ProoFVer: Natural Logic Theorem Proving for Fact Verification
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
ProoFVer: Natural Logic Theorem Proving for Fact Verification
Amrith Krishna Sebastian Riedel Andreas Vlachos
University of Cambridge Facebook AI University of Cambridge
ak2329@cam.ac.uk University College London av308@cam.ac.uk
sriedel@fb.com
Abstract instance, NaturalLi (Angeli and Manning, 2014),
proposed for natural language inference, provided
We propose ProoFVer, a proof system for explicit proofs in the form of logical inference
fact verification using natural logic. The using natural logic to determine entailment of a
textual entailment model in ProoFVer is
arXiv:2108.11357v1 [cs.CL] 25 Aug 2021
given sentence. However, the performance of such
a seq2seq model generating valid natu-
ral logic based logical inferences as its proof systems often do not match with that of the
proofs. The generation of proofs makes neural models. For a task like fact verification,
ProoFVer an explainable system. The proof with sensitive areas of application (Graves, 2018),
consists of iterative lexical mutations of explaining the reasoning behind the decision mak-
spans in the claim with spans in a set of re- ing process is valuable. Keeping both performance
trieved evidence sentences. Further, each and explainability in mind, we propose a fact veri-
such mutation is marked with an entail-
fication system whose entailment model is a neural
ment relation using natural logic operators.
The veracity of a claim is determined solely
seq2seq proof generator which generates proofs
based on the sequence of natural logic re- for determining the veracity of a claim.
lations present in the proof. By design, In this work, we propose ProoFVer - Proof
this makes ProoFVer a faithful by construc- System fort Fact Verification using natural logic.
tion system that generates faithful explana- Here, the proofs generated by the proof generator
tions. ProoFVer outperforms existing fact-
are in the form of natural logic based logical in-
verification models, with more than two per-
cent absolute improvements in performance ference. Both ProoFVer and NaturalLi follow the
and robustness. In addition to its explana- natural logic based theory of compositional entail-
tions being faithful, ProoFVer also scores ment, originally proposed in NatLog (MacCartney
high on rationale extraction, with a five and Manning, 2007). ProoFVer is the first such
point absolute improvement compared to system to employ natural logic based proofs in
attention-based rationales in existing mod- fact verification. For a given claim and evidence
els. Finally, we find that humans correctly as shown in Figure 1, its corresponding proof is
simulate ProoFVer’s decisions more often
shown in Figure 2. Here, at each step in the proof,
using the proofs, than the decisions of an
existing model that directly use the retrieved a claim span is mutated with a span in the evi-
evidence for decision making. dence. Each such mutation is marked with an en-
tailment relation, by assigning a natural logic op-
erator (NatOp, Angeli and Manning, 2014). A step
1 Introduction in the proof can effectively be represented using a
Fact verification systems, designed for determin- triple, consisting of the aligned spans in the muta-
ing a claim’s veracity, typically consist of an ev- tion and its assigned NatOp.
idence retrieval model and a textual entailment The seq2seq proof generator generates a se-
model. Recently, several of the high performing quence of such triples as shown in Figure 1. Here,
fact verification models use black box neural mod- the mutations in the first and last triples occur with
els for entailment recognition. In such models, the equivalent lexical entries and hence are assigned
reasoning in the decision making process remains with the equivalence NatOp (”). However, the
opaque to humans. On the contrary, proof sys- mutation in the second triple is between lexical
tems that use logic based approaches can provide entries which are different from each other and
transparency in their decision making process. For thus is assigned the alternation NatOp (ê). TheClaim Page Title
Little Dorrit is a short story by Charles Dickens Evidence Little Dorrit
Little Dorrit is a novel by Charles John Huffam Dickens,
originally published in serial form between 1855 and 1857
ProoFVer Proof Generator (seq2seq)
Little Dorrit is a short story by Charles Dickens
≡ ⥯ ≡
Little Dorrit is a novel by Charles John Huffam Dickens
Figure 1: Explainable fact verification using ProoFVer. The explanation generator (Left) generates a sequence of
triples, representing logical inference in Natural Logic. DFA is used for determining the veracity of the claim, by
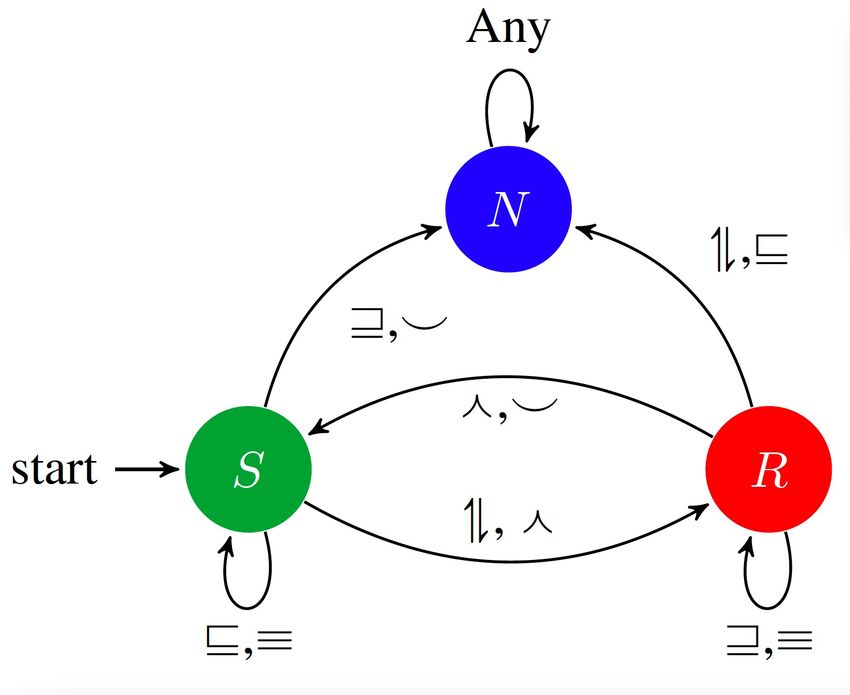
using the sequence of natural logic operators in Figure 2 as a transition sequence in the DFA.
news agency for advice, an end-user to dispute the
S Little Dorrit is a short story by Charles Dickens decision, and a developer to debug the model.
≡ ProoFVer outperforms current state-of-the-
S Little Dorrit is a short story by Charles Dickens art (SOTA) fact verification models (Liu et al.,
⥯
2020; Ye et al., 2020; Zhong et al., 2020) in both
R Little Dorrit is a novel by Charles Dickens
performance and robustness. It achieves a la-
≡
Little Dorrit is a novel by Charles John Huffam
bel accuracy of 79.25 % and a FEVER Score of
R Dickens 74.37 % on the FEVER test data, outperform-
ing SOTA models by 2.4 % and 2.07 % respec-
Figure 2: Steps in the proof for the input in Figure 1. tively. ProoFVer’s explanations are guaranteed to
The transition sequence as per the DFA in Figure 1 is be faithful. They score high on plausibility in
also shown, which terminates at the ‘REFUTE’. terms of token overlap F1-Score with human ra-
tionales. ProoFVer scores an F-Score of 93.28 %,
which is 5.67 % more than attention based high-
sequence of NatOps from the proof in Figure 2 lights from Ye et al. (2020). Further, in forward
form a transition sequence in the deterministic fi- prediction, humans can better predict the model
nite state automaton (DFA) shown in Figure 1, outcome using ProoFVer’s explanations than us-
which in this case terminates at the ‘Refute (R)’ ing all the retrieved evidence. To be more specific,
state. This implies that the evidence do not support human annotators correctly predict the model out-
the claim. Unlike other natural logic based proof come 82.78 % of the times based on ProoFVer’s
systems, ProoFVer can obtain spans from multiple explanations, against 70 % when using only the
sentences for a single proof. The seq2seq model evidence.
is trained using a heuristically annotated dataset, We evaluate the robustness of ProoFVer us-
obtained by combining information from the pub- ing counterfactual instances from Symmetric
licly available FEVER dataset and the FEVER fact FEVER (Schuster et al., 2019). ProoFVer’s label
correction dataset (Thorne et al., 2018a; Thorne accuracy is 13.21 % points more than the next best
and Vlachos, 2021b). model (Ye et al., 2020). Further, fine tuning both
Moreover, the generated proof acts as an expla- the models using Symmetric FEVER development
nation, or rather a faithful explanation. An expla- data leads to catastrophic forgetting on FEVER.
nation is faithful if it reflects the same information We apply L2 regularisation to all the models.
as that is used for decision making. By design, we Here, ProoFVer outperforms the next best model
ensure that the generated proof is solely used for with a margin of 3.73 and 6 percentage points in
determining the label of claim, making it a faithful the original and Symmetric FEVER datasets re-
by construction model (Lei et al., 2016; Jain et al., spectively. Moreover, to evaluate the robustness of
2020). Faithful explanations can find use cases to fact verification systems against the impact of su-
various stakeholders as mechanisms for dispute, perfluous information from the retriever, we pro-
debug or advice (Jacovi and Goldberg, 2021). In pose a new metric, Stability Error Rate (SER). It
fact verification, an explanation may be used by a quantifies the percentage of instances where thesuperfluous information influences the model to them et al.; Valencia, 1991), uses natural logic
change its original decision. This metric mea- for textual inference between a hypothesis and a
sures the ability of an entailment model in distin- premise. NaturalLi (Angeli and Manning, 2014)
guishing between evidence sentences relevant to extended NatLog by adopting the formal seman-
the claim from the ones which merely has lexi- tics of Icard III and Moss (2014).
cal overlap with the claim. Our model achieves a NaturalLi is a proof system formulated for the
SER of 6.21 %, compared to 10.27 % of Ye et al. NLI task. It determines the entailment of a hypoth-
(2020), where a lower SER is preferred. esis by searching over a database of true facts, i.e.
premise statements. The proofs are in the form of
2 Natural Logic for Explainable a natural logic based logical inference, which re-
Fact-Verification sults in a sequence of mutations between a premise
and a hypothesis. Each mutation is marked with
Justifying the model decisions has been central a natural logic relation and is realised as lexical
to fact verification. While earlier models sub- substitution, forming a step in the inference. Each
stantiate their decisions by presenting the evi- mutation results in a new sentence and the natu-
dence as is, e.g. systems developed for the FEVER ral logic relation assigned to it identifies the type
benchmark (Thorne et al., 2018b), more recent of entailment that holds between the sentences be-
proposals use the evidence to generate explana- fore and after the mutation. NaturalLi adopts a set
tions. Here, models either highlight salient sub- of seven natural logic operators, namely, equiv-
sequences from the evidence (Popat et al., 2018; alence (”), forward-entailment (Ď), reverse en-
Wu et al., 2020), generate summaries (Kotonya tailment (Ě), negation (N), alternation (ê), cover
and Toni, 2020; Atanasova et al., 2020), correct (!), and independence (#). The operators were
factual errors (Thorne and Vlachos, 2021b; Schus- originally proposed in NatLog and they are de-
ter et al., 2021) or perform rule discovery (Ah- fined by MacCartney (2009, p. 79). We hence-
madi et al., 2019; Gad-Elrab et al., 2019). In this forth refer these operators as NatOps. For NLI,
work, we use natural logic for explainable fact NaturalLi and later Kotonya and Toni (2020), sup-
verification. Natural logic is a prominent logic press the use of cover and alternation operators.
based paradigm in textual entailment (Abzianidze, They merge the cases of alternation and negation
2017a; Hu et al., 2019; Feng et al., 2020). together. However, for fact verification, we treat
Natural logic operates directly on natural lan- these as separate cases. However, we also suppress
guage (Angeli and Manning, 2014; Abzianidze, the use of cover operator, as such instances rarely
2017b), and thus is appealing for fact verifica- occur in fact verification datasets as well. Thus, in
tion, as structured knowledge bases like Wiki- ProoFVer we use six NatOps in our proofs.
data typically lag behind text-based encyclopedias To determine whether a hypothesis is entailed
such as Wikipedia in terms of coverage (Johnson, by a premise, NaturalLi uses a deterministic finite
2020). Furthermore, it obviates the need to trans- state automaton (DFA). Here, each state is an en-
late claims and evidence into meaning represen- tailment label, and the transitions are the NatOps
tations such as lambda calculus (Zettlemoyer and (Figure 1). The Logical inference consists of a se-
Collins, 2005). While such representations may quence of mutations, each assigned with a NatOp.
be more expressive, they require the development The sequence of NatOps is used to traverse the
of semantic parsers, introducing another source of DFA, and the state where it terminates decides the
error in the verification process. label of the hypothesis-premise pair. The decision
Natural Logic, a term originally coined by making process solely relies on the steps in the
Lakoff (1972), has been previously employed in logical inference. Thus the proofs form faithful
several information extraction and NLU tasks such explanations.
as Natural Language Inference (NLI, Angeli and
Manning, 2014; Abzianidze, 2017a; Feng et al., 3 ProoFVer
2020), question answering (Angeli et al., 2016)
and open information extraction (Angeli, 2016, ProoFVer is an explainable fact verification sys-
Chapter 5). NatLog (MacCartney and Manning, tem. It has a seq2seq proof generator that gener-
2007), building on past theoretical work on nat- ates proofs in the form of natural logic based log-
ural logic and monotonicity calculus (Van Ben- ical inferences, and a deterministic finite automa-Claim Page Title Hyperlinked mention Page Title
Bermuda Spanish Empire
Bermuda was part of one of Evidence-1 Evidence-2
the largest empires in He claimed the islands The Spanish Empire was one of
history.
for the Spanish Empire the largest empires in history
GENIE NATLOG Explanation Generator (seq2seq)
Bermuda was part INS of one of the largest empires in history
≡ ⊑ ⊑ ≡ ≡
Bermuda claimed for the Spanish Empire one of the largest empires in history
≡ ⊑ ⊑ ≡ ≡
Transition Sequence: S S S S S S Outcome: Supports (S)
Figure 3: An instance of claim verification requiring multiple evidences. The encoder inputs the concatenated
sequence of claim and evidences.
ton (DFA) for predicting the veracity of a claim. We use a seq2seq model for the proof gener-
The proof generator follows GENRE (De Cao ation, following a standard auto-regressive formu-
et al., 2021) in its training and inference. We elab- lation. At each step of the prediction, the predicted
orate in detail on our proof generation process in token will have to belong to one of the three ele-
Subsection 3.1 and on the deterministic decision ments of a triple, i.e. a token from the claim, a
maker in Subsection 3.2. token from the evidence or a NatOp. This implies
that we need to lexically constrain the search space
3.1 Proof Generation during prediction to avoid invalid triples, e.g. a
The proof generator, as shown in Figures 1 and 3, triple lacking the NatOp or a triple containing lex-
takes as input a claim along with one or more ical entries which are not in the input. Further, the
evidence sentences retrieved from a knowledge search space needs to change depending on which
source. We generate the steps in the proof as a element of the triple is being predicted. Therefore,
sequence of triples, where each triple consists of a we perform dynamically constrained markup de-
span from the claim, a span from the evidence and coding, a modified form of lexically constrained
a NatOp. The claim span being substituted and the decoding (Post and Vilar, 2018), introduced by
evidence span replacing it form a mutation. In a De Cao et al. (2021). This approach helps not only
proof, we start with the claim, and span level mu- to lexically constrain the search space, but also
tations are iteratively applied to the claim from left to dynamically switch between the three different
to right. For each claim span in a mutation, a rele- spaces depending on what the decoder is currently
vant evidence span is used as its replacement. Fur- generating.
ther, each mutation is assigned a NatOp. Figure 1
shows the generated proof containing a sequence Dynamically constrained markup decoding uses
of three triples. The corresponding mutated string markups to identify the boundaries of the elements
at each step of the proof, along with the assigned in a triple in order to switch search spaces. The
NatOps, is shown in Figure 2. Based on this as claim and evidence spans in a triple are enclosed
proof, the DFA in Figure 1 determines that the ev- within the delimiters, ‘{}’ and ‘[]’ respectively. A
idence refutes the claim, i.e. it terminates in state triple starts with generating a claim span. Here,
R. As shown in Figure 3, the evidence spans may the prediction proceeds either by monotonically
come from multiple sentences, may be accessed in copying the tokens from the claim, or by predict-
any order, and need not all end up being used. In ing the delimiter ‘}’, where ‘}’ signifies the end
Figure 3, the first three mutations use spans from of the span. This results in switching the search
“Evidence-1", while the last one uses a span from space to that of evidence spans. Here, the candi-
“Evidence-2", a span which happens to be in the dates for the search space will contain all the pos-
middle of the sentence. Finally, each mutation sible spans obtained from the evidence, as any ar-
is marked with the NatOp that holds between the bitrary span from the evidence can be predicted as
claim and evidence spans. the span most relevant to the claim span alreadygenerated. The evidence span prediction, which alignment step finds the corresponding evidence
begins with the ‘[’ delimiter, ends when the final span for each such claim span. Here, the evidence
token of the selected evidence span is reached and sentences in the input are aligned separately with
is marked by ‘]’ delimiter. This is followed by pre- the claim using a word aligner (Jalili Sabet et al.,
diction of a NatOp, and the decoder is constrained 2020). For each claim span from the chunking
to predict from one of the seven NatOps consid- step, the corresponding evidence span is obtained
ered. The generation process will similarly gen- by grouping together those words from the evi-
erate all the triples, until the triple with the final dence that are aligned to it.1 Further, alignments
claim span is generated. with similarity scores that fall below an empiri-
cally set threshold are ignored. These are marked
3.2 Verification with ‘DEL’ in Figure 4, implying the correspond-
The DFA shown in Figure 1 uses the sequence of ing claim span is deleted in such mutations.
NatOps generated by the proof generator as transi- As shown in Figure 4, we convert the align-
tions to arrive at the outcome. Figure 2 shows the ments into a sequence of mutations. The result-
corresponding sequence of transitions for the in- ing sequence needs to contain at least one span
put in Figure 1. NaturalLi (Angeli and Manning, from each of the evidence sentences given in the
2014) designed the DFA for the three class classifi- ground truth for an instance. To switch between
cation NLI task, namely entail, contradict and neu- evidence spans, we assume these sentences will
tral. Here, we replace them with SUPPORTS (S), be hyperlinked. As shown in Figure 3, ‘Evidence
REFUTES (R), and NOT ENOUGH INFO (N) re- - 1’ is hyperlinked to ‘Evidence - 2’ via the men-
spectively for fact verification. Figure 2 shows the tion ‘Spanish Empire’. Here, if the hyperlinked
transition sequence in the DFA for the input in Fig- entity is not part of the aligned evidence spans
ure 1, based on the NatOps in the generated proof. then we insert it as a mutation. Such an inser-
tion is shown as box three of ‘mutations’ in Figure
4 Generating Proofs for Training 4. Further, the aligned evidence spans that form
part of the mutations before and after the insertion
Training datasets for evidence-based fact verifica-
are from Evidence-1 and Evidence-2 respectively
tion consist of instances containing a claim, a la-
and are marked with solid borders in Figure 4. We
bel indicating its veracity and the evidence, typ-
generalise this to a trajectory of hyperlinked men-
ically a set of sentences (Thorne et al., 2018a;
tions for cases with more than two evidence sen-
Hanselowski et al., 2019; Wadden et al., 2020).
tences. Further, if there are multiple possible mu-
However, we need the proofs to train our proof
tation sequences as candidates, we enumerate all
generator (Section 3.1). Manually obtaining these
such combinations. We then calculate their aver-
annotations would be laborious; thus, we heuristi-
age similarity score based on their alignment with
cally generate the proofs from existing resources.
the claim. Finally, we choose the one with the
A proof is a sequence of triples, where each triple
highest average similarity.
contains a ‘mutation’, i.e. a claim span and an
Insertions can also occur when a claim needs to
evidence span, along with a NatOp. As shown
be substantiated with enumeration of items from
in Figure 4, we perform a three step-annotation
a list. For instance, the claim “Steve Buscemi has
process: chunking, alignment and entailment as-
appeared in multiple films” would require enumer-
signment. The claim spans are obtained using the
ation of a list of films as its explanation. Here,
chunking step; Alignment provides the mutations
the first film name in the list would be aligned
by obtaining the corresponding evidence spans for
with the claim span ‘multiple films’ and the rest of
each claim span; and the entailment assignment
them will be treated as insertions with no aligned
step assigns NatOps for the mutations.
claim spans. The second case occurs when a claim
4.1 Chunking and Alignment requires information from multiple evidence sen-
tences, which we discuss below. Summarily, for a
The chunking step performs span level segmenta-
given input instance, the alignment step produces
tion of the claim using the chunker of Akbik et al.
(2019). Any span that contains only non-content 1
If there are additional words between two words in evi-
words is merged with its subsequent span as a dence aligned to the same claim span, then those words are
post-processing step. As shown in Figure 4, the also considered as part of the evidence span.Chunking Claim: Segmented spans Bermuda was part of one … empires in history
Alignment
Evidence-1: Bermuda claimed Spanish Empire DEL
Aligned
evidence spans Empire DEL of one … empires in history
Evidence-2:
1 2 3 4 5
Converting
Bermuda was part INS of one …empires in history
alignments Mutations
to mutations: Bermuda claimed for the Spanish Empire of one …empires in history
Entailment Filtering Filtering
Assignment Individual assignment using oracle
of NatOps
using label
≡ ⊑ ⊑≡≡
_____ ≡_ ⊑≡≡ ≡ ≡ ⊑≡≡
≡ ⊑ ⊑≡≡
1 2 3 4 5 1 2 3 4 5 Transform
Label: Supports 1 2 3 4 5
to specific
Figure 4: Annotation process for obtaining explanations for the claim and evidence in Figure 3. Annotation
proceeds in three steps, chunking, alignment and entailment assignment. Entailment assignment proceeds by
individual mutation assignment and two filtering steps.
a sequence of mutations where a mutation can be paraphrases and assign the corresponding NatOp
an aligned pair of claim and evidence spans, in- to those. Similarly, mutations which fully match
sertion of an evidence span or deletion of a claim lexically are assigned with the equivalence opera-
span. tor, like the mutations marked as 1, 4 and 5 in Fig-
ure 2. Next, cases of insertions (deletions) are gen-
4.2 Entailment Assignment
erally treated as making the existing claim more
As shown in Figure 4, the entailment assignment specific (general) and hence assigned the forward
step produces a sequence of NatOps, one each for (reverse) entailment operator, like mutation 4 in
every mutation. Here, the search space will be- Figure 2. An exception to this is that a deletion
come exponentially large, i.e. 6n possible NatOp or insertion of a negation word would result in as-
sequences for n mutations. First, we restrict the signing the negation operator. The negation words
search space by identifying individual mutations include common negation terms such as “not” and
that can be assigned a NatOp based on external “none”, as well as words with a negative polarity
lexicons and knowledge bases (KBs). We then on the lexicon by Hu and Liu (2004).
perform two filtering steps to further narrow down
the search space; one using label information from
training data and the other using an oracle. In case Little Dorrit Rashomon Inception
this filtering results in multiple NatOp sequences,
genre instance of
we arbitrarily choose one.
novel short story
4.2.1 Individual Assignment of NatOps film
We assign a NatOp to individual mutations from subclass of subclass of
the mutation sequence by relying on external visual artwork
fiction literature
lexicons and KBs. Specifically, we use Word-
subclass of
net (Miller, 1995), Wikidata (Vrandečić and subclass of
Krötzsch, 2014), Paraphrase Database (Ganitke- fiction work of art
vitch et al., 2013, PPDB), and negative sentiment subclass of
polarity words from the opinion lexicon by Hu
and Liu (2004). Every paraphrase pair present in creative work
PPDB 2.0 (Pavlick et al., 2015) is marked with
a NatOp. We identify mutations where both the Figure 5: A snapshot of entities and their relations in
claim and evidence spans are present in PPDB as Wikidata.For several of these mutations, the NatOp in- say between “novel” and “Rashomon”, then those
formation need not be readily available to be di- entities are assigned the independence operator, .
rectly assigned at a span level. In such cases, we This signifies that the relatedness between the en-
retain the word level alignments from the aligner tities are not of any significance in our annotation.
and perform lexical level entailment assignment will be assigned with independence operator.
with the help of Wordnet and Wikidata. We follow
MacCartney (2009, Chapter 6) for entailment as-
signment of open-class terms using Wordnet. Ad- O-class S R N
ditionally, we define our own rules to assign a substitute with
Ď ê Ě
NatOp for named entities using Wikidata as our similar information
KB. Here, aliases of an entity are marked with an substitute with
Ď ê #
equivalence operator, as shown in third triple in dissimilar information
Figure 1. Further, we manually assign NatOps to paraphrasing ” ê #
500 relations in Wikidata, which are held most fre- negation N N N
quently between the aligned pairs of named enti- transform to specific Ď Ď Ď
ties in our training dataset. For instance, as shown transform to general Ě Ě Ě
in Figure 5, the entities “Little Dorrit” and “novel”
form the relation “genre”. As “Little Dorrit” is a Table 1: NatOp assignment based on O-class and ve-
racity label information.
novel, we consider the entity “novel” as a gener-
alisation of ‘Little Dorrit’. Here, for a mutation
with ‘Little Dorrit’ in the claim span and ‘novel’
in the evidence span, we assign the reverse en-
tailment operator, signifying generalisation. How-
4.2.2 Filtering Using Label and Oracle
ever, we assign forward entailment operator, signi-
fying specialisation, when the entities switch their
positions. Summarily any two entities that share In Figure 4, there is only one unfilled NatOp af-
the ‘genre’ relation is assigned a forward or re- ter NatOp assignment in Subsection 4.2.1. Hence
verse entailment operator. there are six possible candidate transition se-
The KB relations we annotated have to occur quences possible. We first filter out invalid candi-
directly between the entities, and they do not cap- dates by using the veracity label information from
ture hierarchical multihop relations between the the training set, which is ‘SUPPORTS’ in Figure
entities in the KB. We create such a hierarchy by 4. Of the six, only two terminates at the ‘SUP-
combining the “instance of”, “part of”, and “sub- PORTS (S)’ state when used as a transition se-
class of” relations in Wikidata.2 In this hierar- quence in the DFA (Section 3.2). Hence only those
chy, if an entity is connected to another via a di- two candidates will be retained. For the next fil-
rected path of length k ď 3, such as “Work of tering step, we use an oracle to find two additional
art” and “Rashomon” in Figure 5, then the pair is pieces of information. First, we use it to obtain a
considered to have a parent child-relation. Here, six class categorisation of the mutation sequence,
the parent entity is considered as a generalisation as shown in Table 1. This categorisation is based
of the child entity, leading to assignment of for- on the annotation process followed in the FEVER
ward or reverse entailment NatOp, as previously dataset (Thorne et al., 2018a, §3.1), and we re-
explained. Similarly, two entities are considered to fer to it as the O-classes. Second, while the la-
be siblings if they have a common parent, and are bel information can change after every mutation,
assigned the alternation NatOp. This signifies that the O-class is assigned to a specific mutation after
the two entities have related properties but are still which it remains unchanged. The oracle identi-
different instantiations, such as “Rashomon” and fies the specific mutation as well, which we refer
“Inception”. However, if two connected entities to as O-span. In Figure 4, O-span happens to be
do not satisfy the aforementioned length criteria, the second mutation. We assign a unique NatOp
for each O-class and label combination as shown
2
We do not distinguish between these relations in our hi-
in Table 1, at the O-span. In Figure 4, the muta-
erarchy, though Wikidata does. For more details refer to: tion sequence at the top is selected based on the
https://bit.ly/hier_props information in Table 1.5 Experimental Methodology 5.3 Baseline Systems
KernelGAT (Liu et al., 2020) propose a graph
5.1 Data attention based network. where each retrieved
We evaluate our model on FEVER (Thorne et al., evidence sentence, concatenated with the claim,
2018a), a benchmark dataset for fact verification. forms a node in the graph. The node represen-
It is split into train, development and a blind tations are initialised using a pretrained LM; we
test-set containing 145,449, 19,998, and 19,998 use their best performing RoBERTA (Large) con-
claims respectively. We further evaluate our model figuration. The relative importance of each node,
on Symmetric FEVER (Schuster et al., 2019), a is computed with node kernels, and information
dataset designed to evaluate the robustness of fact propagation is performed using edge kernels.
verification systems against the claim-only bias CorefBERT (Ye et al., 2020) follows the Ker-
present in FEVER. The dataset consists of 1,420 nelGAT architecture, and differs only in terms of
counterfactual instances, split into development the LM used for the node initialisation. Here, they
and test sets of 708 and 712 instances respectively. further pretrain the LM on a task that involves pre-
diction of referents of a masked mention to capture
5.2 Evaluation Metrics co-referential relations in context. We use Core-
fRoBERTA, their best performing configuration.
The official evaluation metrics for FEVER include
label accuracy (LA) and FEVER Score (Thorne DREAM (Zhong et al., 2020) use a graph con-
et al., 2018b). Label accuracy is simply the ve- volutional network for information propagation
racity classification accuracy. FEVER Score re- followed by a graph attention network for aggre-
wards only those predictions which are accom- gation. However, unlike KernelGAT, they operate
panied by at least one complete set of ground on a semantic structure involving span level nodes,
truth evidence. For robustness related experiments obtained using semantic role labelling of the in-
with Symmetric FEVER, five random initialisa- put. Their graph structure is further enhanced with
tions of each model are trained. We perform mul- edges based on lexical overlap and similarity be-
tiple training with random seeds due to the limited tween span level nodes.3
size of dataset available for the training. We re- 5.4 ProoFVer: Implementation Details
port their mean accuracy, standard deviation, and
We follow most previous works on FEVER which
p-value with an unpaired t-test.
model the task in three steps, namely document re-
We further introduce a new evaluation metric, trieval, retrieval of evidence sentences from those
to assess model robustness, called Stability Error documents, and finally classification based on the
Rate (SER). Neural models, especially with a re- claim and the evidence. ProoFVer’s novelty lies
triever component, have shown to be vulnerable to in proof generation at the third step. Hence, for
model overstability (Jia and Liang, 2017). Model better comparability against the baselines, for the
overstability is the inability of a model to distin- first two steps we follow the setup of Liu et al.
guish between strings that is relevant to address (2020), also used in Ye et al. (2020). We retrieve
the user given query and those which merely have five sentences for each claim since more evidence
lexical similarity with the user input. Due to over- is ignored in the FEVER evaluation.
stability, superfluous information in the input may
influence the decision making capacity of a model, Claim Verification For the proof generator, we
even when sufficient information to arrive at the take the pretrained BART (Large) model (Lewis
correct decision is available in the input. In a et al., 2020) and fine tune it using the heuristi-
fact verification system, it is expected that an ideal cally annotated data from Section 4. The encoder
verification model should predict a ‘REFUTE’ or takes as input the concatenation of a claim and
’SUPPORT’ label for a claim only given sufficient one or more evidence sentences, each separated
evidence, and any additional evidence should not with a delimiter, and the decoder generates a se-
alter this decision. To asses this, we define SER quence of triples. We use three different configu-
as the percentage of claims where additional evi- rations, namely ProoFVer-SE, ProoFVer-ME-Full,
dence alters the SUPPORT or REFUTE decision 3
Since their implementation is not publicly available, we
of the model. report the results stated by Zhong et al. (2020).and ProoFVer-ME-Align which differ in the way shown in Table 1. We use the categorisation infor-
the retrieved evidence is handled. In ProoFVer- mation as O-class. The O-span at which O-class
SE (single evidence), a claim is concatenated with is applied, is identified as the claim span where the
exactly one evidence sentence as input; this pro- modification was done to create the claim. We use
duces five proofs and five decisions per claim, and both these information in our final filtering step.
we arrive at the final decision based on majority To limit the reliance on gold standard data from
voting. The remaining two use all the retrieved Thorne and Vlachos (2021b) during the heuris-
evidence together as a single input, by concatenat- tic annotation, we first train a classifier for pre-
ing with the claim. Also both the models produce dicting the O-class. The classifier is trained us-
only one proof and hence one decision for a claim. ing KEPLER (Wang et al., 2021), a RoBERTA
While ProoFVer-ME-Full (multiple evidence) use based pretrained LM that is enhanced with KB
the evidence as is, ProoFVer-ME-Align use a word relations and entity pairs from WikiData.It cov-
aligner (Jalili Sabet et al., 2020) to extract subse- ers 97.5 % of the entities present in FEVER. We
quences that align with the claim from each of the first fine tune KEPLER with the FEVER training
five evidence sentences. Only the extracted subse- dataset. We further fine tune it for the six class
quences are concatenated with the claim to form classification task of predicting the O-class, and
the input in the latter. refer to this classifier as Kepler-CT. Kepler-CT is
trained with varying the size of training data from
5.5 Heuristic Annotation for Training Thorne and Vlachos (2021b), ranging from 1.24 %
(1,800; 300 per class) to 41.25 % (60,000; 10,000
As elaborated in Section 4, the explanations are per class) of the FEVER dataset. We now con-
generated using a three step heuristic annotation sider two configurations; one where the oracle still
process. We first obtain a phrase level chunk- uses gold data to identify the O-span, which we
ing of the claims using the flair based phrase refer to as ProoFVer-K. In the second configura-
chunker (Akbik et al., 2019). Second, we ob- tion, ProoFVer-K-NoCS, we relax this constraint
tain alignments between the evidence sentences and instead retain only those candidate sequences
and the claim using simAlign (Jalili Sabet et al., where at least one occurrence of the corresponding
2020). For this, we use RoBERTA Large, fine NatOp as per Table 1 is possible in the candidate
tuned on MNLI, for obtaining the contextualised sequence. Summarily, ProoFVer-K-NoCS does
word embeddings for the alignment. The final not use any gold information from the fact correc-
step, i.e. entailment assignment, starts by assign- tion dataset directly, apart from using Kepler-CT.
ing NatOps to individual mutations, in isolation, Further, ProoFVer-K use gold standard informa-
by relying on external lexicons and KBs. About tion for identifying O-span for the heuristic anno-
93.59 % of the claims had only at most one mu- tation of our training data.
tation for which we could not assign a NatOp in
isolation. There were another 4.17 % cases where 6 Evaluation Results
exactly two mutations were unfilled after the in-
dividual assignment. In the oracle based filter- 6.1 Fact-checking accuracy
ing during entailment assignment, the information As shown in Table 2, ProoFVer-ME-Full has the
required for the oracle is obtained from the an- best scores in terms of Label accuracy and FEVER
notation logs of the FEVER annotations process. score on both the blind test data and the devel-
Recently, Thorne and Vlachos (2021b) released a opment data, among all the models we compare
fact correction dataset which contains this infor- against. Compared to ProoFVer-SE, these gains
mation from FEVER. In the annotation of FEVER, come primarily from ProoFVer-ME-Full’s ability
given a sentence in Wikipedia, annotators first ex- to handle multiple evidence sentences (five in our
tract a subsequence containing exactly one piece experiments) together as one input as opposed
of information about an entity. These extracted to handling each separately and then aggregat-
subsequences become the source statements which ing the predictions. The FEVER development set
are then modified to create the claims in FEVER contains 9.8 % (1,960) of the instances requir-
(Thorne et al., 2018a). Further, each such pair of ing multiple evidence sentences for claim verifica-
the source statement and the claim created from tion. While ProoFVer-SE predicts 60.1 % of these
it is annotated with a six class categorisation, as instances correctly, ProoFVer-ME-Full correctlyDev Test
System Stability
Fever Fever
LA LA Error Rate
Score Score
SE 78.71 74.62 74.18 70.09 ProoFVer 6.21
ProoFVer KernelGAT 12.35
ME-Align 79.83 76.33 77.16 72.47
(BART) CorefBERT 10.27
ME-Full 80.23 78.17 79.25 74.37
KGAT (Roberta) 78.29 76.11 74.07 70.38
Table 3: Stability Error Rate
CorefBERT (Roberta) 79.12 77.46 75.96 72.30 (SER) on FEVER development
DREAM (XLNET) 79.16 - 76.85 70.60 data. Lower the SER, better the
model.
Table 2: Performance on the development and blind test data on FEVER.
predicts 67.44 % of these. Further, around 80.73 Training ProoFVer
Kepler-CT
% (of 18,038) of the single evidence instances are Set Size K-NoCS K
correctly predicted by ProoFVer-SE, in compari- 1,800 69.07 64.65 66.73
son to 81.62 % instances for ProoFVer-ME-Full. 3,600 72.53 67.25 69.17
All the configurations of ProoFVer use dynami- 6,000 74.02 68.86 72.41
cally constrained markup decoding during predic- 12,000 77.95 72.83 74.42
tion (3.1) to constrain the search space. How- 18,000 79.67 74.25 76.23
ever, we observe that any attempts to further re- 30,000 80.61 75.39 77.76
strict the control of the proof generator over pre- 45,000 82.76 77.62 78.84
dicting the text portions results in performance 60,000 84.85 78.61 79.67
deterioration. In our most restrictive version of
Table 4: Performance (label accuracy) of ProoFVer-K
ProoFVer, we determine the aligned spans of the and -NoCS, two variants which use predictions from
claim and evidence beforehand using the same Kepler-CT classifier for identifying O-class. The size
chunker and aligner used in heuristic annotation of training data used for Kepler-CT and its classifier
of the training data. During prediction, the de- accuracy is also provided.
coding mechanism is coded to enforce the pre-
determined aligned spans as predictions. During
evaluation, this setup provides perfect overlap in
text portions of the proof in the prediction and the in Table 4, we can limit the influence of the addi-
groundtruth of the development data of FEVER. tional data required by building the six class classi-
Here, the proof generator has control only over fier, Kepler-CT. Here, by only using gold informa-
prediction of the NatOps. However, this config- tion from 41.25 % of the instances in FEVER, we
uration reported a label accuracy of 77.42 % and a can obtain a classifier with an accuracy 0f 84.85
FEVER score of 75.27 % on the development data, %. Moreover, the corresponding ProoFVer config-
performing worse than all the models reported in urations trained on proofs generated using infor-
Table 2. Similarly, the proof generator performs mation from Kepler-CT are competitive with those
the best when it has access to the entire evidence using the gold standard information. For instance,
retrieved. ProoFVer-ME-Full and ProoFVer-ME- ProoFVer-K-NOCS achieves a label accuracy of
Align differs only in terms of access to the re- 78.61 % as against 80.23 % of ProoFVer-ME-Full
trieved evidence, where the latter uses only those on the FEVER development data. This configu-
parts of the evidence sentences that align with the ration uses no additional gold information other
claim, instead of the whole sentences. While this than what is required for training Kepler-CT. Sim-
configuration outperforms all the baselines, it still ilarly, ProoFVer-K which use gold information for
falls short of ProoFVer-ME-Full as shown in Table identifying the O-span, achieve a label accuracy
2. of 79.67 %, outperforming all the baseline models.
Moreover, with Kepler-CT, trained with as low as
Impact of additional manual annotation The 1.24 % of instances in FEVER, helps ProoFVer-K-
use of manual annotation from the fact correction NoCS and ProoFVer-K achieve label accuracy of
dataset in terms of both O-class and O-span help 64.65 % and 66.73 % respectively on the FEVER
the performance of the model. However, as shown development data.Dataset
Model FEVER-DEV Symmetric FEVER
Original FT FT+L2 Original FT FT+L2
ProoFVer 89.07˘0.3 86.41˘0.8 87.95˘1.0 ˚ 81.70˘0.4 85.88˘1.3 # 83.37˘1.3#˚
KernelGAT 86.02˘0.2 76.67˘0.3 79.93˘0.9 ˚ 65.73˘0.3 84.94˘1.1 # 73.34˘1.5#˚
CorefBERT 88.26˘0.4 78.79˘0.2 84.22˘1.5˚ 68.49˘0.6 85.45˘0.2# 77.37˘0.5#˚
Table 5: Accuracies of models on FEVER-DEV and Symmetric FEVER with and without fine tuning. All results
marked with ˚ and # are statistically significant with p ă 0.05 against their FT and Original variants respectively.
6.2 Robustness 6.3 ProoFVer proofs as explanations
Stability Error Rate (SER): SER quantifies the ProoFVer’s proofs are guaranteed to be faithful ex-
rate of instances where a system alters its deci- planations by construction. We further evaluate
sion due to the presence of superfluous informa- the explanations for plausibility and also conduct
tion in its input, passed on by the retriever com- a human evaluation using forward prediction task.
ponent. Table 3 shows the SER for the three
competing systems, where a lower SER implies Plausibility: Rationales extracted based on at-
improved robustness against superfluous informa- tention scores are often used as means to highlight
tion. Both KernelGAT and CorefBERT have the reasoning involved in the decision making pro-
a SER of 12.35 % and 10.27 % respectively, cess of various models (DeYoung et al., 2020). We
whereas ProoFVer reports an SER of only 6.21 %. use thresholded attention scores from KernelGAT
The SER results imply that both the baselines and CorefBERT to identify rationales for the pre-
change their predictions from SUPPORT or RE- dictions of these systems. For ProoFVer, we obtain
FUTE after providing them with superfluous in- our rationales from the generated prof, by extract-
formation more often than ProoFVer, and hence ing those lexical entries from the aligned evidence
are more vulnerable to model overstability. spans in the proof that do not have a lexical over-
lap with the claim. The evaluation compares the
Symmetric FEVER As shown in Table 5, extracted rationales with human rationales. To ob-
ProoFVer shows better robustness by reporting tain the latter, we identify those claims from the
a mean accuracy of 81.70 % on the Symmetric FEVER development data, where the claim and
FEVER test dataset, which is 13.21 percentage its source statement differ from each other only by
points more than that of CorefBERT, the next best a word, an entity or a phrase. This implies that
model. All models improve their accuracy and the portion of the text in the source statement is
are comparable on Symmetric FEVER test set, the human rationale, as long as it is present in the
when we fine tune them using the dataset’s de- evidence. We ensure that all the systems have ac-
velopment set. However, this comes at a perfor- cess to this rationale, we filter 300 such cases from
mance degradation of more than 9 % on the orig- FEVER development data where the source state-
inal FEVER development data for both Kernel- ment form a subsequence in the evidence. We use
GAT and CorefBERT, due to catastrophic forget- token-level F-score based on the matches between
ting (French, 1999). This occurs primarily due to the ground truth rationales and the rationales from
the shift in label distribution during fine tuning, different systems. We experiment with tokens of
as Symmetric FEVER contains claims with only a different attention weights ranging from top 1 %
SUPPORT or REFUTE label. ProoFVer reports a to 50 % with a step size of 5 for both KernelGAT
degradation of less than 3 % in its accuracy as it is and CorefBERT. For ProoFVer, we remove those
a seq2seq model with an objective trained to gen- evidence spans in our explanations which are exact
erate a sequence of NatOps. To mitigate the effect matches with the claim and keep the rest. We find
of catastrophic forgetting, we apply L2 regularisa- that the ProoFVer reports a token level F-score of
tion for all the three models (Thorne and Vlachos, 93.28 %, compared to 87.61 % and 86.42 %, the
2021a) which improves all models on the FEVER best F-Scores for CorefBERT and KernelGAT.
development set. Nevertheless, ProoFVer has the
highest scores among the competing models after Human evaluation of the Natural Logic rea-
regularisation. soning as an explanation: We perform humanevaluation of our explanations using forward sim- cent state-of-the-art models both in terms of ac-
ulation (Doshi-Velez and Kim, 2017), where we curacy and robustness. Further, our explanations
ask humans to predict the system output based on are shown to score better on rationale extraction in
the explanations. For ProoFVer we provide the comparison to attention based highlights, and in
claim along with the sequence of triples gener- improving the understanding of the decision mak-
ated, as well as the those sentences from which ing process of the models by humans .
the evidence spans in the explanation were ex-
tracted. The baseline is a claim provided with 5 re- Acknowledegments
trieved evidence sentences, which are the same for Amrith Krishna and Andreas Vlachos are sup-
all models considered. We use predictions from ported by a Sponsored Research Agreement be-
CorefBERT as the model predictions in the base- tween Facebook and the University of Cambridge.
line. Each annotator is presented with 24 different Andreas Vlachos is additionally supported by the
claims, 12 from each system, ProoFVer and base- ERC grant AVeriTeC.
line. We used 60 claims, thus 120 explanations ob-
tained a total of 360 impressions, from 15 annota-
tors. All the annotators are either pursuing a PhD, References
or are postdocs in fields related to computer sci-
Lasha Abzianidze. 2017a. LangPro: Natural lan-
ence and computational linguistics, or are indus-
guage theorem prover. In Proceedings of the
try researchers or data scientists. Since the human
2017 Conference on Empirical Methods in Nat-
annotators need not be aware of the natural logic
ural Language Processing: System Demonstra-
operators, we replaced them with human readable
tions, pages 115–120, Copenhagen, Denmark.
phrases.4 The rephrasing also allows to avoid the
Association for Computational Linguistics.
use of the DFA to arrive at the model prediction
by those who are aware of the deterministic na- Lasha Abzianidze. 2017b. A Natural Proof Sys-
ture of the explanation. With the ProoFVer expla- tem for Natural Language. Ph.D. thesis, Tilburg
nations, the human evaluators are able to predict University.
the model decisions correctly in 82.78 % of the
cases as against 70 % of the cases for the baseline. Naser Ahmadi, Joohyung Lee, Paolo Papotti, and
In both systems, humans were mostly confused Mohammed Saeed. 2019. Explainable fact
in instances with a ‘Not Enough Info’ label, and checking with probabilistic answer set program-
had comparable percentage of correct predictions ming. In Proceedings of the 2019 Truth and
between the two systems, 68.33 % and 65 % re- Trust Online Conference (TTO 2019), London,
spectively. The biggest gain occurred for instances UK, October 4-5, 2019.
with a REFUTE label. Here, annotators could cor-
Alan Akbik, Tanja Bergmann, Duncan Blythe,
rectly predict the model decisions in 86.67 % of
Kashif Rasul, Stefan Schweter, and Roland
the cases for ProoFVer, though it was only 70 %
Vollgraf. 2019. Flair: An easy-to-use frame-
for the baseline.
work for state-of-the-art nlp. In NAACL 2019,
7 Conclusion 2019 Annual Conference of the North American
Chapter of the Association for Computational
We present ProoFVer, a natural logic based proof Linguistics (Demonstrations), pages 54–59.
system for fact verification that generates faithful
explanations. The proofs we provide are aligned Gabor Angeli. 2016. Learning Open Domain
spans of evidences labelled with natural logic op- Knowledge From Text. Ph.D. thesis, Stanford
erators, making it more fine grained than sentence University.
level explanations. Further, our explanations rep- Gabor Angeli and Christopher D. Manning. 2014.
resent a reasoning process using the natural logic NaturalLI: Natural logic inference for common
relations, making the decision making determinis- sense reasoning. In Proceedings of the 2014
tic. Our extensive experiments based on FEVER, Conference on Empirical Methods in Natural
shows that our model performs better than re- Language Processing (EMNLP), pages 534–
4
The screenshot for our evaluation page is shown here 545, Doha, Qatar. Association for Computa-
https://pasteboard.co/KcleMbf.png tional Linguistics.Gabor Angeli, Neha Nayak, and Christopher D. New York, NY, USA. Association for Comput-
Manning. 2016. Combining natural logic and ing Machinery.
shallow reasoning for question answering. In
Proceedings of the 54th Annual Meeting of the Juri Ganitkevitch, Benjamin Van Durme, and
Association for Computational Linguistics (Vol- Chris Callison-Burch. 2013. PPDB: The para-
ume 1: Long Papers), pages 442–452, Berlin, phrase database. In Proceedings of the 2013
Germany. Association for Computational Lin- Conference of the North American Chapter of
guistics. the Association for Computational Linguistics:
Human Language Technologies, pages 758–
Pepa Atanasova, Jakob Grue Simonsen, Christina 764, Atlanta, Georgia. Association for Compu-
Lioma, and Isabelle Augenstein. 2020. Gener- tational Linguistics.
ating fact checking explanations. In Proceed-
ings of the 58th Annual Meeting of the As- D Graves. 2018. Understanding the promise and
sociation for Computational Linguistics, pages limits of automated fact-checking. Technical
7352–7364, Online. Association for Computa- report.
tional Linguistics.
Andreas Hanselowski, Christian Stab, Claudia
Nicola De Cao, Gautier Izacard, Sebastian Riedel, Schulz, Zile Li, and Iryna Gurevych. 2019. A
and Fabio Petroni. 2021. Autoregressive en- richly annotated corpus for different tasks in
tity retrieval. In International Conference on automated fact-checking. In Proceedings of
Learning Representations. the 23rd Conference on Computational Natural
Language Learning (CoNLL), pages 493–503,
Jay DeYoung, Sarthak Jain, Nazneen Fatema Ra- Hong Kong, China. Association for Computa-
jani, Eric Lehman, Caiming Xiong, Richard tional Linguistics.
Socher, and Byron C. Wallace. 2020. ERASER:
A benchmark to evaluate rationalized NLP Hai Hu, Qi Chen, and Larry Moss. 2019. Nat-
models. In Proceedings of the 58th Annual ural language inference with monotonicity. In
Meeting of the Association for Computational Proceedings of the 13th International Confer-
Linguistics, pages 4443–4458, Online. Associ- ence on Computational Semantics - Short Pa-
ation for Computational Linguistics. pers, pages 8–15, Gothenburg, Sweden. Asso-
ciation for Computational Linguistics.
Finale Doshi-Velez and Been Kim. 2017. To-
wards a rigorous science of interpretable ma- Minqing Hu and Bing Liu. 2004. Mining and
chine learning. summarizing customer reviews. In Proceed-
ings of the Tenth ACM SIGKDD International
Yufei Feng, Zi’ou Zheng, Quan Liu, Michael Conference on Knowledge Discovery and Data
Greenspan, and Xiaodan Zhu. 2020. Explor- Mining, KDD ’04, page 168–177, New York,
ing end-to-end differentiable natural logic mod- NY, USA. Association for Computing Machin-
eling. In Proceedings of the 28th Interna- ery.
tional Conference on Computational Linguis-
tics, pages 1172–1185, Barcelona, Spain (On- Thomas F. Icard III and Lawrence S. Moss. 2014.
line). International Committee on Computa- Recent progress on monotonicity. In Linguistic
tional Linguistics. Issues in Language Technology, Volume 9, 2014
- Perspectives on Semantic Representations for
Robert M. French. 1999. Catastrophic forgetting Textual Inference. CSLI Publications.
in connectionist networks. Trends in Cognitive
Sciences, 3(4):128–135. Alon Jacovi and Yoav Goldberg. 2021. Align-
ing Faithful Interpretations with their Social At-
Mohamed H. Gad-Elrab, Daria Stepanova, Jacopo tribution. Transactions of the Association for
Urbani, and Gerhard Weikum. 2019. Exfakt: A Computational Linguistics, 9:294–310.
framework for explaining facts over knowledge
graphs and text. In Proceedings of the Twelfth Sarthak Jain, Sarah Wiegreffe, Yuval Pinter, and
ACM International Conference on Web Search Byron C. Wallace. 2020. Learning to faithfully
and Data Mining, WSDM ’19, page 87–95, rationalize by construction. In Proceedings ofthe 58th Annual Meeting of the Association for Zhenghao Liu, Chenyan Xiong, Maosong Sun,
Computational Linguistics, pages 4459–4473, and Zhiyuan Liu. 2020. Fine-grained fact ver-
Online. Association for Computational Linguis- ification with kernel graph attention network.
tics. In Proceedings of the 58th Annual Meeting
of the Association for Computational Linguis-
Masoud Jalili Sabet, Philipp Dufter, François
tics, pages 7342–7351, Online. Association for
Yvon, and Hinrich Schütze. 2020. SimAlign:
Computational Linguistics.
High quality word alignments without paral-
lel training data using static and contextualized Bill MacCartney. 2009. NATURAL LANGUAGE
embeddings. In Proceedings of the 2020 Con- INFERENCE. Ph.D. thesis, STANFORD UNI-
ference on Empirical Methods in Natural Lan- VERSITY.
guage Processing: Findings, pages 1627–1643,
Online. Association for Computational Linguis- Bill MacCartney and Christopher D. Manning.
tics. 2007. Natural logic for textual inference. In
Proceedings of the ACL-PASCAL Workshop on
Robin Jia and Percy Liang. 2017. Adversarial ex- Textual Entailment and Paraphrasing, pages
amples for evaluating reading comprehension 193–200, Prague. Association for Computa-
systems. In Proceedings of the 2017 Confer- tional Linguistics.
ence on Empirical Methods in Natural Lan-
guage Processing, pages 2021–2031, Copen- George A. Miller. 1995. Wordnet: A lexi-
hagen, Denmark. Association for Computa- cal database for english. Commun. ACM,
tional Linguistics. 38(11):39–41.
Isaac Johnson. 2020. Analyzing wikidata tran- Ellie Pavlick, Pushpendre Rastogi, Juri Gan-
sclusion on english wikipedia. arXiv preprint itkevitch, Benjamin Van Durme, and Chris
arXiv:2011.00997. Callison-Burch. 2015. PPDB 2.0: Better para-
phrase ranking, fine-grained entailment rela-
Neema Kotonya and Francesca Toni. 2020. Ex- tions, word embeddings, and style classifica-
plainable automated fact-checking for public tion. In Proceedings of the 53rd Annual Meet-
health claims. In Proceedings of the 2020 Con- ing of the Association for Computational Lin-
ference on Empirical Methods in Natural Lan- guistics and the 7th International Joint Con-
guage Processing (EMNLP), pages 7740–7754, ference on Natural Language Processing (Vol-
Online. Association for Computational Linguis- ume 2: Short Papers), pages 425–430, Beijing,
tics. China. Association for Computational Linguis-
George Lakoff. 1972. Linguistics and Natural tics.
Logic. Springer Netherlands, Dordrecht.
Kashyap Popat, Subhabrata Mukherjee, Andrew
Tao Lei, Regina Barzilay, and Tommi Jaakkola. Yates, and Gerhard Weikum. 2018. DeClarE:
2016. Rationalizing neural predictions. In Pro- Debunking fake news and false claims using
ceedings of the 2016 Conference on Empiri- evidence-aware deep learning. In Proceedings
cal Methods in Natural Language Processing, of the 2018 Conference on Empirical Methods
pages 107–117, Austin, Texas. Association for in Natural Language Processing, pages 22–32,
Computational Linguistics. Brussels, Belgium. Association for Computa-
tional Linguistics.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer Matt Post and David Vilar. 2018. Fast lexically
Levy, Veselin Stoyanov, and Luke Zettlemoyer. constrained decoding with dynamic beam allo-
2020. BART: Denoising sequence-to-sequence cation for neural machine translation. In Pro-
pre-training for natural language generation, ceedings of the 2018 Conference of the North
translation, and comprehension. In Proceed- American Chapter of the Association for Com-
ings of the 58th Annual Meeting of the As- putational Linguistics: Human Language Tech-
sociation for Computational Linguistics, pages nologies, Volume 1 (Long Papers), pages 1314–
7871–7880, Online. Association for Computa- 1324, New Orleans, Louisiana. Association for
tional Linguistics. Computational Linguistics.You can also read

















































