anagram, ACW + ACW-descramble + ana-
involving anagrams. Thus, it seems that, to some
gram.
extent, pre-training geared around a particular clue
We use the same T5 training parameters as in our type can improve performance on that subtask, but
vanilla model and hand-tune the number of pretrain- perhaps at the expense of performance on other
ing epochs, generally finding that training nearly clue types. Nonetheless, as seen in Table 3, the
to convergence on a held-out validation set for the curricular approach substantially improves perfor-
primary pretraining task is optimal. We reset the mance relative to the vanilla T5 approach.
optimizer between pretraining and primary training,
and we review the curricular tasks by introducing Furthermore, we show that these gains in perfor-
them during the primary training phase, at a ratio mance hold for the disjoint set in Table 2.Model
% samples % sample % sample antees at least some overlap.
containing outputs outputs
answer (no with correct with correct
The fact that T5 seems to learn both character-
len filter) length word count level and word-level length information is perhaps
dev test dev test dev test more interesting. It is particularly proficient at
KNN
learning when an answer is more than one word.
- (no lengths) 6.5 6.6 13.4 13.3 70.7 70.7 Recall that multiword answers are indicated with
- (lengths) 10.6 10.7 85.4 85.3 89.7 89.6 an enumeration that has two numbers separated
T5-base by a comma, as in “(4, 6)” (indicating an answer
- (no lengths) 19.0 18.8 16.0 16.2 74.2 74.1 composed of 4-letter word plus a 6-letter word,
- (lengths) 27.5 28.1 48.3 48.5 97.9 97.9
like ALAN TURING). Based on the fact that T5
Table 4: Sample metrics for models that have access to generates a high proportion of multi-word answers
the meaning of length enumeration. Metrics are calcu- when the enumeration calls for it, it seems plausible
lated over the top 10 outputs for each clue (a sample) that the sequence-to-sequence model is learning the
without length filtering. Models tested on naive split correspondence between the enumeration (in par-
(dev and test). ticular the comma(s)) and the presence of a space
or spaces in its output.
7 Model Analysis
7.2 Disjointness
7.1 Learning Meta-Linguistic Properties:
Output Length and Number of Words Based on the performance of the KNN model on the
Beyond characterizing each model’s ability to gen- naive data split, we see that at least some answers
erate correct outputs, we are interested in the extent can be learned merely by picking up on similarity to
to which each model learns underlying features rel- previous clues. Thus, there is an open question as to
evant to the task, such as how long the answer what explains the relative success of the T5 model
should be (information it has access to through the approaches: are they picking up on similarity to
enumeration given with each clue). previous seen clues? Or are they understanding
For both the KNN and the T5 models, we find something about the compositional and functional
that including length enumeration improves mod- structure of the cryptic clues?
els’ abilities to generate correct answers, as can To assess the extent to which the T5 model relies
be seen in Table 2. (The Wordnet and rule-based on having seen similar clues for the same word, we
models cannot incorporate this information, except first segment performance on the random split into
as the hard filter we apply in restricting to answers groups based on whether the answer occurs in the
of the correct length for the crossword grid, so we train set. Performance is considerably lower on the
do not discuss them in this analysis.) 8,354 examples (29.3%) of the dev set clues whose
To further study the extent to which the models answers do not occur in the train set.
learn length information, we look at model perfor- We further assess this question by training on
mance without the length filter and ask, not only two disjoint datasets, described in 3: the naive
how often the list of top 10 candidates contains disjoint split (e.g., if ‘BERT’ is seen as an answer
the correct answer, but also how often the top 10 in train, then ‘BERT’ cannot be an answer in dev
candidates are the correct length, both in characters or test), and the word-initial disjoint dataset (words
and in words. with the same two initial characters cannot appear
The results of this analysis are in Table 4. Both in both train and test). The T5 model achieves 3.3%
the KNN model and the T5 model seem able to pick accuracy on the naive disjoint dev set and only
up on length information and more often generate 1.1% accuracy on the word-initial disjoint split. We
answers of the correct length when the enumera- attribute this drop between the naive disjoint set
tion is provided. The KNN model learns length in and the word-initial disjoint set to the fact that the
a somewhat trivial way: a clue for the word PETAL model seems to benefit from seeing similar clues
will always have the enumeration “(5).” And so, for related words, and related words, like inflected
for a bag-of-words nearest neighbor approach that forms, start with the same two letters.
cares about lexical overlap between clues, it is rel- As can be seen in Section 7.4, the challenge of
evant that all PETAL clues will have at least one the fully disjoint split is not substantially amelio-
“word” in common: the “(5).” This effectively guar- rated by a larger model (T5-large) trained on theTop output Top 10 outputs
Dataset correct contain answer
dev test dev test
Random split
- Full split 16.0 16.3 33.1 33.9
- Subset not in train set 3.0 2.8 9.5 9.7
- Subset not in train set, up to plurals 2.3 2.2 7.6 8.0
Disjoint split:
- Basic disjoint 3.3 3.2 12.6 12.9
- Word-initial disjoint split 1.1 1.1 5.6 5.8
Table 5: T5-base performance under various tests of disjointness: performance on the random split and subsets of
the random split, performance on the basic disjoint and word-initial disjoint subsets
Split and task Match top Match any well as under two task setups.
sampled sampled (10) Using the ACW set which maps from clue
to answer, we produce examples of the form
Random split
scrambled(answer) => answer for the
- Descramble 63.8 91.6
first task and of the form scrambled(answer)
- Descramble w/ phrase 79.4 91.2
| clue => answer for the second task. The
Disjoint split second task is designed to mimic the cryptic setup,
- Descramble 3.7 12.5 in which we have a wordplay whose output is con-
- Descramble w/ phrase 12.4 24.4 ditioned on a phrasal synonym. In this case our
wordplay is the implicit descramble function.
Table 6: Descrambling task under random and disjoint We present results for this wordplay subtask in
splits, with and without paraphrase given. Performance
Table 6. Accuracy (as measured by how often the
reported without filter.
correct answer is in the top 11 candidates) is high
(over 90%) when the answer word appears in both
larger Cryptonite dataset.
the training and test set, even though the actual
7.3 Wordplay: Minimal Task scrambled form of the word can be quite different.
But accuracy drops considerably when the training
We know that the SentencePiece tokenization
and test sets are disjoint.
scheme used by T5 may pose a problem for sub-
To see whether this marked drop in performance
word and character-level manipulations. To charac-
was simply because the T5 model cannot produce
terize whether the T5 model is capable of wordplay-
answers that it has not seen in its training set, we
like tasks, we test it on a simple descrambling task.
ran an experiment in which the model simply had to
In effect, this task can put an upper bound on how
reproduce answers verbatim (i.e., a copy task). We
well the full model can actually do a wordplay
use the same four datasets as just described, but re-
similar to what is necessary to arrive at a “full un-
place all occurrences of scrambled(answer)
derstanding” of the answer (that is, without simply
with answer, i.e., as if we used the identity func-
relying on heuristics or solving the clue by guess-
tion in place of the scramble function. The model
ing the definition part).
achieves 100% accuracy on all four versions of
We start with the ACW dataset from Section 6.3
the dataset, suggesting that the inability of the T5-
We further restrict it to words found in a dictio-
based model to do the descrambling task on the
nary (i.e. removing multiword answers), and then
disjoint set is not due merely to an inability to gen-
downsample to 10% of the dataset producing 180k
erate an answer that has not been seen in training.
examples. We note that this dataset does contain
multiple clues that map to the same answer but that
7.4 Comparison to Efrat et al.
there are no exact duplicates (i.e. although the an-
swer is the same, the clue strings differ). We test Contemporaneously, Efrat et al. (2021) presented
under a random and disjoint split of the data, as a similar dataset and trained T5-large to produceSplit Efrat et al Our replication Curricular
of Efrat et al (our best approach)
Efrat ‘naive’ (test) 56.2 53.2 52.1
Efrat ‘official’ (test) 7.6 10.9 19.9
Word-initial disjoint (test) – 4.9 12.8
Table 7: Performance of T5-large as reported by Efrat et al. (2021), in our replication of their work, and using
our best-performing curricular approach (ACW + ACW-descramble). Metric is correctness of top output using 5
beams over the test set for each split.
answers to cryptic clues. While Efrat et al. (2021) tative distribution for the test set, so supplementary
reach the conclusion that train/test disjointness is data actually very slightly reduces performance.
important in this problem, they stop short of cre- Our results are presented in Table 7.
ating a truly disjoint dataset, overlooking T5’s ro-
bustness to plural and other inflections. The word- 8 Conclusion
initial disjoint split that we produce addresses this
Our contribution is, first, to introduce a dataset of
oversight. (Note that our “naive disjoint split” is
cryptic crossword clues and answers that can be
equivalent to their “official disjoint split.”)
used as a task for future work and, second, to offer
In order to directly compare our own results to a set of benchmarks and models that attempt to
to those of Efrat et al. (2021), we first replicate solve the task.
their results by training and testing T5-large (the In particular, we found that a T5-based solution,
model they use) on their ‘naive’ and ‘official’ splits. with curriculum learning, shows some promise at
Note that their ‘naive’ is the same as our naive solving cryptic crossword clues. It achieves this
split, that their ‘official’ is the same as our disjoint success despite being exposed in its early train-
(i.e. answer-disjoint) split. We select the top model ing phase to only a small subset of the sub-tasks
based on dev-split performance and evaluate on the (namely descrambling and definition matching)
test split. For both model selection and test evalu- that are core parts of solving cryptic crossword
ation, we use the same metric used in their paper: clues. In future work, it may be possible to extend
percent accuracy as percentage of clues where the this approach to a wider variety of sub-tasks by
model’s top output (over 5 beams) is correct. Hav- using heuristics to generate additional curricular
ing shown that we achieve slightly lower accuracy datasets.
on their naive split and slightly high accuracy on That said, an approach which requires enumer-
their official split, we next show a considerable ating possible clue types is inherently limited by
decline in performance under a truly disjoint split the time and imagination of the people training the
(10.9% to 4.9%). This illustrates that, for a truly model. Expert humans flexibly learn and adapt to
disjoint split, training a larger model on more data new clue types and recognize novel ways in which
does not lead to real “success” on the task. (As a they are combined. For instance, a recent cryptic
point of comparison, t5-base achieved 1.1% on the crossword contained the clue: “Auntie is primed for
true disjoint split of our dataset). college, briefly (3).” The answer is “UNI”, which
Next, we apply our curricular pretraining ap- is derived by taking the “prime number” letters of
proach to T5-large, using our best performing ACW “auntie” (namely, the letters in positions 2, 3, and
+ ACW-descramble curriculum (three epochs of 5). These form the answer “UNI”, which is a syn-
pretraining) and show that it considerably improves onym for “college.” There are no clues like this in
primary task performance. In particular, perfor- our database, but an expert solver can draw on their
mance on the Cryptonite ‘official’ split almost dou- experience to understand how to solve this clue.
bles, from 10.9% to 19.9%, and performance on Being able to solve novel clue types like this
the true disjoint split more than doubles, improving points to the need for a system which can draw on
from 4.9% to 12.8%. Performance on the ‘naive’ a rich base of lexical and linguistic knowledge like
split does not change considerably with curricular that contained in T5 (that “college” and “uni” are
pretraining. This may be because the Cryptonite synonyms, that the word “prime” has a meaning in
training set itself is already a reasonably represen- math, that “briefly” indicates that the word beingclued is a shortening of a longer word “university”). Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
But it also needs to be able to more flexibly learn Kristina Toutanova. 2018. Bert: Pre-training of deep
bidirectional transformers for language understand-
different kinds of wordplay functions and how to
ing. arXiv preprint arXiv:1810.04805.
functionally compose them to create the answer
word. Given the need to learn novel functions, it Avia Efrat, Uri Shaham, Dan Kilman, and Omer Levy.
may be worth exploring other approaches to this 2021. Cryptonite: A cryptic crossword benchmark
for extreme ambiguity in language.
problem, like the compositional recursive learner
(Chang et al., 2019) or the recursive routing net- C. Fellbaum. 1998. WordNet: An electronic lexical
work (Cases et al., 2019). database. MIT Press, Cambridge, MA.
In that sense, we believe that the cryptic cross-
Robert M. French. 1999. Catastrophic forgetting in
word task serves as a good candidate task for those connectionist networks. Trends in Cognitive Sci-
interested in building NLP systems that can apply ences, 3(4):128–135.
linguistic knowledge in more creative, flexible, and
human-like ways. Kathryn J Friedlander and Philip A Fine. 2018. “the
penny drops”: Investigating insight through the
medium of cryptic crosswords. Frontiers in psychol-
9 Ethics ogy, 9:904.
To respect the intellectual property of the crossword Kathryn J Friedlander and Philip A Fine. 2020. Fluid
creators and publisher, we do not release the dataset intelligence is key to successful cryptic crossword
but make available the code we used to download solving. Journal of Expertise, 3(2):101–132.
and clean it. Matthew L Ginsberg. 2011. Dr. fill: Crosswords and an
implemented solver for singly weighted csps. Jour-
nal of Artificial Intelligence Research, 42:851–886.
References
D Hardcastle. 2001. Using the bnc to produce dialectic
Emily M Bender and Alexander Koller. 2020. Climb- cryptic crossword clues. In Corpus Linguistics 2001,
ing towards nlu: On meaning, form, and understand- pages 256–265.
ing in the age of data. In Proc. of ACL.
David Hardcastle. 2007. Riddle posed by computer (6):
Yonatan Bisk, Ari Holtzman, Jesse Thomason, Jacob the computer generation of cryptic crossword clues.
Andreas, Yoshua Bengio, Joyce Chai, Mirella Lap- Ph.D. thesis, Citeseer.
ata, Angeliki Lazaridou, Jonathan May, Aleksandr
Nisnevich, Nicolas Pinto, and Joseph Turian. 2020. M Hart and Robert H Davis. 1992. Cryptic crossword
Experience grounds language. clue interpreter. Information and Software Technol-
ogy, 34(1):16–27.
Tom B Brown, Benjamin Mann, Nick Ryder, Melanie
Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind He He, Nanyun Peng, and Percy Liang. 2019.
Neelakantan, Pranav Shyam, Girish Sastry, Amanda Pun generation with surprise. arXiv preprint
Askell, et al. 2020. Language models are few-shot arXiv:1904.06828.
learners. arXiv preprint arXiv:2005.14165.
Brad Jascob. 2019. bjascob/lemminflect.
Ignacio Cases, Clemens Rosenbaum, Matthew Riemer,
Atticus Geiger, Tim Klinger, Alex Tamkin, Olivia Justine T Kao, Roger Levy, and Noah D Goodman.
Li, Sandhini Agarwal, Joshua D. Greene, Dan Juraf- 2013. The funny thing about incongruity: A com-
sky, Christopher Potts, and Lauri Karttunen. 2019. putational model of humor in puns. In Proceedings
Recursive routing networks: Learning to compose of the Annual Meeting of the Cognitive Science Soci-
modules for language understanding. In Proceed- ety, volume 35.
ings of the 2019 Conference of the North American
Chapter of the Association for Computational Lin- Brenden M. Lake, Tomer D. Ullman, Joshua B. Tenen-
guistics: Human Language Technologies, Volume 1 baum, and Samuel J. Gershman. 2016. Building ma-
(Long and Short Papers), pages 3631–3648, Min- chines that learn and think like people.
neapolis, Minnesota. Association for Computational
Linguistics. Michael L Littman, Greg A Keim, and Noam Shazeer.
2002. A probabilistic approach to solving crossword
Michael B. Chang, Abhishek Gupta, Sergey Levine, puzzles. Artificial Intelligence, 134(1-2):23–55.
and Thomas L. Griffiths. 2019. Automatically com-
posing representation transformations as a means for Fuli Luo, Shunyao Li, Pengcheng Yang, Baobao
generalization. Chang, Zhifang Sui, Xu Sun, et al. 2019. Pun-gan:
Generative adversarial network for pun generation.
Robin Deits. 2015. rdeits/cryptics. arXiv preprint arXiv:1910.10950.Christopher D Manning, Kevin Clark, John Hewitt, Ur- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob
vashi Khandelwal, and Omer Levy. 2020. Emer- Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz
gent linguistic structure in artificial neural networks Kaiser, and Illia Polosukhin. 2017. Attention is all
trained by self-supervision. Proceedings of the Na- you need. In I. Guyon, U. V. Luxburg, S. Bengio,
tional Academy of Sciences. H. Wallach, R. Fergus, S. Vishwanathan, and R. Gar-
nett, editors, Advances in Neural Information Pro-
Gary Marcus. 2020. The next decade in ai: Four steps cessing Systems 30, pages 5998–6008. Curran Asso-
towards robust artificial intelligence. arXiv preprint ciates, Inc.
arXiv:2002.06177.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Chaumond, Clement Delangue, Anthony Moi, Pier-
Andrei A Rusu, Joel Veness, Marc G Bellemare, ric Cistac, Tim Rault, Rémi Louf, Morgan Funtow-
Alex Graves, Martin Riedmiller, Andreas K Fidje- icz, Joe Davison, Sam Shleifer, Patrick von Platen,
land, Georg Ostrovski, et al. 2015. Human-level Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu,
control through deep reinforcement learning. nature, Teven Le Scao, Sylvain Gugger, Mariama Drame,
518(7540):529–533. Quentin Lhoest, and Alexander M. Rush. 2020.
Transformers: State-of-the-art natural language pro-
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, cessing. In Proceedings of the 2020 Conference on
B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, Empirical Methods in Natural Language Processing:
R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, System Demonstrations, pages 38–45, Online. Asso-
D. Cournapeau, M. Brucher, M. Perrot, and E. Duch- ciation for Computational Linguistics.
esnay. 2011. Scikit-learn: Machine learning in
Python. Journal of Machine Learning Research,
12:2825–2830.
Saul Pwanson. 2021. [link].
Alec Radford, Jeffrey Wu, Rewon Child, David Luan,
Dario Amodei, and Ilya Sutskever. 2019. Language
models are unsupervised multitask learners. OpenAI
Blog, 1(8):9.
Colin Raffel, Noam Shazeer, Adam Roberts, Kather-
ine Lee, Sharan Narang, Michael Matena, Yanqi
Zhou, Wei Li, and Peter J. Liu. 2020. Exploring
the limits of transfer learning with a unified text-to-
text transformer. Journal of Machine Learning Re-
search, 21(140):1–67.
Anna Rogers, Olga Kovaleva, and Anna Rumshisky.
2020. A primer in bertology: What we know about
how bert works. arXiv preprint arXiv:2002.12327.
Noam Shazeer and Mitchell Stern. 2018. Adafactor:
Adaptive learning rates with sublinear memory cost.
In International Conference on Machine Learning,
pages 4596–4604. PMLR.
Noam M Shazeer, Michael L Littman, and Greg A
Keim. 1999. Solving crossword puzzles as proba-
bilistic constraint satisfaction. In AAAI/IAAI, pages
156–162.
David Silver, Aja Huang, Chris J Maddison, Arthur
Guez, Laurent Sifre, George Van Den Driessche, Ju-
lian Schrittwieser, Ioannis Antonoglou, Veda Pan-
neershelvam, Marc Lanctot, et al. 2016. Mastering
the game of go with deep neural networks and tree
search. nature, 529(7587):484–489.
David Silver, Thomas Hubert, Julian Schrittwieser,
Ioannis Antonoglou, Matthew Lai, Arthur Guez,
Marc Lanctot, Laurent Sifre, Dharshan Kumaran,
Thore Graepel, et al. 2018. A general reinforcement
learning algorithm that masters chess, shogi, and go
through self-play. Science, 362(6419):1140–1144.You can also read

















































