AttentionGAN: Unpaired Image-to-Image Translation using Attention-Guided Generative Adversarial Networks
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

PREPRINT - WORK IN PROGRESS 1
AttentionGAN: Unpaired Image-to-Image Translation using
Attention-Guided Generative Adversarial Networks
Hao Tang, Hong Liu, Dan Xu, Philip H.S. Torr and Nicu Sebe
State-of-the-art methods in image-to-image translation are capable of learning a mapping from a source domain to a target
domain with unpaired image data. Though the existing methods have achieved promising results, they still produce visual artifacts,
being able to translate low-level information but not high-level semantics of input images. One possible reason is that generators do
not have the ability to perceive the most discriminative parts between the source and target domains, thus making the generated
images low quality. In this paper, we propose a new Attention-Guided Generative Adversarial Networks (AttentionGAN) for the
unpaired image-to-image translation task. AttentionGAN can identify the most discriminative foreground objects and minimize the
change of the background. The attention-guided generators in AttentionGAN are able to produce attention masks, and then fuse the
arXiv:1911.11897v4 [cs.CV] 12 Feb 2020
generation output with the attention masks to obtain high-quality target images. Accordingly, we also design a novel attention-guided
discriminator which only considers attended regions. Extensive experiments are conducted on several generative tasks with 8 public
datasets, demonstrating that the proposed method is effective to generate sharper and more realistic images compared with existing
competitive models. The code is available at https://github.com/Ha0Tang/AttentionGAN.
Index Terms—GANs, Unpaired Image-to-Image Translation, Attention
I. I NTRODUCTION
Recently, Generative Adversarial Networks (GANs) [1] in
various fields such as computer vision and image processing
have produced powerful translation systems with supervised
settings such as Pix2pix [2], where paired training images
are required. However, paired data are usually difficult or
expensive to obtain. The input-output pairs for tasks such
as artistic stylization could be even more difficult to acquire
since the desired output is quite complex, typically requiring
artistic authoring. To tackle this problem, CycleGAN [3],
DualGAN [4] and DiscoGAN [5] provide a new insight, in
which the GAN models can learn the mapping from a source
domain to a target one with unpaired image data.
Despite these efforts, unpaired image-to-image translation, Fig. 1: Comparison with existing image-to-image translation
remains a challenging problem. Most existing models change methods (e.g., CycleGAN [3] and GANimorph [6]) with an
unwanted parts in the translation, and can also be easily example of horse to zebra translation. We are interest in trans-
affected by background changes (see Fig. 1). In order to ad- forming horses to zebras. In this case we should be agnostic
dress these limitations, Liang et al. propose ContrastGAN [7], to the background. However methods such as CycleGAN and
which uses object-mask annotations provided by the dataset GANimorph will transform the background in a nonsensical
to guide the generation, first cropping the unwanted parts way, in contrast to our attention-based method.
in the image based on the masks, and then pasting them
back after the translation. While the generated results are works (AttentionGAN) for unpaired image-to-image transla-
reasonable, it is hard to collect training data with object- tion tasks. Fig. 1 shows a comparison with exiting image-to-
mask annotations. Another option is to train an extra model to image translation methods using a horse to zebra translation
detect the object masks and then employ them for the mask- example. The most important advantage of AttentionGAN is
guided generation [8], [9]. In this case, we need to significantly that the proposed generators can focus on the foreground of
increase the network capacity, which consequently raises the the target domain and preserve the background of the source
training complexity in both time and space. domain effectively.
To overcome the aforementioned issues, in this paper we Specifically, the proposed generator learns both foreground
propose a novel Attention-Guided Generative Adversarial Net- and background attentions. It uses the foreground attention to
select from the generated output for the foreground regions,
Hao Tang and Nicu Sebe are with the Department of Information Engineer-
ing and Computer Science (DISI), University of Trento, Trento 38123, Italy. while uses the background attention to maintain the back-
E-mail: hao.tang@unitn.it. ground information from the input image. In this way, the
Hong Liu is with the Shenzhen Graduate School, Peking University, proposed AttentionGAN can focus on the most discriminative
Shenzhen 518055, China.
Dan Xu and Philip H.S. Torr are with the Department of Engineering foreground and ignore the unwanted background. We observe
Science, University of Oxford, Oxford OX1 3PJ, United Kingdom. that AttentionGAN achieves significantly better results than
PREPRINT - WORK IN PROGRESS 2
Fig. 2: Framework of the proposed attention-guided generation scheme I, which contains two attention-guided generators
G and F . We show one mapping in this figure, i.e., x→G(x)→F (G(x))≈x. We also have the other mapping, i.e.,
y→F (y)→G(F (y))≈y. The attention-guided generators have a built-in attention module, which can perceive the most
discriminative content between the source and target domains. We fuse the input image, the content mask and the attention
mask to synthesize the final result.
both GANimorph [6] and CycleGAN [3]. As shown in Fig. 1, space. The intermediate content masks are then fused with
AttentionGAN not only produces clearer results, but also the foreground attention masks to produce the final content
successfully maintains the little boy in the background and masks. Extensive experiments on several challenging public
only performs the translation for the horse behind it. However, benchmarks demonstrate that the proposed scheme II can
the existing holistic image-to-image translation approaches are produce higher-quality target images compared with existing
generally interfered by irrelevant background content, thus state-of-the-art methods.
hallucinating texture patterns of the target objects. The contribution of this paper is summarized as follows:
We propose two different attention-guided generation • We propose a new Attention-Guided Generative Adversar-
schemes for the proposed AttentionGAN. The framework of ial Network (AttentionGAN) for unpaired image-to-image
the proposed scheme I is shown in Fig. 2. The proposed translation. This framework stabilizes the GANs training
generator is equipped with a built-in attention module, which and thus improves the quality of generated images through
can disentangle the discriminative semantic objects from the jointly approximating attention and content masks with
unwanted parts via producing an attention mask and a content several losses and optimization methods.
mask. Then we fuse the attention and the content masks • We design two novel attention-guided generation schemes
to obtain the final generation. Moreover, we design a novel for the proposed framework, to better perceive and generate
attention-guided discriminator which aims to consider only the the most discriminative foreground parts and simultaneously
attended foreground regions. The proposed attention-guided preserve well the unfocused objects and background. More-
generator and discriminator are trained in an end-to-end fash- over, the proposed attention-guided generator and discrim-
ion. The proposed attention-guided generation scheme I can inator can be flexibly applied in other GANs to improve
achieve promising results on the facial expression translation multi-domain image-to-image translation tasks, which we
as shown in Fig. 5, where the change between the source believe would also be beneficial to other related research.
domain and the target domain is relatively minor. However, • Extensive experiments are conducted on 8 publicly available
it performs unsatisfactorily on more challenging scenarios in datasets and results show that the proposed AttentionGAN
which more complex semantic translation is required, such model can generate photo-realistic images with more clear
as horse to zebra translation and apple to orange translation details compared with existing methods. We also established
shown in Fig. 1. To tackle this issue, we further propose a new state-of-the-art results on these datasets.
more advanced attention-guided generation scheme, i.e. the
scheme II, as depicted in Fig. 3. The improvement upon
II. R ELATED W ORK
the scheme I is mainly three-fold: first, in the scheme I
the attention mask and the content mask are generated with Generative Adversarial Networks (GANs) [1] are powerful
the same network. To have a more powerful generation of generative models, which have achieved impressive results on
them, we employ two separate sub-networks in the scheme II; different computer vision tasks, e.g., image generation [10],
Second, in the scheme I we only generate the foreground [11]. To generate meaningful images that meet user require-
attention mask to focus on the most discriminative semantic ments, Conditional GANs (CGANs) [12] inject extra infor-
content. However, in order to better learn the foreground and mation to guide the image generation process, which can be
preserve the background simultaneously, we produce both discrete labels [13], [14], object keypoints [15], human skele-
foreground and background attention masks in scheme II; ton [16], semantic maps [17], [18] and reference images [2].
Third, as the foreground generation is more complex, instead Image-to-Image Translation models learn a translation func-
of learning a single content mask in the scheme I, we learn a tion using CNNs. Pix2pix [2] is a conditional framework using
set of several intermediate content masks, and correspondingly a CGAN to learn a mapping function from input to output im-
we also learn the same number of foreground attention masks. ages. Wang et al. propose Pix2pixHD [17] for high-resolution
The generation of multiple intermediate content masks is photo-realistic image-to-image translation, which can be used
beneficial for the network to learn a more rich generation for turning semantic label maps into photo-realistic images.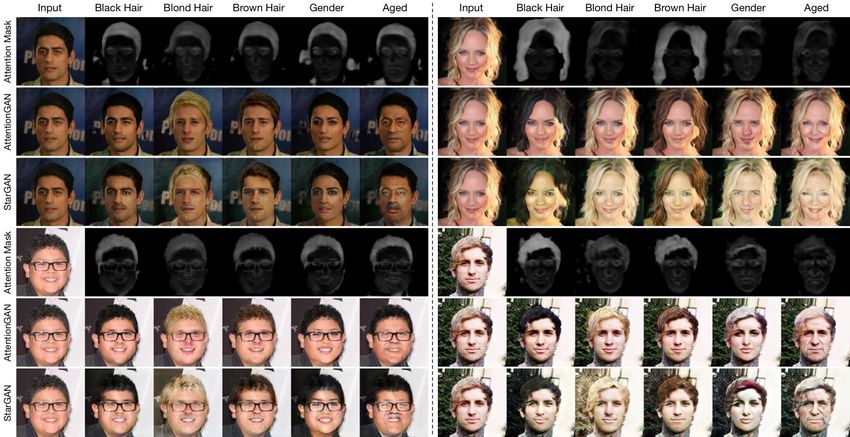
PREPRINT - WORK IN PROGRESS 3
Similar ideas have also been applied to many other tasks, avoiding undesired artifacts or changes. Most importantly, the
such as hand gesture generation [16]. However, most of the proposed methods can be applied to any GAN-based frame-
tasks in the real world suffer from having few or none of the work such as unpaired [3], paired [2] and multi-domain [14]
paired input-output samples available. When paired training image-to-image translation frameworks.
data is not accessible, image-to-image translation becomes an
ill-posed problem. III. ATTENTION -G UIDED GAN S
Unpaired Image-to-Image Translation. To overcome this We first start with the attention-guided generator and dis-
limitation, the unpaired image-to-image translation task has criminator of the proposed AttentionGAN, and then introduce
been proposed. In this task, the approaches learn the mapping the loss function for better optimization of the model. Finally,
function without the requirement of paired training data. we present the implementation details including network ar-
Specifically, CycleGAN [3] learns the mappings between two chitecture and training procedure.
image domains instead of the paired images. Apart from
CycleGAN, many other GAN variants [5], [4], [19], [20],
[21], [14], [22] have been proposed to tackle the cross-domain A. Attention-Guided Generation
problem. However, those models can be easily affected by GANs [1] are composed of two competing modules: the
unwanted content and cannot focus on the most discriminative generator G and the discriminator D, which are iteratively
semantic part of images during the translation stage. trained competing against with each other in the manner of
Attention-Guided Image-to-Image Translation. To fix the two-player mini-max. More formally, let X and Y denote two
aforementioned limitations, several works employ an attention different image domains, xi ∈X and yj ∈Y denote the training
mechanism to help image translation. Attention mechanisms images in X and Y , respectively (for simplicity, we usually
have been successfully introduced in many applications in omit the subscript i and j). For most current image translation
computer vision such as depth estimation [23], helping the models, e.g., CycleGAN [3] and DualGAN [4], they include
models to focus on the relevant portion of the input. two generators G and F , and two corresponding adversarial
Recent works use attention modules to attend to the region discriminators DX and DY . Generator G maps x from the
of interest for the image translation task in an unsupervised source domain to the generated image G(x) in the target
way, which can be divided into two categories. The first domain Y and tries to fool the discriminator DY , whilst DY
category is to use extra data to provide attention. For instance, focuses on improving itself in order to be able to tell whether
Liang et al. propose ContrastGAN [7], which uses the object a sample is a generated sample or a real data sample. Similar
mask annotations from each dataset as extra input data. Sun et to generator F and discriminator DX .
al. [24] generate a facial mask by using FCN for face attribute Attention-Guided Generation Scheme I. For the pro-
manipulation. Moreover, Mo et al. propose InstaGAN [25] that posed AttentionGAN, we intend to learn two mappings be-
incorporates the instance information (e.g., object segmenta- tween domains X and Y via two generators with built-
tion masks) and improves multi-instance transfiguration. in attention mechanism, i.e., G:x→[Ay , Cy ]→G(x) and
The second type is to train another segmentation or attention F :y→[Ax , Cx ]→F (y), where Ax and Ay are the attention
model to generate attention maps and fit it to the system. For masks of images x and y, respectively; Cx and Cy are the
example, Chen et al. [8] use an extra attention network to content masks of images x and y, respectively; G(x) and F (y)
generate attention maps, so that more attention can be paid are the generated images. The attention masks Ax and Ay
to objects of interests. Kastaniotis et al. present ATAGAN [9], define a per pixel intensity specifying to which extent each
which uses a teacher network to produce attention maps. Yang pixel of the content masks Cx and Cy will contribute in the
et al. [26] propose to add an attention module to predict an final rendered image. In this way, the generator does not need
attention map to guide the image translation process. Zhang to render static elements (basically it refers to background),
et al. propose SAGAN [27] for image generation task. Kim et and can focus exclusively on the pixels defining the domain
al. [28] propose to use an auxiliary classifier to generate atten- content movements, leading to sharper and more realistic syn-
tion masks. Mejjati et al. [29] propose attention mechanisms thetic images. After that, we fuse input image x, the generated
that are jointly trained with the generators, discriminators and attention mask Ay and the content mask Cy to obtain the
other two attention networks. targeted image G(x). In this way, we can disentangle the most
All these methods employ extra networks or data to obtain discriminative semantic object and unwanted part of images.
attention masks, which increases the number of parameters, Take Fig. 2 for example, the attention-guided generators focus
training time and storage space of the whole system. More- only on those regions of the image that are responsible of
over, we still observe unsatisfactory aspects in the generated generating the novel expression such as eyes and mouth, and
images by these methods. To fix both limitations, in this work keep the rest of parts of the image such as hair, glasses, clothes
we propose a novel Attention-Guided Generative Adversarial untouched. The higher intensity in the attention mask means
Networks (AttentionGAN), which can produce attention masks the larger contribution for changing the expression.
by the generators. For this purpose, we embed an attention The input of each generator is a three-channel image,
method to the vanilla generator meaning that we do not need and the outputs of each generator are an attention mask
any extra models to obtain the attention masks of objects and a content mask. Specifically, the input image of gen-
of interests. AttentionGAN learns to attend to key parts of erator G is x∈RH×W ×3 , and the outputs are the attention
the image while keeping everything else unaltered, essentially mask Ay ∈{0, ..., 1}H×W and content mask Cy ∈RH×W ×3 .
PREPRINT - WORK IN PROGRESS 4
Fig. 3: Framework of the proposed attention-guided generation scheme II, which contains two attention-guided generators
G and F . We show one mapping in this figure, i.e., x→G(x)→F (G(x))≈x. We also have the other mapping, i.e.,
y→F (y)→G(F (y))≈y. Each generator such as G consists of a parameter-sharing encoder GE , an attention mask generator
GA and a content mask generator GC . GA aims to produce attention masks of both foreground and background to attentively
select the useful content from the corresponding content masks generated by GC . The proposed model is constrained by
the cycle-consistency loss and trained in an end-to-end fashion. The symbols ⊕, ⊗ and s denote element-wise addition,
element-wise multiplication and channel-wise Softmax, respectively.
Thus, we use the following formula to calculate the final solve these limitations, we further propose a more advanced
image G(x), attention-guided generation scheme II as shown in Fig. 3.
Attention-Guided Generation Scheme II. Scheme I adopts
G(x) = Cy ∗ Ay + x ∗ (1 − Ay ), (1)
the same network to produce both attention and content
masks and we argue that this will degrade the generation
where the attention mask Ay is copied to three channels
performance. In scheme II, the proposed generators G and
for multiplication purpose. Intuitively, the attention mask Ay
F are composed of two sub-nets each for generating attention
enables some specific areas where domain changed to get more
masks and content masks as shown in Fig. 3. For instance, G
focus and applying it to the content mask Cy can generate
is comprised of a parameter-sharing encoder GE , an attention
images with clear dynamic area and unclear static area. The
mask generator GA and a content mask generator GC . GE
static area should be similar between the generated image and
aims at extracting both low-level and high-level deep feature
the original real image. Thus, we can enhance the static area
representations. GC targets to produce multiple intermediate
in the original real image (1−Ay ) ∗ x and merge it to Cy ∗Ay
content masks. GA tries to generate multiple attention masks.
to obtain final result Cy ∗Ay + x∗(1−Ay ). The formulation
In the way, both attention mask generation and content mask
for generator F and input image y can be expressed as
generation have their own network parameters and will not
F (y)=Cx ∗ Ax +y ∗ (1−Ax ).
interfere with each other.
Limitations. The proposed attention-guided generation
scheme I performs well on the tasks where the source domain To fix the limitation (ii) of the scheme I, in scheme II the
and the target domain have large overlap similarity such as attention mask generator GA targets to generate both n−1
the facial expression-to-expression translation task. However, foreground attention masks {Afy }n−1 f =1 and one background
we observe that it cannot generate photo-realistic images on attention mask Aby . By doing so, the proposed network can
complex tasks such as horse to zebra translation, as shown in simultaneously learn the novel foreground and preserve the
Fig. 5. The drawbacks of the scheme I are three-fold: (i) The background of input images. The key point success of the
attention and the content mask are generated by the same proposed scheme II are the generation of both foreground and
network, which could degrade the quality of the generated background attention masks, which allow the model to modify
images; (ii) We observe that the scheme I only produces the foreground and simultaneously preserve the background of
one attention mask to simultaneously change the foreground input images. This is exactly the goal that unpaired image-to-
and preserve the background of the input images; (iii) We image translation tasks aim to optimize.
observe that scheme I only produces one content mask to Moreover, we observe that in some generation tasks such
select useful content for generating the foreground content, as horse to zebra translation, the foreground generation is
which means the model dose not have enough ability to deal very difficult if we only produce one content mask as did
with complex tasks such as horse to zebra translation. To in scheme I. To fix this limitation, we use the content mask
PREPRINT - WORK IN PROGRESS 5
generator GC to produce n−1 content masks, i.e., {Cyf }n−1
f =1 . using G(F (y))=Cy ∗ Ay +F (y) ∗ (1−Ay ), and the recovered
Then with the input image x, we obtain n intermediate content image G(F (y)) should be very close to y.
masks. In this way, a 3-channel generation space can be Attention-Guided Generation Cycle II. For the proposed
enlarged to a 3n-channel generation space, which is suitable attention-guided generation scheme II, after generating the
for learning a good mapping for complex image-to-image result G(x) by generator G in Eq. (2), we should push back
translation. G(x) to the original domain to reduce the space of possible
Finally, the attention masks are multiplied by the cor- mapping. Thus we have another generator F , which is very
responding content masks to obtain the final target result. different from the one in the scheme I. F has a similar
Formally, this is written as: structure to the generator G and also consists of three sub-
n−1
X nets, i.e., a parameter-sharing encoder FE , an attention mask
G(x) = (Cyf ∗ Afy ) + x ∗ Aby , (2) generator FA and a content mask generator FC (see Fig. 3).
f =1 FC tries to generate n−1 content masks (i.e., {Cxf }n−1f =1 ) and
where n attention masks [{Afy }n−1 b FA tries to generate n attention masks of both background and
f =1 , Ay ] are produced by a
channel-wise Softmax activation function for the normaliza- foreground (i.e., Abx and {Afx }n−1
f =1 ). Then we fuse both masks
tion. In this way, we can preserve the background of the input and the generated image G(x) to reconstruct the original input
image x, i.e., x∗Aby , and simultaneously generate the novel image x and this process can be formulated as,
Pn−1 n−1
foreground content for the input image, i.e., f =1 (Cyf ∗Afy ). X
Pn−1 F (G(x)) = (Cxf ∗ Afx ) + G(x) ∗ Abx , (5)
Next, we merge the generate foreground f =1 (Cyf ∗Afy ) to the f =1
background of the input image x∗Aby to obtain the final result
where the reconstructed image F (G(x)) should be very close
G(x). The formulation P of generator F and input image y can
n−1
be expressed as F (y)= f =1 (Cxf ∗ Afx ) + y ∗ Abx , where n at- Pn−1one x. For image y, we have the cycle
to the original
G(F (y))= f =1 (Cyf ∗ Afy ) + F (y) ∗ Aby , and the recovered
tention masks [{Afx }n−1 b
f =1 , Ax ] are also produced by a channel- image G(F (y)) should be very close to y.
wise Softmax activation function for the normalization.
C. Attention-Guided Discriminator
B. Attention-Guided Cycle Eq. (1) constrains the generators to act only on the attended
To further regularize the mappings, CycleGAN [3] adopts regions. However, the discriminators currently consider the
two cycles in the generation process. The motivation of the whole image. More specifically, the vanilla discriminator DY
cycle-consistency is that if we translate from one domain takes the generated image G(x) or the real image y as input
to the other and back again we should arrive at where we and tries to distinguish them, this adversarial loss can be
started. Specifically, for each image x in domain X, the formulated as follows:
image translation cycle should be able to bring x back to the LGAN (G, DY ) =Ey∼pdata (y) [log DY (y)]
original one, i.e, x→G(x)→F (G(x))≈x. Similarly, for image (6)
+Ex∼pdata (x) [log(1 − DY (G(x)))].
y, we have another cycle, i.e, y→F (y)→G(F (y))≈y. These
behaviors can be achieved by using a cycle-consistency loss: G tries to minimize the adversarial loss objective
LGAN (G, DY ) while DY tries to maximize it. The target
Lcycle (G, F ) =Ex∼pdata (x) [kF (G(x)) − xk1 ] of G is to generate an image G(x) that looks similar to
(3)
+Ey∼pdata (y) [kG(F (y)) − yk1 ], the images from domain Y , while DY aims to distinguish
where the reconstructed image F (G(x)) is closely matched between the generated images G(x) and the real images
to the input image x, and is similar to the generated image y. A similar adversarial loss of Eq. (6) for generator F
G(F (y)) and the input image y. This could lead to generators and its discriminator DX is defined as LGAN (F, DX ) =
to further reduce the space of possible mappings. Ex∼pdata (x) [log DX (x)]+Ey∼pdata (y) [log(1−DX (F (y)))],
We also adopt the cycle-consistency loss in the proposed where DX tries to distinguish between the generated image
attention-guided generation scheme I and II. However, we have F (y) and the real image x.
modified it for the proposed models. To add an attention mechanism to the discriminator, we
Attention-Guided Generation Cycle I. For the proposed propose two attention-guided discriminators. The attention-
attention-guided generation scheme I, we should push back guided discriminator is structurally the same as the vanilla
the generated image G(x) in Eq. (1) to the original domain. discriminator but it also takes the attention mask as input.
Thus we introduce another generator F , which has a similar The attention-guided discriminator DY A , tries to distinguish
structure to the generator G (see Fig. 2). Different from between the fake image pairs [Ay , G(x)] and the real image
CycleGAN, the proposed F tries to generate a content mask pairs [Ay , y]. Moreover, we propose the attention-guided ad-
Cx and an attention mask Ax . Therefore we fuse both masks versarial loss for training the attention-guide discriminators.
and the generated image G(x) to reconstruct the original input The min-max game between the attention-guided discriminator
image x and this process can be formulated as, DY A and the generator G is performed through the following
objective functions:
F (G(x)) = Cx ∗ Ax + G(x) ∗ (1 − Ax ), (4)
LAGAN (G, DY A ) =Ey∼pdata (y) [log DY A ([Ay , y])]
where the reconstructed image F (G(x)) should be very close +Ex∼pdata (x) [log(1 − DY A ([Ay , G(x)]))],
to the original one x. For image y, we can reconstruct it by (7)
PREPRINT - WORK IN PROGRESS 6
where DY A aims to distinguish between the generated image E. Implementation Details
pairs [Ay , G(x)] and the real image pairs [Ay , y]. We also Network Architecture. For a fair comparison, we use the
have another loss LAGAN (F, DXA ) for discriminator DXA generator architecture from CycleGAN [3]. We have slightly
and generator F , where DXA tries to distinguish the fake modified it for our task. Scheme I takes a three-channel RGB
image pairs [Ax , F (y)] and the real image pairs [Ax , x]. In this image as input and outputs a one-channel attention mask
way, the discriminators can focus on the most discriminative and a three-channel content mask. Scheme II takes an three-
content and ignore the unrelated content. channel RGB image as input and outputs n attention masks
Note that the proposed attention-guided discriminator only and n−1 content masks, thus we fuse all of these masks and
used in scheme I. In preliminary experiments, we also used the input image to produce the final results. We set n=10
the proposed attention-guided discriminator in scheme II, but in our experiments. For the vanilla discriminator, we employ
did not observe improved performance. The reason could be the discriminator architecture from [3]. We employ the same
that the proposed attention-guided generators in scheme II architecture as the proposed attention-guided discriminator
have enough ability to learn the most discriminative content except the attention-guided discriminator takes a attention
between the source and target domains. mask and an image as inputs while the vanilla discriminator
only takes an image as input.
D. Optimization Objective Training Strategy. We follow the standard optimization
The optimization objective of the proposed attention-guided method from [1] to optimize the proposed AttentionGAN, i.e.,
generation scheme II can be expressed as: we alternate between one gradient descent step on generators,
L = LGAN + λcycle ∗ Lcycle + λid ∗ Lid , (8) then one step on discriminators. Moreover, we use a least
square loss [31] to stabilize our model during the training
where LGAN , Lcycle and Lid are GAN loss, cycle-consistency procedure. We also use a history of generated images to update
loss and identity preserving loss [30], respectively. λcycle and discriminators similar to CycleGAN.
λid are parameters controlling the relative relation of each
term. IV. E XPERIMENTS
The optimization objective of the proposed attention-guided
generation scheme I can be expressed: To explore the generality of the proposed AttentionGAN,
we conduct extensive experiments on a variety of tasks with
L =λcycle ∗ Lcycle + λpixel ∗ Lpixel
(9) both face and natural images.
+λgan ∗ (LGAN + LAGAN ) + λtv ∗ Ltv ,
where LGAN , LAGAN , Lcycle , Ltv and Lpixel are GAN loss, A. Experimental Setup
attention-guided GAN loss, cycle-consistency loss, attention
Datasets. We employ 8 publicly available datasets to evaluate
loss and pixel loss, respectively. λgan , λcycle , λpixel and λtv
the proposed AttentionGAN, including 4 face image datasets
are parameters controlling the relative relation of each term.
(i.e., CelebA, RaFD, AR Face and Selfie2Anime) and 4 natural
In the following, we will introduce the attention loss and pixel
image datasets. (i) CelebA dataset [32] has more than 200K
loss. Note that both losses are only used in the scheme I since
celebrity images with complex backgrounds, each annotated
the generator needs stronger constraints than those in scheme
with about 40 attributes. We use this dataset for multi-
II.
When training our AttentionGAN we do not have ground- domain facial attribute transfer task. Following StarGAN [14],
truth annotation for the attention masks. They are learned from we randomly select 2,000 images for testing and use all
the resulting gradients of both attention-guided generators and remaining images for training. Seven facial attributes, i.e, gen-
discriminators and the rest of the losses. However, the attention der (male/female), age (young/old), hair color (black, blond,
masks can easily saturate to 1 causing the attention-guided brown) are adopted in our experiments. Moreover, in order to
generators to have no effect. To prevent this situation, we evaluate the performance of the proposed AttentionGAN under
perform a Total Variation regularization over attention masks the situation where training data is limited. We conduct facial
Ax and Ay . The attention loss of mask Ax therefore can be expression translation experiments on this dataset. Specifically,
defined as: we randomly select 1,000 neutral images and 1,000 smile
W,H
images as training data, and another 1,000 neutral and 1,000
smile images as testing data. (ii) RaFD dataset [33] consists of
X
Ltv = |Ax (w + 1, h, c) − Ax (w, h, c)|
w,h=1
(10) 4,824 images collected from 67 participants. Each participant
+ |Ax (w, h + 1, c) − Ax (w, h, c)| , have eight facial expressions. We employ all of the images
for multi-domain facial expression translation task. (iii) AR
where W and H are the width and height of Ax .
Face [34] contains over 4,000 color images in which only
Moreover, to reduce changes and constrain the generator in
1,018 images have four different facial expressions, i.e., smile,
scheme I, we adopt pixel loss between the input images and
anger, fear and neutral. We employ the images with the
the generated images. This loss can be regraded as another
expression labels of smile and neutral to evaluate our method.
form of the identity preserving loss. We express this loss as:
(iv) We follow U-GAT-IT [28] and use the Selfie2Anime
Lpixel (G, F ) =Ex∼pdata (x) [kG(x) − xk1 ] dataset to evaluate the proposed AttentionGAN. (v) Horse
(11)
+Ey∼pdata (y) [kF (y) − yk1 ]. and zebra dataset [3] has been downloaded from ImageNet
We adopt L1 distance as loss measurement in pixel loss. using keywords wild horse and zebra. The training set size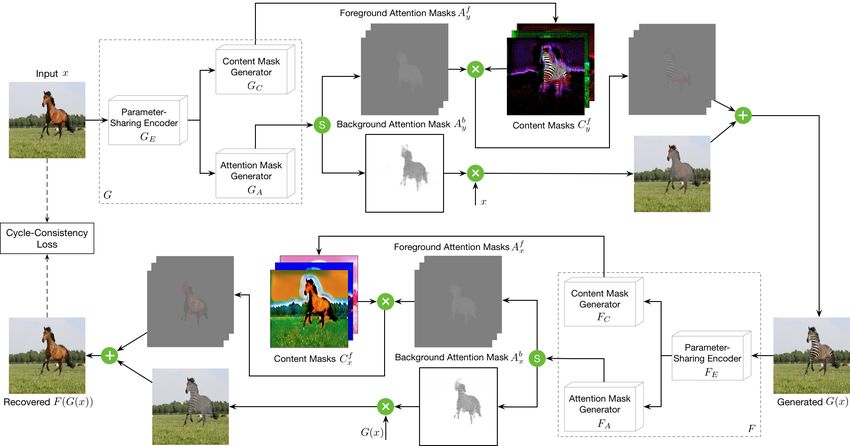
PREPRINT - WORK IN PROGRESS 7
Fig. 5: Comparison results of the proposed attention-guided
generation scheme I and II.
Fig. 4: Ablation study of the proposed AttentionGAN.
TABLE I: Ablation study of the proposed AttentionGAN. we randomly select one output from them for fair comparisons.
Setup of AttentionGAN AMT ↑ PSNR ↑ To re-implement ContrastGAN, we use OpenFace [47] to
Full 12.8 14.9187 obtain the face masks as extra input data.
Full - AD 10.2 14.6352
Full - AD - AG 3.2 14.4646 Evaluation Metrics. Following CycleGAN [3], we adopt
Full - AD - PL 8.9 14.5128
Full - AD - AL 6.3 14.6129 Amazon Mechanical Turk (AMT) perceptual studies to eval-
Full - AD - PL - AL 5.2 14.3287 uate the generated images. Moreover, to seek a quantitative
measure that does not require human participation, Peak
of horse and zebra are 1067 (horse) and 1334 (zebra). The Signal-to-Noise Ratio (PSNR), Kernel Inception Distance
testing set size of horse and zebra are 120 (horse) and 140 (KID) [48] and Fréchet Inception Distance (FID) [49] are
(zebra). (vi) Apple and orange dataset [3] is also collected employed according to different translation tasks.
from ImageNet using keywords apple and navel orange. The
training set size of apple and orange are 996 (apple) and 1020
(orange). The testing set size of apple and orange are 266 B. Experimental Results
(apple) and 248 (orange). (vii) Map and aerial photograph 1) Ablation Study
dataset [3] contains 1,096 training and 1,098 testing images for Analysis of Model Component. To evaluate the components
both domains. (viii) We use the style transfer dataset proposed of our AttentionGAN, we first conduct extensive ablation
in [3]. The training set size of each domain is 6,853 (Photo), studies. We gradually remove components of the proposed
1074 (Monet), 584 (Cezanne). AttentionGAN, i.e., Attention-guided Discriminator (AD),
Parameter Setting. For all datasets, images are re-scaled to Attention-guided Generator (AG), Attention Loss (AL) and
256×256. We do left-right flip and random crop for data Pixel Loss (PL). Results of AMT and PSNR on AR Face
augmentation. We set the number of image buffer to 50 dataset are shown in Table I. We find that removing one of
similar in [3]. We use the Adam optimizer [35] with the them substantially degrades results, which means all of them
momentum terms β1 =0.5 and β2 =0.999. We follow [36] and are critical to our results. We also provide qualitative results in
set λcycle =10, λgan =0.5, λpixel =1 and λtv =1e−6 in Eq. (9). Fig. 4. Note that without AG we cannot generate both attention
We follow [3] and set λcycle =10, λid =0.5 in Eq. (8). and content masks.
Competing Models. We consider several state-of-the-art im- Attention-Guided Generation Scheme I vs. II Moreover,
age translation models as our baselines. (i) Unpaired image we present the comparison results of the proposed attention-
translation methods: CycleGAN [3], DualGAN [4], DIAT [37], guided generation schemes I and II. Schemes I is used in
DiscoGAN [5], DistanceGAN [19], Dist.+Cycle [19], Self our conference paper [36]. Schemes II is a refined version
Dist. [19], ComboGAN [20], UNIT [38], MUNIT [39], proposed in this paper. Comparison results are shown in
DRIT [40], GANimorph [6], CoGAN [41], SimGAN [42], Fig. 5. We observe that scheme I generates good results on
Feature loss+GAN [42] (a variant of SimGAN); (ii) Paired facial expression transfer task, however, it generates identical
image translation methods: BicycleGAN [30], Pix2pix [2], images with the inputs on other tasks, e.g., horse to zebra
Encoder-Decoder [2]; (iii) Class label, object mask or translation, apple to orange translation and map to aerial
attention-guided image translation methods: IcGAN [13], Star- photo translation. The proposed attention-guided generation
GAN [14], ContrastGAN [7], GANimation [43], RA [44], scheme II can handle all of these tasks.
UAIT [29], U-GAT-IT [28], SAT [26]; (iv) Unconditional 2) Experiments on Face Images
GANs methods: BiGAN/ALI [45], [46]. Note that the fully We conduct facial expression translation experiments on 4
supervised Pix2pix, Encoder-Decoder (Enc.-Decoder) and Bi- public datasets to validate the proposed AttentionGAN.
cycleGAN are trained with paired data. Since BicycleGAN can Results on AR Face Dataset. Results of neutral ↔ happy
generate several different outputs with one single input image, expression translation on AR Face are shown in Fig. 6.
PREPRINT - WORK IN PROGRESS 8
Fig. 6: Results of facial expression transfer trained on AR
Face.
Fig. 7: Results of facial expression transfer trained on CelebA.
Fig. 9: Results of facial expression transfer trained on RaFD.
Fig. 8: Results of facial attribute transfer trained on CelebA.
Clearly, the results of Dist.+Cycle and Self Dist. cannot even
generate human faces. DiscoGAN produces identical results
regardless of the input faces suffering from mode collapse.
The results of DualGAN, DistanceGAN, StarGAN, Pix2pix,
Encoder-Decoder and BicycleGAN tend to be blurry, while Fig. 10: Different methods for mapping selfie to anime.
ComboGAN and ContrastGAN can produce the same iden-
tity but without expression changing. CycleGAN generates evaluate the proposed AttentionGAN. Results compared with
sharper images, but the details of the generated faces are not StarGAN are shown in Fig. 8. We observe that the proposed
convincing. Compared with all the baselines, the results of AttentionGAN achieves visually better results than StarGAN
our AttentionGAN are more smooth, correct and with more without changing backgrounds.
details. Results on RaFD Dataset. We follow StarGAN and conduct
Results on CelebA Dataset. We conduct both facial ex- diversity facial expression translation task on this dataset.
pression translation and facial attribute transfer tasks on this Results compared against the baselines DIAT, CycleGAN,
dataset. Facial expression translation task on this dataset is IcGAN, StarGAN and GANimation are shown in Fig. 9.
more challenging than AR Face dataset since the background We observe that the proposed AttentionGAN achieves better
of this dataset is very complicated. Note that this dataset results than DIAT, CycleGAN, StarGAN and IcGAN. For
does not provide paired data, thus we cannot conduct experi- GANimation, we follow the authors’ instruction and use
ments on supervised methods, i.e., Pix2pix, BicycleGAN and OpenFace [47] to obtain the action units of each face as
Encoder-Decoder. Results compared with other baselines are extra input data. Note that the proposed method generate
shown in Fig. 7. We observe that only the proposed Attention- the competitive results compared to GANimation. However,
GAN produces photo-realistic faces with correct expressions. GANimation needs action units annotations as extra training
The reason could be that methods without attention cannot data, which limits its practical application. More importantly,
learn the most discriminative part and the unwanted part. All GANimation cannot handle other generative tasks such facial
existing methods failed to generate novel expressions, which attribute transfer as shown in Fig. 8.
means they treat the whole image as the unwanted part, while Results of Selfie to Anime Translation. We follow U-
the proposed AttentionGAN can learn novel expressions, by GAT-IT [28] and conduct selfie to anime translation on the
distinguishing the discriminative part from the unwanted part. Selfie2Anime dataset. Results compared with state-of-the-art
Moreover, our model can be easily extended to solve multi- methods are shown in Fig. 10. We observe that the proposed
domain image-to-image translation problems. To control mul- AttentionGAN achieves better results than other baselines.
tiple domains in one single model we employ the domain clas- We conclude that even though the subjects in these 4
sification loss proposed in StarGAN. Thus we follow StarGAN datasets have different races, poses, styles, skin colors, il-
and conduct facial attribute transfer task on this dataset to lumination conditions, occlusions and complex backgrounds,
PREPRINT - WORK IN PROGRESS 9
Fig. 11: Attention and content masks on RaFD. Fig. 13: Attention mask on selfie to anime translation task.
Fig. 12: Attention and content masks on CelebA.
TABLE II: Quantitative comparison on facial expression trans-
lation task. For both AMT and PSNR, high is better.
AR Face CelebA
Model Publish
AMT ↑ PSNR ↑ AMT ↑ Fig. 14: Evolution of attention masks and content masks.
CycleGAN [3] ICCV 2017 10.2 14.8142 34.6 TABLE V: Overall model capacity on RaFD (m=8).
DualGAN [4] ICCV 2017 1.3 14.7458 3.2
DiscoGAN [5] ICML 2017 0.1 13.1547 1.2 Method Publish # Models # Parameters
ComboGAN [20] CVPR 2018 1.5 14.7465 9.6
Pix2pix [2] CVPR 2017 m(m-1) 57.2M×56
DistanceGAN [19] NeurIPS 2017 0.3 11.4983 1.9
Encoder-Decoder [2] CVPR 2017 m(m-1) 41.9M×56
Dist.+Cycle [19] NeurIPS 2017 0.1 3.8632 1.3
BicycleGAN [30] NeurIPS 2017 m(m-1) 64.3M×56
Self Dist. [19] NeurIPS 2017 0.1 3.8674 1.2
StarGAN [14] CVPR 2018 1.6 13.5757 14.8 CycleGAN [3] ICCV 2017 m(m-1)/2 52.6M×28
ContrastGAN [7] ECCV 2018 8.3 14.8495 25.1 DualGAN [4] ICCV 2017 m(m-1)/2 178.7M×28
Pix2pix [2] CVPR 2017 2.6 14.6118 - DiscoGAN [5] ICML 2017 m(m-1)/2 16.6M×28
Enc.-Decoder [2] CVPR 2017 0.1 12.6660 - DistanceGAN [19] NeurIPS 2017 m(m-1)/2 52.6M×28
BicycleGAN [30] NeurIPS 2017 1.5 14.7914 - Dist.+Cycle [19] NeurIPS 2017 m(m-1)/2 52.6M×28
AttentionGAN Ours 12.8 14.9187 38.9 Self Dist. [19] NeurIPS 2017 m(m-1)/2 52.6M×28
ComboGAN [20] CVPR 2018 m 14.4M×8
TABLE III: AMT results of facial attribute transfer task on StarGAN [14] CVPR 2018 1 53.2M×1
CelebA dataset. For this metric, higher is better. ContrastGAN [7] ECCV 2018 1 52.6M×1
AttentionGAN Ours 1 52.6M×1
Method Publish Hair Color Gender Aged
DIAT [37] arXiv 2016 3.5 21.1 3.2
CycleGAN [3] ICCV 2017 9.8 8.2 9.4 attention makes, which significantly increases the number of
IcGAN [13]
StarGAN [14]
NeurIPS 2016
CVPR 2018
1.3
24.8
6.3
28.8
5.7
30.8
network parameters and training time.
AttentionGAN Ours 60.6 35.6 50.9 Visualization of Learned Attention and Content Masks.
TABLE IV: KID × 100 ± std. × 100 of selfie to anime Instead of regressing a full image, our generator outputs
translation task. For this metric, lower is better. two masks, a content mask and an attention mask. We also
Method Publish Selfie to Anime visualize both masks on RaFD and CelebA datasets in Fig. 11
U-GAT-IT [28] ICLR 2020 11.61 ± 0.57 and Fig. 12, respectively. In Fig. 11, we observe that different
CycleGAN [3] ICCV 2017 13.08 ± 0.49
UNIT [38] NeurIPS 2017 14.71 ± 0.59 expressions generate different attention masks and content
MUNIT [39] ECCV 2018 13.85 ± 0.41 masks. The proposed method makes the generator focus
DRIT [40] ECCV 2018 15.08 ± 0.62
AttentionGAN Ours 12.14 ± 0.43 only on those discriminative regions of the image that are
responsible of synthesizing the novel expression. The attention
our method consistently generates more sharper images with masks mainly focus on the eyes and mouth, which means
correct expressions/attributes than existing models. We also these parts are important for generating novel expressions. The
observe that our AttentionGAN preforms better than other proposed method also keeps the other elements of the image
baselines when training data are limited (see Fig. 7), which or unwanted part untouched. In Fig. 11, the unwanted part are
also shows that our method is very robust. hair, cheek, clothes and also background, which means these
Quantitative Comparison. We also provide quantitative re- parts have no contribution in generating novel expressions.
sults on these tasks. As shown in Table II, we see that Atten- In Fig. 12, we observe that different facial attributes also
tionGAN achieves the best results on these datasets compared generate different attention masks and content masks, which
with competing models including fully-supervised methods further validates our initial motivations. More attention masks
(e.g., Pix2pix, Encoder-Decoder and BicycleGAN) and mask- generated by AttentionGAN on the facial attribute transfer task
conditional methods (e.g., ContrastGAN). Next, following are shown in Fig. 8. Note that the proposed AttentionGAN
StarGAN, we perform a user study using Amazon Mechanical can handle the geometric changes between source and target
Turk (AMT) to assess attribute transfer task on CelebA dataset. domains, such as selfie to anime translation. Therefore, we
Results compared the state-of-the-art methods are shown in Ta- show the learned attention masks on selfie to anime translation
ble III. We observe that AttentionGAN achieves significantly task to interpret the generation process in Fig. 13.
better results than all the leading baselines. Moreover, we We also present the generation of both attention and content
follow U-GAT-IT [28] and adopt KID to evaluate the generated masks on AR Face dataset epoch-by-epoch in Fig. 14. We see
images on selfie to anime translation. Results are shown in that with the number of training epoch increases, the attention
Table IV, we observe that our AttentionGAN achieves the best mask and the result become better, and the attention masks
results compared with baselines except U-GAT-IT. However, correlate well with image quality, which demonstrates the
U-GAT-IT needs to adopt two auxiliary classifiers to obtain proposed AttentionGAN is effective.
PREPRINT - WORK IN PROGRESS 10
Fig. 15: Different methods for mapping horse to zebra. Fig. 17: Different methods for mapping zebra to horse.
Fig. 16: Different methods for mapping horse to zebra.
Fig. 18: Different methods for mapping apple to orange.
Comparison of the Number of Parameters. The number
of models for different m image domains and the number other approaches. However, if we look closely at the results
of model parameters on RaFD dataset are shown in Table V. generated by both methods, we observe that U-GAT-IT slightly
Note that our generation performance is much better than these changes the background, while the proposed AttentionGAN
baselines and the number of parameters is also comparable perfectly keeps the background unchanged. For instance, as
with ContrastGAN, while ContrastGAN requires object masks can be seen from the results of the first line, U-GAT-IT
as extra data. produces a darker background than the background of the input
3) Experiments on Natural Images image in Fig. 16. While the background color of the generated
We conduct experiments on 4 natural image datasets to images by U-GAT-IT is lighter than the input images as shown
evaluate the proposed AttentionGAN. in the second and third rows in Fig. 16.
Results of Horse ↔ Zebra Translation. Results of horse Lastly, we also compare the proposed AttentionGAN with
to zebra translation compared with CycleGAN, RA, Disco- GANimorph and CycleGAN in Fig. 1. We see that the
GAN, UNIT, DualGAN and UAIT are shown in Fig. 15. We proposed AttentionGAN demonstrates a significant qualitative
observe that DiscoGAN, UNIT, DualGAN generate blurred improvement over both methods.
results. Both CycleGAN and RA can generate the correspond- Results of zebra to horse translation are shown in Fig. 17.
ing zebras, however the background of images produced by We note that the proposed method generates better results than
both models has also been changed. Both UAIT and the all the leading baselines. In summary, the proposed model
proposed AttentionGAN generate the corresponding zebras is able to better alter the object of interest than existing
without changing the background. By carefully examining the methods by modeling attention masks in unpaired image-to-
translated images from both UAIT and the proposed Attention- image translation tasks, without changing the background at
GAN, we observe that AttentionGAN achieves slightly better the same time.
results than UAIT as shown in the first and the third rows of Results of Apple ↔ Orange Translation. Results compared
Fig. 15. Our method produces better stripes on the body of with CycleGAN, RA, DiscoGAN, UNIT, DualGAN and UAIT
the lying horse than UAIT as shown in the first row. In the are shown in Fig. 18 and 19. We see that RA, DiscoGAN,
third row, the proposed method generates fewer stripes on the UNIT and DualGAN generate blurred results with lots of
body of the people than UAIT. visual artifacts. CycleGAN generates better results, however,
Moreover, we compare the proposed method with Cy- we can see that the background and other unwanted objects
cleGAN, UNIT, MUNIT, DRIT and U-GAT-IT in Fig. 16. have also been changed, e.g., the banana in the second row
We can see that UNIT, MUNIT and DRIT generate blurred of Fig. 18. Both UAIT and the proposed AttentionGAN can
images with many visual artifacts. CycleGAN can produces generate much better results than other baselines. However,
the corresponding zebras, however the background of images UAIT adds an attention network before each generator to
has also been changed. The just released U-GAT-IT and achieve the translation of the relevant parts, which increases
the proposed AttentionGAN can produce better results than the number of network parameters.PREPRINT - WORK IN PROGRESS 11
Fig. 21: Different methods for mapping aerial photo to map.
Fig. 19: Different methods for mapping orange to apple.
Fig. 20: Different methods for mapping map to aerial photo. Fig. 22: Different methods for style transfer.
TABLE VI: KID × 100 ± std. × 100 for different methods. TABLE VIII: FID between generated samples and target
For this metric, lower is better. Abbreviations: (H)orse, (Z)ebra samples for horse to zebra translation task. For this metric,
(A)pple, (O)range. lower is better.
Method Publish H→Z Z→H A→O O→A Method Publish Horse to Zebra
DiscoGAN [5] ICML 2017 13.68 ± 0.28 16.60 ± 0.50 18.34 ± 0.75 21.56 ± 0.80 UNIT [38] NeurIPS 2017 241.13
RA [44] CVPR 2017 10.16 ± 0.12 10.97 ± 0.26 12.75 ± 0.49 13.84 ± 0.78
CycleGAN [3] ICCV 2017 109.36
DualGAN [4] ICCV 2017 10.38 ± 0.31 12.86 ± 0.50 13.04 ± 0.72 12.42 ± 0.88
UNIT [38] NeurIPS 2017 11.22 ± 0.24 13.63 ± 0.34 11.68 ± 0.43 11.76 ± 0.51 SAT (Before Attention) [26] TIP 2019 98.90
CycleGAN [3] ICCV 2017 10.25 ± 0.25 11.44 ± 0.38 8.48 ± 0.53 9.82 ± 0.51 SAT (After Attention) [26] TIP 2019 128.32
UAIT [29] NeurIPS 2018 6.93 ± 0.27 8.87 ± 0.26 6.44 ± 0.69 5.32 ± 0.48 AttentionGAN Ours 68.55
2.03 ± 0.64 6.48 ± 0.51 10.03 ± 0.66 4.38 ± 0.42
AttentionGAN Ours
TABLE IX: AMT “real vs fake” results on maps ↔ aerial
TABLE VII: Preference score of generated results on both
photos. For this metric, higher is better.
horse to zebra and apple to orange translation tasks. For this
Method Publish Map to Photo Photo to Map
metric, higher is better. CoGAN [41] NeurIPS 2016 0.8 ± 0.7 1.3 ± 0.8
Method Publish Horse to Zebra Apple to Orange BiGAN/ALI [45], [46] ICLR 2017 3.2 ± 1.5 2.9 ± 1.2
SimGAN [42] CVPR 2017 0.4 ± 0.3 2.2 ± 0.7
UNIT [38] NeurIPS 2017 1.83 2.67 Feature loss + GAN [42] CVPR 2017 1.1 ± 0.8 0.5 ± 0.3
MUNIT [39] ECCV 2018 3.86 6.23 CycleGAN [3] ICCV 2017 27.9 ± 3.2 25.1 ± 2.9
DRIT [40] ECCV 2018 1.27 1.09 Pix2pix [2] CVPR 2017 33.7 ± 2.6. 29.4 ± 3.2
CycleGAN [3] ICCV 2017 22.12 26.76 AttentionGAN Ours 35.18 ± 2.9 32.4 ± 2.5
U-GAT-IT [28] ICLR 2020 33.17 30.05
AttentionGAN Ours 37.75 33.20
score on apple to orange translation (A → O) but have poor
Results of Map ↔ Aerial Photo Translation. Qualitative quality image generation as shown in Fig. 18.
results of both translation directions compared with existing Moreover, following U-GAT-IT [28], we conduct a percep-
methods are shown in Fig. 20 and 21, respectively. We note tual study to evaluate the generated images. Specifically, 50
that BiGAN, CoGAN, SimGAN, Feature loss+GAN only participants are shown the generated images from different
generate blurred results with lots of visual artifacts. Results methods including our AttentionGAN with source image, and
generated by our method are better than those generated by asked to select the best generated image to target domain, i.e.,
CycleGAN. Moreover, we compare the proposed method with zebra and orange. Results of both horse to zebra translation
the fully supervised Pix2pix, we see that the proposed method and apple to orange translation are shown in Table VII. We
achieves comparable or even better results than Pix2pix as observe that the proposed method outperforms other baselines
indicated in the black boxes in Fig. 21. including U-GAT-IT on both tasks.
Results of Style Transfer. Lastly, we also show the generation Next, we follow SAT [26] and adopt Fréchet Inception
results of our AttentionGAN on the style transfer task. Results Distance (FID) [49] to measure the distance between generated
compared with the leading method, i.e., CycleGAN, are shown samples and target samples. We compute FID for horse to
in Fig. 22. We observe that the proposed AttentionGAN zebra translation and results compared with SAT, CycleGAN
generates much sharper and diverse results than CycleGAN. and UNIT are shown in Table VIII. We observe that the
Quantitative Comparison. We follow UAIT [29] and adopt proposed model achieves significantly better FID than all
KID [48] to evaluate the generated images by different meth- baselines. We note that SAT with attention has worse FID
ods. Results of horse ↔ zebra and apple ↔ orange are shown than SAT without attention, which means using attention might
in Table VI. We observe that AttentionGAN achieves the have a negative effect on FID because there might be some
lowest KID on H → Z, Z → H and O → A translation tasks. correlations between foreground and background in the target
We note that both UAIT and CycleGAN produce a lower KID domain when computing FID. While we did not observe suchPREPRINT - WORK IN PROGRESS 12
Fig. 23: Attention masks on horse ↔ zebra translation.
Fig. 26: Attention masks on aerial photo ↔ map translation.
domains differ greatly on the appearance, the images of both
domains are structurally identical. Thus the learned attention
Fig. 24: Attention masks on apple ↔ orange translation. masks highlight the shared layout and structure of both source
and target domains. Thus we can conclude that the proposed
AttentionGAN can handle both images requiring large shape
changes and images requiring holistic changes.
V. C ONCLUSION
We propose a novel attention-guided GAN model, i.e., At-
tentionGAN, for both unpaired image-to-image translation and
multi-domain image-to-image translation tasks. The generators
in AttentionGAN have the built-in attention mechanism, which
can preserve the background of the input images and discovery
the most discriminative content between the source and target
domains by producing attention masks and content masks.
Then the attention masks, content masks and the input images
are combined to generate the target images with high-quality.
Fig. 25: Attention masks compared with SAT [26] on horse Extensive experimental results on several challenging tasks
to zebra translation. demonstrate that the proposed AttentionGAN can generate
better results with more convincing details than numerous
negative effect on the proposed AttentionGAN. Qualitative state-of-the-art methods.
Acknowledgements. This work is partially supported by National Natu-
comparison with SAT is shown in Fig. 25. We observe that ral Science Foundation of China (NSFC, No.U1613209,61673030), Shen-
the proposed AttentionGAN achieves better results than SAT. zhen Key Laboratory for Intelligent Multimedia and Virtual Reality
Finally, we follow CycleGAN and adopt AMT score to (ZDSYS201703031405467).
evaluate the generated images on the map ↔ aerial photo
translation task. Participants were shown a sequence of pairs of R EFERENCES
images, one real photo or map and one fake generated by our [1] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley,
S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in
method or exiting methods, and asked to click on the image NeurIPS, 2014. 1, 2, 3, 6
they thought was real. Comparison results of both translation [2] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation
directions are shown in Table IX. We observe that the proposed with conditional adversarial networks,” in CVPR, 2017. 1, 2, 3, 7, 9, 11
[3] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image
AttentionGAN generate the best results compared with the translation using cycle-consistent adversarial networks,” in ICCV, 2017.
leading methods and can fool participants on around 1/3 of 1, 2, 3, 5, 6, 7, 9, 11
trials in both translation directions. [4] Z. Yi, H. Zhang, P. Tan, and M. Gong, “Dualgan: Unsupervised dual
learning for image-to-image translation,” in ICCV, 2017. 1, 3, 7, 9, 11
Visualization of Learned Attention Masks. Results of both [5] T. Kim, M. Cha, H. Kim, J. Lee, and J. Kim, “Learning to discover
horse ↔ zebra and apple ↔ orange translation are shown in cross-domain relations with generative adversarial networks,” in ICML,
Fig. 23 and 24, respectively. We see that our AttentionGAN is 2017. 1, 3, 7, 9, 11
[6] A. Gokaslan, V. Ramanujan, D. Ritchie, K. In Kim, and J. Tompkin,
able to learn relevant image regions and ignore the background “Improving shape deformation in unsupervised image-to-image transla-
and other irrelevant objects. Moreover, we also compare with tion,” in ECCV, 2018. 1, 2, 7
the most recently method, SAT [26], on the learned attention [7] X. Liang, H. Zhang, and E. P. Xing, “Generative semantic manipulation
with contrasting gan,” in ECCV, 2018. 1, 3, 7, 9
masks. Results are shown in Fig. 25. We observe that the [8] X. Chen, C. Xu, X. Yang, and D. Tao, “Attention-gan for object
attention masks learned by our method are much accurate than transfiguration in wild images,” in ECCV, 2018. 1, 3
those generated by SAT, especially in the boundary of attended [9] D. Kastaniotis, I. Ntinou, D. Tsourounis, G. Economou, and S. Fo-
topoulos, “Attention-aware generative adversarial networks (ata-gans),”
objects. Thus our method generates more photo-realistic object in IVMSP Workshop, 2018. 1, 3
boundary than SAT in the translated images, as indicated in [10] A. Brock, J. Donahue, and K. Simonyan, “Large scale gan training for
the red boxes in Fig. 25. high fidelity natural image synthesis,” in ICLR, 2019. 2
[11] Y. Wang, C. Wu, L. Herranz, J. van de Weijer, A. Gonzalez-Garcia, and
Results of map ↔ aerial photo translation are shown in B. Raducanu, “Transferring gans: generating images from limited data,”
Fig. 26. Note that although images of the source and target in ECCV, 2018. 2You can also read

















































