HPE and Mesosphere Simplify Container Management for Modern Data Centers Using Open Source DC/OS
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

HPE and Mesosphere Simplify Container Management for Modern Data Centers Using Open Source DC/OS Technical white paper
Technical white paper
Contents
Introduction ....................................................................................................................................................................................................................................................................................................................................................3
DC/OS ..................................................................................................................................................................................................................................................................................................................................................................3
Solution overview ..................................................................................................................................................................................................................................................................................................................................... 5
Server and networking hardware ........................................................................................................................................................................................................................................................................................ 5
DC/OS services .................................................................................................................................................................................................................................................................................................................................... 5
DC/OS installation ............................................................................................................................................................................................................................................................................................................................. 6
Data Analytics use case...................................................................................................................................................................................................................................................................................................................... 6
Components ........................................................................................................................................................................................................................................................................................................................................... 7
DC/OS Spark service....................................................................................................................................................................................................................................................................................................................... 9
Data Analytics use case implementation ...................................................................................................................................................................................................................................................................10
DC/OS service installation and configuration ........................................................................................................................................................................................................................................................10
Data Analytics results .................................................................................................................................................................................................................................................................................................................. 15
Container Orchestration use case........................................................................................................................................................................................................................................................................................... 16
Components ......................................................................................................................................................................................................................................................................................................................................... 17
Logical architecture ....................................................................................................................................................................................................................................................................................................................... 19
Marathon service for DC/OS.................................................................................................................................................................................................................................................................................................. 19
Container Orchestration use case implementation ..........................................................................................................................................................................................................................................19
DC/OS service installation and configuration .......................................................................................................................................................................................................................................................20
Container Orchestration results ........................................................................................................................................................................................................................................................................................28
Conclusion ...................................................................................................................................................................................................................................................................................................................................................30
Resources, contacts, or additional links ............................................................................................................................................................................................................................................................................30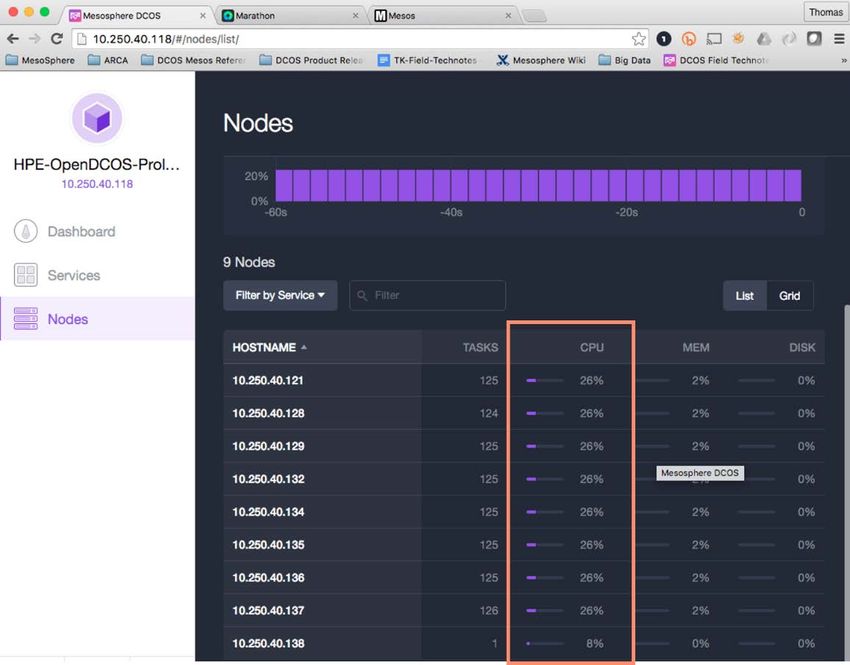
Technical white paper Page 3 Introduction Businesses today are faced with ever-increasing challenges to develop new services quickly, to gather and analyze large amounts and types of data, then act on the insights gained from the data by developing even more services and cloud-native or mobile apps. IT organizations, meanwhile, need to meet these challenges while addressing the traditional concerns of efficiency, security, service quality, and operational flexibility. Many companies are tackling these challenges by using modern distributed application architectures and by dynamically scaling up their IT— whether it is run in their own data centers or as a public cloud architecture enabled by a service provider. Many enterprise IT organizations and service providers have leveraged Mesosphere's industry-proven Data Center Operating System to achieve their goals of speed, agility, flexibility, and administrative efficiency. Recently, Mesosphere announced the release of an open-source version of its Data Center Operating System (DC/OS). To help HPE ProLiant and Cloudline server customers evaluate and test the open-source DC/OS on their systems, this white paper discusses two distinct use cases that show the flexibility and versatility of DC/OS —a data analytics use case and a container orchestration use case. The document outlines a solution architecture for deploying Apache Spark™, Kafka, Cassandra, and Zeppelin on DC/OS to provide a highly optimized environment for large-scale data processing while allowing for cluster utilization by other workloads like Web Servers or Java applications. We focus on achieving the following key business outcomes via DC/OS implementation on HPE ProLiant and Cloudline servers: • Hyperscale efficiency, flexibility, and automation—The DC/OS two-level scheduler architecture enables pooling of multiple distributed workloads (DC/OS services). Deploying, scaling, and managing services are simplified to single commands, and security and business continuity are also dramatically simplified. HPE ProLiant servers provide flexible designs with ideal memory and I/O expandability along with world-class performance for data center environments. HPE Cloudline servers are built for extreme scale and are designed for service providers who need fast deployment, flexible operation, and low total cost of ownership. • Accelerated time to value for new services—DC/OS enables enterprises to easily roll out and scale (to multiple development teams) a continuous integration and delivery model using common tools like Jenkins (an open-source continuous integration tool), artifact repositories, and source control tools. • Agile infrastructure management—ProLiant servers provide robust infrastructure management and update tools like HPE OneView and Smart Update and embedded management tools like HPE iLO to deploy and monitor your server remotely. Cloudline servers, on the other hand, are built on an open management design philosophy and leverage common industry interfaces so they can fit easily into a multi-vendor environment where the same service provider management software may be running on platforms sourced from different vendors. HPE is a founding member of the Redfish specification, which is the open industry standard for software-defined data centers and is based largely on HPE’s work to implement the RESTful API for iLO. HPE implements the Redfish API in both ProLiant and Cloudline servers. • Movement, integration, and delivery of applications across multiple environments—HPE believes strongly in open standards, API-based architectures, and open-source software, including Cloud Foundry, DC/OS, and OpenStack. Whether your cloud environment is public, private, or hybrid, you can choose from a vast global ecosystem of hardware, software, and services for your cloud computing needs. • Quickly gain insights from ubiquitous data—DC/OS elegantly runs common services like Kafka, Spark, and Cassandra that power many of today’s Internet of Things and big data stacks, enabling enterprises to run a simple and integrated turnkey solution powering their big data applications. DC/OS DC/OS is an open-source software project that creates an operating system that spans all of the machines in your datacenter or cloud and provides a powerful abstraction layer for your computing needs. DC/OS is powered by the Apache Mesos distributed systems kernel, which is a highly scalable two-level scheduler that pools your infrastructure, automatically allocating resources, and scheduling tasks based on demands and policy. It provides a highly elastic and scalable way of developing and deploying applications, services, and big data infrastructure on shared resources. You can run all your apps and workloads, from platform-as-a-service (PaaS)-based microservices to big data and databases—and everything in between (Figure 1).
Technical white paper Page 4 DC/OS runs in any modern Linux® environment: public and private cloud, virtual machines, and bare metal x86 servers, allowing you to use the underlying cluster resources more efficiently. Figure 1. DC/OS architectural overview (source: Mesosphere). DC/OS provides the following operational advantages: • Ease of install and control: The user interface lets you control the entire DC/OS-powered data center (install DC/OS services and groups of DC/OS services) from a single command line and single web user interface. • Runtime configuration update and software upgrades: Update DC/OS service configurations and upgrade software during runtime for continuous operations. • Simplified infrastructure: Eliminate statically partitioned and uniquely configured environments and unlock dramatically higher server utilization. In addition, running Spark, Kafka, and Cassandra on DC/OS allows you to scale up (or down) the compute resources dynamically. • Fault-domain-aware placement and data replication: DC/OS services automatically provision nodes and intelligently replicate data across fault domains (i.e., racks) for improved availability and data durability. • Automatic failed server recovery: Configurable policies enable DC/OS services to remediate failed servers automatically for improved availability. • Run multiple processing engines and change components easily: Run different versions of data processing (e.g., Spark) jobs against the same Spark Dispatcher. Add or modify components to accommodate changing business needs. For example, you could change Zeppelin to IPython or use ArangoDB instead of Cassandra without having to purchase or repurpose hardware. • Write once, run anywhere: DC/OS provides an abstraction layer that you can write against which is the same no matter where the DC/OS installed (your own infrastructure or a service provider’s). There is no longer a need to understand the APIs of separate cloud providers, because simple commands (such as DC/OS package install spark) work everywhere.
Technical white paper Page 5 Solution overview The solution architecture is based on DC/OS installed on HPE servers running Red Hat® Enterprise Linux® 7.2. Each use case has its own DC/OS Cluster comprised of Master Nodes and DC/OS Agent Nodes. • Three DC/OS Master Nodes host the Cluster Management Services, including the following services: – Mesos Masters – Service Discovery – Name Resolution – DC/OS Service Administration – DC/OS Service Availability Management • DC/OS Agent Nodes perform the work in the cluster on behalf of the DC/OS services; these nodes leverage containers to achieve process, memory, disk, and network isolation. Server and networking hardware For these two use case examples, DC/OS was installed on two separate hardware environments to show how hardware could be optimally deployed to match the use case. For the Data Analytics use case, we used HPE Cloudline CL 2100 and CL5200 servers that are optimized for Service Providers and built for extreme scale. These bare-metal, rack-mount servers are cost-optimized for large-scale deployments and designed for environments where resiliency is software-based and derived from your service application. • The Cloudline CL2100 server design includes two Intel® Xeon® E5–2600 v3/v4 processors and is matched by the 16 DIMM slots to accommodate demanding memory and storage applications such as NoSQL, cloud, caching and search workloads. • The Cloudline CL5200 Server is a high density, storage server designed for high-density storage to run cloud storage and data analytics/Big Data applications. It includes up to 80 hard disk drives in a single 4U chassis. For the Container Orchestration use case, we used HPE ProLiant DL360 Gen9 and DL380 Gen9 servers, designed for mixed workloads in enterprise environments. ProLiant servers have a long history for providing industry-leading performance and provide a comprehensive portfolio of versatile and reliable servers that deliver data center efficiency across numerous workload and application types. • The ProLiant DL360 Gen9 server delivers an optimal 2P unit (with two Intel Xeon E5–2600 v4 processors) along with the latest HPE 2400 MHz DDR4 Smart Memory. It combines high-performance, low energy consumption, improved uptime, and increased density, all in a compact 1U chassis. • The ProLiant DL380 Gen9 server delivers the latest in performance, also using Intel Xeon E5–2600 v4 processors and HPE 2400 MHz DDR4 Smart Memory. The DL380 Gen9, however, provides an extremely expandable environment that is also highly reliable and serviceable with near continuous availability. DC/OS services Spark Apache Spark is a fast and general engine for large-scale data processing. Spark has an execution engine that supports advanced features and in-memory computing. Using Spark, customers can run programs up to 100X faster than Hadoop MapReduce in memory, or 10X faster than on disk. Cassandra Apache Cassandra is an open-source distributed database designed to handle large amounts of data across commodity servers, providing high availability with no single point of failure. Cassandra was designed for clusters spanning multiple datacenters providing high performance and low latency operations for all clients.
Technical white paper Page 6 Kafka Apache Kafka is a high throughput, publish-subscribe messaging solution implemented as a distributed, partitioned, replicated commit log service. Kafka is extremely highly performing, with a single Kafka broker being able to handle hundreds of megabytes of reads and writes per second from thousands of clients. Because of its distributed nature and message persistence across multiple replicas, the solution can be maintained or expanded live without downtime. Zeppelin Apache Zeppelin is a web-based notebook that enables interactive data analytics and lets you make collaborative data visualization documents with applications such as SQL and Scala. Zeppelin leverages interpreters that are pluggable language/data processing backends and can be used to build queries and data analysis. Zeppelin includes interpreters for Scala, Python, SparkSQL, Apache Hive™, Markdown, Shell and more. Data scientists can use Zeppelin to dramatically reduce the amount of time it takes to do data interpretation. Marathon Marathon is a production-grade container orchestration platform for Mesosphere’s Datacenter Operating System (DCOS). Marathon is a mature platform that includes advanced placement characteristics, Service Discovery and Load Balancing, Multiple Container technologies (Mesos containers and Docker), and Health Checks. DC/OS installation This section discusses the installation and configuration of the DC/OS environment for the Data Analytics and Container Orchestration use cases. We will not cover the DC/OS installation in detail and although DC/OS was installed in two separate environments, there were no fundamental differences between the installation processes aside from changing environment-specific information. We configured all DC/OS Cluster nodes as follows: Installed Red Hat Enterprise Linux 7.2 with Docker 1.10.3. Created a Logical Volume of type thin-pool from two physical disks on each node. Configured Docker daemon via a drop in file for Systemd to use Devicemapper Storage Driver, which was mapped to the Logical Volume thin- pool created in the previous step. Stopped the firewall and set SElinux to permissive mode. DC/OS installation is an automated image-based install that provides optimized build settings based on customer inputs. You can find instructions for DC/OS installation at docs.mesosphere.com/concepts/installing/. The DC/OS CLI is installed on workstations to allow both Administrators and Data Analysts to interact with DC/OS, Spark, Kafka, and Cassandra through the DC/OS CLI and Service Sub-CLI without having to SSH directly into the DC/OS Master or Agent nodes.. You can find installation instructions for DC/OS CLI at docs.mesosphere.com/administration/introcli/cli/. Data Analytics use case The Data Analytics use case uses a sample Twitter-like application called “Tweeter” that produces tweets, streams those tweets to Kafka brokers as they come in, and then stores the tweets in Cassandra, as shown in Figure 2. We will then use Zeppelin and Spark to perform real time analytics on those data streams. As described previously, Zeppelin enables interactive, real-time data analysis using interpreters like Spark SQL or Spark Streaming of your data. Zeppelin also provides the ability to create visually appealing graphical representations of this data, while Spark is the back-end engine that powers the data processing.
Technical white paper Page 7
Figure 2. Tweeter application logical architecture (source: Mesosphere).
Components
Table 1 and Table 2 give the hardware and software components used for the Data Analytics use case, and
Figure 3 shows how the physical components were placed in the rack.
Table 1. Hardware components for the Data Analytics use case
HARDWARE VERIFIED VERSION
DC/OS Master Cluster Nodes HPE Cloudline CL 2100
• 2 x 10 cores (Haswell CPUs)
• 128 GB Memory
• One 2 TB OS Drive
• Three 6 TB Data Disks
DC/OS Agent Compute Nodes HPE Cloudline CL 2100
• 2 x 10 cores (Haswell CPUs)
• 128GB Memory
• One 2 TB OS Drive
• Three 6 TB Data Disks
HPE Cloudline CL5200
• 2x12 cores (Haswell CPUs)
• 256GB Memory
• One 2 TB OS Drive
• Ten 6 TB Data Drives
Network HP Procurve 2510–48 J9020A
H3C S5820X Series Switch
Storage HPE Cloudline CL5200–Compute + Storage
• 2 x 12 Cores (Haswell CPUs)
• 256 GB Memory
• One 2 TB OS Drive
• Ten 6 TB Data Drives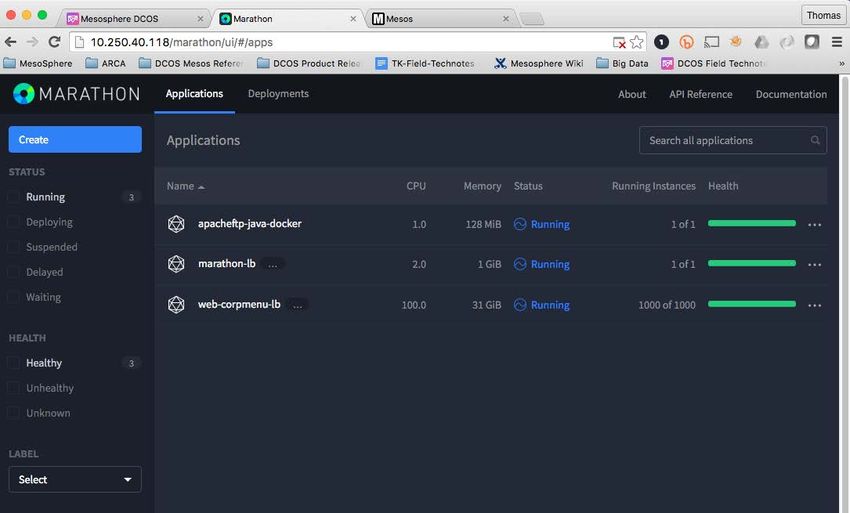
Technical white paper Page 8 Table 2. Software components for the Data Analytics use case SOFTWARE VERIFIED VERSION DC/OS 1.6.1 Docker Daemon 1.10.3 Red Hat Enterprise Linux 7.2 Figure 3. Physical configuration for the Data Analytics use case. The Data Analytics use case has a total of 3 DC/OS Master Nodes and 12 DC/OS Agent Nodes, as illustrated in Figure 4. One of the Agent Nodes is configured with the DC/OS Public Agent role. This allows differentiated network security profiles to be applied to the server, since it will be used for exposing any applications that require access from the corporate network. In this use case, a load balancer (marathon-lb) will be deployed to the Public Agent to expose the Tweeter application as well as the Zeppelin notebooks outside the cluster.
Technical white paper Page 9 Figure 4. Data Analytics DC/OS component distribution (source: Mesosphere). DC/OS Spark service Spark natively supports using Apache Mesos as its “cluster manager” that is used to allocate resources across Spark jobs. Spark on DC/OS supports cluster mode. When you install the Spark package from the DC/OS Universe Repository (a repository that stores available DC/OS services), the Spark driver automatically starts running as a Cluster Dispatcher and is managed by Marathon.
Technical white paper Page 10
Figure 5. Spark architecture on DC/OS (source: Mesosphere).
Data Analytics use case implementation
After DC/OS is installed, you can add powerful and complex functionality with a single command, within just a few minutes. Without DC/OS, just
installing and setting up one of these services can take days and weeks. DC/OS services also include the Management interfaces for those
Services. This includes any CLI commands or web interfaces proxied over HTTP/HTTPS on the DC/OS Master Nodes and available from the
Services Tab in the DC/OS Web UI.
DC/OS service installation and configuration
The DC/OS service is installed and configured by using the following simple commands. For services that have sub-commands in steps 1–5, the
sub-commands are installed automatically with the DC/OS package install command for those services.
Install the Marathon load balancer (marathon-lb) DC/OS service, which provides simplified service discovery and service load balancing for
Marathon applications. In this use case, the marathon-lb service is used for accessing the Tweeter application UI from outside the DC/OS
cluster over a Load Balancer virtual IP address (VIP) and service port.
$ dcos package install –-yes marathon-lb
Install the Cassandra service on DC/OS.
NOTE: Customized install options are available by adding the --options=filename.json argument during installation.
$ dcos package install --yes cassandra
Install the Kafka service on DC/OS.
NOTE: Customized install options are available by adding the --options=filename.json argument during installation.
$ dcos package install --yes kafkaTechnical white paper Page 11
Install Spark using the DC/OS CLI, just as with the other DC/OS services. More advanced options are possible by specifying a config.json
file during the installation.
$ dcos package install --yes spark
Install Zeppelin in the same way as the other DC/OS services.
$ dcos package install --yes zeppelin
In the previous steps, any associated DC/OS Sub CLI commands are installed automatically along with the DC/OS services. For Kafka, we used
the DC/OS Sub CLI to add the three brokers and configure them.
$ dcos kafka broker add 0..2
$ dcos kafka broker start 0..2
To install the Tweeter application, it is pulled from GitHub and deployed by using the DC/OS Marathon Sub CLI.
$ cd /home/user1/mesosphere/tweeter
$ dcos marathon app add marathon.json
At this point, the environment as shown in the Marathon Web UI should look like Figure 6.
Figure 6. Marathon UI for the Data Analytics use case
Next, we will check the services we stood up, including the Tweeter application. The Tweeter application has definitions that tell DC/OS to
expose its application Interface in the marathon-lb service over a specific service port (in this case, the service port is 10000). By opening a
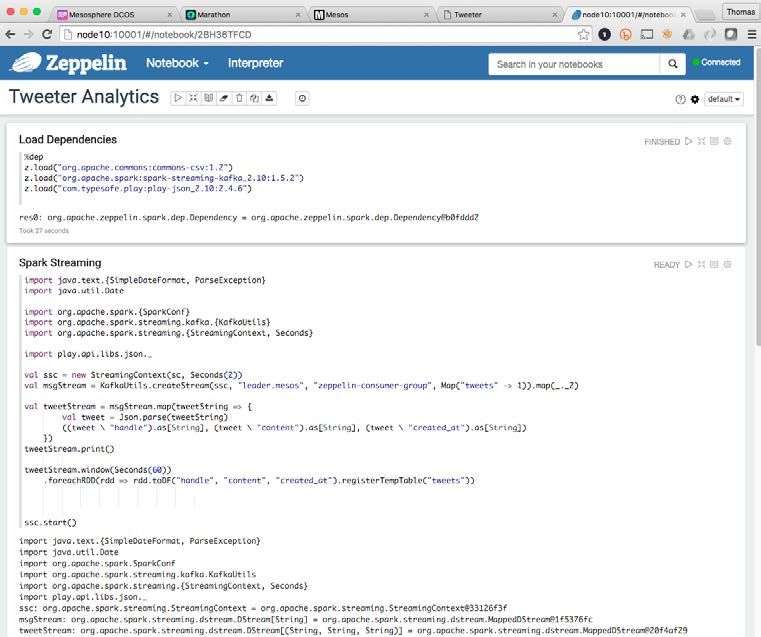
browser to http://:10000, we should be able to see the application without any tweets posted (Figure 7).Technical white paper Page 12 Figure 7. Tweeter application UI exposed from the Marathon load balancer For this test configuration, we populated the Tweeter application with content by sending more than 100,000 tweets to Kafka. We sent the tweets using a Ruby application, which takes pieces of text from Shakespeare plays that have been stored in a text file. Figure 8 shows the Tweeter application again after the data has been populated. Figure 8. Tweeter application UI after populating with tweets. Now, we use Zeppelin to generate graphics from the artificially generated tweet data. Zeppelin Web UI traffic is exposed over two ports that are assigned by DC/OS dynamically by default. Best practice is to configure Zeppelin to use Marathon-lb by using Marathon Labels that specify the load balancer profile and service port. To perform real time analysis on the streaming tweet data, we navigate to the DC/OS Public Agent IP or Hostname with the Service Port configured for the Zeppelin Service (100001) and open the Zeppelin Web UI (Figure 9). a. From the Zeppelin Web UI, we can import a Notebook or create a new one. b. For demonstration purposes, we have imported the “Tweeter Analytics” Zeppelin notebook from our Tweeter application repository.
Technical white paper Page 13 Figure 9. Zeppelin UI Exposed from Marathon Load Balancer After importing the Zeppelin notebook, we run Spark Streaming tasks against the streaming dataset of “Tweets” as shown by the examples in Figure 10 through Figure 12.
Technical white paper Page 14 Figure 10. Zeppelin UI showing Tweeter Spark notebook. Figure 11. Zeppelin Tweeter Spark notebook showing pie chart of top tweeters.
Technical white paper Page 15 Figure 12. Zeppelin Tweeter Spark notebook showing bar chart of top tweeters. Data Analytics results DC/OS leverages all available cluster agents efficiently to execute the computational tasks on our data set (Figure 13). We can see the resource utilization of the cluster nodes increase because there are no other workloads running on these DC/OS Agents. DC/OS leverages Mesos dominant resource fairness (DRF), a fair-share algorithm to balance the work that needs to be completed throughout the cluster and to provide resources in a fair and consistent manner.
Technical white paper Page 16 Figure 13. Dashboard for the DC/OS UI. Container Orchestration use case The Container Orchestration use case is similar to the Data Analytics use case, but we installed it on a different hardware platform that is best suited for a mixed workload. Also, we only need the DC/OS Marathon and Marathon-lb Services to achieve this use case. The use case documents how to efficiently deploy a large number of applications on Marathon running on DC/OS, including a simulated legacy Java application running under Docker and a web server with a Corporate Menu running in a native Linux container. The DC/OS platform provides a Universal Containerizer, which abstracts the underlying container technology from the application developers so they can focus on their application and not the isolation mechanism or infrastructure supporting it.
Technical white paper Page 17
Components
Table 3 and Table 4 give the hardware and software components used for the Data Analytics use case, and Figure 14 shows how the physical
components were placed in the rack.
Table 3. Hardware components used in Container Orchestration use case
HARDWARE VERIFIED VERSION
DC/OS Master Cluster Nodes HPE ProLiant DL380 G9
• 1 x 6 cores (Haswell CPUs)
• 64 GB Memory
• 1.2 TB OS Drive
DC/OS Agent Compute Nodes HPE ProLiant DL380 G9
• 2 x 12 cores (Haswell CPUs)
• 256 GB Memory
• 600 GB OS Drive
• 6 TB Data Drive
HPE ProLiant DL360 G9
• 2 x 12 cores (Haswell CPUs)
• 256 GB Memory
• 600 GB OS Drive
• 6 TB Data Drive
Network HPE FlexFabric 5900 series switch for 2 x 10 GbE connections to each server
HPE FlexFabric 5700 series switch for 1 GbE connection to iLO ports on each
server
Storage 6 TB SAS data drives on the Agent Compute Nodes
Table 4. Software components used in Container Orchestration use case
SOFTWARE VERIFIED VERSION
DC/OS 1.6.1
Docker Daemon 1.10.3
Red Hat Enterprise Linux 7.2Technical white paper Page 18 Figure 14. Rack configuration for Container Orchestration use case.
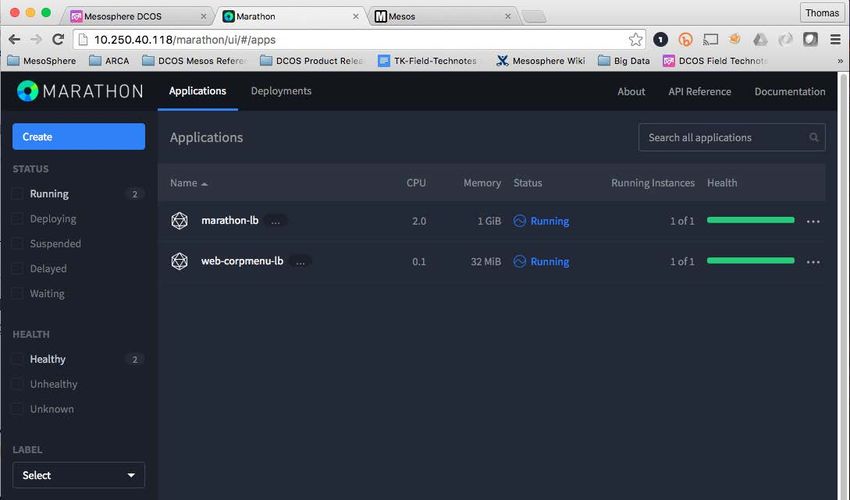
Technical white paper Page 19 Logical architecture Figure 15. Logical architecture of DC/OS with Marathon (source: Mesosphere). Marathon service for DC/OS Marathon is a cluster scheduler that provides extremely scalable cluster-wide deployment and management of application services running on DC/OS. The Marathon framework consumes Mesos resource “offers” and facilitates the running of tasks based on these resources. Marathon provides a common abstraction language for starting, scheduling, and scaling application services on distributed clusters of x86 servers that are managed by DC/OS. In the context of this whitepaper, Marathon is a DC/OS service running on top of DC/OS; it includes its own scheduler that can add, restart, scale, and stop tasks or application services within containers. For this use case, Marathon handles the “plumbing” for our application, including the following: • Scaling the application • Ensuring it is running the correct number of instances • Automatically updating the Load Balancer Pool members as the application is scaled • Monitoring the health and versioning for the applications Container Orchestration use case implementation DC/OS ships with its own resilient Marathon service for managing long running applications on DC/OS that we will use for the Container Orchestration use case. The only other DC/OS Service we will need for this use case is marathon-lb, which provides simplified service discovery and service load balancing for Marathon applications.
Technical white paper Page 20
DC/OS service installation and configuration
As with the Data Analytics use case, the DC/OS service can be installed and configured by using a simple command.
Install the marathon-lb using the following command.
$ dcos package install –yes marathon-lb
At this point, you will have a DC/OS cluster environment with marathon-lb running on the DC/OS Public Agent ready to expose VIP addresses
and ports of Marathon applications that are configured to use load balancing services.
Figure 16. Marathon UI showing Container Orchestration use case.
Test corporate web menu server using native Linux containers
DC/OS supports both native Linux containers as well as Docker containers—all with the same Marathon application specification language.
The following steps show how to configure a Marathon application to run a Web Server in Python inside a native Linux container. The application
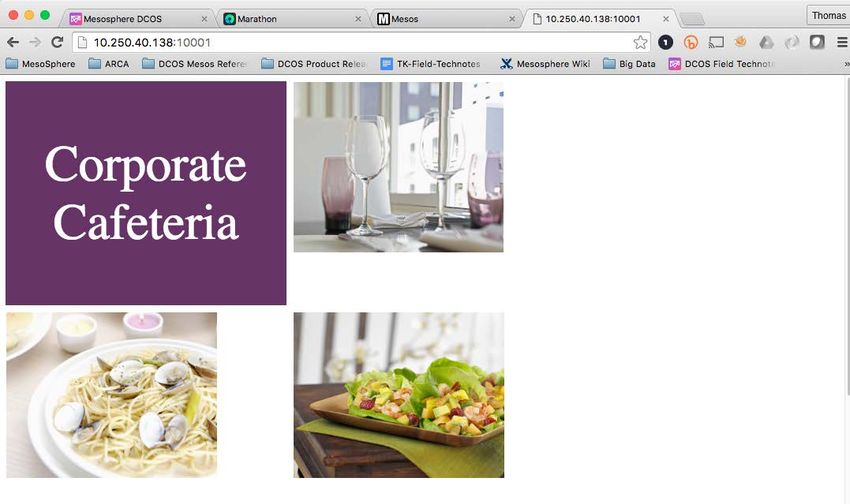
serves a Corporate Cafeteria Menu from the Load Balancer VIP. The Marathon Load Balancer will proxy the connections back to the pool
members as we scale up the application.
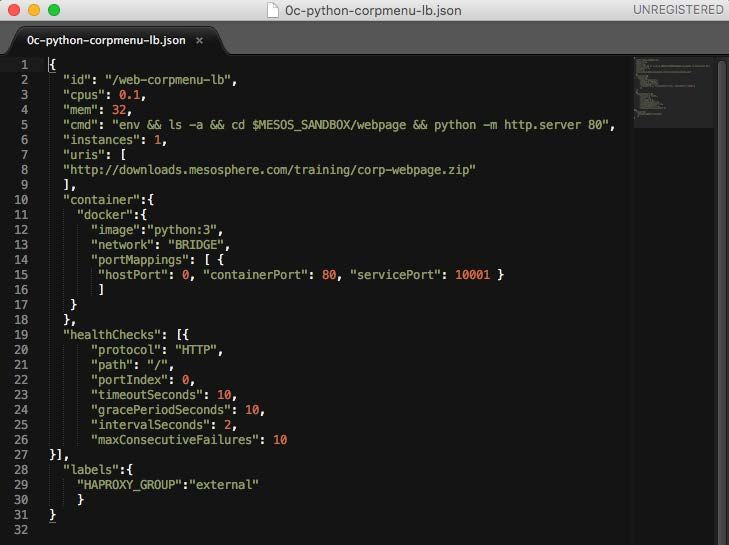
As shown in Figure 17, the Marathon application definition is a simple.json file.Technical white paper Page 21
Figure 17. Web Menu Python application definition for native Linux container.
We can deploy the application from the Marathon UI or from the DC/OS CLI. The example below uses the DC/OS CLI.
$ dcos marathon app add 0c-python-corpmenu-lb.json
Figure 18. Container Orchestration Marathon UI with Web Menu application.
The Corporate Menu application definition contains instructions for connecting this application to the Load Balancer and which TCP Port to
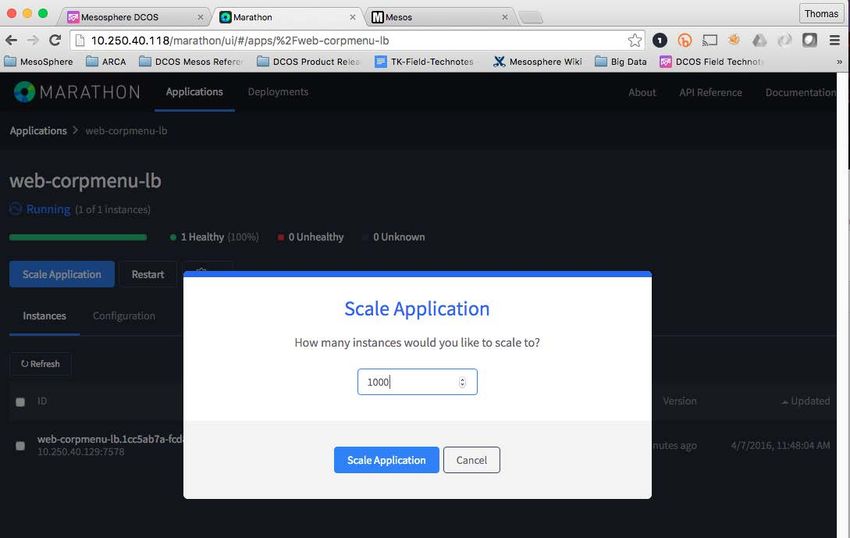
expose for the Web Service. This port gets proxied back to the specific DC/OS Agent on a randomly chosen port that is assigned andTechnical white paper Page 22 managed by Mesos and Marathon for each instance in our application. We started the web-corpmenu-lb application with a single instance but as we scale, Marathon manages the complexity for us. NOTE: For an explanation of Marathon application definitions and syntax, see mesosphere.github.io/marathon/docs/application-basics.html. Next, we test the application by accessing the Load Balancer VIP on the service port we specified (10001). The Load Balancer is running on our DC/OS Public Agent, which is 10.250.40.138. Figure 19. Container Orchestration Web Menu application UI exposed by Marathon load balancer. Now we can scale our application to 1000 instances. Marathon will deploy the instances, track the progress of each instance, and display the status in the UI. The instances are very quickly instantiated throughout the cluster on the nine DC/OS Private Agents.
Technical white paper Page 23 Figure 20. Scaling the Web Menu application to 1000 instances (shown in Marathon UI). Figure 21. Marathon Web UI manages and displays status during scaling activity for Web Menu application.
Technical white paper Page 24 As the Marathon application for the Corporate Web Menu scales to 1000 instances, Marathon spreads these instances automatically across the available DC/OS Agents. Marathon distributes the instances according to the utilization and the application Constraints initially provided in the Marathon application Definition. Figure 22 shows the DC/OS cluster utilization starting to increase. Figure 22. DC/OS Cluster utilization with 1000 instances running of Web Menu application. Test network Java application using Docker image After the 1000 instances of the Corporate Web Menu are started, we will build and deploy a second Marathon application. This Marathon application leverages a previously built Docker image that installs a Java Runtime Environment and the binaries for our application from a Uniform Resource Identifier defined in the Marathon application definition. Ultimately, this application will run Apache FTP Server based on the Apache MINA Project.
Technical white paper Page 25
Figure 23. Marathon application definition for Java application in Docker container.
To deploy the application using the DC/OS CLI, use the following command.
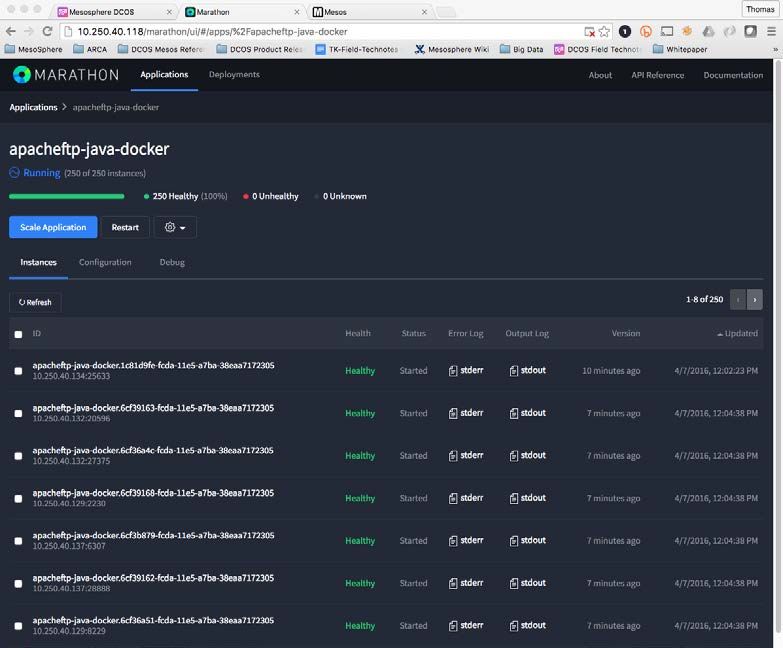
$ dcos marathon app add 10b-apacheftp-java-docker.jsonTechnical white paper Page 26 Figure 24. Marathon UI after adding single instance of Java application for Docker. Figure 25 shows the application scaled to 250 instances. Figure 25. Marathon UI after scaling Java application to 250 instances.
Technical white paper Page 27 Unlike the Web Server example, we are not using a Load Balancer for this application. Therefore, in this case, we would rely on a Service Discovery tool like Mesos-DNS. (Mesos-DNS is included in and configured automatically with DC/OS). For this exercise, we can use the Marathon UI to determine the IP: Port combination assigned by Marathon for the application instance that we want to connect to. Figure 26. Marathon UI network information for one instance of the Java application. We can now use an FTP client to test one of the 250 instances deployed for our test Java application. Figure 27. Java application test From Linux Bash FTP client.
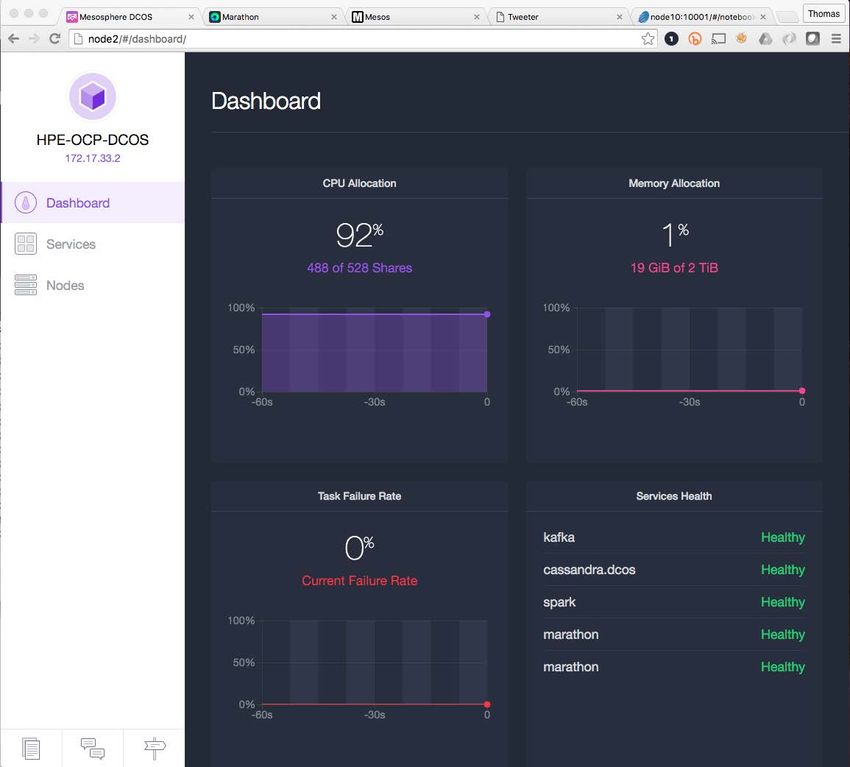
Technical white paper Page 28 Container Orchestration results In this example, we delivered a large number of application instances across the DC/OS cluster running on two different Container technologies in a matter of minutes and scaled these applications to hundreds of Instances in a matter of seconds. We also achieved higher utilization levels with our DC/OS cluster getting a better ROI for our hardware investment. Figure 28. Marathon UI showing both applications running at scale. Figure 29. DC/OS UI cluster utilization with both test applications running at scale.
Technical white paper Page 29 Figure 30. DC/OS Dashboard with both test applications running at scale.
Technical white paper Page 30
Conclusion
The Datacenter Operating System (DC/OS) is an open-source, industry-proven platform of choice for enterprises running modern apps, powered
by the Apache Mesos distributed systems kernel. For enterprises and cloud service providers, using DC/OS with HPE ProLiant and Cloudline
Servers enables an automated hyperscale operating model using open-source software. Enterprises get the broadest flexibility and agility in
running modern distributed applications and the confidence only possible from HPE systems.
Resources, contacts, or additional links
HPE solutions
hpe.com/us/en/solutions/infrastructure.html
HPE technical white papers
hpe.com/docs/servertechnology
Mesosphere
mesosphere.com
DC/OS open source
dcos.io
Sign up for updates
Rate this document
© Copyright 2016 Hewlett Packard Enterprise Development LP. The information contained herein is subject to change without notice.
The only warranties for HPE products and services are set forth in the express warranty statements accompanying such products and
services. Nothing herein should be construed as constituting an additional warranty. HPE shall not be liable for technical or editorial errors
or omissions contained herein.
Intel and Xeon are trademarks of Intel Corporation in the U.S. and other countries. Linux is a registered trademark of Linus Torvalds.
Microsoft is a registered trademark of Microsoft Corporation in the United States and/or other countries. Red Hat and Enterprise Linux
are registered trademarks of Red Hat, Inc. in the United States and other countries.
4AA6-5134ENW, April 2016You can also read

















































