"Found in Translation" - Neural machine translation models for chemical reaction prediction - IBM RXN for Chemistry
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
“Found in Translation” – Neural machine
translation models for chemical reaction
prediction
Philippe Schwaller (@phisch124)
Chem. Sci., 2018, 9, 6091-6098
Theophile Gaudin, Riccardo Pisoni, David
Lanyi, Costas Bekas & Teodoro Laino
IBM Research Zurich, Switzerland
Alpha Lee
University of Cambridge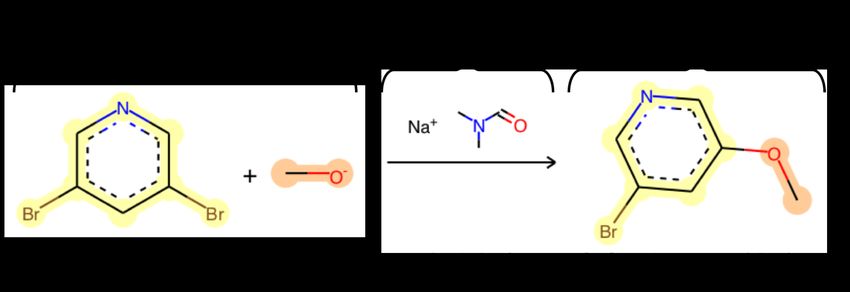
OH
O
O
Exploring the nearly
O
N
NH
S
endless chemical space
OH
OH
O
O
N
O
O
HO
Cl
Cl Cl
OH
O
Cl Cl
S
O
-
HO Na
+
O
O
De Novo Molecules Synthetic route planning
VAE / GAN / RL Reaction outcome prediction
Design Make
Test
Experimental verification
Credits to Marwin Segler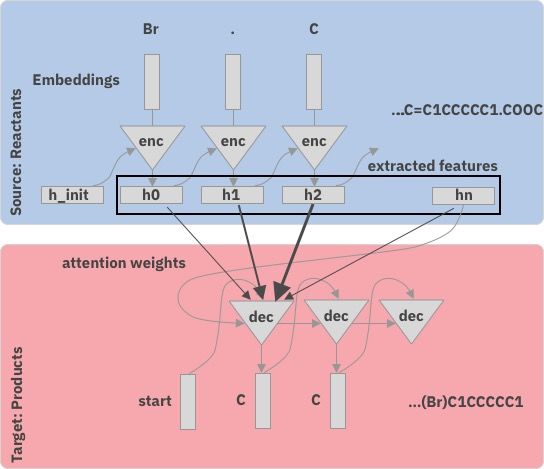
Chemical reaction prediction
Data
Lowe (2012, Jin et. al.
2017) SMARTS (NIPS 2017)
US patents - reactants>>products Benchmark dataset
- partly correct atom-mapping
- >1M reactions (USPTO_500k)
text-mining filtering
C:8
C:7 N:5 C:4
N:5 OH:13
N:6 O
-:16 OH:14 O:11
O:14
C:4 C:8 + :15
N
+ + S:9
C:7
N:6 C:3
C:2 O:10 :15
N
+
C:2
C:3 OH:12
Cl:1 O:17
O
-:16
Cl:1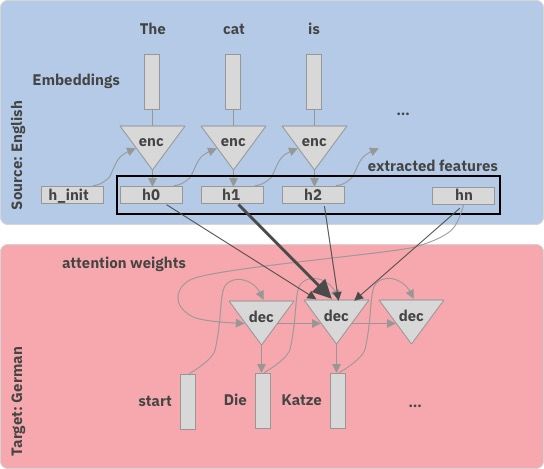
Representing molecules for ML N
N
O
Molecular fingerprints N
000010000….0100 N
Text-based representations O
- SMILES / INCHI
- CN1C=NC2=C1C(=O)N(C(=O)N2C)C
Graph-based
3D structure
N
N
O
N
N
O
1D 2D 3D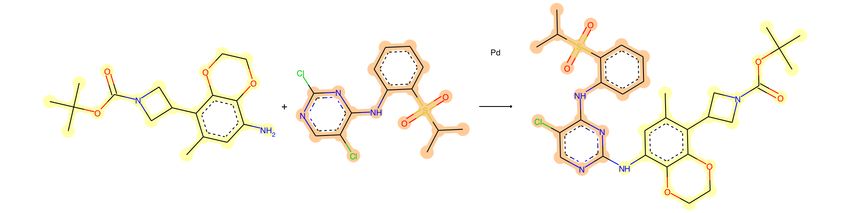
Atoms as letters, molecules as words SMILES to SMILES prediction with sequence-2-sequence models Schwaller et. al. Chem. Sci., 2018, 9, 6091-6098 / Nam & Kim arXiv:1612.09529
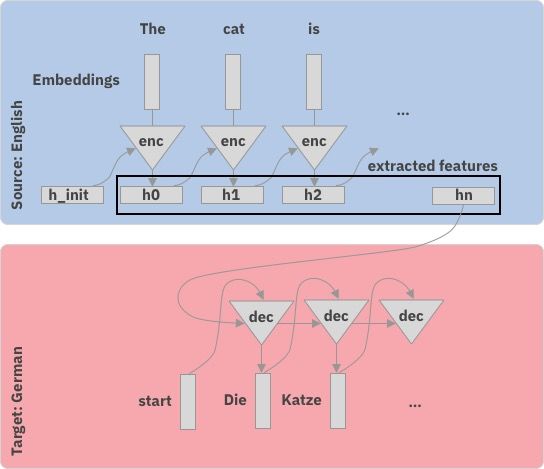
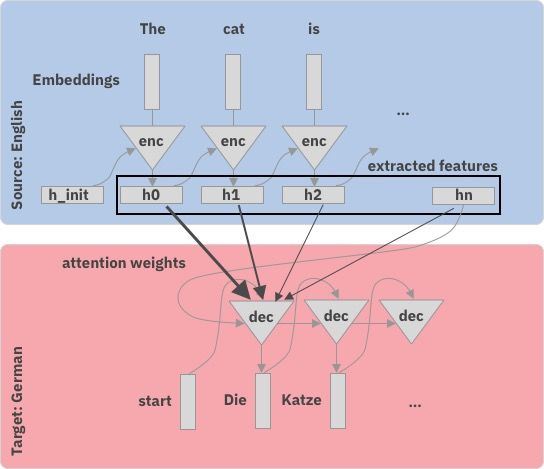
How do Seq-2-Seq models work?
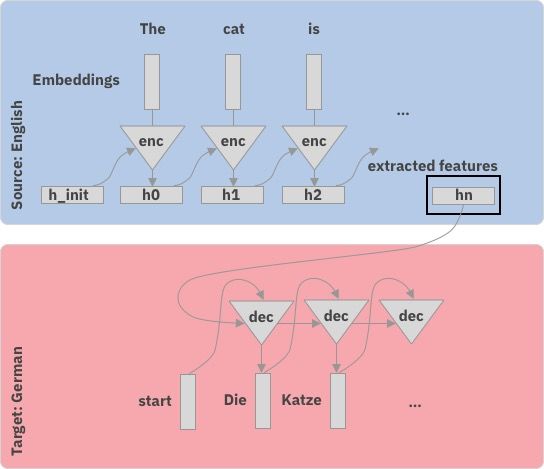
Step-by-step Inspired by Hendrik’s talk in Zurich
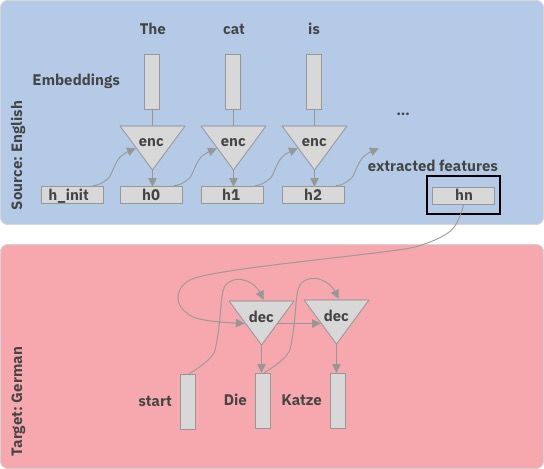
Step-by-step
with attention
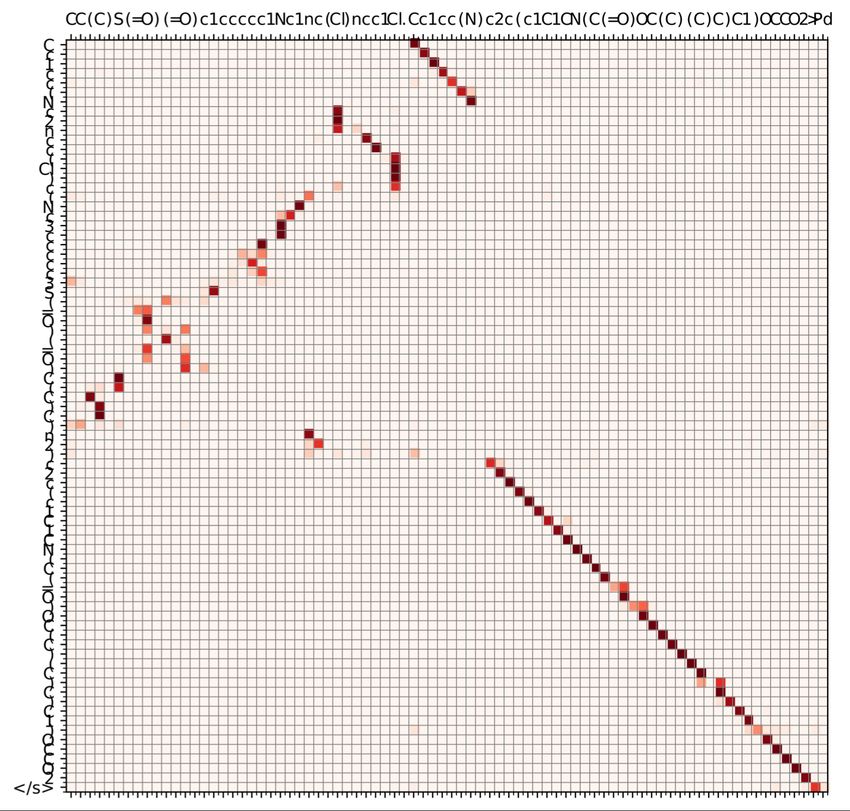
Source
Br . C C = C 1 C …
C
Prediction
Link to reaction prediction?
- Reactants to productsAttention weights Plotting the attention weights at every decoder time step.
Source: Reactants
Attention weights
Target: Product
Chloro Buchwald-Hartwig amination:
US20170240534A1Fully data-driven
Trained end-2-end
Template-free
SMILES-2-SMILES No
Attention weights
chemical
and confidence score
knowledge
incorporated
Less than 0.5%
invalid SMILES No atom-mapping
requiredOnly as good as Difficult to include
the training data negative data
Limitations
Chemically unreasonable
predictions possibleWhat other template-free approaches exist?
Graph neural networks
• Jin et al. (MIT, 2017): Weisfeiler-Lehman Networks (WLDN)
• Network 1: Reaction center identification
• Network 2: Product candidate ranking
• Trained separately
• Outperforms template-based by 10% on USPTO_500k dataset
• Bradshaw et al. (Cambridge, 2018): Electron path prediction
• Gated Graph Neural Networks
• Outperforms WLDN on USPTO_350k dataset
(subset without more difficult reactions, e. g. cycloadditions)
Fundamental limitation: require atom-mapped training setsHow do we perform compared to others?
Reactants > reagents Products
Top-1 accuracy:
Data set Jin et. al., Schwaller et. Bradshaw et Our new
WLDN al., Seq-2seq al., GGNN model
MIT_500k 79.6 % 80.3 % 88.8 %
-subset 350k 84.0 % 87.0 %
Reactants & reagents mixed Products
Data set Jin et. al., Schwaller et. al. Our new model
MIT_500k 74.0 %What else can we do? CC=C1CCCCC1.Cl>>CCC1(Cl)CCCCC1
Reaction scoring
v
ovniko
rk
Ma
Score: 0.99
Anti CC=C1CCCCC1.Cl>>CC(Cl)C1CCCCC1
-Mar
kovn
ikov
When we provide the model
with reactants>>products
Score: 0.001Booth #530 IBM RXN #RXNFORCHEMISTRY for Chemistry Freely available now: research.ibm.com/ai4chemistry
Questions?
IBM RXN
Chemistry
for
tr y
mis
e
ch
i4
/a
m
m.co
.i b
rch
resea
Philippe Schwaller
phs@zurich.ibm.com / @phisch124You can also read

















































