Ananta: Cloud Scale Load Balancing
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Ananta: Cloud Scale Load Balancing
Parveen Patel, Deepak Bansal, Lihua Yuan, Ashwin Murthy, Albert Greenberg,
David A. Maltz, Randy Kern, Hemant Kumar, Marios Zikos, Hongyu Wu,
Changhoon Kim, Naveen Karri
Microsoft
ABSTRACT
Layer-4 load balancing is fundamental to creating scale-out web
services. We designed and implemented Ananta, a scale-out layer-4
load balancer that runs on commodity hardware and meets the per-
formance, reliability and operational requirements of multi-tenant
cloud computing environments. Ananta combines existing tech-
niques in routing and distributed systems in a unique way and splits
the components of a load balancer into a consensus-based reliable
control plane and a decentralized scale-out data plane. A key com-
ponent of Ananta is an agent in every host that can take over the
packet modification function from the load balancer, thereby en-
abling the load balancer to naturally scale with the size of the data
center. Due to its distributed architecture, Ananta provides direct Figure 1: Ananta Data Plane Tiers
server return (DSR) and network address translation (NAT) capa-
bilities across layer-2 boundaries. Multiple instances of Ananta
have been deployed in the Windows Azure public cloud with com-
to be at least as high as applications’ SLA, but often significantly
bined bandwidth capacity exceeding 1Tbps. It is serving traffic
higher to account for failures in other infrastructure services.
needs of a diverse set of tenants, including the blob, table and rela-
As a cloud provider, we have seen that cloud services put huge
tional storage services. With its scale-out data plane we can easily
pressure on the load balancer’s control plane and data plane. In-
achieve more than 100Gbps throughput for a single public IP ad-
bound flows can be intense — greater than 100 Gbps for a single
dress. In this paper, we describe the requirements of a cloud-scale
IP address — with every packet hitting the load balancer. The pay-
load balancer, the design of Ananta and lessons learnt from its im-
as-you-go model and large tenant deployments put extremely high
plementation and operation in the Windows Azure public cloud.
demands on real-time load balancer configuration — in a typical
Categories and Subject Descriptors: C.2.4 [Computer-Communi- environment of 1000 hosts we see six configuration operations per
cation Networks]: Distributed Systems minute on average, peaking at one operation per second. In our ex-
General Terms: Design, Performance, Reliability perience, the data plane and control plane demands drove our hard-
ware load balancer solution into an untenable corner of the design
Keywords: Software Defined Networking; Distributed Systems;
space, with high cost, with SLA violations and with load balancing
Server Load Balancing
device failures accounting for 37% of all live site incidents.
The design proposed in this paper, which we call Ananta (mean-
1. INTRODUCTION ing infinite in Sanskrit), resulted from examining the basic require-
The rapid rise of cloud computing is driving demand for large ments, and taking an altogether different approach. Ananta is a
scale multi-tenant clouds. A multi-tenant cloud environment hosts scalable software load balancer and NAT that is optimized for multi-
many different types of applications at a low cost while providing tenant clouds. It achieves scale, reliability and any service any-
high uptime SLA — 99.9% or higher [3, 4, 19, 10]. A multi-tenant where (§2) via a novel division of the data plane functionality into
load balancer service is a fundamental building block of such multi- three separate tiers. As shown in Figure 1, at the topmost tier
tenant cloud environments. It is involved in almost all external and routers provide load distribution at the network layer (layer-3) based
half of intra-DC traffic (§2) and hence its uptime requirements need on the Equal Cost Multi Path (ECMP) routing protocol [25]. At the
second tier, a scalable set of dedicated servers for load balancing,
called multiplexers (Mux), maintain connection flow state in mem-
Permission to make digital or hard copies of all or part of this work for
personal or classroom use is granted without fee provided that copies are not ory and do layer-4 load distribution to application servers. A third
made or distributed for profit or commercial advantage and that copies bear tier present in the virtual switch on every server provides stateful
this notice and the full citation on the first page. Copyrights for components NAT functionality. Using this design, no outbound trafffic has to
of this work owned by others than ACM must be honored. Abstracting with pass through the Mux, thereby significantly reducing packet pro-
credit is permitted. To copy otherwise, or republish, to post on servers or to cessing requirement. Another key element of this design is the
redistribute to lists, requires prior specific permission and/or a fee. Request ability to offload multiplexer functionality down to the host. As
permissions from permissions@acm.org.
SIGCOMM’13, August 12–16, 2013, Hong Kong, China. discussed in §2, this design enables greater than 80% of the load
Copyright 2013 ACM 978-1-4503-2056-6/13/08 ...$15.00. balanced traffic to bypass the load balancer and go direct, thereby
207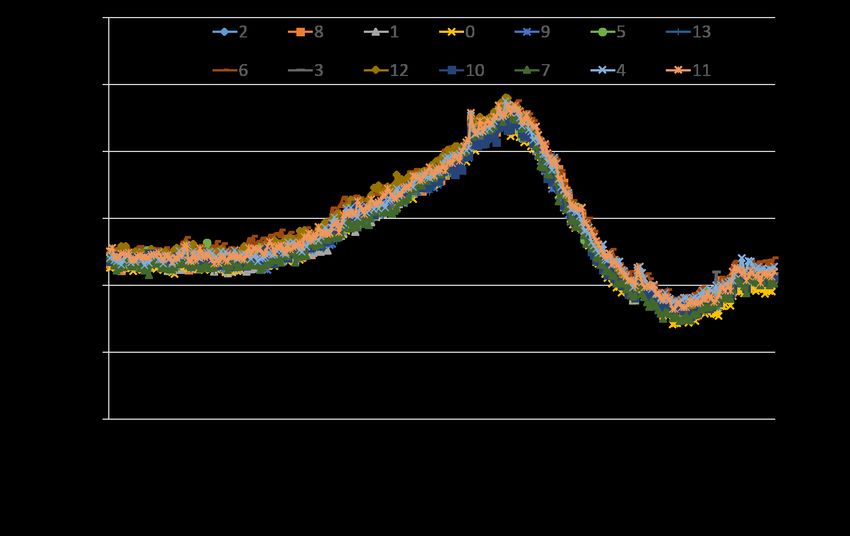
eliminating throughput bottleneck and reducing latency. This divi-
sion of data plane scales naturally with the size of the network and
introduces minimal bottlenecks along the path.
Ananta’s approach is an example of Software Defined Network-
ing (SDN) as it uses the same architectural principle of manag-
ing a flexible data plane via a centralized control plane. The con-
troller maintains high availability via state replication based on the
Paxos [14] distributed consensus protocol. The controller also im-
plements real-time port allocation for outbound NAT, also known
as Source NAT (SNAT).
Ananta has been implemented as a service in the Windows Azure
cloud platform. We considered implementing Ananta functionality
in hardware. However, with this initial Ananta version in software,
we were able to rapidly explore various options in production and
determine what functions should be built into hardware, e.g., we Figure 2: Flat Data Center Network of the Cloud. All network
realized that keeping per-connection state is necessary to maintain devices run as Layer-3 devices causing all traffic external to a rack
application uptime due to the dynamic nature of the cloud. Sim- to be routed. All inter-service traffic — intra-DC, inter-DC and
ilarly, weighted random load balancing policy, which reduces the Internet — goes via the load balancer.
need for per-flow state synchronization among load balancer in-
stances, is sufficient for typical cloud workloads. We consider the
evaluation of these mechanisms, regardless of how they are imple-
mented, to be a key contribution of this work.
More than 100 instances of Ananta have been deployed in Win-
dows Azure since September 2011 with a combined capacity of
1Tbps. It has been serving 100,000 VIPs with varying workloads.
It has proven very effective against DoS attacks and minimized dis-
ruption due to abusive tenants. Compared to the previous solution,
Ananta costs one order of magnitude less; and provides a more
scalable, flexible, reliable and secure solution overall.
There has been significant interest in moving middlebox func-
tionality to software running on general-purpose hardware in both
research [23, 24, 5] and industry [8, 2, 27, 21, 31]. Most of these
architectures propose using either DNS or OpenFlow-enabled hard- Figure 3: Internet and inter-service traffic as a percentage of
ware switches for scaling. To the best of our knowledge Ananta is total traffic in eight data centers.
the first middlebox architecture that refactors the middlebox func-
tionality and moves parts of it to the host thereby enabling use of
network routing technologies — ECMP and BGP — for natural is a collection of virtual or native machines that is managed as one
scaling with the size of the network. The main contributions of this entity. We use the terms tenant and service interchangeably in this
paper to the research community are: paper. Each machine is assigned a private Direct IP (DIP) address.
• Identifying the requirements and design space for a cloud- Typically, a service is assigned one public Virtual IP (VIP) address
scale solution for layer-4 load balancing. and all traffic crossing the service boundary, e.g., to the Internet or
to back-end services within the same data center such as storage,
• Providing design, implementation and evaluation of Ananta uses the VIP address. A service exposes zero or more external end-
that combines techniques in networking and distributed sys- points that each receive inbound traffic on a specific protocol and
tems to refactor load balancer functionality in a novel way to port on the VIP. Traffic directed to an external endpoint is load-
meet scale, performance and reliability requirements. balanced to one or more machines of the service. All outbound
traffic originating from a service is Source NAT’ed (SNAT) using
• Providing measurements and insights from running Ananta the same VIP address as well. Using the same VIP for all inter-
in a large operational Cloud. service traffic has two important benefits. First, it enables easy
upgrade and disaster recovery of services since the VIP can be dy-
2. BACKGROUND namically mapped to another instance of the service. Second, it
In this section, we first consider our data center network archi- makes ACL management easier since the ACLs can be expressed
tecture and the nature of traffic that is serviced by the load balancer. in terms of VIPs and hence do not change as services scale up or
We then derive a set of requirements for the load balancer. down or get redeployed.
2.1 Data Center Network 2.2 Nature of VIP Traffic
Figure 2 shows the network of a typical data center in our cloud. Public cloud services [3, 4, 19] host a diverse set of workloads,
A medium sized data center hosts 40, 000 servers, each with one such as storage, web and data analysis. In addition, there are an in-
10Gbps NIC. This two-level Clos network architecture [11] typi- creasing number of third-party services available in the cloud. This
cally has an over-subscription ratio of 1 : 4 at the spine layer. The trend leads us to believe that the amount of inter-service traffic in
border routers provide a combined capacity of 400Gbps for con- the cloud will continue to increase. We examined the total traffic
nectivity to other data centers and the Internet. A cloud controller in eight data centers for a period of one week and computed the
manages resources in the data center and hosts services. A service ratio of Internet traffic and inter-service traffic to the total traffic.
208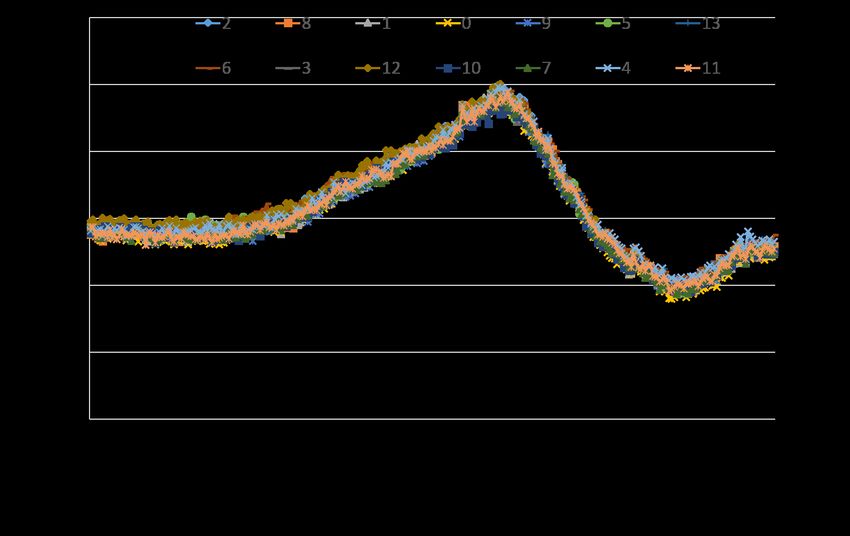
The result is shown in Figure 3. On average, about 44% (with a
minimum of 18% and maximum of 59%) of the total traffic is VIP
traffic — it either needs load balancing or SNAT or both. Out of
this, about 14% traffic on average is to the Internet and the remain-
ing 30% is intra-DC. The ratio of intra-DC VIP traffic to Internet
VIP traffic is 2 : 1. Overall, we find that 70% of total VIP traffic
is inter-service within the same data center. We further found that
on average the ratio of inbound traffic to outbound traffic across
our data centers is 1 : 1. Majority of this traffic is read-write traf-
fic and cross-data center replication traffic to our storage services.
In summary, greater than 80% of VIP traffic is either outbound or
contained within the data center. As we show in this paper, Ananta
offloads all of this traffic to the host, thereby handling only 20% of
the total VIP traffic.
2.3 Requirements Figure 4: Components of a traditional load balancer. Typically,
Scale, Scale and Scale: The most stringent scale requirements the load balancer is deployed in an active-standby configuration.
can be derived by assuming that all traffic in the network is either The route management component ensures that the currently active
load balanced or NAT’ed. For a 40, 000 server network, built us- instance handles all the traffic.
ing the architecture shown in Figure 2, 400Gbps of external traffic
and 100 Tbps of intra-DC traffic will need load balancing or NAT.
it is important that the load balancer provides each service its fair
Based on the traffic ratios presented in §2.2, at 100% network uti-
share of resources.
lization, 44Tbps traffic will be VIP traffic. A truly scalable load
balancer architecture would support this requirement while main-
taining low cost. While cost is a subjective metric, in our cloud, less 3. DESIGN
than 1% of the total server cost would be considered low cost, so
any solution that would cost more than 400 general-purpose servers 3.1 Design Principles
is too expensive. At the current typical price of US$2500 per server, Scale-out In-network Processing: Figure 4 illustrates the main
the total cost should be less than US$1,000,000. Traditional hard- components of a traditional load balancer. For each new flow, the
ware load balancers do not meet this requirement as their typical load balancer selects a destination address (or source for SNAT)
list price is US$80,000 for 20Gbps capacity without considering depending on the currently active flows and remembers that deci-
bulk discounts, support costs or redundancy requirements. sion in a flow table. Subsequent packets for that flow use the state
There are two more dimensions to the scale requirement. First, created by the first packet. Traditional NAT and load balancing al-
the bandwidth and number of connections served by a single VIP gorithms (e.g., round-robin) require knowledge of all active flows,
are highly variable and may go up to 100Gbps and 1million simul- hence all traffic for a VIP must pass through the same load balancer.
taneous connections. Second, the rate of change in VIP configura- This forces the load balancer into a scale-up model. A scale-up or
tion tends to be very large and bursty, on average 12000 configura- vertical scaling model is one where handling more bandwidth for
tions per day for a 1000 node cluster, with bursts of 100s of changes a VIP requires a higher capacity box.
per minute as customer services get deployed, deleted or migrated. Network routers, on the other hand, follow a scale-out model. A
Reliability: The load balancer is a critical component to meet scale-out or horizontal scaling model is one where more bandwidth
the uptime SLA of applications. Services rely on the load balancer can be handled by simply adding more devices of similar capac-
to monitor health of their instances and maintain availability during ity. Routers scale out because they do not maintain any per-flow
planned and unplanned downtime. Over many years of operation state that needs synchronization across routers and therefore one
of our cloud we found that traditional 1 + 1 redundancy solutions can add or remove additional routers easily. Ananta design reduces
deployed as active/standby hardware load balancers are unable to the in-network functionality needed for load balancing to be such
meet these high availability needs. The load balancer must support that multiple network elements can simultaneously process packets
N + 1 redundancy model with auto-recovery, and the load balanc- for the same VIP without requiring per-flow state synchronization.
ing service must degrade gracefully in the face of failures. This design choice is enabled because we can make certain as-
Any Service Anywhere: In our cloud, applications are gener- sumptions about our environment. One of the key assumptions is
ally spread over multiple layer-2 domains and sometimes even span that load balancing policies that require global knowledge, e.g.,
multiple data centers. The load balancer should be able to reach weighted round robin (WRR), are not required for layer-4 load bal-
DIPs located anywhere on the network. Traditional load balancers ancing. Instead, randomly distributing connections across servers
provide some of their functionality, e.g., NAT, to DIPs only within based on their weights is a reasonable substitute for WRR. In fact,
a layer-2 domain. This fragments the load balancer capacity and weighted random is the only load balancing policy used by our load
makes them unusable in layer-3 based architectures. balancer in production. The weights are derived based on the size
Tenant Isolation: A multi-tenant load balancer is shared by of the VM or other capacity metrics.
thousands of services. It is critical that DoS attacks on one ser- Offload to End Systems: Hypervisors in end systems can al-
vice do not affect the availability of other services. Similarly, an ready do highly scalable network processing, e.g., ACL enforce-
abusive service should not be able to affect the availability of NAT ment, rate limiting and metering. Ananta leverages this distributed
for other services by creating large number of outbound connec- scalable platform and offloads significant data plane and control
tions. In our cloud environment, we often see services with large plane functionality down to the hypervisor in end systems. The hy-
number of outbound NAT connections due to bugs and poor appli- pervisor needs to handle state only for the VMs hosted on it. This
cation design. Furthermore, when the load balancer is under load, design choice is another key differentiator from existing load bal-
209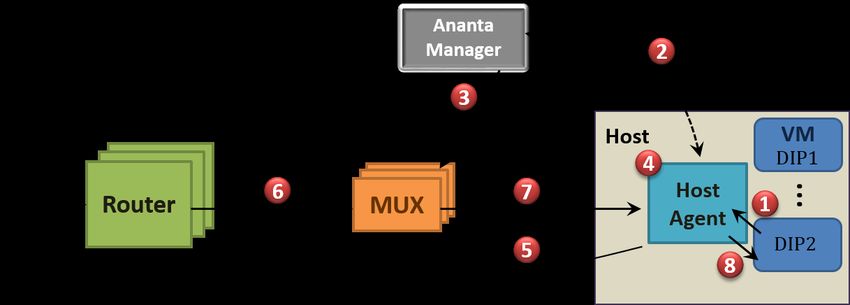
Figure 6: JSON representation of a simple VIP Configuration.
Figure 5: The Ananta Architecture. Ananta consists of three
components — Ananta Manager, Ananta Mux and Host Agent.
Each component is independently scalable. Manager coordinates
state across Agents and Muxes. Mux is responsible for packet for-
warding for inbound packets. Agent implements NAT, which allows Figure 7: Load Balancing for Inbound Connections.
all outbound traffic to bypass Mux. Agents are co-located with des-
tination servers.
using IP-in-IP protocol [18] setting the selected DIP as the destina-
tion address in the outer header (step 2). It then sends it out using
ancers. While on one hand it enables natural scaling with the size of regular IP routing at the Mux (step 3). The Mux and the DIP do not
the data center; on the other hand, it presents significant challenges need to be on the same VLAN, they just need to have IP (layer-3)
in managing distributed state across all hosts and maintaining avail- connectivity between them. The HA, located on the same physi-
ability during failures of centralized components. cal machine as the target DIP, intercepts this encapsulated packet,
removes the outer header, and rewrites the destination address and
3.2 Architecture port (step 4) and remembers this NAT state. The HA then sends the
Ananta is a loosely coupled distributed system comprising three rewritten packet to the VM (step 5).
main components (see Figure 5) — Ananta Manager (AM), Multi- When the VM sends a reply packet for this connection, it is in-
plexer (Mux) and Host Agent (HA). To better understand the details tercepted by the HA (step 6). The HA does a reverse NAT based on
of these components, we first discuss the load balancer configura- the state from step 4 and rewrites the source address and port (step
tion and the overall packet flow. All packet flows are described 7). It then sends the packet out to the router towards the source of
using TCP connections but the same logic is applied for UDP and this connection. The return packet does not go through the Mux at
other protocols using the notion of pseudo connections. all, thereby saving packet processing resources and network delay.
This technique of bypassing the load balancer on the return path is
3.2.1 VIP Configuration known as Direct Server Return (DSR). Not all packets of a connec-
The load balancer receives a VIP Configuration for every VIP tion would end up at the same Mux, however all packets for a single
that it is doing load balancing and NAT for. A simplified VIP con- connection must be delivered to the same DIP. Muxes achieve this
figuration is shown in Figure 6. An Endpoint refers to a specific via a combination of consistent hashing and state management as
transport protocol and port on the VIP that is load balanced to a set explained later in this section.
of DIPs. Packets destined to an Endpoint are NAT’ed to the DIP
address and port. SNAT specifies a list of IP addresses for which 3.2.3 Outbound Connections
outbound connections need to be Source NAT’ed with the VIP and A unique feature of Ananta is a distributed NAT for outbound
an ephemeral port. connections. Even for outbound connections that need source NAT
(SNAT), Ananta ensures that outgoing packets do not need to go
3.2.2 Inbound Connections through Mux. Figure 8 shows how packets for an outbound SNAT
Figure 7 shows how packets destined for a VIP are load bal-
anced and delivered to the DIP of a VM. When a VIP is con-
figured on Ananta, each Mux advertises a route to its first-hop
router announcing itself as the next hop for that VIP1 . This causes
the routers to distribute packets destined for the VIP across all
the Mux nodes based on Equal Cost MultiPath Routing Protocol
(ECMP) [25] (step 1). Upon receiving a packet, the Mux chooses
a DIP for the connection based on its load balancing algorithm, de-
scribed later in this section. It then encapsulates the received packet
1
In reality, routes are advertised for VIP subnets due to small rout-
ing tables in commodity routers but the same logic applies. Figure 8: Handling Outbound SNAT Connections.
210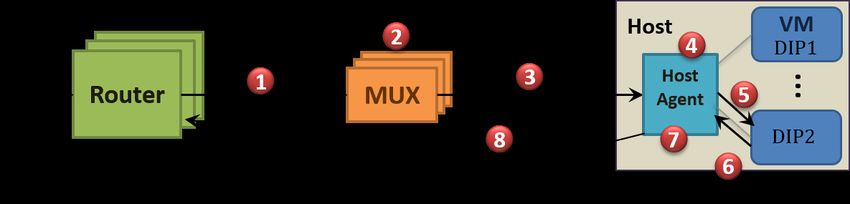
connection are handled. A VM sends a packet containing its DIP
as the source address, portd as the port and an external address as
the destination address (step 1). The HA intercepts this packet and
recognizes that this packet needs SNAT. It then holds the packet
in a queue and sends a message to AM requesting an externally
routable VIP and a port for this connection (step 2). AM allocates
a (V IP, ports ) from a pool of available ports and configures each
Mux with this allocation (step 3). AM then sends this allocation to
the HA (step 4). The HA uses this allocation to rewrite the packet
so that its source address and port are now (V IP, ports ). The HA
sends this rewritten packet directly to the router. The return pack-
ets from the external destination are handled similar to inbound
connections. The return packet is sent by the router to one of the
Mux nodes (step 6). The Mux already knows that DIP 2 should
receive this packet (based on the mapping in step 3), so it encap-
sulates the packet with DIP 2 as the destination and sends it out
(step 7). The HA intercepts the return packet, performs a reverse Figure 9: Fastpath Control and Data Packets. Routers are not
translation so that the packet’s destination address and port are now shown for brevity. Starting with step 8, packets flow directly
(DIP, portd ). The HA sends this packet to the VM (step 8). between source and destination hosts.
3.2.4 Fastpath
In order to scale to the 100s of terabit bandwidth requirement of jack traffic. HA prevents this by validating that the source address
intra-DC traffic, Ananta offloads most of the intra-DC traffic to end of redirect message belongs to one of the Ananta services in the
systems. This is done by a technique we call Fastpath. The key data center. This works in our environment since the hypervisor
idea is that the load balancer makes its decision about which DIP prevents IP spoofing. If IP spoofing cannot be prevented, a more
a new connection should go to when the first packet of that con- dynamic security protocol such as IPSEC can be employed.
nection arrives. Once this decision is made for a connection it does
not change. Therefore, this information can be sent to the HAs on
3.3 Mux
the source and destination machines so that they can communicate The Multiplexer (Mux) handles all incoming traffic. It is respon-
directly. This results in the packets being delivered directly to the sible for receiving traffic for all the configured VIPs from the router
DIP, bypassing Mux in both directions, thereby enabling commu- and forwarding it to appropriate DIPs. Each instance of Ananta has
nication at full capacity supported by the underlying network. This one or more sets of Muxes called Mux Pool. All Muxes in a Mux
change is transparent to both the source and destination VMs. Pool have uniform machine capabilities and identical configuration,
To illustrate how Fastpath works, consider two services 1 and 2 i.e., they handle the same set of VIPs. Having a notion of Mux Pool
that have been assigned virtual addresses V IP 1 and V IP 2 respec- allows us to scale the number of Muxes (data plane) independent
tively. These two services communicate with each other via V IP 1 of the number of AM replicas (control plane).
and V IP 2 using the algorithms for load balancing and SNAT de-
scribed above. Figure 9 shows a simplified version of packet flow 3.3.1 Route Management
for a connection initiated by a VM DIP 1 (belonging to service 1) Each Mux is a BGP speaker [20]. When a VIP is configured on
to V IP 2. The source host of DIP 1 SNATs the TCP SYN packet Ananta, each Mux starts advertising a route for that VIP to its first-
using V IP 1 and sends it to V IP 2 (step 1). This packet is de- hop router with itself as the next hop. All Muxes in a Mux Pool are
livered to a Mux2, which forwards the packet towards destination equal number of Layer-3 network hops away from the entry point
DIP 2 (step 2). When DIP 2 replies to this packet, it is SNAT’ed of the data center. This ensures that the routers distribute traffic for
by the destination host using V IP 2 and sent to Mux1 (step 3). This a given VIP equally across all Muxes via the Equal Cost MultiPath
Mux uses its SNAT state and sends this packet to DIP 1 (step 4). (ECMP) routing protocol [25]. Running the BGP protocol on the
Subsequent packets for this connection follow the same path. Mux provides automatic failure detection and recovery. If a Mux
For Fastpath, Ananta configures Mux with a set of source and fails or shuts down unexpectedly, the router detects this failure via
destination subnets that are capable of Fastpath. Once a connec- the BGP protocol and automatically stops sending traffic to that
tion has been fully established (e.g., TCP three-way handshake has Mux. Similarly, when the Mux comes up and it has received state
completed) between V IP 1 and V IP 2, Mux2 sends a redirect mes- from AM, it can start announcing the routes and the router will start
sage to V IP 1, informing it that the connection is mapped to DIP 2 forwarding traffic to it. Muxes use the TCP MD5 [13] protocol for
(step 5). This redirect packet goes to a Mux handling V IP 1, which authenticating their BGP sessions.
looks up its table to know that this port is used by DIP 1. Mux1
then sends a redirect message towards DIP 1 and DIP 2 (steps 6 3.3.2 Packet Handling
and 7 respectively). HA on the source host intercepts this redirect The Mux maintains a mapping table, called VIP map, that deter-
packet and remembers that this connection should be sent directly mines how incoming packets are handled. Each entry in the map-
to DIP 2. Similarly HA on the destination host intercepts the redi- ping table maps a VIP endpoint, i.e., three-tuple (VIP, IP protocol,
rect message and remembers that this connection should be sent to port), to a list of DIPs. The mapping table is computed by AM and
DIP 1. Once this exchange is complete, any future packets for this sent to all the Muxes in a Mux Pool. When Mux receives a packet
connection are exchanged directly between the source and destina- from the router, it computes a hash using the five-tuple from packet
tion hosts (step 8). header fields — (source IP, destination IP, IP Protocol, source port,
There is one security concern associated with Fastpath – a rogue destination port). It then uses this hash to lookup a DIP from the
host could send a redirect message impersonating the Mux and hi- list of DIPs in the associated map. Finally, it encapsulates [18] the
211packet with an outer IP header — with itself as the source IP and the Host Agent, it decapsulates them and then performs a NAT as
the DIP as the destination IP — and forwards this packet to the DIP. per the NAT rules configured by Ananta Manager. The NAT rules
The encapsulation at the Mux preserves the original IP header describe the rewrite rules of type: (V IP, protocolv , portv ) ⇒
and IP payload of the packet, which is essential for achieving Di- (DIP, protocolv , portd ). In this case, the Host Agent identifies
rect Server Return (DSR). All Muxes in a Mux Pool use the exact packets that are destined to (V IP, protocolv , portv ), rewrites the
same hash function and seed value. Since all Muxes have the same destination address and port to (DIP, portd ) and creates bi-directional
mapping table, it doesn’t matter which Mux a given new connec- flow state that is used by subsequent packets of this connection.
tion goes to, it will be directed to the same DIP. When a return packet for this connection is received, it does re-
verse NAT based on flow state and sends the packet to the source
3.3.3 Flow State Management directly through the router, bypassing the Muxes.
Mux supports two types of mapping entries – stateful and state-
less. Stateful entries are used for load balancing and stateless en- 3.4.2 Source NAT for Outbound Connections
tries are used for SNAT. For stateful mapping entries, once a Mux For outbound connections, the Host Agent does the following.
has chosen a DIP for a connection, it remembers that decision in It holds the first packet of a flow in a queue and sends a mes-
a flow table. Every non-SYN TCP packet, and every packet for sage to Ananta Manager requesting a VIP and port for this con-
connection-less protocols, is matched against this flow table first, nection. Ananta Manager responds with a VIP and port and the
and if a match is found it is forwarded to the DIP from the flow Host Agent NATs all pending connections to different destinations
table. This ensures that once a connection is directed to a DIP, it using this VIP and port. Any new connections to different destina-
continues to go to that DIP despite changes in the list of DIPs in the tions (remoteaddress, remoteport) can also reuse the same port
mapping entry. If there is no match in the flow table, the packet is as the TCP five-tuple will still be unique. We call this technique
treated as a first packet of the connection. port reuse. AM may return multiple ports in response to a single
Given that Muxes maintain per-flow state, it makes them vulner- request. The HA uses these ports for any subsequent connections.
able to state exhaustion attacks such as the SYN-flood attack. To Any unused ports are returned back after a configurable idle time-
counter this type of abuse, Mux classifies flows into trusted flows out. If the HA keeps getting new connections, these ports are never
and untrusted flows. A trusted flow is one for which the Mux has returned back to AM, however, AM may force HA to release them
seen more than one packet. These flows have a longer idle time- at any time. Based on our production workload, we have made a
out. Untrusted flows are the ones for which the Mux has seen only number of optimizations to minimize the number of SNAT requests
one packet. These flows have a much shorter idle timeout. Trusted a Host Agent needs to send, including preallocation of ports. These
and untrusted flows are maintained in two separate queues and they and other optimizations are discussed later in this paper.
have different memory quotas as well. Once a Mux has exhausted
its memory quota, it stops creating new flow states and falls back to 3.4.3 DIP Health Monitoring
lookup in the mapping entry. This allows even an overloaded Mux Ananta is responsible for monitoring the health of DIPs that are
to maintain VIP availability with a slightly degraded service. behind each VIP endpoint and take unhealthy DIPs out of rotation.
DIP health check rules are specified as part of VIP Configuration.
3.3.4 Handling Mux Pool Changes On first look, it would seem natural to run health monitoring on the
When a Mux in a Mux Pool goes down, routers take it out of ro- Mux nodes so that health monitoring traffic would take the exact
tation once BGP hold timer expires (we typically set hold timer to same network path as the actual data traffic. However, it would put
30 seconds). When any change to the number of Muxes takes place, additional load on each Mux, could result in a different health state
ongoing connections will get redistributed among the currently live on each mux and would incur additional monitoring load on the
Muxes based on the router’s ECMP implementation. When this DIPs as the number of Muxes can be large. Guided by our principle
happens, connections that relied on the flow state on another Mux of offloading to end systems, we chose to implement health mon-
may now get misdirected to a wrong DIP if there has been a change itoring on the Host Agents. A Host Agent monitors the health of
in the mapping entry since the connection started. We have de- local VMs and communicates any changes in health to AM, which
signed a mechanism to deal with this by replicating flow state on then relays these messages to all Muxes in the Mux Pool. Perhaps
two Muxes using a DHT. The description of that design is outside surprising to some readers, running health monitoring on the host
the scope of this paper as we have chosen to not implement this makes it easy to protect monitoring endpoints against unwarranted
mechanism yet in favor of reduced complexity and maintaining low traffic – an agent in the guest VM learns the host VM’s IP address
latency. In addition, we have found that clients easily deal with oc- via DHCP and configures a firewall rule to allow monitoring traffic
casional connectivity disruptions by retrying connections, which only from the host. Since a VM’s host address does not change
happen for various other reasons as well. (we don’t do live VM migration), migration of a VIP from one in-
stance of Ananta to another or scaling the number of Muxes does
3.4 Host Agent not require reconfiguration inside guest VMs. We believe that these
A differentiating component of the Ananta architecture is an agent, benefits justify this design choice. Furthermore, in a fully managed
called Host Agent, which is present on the host partition of every cloud environment such as ours, out-of-band monitoring can detect
physical machine that is served by Ananta. The Host Agent is the network partitions where HA considers a VM healthy but some
key to achieving DSR and SNAT across layer-2 domains. Further- Muxes are unable to communicate with its DIPs, raise an alert and
more, the Host Agent enables data plane scale by implementing even take corrective actions.
Fastpath and NAT; and control plane scale by implementing VM
health monitoring. 3.5 Ananta Manager
The Ananta Manager (AM) implements the control plane of Ananta.
3.4.1 NAT for Inbound Connections It exposes an API to configure VIPs for load balancing and SNAT.
For load balanced connections, the Host Agent performs stateful Based on the VIP Configuration, it configures the Host Agents and
layer-4 NAT for all connections. As encapsulated packets arrive at Mux Pools and monitors for any changes in DIP health. Ananta
212Manager is also responsible for keeping track of health of Muxes the number of VMs. Furthermore, there are limits on the number of
and Hosts and taking appropriate actions. AM achieves high avail- ports allocated and rate of allocations allowed for any given VM.
ability using the Paxos [14] distributed consensus protocol. Each
instance of Ananta runs five replicas that are placed to avoid cor- 3.6.2 Packet Rate Fairness
related failures. Three replicas need to be available at any given Mux tries to ensure fairness among VIPs by allocating available
time to make forward progress. The AM uses Paxos to elect a bandwidth among all active flows. If a flow attempts to steal more
primary, which is responsible for performing all configuration and than its fair share of bandwidth, Mux starts to drop its packets with
state management tasks. We now look at some key AM functions a probability directly proportional to the excess bandwidth it is us-
in detail. ing. While bandwidth fairness works for TCP flows that are send-
ing large-sized packets, it does not work for short packets spread
3.5.1 SNAT Port Management across flows, or flows that are non-TCP (e.g., UDP) or flows that
AM also does port allocation for SNAT (§3.2.3). When an HA are malicious (e.g., a DDoS attack). A key characteristic of these
makes a new port request on behalf of a DIP, AM allocates a free flows is that they do not back off in response to packet drops, in
port for the VIP, replicates the allocation to other AM replicas, cre- fact we sometimes see the exact opposite reaction. Since dropping
ates a stateless VIP map entry mapping the port to the requesting packets at the Mux is not going to help and increases the chances
DIP, configures the entry on the Mux Pool and then sends the allo- of overload, our primary approach has been to build a robust detec-
cation to the HA. There are two main challenges in serving SNAT tion mechanism for overload due to packet rate. Each Mux keeps
requests — latency and availability. Since SNAT request is done track of its top-talkers – VIPs with the highest rate of packets. Mux
on the first packet of a connection, a delay in serving SNAT request continuously monitors its own network interfaces and once it de-
directly translates into latency seen by applications. Similarly, AM tects that there is packet drop due to overload, it informs AM about
downtime would result in failure of outbound connections for appli- the overload and the top talkers. AM then identifies the topmost
cations resulting in complete outage for some applications. Ananta top-talker as the victim of overload and withdraws that VIP from
employs a number of techniques to reduce latency and increase all Muxes, thereby creating a black hole for the VIP. This ensures
availability. First, it allocates a contiguous port range instead of that there is minimal collateral damage due to Mux overload. De-
allocating one port at a time. By using fixed sized port ranges, we pending on the policy for the VIP, we then route it through DoS
optimize storage and memory requirements on both the AM and the protection services (the details are outside the scope of this paper)
Mux. On the Mux driver, only the start port of a range is configured and enable it back on Ananta. We evaluate the effectiveness of
and by making the port range size a power of 2, we can efficiently overload detection and route withdrawal in §5.
map a range of ports to a specific DIP. Second, it preallocates a set
of port ranges to DIPs when it first receives a VIP configuration.
3.7 Design Alternatives
Third, it tries to do demand prediction and allocates multiple port
ranges in a single request. We evaluate the effectiveness of these 3.7.1 DNS-based Scale Out
techniques in §5. Ananta uses BGP to achieve scale out among multiple active in-
stances of Mux. A traditional approach to scaling out middlebox
3.6 Tenant Isolation functionality is via DNS. Each instance of the middlebox device,
e.g., load balancer, is assigned a public IP address. The author-
Ananta is a multi-tenant load balancer and hence tenant isola- itative DNS server is then used to distribute load among IP ad-
tion is an essential requirement. The goal of tenant isolation is to dresses of the instances using an algorithm like weighted round-
ensure that the Quality of Service (QoS) received by one tenant is robin. When an instance goes down, the DNS server stops giving
independent of other tenants in the system. However, Ananta is out its IP address. This approach has several limitations. First, it
an oversubscribed resource and we do not guarantee a minimum is harder to get good distribution of load because it is hard to pre-
bandwidth or latency QoS. As such, we interpret this requirement dict how much load can be generated via a single DNS resolution
as follows – the total CPU, memory and bandwidth resources are request. For example, load from large clients such as a megaproxy
divided among all tenants based on their weights. The weights are is always sent to a single server. Second, it takes longer to take
directly proportional to the number of VMs allocated to the tenant. unhealthy middlebox nodes out of rotation due to DNS caching
We make another simplifying assumption that traffic for all VIPs – many local DNS resolvers and clients violate DNS TTLs. And
is distributed equally among all Muxes, therefore, each Mux can third, it cannot be used for scale out of stateful middleboxes, such
independently implement tenant isolation. We find this assumption as a NAT.
to hold true in our environment. If this assumption were to not hold
true in the future, a global monitor could dynamically inform each 3.7.2 OpenFlow-based Load Balancing
Mux to assign different weights to different tenants. Memory fair-
An alternative to implementing Mux functionality in general-
ness is implemented at Muxes and AM by keeping track of flow
purpose servers is to use OpenFlow-capable switches [16]. How-
state and enforcing limits.
ever, currently available OpenFlow devices have insufficient sup-
port for general-purpose layer-4 load balancing. For example, ex-
3.6.1 SNAT Fairness isting OpenFlow switches only support 2000 to 4000 flows, whereas
AM is a critical resource as it handles all SNAT port requests. Mux needs to maintain state for millions of flows. Another key
Excessive requests from one tenant should not slow down the SNAT primitive lacking in existing OpenFlow hardware is tenant isola-
response time of another tenant. AM ensures this by processing re- tion. Finally, in a pure OpenFlow-based network, we will also need
quests in a first-come-first-serve (FCFS) order and it ensures that at to replace BGP with centralized routing in Ananta Manager, which
any given time there is at most one outstanding request from a DIP. has certain drawbacks as discussed in §6. Other researchers have
If a new request is received while another request from the same also attempted to build load balancers using OpenFlow switches [28],
DIP is pending, the new request is dropped. This simple mecha- however, these solutions do not yet meet all the requirements, e.g.,
nism ensures that VIPs get SNAT allocation time in proportion to tenant isolation and scalable source NAT across layer-2 domains.
213Figure 10: Staged event-driven (SEDA) Ananta Manager.
Ananta manager shares the same threadpool across multiple stages
and supports priority event queues to maintain responsiveness of
VIP configuration operations under overload.
4. IMPLEMENTATION Figure 11: CPU usage at Mux and Hosts with and without Fast-
We implemented all three Ananta components from Figure 5. path. Once Fastpath is turned on, the hosts take over the encap-
Ananta Manager and Mux are deployed as a tenant of our cloud sulation function from Mux. This results in lower CPU at Mux and
platform itself. The Host Agent is deployed on every host in our CPU increase at every host doing encapsulation.
cloud and is updated whenever we update the Ananta tenant. In a
typical deployment five replicas of AM manage a single Mux Pool.
Most Mux Pools have eight Muxes in them but the number can be in its VIP Map with 1GB of memory. Each mux can maintain state
based on load. for millions of connections and is only limited by available mem-
Ananta Manager: AM performs various time-critical tasks — ory on the server. CPU performance characteristics of the Mux are
configuration of VIPs, allocation of ports, coordination of DIP health discussed in §5.2.3.
across Muxes. Therefore, its responsiveness is very critical. To Host Agent: The Host Agent also has a driver component that
achieve a high degree of concurrency, we implemented AM using runs as an extension of the Windows Hyper-V hypervisor’s virtual
a lock-free architecture that is somewhat similar to SEDA [29]. As switch. Being in the hypervisor enables us to support unmodified
shown in Figure 10, AM is divided into the following stages — VIP VMs running different operating systems. For tenants running with
validation, VIP configuration, Route Management, SNAT Man- native (non-VM) configuration, we run a stripped-down version of
agement, Host Agent Management and Mux Pool Management. the virtual switch inside the host networking stack. This enables us
Ananta implementation makes two key enhancements to SEDA. to reuse the same codebase for both native and VM scenarios.
First, in Ananta, multiple stages share the same threadpool. This Upgrading Ananta: Upgrading Ananta is a complex process
allows us to limit the total number of threads used by the system. that takes place in three phases in order to maintain backwards-
Second, Ananta supports multiple priority queues for each stage. compatibility between various components. First, we update in-
This is useful in maintaining responsiveness during overload con- stances of the Ananta Manager, one at a time. During this phase,
ditions. For example, SNAT events take less priority over VIP con- AM also adapts its persistent state from previous schema version
figuration events. This allows Ananta to finish VIP configuration to the new version. Schema rollback is currently not supported.
tasks even when it is under heavy load due to SNAT requests. Second, we upgrade the Muxes; and third, the Host Agents.
Ananta maintains high availability using Paxos [14]. We took an
existing implementation of Paxos and added discovery and health 5. MEASUREMENTS
monitoring using the SDK of our cloud platform. The SDK notifies In this section we first present a few micro-benchmarks to evalu-
AM of addition, removal or migration of any replicas of the Paxos ate effectiveness and limitations of some of our design choices and
cluster. This allows us to automatically reconfigure the cluster as implementation, and then some data from real world deployments.
instances are added or removed dynamically. These features of the
platform SDK result in significantly reduced operational overhead 5.1 Micro-benchmarks
for Ananta. The platform also provides a guarantee that no more
than one instance of the AM role is brought down for OS or applica- 5.1.1 Fastpath
tion upgrade. This notion of instance-by-instance update maintains To measure the effectiveness of Fastpath and its impact on host
availability during upgrades. Ananta uses Paxos to elect a primary CPU, we conducted the following experiment. We deployed a 20
and only the primary does all the work. VM tenant as the server and two 10 VM tenants as clients. All
Mux: Mux has two main components — a kernel-mode driver the client VMs create up to ten connections to the server and up-
and a user-mode BGP [20] speaker. The kernel-mode driver is im- load 1MB of data per connection. We recorded the CPU usage at
plemented using the Windows Filtering Platform (WFP) [30] driver the host nodes and one Mux. The results are shown in Figure 11.
model. The driver intercepts packets at the IP layer, encapsulates We found the host CPU usage to be uniform across all hosts, so
and then sends them using the built-in forwarding function of the we only show median CPU observed at a representative host. As
OS. Delegating routing to the OS stack has allowed Mux code expected, as soon as Fastpath is turned on, no new data transfers
to remain simple, especially when adding support for IPv6, as it happen through the Mux. It only handles the first two packets of
does not need to deal with IP fragmentation and next-hop selec- any new connection. Once the Mux is out of the way, it also stops
tion. The driver scales to multiple cores using receive side scaling being a bottleneck for data transfer and VMs can exchange data at
(RSS) [22]. Since the Mux driver only encapsulates the packet with the speed allowed by the underlying network.
a new IP header and leaves the inner IP header and its payload in-
tact, it does not need to recalculate TCP checksum and hence it does 5.1.2 Tenant Isolation
not need any sender-side NIC offloads. For IPv4, each Mux can Tenant isolation is a fundamental requirement of any multi-tenant
hold 20,000 load balanced endpoints and 1.6 million SNAT ports service. In the following we present two different experiments
214Figure 12: SYN-flood Attack Mitigation. Duration of impact
shows the time Ananta takes to detect and black-hole traffic to the Figure 13: Impact of heavy SNAT user H on a normal user
victim VIP on all Muxes. N. Heavy user H sees higher latency and higher SYN retransmits.
Normal user N’s performance remains unchanged.
that show Ananta’s ability to isolate inbound packet and outbound
SNAT abuse. For these experiments, we deployed five different
tenants, each with ten virtual machines, on Ananta.
SYN-flood Isolation: To measure how quickly Ananta can iso-
late a VIP under a SYN-flood attack, we ran the following experi-
ment (other packet rate based attacks, such as a UDP-flood, would
show similar result.) We load Ananta Muxes with a baseline load
and launch a SYN-flood attack using spoofed source IP addresses
on one of the VIPs. We then measure if there is any connection
loss observed by clients of the other tenants. Figure 12 shows the
maximum duration of impact observed over ten trials. As seen in
the chart, Mux can detect and isolate an abusive VIP within 120
seconds when it is running under no load, minimum time being 20
seconds. However, under moderate to heavy load it takes longer to
detect an attack as it gets harder to distinguish between legitimate Figure 14: Connection establishment time experienced by out-
and attack traffic. We are working on improving our DoS detection bound connections with and without port demand prediction.
algorithms to overcome this limitation.
SNAT Performance Isolation: SNAT port allocation at Ananta
Manager could be a subject of abuse by some tenants. It is possi- data is partitioned into buckets of 25ms. The minimum connection
ble that a tenant makes a lot of SNAT connections causing impact establishment time to the remote service (without SNAT) is 75ms.
on other tenants. To measure the effectiveness of per-VM SNAT Figure 14 shows connection establishment times for the following
isolation at AM, we conducted the following experiment. A set of two optimizations when there is no other load on the system.
normal use tenants (N) make outbound connections at a steady rate Single Port Range: In response to a port request, AM allocates
of 150 connections per minute. Whereas, a heavy SNAT user (H) eight contiguous ports instead of a single port and returns them to
keeps increasing its SNAT requests. We measure the rate of SYN the requesting HA. HA uses these ports for any pending and sub-
retransmits and the SNAT response time of Ananta at the corre- sequent connections. The HA keeps any unused ports until a pre-
sponding HAs. Figure 13 shows the aggregate results over multiple configured timeout before returning them to AM. By doing this
trials. As seen in the figure, the normal tenants’ connections keep optimization, only one in every eight outbound connections ever
succeeding at a steady rate without any SYN loss; and its SNAT results in a request to AM. This is evident from Figure 14 — 88%
port requests are satisfied within 55ms. The heavy user, on the connections succeed in the minimum possible time of 75ms. The
other hand, starts to see SYN retransmits because Ananta delays its remaining 12% connections take longer due to the round-trip to
SNAT requests in favor of N. This shows that Ananta rewards good AM. Without the port range optimization every new connection re-
behavior by providing faster SNAT response time. quest that cannot be satisfied using existing already allocated ports
will make a round-trip to AM.
5.1.3 SNAT Optimizations Demand Prediction: When this optimization is turned on, AM
A key design choice Ananta made is to allocate SNAT ports in attempts to predict port demand of a DIP based on its recent his-
AM and then replicate the port allocations to all Muxes and other tory. If a DIP requests new ports within a specified interval from
AM replicas to enable scale out and high availability respectively. its previous requests, AM allocates and returns multiple eight-port
Since port allocation takes place for the first packet of a connec- port ranges instead of just one. As shown in Figure 14, with this op-
tion, it can add significant latency to short connections. Ananta timization 96% of connections are satisfied locally and don’t need
overcomes these limitations by implementing three optimizations to make a round-trip to AM. Furthermore, since AM handles fewer
as mentioned in §3.5.1. To measure the impact of these optimiza- requests, its response time is also better than allocating a single port
tions we conducted the following experiment. A client continu- range for each request.
ously makes outbound TCP connections via SNAT to a remote ser-
vice and records the connection establishment time. The resulting
215Figure 15: CDF of SNAT response latency for the 1% requests
handled by Ananta Manager. Figure 17: Distribution of VIP configuration time over a 24-hr
period.
over this period across all test tenants was 99.95%, with a mini-
mum of 99.92% for one tenant and greater than 99.99% for two
tenants. Five of the low availability conditions between Jan 21 and
Jan 26 happened due to Mux overload. The Mux overload events
were primarily caused by SYN-flood attacks on some tenants that
are not protected by our DoS protection service. Two availability
drops were due to wide-area network issues while the rest were
false positives due to update of the test tenants.
5.2.3 Scale
For control plane, Ananta ensures that VIP configuration tasks
are not blocked behind other tasks. In a public cloud environ-
Figure 16: Availability of test tenants in seven different data
ment, VIP configuration tasks happen at a rapid rate as customers
centers over one month.
add, delete or scale their services. Therefore, VIP configuration
time is an important metric. Since Ananta needs to configure HAs
5.2 Real World Data and Muxes during each VIP configuration change, its programming
time could be delayed due to slow HAs or Muxes. Figure 17 shows
Several instances of Ananta have been deployed in a large pub-
the distribution of time taken by seven instances Ananta to com-
lic cloud with a combined capacity exceeding 1Tbps. It has been
plete VIP configuration tasks over a 24-hr period. The median con-
serving Internet and intra-data center traffic needs of very diverse
figuration time was 75ms, while the maximum was 200seconds.
set of tenants, including blob, table and queue storage services for
These time vary based on the size of the tenant and the current
over two years. Here we look at some data from real world.
health of Muxes. These times fit within our API SLA for VIP con-
5.2.1 SNAT Response Latency figuration tasks.
For data plane scale, Ananta relies on ECMP at the routers to
Based on production data, Ananta serves 99% of the SNAT re-
spread load across Muxes and RSS at the NIC to spread load across
quests locally by leveraging port reuse and SNAT preallocation as
multiple CPU cores. This design implies that the total upload through-
described above. The remaining requests for tenants initiating a lot
put achieved by a single flow is limited by what the Mux can achieve
of outbound requests to a few remote destinations require SNAT
using a single CPU core. On our current production hardware, the
port allocation to happen at the AM. Figure 15 shows the distribu-
Mux can achieve 800Mbps throughput and 220Kpps using a sin-
tion of latency incurred for SNAT port allocation over a 24 hour
gle x64, 2.4GHz core. However, Muxes can achieve much higher
window in a production data center for the requests that go to AM.
aggregate throughput across multiple flows. In our production de-
10% of the responses are within 50ms, 70% within 200ms and 99%
ployment, we have been able to achieve more than 100Gbps sus-
within 2 seconds. This implies that in the worst case, one in every
tained upload throughput for a single VIP. Figure 18 shows band-
10000 connections suffers a SYN latency of 2 seconds or higher;
width and CPU usage seen over a typical 24-hr period by 14 Muxes
however, very few scenarios require that number of connections to
deployed in one instance of Ananta. Here each Mux is running on
the same destination.
a 12-core 2.4Ghz intel R Xeon CPU. This instance of Ananta is
5.2.2 Availability serving 12 VIPs for blob and table storage service. As seen in the
figure, ECMP is load balancing flows quite evenly across Muxes.
As part of ongoing monitoring for our cloud platform, we have
Each Mux is able to achieve 2.4Gbps throughput (for a total of
multiple test tenants deployed in each data center. A monitoring
33.6Gbps) using about 25% of its total processing power.
service connects to the VIP of every test tenant from multiple geo-
graphic locations and fetches a web page once every five minutes.
Figure 16 shows average availability of test tenants in seven dif- 6. OPERATIONAL EXPERIENCE
ferent data centers. If the availability was less than 100% for any We have been offering layer-4 load balancing as part of our cloud
five minute interval, it makes up a point in the above graph. All platform for the last three years. The inability of hardware load bal-
the other intervals had 100% availability. The average availability ancers to deal with DoS attacks, network elasticity needs, the grow-
216Figure 18: Bandwidth and CPU usage over a 24-hr period for 14 Muxes in one instance of Ananta.
ing bandwidth requirements and increasing price pressure made One design decision that has been a subject of many debates is
us finally give up on hardware load balancers. Having our own collocation of data plane and its control via BGP on Mux. An al-
software-based load balancer has not been without any issues ei- ternative design would be to host BGP in a separate service and
ther, however, we have been able to troubleshoot and fix those is- control it from AM. Collocation works better for hard failures as
sues much faster – in days instead of weeks or months. Here we routers quickly take an unhealthy Mux out of rotation due to BGP
look at some of those issues. timeout. However, when incoming packet rate exceeds the process-
Ananta Manager uses Paxos to elect a primary replica that does ing capacity of a Mux, the BGP traffic gets affected along with data
all the work. During the initial stages of Ananta, we assumed traffic. This causes the Mux to lose BGP connection to the router
that there can never be two replicas claiming to be primary at the and that traffic shifts to another Mux, which in turn gets overloaded
same time. However, we encountered issues where this assumption and goes down, and so on. This cascading failure can bring down
was not true. This happens due to old hard disks where the disk all the Muxes in a cluster. There are multiple ways to address this
controller would freeze for two minutes or longer on the primary limitation. One solution is to use two different network interfaces
replica. During this freeze, the secondary replicas would conclude – one for control plane and the other for data plane. Another solu-
that the primary is down and elect a new primary. But once the disk tion is to rate limit data traffic at the router so that there is always
controller on the old primary becomes responsive again, it contin- sufficient headroom for control traffic. The same mechanisms will
ues to do work assuming it is still the primary for a short period be required to separate control traffic from data traffic even if BGP
of time. This resulted in customers facing outages because all the was hosted in a separate service. Overall, we found that collocation
host agents would continue to send health reports to the old primary leads to a simpler design in this case.
while Muxes would only accept commands from the new primary. One of the issues with using hardware load balancers was that
We fixed this issue by having the primary perform a Paxos write we had to set an aggressive idle connection timeout ( 60 seconds),
transaction whenever a Mux rejected its commands. This change otherwise legitimate connections were getting dropped under heavy
resulted in the old primary detecting its stale status as soon as it load, e.g., under connection state-based attacks. In the initial ver-
would try to take any action. sions of Ananta, we kept the same aggressive idle timeout. How-
We made an explicit design choice to use encapsulation to deliver ever, with the increase in the number of low-power, battery-operated
packets between the Muxes and hosts so that Muxes could load bal- mobile devices, there was a need to keep connections open for a
ance across layer-2 domains. This lowers the effective MTU avail- long time even where there is no active traffic. For example, a
able for transport layer payload. In order to avoid fragmentation phone notification service needs to push data immediately to such
of packets at the Mux, which incurs high CPU overhead, Ananta devices without requiring them to send frequent keep-alive mes-
Host Agents adjust the MSS value exchanged as part of TCP con- sages. We were able to increase idle timeout in Ananta because it
nection establishment to a lower value – 1440 from 1460 for IPv4. keeps the NAT state on the hosts and, under overload, the Muxes
This technique worked perfectly fine for almost two years and then can continue forwarding traffic using the VIP map (§3.3) without
we suddenly started seeing connection errors because clients were creating new per-connection state. This makes Ananta significantly
sending full-sized packets (1460 byte payload) with IP Don’t Frag- less vulnerable to connection state-based attacks.
ment (DF) bit set. After encapsulation at the Muxes the ethernet
frame size (1520) exceeded network MTU of 1500, resulting in
packet drops. This started to happen because of two external bugs. 7. RELATED WORK
A specific brand of home routers has a bug in that it always over- To the best of our knowledge, Ananta takes a new approach to
writes the TCP MSS value to be 1460. Therefore, clients never see building layer-4 distributed load balancer and NAT that meets the
the adjusted MSS. Normally this is fine because clients are sup- requirements of a multi-tenant cloud environment. In this section
posed to retry lost full-sized TCP segments by sending smaller- we compare it to the state-of-the-art in industry and research. We
sized segments. However, there was a bug in the TCP implementa- recognize that many existing solutions provide more than layer-4
tion of a popular mobile operating system in that TCP retries used load balancing and their design choices may have been influenced
the same full-sized segments. Since we control our entire network, by those additional features. Ananta’s modular approach can be
we increased the MTU on our network to a higher value so that it used to build application-layer functionality, such as layer-7 load
can accommodate encapsulated packets without fragmentation. balancing, on top of the base layer-4 functionality.
Traditional hardware load balancers (e.g., [9, 1]) have a scale
217You can also read

















































