On the (Im)Practicality of Adversarial Perturbation for Image Privacy
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Proceedings on Privacy Enhancing Technologies ; 2021 (1):85–106
Arezoo Rajabi*, Rakesh B. Bobba*, Mike Rosulek, Charles V. Wright, and Wu-chi Feng
On the (Im)Practicality of Adversarial Perturbation for Image
Privacy
Abstract: Image hosting platforms are a popular way
to store and share images with family members and
friends. However, such platforms typically have full ac-
cess to images raising privacy concerns. These concerns
are further exacerbated with the advent of Convolu-
tional Neural Networks (CNNs) that can be trained on
available images to automatically detect and recognize
Fig. 1. From left to right: original image, UEP perturbed image,
faces with high accuracy. and k-RTIO perturbed image.
Recently, adversarial perturbations have been proposed
as a potential defense against automated recognition
and classification of images by CNNs. In this paper, 1 Introduction
we explore the practicality of adversarial perturbation-
based approaches as a privacy defense against au- Integration of high-resolution cameras into ubiquitous
tomated face recognition. Specifically, we first iden- handheld devices (e.g., mobiles, tablets) has made it
tify practical requirements for such approaches and easy to capture everyday moments in digital photos.
then propose two practical adversarial perturbation ap- Combined with the availability of fast mobile networks
proaches – (i) learned universal ensemble perturbations many of the captured digital images and videos are
(UEP), and (ii) k-randomized transparent image over- shared over the network or transmitted to third-party
lays (k-RTIO) that are semantic adversarial perturba- storage providers. It has been reported that users of
tions. We demonstrate how users can generate effective social networks share more than 1.8 billion new photos
transferable perturbations under realistic assumptions each day [2]. While cloud-based photo storage and shar-
with less effort. ing platforms provide virtually unlimited storage space
We evaluate the proposed methods against state-of-the- for saving and sharing images and are highly reliable
art online and offline face recognition models, Clari- and available, such services also raise privacy concerns.
fai.com and DeepFace, respectively. Our findings show Although most social networks and photo storage and
that UEP and k-RTIO respectively achieve more than sharing platforms now provide privacy settings to limit
85% and 90% success against face recognition models. public accessibility of images, they are often compli-
Additionally, we explore potential countermeasures that cated and insufficient [54, 65]. Furthermore, those plat-
classifiers can use to thwart the proposed defenses. Par- forms have direct access to users’ images and it is not
ticularly, we demonstrate one effective countermeasure inconceivable for such service providers to exploit the
against UEP. users’ image data for their own benefit [62, 68].
Keywords: Image Privacy, Convolutional Neural Net- The advent of scalable Convolutional Neural Net-
works (CNNs), Adversarial Examples, Transferable Per- works (CNNs) for automated face detection and recog-
turbations, Transparent Image Overlays nition [35, 38, 45, 70, 77] exacerbates this concern. While
such tools provide benign and beneficial service to users,
DOI 10.2478/popets-2021-0006
they nevertheless pose a significant privacy threat. For
Received 2020-05-31; revised 2020-09-15; accepted 2020-09-16.
example, Shoshitaishvili et al. [65] recently proposed
a method for tracking relationships among people by
analyzing pictures shared on social platforms using
*Corresponding Author: Arezoo Rajabi: Oregon State face recognition and detection CNNs. Recently, a face-
University, rajabia@oregonstate.edu
recognition based image search application, Clearview
*Corresponding Author: Rakesh B. Bobba: Oregon
State University, rakesh.bobba@oregonstate.edu
AI app [26], has emerged that can take a given picture
Mike Rosulek: Oregon State University, ro-
sulekm@oregonstate.edu
Charles V. Wright: Portland State University, Wu-chi Feng: Portland State University, wuchi@pdx.edu
cvw@pdx.edu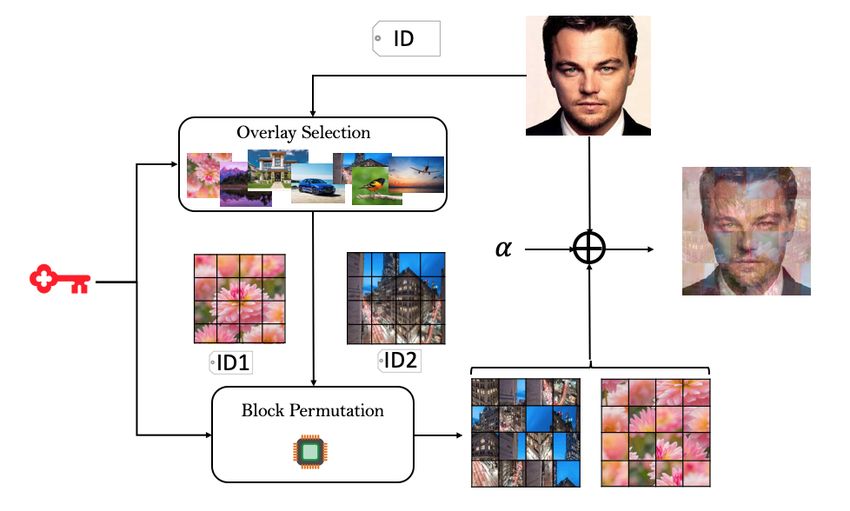
On the (Im)Practicality of Adversarial Perturbation for Image Privacy 86
of a person and search a database of more than 3 billion perturbation that can be applied to multiple im-
images scraped from Facebook, YouTube and millions ages. Compared to previous adversarial pertur-
of other websites and provide matching images along bation learning techniques, our UEP approach
with links to websites containing those photos. News requires fewer and smaller local CNNs trained
of the use of this application by law enforcement agen- over smaller (by an order of magnitude) training
cies has raised concerns about severe erosion of privacy. sets.
Emergence of such applications combined with the inef- (b) Our k-Randomized Transparent Image Overlays
fective privacy settings of social networks, necessitates (k-RTIO) is a novel semantic adversarial per-
the development of practical tools that allow end users turbation [28] approach that generates many
to protect their privacy against automated classifiers. In unique image perturbations (3rd image in Fig-
this paper, we primarily focus on thwarting automated ure 1) using only a small number of overlay
face recognition. source images and a secret key, and without re-
Adversarial image perturbation has been recently quiring users to train their own CNNs. In con-
proposed as a way to protect against automated face trast to previous semantic adversarial perturba-
recognition by fooling CNNs into misclassifying the im- tion approaches, k-RTIO perturbations are re-
age [20, 31, 63]. Adversarial perturbations [22, 23] have versible.
the nice property that the perturbed images are percep- 3. We evaluate the effectiveness of both meth-
tually indistinguishable from the original image but are ods against highly accurate celebrity recognition
misclassified by a CNN. Thus adversarial perturbation and face detection models from clarifai.com,
provides a nice balance of privacy against automated Google Vision API, and DeepFace [57], two state-
classifiers without degrading the usability of the images of-the-art online classifiers and one offline classi-
for end users. However, these methods are not always fier, respectively. Our results show that while UEP
practical for real-world use due to the unrealistic as- and k-RTIO are effective at thwarting automated
sumption of full knowledge about the adversaries’ CNNs face recognition, k-RTIO is computationally much
(i.e., white-box model). cheaper than UEP.
While black-box approaches for adversarial pertur- 4. We discuss potential counter measures against our
bations do exist (e.g., [42, 48, 56]), they either assume schemes and demonstrate one effective countermea-
that end users have access to large datasets (e.g., mil- sure against UEP.
lions of images) and can train large local CNNs (e.g.,
with thousands of classes), or that they can query the The rest of this paper is organized as follows: We dis-
target CNN making them unrealistic as well. Seman- cuss related work in Section 2. In Section 3, we present
tic adversarial perturbations [28, 29] are a newer class the system model and requirements for a practical pri-
of adversarial perturbations that can target unknown vacy mechanism based on adversarial perturbations. We
CNNs. They do not require any learning and are there- present some preliminaries on adversarial examples and
fore computationally very efficient. However, they are transferable adversarial methods in Section 4. We in-
not reversible making them unsuited for image storage troduce our two proposed approaches in Section 5 and
applications. evaluate them in Section 6. In Section 7, we discuss our
Contributions: We explore the practicality of adver- findings and some future directions. Finally, we conclude
sarial perturbations to thwart automated image classifi- in Section 8.
cation by CNNs, and make the following contributions:
1. We identify key requirements for practical adversar-
ial perturbation based image privacy against auto-
mated face recognition.
2 Related Work
2. We propose two novel schemes for adversarial per-
Many cryptographic and non-cryptographic techniques
turbation of images that do not require special
for protecting image privacy have been proposed. Here
knowledge of the target CNNs (i.e., black-box ad-
we primarily focus on works most relevant to the prob-
versarial methods) and that satisfy the identified
lem of thwarting recognition by automated classifiers
requirements.
while allowing recognition by humans.
(a) Our learning-based Universal Ensemble Per-
Adversarial Perturbations: The problem of thwart-
turbation (UEP) approach (2nd image in Fig-
ing recognition by automated classifiers while allowing
ure 1) learns a single transferable adversarial
On the (Im)Practicality of Adversarial Perturbation for Image Privacy 87
recognition by humans has recently received attention in an image with the same thumbnail as the original im-
the research community [20, 31, 44, 63, 74]. Adversar- age. Depending on the size of the thumbnail preserved,
ial perturbation based approaches [20, 31, 63] among TPE schemes are capable of thwarting recognition by
them are most closely related to this paper. While CNNs [44, 74] while still allowing image owners to dis-
those approaches can fool CNNs and preserve images’ tinguish between encrypted images. Their goal was to
recognizability by humans they have some limitations. thwart recognition by any end user other than those
Oh et al. [31] assume that end users have full knowl- who are already familiar with the image, and hence
edge about and access to target CNNs (i.e., white-box preserve thumbnails with very low resolution. In con-
model). Other works [20, 63], while they use a black- trast, our work aims to thwart only classifiers and not
box model, assume users are able to train large CNNs humans.
to learn perturbations. However, in real-world settings, Irreversible Obfuscations: An early approach to
users typically do not have access to the target CNNs thwarting facial recognition software while preserving
or other automated tools used by adversaries or on- facial details was face deidentification (e.g., [16, 24, 25,
line service providers to analyze images. Moreover, all 32, 50, 71]) that was proposed to provide privacy guar-
those approaches learn a perturbation for each image antees when sharing deanonymized video surveillance
making it expensive to protect a large set of images. data. In this approach instead of obfuscating the im-
Fawkes [63] aims to perturb images to prevent target age or parts of it, faces in the image are modified to
CNNs from learning a model on them and can be com- thwart automated face recognition algorithms. These
plementary to our effort. Semantic adversarial pertur- approaches extend the k-anonymity [72] privacy notion
bations [28, 29] that can fool unknown CNNs without to propose the k-same family of privacy notions for im-
requiring any learning have been recently proposed. As ages. At a high-level, to provide k-same protection for
they do not require any learning, they are computa- a face in an image it is replaced with a different face
tionally very efficient. However, they are not reversible that is constructed as an average of k faces that are the
making them ill-suited for image storage applications. closest to the original face. These approaches have the
In contrast, we aim to propose practical methods for benefit of providing mathematically well-defined protec-
generating reversible transferable perturbations that do tion against face recognition algorithms. However, these
not need high computation or storage resources. approaches have the downside that these modify the
Image Encryption: Encryption techniques specifically original image and the transformation is typically not
designed for protecting image privacy have also been reversible. Further, the perturbed image is typically not
proposed (e.g., [58, 76]). These techniques obfuscate correctly recognizable by humans. A slightly different
the entire image and as a consequence images are ren- but related approach is where a face that needs pri-
dered unrecognizable even by their owners making them vacy protection in an image is replaced with a similar
unable to distinguish between images without first de- one from a database of 2D or 3D faces (e.g., [8, 41]).
crypting them. Further, it has been shown that P3 [58] AnonymousNet [40] is recent de-identification approach
is vulnerable to automated face recognition [46]. using generative adversarial networks (GANs). These
To address the problem of searching through en- approaches are also irreversible. In contrast, we aim to
crypted images, Pixek App [1] uses image encryption create reversible perturbations where the perturbed im-
with embedded searchable tags. However, such schemes ages are recognizable by humans.
require modifications at the service providers (this is the Approaches like blurring, pixelation, or redaction
same for encrypted file system [21, 33] based solutions have long been used for protecting privacy in images and
as well) and need additional effort on part of end users text (e.g., [37, 81]). However, such techniques are not
to tag and browse images using tags. In contrast, our fo- only irreversible but have been shown to be ineffective
cus is on techniques that are not only reversible but also especially against automated recognition methods [27,
allow end users to manage their image repositories nat- 37, 46, 50, 81].
urally (i.e., visually rather than using keywords/tags). Approaches that remove people or objects from im-
Thumbnail Preserving Encryption (TPE) ages (e.g., [7, 34, 59]) or that abstract people or objects
schemes [44, 74, 78] have been proposed to preserve (e.g., [13, 75]), or that replace faces [69] also exist. How-
privacy of images while allowing image owners to distin- ever, those approaches are irreversible. Further, it has
guish between ciphertexts of different images naturally been shown that even if redaction techniques like replac-
(i.e., visually) without having to decrypt them. They ing faces with black space are used, it may be possible to
achieve this by ensuring that the ciphertext is itself deanonymize using person recognition techniques [53].
On the (Im)Practicality of Adversarial Perturbation for Image Privacy 88
3 System Model and tions should not require excessive computational effort
or large volumes of training data. We assume that, while
Requirements an individual user may have access to their own images
and some images of other potential users of the plat-
In this work, our focus is on practical adversarial per- form (either publicly available or those of friends using
turbation approaches that make scalable automated im- the same platform), a user does not have access to the
age analysis by service providers more difficult. Thwart- entire dataset used by the service provider for training
ing recognition by humans is not a goal. In fact, we the target CNN.
aim to develop approaches that allow image recognition Low Storage Cost: The storage requirements of the
by end users so they can interact with images natu- scheme should be small and should not increase with
rally. We assume that image storage and sharing service the number of images. Any information needed to re-
providers do not have access to meta-data or auxiliary verse the perturbation should take up minimal storage
information and treat them as an honest-but-curious or at the end user.
semi-honest adversary [52]. We assume that the service Compatibility: Since service providers have incen-
provider has trained an image classification CNN either tives to learn and profit from user data, proposed
using publicly available user images or images that the schemes should not depend on their support and should
users have already stored with the service. A user’s goal be compatible with existing services to ease adoption.
is to perturb the images that they upload to the ser- Hence, using embedded thumbnails, encrypted file sys-
vice to prevent automated recognition or classification tems (e.g., [21, 33]) and more advanced solutions such
of their images. To be practical the perturbation mech- as searchable encryption for images [1] are not practical.
anism should satisfy the following requirements. Most of the popular storage services that we tested such
Black-box Scheme: In practice, end users will not as Google Drive, iCloud, etc. do not support embedded
have access to the CNNs used by third-party service thumbnails.
providers and typically will not have detailed knowledge
of the target CNNs parameters and weights. Thus, any
viable perturbation mechanism should not require any
special knowledge of the target CNN, eliminating the
4 Preliminaries
use of white-box adversarial perturbation techniques.
CNNs: Convolutional Neural Networks (CNNs) have
We assume that the user does not know anything about
become very popular for image classification. CNNs are
the structure of the target CNN, not even all the classes
constructed by several convolutional and maxpooling
that the CNN is able to classify images into (i.e., it is
layers and one or two fully connected layers (see Fig-
a black-box), and assume that the user does not have
ure 18 in Appendix A). At the end, there is a soft-
query access to the CNN.
max layer which translates the output of the last layer
Recognizability: While white-box (i.e., full knowledge
to probabilities. Generally, a convolutional neural net-
of target CNN) adversarial perturbations typically are
work is defined by a function F (x, θ) = Y which takes
very small and imperceptible [23], black-box perturba-
an input (x) and returns a probability vector (Y =
tions on the other hand can be significant and are typ- P
[y1 , · · · , ym ] s.t. i yi = 1) representing the proba-
ically perceptible [48]. To be viable, the perturbed im-
bility of the input belonging to each of the m classes.
ages should be perceptually recognizable by end users
The input is assigned to the class with maximum prob-
but not recognizable by automated classifiers. Users
ability.
should be able to browse through perturbed images nat-
To learn classifiers, the loss function which repre-
urally using the standard interface, without having to
sents the cost paid for inaccuracy in classification prob-
reverse the perturbation.
lems, is minimized. The cross entropy loss function is
Recoverability or Reversibility: For image storage
one of the popular and sufficient loss functions that is
applications, end users must be able to reverse the per-
used in classification problems. For training a CNN, we
turbation in order to recover the original image with
optimize the CNN’s parameters (θ) for given inputs.
minimum to no distortion, i.e., no loss of perceptual
Adversarial Perturbations: Adversarial generation
quality. At the same time, the service provider should
methods find and add a small perturbation (δ) to an
not be able to remove or reduce the perturbation.
Low Computational Cost: Since end users need to
create the perturbations, learning or creating perturba-
On the (Im)Practicality of Adversarial Perturbation for Image Privacy 89
image that will cause the target CNN to misclassify it.
5 Proposed Approaches
min kδk2 + J(F (x, θ))
δ
(1) In this section, we introduce two methods to perturb
s.t. argmax F (x + δ) 6= y ∗ , x + δ ∈ [0, 1]d images in order to fool any unknown CNN. The first
method is a learning-based approach called Universal
where δ, x, y ∗ and J(.) are the perturbation, given
Ensemble Perturbation (UEP). The second method is
input image, true label of input image, and the loss
a semantic perturbation method called k-Randomized
function, respectively. Many methods have been pro-
Transparent Image Overlays (k-RTIO). We motivate
posed to generate a small perturbation for a known
each approach and describe how we generate and ap-
CNN (e.g., [11, 23, 49, 73]), but they suffer from low
ply the perturbations.
transferability to unknown CNNs (See Appendix A for
different types of adversarial attacks). Therefore, trans-
ferable perturbation generation methods were proposed
to address this issue and are discussed next.
5.1 Universal Ensemble Perturbation
Ensemble Method: Ensemble methods to create
As discussed in Section 3, any viable perturbation ap-
transferable perturbations were proposed in [6, 42].
proach for image privacy should be black-box as users
Those works learn a perturbation for a given image on
are unlikely to have access to or knowledge about CNNs
several local CNNs, instead of using only one CNN, such
used by service providers. Since black-box perturbations
that the learned perturbation fools all local CNNs. They
tend to be significant and perceptible, reversibility of
established that such perturbations are transferable and
perturbations becomes important to recover the origi-
can fool unknown CNNs with high success rate. In other
nal image. Storing the perturbations used for each im-
words, a perturbation for an image is generalized by
age so the original can be recovered will require nearly
learning it on multiple CNNs. To show the transferabil-
the same order of storage as storing the original images
ity of perturbations, authors assessed their method on,
themselves. Therefore, in our approach we aim to gen-
clarifai.com, a state-of-the-art online classifier.
erate a single perturbation that can be applied to sev-
Universal Perturbation: Moosavi-Dezfooli et al. [48],
eral images to successfully fool an unknown CNN, that
showed that it is possible to find a single (universal)
is, both universal and transferable. We achieve this by
perturbation that can be applied to multiple images to
using an ensemble approach through learning on a few
successfully fool a CNN into misclassifying all of them.
local CNNs. Unlike previous work [42, 48], our approach
Universal perturbation is defined as a noise pattern δ
uses fewer and smaller CNNs, and requires significantly
which leads a CNN misclassifying most of the input im-
smaller training datasets than the one used to train local
ages (x’s) with probability of p (p-value) when added
CNNs (see Section 6).
to those input images. This work showed that a uni-
Perturbation Learning: We create our Universal En-
versal perturbation is transferable to other CNNs with
semble Perturbation (UEP) approach by building on the
different structures but trained on the same dataset as
ideas from the ensemble approach [42], universal pertur-
the original. Further, the perturbation is added directly
bation approach [48], and CW perturbation optimiza-
to images which causes significant loss during image re-
tion and addition approach [11].
covery because of rounding the pixels’ value to 0 or 1 if
UEP learns a highly transferable, universal, and re-
they are not in range of [0, 1].
versible perturbation using an ensemble of a few small
While all of these approaches are black-box ap-
local CNNs. Moreover, to prevent the target CNN from
proaches, (i) they either need to train and learn on mul-
reducing the impact of the perturbation by using a re-
tiple (4 − 5) large local CNN(s) (see Summary in Sec-
duced resolution version of the image [15], we learn a
tion 6.1) to create a transferable perturbation(s) [6, 42,
perturbation which works for different image resolutions
48] or (ii) generate one perturbation per image [6, 42]
by training each local CNN on different resolutions of
and do not meet low computation and low storage cost
the image. For this work, we used three small CNNs
requirements. Further, they add the perturbation di-
with only 10 classes each (see Section 6). We empiri-
rectly to image’s pixel value leading to significant losses
cally found that using fewer than three CNNs makes
during recovery.
learning transferable perturbations harder, while using
more than three CNNs makes learning a perturbation
3 for Image Privacy
On the (Im)Practicality of Adversarial Perturbation 90
Recovered UEP(Y1 (x), · · · , Ym (x), x1 , · · · , xn , p):
δ = inf
// finding the true label of each image
∀ i yi∗ = argmax(Y (xi ))
lbound = 0.001, upbound = 100000
while lbound < upbound:
Perturbed
c = (upbound + lbound)/2
∀ i, zi = xi
while i k σ(Yk (zi ) 6= yi∗ ) < p × N
P Q
δ 0 ← minδ kδk2 + cf (z1 , · · · , zN )
zi = 12 (tanh (arctanh (2 × (xi − 0.5)) + δ 0 )) + 0.5
Original
if kδ 0 k2 < kδk2 :
δ ← δ0
upbound = (upbound + lbound)/2
else
Fig. 2. From bottom to top: The last row shows the original lbound = (upbound + lbound)/2
images of celebrities. The middle row represents the UEP per-
return δ
turbed images. The first row displays the recovered images.
Fig. 3. UEP method learns a universal perturbation δ on a few
computationally expensive without significant improve- local CNNs (Y1 , · · · , Yc ) for set of given inputs x1 , · · · , xn .
ment in success rate.
After learning a few (in our case only 3) local CNNs Perturbation Addition: In the universal perturba-
on different image resolutions, we learn a universal per- tion approach [48], the perturbation vector is added di-
turbation which can fool all the local CNNs with a given rectly to all images, and if the new value of pixels are not
probability of p (∈ [0, 1]). To optimize the misclassifica- in the range of [0, 1], then the new values are rounded to
tion rate, we extend the objective function introduced the nearest acceptable values (0 or 1). However, round-
in [11] for an ensemble of CNNs and a universal attack ing a pixel’s value leads to information loss during image
as follows: recovery. Therefore, we add the learned perturbation to
f (x1 , · · · , xN ) = the arc-tangent hyperbolic value of an image instead of
adding directly to the images as in [11]:
max(max{Yl (xi )j : j 6= yi∗ } − Yl (xi )yi∗ , −κ) (2)
XX
l i
1
where Yl (xi ) is the probability vector assigned by the xi,pert = (tanh (arctanh (2 × (xi − 0.5)) + β × δ)) + 0.5
2
lth CNN to the ith input which shows the probability (4)
of the input image belonging to each category. And yi∗ where xi,pert is the perturbed version of the image
denotes the true label of xi . We aim to minimize the xi and δ is the learned perturbation. Here β is a weight-
perturbation amount as well as maximize the misclassi- ing factor that tunes transferability versus perturbation
fication confidence (κ). The problem can be defined as amount. While this does not eliminate rounding losses
follows: completely, it significantly reduces such loss.
Further, unlike the traditional adversarial ap-
min kδk2 + cf (x1,perturbed , · · · , xN,perturbed ) (3) proaches, UEP perturbation can be added in with dif-
δ
ferent weights to the image to control the trade-off be-
A large value for coefficient c causes the resulting per- tween transferability and recognizability. While learning
turbation to have a larger value (to force all CNNs to UEP on local CNNs, we set β = 1 to create a powerful
misclassify it), while a very small value for this param- perturbation. But, when applying the learned perturba-
eter may lead to null solution space since it tries to fool tion to an image, we can set β value to trade-off between
all CNNs for all inputs with a small perturbation. We fooling success rate and recognizability (see Section 6).
optimize the perturbation for different coefficient c val- The original image is recovered by reversing the pro-
ues using a binary-search (see Figure 3) and pick the cess on the perturbed image. Adding the perturbation
smallest perturbation that can fool p × N of total sam- to the arc-tangent hyperbolic value of an image, both
ples (N ).
On the (Im)Practicality of Adversarial Perturbation for Image Privacy 91
simplifies the objective function and alleviates informa-
tion loss during image recovery [11].
Practicality of UEP: As the preceding discussion
shows, UEP is designed to be a black-box perturbation
approach that produces highly transferable and uni-
versal perturbations. It meets the reversibility and low Fig. 5. Left to right: original, k-RTIO perturbed and recovered
storage cost requirements identified in Section 3 as per- images.
turbations can be reversed by storing only the univer-
sal perturbation. While the perturbations produced by over image space and measuring dependencies among
UEP are significant and perceptible, as seen in Figure 2, adjacent pixels to find a pattern or a feature. Trans-
the perturbed images are still recognizable for humans parent image overlay-based approach tends to decrease
and can be recovered with very low loss by removing the pixel dependencies and makes features invisible to
perturbation. Further, since UEP uses three small local CNN kernels. Here we build on this transparent overlays
CNNs with only 10 classes and does not require users based approach that was originally proposed for fooling
to have access to large datasets. UEP is also computa- Google Video API [29]. When translated to images, this
tionally more efficient compared to previous approaches approach adds a weighted overlay image to the original
as will see in Section 6. Further, UEP does not require image as follows:
any changes to the service provider and can work with
existing services. Ipert = α × Iorg + (1 − α) × Iovl (5)
where α is mixing parameter, and Ipert , Iorg and Iovl
5.2 k-Randomized Transparent Image are perturbed, original, and overlay images.
Overlays
Despite the high transferability (success in fooling
unknown CNNs) especially at low values of α, direct
application of this technique has the following draw-
While our UEP approach requires lower computa-
back. If the same overlay image is used for perturbing
tional resources compared to previous learning-based
multiple original images then the original images can
approaches, learning perturbations is still computation-
potentially be recovered through a well known signal
ally expensive (see Section 6.1). Semantic perturba-
processing technique called Blind Signal Separation [10]
tions [29] on the other hand do not rely on learning and
(see Figure 21 in Appendix D). If a different overlay im-
tend to be computationally cheaper. Different semantic
age is used for each original image, then all those overlay
perturbation approaches target different weaknesses of
images need to be stored locally to be able to recover the
CNNs (e.g., coverage of training data, reliance on inter-
original images defeating the purpose of cloud-storage
pixel dependencies etc.) [28].
and violating our low storage requirement. Further, we
The main component of CNNs are kernels in the
need to make sure that perturbed image is recognizable
convolutional layers. Kernels are small windows moving
by end users. To overcome this problem, we propose
k-Randomized Transparent Image Overlays which gen-
erates a unique overlay for every image using only a
small set of initial overlay images, a secret seed and a
pseudorandom function.
Perturbation Generation: To generate unique over-
lays for each original image, we first choose a random
subset of k (typically 3 or 4) candidate overlay images
from a set S of stored initial overlay images. This set
S is relatively small (30 images) and can be stored en-
crypted on a cloud platform or locally. The choice of
this set does not significantly change the fooling per-
formance of k-RTIO; we discuss selection of this set in
Fig. 4. k-RTIO Scheme. ID of main image is used to select k
overlay images from the set S and then ID of selected images
Section 6.2. As shown in Figure 4, to select these k im-
are used to generate a permutation. Both overlay selection and ages for each source image, users use their secret key
block permutation algorithm use the user’s secret key. and ID of the original image (each image has a different
On the (Im)Practicality of Adversarial Perturbation for Image Privacy 92
ID) as inputs to a pseudorandom function. More con-
cretely, we employ AES as the pseudorandom function.
Let key denote a 128-bit seed and let id be a unique
(a) Original (b) =1 (c) =2 (d) =3 (e) =4 (f) =5
identifier for the given source image (e.g., a filename or
timestamp). Then the choice of the jth overlay image Fig. 6. UEP recognizability vs. β that controls noise level
(out of |S| = m possibilities) is made according to:
AES(key, idk0kj) mod m. image using the reverse process as follows:
After selecting k random candidate images, the k chosen Iper (1 − α) X
Iorg = − Iovli
images are divided into b blocks each and these blocks α k×α
Iovli ∈Overlays(key,id,b,S)
are permuted using a pseudorandom permutation. The
permutation of blocks is based on the candidate overlay Practicality of k-RTIO: As the preceding discussion
image ID, source image ID, and user’s secret key. Specif- shows, k-RTIO does not require knowledge of the tar-
ically, the blocks of the jth overlay image are permuted get CNN, nor does it require support from the service
using the Fisher-Yates shuffling algorithm [19]. Recall provider. Further, k-RTIO generates semantic pertur-
that in the ith iteration of Fisher-Yates, the algorithm bations and does not require learning using any CNNs
chooses a random value in the range {0, . . . , b−i}, where and is therefore computationally
2 cheaper than UEP (see
b is the number of items being shuffled. This random Section 6.2). Since the perturbations are efficient to gen-
choice can be derived in a repeatable way (for the jth erate, end users do not need to store individual pertur-
overlay image) via: bations for recovering original images but can re-create
them using a secret key and a small set of initial overlay
AES(key, idk1kjki) mod b − i + 1. images leading to low near constant storage overhead.
The recognizability of images perturbed using k-RTIO
As long as the ids of a user’s images are distinct, is a function of α, b and k. In Section 6.2 we will ex-
then all inputs to AES are distinct. Use of a pseudo- plore values of these parameters such that k-RTIO can
random function guarantees that all its outputs are in- thwart recognition by automated classifiers while pro-
distinguishable from random, when invoked on distinct viding reasonable recognizability for humans.
inputs. Using this approach, the user needs to store only
the short AES key, and the set of initial images S from
which all unique overlay images can be re-derived as
needed for recovering the original image (see Figure. 7). 6 Evaluation
The final overlay image is simply the average of
these k images with permuted blocks. Although the pool In this section, we evaluate the success rate of the two
S of base overlay images may be small, the number of proposed methods against two state-of-the-art online
derived overlay images that result from this process is image classifiers (www.clarifai.com and Google Vision
very large. For example, for an image set of |S| = 10, API) and a state-of-the-art offline recognition and de-
k = 4 and b = 12, the number of possible overlay images tection model DeepFace [57]. We then discuss the com-
10!
is 10!(10−4)! × (12!)4 ≈ 7.3 × 1031 making it hard for the putational costs of each approach. Finally, we explore
target CNN to correctly guess the overlay used even if different filtering techniques that classifiers could po-
S is known. tentially use as countermeasures against the proposed
Perturbation Addition: As shown in Figure 4, the perturbations.
generated overlay is added to the source image as fol-
lows:
6.1 UEP Performance
(1 − α) X
Ipert = α × Iorg + Iovli
k
Iovli ∈Overlays(key,id,b,S) UEP Simulation Setup: UEP requires training a
few small local CNNs. We trained 3 small CNNs, two
where Overlays(key, id, b, S) is a function that takes se-
VGG-16 [66] and one Facescrub CNN [46] using ran-
cret key, image id, number of blocks and overlays set
dom initialization points. VGG-16 has 5 convolutional
S and returns k overlays images with permuted blocks.
layers and 2 fully connected layers (see Figure 18) and
The perturbation can be removed to recover the original
FaceScrub CNN has 3 convolutional layers and 2 fully
On the (Im)Practicality of Adversarial Perturbation for Image Privacy 93
Overlays(key, id, b, S): rameter (see Equation 3), which controls the pertur-
K=∅ bation amount, we used binary search in the range of
for j = 1 to k: [0.001, 100000] and set p = 0.7.
// randomly choose k overlay candidates
v = AES(key, idk0kj) mod |S|
IMG = vth element of S
remove vth element from S
// keyed Fisher-Yates shuffle on blocks
for i = 1 to b:
t = AES(key, idk1kjki) mod b − i + 1
swap blocks b − i and t in IMG
add IMG to K
return K
Fig. 7. Pseudorandom method for creating overlay images with
Fig. 8. UEP performance on Google Vision API face detection
permuted blocks for an image with identifier id. # of blocks per
model, and DeepFace face detector and recognition models.
overlay image is b. Set of candidate overlay images is S.
connected layers (more details of the CNNs are in Ap- UEP Effectiveness: We evaluate UEP against
pendix C). Recall that, to prevent the target CNN from Google Vision API’s face detection model, and face de-
reducing the impact of the perturbation by using a lower tection and recognition models of clarifai.com and
resolution version of the image [15], we train each local DeepFace [57]. To this end, we selected more than 1000
CNN on different image resolutions and learn a pertur- FaceScrub images in total from all the 530 classes (not
bation over them. To implement a resolution reduction just the 10 classes on which local CNNs were trained).
or a thumbnail function, we used an additional convo- Then we cropped (Note: all adversarial perturbation
1
lutional layer size of 2 × 2 with values of 2×2 = 0.25 to methods learn on a specific image size that depends on
resize input images before rendering them to CNNs. For the CNNs’ input size.) faces with DeepFace face detec-
example, by setting up the stride value to 2 × 2 we can tor model [51] and then applied UEP generated pertur-
have a thumbnail function that reduces the size of the bation. Moreover, we can control the transferability of
image to 2×21
= 0.25 of original size (see Figure 19 in UEP perturbation by using different weighting (β) pa-
Appendix A). rameter (see equation 4). We evaluate our method for
We used the FaceScrub [51] dataset, an image different values of β parameter.
dataset of 530 celebrities (classes) and ≈ 100K images UEP vs. Google Vision API: Google Vision API was
for our evaluations. We selected 10 classes, uniformly able to detect 98.8% of faces in cropped benign images.
at random, from among 230 classes of FaceScrub that As shown in Figure 8 (dashed blue line), for a small
have at least 150 images in the training dataset. The value of β, UEP perturbation exhibited low transfer-
use of only 10 classes for training local CNNs is keeping ability (i.e., success rate) against Google Vision API.
inline with our assumption of limited end user access However, for larger β values, Google Vision API’s face
to data and computational capacity. To detect celebrity detection rate decreases significantly (≤ 30% at β = 5).
faces and crop them, we used DeepFace face detector While larger β values can fool face detection models,
CNN [57]. For each of the 10 celebrities (classes), we they also decrease recognizability for humans. Figure 6
randomly selected 150 − 200 images from the training shows the recognizability of the images for different val-
dataset and learned three local CNNs, two at 224 × 224 ues of β. Thus, there is a trade-off between fooling suc-
pixel resolution and one at 112×122 pixel resolution. We cess rate and human recognizability. Note that, this is
then chose 200 (N ) images in total over these 10 celebri- a face detection model and not a recognition model.
ties (classes) from the training dataset and learned a UEP vs. Clarifai.com: Clarifai.com’s face detection
universal ensemble (UEP) perturbation over these im- could detect more than 99% of faces and recognize
ages across the three local CNNs that we trained. As 87.25% faces of unmodified images. Clarifai.com was
shown in Figure 3, to find the best value for c pa- able to detect 98% of perturbed faces with UEP per-
On the (Im)Practicality of Adversarial Perturbation for Image Privacy 94
turbation even with β = 5. However, its face recogni-
tion was able to recognize fewer than 6% of faces for 8
β = 3 (green dash-and-dot line in Figure 8). In other
words, face recognition model is more sensitive to per-
6
turbations. While small values of β are not good enough
to thwart recognition by unknown CNNs, with β = 2,
k
face recognition model of clarifai.com was able to recog-
4
nize only 37% of faces and this comes down to less than
6% for β = 3. As seen in Figure 6, perturbed faces still
remain recognizable for β = 3.
2
UEP vs. DeepFace Models: We also evaluated UEP
against DeepFace face detection and recognition mod- 4 8 16 32 64
Block Size
els. We sampled more than 1000 images of celebrities
from FaceScrub dataset that are known to DeepFace Fig. 10. Different number of overlay images vs. different number
face recognition model (about 186 classes). This model of block sizes for α = 0.6. Used same overlay images per row.
was able to detect all faces in unperturbed images and
recognize 97.28% of them. We then tested DeepFace
with perturbed images with different levels of pertur- that the average SSIM measured over the 1000 original
bation (β values). As shown in Figure 8, the face de- and recovered images is 0.99 (SD = 0.0038). A distribu-
tection and face recognition models have low accuracy, tion of SSIM values for UEP recovered images is shown
less than 20% (for both detection and recognition) for in Figure 13.
larger values of β(≥ 3). UEP Computational Cost: Our universal transfer-
able 1perturbation is learned using only 200 randomly
selected images but can be applied to any other image.
Compared to previous approaches [42, 48], our hybrid
0.6
approach requires significantly less computational effort
and time and achieves better results. But even training
small CNNs is computationally expensive operation. For
0.5
instance, training three small local CNNs and learning
a universal transferable perturbation using 200 images
–
0.45
took 13 hours on a standard desktop with 64GB RAM
and an Intel Xeon E5-1630v4 3.70GHz quad-core CPU,
and a GTX 1080 Ti GPU with 11GB RAM (Appendix C
0.4 has network details). Training the 3 local CNNs took
less than 1 hour and learning the universal transferable
4 8 16 32 64
Block Size
perturbation over 200 images took about 12 hours. How-
ever, this is a one-time computation cost that can be
Fig. 9. Different α values vs. size of block for k = 3 overlay im- expended offline. The learned perturbation can be used
ages. Overlay images were chosen randomly but the same overlay for perturbing multiple images and hence the learning
images were used in all cases.
cost is amortized over all the images.
Since a single perturbation can be applied for a
Recoverability/Reversibility: UEP does not add the per- batch of images, the cost for storing the learned per-
turbation
8 directly to pixels but adds it in the arc- turbations in order to recover the original image is only
tangent hyperbolic space (see equation 4). When map- a small fraction of the storage required for the images.
ping back to the pixel space (integers values in [0, 255]), For example, in our evaluation we created a universal
we may 6 need to round the pixel’s value. However, this perturbation for 200 images and hence the additional
loss is not perceptually recognizable as measured by the cost for local storage is one perturbation (1/200th of
k
structural similarity index (SSIM) [82] between the orig- total image storage).
4 Summary: We showed that even with access to a small
inal and recovered images. SSIM is a popular measure
used to compare perceptual image similarity. For two dataset, 10 classes and at most 200 images per class,
identical images SSIM value will be 1. Our results show one can learn small CNNs and generate a universal per-
2
4 8 16 32 64
Block SizeOn the (Im)Practicality of Adversarial Perturbation for Image Privacy 95
Fig. 11. Google Vision API face detection model performance on kRTIO images for k=3 and k=8.
turbation with high transferability. This is in contrast from our initial set S (this set is shown in Figure 20 in
with Liu et al. [42] who train 4 large CNNs (with 1000 Appendix B). Similar to UEP evaluation, we selected
classes each) using a training dataset (ILSVRC [61]) of 1000 images from the FaceScrub dataset uniformly at
1.2M images to achieve only 76% transferability (over random and applied k-RTIO perturbations that were
200 test images) on Clarifai.com. Similarly, Moosavi- generated using different values for α (mixing parame-
Dezfooli et al. achieved only 70% fooling rate even af- ter), k (number of overlay source images), and b (number
ter using 4000 images to learn a universal perturbation. of blocks in an overlay image).
When using only 1000 images to learn a perturbation Effectiveness of k-RTIO: Similar to UEP evaluation,
they achieved less than 40% fooling rate (see Figure 6 to assess k-RTIO, we evaluated it against Google Vision
in [48]). In contrast, UEP can learn an effective uni- API’s face detection model, online face detection and
versal perturbation using only 200 images and achieve recognition models of Clarifai.com, and face detection
≥ 94% fooling rate. and recognition models of DeepFace.
Our evaluation of UEP, on more than 1000 images k-RTIO vs. Google Vision API : Google Vision API de-
and 3 different face detection and 2 different face recog- tected faces in less than 40% of original unperturbed
nition models, shows that fooling face detection models images (here we did not crop the faces but rather sub-
is harder than face recognition models. In other words, mitted the original images). Then we perturbed those
face recognition models are more sensitive to pertur- images for which Google Vision API correctly detected
bations. Also, a β = 3 showed sufficient fooling capa- faces with k-RTIO approach. Note that unlike UEP that
bility on face recognition models while keeping the im- needs to resize images to apply perturbation, k-RTIO
ages recognizable. Our UEP method also has less loss does not need to resize the main image (just overlay im-
compared to other transferable perturbation generation ages should be resized to main image’s size). As shown
approaches because perturbation is added in the arc- in Figure 11, Google Vision API only can detect faces
tangent hyperbolic space of the images instead of di- in less than 35% of images when k = 3 and α ≤ 0.5 for
rectly to their pixel values. small block sizes (less than 10). Increasing α value or
number of overlay images (k) leads face detection suc-
cess rate to increase. This is because a larger α value
6.2 k-RTIO Performance implies more of the original image is present in the
perturbed image and thus can increase recognizability
k-RTIO Simulation Setup: Recall that k-RTIO re- for both humans and automated classifiers. This can
quires a set S of initial overlay images. We observed em- be seen in Figure 9 where the image becomes clearer
pirically that the choice of this set of images did not sig- for higher α values for every block size. Increasing the
nificantly alter the fooling performance of k-RTIO. How- number of overlay images used (k) leads k-RTIO pertur-
ever, we felt that including images with human faces bation to look like random noise as the different overlay
may reduce recognizability. So we chose a set of 30 ran- images are averaged, and therefore the perturbation be-
dom images from the Internet that did not include facesOn the (Im)Practicality of Adversarial Perturbation for Image Privacy 96 comes ineffective. This is evident from Figure 10 where sive especially with hardware instruction set support. for k values greater than 4 images become easy to per- For example, generating a permutation for 500 blocks ceptually recognize for all block sizes. Interestingly, both takes 9 × 10−5 milliseconds and permuting an overlay Figures 9 and 10 show that smaller block sizes seem to image with 625 blocks of 40 × 40 pixels each took less produce less obfuscated images for humans while still 5 × 10−4 milliseconds (wall-clock time) with no special thwarting automated classifiers. optimizations or effort. Further, creation of unique over- k-RTIO vs. Clarifai.com: Clarifai.com’s face detection lays can easily be parallelized when perturbing multiple model was able to detect faces in all original images images. End users need only store the secret key (128 sampled from the FaceScrub dataset. Clarifai.com’s face bits) and a small image set S used in the creation of recognition model was able to recognize ≈ 82% of the unique overlays to recover the original images. Thus, celebrities in these images. To evaluate the k-RTIO storage costs remain constant irrespective of the num- performance on face recognition model, we used only ber of images that are perturbed. the images that were recognized by Clarifai.com’s face Summary: Similar to the case of UEP, we find that recognition model. As shown in the top row of Fig- fooling face detection models is harder than fooling face ure 12, similar to Google Vision API, for small values of recognition models. As shown in Figures 11 and 12, face α ≤ 0.45 and small block sizes clarifai.com’s face recog- detection models can detect faces better for larger block nition model is able to detect faces in very few images sizes (i.e., smaller number of blocks (b)) even at lower (< 7%) even when face detection model is able to detect α values. However, k-RTIO is able to effectively thwart faces in more than 80% of images successfully. face recognition models. For small block sizes (4 × 4 or k-RTIO vs. DeepFace Models: We also evaluated k- 8 × 8), face recognition models recognize 15% of faces RTIO against DeepFace face detection and recognition at best for α ≤ 0.5. For lower alpha values, say α = models. As in the case of UEP, we selected more than 0.4, face recognition rate does not go above 15% for 1000 images from FaceScrub dataset that DeepFace clas- any block size. Thus, the mixing parameter α and the sified correctly. We perturbed the selected images us- number of blocks b are critical factors that impact face ing k-RTIO with different α values and block sizes and recognition. Similarly, as shown in Figures 10 and 11, tested them against DeepFace. As shown in the bottom number of overlay images used is also a critical factor row of Figure 12, both models showed low performance as using more overlays leads to a final perturbation that for k-RTIO perturbed images with a small block size looks like random noise and therefore ineffective. (even for larger α values). Recoverability/Reversibility: We can always regenerate the exact overlay image that was added to original im- 6.3 Potential Attacks Against UEP and ages using the secret key. However, k-RTIO still needs k-RTIO to round up the pixel values after adding overlay images leading to some loss. However, this loss is not perceptu- We explore different countermeasures that can poten- ally recognizable. To measure the perceptual similarity, tially be deployed against the proposed perturbation we again used SSIM to evaluate the similarity between approaches. We show that using one perturbation for the original and recovered images. Our results show that several images provides adversaries with an opportunity SSIM measure between original and recovered images to estimate the perturbation and recover classifiable im- averaged over the 1000 tested images is 0.96 (SD=0.07). ages (if not original images). This is a downside of using A distribution of SSIM values k-RTIO recovered images a single semantic perturbation for multiple images and is shown in Figure 13. k-RTIO recovered images tend to led to the k-RTIO approach which uses a unique per- exhibit lower SSIM values as the perturbation is applied turbation per image. We also explore a countermeasure to the whole image and not just the faces as is done for where the target CNNs learns on perturbed images. UEP. For this experiment, we set the k-RTIO parame- Perturbation Estimation and Removal: Let us as- ters as k = 3, block-size= 8 and α = 0.45 (a sweet spot sume that the perturbation is added directly to images for fooling unknown face recognition models). (x0i = xi + δ) and an adversary wants to find δ given Computational Costs of k-RTIO: Unlike transfer- only the perturbed images. Adversaries can treat δ as able perturbation generation, the k-RTIO method is the main signal and the images as noise added to the computationally much more efficient. While it does in- main signal. In this case, the noise signal is not indepen- volve (k×b)+k AES invocations for generating a unique dent or zero mean (but rather images of faces). However, overlay for each image, AES is computationally inexpen- target CNNs do not need to recover the exact pertur-
On the (Im)Practicality of Adversarial Perturbation for Image Privacy 97
Clarifai.com
DeepFace
Fig. 12. Clarifai.com (online) and DeepFace (offline) face recognition and detection models on k-RTIO perturbed images for k = 3.
Fig. 14. UEP perturbation estimation and removal. The first
image is the perturbed image, the second one is median of 200
perturbed images. The third image is inverted median and the
final image is the recovered image by an adversary (λ = 0.42).
the inverted median to a perturbed image as a new layer
Fig. 13. SSIM histogram for recovered UEP and k-RTIO im-
ages. In contrast to k-RTIO, UEP only perturbs faces in an (x = λ × x0i + (1 − λ) × inv(δ 0 )).
image, therefore it has larger SSIM on average. As shown in Figure 14, using this approach a tar-
get CNN can obtain an image close to the original and
that seems to be sufficient for recognition. We have
bation as they do not have to recover the exact original
assessed 200 images after removing the perturbation
image. They only need to recover enough of a likeness
with median estimation method and submitted it to
to the original image to be able to classify the image
the clarifai.com’s celebrity face detection model. As
correctly. To get a rough estimate of the perturbation,
shown in Figure 15, clarifai.com’s success rate for
a target CNNs can compute the median of pixels in all
different values of λ (0.40 to 0.56) is as high as 70% (for
perturbed images to approximate the δ. It can then add
λ ∈ [0.44, 0.48]) - more than tenfold improvement! In the
worst case scenario, if we assume that the target CNNOn the (Im)Practicality of Adversarial Perturbation for Image Privacy 98
Fig. 15. Target CNN can recover 60% of the images by using Perturbation Estimation and Removal method just with 5 images
using the same perturbation. By setting λ value to 0.48, an adversary can improves its success rate to 70%.
can know when it classified correctly then it can vary λ provement on k-RTIO perturbed images when one trains
for every image and reach an accuracy as high as 80.5% a CNN both on benign and k-RTIO perturbed images.
with access to only 35 images modified using the same For this, we selected TinyImageNet [39] with 200
perturbation. Thus, using a single UEP perturbation classes, 100000 training-set images, and 10000 test-set
for several images may allow target classifiers to esti- images as the target CNN. We trained an Xception
mate the perturbation and recover classifiable images. Convolutional Neural Network [14] on this dataset. In
As shown in the Figure 15, an automated classifier can 100 training epochs, this CNN achieved 65.42% accu-
improve their classification accuracy to 70% by estimat- racy on the test-set images. We then added 100000 and
ing perturbation using as few as 10 perturbed images. 10000 k-RTIO perturbed images to training and test re-
Unlike UEP that uses a single perturbation for sev- spectively, and retrained the Xception CNN. We used
eral images, k-RTIO generates a unique perturbation the same learning rate and same random seed num-
for each image, hence this perturbation estimation and ber to initialize the CNN weights. The robust Xception
removal approach is not effective against k-RTIO. CNN achieved 68.50% accuracy on benign test-set im-
Robust CNNs: Many methods have been proposed to ages and 32.1% accuracy on average on k-RTIO images
detect and reject adversarial examples (e.g., [3, 4, 47, (α ∈ {0.45, 0.5}, block − size ∈ {4, 8, 16, 64}).
67, 80]). These methods are suitable for safety sensitive As shown in Figure 16, learning on k-RTIO images
application such as disease recognition and autonomous can improve accuracy. However, the accuracy on images
cars in which making wrong decision may cause huge with low alpha values α = {0.4, 0.45} was still less than
consequences. However, such approaches are not useful 29% and 39% respectively. In other words, robust CNNs
as defenses against UEP or k-RTIO as those methods can improve their accuracy on k-RTIO perturbed im-
want to detect and reject perturbed images as much as ages but not significantly for small α values. Note that
possible which aligns with our goal of preventing auto- we used the same overlay set for perturbing images in
mated classifiers from correct classification. Other pro- the training and test sets to evaluate the robust CNN.
posed methods tend to make learning white-box attacks This simulates a situation when the target CNN has
harder for an adversary [5, 56]. However, such defenses access to a user’s overlay set S.
are still vulnerable to black-box attacks in which an ad- Noise Reduction Techniques: Adversarial training
versary learns highly transferable perturbations on us- showed good performance against adversarial examples
ing local CNNs. Another approach is to train robust for small CNNs, but this approach has been shown to be
CNNs that are able to classify adversarial images cor- computationally expensive at large scale [5] and not a
rectly [43] by re-training the network on both benign desirable solution for dealing with adversarial samples.
and adversarial images. However, it has been shown that Approaches to recover classifiable images from per-
this approach does not make CNNs robust against all turbed ones using different filtering techniques have
kinds of adversarial examples even for small CNNs [64]. been explored [15]. Note that CNNs do not need to re-
Here we aim to assess the classification accuracy im- cover original images to classify them correctly. They
only need to reduce the impact of the perturbation toYou can also read

















































