UNIFYING REMOTE SENSING IMAGE RETRIEVAL AND CLASSIFICATION WITH ROBUST FINE-TUNING
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
UNIFYING REMOTE SENSING IMAGE RETRIEVAL AND CLASSIFICATION WITH
ROBUST FINE-TUNING
Dimitri Gominski a,b , Valérie Gouet-Brunet a , Liming Chen b
a b
Univ. Gustave Eiffel, IGN/ENSG - LaSTIG École Centrale Lyon - LIRIS
dimitri.gominski@ign.fr, valerie.gouet@ign.fr, liming.chen@ec-lyon.fr
arXiv:2102.13392v1 [cs.CV] 26 Feb 2021
ABSTRACT Browsing the litterature, we noted a variety of relatively
small datasets and methods in RSIR and RSC, with saturated
Advances in high resolution remote sensing image analysis performance (>95% mAP or accuracy) on most of them.
are currently hampered by the difficulty of gathering enough However, most of these methods are trained and tested on
annotated data for training deep learning methods, giving rise a single small dataset, with varying train/test splits. To our
to a variety of small datasets and associated dataset-specific knowledge, and according to a review comparing RSIR meth-
methods. Moreover, typical tasks such as classification and ods [4], no method has been proven better than pretrained
retrieval lack a systematic evaluation on standard benchmarks CNNs when evaluating on an ensemble of remote sensing
and training datasets, which make it hard to identify durable datasets. To better represent real world conditions, we argue
and generalizable scientific contributions. We aim at uni- that 1) RSIR and RSC performance evaluation should be done
fying remote sensing image retrieval and classification with on a standard benchmark reflecting all possible image varia-
a new large-scale training and testing dataset, SF3001 , in- tions, 2) the lack of such a benchmark encourages system-
cluding both vertical and oblique aerial images and made atic performance evaluation on several datasets (with varying
available to the research community, and an associated fine- spatial resolution especially), 3) RSC can be considered as
tuning method. We additionally propose a new adversarial a special case of RSIR, which makes us consider RSIR as a
fine-tuning method for global descriptors. We show that our ”driving” task of remote sensing image comprehension.
framework systematically achieves a boost of retrieval and
classification performance on nine different datasets com- In this work, we propose to address these issues with a
pared to an ImageNet pretrained baseline, with currently no unified RSIR and RSC fine-tuning framework.
other method to compare to. Our first contribution is the proposal of SF300, a new
large-scale dataset of aerial oblique and vertical images. It
1. INTRODUCTION features 308k images in the train set and 22k in the test set,
with a class and vertical orientation label for each image. The
The technological advances in remote sensing and rising in- 27k unique classes depict various urban and semi-urban lo-
terest in geographical data are generating a growing volume cations. We include a comparison of the proposed dataset
of high resolution images. Two important tasks of remote with 9 other commonly used datasets in RSIR and RSC. In-
sensing are remote sensing scene classification (RSC) or land- spired by parallel propositions in landmark retrieval, we build
use classification, and remote sensing image retrieval (RSIR), a fine-tuning framework using SF300, and show that it yields
with the goal of providing fast and accurate understanding competitive performance for 8 out of these 9 RSIR datasets.
and management of remote sensing image databases. Simi- As a second contribution, we propose an addition to the
larly to general purpose classification and content-based im- fine-tuning framework for enforcing descriptor robustness to
age retrieval (CBIR), these tasks have both recently benefited the vertical orientation variation, which relies on the adver-
from advances in image processing with Convolutional Neu- sarial training paradigm. We show that it brings improvement
ral Networks (CNN). The ”gold standard” for image analysis of test performance on our dataset, and on several of the 9
consists in a backbone network pretrained on ImageNet [1] compared datasets.
and fine-tuned on a dataset related to the target task, used to
extract activation tensors, which are then processed to extract The paper is organized as follows. Section 2 gives an
global descriptors or perform classification. overview of methods in CBIR and the issues of remote sens-
However, as concluded by [2] and [3], RSIR and RSC lack ing data. Section 3 introduces the new SF300 dataset, on
a truly large scale dataset that would allow fine-tuning. which we propose a new method for robust descriptor ex-
traction in section 4. Section 5 details our experiments and
1 URL coming soon discussion, and we conclude in section 6.2. RELATED WORK
We divide our literature review in two parts : first propositions
in general-purpose CBIR (as later shown in sections and 3.2
and 5.2, this is relevant for remote sensing images), before
addressing the specific case of remote sensing images.
2.1. Advances in Content-Based Image Retrieval
Inspired by parallel propositions in all-purpose CBIR, we de-
tail here important technical considerations for designing a
RSIR/RSC fine-tuning framework.
Fine-tuning boosts test performance significantly because
it allows adaptation of the convolutional filters to the speci-
ficities of the target dataset, but should be done with a dataset
both clean [5], i.e. with reasonnable intraclass variation, and Fig. 1: Examples of images from the SF300 dataset. The
large, i.e. with enough interclass variation, as concluded by images of the same column belong to the same class. Con-
[6]. tains data from Styrelsen for dataforsyning og effektivisering,
A pooling layer is typically used to efficiently select ”Skraafoto”, November 2018.
meaningful activations in the last layers and get compact de-
scriptors. Global approches generally extract a single vec-
tor per image by sum pooling (SPoC) [7], maximum pooling
Danish Institute of Data Supply and Efficiency Improve-
(MAC) [8] or generalized-mean pooling (GeM) which is a
ment (SDFE) in open-access. The SF300 dataset consists of
generalization of the two previous methods with a new learn-
512x512 pixels images, with 308353 images in 27502 classes
able parameter [9].
in the train set, and 21844 images in 2421 classes in the test
The choice of the loss function for performing the fine-
set. Each class corresponds to a real-world square footprint,
tuning step, and in fine, the whole training process, is a matter
and is composed of a varying number of either vertical (cam-
of debate: some works use the standard cross-entropy loss
era pointing the nadir direction) or oblique images (camera
with softmax normalization for simplicity [5, 26, 27] or its
directed with known angle) of this geographical location. The
enhanced variation ArcFace [28] enforcing better interclass
dataset is available to the research community, for the train-
separation ; others insist on the fact that the retrieval problem
ing and testing of classification and retrieval methods, with an
is fundamentally a ranking problem and thus prefer a pairwise
emphasis on (known) vertical orientation variation.
loss [9] or a triplet-wise loss [29].
2.2. Remote Sensing 3.1. Dataset construction
Works on adapting CNNs for remote sensing images have pro- Following a whole country aerial acquisition by planes
posed strategies to transfer features from pretrained CNNs equipped with 5-angle cameras, the source images
[19], or to fine-tune them efficiently with limited data [23, 25]. are available at the address https://skraafoto.
A common approach to boost performance is to fuse features kortforsyningen.dk/. We first collected all available
from different models to enhance discriminability [20, 22, high-resolution (∼100MP) images in a set of selected urban
21]. and semi-urban areas. Using the provided footprint coordi-
Adressing the specificity of remote sensing images, [24] nates, we matched n-tuples of images covering approximately
designed an attention module focusing on objects typically the same zone. To enhance precision, we manually aligned
found in remote sensing images to boost scene classification the images by picking a common point for all images in each
performance. [18] designed a discriminative training loss tak- tuple. We then computed the homography matrices linking
ing into account the high intraclass variation. pixel coordinates to real-world coordinates for each image,
We note that all of these works were trained and tested on which allowed an automated cropping of tuples into a varying
different datasets, and the corresponding code is rarely avail- number of smaller images of fixed size. Available parameters
able, which severely limits reproducibility and comparison. for the source images were propagated to the smaller images
and stored in a .csv file for each class. This process was
3. SF300 DATASET repeated on a smaller number of other locations to create
the test set. We believe that image retrieval aims at handling
We introduce a new large-scale aerial imagery dataset con- any image including ones belonging to classes unseen at
structed using raw high-resolution images provided by the train time, and therefore build the test set with new classes,Table 1: Comparison of remote-sensing image datasets and state of the art performance with Overall Accuracy (OA) for classification and mean Average Precision (mAP) for retrieval, using indicated ratio for train/test splits. Dataset name AID [4] BCS [10] PatternNet [11] RESISC45 [12] RSI-CB [13] RSSCN7 [14] SIRI-WHU [15] UCM [16] WHU-RS19 [17] SF300-train SF300-test Classes 30 2 38 45 35 7 12 21 19 27502 2421 Images per class 200-400 1438 800 700 609 400 200 100 50 2-46 2-15 Images total 10,000 2,876 30,400 31,500 24,747 2,800 2,400 2,100 1,005 308,553 21844 Spatial resolution (m) 0.5-0.8 N/A 0.062-4.693 0.2-30 0.3 - 3 N/A 2 0.3
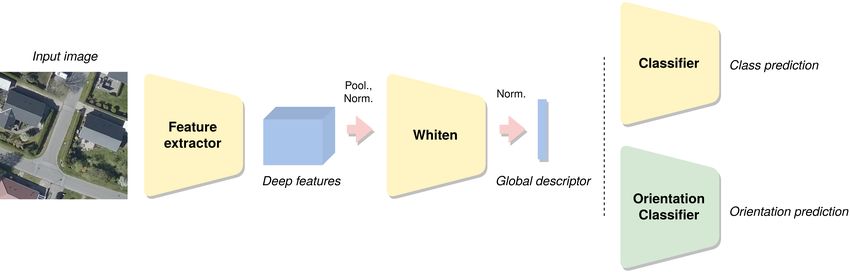
Fig. 2: Architecture diagram. Our fine-tuning baseline using the GeM descriptor is depicted in yellow, consisting of a Feature
extractor, a whitening network (Whiten), and a Classifier to allow training of descriptors using class labels. Our proposed
adversarial fine-tuning method adds an Orientation Classifier depicted in green.
4.2. Adversarial fine-tuning 5.1. Implementation details
Our main hypothesis is that variations in input images are also The orientation classifier is trained for 5 iterations before up-
entangled with deep features, which impacts the quality of dating the feature extractor. We found this adjustement to be
global descriptors and thus retrieval accuracy. crucial for getting better results : the orientation classifier can
To enforce robustness and gain accuracy for the retrieval be seen as a discriminator that needs to be trained to near op-
task, we propose to use an adversarial framework, adding an timality to provide useful gradients to the feature extractor.
orientation classifier Co . The orientation classifier outputs Database search for testing is performed using the dot
logits for the 5 possible orientation values that we transform product as the similarity measure, with no additional index-
into probabilities with a softmax layer. Similarly to Lclass , ing method or post-processing steps.
we define Lo as the cross-entropy loss for orientation predic- Parameter α is set to 6.10−4 following a parameter sweep.
tion. C is still optimized through Lclass , and Co is optimized
following: 5.2. Evaluation
We use the mean Average Precision (mAP) [32] to measure
Co → min(Lo ) (2) C → min(Lclass ) (3)
retrieval performance. Additionally, as stated in section 1, re-
trieval can be used as a proxy for classification with a very
But F and W are now jointly optimized to minimize simple labeling scheme: each query image is assigned the
Lclass while maximizing Lo : most frequently occurring label in the first k images. Choos-
ing k = 1 in the following, we measure classification accu-
F, C → min(Lclass − αLo ) (4) racy with the Overall Accuracy (OA), which is equivalent to
the mean Precision at first rank (mP@1).
α is a weighting parameter, of which we experimentally Table 2 displays the measured performance of the four
set the value. models we compare, accross the nine datasets we introduced
in section 3 and SF300.
We report systematic improvement of the performance
5. EXPERIMENTS when using models fine-tuned on SF300 (with the exception
of precision for BCS, which can be considered not signifi-
This section is dedicated to the evaluation of performance be- cant considering the size of the dataset and the margin), com-
tween a baseline with no fine-tuning (ImageNet weights), a pared to the ImageNet pretrained model. This indicates that
baseline trained from scratch on SF300, a baseline with fine- SF300 is a relevant dataset for fine-tuning classification and
tuning on SF300, and our proposed adversarial fine-tuning CBIR methods on remote sensing data. The margin varies
framework. Section 5.1 presents the technical details of train- fromMetric Model AID BCS PatternNet RESISC45 RSI-CB RSSCN7 SIRI-WHU UCM WHU-RS19 SF300 Mean
Retrieval
Pretrained 34.52 62.93 61.43 29.04 68.50 39.98 45.10 53.46 68.80 16.25 48.00
Scratch 24.91 64.42 51.19 17.87 57.66 43.01 35.58 37.61 53.28 77.91 46.34
mAP (%)
FT 39.87 61.44 68.93 30.41 68.88 49.13 47.35 54.57 72.42 87.66 58.07
AdvFT 39.72 66.95 71.52 31.04 67.60 49.27 47.96 57.43 71.77 91.50 59.48
Classification
Pretrained 82.55 84.42 96.06 79.78 98.40 84.79 87.00 93.05 85.26 52.79 84.41
Scratch 71.21 83.45 94.88 69.78 97.92 85.04 83.75 89.1 72.63 95.51 84.33
OA/mP@1 (%)
FT 86.58 83.48 97.96 85.12 99.11 90.75 92.46 95.43 87.89 97.41 91.62
AdvFT 85.61 84.39 98.33 86.30 98.95 89.57 91.00 96.00 89.47 98.27 91.79
Table 2: Results of the four compared models accross remote sensing datasets. Pretrained refers to a baseline pretrained on
ImageNet with no additional fine-tuning, Scratch refers to a baseline fully trained from scratch on SF300, FT refers to a baseline
with fine-tuning on SF300, AdvFT refers to our proposed amelioration with adversarial fine-tuning on SF300.
90% mAP and OA) indicates Evaluation of Aerial Scene Classification,” IEEE Trans-
that the train and test sets are correctly matched, but leaves actions on Geoscience and Remote Sensing, vol. 55, no.
small room for improvement. We thus suggest using the test 7, pp. 3965–3981, July 2017.
split as a validation split when fine-tuning. [5] Artem Babenko, Anton Slesarev, Alexandr Chigorin,
and Victor Lempitsky, “Neural Codes for Image Re-
6. CONCLUSIONS trieval,” in LNCS, 2014, vol. 8689.
[6] Raffaele Imbriaco, Clint Sebastian, Egor Bondarev, and
In this article, we have proposed two contributions in the do- Peter de With, “Aggregated Deep Local Features for
main of remote sensing image analysis. We first introduced Remote Sensing Image Retrieval,” Remote Sensing, vol.
the new SF300 large-scale dataset for training and testing re- 11, no. 5, pp. 493, 2019, Publisher: MDPI AG.
trieval and classification of remote sensing images. Secondly, [7] Artem Babenko and Victor S. Lempitsky, “Aggregating
we proposed a simple adversarial fine-tuning framework, to Local Deep Features for Image Retrieval,” in 2015 IEEE
enforce robustness to orientation variations in global descrip- International Conference on Computer Vision (ICCV),
tors. The framework was experimented and validated with 2015, pp. 1269–1277.
the global descriptor GeM, but it can be quickly adapted to [8] Hossein Azizpour, Ali Sharif Razavian, Josephine Sul-
any current state-of-the-art global descriptor. Our results con- livan, Atsuto Maki, and Stefan Carlsson, “From generic
firmed the added value of this framework when applied to to specific deep representations for visual recognition,”
several remote sensing datasets. in 2015 IEEE Conference on Computer Vision and Pat-
tern Recognition Workshops (CVPRW), June 2015, pp.
7. REFERENCES 36–45, ISSN: 2160-7516.
[9] F. Radenović, G. Tolias, and O. Chum, “Fine-Tuning
[1] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hin- CNN Image Retrieval with No Human Annotation,”
ton, “ImageNet Classification with Deep Convolutional IEEE Transactions on Pattern Analysis and Machine In-
Neural Networks,” in Advances in Neural Information telligence, vol. 41, no. 7, pp. 1655–1668, 2019.
Processing Systems 25, pp. 1097–1105. 2012. [10] Otávio AB Penatti, Keiller Nogueira, and Jefersson ADos Santos, “Do deep features generalize from ev- for Classification of Benchmark High-Resolution Image
eryday objects to remote sensing and aerial scenes do- Data Sets,” IEEE Geoscience and Remote Sensing Let-
mains?,” in Proceedings of the IEEE conference on com- ters, vol. 15, no. 9, pp. 1451–1455, Sept. 2018.
puter vision and pattern recognition workshops, 2015, [21] Nouman Ali, Bushra Zafar, Faisal Riaz, Saadat
pp. 44–51. Hanif Dar, Naeem Iqbal Ratyal, Khalid Bashir Ba-
[11] Weixun Zhou, Shawn Newsam, Congmin Li, and Zhen- jwa, Muhammad Kashif Iqbal, and Muhammad Sajid,
feng Shao, “PatternNet: A Benchmark Dataset for “A Hybrid Geometric Spatial Image Representation for
Performance Evaluation of Remote Sensing Image Re- scene classification,” PLoS ONE, vol. 13, no. 9, Sept.
trieval,” ISPRS Journal of Photogrammetry and Remote 2018.
Sensing, 2018. [22] Qiqi Zhu, Yanfei Zhong, Liangpei Zhang, and Deren Li,
[12] Gong Cheng, Junwei Han, and Xiaoqiang Lu, “Re- “Scene Classification Based on the Fully Sparse Seman-
mote Sensing Image Scene Classification: Benchmark tic Topic Model,” IEEE Transactions on Geoscience and
and State of the Art,” Proceedings of the IEEE, vol. Remote Sensing, vol. 55, no. 10, pp. 5525–5538, Oct.
105, no. 10, pp. 1865–1883, Oct. 2017. 2017.
[13] Haifeng Li, Xin Dou, Chao Tao, Zhixiang Wu, Jie [23] Gong Cheng, Ceyuan Yang, Xiwen Yao, Lei Guo, and
Chen, Jian Peng, Min Deng, and Ling Zhao, “RSI- Junwei Han, “When Deep Learning Meets Metric
CB: A Large-Scale Remote Sensing Image Classifica- Learning: Remote Sensing Image Scene Classification
tion Benchmark Using Crowdsourced Data,” Sensors, via Learning Discriminative CNNs,” IEEE Transactions
vol. 20, no. 6, pp. 1594, Jan. 2020. on Geoscience and Remote Sensing, vol. 56, no. 5, pp.
[14] Qin Zou, Lihao Ni, Tong Zhang, and Qian Wang, “Deep 2811–2821, May 2018.
Learning Based Feature Selection for Remote Sensing [24] Qi Wang, Shaoteng Liu, Jocelyn Chanussot, and Xue-
Scene Classification,” IEEE Geoscience and Remote long Li, “Scene Classification With Recurrent Attention
Sensing Letters, vol. 12, no. 11, pp. 2321–2325, Nov. of VHR Remote Sensing Images,” IEEE Transactions
2015. on Geoscience and Remote Sensing, vol. 57, no. 2, pp.
[15] Bei Zhao, Yanfei Zhong, Gui-Song Xia, and Liangpei 1155–1167, Feb. 2019.
Zhang, “Dirichlet-Derived Multiple Topic Scene Clas-
[25] Lili Fan, Hongwei Zhao, and Haoyu Zhao, “Distribu-
sification Model for High Spatial Resolution Remote
tion Consistency Loss for Large-Scale Remote Sensing
Sensing Imagery,” IEEE Transactions on Geoscience
Image Retrieval,” Remote Sensing, vol. 12, no. 1, pp.
and Remote Sensing, vol. 54, no. 4, pp. 2108–2123, Apr.
175, Jan. 2020.
2016.
[26] H. Noh, A. Araujo, J. Sim, T. Weyand, and B. Han,
[16] Yi Yang and Shawn Newsam, “Bag-of-visual-words and
“Large-Scale Image Retrieval with Attentive Deep Lo-
Spatial Extensions for Land-use Classification,” in Pro-
cal Features,” in 2017 IEEE International Conference
ceedings of the 18th SIGSPATIAL International Confer-
on Computer Vision (ICCV), Oct. 2017, pp. 3476–3485.
ence on Advances in Geographic Information Systems.
2010, GIS ’10, pp. 270–279, ACM. [27] Bingyi Cao, Andre Araujo, and Jack Sim, “Unify-
[17] Gui-Song Xia, Wen Yang, Julie Delon, Yann Gousseau, ing Deep Local and Global Features for Efficient Image
Hong Sun, and Henri Maı̂tre, “Structural High- Search,” arXiv:2001.05027 [cs], Jan. 2020.
resolution Satellite Image Indexing,” International [28] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos
Archives of the Photogrammetry, Remote Sensing and Zafeiriou, “ArcFace: Additive Angular Margin Loss for
Spatial Information Sciences - ISPRS Archives, vol. 38, Deep Face Recognition,” 2019, pp. 4690–4699.
2010. [29] Albert Gordo, Jon Almazán, Jerome Revaud, and Diane
[18] Yishu Liu, Zhengzhuo Han, Conghui Chen, Liwang Larlus, “End-to-End Learning of Deep Visual Repre-
Ding, and Yingbin Liu, “Eagle-Eyed Multitask CNNs sentations for Image Retrieval,” International Journal
for Aerial Image Retrieval and Scene Classification,” of Computer Vision, vol. 124, no. 2, pp. 237–254, Sept.
IEEE Transactions on Geoscience and Remote Sensing, 2017.
vol. 58, no. 9, pp. 6699–6721, Sept. 2020. [30] Tobias Weyand, Andre Araujo, Bingyi Cao, and Jack
[19] Jie Wang, Chang Luo, Hanqiao Huang, Huizhen Zhao, Sim, “Google Landmarks Dataset v2 – A Large-
and Shiqiang Wang, “Transferring Pre-Trained Deep Scale Benchmark for Instance-Level Recognition and
CNNs for Remote Scene Classification with General Retrieval,” arXiv:2004.01804 [cs], 2020.
Features Learned from Linear PCA Network,” Remote [31] Filip Radenovic, Ahmet Iscen, Giorgos Tolias, Yannis
Sensing, vol. 9, no. 3, pp. 225, Mar. 2017. Avrithis, and Ondrej Chum, “Revisiting Oxford and
[20] Grant J. Scott, Kyle C. Hagan, Richard A. Marcum, Paris: Large-Scale Image Retrieval Benchmarking,” in
James Alex Hurt, Derek T. Anderson, and Curt H. 2018 IEEE/CVF Conference on Computer Vision and
Davis, “Enhanced Fusion of Deep Neural Networks Pattern Recognition, 2018, pp. 5706–5715.[32] J. Philbin, O. Chum, M. Isard, J. Sivic, and A. Zisser-
man, “Object retrieval with large vocabularies and fast
spatial matching,” in 2007 IEEE Conference on Com-
puter Vision and Pattern Recognition, 2007, pp. 1–8.You can also read

















































