Documents Representation via Generalized Coupled Tensor Chain with the Rotation Group Constraint
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Documents Representation via Generalized Coupled Tensor Chain
with the Rotation Group Constraint
Igor Vorona, Anh-Huy Phan, Alexander Panchenko and Andrzej Cichocki
Skolkovo Institute of Science and Technology, Moscow, Russia
{igor.vorona,a.phan, a.panchenko, a.cichocki}@skoltech.ru
Abstract at the cost of loss of some interpretability and the
cost of increased computation time.
Continuous representations of linguistic struc- However, there exist other ways to utilize higher-
tures are an important part of modern natu- order interactions and still preserve the efficiency
ral language processing systems. Despite the of linear models. In this research, we focus on more
diversity, most of the existing log-multilinear
data-oriented, i.e., more linguistic grounded, and
embedding models are organized under vector
operations. However, these operations can not better interpretable methods which still can achieve
precisely represent the compositionality of nat- high results in the practical tasks. Particularly, we
ural language due to a lack of order-preserving investigate the matrix-space model of language, in
properties. In this work, we focus on one of which semantic space consists of square matrices
the promising alternatives based on the embed- of real values. The key idea behind this method
ding of documents and words in the rotation goes from realization of the Frege’s principle of
group through the generalization of the cou-
compositionality through order-preserving prop-
pled tensor chain decomposition to the expo-
nential family of the probability distributions. erty of matrix operations. As shown by Rudolph
In this model, documents and words are rep- and Giesbrecht (2010), this type of models can in-
resented as matrices, and n-grams representa- ternally combine various properties from statistical
tions are combined from word representations and symbolic models of natural language and there-
by matrix multiplication. The proposed model fore it is more flexible than vector space models.
is optimized via noise-contrastive estimation. In spite of that fact, such models are usually hard
We show empirically that capturing word or-
to optimize on the real data. To this end, Yesse-
der and higher-order word interactions allows
our model to achieve the best results in several
nalina and Cardie (2011) took attention to the needs
document classification benchmarks. of nontrivial initialization and proposed to learn the
weights by the bag-of-words model. Asaadi and
1 Introduction Rudolph (2017) used complex multi-stage initial-
ization based on unigrams and bigrams scoring.
The current progress in natural language process- Both approaches try to solve the sentiment anal-
ing systems is largely based on the success of the ysis task. Recently Mai et al. (2019) considered
representation learning of linguistic structures such the problem of self-supervised continuous repre-
as word, sentence and document embeddings. The sentation of words via matrix-space models. They
most promising and successful methods are based optimized a modified word2vec objective function
on learning representations via two types of models: (Mikolov et al., 2013) and proposed a novel initial-
shallow log-multilinear models and deep neural ization by adding small isotropic Gaussian noise to
networks. Despite the efficiency and interpretabil- the identity matrix.
ity of log-multilinear models, they can not use In this paper, we use a similarity function be-
higher-order linguistic features like dependency tween matrices similar to Mai et al. (2019), but
between subsequences of words. To avoid these instead of neural network type of learning, we im-
disadvantages, we usually use nonlinear predictors plement the model as the coupled tensor chain and
like recurrent, recursive, convolution neural net- impose the rotation group constraint. We focus on
works, and more recently Transformers. Neverthe- the document representation problem. Given a doc-
less, these methods can achieve high performance ument collection, we try to find unsupervised doc-
1674
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1674–1684
August 1–6, 2021. ©2021 Association for Computational Linguisticsument and word representation suitable for down- tensor for computation of compositionality. The
stream linear classification tasks. To this end, we most similar to our task is the word embedding
represent words, n-grams and documents as ma- problem. In this direction, Sharan and Valiant
trices and train self-supervised model. Our intu- (2017) explored the Canonical Polyadic Decom-
ition is based on the fact that modeling interaction position (CPD) of word triplet tensor. Bailey and
between words and documents is insufficient for Aeron (2017) used symmetric CPD of pointwise
modeling relations between complex phrases and mutual information tensor. Frandsen and Ge (2019)
documents. extended the RAND-WALK model (Arora et al.,
Contributions. The main contributions of this 2016) to word triplets. The main drawback of exist-
work can be summarized as follows: ing approaches is that they can not preserve word
• To the best of our knowledge, this is the first order information of long n-grams properly. For
representation learning method based on the example, in the case of the CPD, we need to use
Riemannian geometry of matrix groups. separate parameters for each word based on its po-
sition in the text. This restriction does not allow
• We show that our approach to model the com- us to efficiently use the linguistic meaning of ten-
positionality and word order allows us to in- sor modes. The symmetric CPD completely loses
crease the quality of document embedding on word order information and the Tucker model suf-
downstream tasks. Moreover, it is also more fers from exponentially increasing parameter size
computationally efficient in comparison with in the case of long length n-grams. Our approach
neural network models. eliminates these disadvantages.
• Our model achieves state-of-the-art perfor-
mance on the task of representation learning 3 Problem and model description
for multiclass classification both on short and In this section, we describe our model for the doc-
long document datasets. ument representation task. We begin with a short
introduction of the multilinear algebra, then present
Our implementation of the proposed model is
the proposed document modeling framework in
available online1 .
the view of the coupled tensor decomposition and
2 Related work provide the detailed description of our model and
indicate benefits/drawbacks which are related to
Euclidean embedding models (Mikolov et al., rotational group constraints.
2013; Pennington et al., 2014) based on implicit
word-context co-occurance matrix factorization 3.1 Basic multilinear algebra
(Levy and Goldberg, 2014) are an important frame- A tensor is a higher-order generalization of vectors
work for current NLP tasks. Proposed models and matrices to multiple indices. The order of a
achieve relatively high performance in various NLP tensor is the number of dimensions, also known
tasks like text classification (Kim, 2014), named as modes or ways. An N -th order tensor is rep-
entity recognition (Lample et al., 2016), machine resented as X ∈ RI1 ×I2 ×···×IN , and its element
translation (Cho et al., 2014). is denoted as xi1 ...iN . We can always represent a
Riemannian embedding models have shown tensor X as sum of rank-1 tensors, where each of
promising results by expanding embedding meth- them is defined as outer product of N -vectors, i.e.,
ods beyond Euclidean geometry. There are sev- a(1) ◦ · · · ◦ a(N ) and a(n) ∈ RIn for n = 1, . . . , N .
eral models with negative sectional curvature like The minimal number of rank-1 tensors in this sum
Poincare (Dhingra et al., 2018; Nickel and Kiela, defines tensor rank.
2017) and Lorentz models (Nickel and Kiela, 2018). In this research we focus on a particular type of
Furthermore, Meng et al. (2019) proposed a text tensor decomposition called tensor chain (Perez-
embedding model based on spherical geometry. Garcia et al., 2007; Khoromskij, 2011; Zhao et al.,
Tensor decomposition models have been applied 2019). It represents tensor via the following sum
to many tasks in the NLP. Particularly, Van de of rank-1 tensors
Cruys et al. (2013) proposed the Tucker model
R1X
,...,RN
for decomposing subject-verb-object co-occurance
X= a(1) (N )
r1 r2 ◦ · · · ◦ arN r1 , (1)
1
https://github.com/harrycrow/RDM r1 ,...,rN =1
1675Notation Description gram distribution as with the separate distribution
a Scalar of the single random variable rather than define
a Vector or tuple joint distribution for all n-grams sets and assume
A Matrix that particular distribution for each n-gram set can
A Higher-order tensor be constructed through marginalization from this
◦ Outer (tensor) product joint distribution.
⊗ Kronecker product Following this intuition for each n-gram set, n,
tr(·) Trace of matrix we assign appropriate joint distribution, p(w, d),
vec(·) Vectorization of tensor where w ∈ Wn and d ∈ D. We represent co-
[·]+ Euclidean projection onto occurrence of each n-gram, w = (w1 , . . . , wn ),
nonnegative orthant, i.e., max{0, ·} and each document, d ∈ D, as (n + 1)th-order
QR(·) QR decomposition tensor X(wd) ∈ R|W|×···×|W|×|D| , where
Table 1: Basic notation. (
(wd) 1, if i = w, j = d
xij = (3)
0, otherwise .
where R1 , . . . , RN are called ranks of the TC
model and the element-wise form of the follow- Then we represent probability p(w, d) as the mean
ing decomposition is given by of these tensors
(1) (2) (N )
xi1 i2 ...iN = tr(Ai1 Ai2 · · · AiN ), (2) X̄
(n)
= E(w,d)∼p(w,d) X(wd) .
(n)
and Ain ∈ RRn ×Rn+1 represents the in -th frontal
Note that co-occurrences of n-grams and doc-
slice of the core tensors A(n) ∈ RRn ×In ×Rn+1 for uments define bipartite graphs between them and
(n)
n = 1, . . . , N and RN +1 = R1 and arn rn+1 are (n)
X̄ can be interpreted as adjacency tensors of
tubes of A(n) . these graphs.
3.2 Document modelling setting
3.3 Proposed model
In our research, we use the fact that the same text
can be represented in different ways via differ- Following compositional matrix-space modelling
ent sets of n-grams with fixed lengths {Wn }N approach we represent each word, w ∈ W, as a
n=1 , R×R , a n-gram, w ∈ Wn , as
matrix U Qwn ∈ R
n
where W = W | × ·{z
· · × W} and W is the word set.
n Uw = k=1 Uwk , and each document, d ∈ D,
The main hypothesis is that the occurance statistics as a matrix Vd ∈ RR×R . To measure dependence
of the each of these n-grams sets contains some new between n-gram, w, and document, d, we use the
information about this text, which can not be ex- Frobenius inner product, defined as hUw , Vd iF =
tracted from any other n-grams set. If we combine tr(UTw Vd ) = tr(Uw VdT ) = vec(Uw )T vec(Vd ).
information from all of these sets we can achieve We assume that embeddings organized accordingly
better quality for our document embedding model. to this operation can be suitable for linear classi-
Due to the fact that the occurrence of the se- fiers.
quence of words depends on the occurrence of each The resulting model is the generalized to expo-
word from this sequence, it is reasonable to treat the nential family of probability distributions coupled
distribution of each fixed-length n-grams set sep- tensor decomposition (Collins et al., 2001; Yilmaz
arately. Otherwise, by the reason of dependence (n)
et al., 2011) of the set of tensors {X̄ }N n=1 by
between the length of word sequence and their fre- the corresponding set of tensor chain models with
quency, small length n-grams can downweight the restricted set of parameters
importance of long length n-grams. Thus the effect
|W| |D|
of higher-order interaction can become low. Also, Θ = {Uw }w=1 ∪ {Vd }d=1 , (4)
we notice that consider p(w) as a distribution over
unordered sets is a quite restrictive assumption on in the following optimization problem
the structure of the model due to the importance N
of the order of the words in the language seman- X (n) (n)
min KL[X̄ ||X̂ ; Θ], (5)
tics. For all these reasons, we work with each n- Θ
n=1
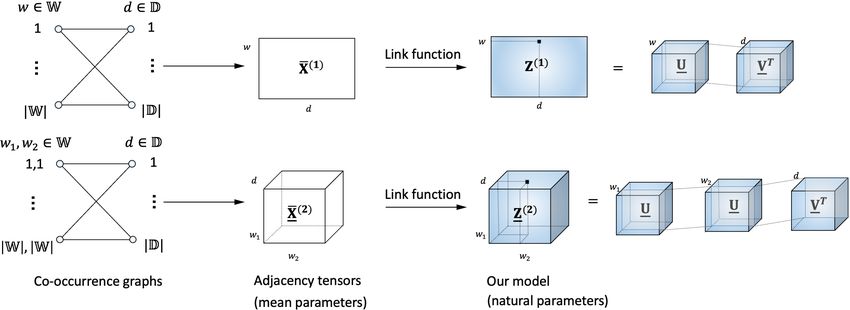
1676Figure 1: Illustration of representation of document collection in a multi-view way as a collection of bipartite
graphs. Each of these graphs represents dependence (number of co-occurrence) between word’s strings of length
n
n and documents. Adjacency matrices X̄(n) ∈ R|W| ×|D| of these graphs can be appropriately tensorized to
(n)
adjacency tensors X̄ ∈ R|W|×···×|W|×|D| which can be linked through modified multinomial link function with
(n)
latent tensors Z ∈ R|W|×···×|W|×|D| . Latent tensors can be decomposed via the Coupled Tensor Chain model.
In our model, all core tensors U (VT ) which represent words (documents) are additionally restricted to have the
|W| |D|
same parameters {Uw }w=1 ({VdT }d=1 ).
where each Kullback-Leibler divergence can be and Tsvetkov, 2019; Meng et al., 2019) enforcing
expressed as the spherical geometry constraints is a promising
! choice for tasks focusing on directional similar-
(n)
(n) (n) X X (n) x̄ wd ity. For doing so it can be reasonable to constrain
KL[X̄ ||X̂ ; Θ] = x̄wd log (n)
x̂wd our model to the orthogonal group. In this case
w∈Wn d∈D
Frobenius inner product became proper similarity
|W | |W | |D| (n)
!
X X X (n) x̄w1 ...wn d measure and the sequential matrix product always
= ··· x̄w1 ...wn d log (n)
,
x̂w1 ...wn d preserves fixed norm and group structure (i.e., in-
w1 =1 wn =1 d=1
vertibility of matrix multiplication). Due to the
(n)
and x̂wd = p(w, d). group structure, our model has an interesting prop-
Our model represents p(w, d) by using follow- erty to uniquely determine each word in the n-gram
ing mean function by their left and right aggregated context matrices
and general n-gram matrix.
p(w, d) ∝ p(w)p(d) exp(vec(X(wd) )T vec(Z(n) )), However, orthogonal group is a disjoint set of
two connected components: set of rotations
(n)
where vec(X(wd) )T vec(Z(n) ) = zwd is one of
natural parameters, which organized in the la- SO(R) = {A|AT A = AAT = I, det(A) = +1}
tent tensors Z(n) ∈ R|W|×···×|W|×|D| . This latent
tensors contain pointwise mutual information be- and set of reflections {A|AT A = AAT =
tween n-grams and documents and we assume that I, det(A) = −1}. We impose constraints on our
each of this tensor has low tensor chain rank, i.e., model parameters enforcing rotation matrices since
(n)
zwd = tr(Uw VdT ). the product of any number of rotations is always
rotation, i.e. rotation set forms a matrix group.
3.4 Intuition from geometric interpretation
While the product of an even number of reflections
If we avoid generative assumptions (Saunshi et al., becomes rotation.
2019), our task can be interpreted as maximizing
the similarity between document d and n-grams 3.5 Noise-contrastive estimation
from its document distribution p(w|d) with simul-
taneous minimization of similarity between this In practice we do not need to construct set of ten-
(n) (n)
document and n-grams from common n-gram distri- sors {X̄ }N n=1 explicitly. Instead, since each X̄
bution p(w). As shown in previous works (Kumar represents a higher-order frequency table, we can
1677optimize the sum of MLE tasks: Stiefel manifold we can swap two columns for each
(1) (N )
parameter matrix if the determinant of the this ma-
Ew,d∼X̄(1) log(x̂wd ) + · · · + Ew,d∼X̄(N ) log(x̂wd ). trix is -1. However, this initialization can be below
optimal way, because these rotation matrices can be
Usually, we have huge amount of data which make
far away from each other and due to the non-trivial
problem of computing partition function for each
(n) structure of the loss function on this manifold we
x̂wd intractable for many current computing ar- can stuck in local minima. To overcome this prob-
chitectures. We can avoid this problem by us- lem, we can fix particular point on the manifold for
ing noise-contrastive estimation (Gutmann and all matrices and perform small movement from this
Hyvärinen, 2012) for conditional model (Ma and point in arbitrary direction. We use following strat-
Collins, 2018). Similar to Chen et al. (2017), we |W| |D|
egy for each parameter A ∈ {Uw }w=1 ∪{Vd }d=1 :
construct negative samples from our batch by con-
necting non-linked n-grams and documents. Fi-
nally, for parameter set 1
A0 ∼ N 0, 2
|W| |D| R
Θ = {Uw }w=1 ∪ {Vd }d=1 ∪ {κ(n) }N
n=1 , (6)
1 T (9)
[Q, R] = QR I + (A0 − A0 )
we formulate optimization problem in the follow- 2
ing way: A = Q.
N N
X λ X (n) 2 We initialize all concentration parameters us-
min L(n) (Θ) + (κ ) (7) ing following equation κ(n) = R u
, where u ∼
Θ 2
n=1 n=1
U(0.9, 1.1) and n = 1, . . . , N .
s.t. Uw ∈ SO(R), w = 1, . . . , |W|
Vd ∈ SO(R), d = 1, . . . , |D| 4.3 Riemannian optimization
κ(n) ≥ 0, n = 1, . . . , N, We solve our problem on the product manifold
of rotation group and nonnegative orthant by
where each risk function is equal to simultaneous optimization of model parameters
|W| |D|
{Uw }w=1 ∪ {Vd }d=1 and {κ(n) }N n=1 by Rieman-
L(n) (Θ) = E{(w ,d )}I QI (n)
i i i=1 ∼ i=1 x̄w
i di nian (Bécigneul and Ganea, 2019) and projected
exp κ(n) tr(Uwi VdTi ) Adagrad (Duchi et al., 2011) respectively.
(8)
− log P . Let M be a real smooth manifold and L : M →
I (n) tr(U VT )
j=1 exp κ wj di R a smooth real-valued function over parameters
θ ∈ M. Riemannian gradient descent (Gabay,
We add concentration parameters κ(n) to our 1982; Absil et al., 2008) based on two sequential
loss function to overcome the problem of fixed steps. At first we compute Riemannian gradient
scale. This makes our model more flexible to rep- by orthogonal projection of the Euclidean gradient
resent sharp distributions. Due to the fact that each on the tangent space at the same point on which
n-gram distribution has its own scale, it can be rea- we compute Euclidean gradient by projθt : R →
sonable to have a different κ(n) for different n-gram Tθ M
distributions.
∇R L(θ t ) = projθt (∇E L(θ t )), (10)
4 Optimization setup
and then we perform movement on the manifold
4.1 N-gram construction
by specific curve, which called retraction Rθt :
We construct n-grams from text corpora by using se- Tθ M → M
quentially moving of the sliding window of length
n (from 1 to N ) inside each document. θ t+1 = Rθt (−α∇R L(θ t )). (11)
4.2 Parameters initialization For optimization on rotation group the orthogonal
Initialization from the uniform distribution on the projector of matrix G ∈ RR×R on the tangent
Stiefel manifold (Saxe et al., 2014) is one of promis- space at the point A ∈ SO(R) is given by:
ing ways to initialize deep neural network. To ini- 1
tialize parameters only from rotation component of projA (G) = (G − AGT A), (12)
2
1678For movement on the manifold in this direction we Bi-LSTM models like ELMo, our model has lower
use QR-based retraction: complexity on embedding dimension, and can be
computed in parallel using the associativity prop-
[Q, R] = QR (At − α∇R L(At )) erty of matrix multiplication. Although our model
(13)
At+1 = Q. has a higher theoretical time complexity than the
vector space models, the real gap between them is
We choose the QR-based retraction because it al- relatively small at ordinary embedding dimension
lows Riemannian Adagrad to achieve the fastest (∼ 400).
convergence in our experiments in comparison
with Cayley retraction (first-order), Polar retraction Method Time Space
(second-order), and geodesic (matrix exponential). PV-DBOW O(kd) O(d)
PV-DM (Concat) O(kd) O(kd)
ELMo O(kld2 ) O(ld2 )
Algorithm 1 Optimization algorithm for RDM BERT O(k 2 hld) O(khld)
Input: Learning rates α and β, number of itera- RDM (Ours) O(kd1.5 ) O(d)
tions T , maximum n-gram length N .
|W|
Output: Embedding parameters {Uw }w=1 ∪ Table 2: Comparison of time and space complexity of
|D|
{Vd }d=1 and {κ(n) }N n=1 .
several document embedding models, where k - size of
for t = 1 to T do . after computing gradients: context window, d - embedding dimension, l - number
|W| |D| of layers, h - number of heads. The time complexity of
for all At ∈ {Uw }w=1 ∪ {Vd }d=1 do
PN other discussed here vector space models is equivalent
∇E L(At ) = n=1 ∇E L(n) (At ) to the complexity of PV-DBOW.
∇R L(At ) ← (12) with ∇E L(At )
α
αt = qP
t 2 5 Numerical experiments
i=1 k∇R L(Ai )kF
At+1 ← (13) with αt 5.1 Experimental setup
end for
Downstream Linear Protocol. We estimate
for n = 1 to N do
(n) (n) (n) quality of pre-trained representations on the multi-
grad(κt ) = ∇E L(n) (κt ) + λκt class document categorization tasks on the 20
(n)
(n) (n) grad(κt ) Newsgroups and the ArXiv based long document
κt+ 1 = κt − β q
2 Pt 2 (n) dataset (He et al., 2019). We choose these datasets
i=1 grad (κi )
for our benchmarks because they are significantly
(n) (n)
κt+1 = κt+ 1 different in the document’s average length. This im-
2 +
plies that statistics of long n-grams differ between
end for
these datasets too and in the case of the ArXiv
end for
dataset statistics of n-grams are significantly bet-
ter converged than in the case of 20 newsgroups.
This fact allow us to hypothesize that matrix-space
4.4 Computational efficiency models should less overfit on the ArXiv dataset.
The computational complexity of our model de- We fix the document embeddings and optimize
pends on the complexity R3 of multiplication of multinomial logistic regression with SAGA opti-
matrices of size R × R, and QR decomposition mizer and l2 -norm regularization. Instead of test
4 3
3 R (Layton and Sussman, 2020; Trefethen and set we use nested 10-fold cross-validation to esti-
III, 1997). Due to the number of elements in these mate statistical significance using Wilcoxon signed-
matrices d = R2 , we can transform the complexity rank test (Japkowicz and Shah, 2011; Dror et al.,
of our model in the dimension of embedding. In 2018). For each fold we estimate the hyperparam-
this view, the time complexity is O(kd1.5 ), where eter of l2 -regularization on 10 point logarithmic
k is the size of the context window. As shown in grid from 0.01 to 100 by using additional 10-fold
Table (2), our model has computational benefits cross-validation with macro-averaged F1 score. For
in comparison with Transformer due to the linear text preprocessing, we use CountVectorizer from
dependence of time complexity on the word se- the Scikit-learn package. Additionally we remove
quence length. We note that in comparison with words which occur in the NLTK stopwords list or
1679occur only in 1 document. In the case of ArXiv vectors from BERT model ”bert-base-uncased”.
dataset we use half of this dataset and use only Following Devlin et al. (2019) we take the last layer
documents in the range from 1000 to 5000 words hidden state corresponding to the [CLS] token as
(smaller documents are removed and bigger docu- the aggregate document representation. If length of
ments are reduced to the first 5000 words). document is bigger than 512 we cut document on
512-length parts and average representation of this
Dataset #cls |W| |D| #w parts. Finally, we add Sentence BERT (Reimers
20 Newsgroups 20 75752 18846 180 and Gurevych, 2019) to the baseline models. This
ArXiv 6 251108 16371 3829 model is fine-tuned on SNLI and MultiNLI datasets
Table 3: Datasets considered in the paper, where #cls for sentence embedding generation. We use 768-
- number of classes, #w - average number of words in dimensional embedding vectors from model ”bert-
documents, |W| - vocabulary size, |D| - number of doc- base-nli-mean-tokens”.
uments. We do not perform fine-tuning of BERT and
ELMo models for our datasets, because in our ex-
periments it doesn’t give any positive effect on
Baselines. We compare our model with differ- the final performance of these models. However,
ent vector space models: paragraph vectors (Le this is not true for Sentence BERT. Fine-tuning
and Mikolov, 2014), weighted combinations of slightly improve performance of this model on the
the word2vec skipgram vectors (Mikolov et al., 20 newsgroup (50 epoch with maximum margin
2013) (average, TF-IDF and SIF (Arora et al., triplet loss).
2017)), Doc2vecC (Chen, 2017), sent2vec (Pagliar- We should notice that this experimental design
dini et al., 2018) and recently proposed JoSe (Meng gives some benefits to neural network models in
et al., 2019). The comparison with the last two of comparison with log-multilinear models, but it is
these models seems to be more informative than more consistent with the ordinary practical use case
with others because of some similarity of these of the Transformers and RNN models. However,
models to our model (sent2vec can use n-gram in- the next experiment will show that log-multilinear
formation and JoSe also based on the spherical type models can still outperform pre-trained neural net-
of embedding geometry). works.
Due to the large number of possible values of hy-
perparameters for each model, we used the default Ablation study. For ablation study, we use dif-
values proposed by the authors of these models or ferent settings of our model. RDM means rotation
proposed in subsequent studies of these models like document model, i.e. our model. RDM-R means
in the case of paragraph vectors (Lau and Baldwin, our model without rotation group constraints. By
2016). We modify only the min count to 1 and (1) we mean model which utilize only unigrams
window size to be equal to the number of negative and documents co-occurance information. By (3)
samples for paragraph2vec and word2vec models and (5) we mean model which utilizes informa-
because it gives better results for these methods in tion from (1, 2, 3)-grams and (1, 2, 3, 4, 5)-grams
our experiments. We choose n-grams number equal respectively. For RDM, we use 1e-2 and 1e-3 as
to 1 for sent2vec, because other values doesn’t im- learning rates of Radagrad and projected Adagrad
prove results. To preserve the fairness of compar- respectively and we use λ = 15 for 20 newsgroups
ison we use fixed embedding dimension, number and change λ to 5 for ArXiv dataset due to smaller
of negative samples, and number of epochs for all number of epoch in this experiment. For RDM-R
models including ours. These values try to mimic we use 1e-2 as learning rate for Adagrad.
the usual values of these hyperparameters in prac-
tice. 5.2 Experimental results and comparison of
We compare our model not only with vector mod- performance
els but also with neural network models. We use Comparison to baselines. As one may observe
5.5B ELMo (Peters et al., 2018) version which in the Table (4), our models yield results compara-
is pre-trained on Wikipedia (1.9B) and all of the ble or outperforming the baseline methods, includ-
monolingual news crawl data from WMT 2008- ing the simpler log-multilinear models (e.g. Skip-
2012 (3.6B). ELMo embedding dimension is equal gram) and more complex models featuring nonlin-
to 1024. Also we use 768-dimensional embedding ear transformations, such as recurrences (ELMo)
1680Models 20 Newsgroups ArXiv
Acc Prec Rec F1 Acc Prec Rec F1
PV-DBOW 88.7 88.4 88.2 88.2 89.1 89.2 89.2 89.2
PV-DM 77.2 76.8 76.5 76.5 42.2 42.3 42.0 41.9
Skipgram+Average 90.3 90.2 90.0 90.0 92.4 92.3 92.3 92.3
Skipgram+TF-IDF 90.4 90.2 90.1 90.1 92.6 92.5 92.4 92.4
Skipgram+SIF 90.4 90.2 90.1 90.1 92.4 92.3 92.3 92.3
Sent2vec 87.9 87.6 87.5 87.5 91.9 91.7 91.7 91.7
Doc2vecC 90.0 89.8 89.7 89.7 93.2 93.1 93.1 93.1
JoSe 87.8 87.6 87.4 87.4 91.3 91.3 91.2 91.2
ELMo 79.2 78.8 78.8 78.7 91.6 91.5 91.4 91.4
BERT 74.3 73.6 73.6 73.5 92.3 92.2 92.1 92.1
Sentence BERT 79.5 79.1 79.0 79.0 89.0 88.9 88.8 88.8
RDM-R (1) 86.8 86.4 86.3 86.3 94.0∗ 93.9 ∗ 93.8∗ 93.8∗
∗
RDM-R (3) 87.9 87.6 87.4 87.4 94.5∗ 94.4 94.4∗ 94.4∗
RDM-R (5) 88.3 88.0 87.9 87.9 94.6∗ 94.4∗ 94.4∗ 94.4∗
RDM (1) 89.3 89.2 89.0 89.0 94.0∗ 93.9∗ 93.9∗ 93.9∗
RDM (3) 90.7 90.5 90.4 90.4 94.0∗ 93.9∗ 93.9∗ 93.9∗
RDM (5) 91.1∗ 90.9 ∗ 90.8 ∗ 90.8∗ 94.0∗ 93.9∗ 93.9∗ 93.9∗
Table 4: Text classification performance on the 20 Newsgroups (short documents) and on the modified ArXiv (long
documents) datasets. We fix the number of epochs to 50, the embedding dimension to 400, and the number of neg-
ative samples to 15 for all models on the 20 Newsgroups. On the ArXiv dataset, we use the same hyperparameters
except for only the number of epochs which is equal to 5. We use macro-average for Precision, Recall, and F1.
and transformer blocks (BERT, SentenceBERT). can see the model without rotation constraints is
More specifically, on the 20 newsgroups, the RDM less robust in respect to noisy statistics of small doc-
(5) model yields the best results significantly2 out- ument dataset and achieve performance less than
performing all the listed baseline approaches. It is the PV-DBOW model, while the rotation group
interesting that contrary to the 20 Newsgroups, all model outperforms all other models. However,
RDM variants with any number of the n-grams sets once we move on to a dataset with a larger doc-
show strong results and significantly outperform ument’s average length (ArXiv), RDM-R performs
other models on the ArXiv dataset. Weighted com- better than all other models, including RDM. This
binations of the skipgram vectors and doc2vecC confirms our hypothesis that the existence of good
model achieve the closest to our result. This con- statistics of long n-grams has critical value for
firms that neural models like ELMo and BERT, are matrix space models. Due to strong associativ-
not the best way for all datasets and log-multilinear ity between sets of n-grams, our model needs more
models can outperform them. We can see that per- parameters to approximate all the co-occurrences.
formance of nonlinear models increase if we use The RDM-R has a higher number of degrees of
a large document dataset and BERT can outper- freedom than the RDM R2 vs R(R−1) 2 . We think
form some of the log-multilinear approaches (PV- that it allows RDM-R to outperform RDM in this
DBOW, JoSe and sent2vec), but still, its result is experiment. This intuition can be also confirmed
not on the top level. by the fact that RDM (1) and RDM-R (1) have the
same performance level. And only if we increase
Comparison between our models. On observ- the number of n-grams for the model from 1 to
ing the results we can see that our model increase 3, then RDM-R can achieve better performance.
the performance of classification when adding the However, if we increase the number of n-grams set
n-gram set with a bigger length. This property has from 3 to 5 both models stay on the same level of
both models with rotation group constraints and performance. This is the sign that we need to use a
without such constraints. Despite this fact, as we bigger embedding dimension if we want to achieve
2
We use ∗ if the comparison of our model with the baseline even better results.
models has p < 0.05.
1681In summary, if we have short documents, it’s Shima Asaadi and Sebastian Rudolph. 2017. Gradual
better to use RDM. For long document dataset with learning of matrix-space models of language for sen-
timent analysis. In Proceedings of the 2nd Workshop
restriction on the embedding dimension, we sug-
on Representation Learning for NLP, pages 178–
gest to relax the rotation group constraints. This 185, Vancouver, Canada. Association for Computa-
trick allows RDM to use more degrees of freedom tional Linguistics.
to estimate data precisely.
Eric Bailey and Shuchin Aeron. 2017. Word
6 Conclusion embeddings via tensor factorization. CoRR,
abs/1704.02686.
In this paper, we proposed a novel unsupervised
Gary Bécigneul and Octavian-Eugen Ganea. 2019. Rie-
representation learning method based on the gener- mannian adaptive optimization methods. In 7th
alized tensor chain with rotation group constraints, International Conference on Learning Representa-
which can utilize higher-order word interactions tions, ICLR 2019, New Orleans, LA, USA, May 6-9,
and preserve most part of the computational effi- 2019. OpenReview.net.
ciency and interpretability of vector-based mod- Minmin Chen. 2017. Efficient vector representation
els. Our model achieves state-of-the-art results in for documents through corruption. In 5th Inter-
the document classification benchmarks on the 20 national Conference on Learning Representations,
ICLR 2017, Toulon, France, April 24-26, 2017, Con-
newsgroups and modified ArXiv dataset. A further
ference Track Proceedings. OpenReview.net.
direction of research could be focused on adding
tensor kernel functions to the model to eliminate Ting Chen, Yizhou Sun, Yue Shi, and Liangjie Hong.
problems with dependence on the dimension of 2017. On sampling strategies for neural network-
based collaborative filtering. In Proceedings of the
embedding. It could be interesting to augment 23rd ACM SIGKDD International Conference on
this type of model with the different loss functions Knowledge Discovery and Data Mining, Halifax,
based not only on n-gram-document interactions NS, Canada, August 13 - 17, 2017, pages 767–776.
but also on word-word interactions from the knowl- ACM.
edge graph or document-document interaction from Kyunghyun Cho, Bart van Merriënboer, Caglar Gul-
the citation graph of the documents. cehre, Dzmitry Bahdanau, Fethi Bougares, Holger
Schwenk, and Yoshua Bengio. 2014. Learning
Acknowledgments phrase representations using RNN encoder–decoder
for statistical machine translation. In Proceedings of
The Zhores supercomputer (Zacharov et al., 2019) the 2014 Conference on Empirical Methods in Nat-
was used for computations. This research was ural Language Processing (EMNLP), pages 1724–
partially supported by the Ministry of Educa- 1734, Doha, Qatar. Association for Computational
Linguistics.
tion and Science of the Russian Federation
(grant 14.756.31.0001). The work of Alexander Michael Collins, Sanjoy Dasgupta, and Robert E.
Panchenko was partially supported by the MTS- Schapire. 2001. A generalization of principal com-
Skoltech laboratory. ponents analysis to the exponential family. In Ad-
vances in Neural Information Processing Systems
14 [Neural Information Processing Systems: Natu-
ral and Synthetic, NIPS 2001, December 3-8, 2001,
References Vancouver, British Columbia, Canada], pages 617–
Pierre-Antoine Absil, Robert E. Mahony, and 624. MIT Press.
Rodolphe Sepulchre. 2008. Optimization Algo-
rithms on Matrix Manifolds. Princeton University Tim Van de Cruys, Thierry Poibeau, and Anna Korho-
Press. nen. 2013. A tensor-based factorization model of se-
mantic compositionality. In Proceedings of the 2013
Sanjeev Arora, Yuanzhi Li, Yingyu Liang, Tengyu Ma, Conference of the North American Chapter of the
and Andrej Risteski. 2016. A latent variable model Association for Computational Linguistics: Human
approach to PMI-based word embeddings. Transac- Language Technologies, pages 1142–1151, Atlanta,
tions of the Association for Computational Linguis- Georgia. Association for Computational Linguistics.
tics, 4:385–399.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Sanjeev Arora, Yingyu Liang, and Tengyu Ma. 2017. Kristina Toutanova. 2019. BERT: Pre-training of
A simple but tough-to-beat baseline for sentence em- deep bidirectional transformers for language under-
beddings. In 5th International Conference on Learn- standing. In Proceedings of the 2019 Conference
ing Representations, ICLR 2017, Toulon, France, of the North American Chapter of the Association
April 24-26, 2017, Conference Track Proceedings. for Computational Linguistics: Human Language
OpenReview.net. Technologies, Volume 1 (Long and Short Papers),
1682pages 4171–4186, Minneapolis, Minnesota. Associ- Guillaume Lample, Miguel Ballesteros, Sandeep Sub-
ation for Computational Linguistics. ramanian, Kazuya Kawakami, and Chris Dyer. 2016.
Neural architectures for named entity recognition.
Bhuwan Dhingra, Christopher Shallue, Mohammad In Proceedings of the 2016 Conference of the North
Norouzi, Andrew Dai, and George Dahl. 2018. Em- American Chapter of the Association for Computa-
bedding text in hyperbolic spaces. In Proceedings tional Linguistics: Human Language Technologies,
of the Twelfth Workshop on Graph-Based Methods pages 260–270, San Diego, California. Association
for Natural Language Processing (TextGraphs-12), for Computational Linguistics.
pages 59–69, New Orleans, Louisiana, USA. Asso-
ciation for Computational Linguistics. Jey Han Lau and Timothy Baldwin. 2016. An empiri-
cal evaluation of doc2vec with practical insights into
Rotem Dror, Gili Baumer, Segev Shlomov, and Roi Re- document embedding generation. In Proceedings
ichart. 2018. The hitchhiker’s guide to testing statis- of the 1st Workshop on Representation Learning for
tical significance in natural language processing. In NLP, pages 78–86, Berlin, Germany. Association for
Proceedings of the 56th Annual Meeting of the As- Computational Linguistics.
sociation for Computational Linguistics (Volume 1:
Long Papers), pages 1383–1392, Melbourne, Aus- William Layton and Myron Sussman. 2020. Numerical
tralia. Association for Computational Linguistics. Linear Algebra. WSPC.
John C. Duchi, Elad Hazan, and Yoram Singer. 2011. Quoc V. Le and Tomás Mikolov. 2014. Distributed
Adaptive subgradient methods for online learning representations of sentences and documents. In
and stochastic optimization. J. Mach. Learn. Res., Proceedings of the 31th International Conference
12:2121–2159. on Machine Learning, ICML 2014, Beijing, China,
21-26 June 2014, volume 32 of JMLR Workshop
Abraham Frandsen and Rong Ge. 2019. Understanding and Conference Proceedings, pages 1188–1196.
composition of word embeddings via tensor decom- JMLR.org.
position. In 7th International Conference on Learn-
ing Representations, ICLR 2019, New Orleans, LA, Omer Levy and Yoav Goldberg. 2014. Neural word
USA, May 6-9, 2019. OpenReview.net. embedding as implicit matrix factorization. In Ad-
vances in Neural Information Processing Systems,
Daniel Gabay. 1982. Minimizing a differentiable func- volume 27, pages 2177–2185. Curran Associates,
tion over a differential manifold. Journal of Opti- Inc.
mization Theory and Applications, 37:177–219.
Zhuang Ma and Michael Collins. 2018. Noise con-
Michael Gutmann and Aapo Hyvärinen. 2012. Noise-
trastive estimation and negative sampling for condi-
contrastive estimation of unnormalized statistical
tional models: Consistency and statistical efficiency.
models, with applications to natural image statistics.
In Proceedings of the 2018 Conference on Empirical
J. Mach. Learn. Res., 13:307–361.
Methods in Natural Language Processing, Brussels,
Jun He, Liqun Wang, Liu Liu, Jiao Feng, and Hao Wu. Belgium, October 31 - November 4, 2018, pages
2019. Long document classification from local word 3698–3707. Association for Computational Linguis-
glimpses via recurrent attention learning. IEEE Ac- tics.
cess, 7:40707–40718.
Florian Mai, Lukas Galke, and Ansgar Scherp. 2019.
Nathalie Japkowicz and Mohak Shah, editors. 2011. CBOW is not all you need: Combining CBOW with
Evaluating Learning Algorithms: A Classification the compositional matrix space model. In 7th Inter-
Perspective. Cambridge University Press. national Conference on Learning Representations,
ICLR 2019, New Orleans, LA, USA, May 6-9, 2019.
Boris N. Khoromskij. 2011. O(dlogn)-quantics approx- OpenReview.net.
imation of n-d tensors in high-dimensional numeri-
cal modeling. Constructive Approximation, 34:257– Yu Meng, Jiaxin Huang, Guangyuan Wang, Chao
280. Zhang, Honglei Zhuang, Lance M. Kaplan, and Ji-
awei Han. 2019. Spherical text embedding. In Ad-
Yoon Kim. 2014. Convolutional neural networks vances in Neural Information Processing Systems
for sentence classification. In Proceedings of the 32: Annual Conference on Neural Information Pro-
2014 Conference on Empirical Methods in Natural cessing Systems 2019, NeurIPS 2019, December
Language Processing (EMNLP), pages 1746–1751, 8-14, 2019, Vancouver, BC, Canada, pages 8206–
Doha, Qatar. Association for Computational Lin- 8215.
guistics.
Tomás Mikolov, Ilya Sutskever, Kai Chen, Gregory S.
Sachin Kumar and Yulia Tsvetkov. 2019. Von mises- Corrado, and Jeffrey Dean. 2013. Distributed rep-
fisher loss for training sequence to sequence models resentations of words and phrases and their com-
with continuous outputs. In 7th International Con- positionality. In Advances in Neural Information
ference on Learning Representations, ICLR 2019, Processing Systems 26: 27th Annual Conference on
New Orleans, LA, USA, May 6-9, 2019. OpenRe- Neural Information Processing Systems 2013. Pro-
view.net. ceedings of a meeting held December 5-8, 2013,
1683Lake Tahoe, Nevada, United States, pages 3111– Nikunj Saunshi, Orestis Plevrakis, Sanjeev Arora,
3119. Mikhail Khodak, and Hrishikesh Khandeparkar.
2019. A theoretical analysis of contrastive unsuper-
Maximilian Nickel and Douwe Kiela. 2018. Learning vised representation learning. In Proceedings of the
continuous hierarchies in the lorentz model of hy- 36th International Conference on Machine Learn-
perbolic geometry. In Proceedings of the 35th In- ing, ICML 2019, 9-15 June 2019, Long Beach, Cali-
ternational Conference on Machine Learning, ICML fornia, USA, volume 97 of Proceedings of Machine
2018, Stockholmsmässan, Stockholm, Sweden, July Learning Research, pages 5628–5637. PMLR.
10-15, 2018, volume 80 of Proceedings of Machine
Learning Research, pages 3776–3785. PMLR. Andrew M. Saxe, James L. McClelland, and Surya
Ganguli. 2014. Exact solutions to the nonlinear dy-
Maximillian Nickel and Douwe Kiela. 2017. Poincaré namics of learning in deep linear neural networks.
embeddings for learning hierarchical representa- In 2nd International Conference on Learning Rep-
tions. In I. Guyon, U. V. Luxburg, S. Bengio, resentations, ICLR 2014, Banff, AB, Canada, April
H. Wallach, R. Fergus, S. Vishwanathan, and R. Gar- 14-16, 2014, Conference Track Proceedings.
nett, editors, Advances in Neural Information Pro-
cessing Systems 30, pages 6338–6347. Curran Asso- Vatsal Sharan and Gregory Valiant. 2017. Orthogonal-
ciates, Inc. ized ALS: A theoretically principled tensor decom-
position algorithm for practical use. In Proceedings
Matteo Pagliardini, Prakhar Gupta, and Martin Jaggi. of the 34th International Conference on Machine
2018. Unsupervised learning of sentence embed- Learning, volume 70 of Proceedings of Machine
dings using compositional n-gram features. In Pro- Learning Research, pages 3095–3104, International
ceedings of the 2018 Conference of the North Amer- Convention Centre, Sydney, Australia. PMLR.
ican Chapter of the Association for Computational
Linguistics: Human Language Technologies, Vol- Lloyd N. Trefethen and David Bau III. 1997. Numeri-
ume 1 (Long Papers), pages 528–540, New Orleans, cal Linear Algebra, first edition. SIAM: Society for
Louisiana. Association for Computational Linguis- Industrial and Applied Mathematics.
tics.
Ainur Yessenalina and Claire Cardie. 2011. Compo-
Jeffrey Pennington, Richard Socher, and Christopher sitional matrix-space models for sentiment analysis.
Manning. 2014. GloVe: Global vectors for word In Proceedings of the 2011 Conference on Empiri-
representation. In Proceedings of the 2014 Confer- cal Methods in Natural Language Processing, pages
ence on Empirical Methods in Natural Language 172–182, Edinburgh, Scotland, UK. Association for
Processing (EMNLP), pages 1532–1543, Doha, Computational Linguistics.
Qatar. Association for Computational Linguistics.
Yusuf Kenan Yilmaz, Ali Taylan Cemgil, and Umut
David Perez-Garcia, Frank Verstraete, Michael M. Simsekli. 2011. Generalised coupled tensor factori-
Wolf, and J. Ignacio Cirac. 2007. Matrix prod- sation. In Advances in Neural Information Process-
uct state representations. Quantum Info. Comput., ing Systems 24: 25th Annual Conference on Neural
7(5):401–430. Information Processing Systems 2011. Proceedings
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt of a meeting held 12-14 December 2011, Granada,
Gardner, Christopher Clark, Kenton Lee, and Luke Spain, pages 2151–2159.
Zettlemoyer. 2018. Deep contextualized word rep-
Igor Zacharov, Rinat Arslanov, Maksim Gunin, Daniil
resentations. In Proceedings of the 2018 Confer-
Stefonishin, Andrey Bykov, Sergey Pavlov, Oleg
ence of the North American Chapter of the Associ-
Panarin, Anton Maliutin, Sergey Rykovanov, and
ation for Computational Linguistics: Human Lan-
Maxim Fedorov. 2019. Zhores — petaflops super-
guage Technologies, Volume 1 (Long Papers), pages
computer for data-driven modeling, machine learn-
2227–2237, New Orleans, Louisiana. Association
ing and artificial intelligence installed in skolkovo
for Computational Linguistics.
institute of science and technology. Open Engineer-
Nils Reimers and Iryna Gurevych. 2019. Sentence- ing, 9(1):512–520.
BERT: Sentence embeddings using Siamese BERT-
networks. In Proceedings of the 2019 Conference on Qibin Zhao, Masashi Sugiyama, Longhao Yuan, and
Empirical Methods in Natural Language Processing Andrzej Cichocki. 2019. Learning efficient ten-
and the 9th International Joint Conference on Natu- sor representations with ring-structured networks.
ral Language Processing (EMNLP-IJCNLP), pages In IEEE International Conference on Acoustics,
3982–3992, Hong Kong, China. Association for Speech and Signal Processing, ICASSP 2019,
Computational Linguistics. Brighton, United Kingdom, May 12-17, 2019, pages
8608–8612. IEEE.
Sebastian Rudolph and Eugenie Giesbrecht. 2010.
Compositional matrix-space models of language. In
Proceedings of the 48th Annual Meeting of the As-
sociation for Computational Linguistics, pages 907–
916, Uppsala, Sweden. Association for Computa-
tional Linguistics.
1684You can also read

















































