Community Detection in Political Twitter Networks using Nonnegative Matrix Factorization Methods - arXiv
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Community Detection in Political Twitter Networks
using Nonnegative Matrix Factorization Methods
Mert Ozer Nyunsu Kim Hasan Davulcu
School of Computing, Informatics, School of Computing, Informatics, School of Computing, Informatics,
Decision Systems Engineering Decision Systems Engineering Decision Systems Engineering
Arizona State University Arizona State University Arizona State University
Tempe, USA 85287 Tempe, USA 85287 Tempe, USA 85287
mozer@asu.edu nkim30@asu.edu hdavulcu@asu.edu
arXiv:1608.01771v1 [cs.SI] 5 Aug 2016
Abstract—Community detection is a fundamental task in social in the political sub-domain of Twitter, it has been shown that
network analysis. In this paper, first we develop an endorsement retweets tend to happen between like-minded users rather than
filtered user connectivity network by utilizing Heider’s structural between members of opposing camps [8].
balance theory and certain Twitter triad patterns. Next, we
develop three Nonnegative Matrix Factorization frameworks to Using both connectivity and content information for com-
investigate the contributions of different types of user connectivity munity detection in social networks has been a popular ap-
and content information in community detection. We show that proach among many researchers’ prior works [4], [5], [6], [3].
user content and endorsement filtered connectivity information In [4], Tang et al. propose a general framework for integrating
are complementary to each other in clustering politically mo-
tivated users into pure political communities. Word usage is
multiple heterogenous data sources for community detection.
the strongest indicator of users’ political orientation among all Tang’s work does not pay attention to identifying the endorse-
content categories. Incorporating user-word matrix and word ment subgraph of the connectivity graph. In [5] Sachan et al.
similarity regularizer provides the missing link in connectivity- propose an LDA-like social interaction model by representing
only methods which suffer from detection of artificially large user connectivity as a document alongside message content.
number of clusters for Twitter networks.
This approach also does not discriminate between positive
I. I NTRODUCTION or negative user engagement. In [6], Ruan et al. propose to
use a filtered graph to eliminate ambiguous interactions by
Twitter has become one of the main stages of political checking content similarity in the user’s neighborhood. In
activity both among politicians and partisan crowds. We have this formulation, only local content patterns are taken into
seen huge political mobilizations over Twitter in recent up- consideration whereas in our formulations we incorporate the
risings such as the Arab Spring and the Gezi protests [1]. global content patterns into our optimization framework.
Since then, politicians have been engaging in using Twitter to The contributions of this paper can be summarized as
attract supporters and people have been using it to express their follows:
political views and opinions on various leaders and issues.
Community detection is a fundamental task in social net- • We start with retweets without edits as indicators of
work analysis [2]. A community [3] can be defined as a group positive endorsements between users and utilize Heider’s
of users that (1) interact with each other more frequently than P-O-X triad balance theory [11] to incorporate selected
with those outside the group and (2) are more similar to each ”structurally balanced” edited retweets and user mentions
other than to those outside the group. Utilizing community de- into a weighted undirected connectivity graph as addi-
tection algorithms to detect online political camps has attracted tional indicators of positive endorsements.
many researchers [4], [5], [6]. In this work, we propose three • We develop algorithms which incorporate users’ content
nonnegative matrix factorization frameworks to exploit both information in our community detection frameworks to
user connectivity and content information in Twitter to find overcome the sparse nature of Twitter connectivity net-
ideologically pure communities in terms of their members’ works. We break down Twitter message content into
political orientations. three categories; words, hashtags and urls, and design
Twitter presents three types of connectivity information experiments to measure the performance contributions
between users: follow, retweet and user mention. In this paper, of each category. Proposed Nonnegative Matrix Factor-
we do not use follow information since follow relationships ization (NMF) algorithms use user-word, user-hashtag
correspond to longer-term structural bonds [10] and it remains and user-domain frequency matrices to be factorized into
challenging to determine if a follow relationship between a lower rank user vector representations while regularizing
pair of users indicate political support or opposition. Further- over user connectivity and content similarity to map users
more, it has been observed that neither user retweets nor user into their respective communities.
mentions always indicate endorsement in Twitter [7]. However Pei et al. in [3] also model the problem as nonnegativematrix tri-factorization problem which factorizes user-word, incorporate Laplacian graph regularization to the standard
tweet-word and user-user matrices into lower rank representa- NMF algorithm which assumes data points are sampled from
tions of users and tweets while regularizing it with user inter- a Euclidian space which is not the case usually for real-world
action and message similarity matrices. They build user-user applications. Gu et al. [31] further incorporate local learn-
connectivity matrix by utilizing the structural follow relation- ing regularization to NMF which assumes that geometrically
ships which do not capture dynamic political context-sensitive neighboring data points are similar to each other, and should be
engagement. They treat all user mentions and retweets iden- in the same cluster. For co-clustering purposes Ding et al. [28]
tically and without any discrimination for endorsement. Their propose nonnegative matrix tri-factorization with orthogonality
framework also lacks word similarity regularization. constraints. Shang et al. introduce graph dual regularized NMF
We develop and experiment with three nonnegative ma- algorithm in [27] by claiming that not only observed data but
trix factorization frameworks: MultiNMF, TriNMF, DualNMF, also features lie on a manifold. Yao et al. [24] apply the same
which incorporate connectivity alongside different types of logic for collaborative filtering domain and propose a dual
content information as regularizers. After experimenting with regularized one-class collaborative filtering method.
different dimensions of user content and different types of
III. T HE S TRUCTURAL BALANCE OF R ETWEET AND
induced connectivity networks we discovered that incorpo-
M ENTION G RAPH
rating more information does not necessarily yield higher
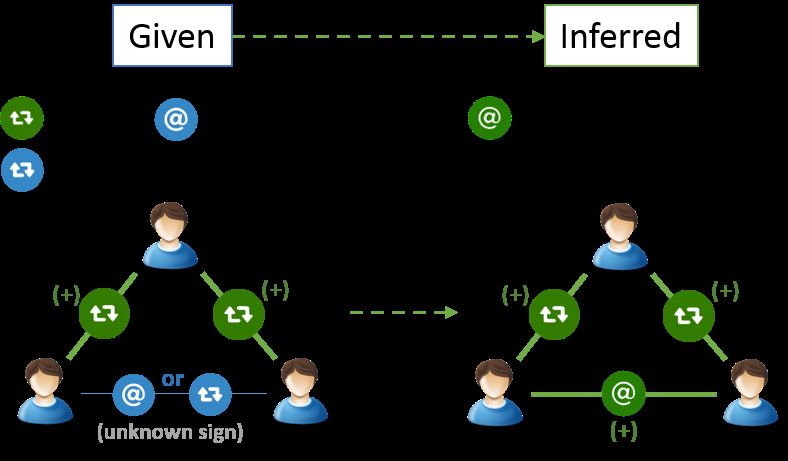
clustering performance. Highest quality clustering is achieved Since P-O-X triad balance theory proposed by Heider in
through endorsement filtered connectivity based on methods [11], structural balance of signed networks has been studied
we develop in Section III alongside user-word matrix based extensively. Heider proposed that in a signed triad, only two
content regularization. Our DualNMF framework gives purity combinations of eight possible sign configurations are possible
scores around 88%, adjusted rand index around 75% and NMI for a triad to be structurally balanced. Those are the following
around 67%. It improves all of the other baseline methods cases;
significantly as presented in Section V and it also improves 1) three positive edges,
over the NMTF framework developed recently by Pei et al. 2) one positive and a pair of negative edges.
[3] by 8% in purity, 47% in ARI and by up to 60% in In other words, there cannot be any structurally balanced triad
NMI metrics. Proposed endorsement filtered sub-graph of user having only one negative edge. We adopt this social theory
mentions and retweets also improves all baseline methods in for the Twitter user connectivity networks, by assuming that
almost all of the experimental setups by up to 109% in NMI, ”retweets without edits” imply political endorsement or an
71% in ARI and 17% in purity. unambiguous positive edge [12]. However, when a retweet is
The rest of the paper is organized as follows. Section edited, it has already been shown that [13], it does not neces-
II briefly surveys related work. In Section III, we present sarily mean endorsement anymore. Moreover, user mentions
Heider’s theory of P-O-X structural balance of triads and do not imply endorsements either. For these reasons, we only
its application to retweet and mention graphs to identify consider retweets without edits as positive edges. For the rest
endorsement filtered user connectivity networks. In Section IV, of the user actions, corresponding to retweets with edits and
we introduce our three nonnegative matrix factorization frame- users mentions, it is hard to detect positivity or negativity of
works for community detection. In Section V, we present our the edges.
experimental design, evaluation metrics and results. Section In certain triad configurations, retweets with edits and user
VI concludes the paper and discusses future work. mentions can be identified as positive edges with the help
of Heider’s triad structural balance (TSB) rules. Since we
II. R ELATED W ORK do not have unambiguous negative edges, the second case
A. Community Detection is not applicable. However, since we have some positive
Since the introduction of the modularity metric by Newman edges to begin with, we can employ Heider’s first case (i.e.
in [16], plenty of modularity based community detection three positive edges), to infer that in the presence of a triad
methods have been proposed in the literature [17], [18], [19], with a pair of positive edges, the third edge can also be
[20]. We employ Blondel et al. [18] and Clauset et al. [19] labeled as positive. An example configuration with a pair of
works as baseline algorithms to compare with ours due to their positive edges is shown in Figure 1. In this case, TSB rule is
wide popularity among practitioners. A general drawback of applicable and would allow us to infer that any user mention
these algorithms, when they are applied to Twitter networks, or retweet with an edit edge connecting the lower pair of
is that due to the sparse nature of the connectivity they end users in the triad is indeed a positive edge. By employing
up with an artificially large number of communities. this inference mechanism we identify the endorsement filtered
user connectivity network.
B. Nonnegative Matrix Factorization
Nonnegative Matrix Factorization(NMF) algorithms by Lee
et al. [22] and Lin et al. [23] have been extensively used IV. P ROPOSED M ETHODS
and extended for different variations of community detection We propose three methods for clustering politically mo-
problems. Cai et al. [29] introduced GNMF algorithm to tivated users in Twitter namely; MultiNMF, TriNMF and• R + M: It is the adjacency matrix of the full retweet and
mention graph. If there exists both retweet and mention
edges between two users, weights are summed up.
• R + ∆M: It is the adjacency matrix of the union of
retweet and mention graphs in which mention edges and
retweet with edits either complete a missing link in a
triad of retweet without edit or already correspond to a
retweet without edit edge. ∆M can be formally defined
as;
PN
∆M = {(i, j, Mij ) | Rij > 0 ∨ k=1 Rik Rkj > 0}
• R + ∆Mw : It is the adjacency matrix of the union of
retweet and mention graphs in which mention edges and
Fig. 1. An example application of TSB Rule retweet with edits either complete a missing link in a triad
of retweet without edit or already correspond to a retweet
without edit edge. The ones that complete a missing link
DualNMF. For MultiNMF method we use document term in a triad of retweet without edit are weighted by the
representation of user-word, user-hashtag and user-domain ma- multiplication of the weights of two retweet without edit
trices to be factorized and regularize the factorization problem edges in the triad. ∆Mw can be defined formally as;
PN
with the user connectivity graph, cosine similarity matrices of ∆Mw = {(i, j, Mij (Rij + k=1 Rik Rkj ))}
words, domains and hashtag co-occurence matrix. For TriNMF For word similarity and domain similarity regularizers
method we use only user-word and one of user-hashtag or we make use of cosine similarity. It can be formally defined as;
user-domain matrices and regularize over user connectivity
and cosine domain similarity or hashtag co-occurence matrix. vi · vj
cos(θ) =
For DualNMF method we factorize user-word matrix into two k v i k ∗ k vj k
nonnegative lower rank matrices while regularizing it with user where vi is the user usage frequency vector of ith word or
connectivity and cosine word similarity. Before going into the domain. For hashtag similarity we build similarity matrix by
details of the three algorithms we present notation in Table I. In making use of co-occurences of hashtags in tweets. If two
TABLE I hashtags occur in the same tweet, we assume that those two
N OTATION hashtags are similar.
Xuw user x word frequencies of words used by users
Xuh user x hashtag frequencies of hashtags used by users
A. MultiNMF with multi regularizers
Xud user x domain
frequencies of distinct domains used To incorporate usage of both hashtags and domains of
by users
shared url links by users, we propose an NMF framework
adjacency matrix of
R user x user which has the following objective function;
retweet without edit graph
adjacency matrix of
M user x user
mention and retweet with edit graph JU,H,D,W =k Xuw − UWT k2F + k Xuh − UHT k2F
adjacency matrix of mentions + k Xud − UDT k2F +αT r(UT LC U)
∆M user x user and retweet with edits completing
retweet without edit triads + γT r(HT LHsim H) + θT r(DT LDsim D) (1)
adjacency matrix of mentions T
and retweet with edits completing + βT r(W LWsim W)
∆Mw user x user
retweet without edit triads s.t. U ≥ 0, H ≥ 0, D ≥ 0, W ≥ 0
weighted by retweet without edit edges
C user x user
any combination of user connectivity where LC is the Laplacian matrix of adjacency matrix of user
graphs connectivity graph defined as DC − C and DC is the matrix
Hsim hashtag x hashtag hashtag co-occurence matrix
Dsim domain x domain domain similarity matrix which contains the degree of each user node in its diagonals.
Wsim word x word word similarity matrix LHsim , LDsim and LWsim follow the same definition for
α number user connectivity regularizer parameter hashtags and words. Due to the very fuzzy multi-class nature
γ number hashtag similarity regularizer parameter
θ number domain similarity regularizer parameter
of words, hashtags and domain names, we do not include
β number word similarity regularizer parameter orthogonality constraints for matrices U, H, D, W, which
U user x cluster cluster assignment matrix of users usually result in more precise clusters for co-clustering tasks.
H hashtag x cluster cluster assignment matrix of hashtags It is easy to see that the proposed objective function is not
D domain x cluster cluster assignment matrix of domains
W word x cluster cluster assignment matrix of words convex for U, H, D and W, hence we develop an iterative
algorithm which tries to find a local minima by updating each
matrix iteratively as follows;
this work, instead of using only full user retweet and mention s
network we offer three types of user connectivity regularizers Xuw W + Xuh H + Xud D + αL− CU
U←U (2)
as follows; UWT W + UHT H + UDT D + αL+ CUv
u Xuh H + γL−
u T
Hsim H
C. DualNMF
H←H t
T
(3)
HU U + γL+ Hsim H
To use only user word matrix as user content and regularize
v factorization with user connectivity and keyword similarity,
u Xud D + θL−
u T inspired by [24], we present DualNMF objective function as;
Dsim D
D←D t (4)
DUT U + θL+
Dsim D
JU,W =k Xuw − UWT k2F +αT r(UT LC U)
v + βT r(WT LWsim W) (10)
u Xuw U + βL−
u T
Wsim W s.t. U ≥ 0, W ≥ 0
W←W t
T
(5)
WU U + βL+ Wsim W After following the same procedure introduced in Section
where L+ = (|Lij | + Lij )/2 and L− = (|Lij | − Lij )/2. IV-A, we can get the update rules for U and W as;
ij ij
[·]
s
represents element-wise multiplication and represents Xuw W + αL− CU
[·] U←U T
(11)
element-wise division. Derivation of update rules can be seen UW W + αL+ CU
in Appendix A. Complexity of the method can be inferred v
u Xuw U + βL−
u T
as O(i(uwk + uhk + udk + u2 k + h2 k + d2 k + w2 k)) Wsim W
W←W t T
(12)
when complexity of multiplying any X matrix with any of WU U + βL+ Wsim W
U, H, D, W is considered to be O(uwk), O(uhk), O(udk)
and multiplying any of Laplacian matrices L with any of Complexity of the method can be inferred as O(i(uwk+u2 k+
U, H, D, W is taken as O(u2 k), O(h2 k), O(d2 k) or O(w2 k) w2 k)) after omitting the extra operations done over matrices
where i is the number of iterations, u is number of users, h is Xuh , H and DHsim in the previous method. The general
the number of hashtags, d is the number of domains, w is the
number of words and k is the number of clusters. The general Algorithm 1 NMF Algorithms
algorithmic framework is given at the end of methodology in Input:{Xuw , Xuh , Xud , C, Hsim , Dsim , Wsim , α, β, θ, γ}
Algorithm 1. Output: U
B. TriNMF with three regularizers 1: Initialize U, H, D, W > 0
2: while ∆residual > threshold do
To incorporate usage of hashtags or domains of shared url
3: Update U by using one of Equations 2, 7, 11
links solely, we propose a new NMF framework which has
4: Update H by using one of Equations 3, 8
the following objective function.
5: Update D by using Equation 4
JU,H,W =k Xuw − UWT k2F + k Xuh − UHT k2F 6: Update W by using one of Equations 5, 9, 12
+ αT r(UT LC U) + γT r(HT LHsim H) 7: end while
(6) 8: Assign user i to community j where j = argmaxj Uij .
+ βT r(WT LWsim W)
s.t. U ≥ 0, H ≥ 0, W ≥ 0
algorithm can be summarized as the application of the related
where LC is the Laplacian matrix of user connectivity defined
update rules to the matrices U, H, D, W. For MultiNMF with
as DC − C and DC is a diagonal matrix which contains the
multi regularizers method, equations 2, 3, 4, 5 are applied.
degree of each user in its diagonals. LHsim and LWsim follows
For TriNMF with three regularizers method, equations 7, 8,
the same definition for hashtags and words. After applying the
9 are applied and D matrix is not included in calculations.
same procedure followed in Section IV-A, we get updating
For DualNMF method, equations 11 and 12 are applied and
rules as follows.
s H and D matrices are not included in calculations.
Xuw W + Xuh H + αL− CU
U←U T T
(7) V. E XPERIMENTS AND R ESULTS
UW W + UH H + αL+ CU
v A. Data Description
u Xuh U + γL−
u T
Hsim H We make use of a pair of publicly available1 political Twitter
H←H t (8)
T
HU U + γL+ datasets to evaluate our methods. These datasets are user lists
Hsim H
v of 419 British political figures from four major political parties
u Xuw U + βL−
u T in the UK, namely; Conservative and Unionist Party, Labour
Wsim W
W←W t T
(9) Party, Scottish National Party, Liberal Democrats and others,
WU U + βL+ Wsim W and 349 major Irish political figures from seven political
Note that this update rules can be obtained by setting D, Dsim parties; Fianna Fil, Fine Gael, Green Party, Sinn Fin, United
and θ equal to 0 in Equations 2, 3, 5. Complexity of the method Left Alliance, Independents. Several statistics for the datasets
can be calculated by omitting the costs of operations done over are shown in Table II.
matrices Xud , D and LDsim . The complexity of the method 1 Users’ Twitter id lists can be obtained from
is O(i(uwk + uhk + u2 k + h2 k + w2 k)). http://mlg.ucd.ie/aggregation/index.htmlTABLE II
DATA ATTRIBUTES where, H(l) and H(C) are the entropy of class and community
assignments of l and C. P (j, i) is the probability that randomly
UK Ireland
picked user has class label j and belongs to the community i
# of Tweets 19,947 14,656 while P (j) gives the probability of randomly picked user to
# of Retweets 1,566 7,088
# of Mentions 4,956 22,072 be in class j and similarly P (i) to be in community i.
# of Words 10,766 7,973
# of Hashtags 945 986 C. Baseline Algorithms
# of URL Domains 946 634
# of Users 233 258 As a baseline to evaluate the performance of using both
# of Baseline Communities 5 7 connectivity and content information, we design experiments
with connectivity-only and content-only clustering methods.
For connectivity-only method, we use Louvain [18] and
For the UK and Ireland data, we crawl all of the tweets sent CNM [19] algorithms utilizing modularity optimization over
from the accounts of given user id lists. In order not to be user adjacency matrix. Modularity is defined as:
heavily influenced by the extremely polarized election season, 1 X ki kj
we only used tweets dated after May, 7 2015, which was the Q= (Aij − )δ(ci , cj ) (13)
2m ij 2m
election day in the UK. To balance the share of number of
tweets from each user we limit the number of tweets to 200 where δ(ci , cj ) is the Kronecker delta symbol, ci is the label
per user. of the community to which node i is assigned, and ki is the
For each dataset, same preprocessing method is followed. degree of node i.
First, words occurring less than 20 times and stop words For content-only approach, we experiment with k-
are eliminated. After eliminating word features, users and means[21] and conventional non-negative matrix factorization
tweets that lack content are also eliminated. Hashtags and algorithm [22].
domains that appear only once are not taken into consideration For approaches employing both connectivity and content
either. Statistics shown in Table II show the numbers after information of users, we test GNMF [29] and NMTF [3]
preprocessing. algorithms besides proposed methods. GNMF algorithm is
B. Evaluation Metrics introduced by Cai et al. to incorporate intrinsic geometric
similarity of users. We feed previously defined three types
To evaluate the methods, we make use of three well known of user connectivity graphs’ adjacency matrices as graph
clustering quality metrics, namely; purity, adjusted rand index regularization terms to the GNMF algorithm.
and normalized mutual information. Pei et al. work in [3] applies nonnegative matrix tri-
Purity can be formally defined as; factorization with regularization to Twitter data. It makes use
k of user similarity, [tweet x word] and [user x word] matrices
1X
P urity = maxj |Ci ∩ lj | and regularize the objective function with tweet similarity and
n i=1
user connectivity matrices. Complexity of the algorithm is
where k is the number of communities found, n is the number O(rk(mn + mw + nw + m3 + n2 )) where r is the iteration
of instances, lj is the set of instances which belong to the class times. m, n, k, and w denote the number of users, messages,
j, and Ci is the set of instances that are members of community features and communities.
i.
Adjusted Rand Index [14] can be formally defined as; D. Experimental Design
RI − E[RI] First set of experiments test the performance of using
ARI = connectivity-only information for community detection, la-
max(RI) − E[RI]
beled as the Experiment Set 1. We test Louvain and CNM
where algorithms on three different types of connectivity graphs.
s + s0
RI = n
Second set of experiments test the performance of content-
2 only methods, labeled as Experiment Set 2. We test k-means
s is the number of pairs which belong to both same ground- and NMF methods. Third set of experiments test the per-
truth class and identified community. s0 is the number of formance of methods utilizing both connectivity and content
pairs which belong to both different ground-truth classes and information, labeled as Experiment Set 3. We test GNMF and
identified communities. It evaluates the similarity of ground- NMTF frameworks proposed by [3] as baseline algorithms,
truth class labels and clustering result. alongside our proposed MultiNMF, TriNMF and DualNMF
Normalized Mutual Information can be formally defined methods. In user content dimension, we use DualNMF method
as; P (j, i) to test the experiment design that only uses user-word content.
P|l| P|C| We use TriNMF method to test the experiment design that
j=1 i=1 P (j, i)log
P (i)P (j) uses user-hashtag or user-domain information in combination
NMI = p
H(l)H(C) with the user-word information. We use MultiNMF methodTABLE V
to test the experiment design that uses all of user-word, user- I RELAND E XPERIMENT S ET 1 R ESULTS
hashtag and user-domain contents. We label these experiments
Algorithm User Graph k Purity ARI NMI
as Experiment Set 3.1, 3.2 and 3.3 respectively.
R+M 13 .8720 .7277 .6849
Louvain R + ∆M 31 .9186 .7453 .7393
E. Experimental Results R + ∆Mw 31 .9224 .7536 .7518
First, we present statistics of retweets without edits and user R+M 10 .7016 .4509 .4720
mentions on the full and endorsement filtered user connectivity CNM R + ∆M 29 .8333 .6426 .6381
graphs. Table III shows that retweeting without edits indeed R + ∆Mw 29 .8333 .6426 .6381
occurs mostly inside like-minded political camps, rather than
cross-camps. Roughly 97% of retweets in the UK data, and
88% of retweets in the Ireland data occur inside like-minded • Using endorsement filtered user connectivity graph usu-
groups, while these percentages are much lower for users men- ally gives better clustering performance compared to
tions. Our endorsement filtered connectivity network boosts using full user connectivity graph. There is a pattern of
the percentage of inner group user mentions from 83% to weighted graph approach outperforming the others.
97% in the UK data and from 59% to 87% in the Ireland
data evidencing that TSB rule in fact identifies positive user TABLE VI
mentions and retweets with edits with high accuracy. UK E XPERIMENT S ET 2 R ESULTS
Algorithm User Content Purity ARI NMI
TABLE III
DATA ATTRIBUTES k-Means user x word .6738 .2378 .2018
NMF user x word .6395 .1541 .1709
UK Ireland
Inner Group Retweet Links 962 1,652
Inter Group Retweet Links 28 216
TABLE VII
Inner Group Retweet + Mention Links 1,986 3,056 I RELAND E XPERIMENT S ET 2 R ESULTS
Inter Group Retweet + Mention Links 398 2,092
Inner Group Retweet + ∆Mention Links 1,456 2,820 Algorithm User Content Purity ARI NMI
Inter Group Retweet + ∆Mention Links 40 432 k-Means user x word .4651 .0488 .1672
NMF user x word .4186 .0434 .1139
We run each experiment 20 times for every method and pick
the maximum score achieved for reporting. Each regularizer Experiment Set 2 indicates that word usage-only based
parameter (α, γ, θ, β) are experimented with values 1, 10, clustering yields considerably lower accuracies compared to
100 and 1000. Best accuracies are usually reached with user connectivity-only based clustering.
experiments in which α and β equal to 10 or 100 while TABLE VIII
γ and θ equal to 1. This shows the contribution of user UK E XPERIMENT S ET 3 R ESULTS
connectivity and word similarity regularizers, and considerably
Algorithm User Graph User Content Purity ARI NMI
lower contributions of hashtag and domain name regularizers
R+M user x word .7854 .4955 .4120
towards overall performance of the algorithms. GNMF[29] R + ∆M .8069 .6099 .4922
R + ∆Mw .8326 .6469 .5461
TABLE IV
UK E XPERIMENT S ET 1 R ESULTS R+M user x word, .8197 .6448 .2593
NMTF[3] R + ∆M tweet x word .8112 .5657 .2471
Algorithm User Graph k Purity ARI NMI R + ∆Mw .8412 .5331 .3751
R+M 20 .9313 .4661 .5854 R+M user x word, .7597 .3707 .3158
Louvain R + ∆M 42 .9613 .3691 .5916 TriNMF R + ∆M user x domain .7940 .5566 .4595
R + ∆Mw 42 .9484 .4291 .5916 R + ∆Mw .8283 .6375 .5006
R+M 17 .8498 .5656 .5257 R+M user x word, .7897 .5232 .4320
CNM R + ∆M 41 .9700 .6150 .6496 TriNMF R + ∆M user x hashtag .8112 .4640 .3780
R + ∆Mw 41 .9700 .6150 .6496 R + ∆Mw .7768 .5001 .3837
R+M user x word .7554 .4025 .3343
MultiNMF R + ∆M user x domain, .8112 .5726 .4404
Major findings for Experiment Set 1 can be summarized as R + ∆Mw user x hashtag .8112 .6108 .4978
follows: R+M user x word .8326 .5674 .5146
DualNMF R + ∆M .8927 .7291 .6086
• Relatively larger clustering scores occur due to artificially R + ∆Mw .8970 .7616 .6380
large number of clusters that are found. Considering the
number of users in both datasets, the number of clusters
identified in Experiment Set 1 are not practical for use Major findings from Experiment Set 3 can be summarized
(e.g. 29 clusters in Ireland data for 7 political parties). as follows;TABLE IX
I RELAND E XPERIMENT S ET 3 R ESULTS VI. C ONCLUSION
Algorithm User Graph Content Purity ARI NMI In Twitter, content and endorsement filtered connectivity
R+M user x word .5543 .2447 .2881
are complementary to each other in clustering politically
GNMF[29] R + ∆M .6279 .4557 .4652 motivated users into pure political communities. Word usage is
R + ∆Mw .8178 .6978 .6399 the strongest indicator of user’s political orientation among all
R+M user x word, .5969 .3119 .2144 content categories. Incorporating user-word matrix and word
NMTF[3] R + ∆M tweet x word .6860 .3986 .2384 similarity regularizer provides the missing link in connectivity-
R + ∆Mw .7597 .5198 .4469
only methods which suffers from detection of artificially large
R+M user x word, .7209 .5051 .5237 number of clusters in sparse Twitter networks. Our future work
TriNMF R + ∆M user x domain .7946 .6045 .5313
R + ∆Mw .8101 .6807 .6372 includes parallel distributed evolutionary community detection
and identification of emerging coalitions and conflicts among
R+M user x word, .6938 .4202 .4431
TriNMF R + ∆M user x hashtag .7016 .5300 .4224 communities.
R + ∆Mw .8062 .6784 .6885
ACKNOWLEDGMENT
R+M user x word, .7481 .4777 .4938
MultiNMF R + ∆M user x domain, .6744 .4597 .4219 This research was supported by ONR Grants N00014-16-1-
R + ∆Mw user x hashtag .8178 .6953 .6411 2386 and N00014-15-1-2722.
R+M user x word .7364 .5561 .5397
DualNMF R + ∆M .7597 .6292 .6029 R EFERENCES
R + ∆Mw .8721 .7536 .7096
[1] Howard, Philip N., and Aiden Duffy, Deen Freelon, Muzammil Hussain,
Will Mari, and Marwa Mazaid. Opening Closed Regimes: What Was the
Role of Social Media During the Arab Spring? Project on Information
TABLE X Technology and Political Islam Data Memo 2011.1. Seattle: University
C OMPARISON OF M ETHODS FOR E XPERIMENT S ET 3 of Washington, 2011.
[2] Girvan,M., Newman M.E.J. (2002). Community structure in social and
Connectivity biological networks, Proceedings of the National Academy of Sciences,
R+M 3R + ∆Mw 99(12), pp.7821-7826.
3word DualNMF 33DualNMF [3] Yulong Pei, Nilanjan Chakraborty, and Katia Sycara. 2015. Nonnegative
word, matrix tri-factorization with graph regularization for community detection
TriNMF 3TriNMF
Content hashtag or domain in social networks. In Proceedings of the 24th International Conference on
word, Artificial Intelligence (IJCAI’15), Qiang Yang and Michael Wooldridge
MultiNMF 3MultiNMF
hashtag and domain (Eds.). AAAI Press 2083-2089.
[4] J. Tang, X. Wang, and H. Liu. Integrating Social Media Data for
Community Detection. In Modeling and Mining Ubiquitous Social Media,
2012.
[5] Mrinmaya Sachan, Danish Contractor, Tanveer A. Faruquie, and L.
• Regardless of the experiment set and algorithms used, Venkata Subramaniam. 2012. Using content and interactions for dis-
endorsement filtered user connectivity graph yields higher covering communities in social networks. In Proceedings of the 21st
international conference on World Wide Web (WWW ’12). ACM, New
accuracy clustering performance compared to using the York, NY, USA, 331-340.
full connectivity graph. Usually weighted graph approach [6] Y. Ruan, D. Fuhry, and S. Parthasarathy. Efficient community detection
outperforms the others. in large networks using content and links. In WWW 13, 2013.
[7] Tufekci, Z. (2014). Big Questions for Social Media Big Data: Represen-
• DualNMF method which factorizes user-word matrix tativeness, Validity and Other Methodological Pitfalls. In: International
alongside user connectivity and word similarity regular- AAAI Conference on Weblogs and Social Media.
izers yields the highest accuracy clustering performance. [8] M. D. Conover, B. Goncalves, J. Ratkiewicz, M. Francisco, A. Flammini,
and F. Menczer, Political polarization on Twitter, in Proceedings of the
• We get much higher scores of clustering accuracy in 5th InternationalConference on Weblogs and Social Media, 2011
Experiment Set 3 compared to Experiment Set 2. Reg- [9] Sandra Gonzlez-Bailn, Ning Wang, Alejandro Rivero, Javier Borge-
ularizing content-only methods with user connectivity Holthoefer, Yamir Moreno, Assessing the bias in samples of large online
networks, Social Networks, Volume 38, July 2014, Pages 16-27, ISSN
graphs(GNMF [29]), dramatically increases the quality 0378-8733, http://dx.doi.org/10.1016/j.socnet.2014.01.004.
of the clustering. DualNMF which incorporates keyword [10] S. A. Myers, A. Sharma, P. Gupta, and J. Lin. Information network
similarity regularization to GNMF further boosts the or social network? The structure of the Twitter follow graph. WWW
Companion, 2014
quality of clustering. [11] Heider F. The psychology of interpersonal relations. New York: Wiley,
• Compared to DualNMF method, including tweet mes- 1958. 322 p.
sages for NMTF method proposed in [3] does not help to [12] Felix Ming Fai Wong, Chee Wei Tan, Soumya Sen, and Mung Chiang.
2013. Quantifying political leaning from tweets and retweets. In Proceed-
further improve the clustering quality, while it increases ings of the International AAAI Conference on Weblogs and Social Media
complexity dramatically. DualNMF provides 9% addi- (ICWSM).
tional purity, 46% additional ARI score while doubling [13] D. Boyd, S. Golder and G. Lotan, ”Tweet, Tweet, Retweet: Conver-
the NMI score compared to the baseline NMTF method sational Aspects of Retweeting on Twitter,” System Sciences (HICSS),
2010 43rd Hawaii International Conference on, Honolulu, HI, 2010, pp.
of Pei et al. in [3]. 1-10. doi: 10.1109/HICSS.2010.412
• Compared to DualNMF method, utilizing hashtag and/or [14] Hubert, L., Arabie, P. (1985). Comparing partitions. Journal of Classi-
domain usage information (i.e. TriNMF and MultiNMF) fication, 2, 193218.
[15] Stephen Boyd and Lieven Vandenberghe. Convex optimization. Cam-
do not contribute to the overall clustering quality. bridge University Press, Cambridge, 2004.[16] M. Newman. 2006. Modularity and community structure in networks. A PPENDIX
Proceedings of the National Academy of Sciences, vol. 103, no. 23, pp. D ERIVATION OF E QUATIONS 2, 3, 4, 5
85778582.
[17] S. Fortunato. 2010. Community detection in graphs. Physics Reports, To follow the conventional theory of constrained optimiza-
vol. 486, pp. 75174 tion we rewrite objective function 1 as;
[18] Vincent D Blondel, Jean-Loup Guillaume, Renaud Lambiotte, Etienne
Lefebvre. Fast unfolding of communities in large networks. Journal of JU,H,D,W = T r((Xuw − UWT )(Xuw − UWT )T )
Statistical Mechanics: Theory and Experiment 2008 (10), P10008 (12pp) + T r((Xuh − UHT )(Xuh − UHT )T )
doi: 10.1088/1742-5468/2008/10/P10008.
[19] A. Clauset, M. Newman, and C. Moore, Finding com- + T r((Xud − UDT )(Xud − UDT )T )
munity structure in very large networks, Physical Re-
view E, vol. 70, p. 066111, 2004. [Online]. Available:
+ αT r(UT LC U) + γT r(HT LHsim H)
http://www.citebase.org/cgibin/citations?id=oai:arXiv.org:cond- + θT r(DT LDsim D) + βT r(WT LWsim W)
mat/0408187
[20] Waltman, L., Van Eck, N. J.. 2013. A smart local moving algorithm JU,H,D,W = T r(Xuw XTuw ) − 2T r(Xuw WUT )
for large-scale modularity-based community detection. European Physical + T r(UWT WUT ) + T r(Xuh XTuh )
Journal B, 86, 471.
[21] Lloyd., S. P. (1982). ”Least squares quantization in PCM” − 2T r(Xuh HUT ) + T r(UHT HUT )
(PDF). IEEE Transactions on Information Theory 28 (2): 129137.
doi:10.1109/TIT.1982.1056489
+ T r(Xud XTud ) − 2T r(Xud DUT ) + T r(UDT DUT )
[22] Daniel D. Lee, H. Sebastian Seung. 2000. Algorithms for Non-negative + αT r(UT LC U) + γT r(HT LHsim H)
Matrix Factorization. In Neural Information Processing Systems (NIPS),
Vol. 13 , pp. 556-562.
+ θT r(DT LDsim D) + βT r(WT LWsim W)
[23] C. J. Lin. On the Convergence of Multiplicative Update Algo- Let Φ, η, Ω and Ψ be the Lagrangian multipliers for constraints
rithms for Nonnegative Matrix Factorization. In IEEE Transactions on
Neural Networks, vol. 18, no. 6, pp. 1589-1596, Nov. 2007. doi: U, H, D, W > 0 respectively. So the Lagrangian function L
10.1109/TNN.2007.895831 becomes;
[24] Yuan Yao, Hanghang Tong, Guo Yan, Feng Xu, Xiang Zhang,
Boleslaw K. Szymanski, and Jian Lu. 2014. Dual-Regularized One- L = T r(Xuw XTuw ) − 2T r(Xuw WUT ) + T r(UWT WUT )
Class Collaborative Filtering. In Proceedings of the 23rd ACM In- + T r(Xuh XTuh ) − 2T r(Xuh HUT ) + T r(UHT HUT )
ternational Conference on Conference on Information and Knowledge
Management (CIKM ’14). ACM, New York, NY, USA, 759-768. + T r(Xud XTud ) − 2T r(Xud DUT ) + T r(UDT DUT )
DOI=http://dx.doi.org/10.1145/2661829.2662042
[25] Linhong Zhu, Aram Galstyan, James Cheng, and Kristina Lerman.
+ αT r(UT LC U) + γT r(HT LHsim H) + θT r(DT LDsim D)
2014. Tripartite graph clustering for dynamic sentiment analysis on + βT r(WT LWsim W) + T r(ΦUT ) + T r(ηHT )
social media. In Proceedings of the 2014 ACM SIGMOD International
Conference on Management of Data (SIGMOD ’14). ACM, New York, + T r(ΩDT ) + T r(ΨWT )
NY, USA, 1531-1542. DOI=http://dx.doi.org/10.1145/2588555.2593682
[26] Quanquan Gu and Jie Zhou. 2009. Co-clustering on manifolds. In The partial derivatives of Lagrangian function L with respect
Proceedings of the 15th ACM SIGKDD international conference on to U, H, D, W are as follows;
Knowledge discovery and data mining (KDD ’09). ACM, New York,
∂L
NY, USA, 359-368. DOI=http://dx.doi.org/10.1145/1557019.1557063 = −2Xuw W + 2UWT W − 2Xuh H + 2UHT H−
[27] Fanhua Shang, L. C. Jiao, and Fei Wang. 2012. Graph ∂U
dual regularization non-negative matrix factorization for co- 2Xud D + 2UDT D + 2αLC U + Φ
clustering. Pattern Recogn. 45, 6 (June 2012), 2237-2250.
∂L
DOI=http://dx.doi.org/10.1016/j.patcog.2011.12.015 = −2XTuh H + 2UHT H + 2γLHsim H + η
[28] Chris Ding, Tao Li, Wei Peng, and Haesun Park. 2006. Orthogonal ∂H
nonnegative matrix t-factorizations for clustering. In Proceedings of the ∂L
12th ACM SIGKDD international conference on Knowledge discovery = −2XTud H + 2UDT D + 2θLDsim D + Ω
∂D
and data mining (KDD ’06). ACM, New York, NY, USA, 126-135.
∂L
DOI=http://dx.doi.org/10.1145/1150402.1150420 = −2XTuw U + 2WUT U + 2βLWsim W + Ψ
[29] D. Cai, X. He, J. Han and T. S. Huang, Graph Regularized Nonnegative ∂W
Matrix Factorization for Data Representation, in IEEE Transactions on Setting derivatives equal to zero and using KKT com-
Pattern Analysis and Machine Intelligence, vol. 33, no. 8, pp. 1548-1560,
Aug. 2011. doi: 10.1109/TPAMI.2010.231
plementarity conditions [15] of nonnegativity of matrices
U, H, D, W, ΦU = 0, ηH = 0, ΩD = 0 and ΨW = 0,
[30] Wei Xu, Xin Liu, and Yihong Gong. 2003. Document clustering based
on non-negative matrix factorization. In Proceedings of the 26th annual we get the update rules given in Equations 2, 3, 4, 5.
international ACM SIGIR conference on Research and development in
informaion retrieval (SIGIR ’03). ACM, New York, NY, USA, 267-273.
DOI=http://dx.doi.org/10.1145/860435.860485
[31] Zhou, Quanquan Gu Jie. Local learning regularized nonnegative matrix
factorization. IJCAI 2009, Proceedings of the 21st International Joint
Conference on Artificial Intelligence, Pasadena, California, USA, July
11-17, 2009
[32] Linhong Zhu, Aram Galstyan, James Cheng, and Kristina Lerman. Tri-
partite graph clustering for dynamic sentiment analysis on social media.
In Proceedings of the 2014 ACM SIGMOD International Conference on
Management of Data, pages 1531-1542. ACM, 2014.You can also read