CAN RAID TECHNOLOGY CONTINUE TO PROTECT OUR DATA IN THE YEAR 2020? - Bruce Yellin Advisory Technology Consultant EMC Corporation
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

CAN RAID TECHNOLOGY CONTINUE TO
PROTECT OUR DATA IN THE YEAR 2020?
Bruce Yellin
Advisory Technology Consultant
Bruce.Yellin@emc.com
EMC Corporation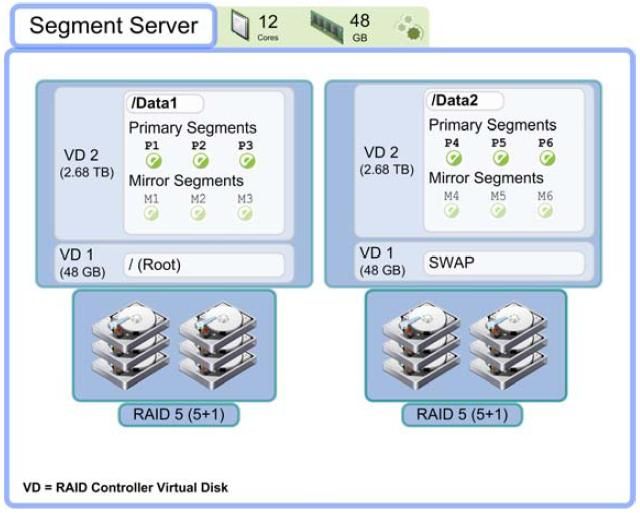
Table of Contents What’s the Issue? ...................................................................................................................... 4 The Danger ................................................................................................................................ 8 Tackling the Issue Head On ......................................................................................................13 Erasure Coding .....................................................................................................................17 What About Solid State Disks?..............................................................................................19 Triple parity ...........................................................................................................................22 RAID 1 ..................................................................................................................................22 Big Data ................................................................................................................................23 Conclusion ................................................................................................................................25 Appendix – Background on How A Disk Handles I/O Requests ................................................27 Footnotes ..................................................................................................................................28 Disclaimer: The views, processes, or methodologies published in this article are those of the author. They do not necessarily reflect EMC Corporation’s views, processes, or methodologies. 2012 EMC Proven Professional Knowledge Sharing 2
The digital data tsunami is coming. It is not a once in a decade storm, but a continuous daily event that can overwhelm the largest of data centers. Like a giant surge of rising water, data continues to grow at 60% a year and you need to be prepared. IDC reports over a zettabyte (one trillion gigabytes) of information was created and replicated worldwide in 2010, growing to 1.8 zettabytes just a year later. Data has increased by a factor of nine in just the last five years, and that the number of files will grow 8-fold over the next five years1. Over 90% of that data surge is unstructured, and “big data” is by far the largest producer of unstructured data. One of the challenging issues is how to store and protect all that data. No one is suggesting you’ll have a zettabyte or even an exabyte, but in the next eight years, you could easily be storing a petabyte of data. Will you use RAID to protect it? RAID is the “Swiss Army” tool invented in 19882 to protect and improve the performance of sub-gigabyte drives. Meanwhile, drive capacities have doubled every year or two since then according to Kryder’s Law3. Similar to Moore’s Law, Mark Kryder’s work suggest that by 2015, 6TB drives will be common and by 2020, we will have inexpensive 14TB4 hard drives. Is RAID still the right tool to use? The numbers can be scary. Years ago, 50-100TB seemed like a lot of storage. These days, 250TB of usable capacity minimally needs 320 x 1TB drives using RAID 6 (14+2) protection. At the projected growth rate, you will have a petabyte of usable capacity and almost 1,300 of those drives three years from now. RAID would be protecting over 13,300 x 1TB drives by 2020. Clearly, that is a lot of drives and eight years is beyond their useful drive life, so it is a good thing those larger 6TB drives are coming, right? Well, maybe. Whether you believe data will grow at 40%, 50%, or 60%, or if drive sizes double every year or two or three, one of the issues facing the storage industry is whether today’s parity RAID concepts are up to the task of protecting those large drives. Many have their doubts. Drives have gotten larger because of the advances in areal density. As shown to the right, areal density is the number of bits in a square inch of magnetic media. The original IBM RAMAC in 19565 had a density of 2,000 bits/in2 and today 625 gigabits fit in a square inch of a 4TB drive6. The downside to increased areal density is the potentially harmful increase in bit error rate (BER). 2012 EMC Proven Professional Knowledge Sharing 3
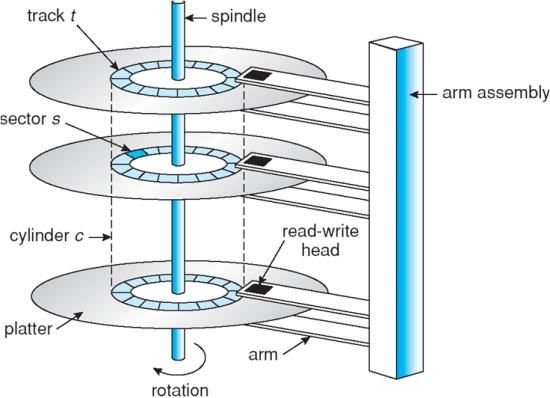
Larger drives also have longer rebuild times. We also know if we consolidate them into even larger ones, such as two 1TB drives combined into a single 2TB drive, the performance profile significantly decreases. Solid-state drives (SSDs) can offset the performance deficiencies of mechanical drives, but they have their own unique reliability issues. With that in mind, this Knowledge Sharing article examines how RAID holds up. What’s the Issue? Mechanical hard disk drives, which will be called HDD throughout this article, use a magnetically coated platter with “flying” disk heads, while SSDs use memory chips. Drive platters are made from aluminum or glass/ceramic that resists expansion and contraction when they get hot or cold. That material is ground down and base coated for an ultra flat surface. Additional polishing is done before various magnetic layers are deposited on the platter through processes such as “sputtering”7, all before a protective coating is applied. The disk drive housing contains one or more platters, a read/write head for each platter surface, a head positioning coil, a motor to spin the platters, and electronics to translate the disk controller’s commands and administer the buffer space. The head, literally flying over the spinning platter at a fraction of an inch at speeds greater than 150 M.P.H. (15,000 RPM drive), imparts a magnetic field or detects the existing magnetic field on the platter. The positioning coil receives instructions from the drive electronics as to where to position the head over the platter. Before a single bit of data is stored on a drive, it is first low-level formatted at the factory and high-level formatted by your storage frame’s operating system. This allows any “bad” sectors to be remapped to spare sectors. With the drive operational, when a server issues a write to a disk sector, the data is broken up into 512 or 4,096 byte sectors. Extra Error Correcting Code (ECC) check bits are calculated at the same time and written along with the sector to the platter. For example, on EMC VMAX®8 and VNX® arrays, a sector is 520 bytes in size with 512 bytes for data and an 8 byte CRC (cyclic redundancy check) checksum to maintain the integrity of the sector’s data. When the drive subsequently reads that sector, it also reads the ECC which together detects if the correct data was read. Data are Run-Length Limited (RLL) encoded to maximize the number of bits stored on the media, well beyond the coding of just a zero or a one bit. 2012 EMC Proven Professional Knowledge Sharing 4
With data packed so densely, ECC frequently corrects the data given the fluctuating signal
strengths and electronic noise of a flying head over a rotating platter. It is when ECC is unable
to correct the data that your operating system displays a disk read error message.
As mentioned earlier, drive capacity is a factor of its
areal density, and the denser you can pack the
zeroes and ones on the magnetic media, the greater
the BER and likelihood of read failures. In this chart,
areal density is shown to be limited by the BER,
especially when heat, commonly called a
9
thermodynamic effect, becomes a factor.
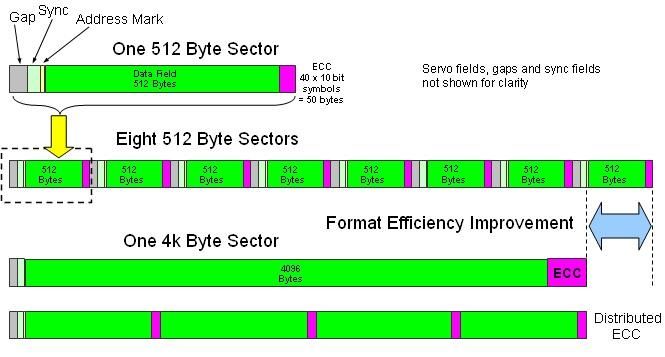
Some manufacturers are tackling the BER problem
by formatting drives with larger 4,096 byte sectors
and 100 bytes of ECC. Larger ECCs distribute the
calculation overhead from eight sectors to one sector
thereby reducing the error checking overhead
caused by 512 byte sectors on dense drives10. The
4KB ECC helps address the BER problem that are in
some cases approaching 1 bit of error for every 12.5TB read – more on this in a later section.
Another benefit of the 4KB sector is a
reduction in the usable capacity
overhead on the drive. The
improvement ranges from “…seven to
eleven percent in physical platter
space” and “The 4K format provides
enough space to expand the ECC field
from 50 to 100 bytes to accommodate
new ECC algorithms.”11
Some systems proactively test drive reliability before failures occur by “sniffing” or “scrubbing”
them and making sure all the data can be “test read” without error. This happens during idle
moments and has very little performance impact on the rest of the system.
2012 EMC Proven Professional Knowledge Sharing 5
Monitoring the well-being of every zero and one on a disk and noting the quantity of recoverable read errors is just one way of predicting a possible future disk failure. These statistics, depending on the system, allow it to proactively move data from troubled disk areas to safe locations on other drives before serious problems arise. This monitoring is just one way a system can perform “self-healing”. Another tool used to predict failure is S.M.A.R.T., or Self-Monitoring Analysis and Reporting Technology. S.M.A.R.T. tracks drive conditions and alerts the user to pending disk failures with the goal of giving you enough time to back up your data before it is lost. This tool incorporates metrics such as reallocated sector counts, temperature, raw read errors, spin-up time, and others. In theory, if the temperature rises or any other triggering event occurs, data can be preemptively moved off the suspect drive or all the data can be copied to a spare. Copying is much faster than parity rebuilding. However, in a Google study of over 100,000 drives, there was “…little predictive value of S.M.A.R.T.“ and “…in the 60 days following the first scan error on a drive, the drive is, on average, 39 times more likely to fail than it would have been had no such error occurred.”12 For more on S.M.A.R.T., please read the article “Playing It S.M.A.R.T.”13. As a disk controller issues read and write drive requests, it may find a sector to be unreliable – i.e., the magnetic coding is not retaining data or is reporting the wrong information. For example, after a write, the drive reads the information again to make sure it was written properly. If it can’t fix the error through ECC, the data may be unrecoverable, in which case the sector can be “marked” as unreliable and mapped to one of many spare sectors on a drive. This is called bad block remapping. Some drive “failures” are caused by extreme heat or vibration, so some systems can spin down a drive, wait a small amount of time, and then spin it up again. This can sometimes allow the drive to continue without the need for rebuilding. Clearly, any drive that is “revived” is also reported to the storage array system so you can proactively replace it. One study found “between 15-60% of drives considered to have failed at the user site are found to have no defect by the manufacturers upon returning the unit.”14 In other words, the failure could be environmental. 2012 EMC Proven Professional Knowledge Sharing 6
Should these approaches fail to correct the problem,
RAID can also improve performance. With
you could restore lost or mangled data from a data processors getting faster and more scalable with
multiple cores, mechanical disks have struggled
backup. However, if your backup is from last midnight to provide adequate performance for read and
write requests. RAID 1 can help improve
and it is now 3 P.M., you probably are guaranteed to performance by offering independent read
functionality, and RAID 5 and 6 to a lesser degree
lose valuable data. That’s where RAID comes in. RAID through distribution of the request across the
drives in the RAID group. SSDs provide
has the ability to rebuild a drive that has unreadable dramatically faster response than HDDs.
sectors or even if the entire drive stops spinning.
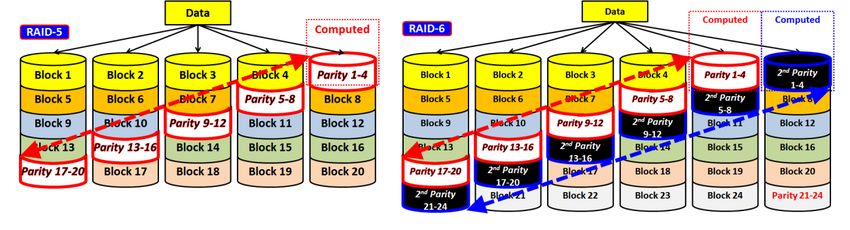
There are three popular forms of RAID – mirrored, single parity, and double
parity. Mirrored RAID or RAID-1 maintains an exact copy of one drive on
another such that if one needs to be replaced, the “good” drive is copied to a
spare drive.
Single parity or RAID 5, is a single dimensional parity written as a diagonal stripe to distribute it
and balance performance among the drives in the RAID group. It is often written as R5(4+1)
meaning four data drives and one parity drive, although the number of data drives is up to each
vendor’s implementation. In the event of a single rebuild activity, single parity plus the surviving
“good” elements can restore the failed element to a spare drive.
Double parity or RAID 6 is like RAID 5 plus a dedicated second parity drive enabling it to rebuild
two unique errors at the same time. It is commonly expressed as R6(6+2), or six data drives
and two parity drives. Like RAID 5, the number of data drives is up to the vendor. Notice in the
diagram above that RAID 5 uses the diagonal from lower left to upper right and RAID 6 uses
two such stripes.
2012 EMC Proven Professional Knowledge Sharing 7
Parity rebuilding certainly comes
in handy when data becomes
unreadable. Using data from the
surviving drives plus the parity,
unreadable data is reconstituted
to a spare drive (if available). The
rebuilding does take up disk
controller resources and many systems have priority rebuilding schemes to reduce or lengthen
the rebuild times. The larger the drive and the greater the number of them in the group, the
longer the rebuild takes. Conversely, the less data on the drive, the faster the rebuild occurs.
An extreme example of a problem that can happen is when a flying disk head crashes into a
disk platter. This is most likely to occur when a drive is just starting up, there is shock or
vibration to the drive, or if a microscopic particle gets caught between the head and the platter.
With the platters rotating at high speed, if the disk head scratches the surface, it can not only
destroy the magnetic media and the data in those sectors, but magnetic material can be kicked
up and contaminate the rest of the drive. Fortunately, head crashes are rare, with some studies
indicating it is 30 times more likely to have a media failure than a disk crash15, but should it
happen, the drive and the data needs to be replaced. The issue is how fast can a drive be
replaced and might another error appear before then?
The Danger
What happens when another drive fails before the first is repaired? How about the impact of a
drive rebuild on other RAID group members, other drives on the same disk controller, or even
the entire storage frame? It is hard to predict rebuild times which makes it difficult to assess the
risk. Rebuild factors include:
1. drive attributes such as sizes and speeds (i.e., larger and slower drives take longer)
2. each storage vendor offers different priority schemes
3. the failed drive and its replacement spare may not be on the same controller
4. the architecture of the storage frame and the version of operating code
Hours to repair a failed drive based on rebuild priority with spare sync
Example: With an EMC VNX 300GB 600GB 1TB 2TB 4TB 8TB 12TB 16TB
running OE 31, a 600GB 15K Size 10K 15K 7.2K 7.2K 7.2K 7.2K 7.2K 7.2K
Low 52 69 230 460 921 1,842 2,763 3,684
drive protected by RAID 5(4+1) Medium 28 37 122 245 490 980 1,470 1,960
High 14 19 63 127 253 507 760 1,014
ASAP 2 2 8 15 31 61 92 123
2012 EMC Proven Professional Knowledge Sharing 8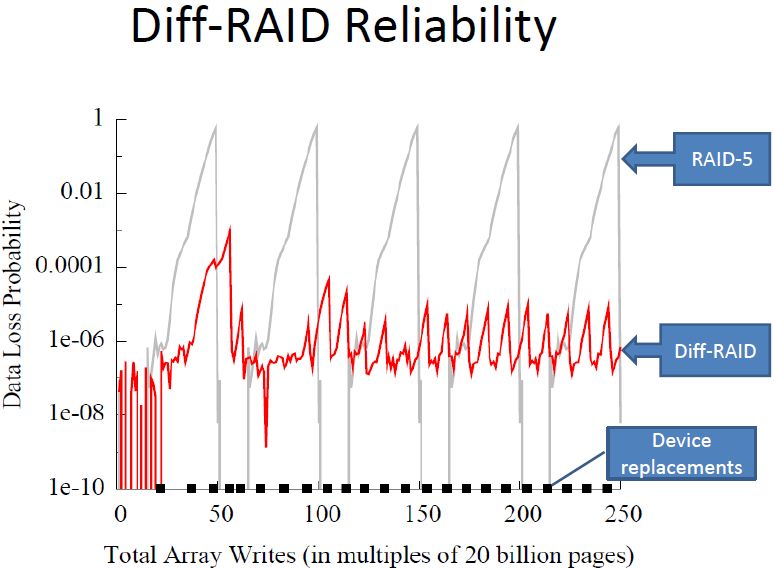
can be rebuilt in just over two hours at the ASAP priority, including the time to replace the
defective drive with a new one and having the hot spare sync its contents to it16. SSD rebuild
times would be on par with 15K HDDs. If your system uses permanent spares such as an EMC
VMAX, once the drive is rebuilt, the data stays on that drive—i.e., there is no need to return that
drive to a spare drive pool, which can in some cases cut the rebuild time almost in half.
Example: Seagate’s Cheetah 15K.7 600GB drive17 has an average sustained transfer rate of
163MB/s. However, trying to achieve that rate during a rebuild would probably bring your
storage unit to its knees since the specification of a SAS disk controller loop is 400-600MB/s. In
other words, 27-40% of the bandwidth would be consumed by just a single disk rebuild, never
mind servicing possibly hundreds of other I/O requests for unaffected drives on the same loop.
Strategies that reduce the impact of a rebuild on a disk controller include the use of smaller
drive loops. Small loops will become more practical as controllers leverage faster multi-core
technology. Data paths for 12Gb SAS 3.018 are also on the drawing board and will allow the use
of higher rebuild priorities while having a lower impact on the storage frame’s other work. Until
that happens, a more conservative calculation that is kinder to the rest of the storage frame is to
pick a priority that yields a drive rebuild of 30-50MB/s.
From our earlier example,
500 Rebuild Time in Hours by Priority 4,000 Rebuild Time in Hours by Priority
setting the rebuild priority 450
Low 3,500 Low
400
Medium 3,000 Medium
to “low” equates to 69 350
High 2,500 High
300
ASAP ASAP
hours or almost 3 days to 250 2,000
200 1,500
rebuild that 600GB drive. 150
1,000
100
500
Increase the priority to 50
0 0
“medium” and the rebuild 300GB
10K
600GB
15K
1TB
7.2K
2TB
7.2K
4TB
7.2K
8TB
7.2K
12TB
7.2K
16TB
7.2K
Drive Size/RPM Drive Size/RPM
time is reduced to 37
hours. Use “high” priority and it takes 19 hours. Notice that as the size of the drive increases, so
does the rebuild time. A 2TB drive takes 127 hours or more than 5 days at “high”! If this
progression continues, 8TB drives in the year 2015 might take 21 days to rebuild and perhaps
impact the storage frame’s response time during that time.
No one wants to wait days to rebuild a drive, but you also don’t want to impact other
applications running on your storage frame. When the drive is running at its maximum transfer
rate, it basically uses so much of the disk controller’s loop capacity that other I/O processing to
surviving drives is effectively reduced to a trickle. That is why using the ASAP priority for
2012 EMC Proven Professional Knowledge Sharing 9
rebuilds is often the exception and not the rule. Many companies use a “high” priority to rebuild
a failed drive, since it has some impact on overall performance yet does an adequate job with
smaller 300GB and 600GB drives. The previous chart has a suggested or “acceptable” rebuild
rate highlighted in white on black. Keep in mind that the larger the RAID group, the longer the
rebuild process can take – i.e., RAID 5(8+1) takes longer to rebuild than RAID 5(4+1).
You should not focus on the precise number of hours or days to rebuild a drive since it depends
on so many factors. Nor should you use these to time your own rebuild rates. Each storage
vendor will have similar specific drive timings given the specifications from Seagate, Western
IBM/NetApp Rebuild Extrapolation
Digital, Hitachi, etc. are so similar. Instead, use the general
Drive RPM Hours
rebuilding concepts being discussed. For example, IBM says 146 15 1.5
300 15 3.1
the RAID 6(14+2) rebuild of 16 x 146GB 15K takes 90 minutes,
300 10 4.6
or a rate of 27MB/s19, which allows you to make drive 450 15 4.6
600 15 6.2
protection decisions based on your risk exposure. Extrapolating
450 10 6.9
IBM’s analysis to larger drives, the table to the right can be 600 10 9.2
1000 7.2 21.4
constructed20. There was no mention of what priority scheme
2000 7.2 42.8
was used, but a 3TB drive might take more than 2 ½ days to 3000 7.2 64.2
rebuild.
The larger the drive, the longer it takes to rebuild and the greater the risk of a second error
occurring during that time. For example, with RAID 5, a second drive failure in a group that is
actively being rebuilt likely leads to data loss. That is the main reason why RAID 6 was
introduced in 198921. RAID 6 can tolerate two drive failures in the same group and rebuild them
without data loss, or a single drive failure and a read error on a second drive. As you can
imagine, rebuilding two drives concurrently, while not taking twice the time, is nonetheless a
lengthy process. And the longer it takes, the greater the probability of yet another loss or a
system that would run very slowly with all the rebuild activity going on.
On top of slow rebuild times, storage frames these days can easily have a thousand or more
disks, perhaps of a similar manufacturing age. If older HDDs begin to fail, there could be an
increased likelihood that others of the same vintage will experience the same fate. This is
sometimes called “bit rot”22, or the corruption of data caused by the decay of magnetic media
over time. While unlikely, it is possible that rebuilding a failed drive can produce a bit rot failure
in a good drive in the same RAID group since they all have the same usage patterns. To
preemptively battle bit rot, manufacturers use continuous fault detection through sniffing and
2012 EMC Proven Professional Knowledge Sharing 10scrubbing, and then employ self-healing to safely move data out of danger before the media
fails.
The dramatic worldwide Amt of usable TB in your 2012 2013 2014 2015 2016 2017 2018 2019 2020
frame, growth at 60%/yr 250 400 640 1,024 1,638 2,621 4,194 6,711 10,737
increase in the volume of data # of 1TB drives R6(14+2) 320 512 800 1,280 2,048 3,280 5,232 8,368 13,392
# of 2TB drives R6(14+2) 160 256 400 640 1,024 1,648 2,624 4,192 6,704
dictates that storage frames # of 3TB drives R6(14+2) 112 176 272 432 688 1,104 1,744 2,800 4,464
# of 4TB drives R6(14+2) 80 128 208 320 512 832 1,312 2,096 3,360
will need to hold many more # of 5TB drives R6(14+2) 64 112 160 256 416 656 1,056 1,680 2,688
# of 6TB drives R6(14+2) 64 96 144 224 352 560 880 1,408 2,240
drives. From our earlier # of 7TB drives R6(14+2) 48 80 128 192 304 480 752 1,200 1,920
example, assume your 2012 # of 8TB drives R6(14+2) 48 64 112 160 256 416 656 1,056 1,680
# of 9TB drives R6(14+2) 48 64 96 144 240 368 592 944 1,488
storage frame had 250TB of # of 10TB drives R6(14+2) 32 64 80 128 208 336 528 848 1,344
usable data and it grew at 60% a year. In three years, you would need 1,280 x 1TB drives and
by 2020, the frame would need over 13,000 x 1TB drives! Fortunately, drive capacity increases
every year or so, and staying on top of the data explosion means leveraging these multi-
terabyte drives along with techniques such as compression and deduplication. With 6TB drives
expected to be common by 2015, you would still need 224 of them to hold a petabyte of
capacity.
Keep in mind that trying to replace a 6TB drive protected with RAID 6(14+2) at an acceptable
priority could take weeks, and the risk of a second or third simultaneous failure increases. That
is why the 1988/1989 concepts of RAID protection may be coming to an end. By 2020, with
10TB drives and 10 petabytes of usable capacity, the idea of more than two mechanical failures
among 1,344 drives could easily lead to crippling data loss.
There are many variables that factor into Seagate Unrecoverable
Drive Size/speed MTBF AFR read errors
HDD reliability, including the drive itself,
Cheetah 300GB FC 15K 1,600,000 0.55% 116
temperature, humidity, vibration, cables, Constellation 3TB SAS 7.2K 1,200,000 0.73% 115
controllers, firmware, operating system, Barracuda XT 3TB SATA 7.2K 750,000 0.34% 114
and others. In an effort to advise the marketplace on disk reliability, manufacturers like Seagate
publish statistical specifications such as Mean Time Between Failure (MTBF) and Annualized
Failure Rate (AFR)23. MTBF is a calculation of how many hours a drive will continue to operate
before there is a failure, estimated for a large population of drives versus an individual drive. For
example, a Cheetah drive with a MTBF of 1,600,000 hours indicates that with a large number of
these model drives, half will fail in 1,600,000 hours or 183 years. If your storage system has
1,000 drives, the results look a lot different and a failure can occur in just 67 days. Drive
reliability can be calculated by this formula:
2012 EMC Proven Professional Knowledge Sharing 11With “half” failing, it is reasonable to expect some will have problems earlier or later than this calculation. It also says with 1,000 Barracuda drives, you can experience 12 failures a year or more than twice as often as the Cheetah because the MTBF is lower. Manufacturers also offer an AFR or Annualized Failure Rate calculation. It is based on the MTBF and relates the likelihood of failure to the number of hours the device is used in a year. For example, the Cheetah has a MTBF of 1,600,000 hours and an AFR of 0.55%, so at first glance it appears the AFR of the Barracuda should be much higher given its MTBF is less than half at 750,000. It turns out that Seagate rates the Barracuda against 2,400 hours a year and not 8,760 used by the Cheetah, or a 27% duty cycle. So if you used your Barracuda for a full year, 8,760 hours, its AFR would increase to 1.17%. You can expect the AFR to increase every year it is used, so a Barracuda XT used for a full 8,760 hours/year would have an AFR of 2.34% by year two, 3.5% by year three, and if you used it for five years, almost 6%. And if you have hundreds of them, you have a problem on your hands. Some studies have shown that spec sheet MTBF and AFR numbers actually underestimate real world observations, in some cases, by orders of magnitude. A 2006 study at Carnegie Mellon University of 70,000 drives found the “annual disk replacement rates exceed 1%, with 2-4% common and up to 12% observed on some systems.”24. However, it should be noted that a small number of drives in their study were seven years old and beyond any reasonably expected useful service life. In an attempt to gain a practical understanding of MTBF and AFR, Google did their own study25 in 2007 and also found the AFR for drives in their environment to be significantly higher during the drive’s initial use, settling down to 1.7% after the first year, but still roughly 3X higher than Seagate’s claim. The AFR spiked to 8% and higher in years two 2012 EMC Proven Professional Knowledge Sharing 12
through five. They also found the “MTBF could degrade by as much as 50% when going from operating temperatures of 30C to 40C”. The Google study also found “…after their first scan error, drives are 39 times more likely to fail within 60 days than drives with no such errors.” They were referring to a sniffing or scrubbing scan that tries to detect errors before they become catastrophic failure. Some might question the validity of Google’s report since the study involved consumer and not enterprise grade drives, used models from various manufacturers, and may not have been mounted or used in accordance with manufacturer’s specifications. For example, in this picture of a Google server26, each drive is attached to the server using Velcro straps rather than mounting screws, which brings up vibration questions. The study was also done six years ago against drives that were already five years old. Nevertheless, the question of reliability is a concern as drives get older and larger, and storage frames have more of them – i.e., your AFR “mileage may vary”. Tackling the Issue Head On What is the magnitude of the problem? Are there useful, practical approaches to deal with it? For example, a petabyte of usable storage with 1TB drives and RAID 5 protection requires 1,400 drives. If the AFR is 0.5%, then seven drives statistically could fail per year. If the Google analysis has any merit and the AFR of a two year old storage frame is 8%, then 112 drives could fail per year. Somewhere between these calculations lies your impact. As discussed earlier, the rebuild time for this size drive without impacting a large portion of the storage frame would be 122 hours at medium priority, or five days. With seven failures per year, rebuild is running 35 days a year. With 112 failed drives, you might have to give up because you would have almost two years of drive repairs for every year of operation. And that assumes you don’t get a second error while repairing a RAID group. Older drives would dramatically increase the 2012 EMC Proven Professional Knowledge Sharing 13
percent of rebuilding per year that was occurring, and in the case of Google’s findings, could
mean a significant amount of storage resources were spent just on rebuilding. That is why the
useful life of a disk drive is usually less than five years.
Multiple drive failures in a RAID group participating in 1 1 1 1 1 1
a thin provisioned storage layout could also lead to a 2 2 2 2 2 2
3 3 3 3 3 3
multi-day outage given the failed drive could contain 4 4 4 4 4 4
logical members from an enormous number of 5 5 5 5 5 5
Thick
LUNs
servers. With traditional thick LUNs, the number of 6 6 6 6 6 6
7 7 7 7 7 7
servers using a RAID group was limited to the size of
8 8 8 8 8 8
the LUN divided into the usable capacity of the 9 9 9 9 9 9
10 10 10 10 10 10
group. In some cases, the LUN could be spread out
across multiple LUNs, but again, to support a
relatively limited number of servers. Thin provisioning
increases utilization and performance, but
architecturally, the slices used in the RAID group are Thin
LUNs
tiny. For example, with a 300GB RAID 5(4+1)
yielding a little more than a terabyte of usable
capacity, traditional LUNs of 50GB or so would mean
about 20 disk slices in that group. With thin
provisioning, the same five drives would create over a thousand slices and could easily be
logically part of each and every virtual and physical server on that storage frame. Larger drives
in a thin pool increase the impact of data loss. If there was a double failure, such as one bad
drive and a second one with a read error, RAID 5 would lose data and would impact just those
hosts in a thick LUN arrangement, versus nearly every host in your data center which had a thin
member on the failed drive. RAID 6 would afford you more protection, but there is a limit to that
protection as well. With thin provisioning RAID data loss, the time to restore the drive from tape
could be excessive and severely impact your company’s business.
A 4TB drive takes 4X as long to rebuild as a 1TB drive, so with RAID 5(4+1) and 490 hours to
rebuild it at medium priority (20 days), the storage frame could risk serious data loss. Even
without lost data, there could be a performance impact should other drives also need
replacement during that time. Fortunately, RAID 6 addresses the issue of a second
simultaneous failure. You should never use RAID 5 with large drives – the risk of data loss is
just too high.
2012 EMC Proven Professional Knowledge Sharing 14With larger drives, the impact of losing a disk drive could have even more far reaching
implications when administrators use data compression and deduplication on them in their
archiving tier. Compressed, a 1TB drive could easily contain 2TB of data. That means the drive
is twice as likely to be in demand. With deduplication, even more data is kept on that critical
drive.
The issue here is not just MTBF and AFR, it is the Drive Bits BER Bits
1TB 8,796,000,000,000 1^14 100,000,000,000,000
number of unrecoverable read errors. In the 10TB 87,960,000,000,000 1^15 10,000,000,000,000,000
earlier Seagate chart, the rate can be anywhere from 1014 to 1015 depending on the quality of
the drive, or statistically an error trying to read 100,000,000,000,000 to 1,000,000,000,000,000
bits. A 1TB drive contains 8,796,000,000,000 bits and a futuristic 10TB drive has
87,960,000,000,000 bits. This roughly equates to every ten full reads of a 1TB drive produces a
single uncorrectable BER with a commercial grade drive. With an enterprise quality drive, you
can expect a hundred such operations with a 1TB drive before you get an unrecoverable error.
The RAID-5 problem with large drives in a nutshell
When the drive is ten times larger, you will
1TB 1TB 1TB 1TB 1TB 1TB 1TB 1TB 1TB 1TB
only need to read the entire drive once to BER 114 BER 114 BER 114 BER 114 BER 114 BER 114 BER 114 BER 114 BER 114 BER 114
produce a single error on a commercial quality
Example: With 1TB drives and RAID-5 (8+1) protection, to rebuild the
disk. In fact, if there needed to be a rebuild failed “red” 1TB drive, the surviving “blue” drives must be completely
read to recreate the data to the spare “white” drive. If other failures
with 10TB drives, you would be guaranteed occurs before the “white” drive is rebuilt, data can be lost.
multiple read errors because every sector on The MTBF specifications of a 1TB SATA drive is between 750,000 to
1,200,000 hours, but studies have this closer to 400,000 hours. If the
every disk must be read to rebuild the image, “white” drive rebuilds at 30MB/s, it takes 10 hours to rebuild with
permanent sparing. With a 400,000 MTBF and a rebuild of 9 drives,
thereby increasing the chances of another there is a 0.025% chance of another drive failure – pretty low risk.
read error (perhaps recoverable, perhaps not). A BER of 1014 means 1 error every 12.5TB. With 8 drives being fully
read, there is a 8/12.5 or 64% chance of an unreadable disk. That
At that point, it will likely interrupt the rebuild means every 1 ½ rebuilds will fail. If the BER improves to 1015, the
probability drops to 6.4%. Larger drives increase the probability.
unless additional logic is employed. Worst
case, you would restart the rebuild session and hope for the best. If you are still not convinced
of the severity of a BER failure, think about the encryption of the data on the drive – if you
cannot read each bit, you will not decrypt that information.
The BER is also significantly different for fibre-channel and SAS drives compared to SATA. In
the chart comparing the Seagate Cheetah to the Barracuda XT, the Cheetah has a BER of
10^15, or 10 times better than the Barracuda at 10^14. Their Constellation series of SAS drives,
available in 2TB or 3TB capacities, also have a BER of 10^15, and would be better choices for
higher capacity drives than their SATA Barracuda, albeit at a higher price.
2012 EMC Proven Professional Knowledge Sharing 15A great deal has been written about the statistical Mean Time To Data Loss (MTTDL)
calculation over the last 20 years, and like most estimations, it is accompanied by arguments
that either serve as an affirmation or a negation of the reliability of disk storage. One thing is
certain – the risk of data loss increases as HDDs get larger simply because their performance
has not kept up with Moore’s Law. In other words, if drive rebuilds were super-fast or perhaps
instantaneous, the drive size would not be a factor. Given drives fail, all that can be done is to
provide adequate protection, either through RAID or another copy of the data, or both.
As already discussed, it is risky to have hundreds or thousands of large drives protected with
RAID 5. RAID 6 is much safer, but far from perfect “…with 1 petabyte of storage and RAID 5 …
the odds of annual data loss are around 80%. RAID 6 extends the window and is fine for 1TB
drives, but with 2TB drives in a 1,000 disk system there’s a 5% chance of annual data loss. That
figure increases to 40% with 8TB drives, and eventually the change of annual data loss will
approach 100%.”27 With the data explosion and limited budgets, you will simply have to use
these very large drives.
So why not use RAID 6 for all your disks? The tradeoff you may need to make when choosing
between RAID 5 and RAID 6 is MTTDL versus performance. From a performance perspective,
depending on how your vendor implements RAID 6, it can have a 10-20% higher write overhead
than RAID 5. That means your RAID 6 system does fewer useful write I/Os per second than
RAID 5 – i.e., each write takes longer to complete. Therefore, RAID 6 should be evaluated in
small block random write-intensive environments. For read-intensive environments, RAID 5 and
RAID 6 have equivalent performance.
Losing data is obviously a serious problem. $40,000,000
$35,000,000 Hourly Compensation Costs Due To Data Loss
Rebuilding a drive is a fact of life, but losing
$30,000,000
1 hour @$25
data because of a second or third failure or $25,000,000 4 hours @$25
8 hours @$25
trying to rebuild it too fast and causing $20,000,000
1 hour @$50
severe performance issues can lead to a $15,000,000 4 hours @$50
8 hours @$50
$10,000,000
loss of employee productivity. If an 1 hour @$100
$5,000,000 4 hours @$100
employer of 20,000 workers loses just one $0
8 hours @$100
1,000
10,000
20,000
30,000
40,000
50,000
hour of productivity because of data
Number of Employees
unavailability, it could cost them a million
dollars in salary and other benefits with a loaded cost of $50/hour/employee. After four hours,
the company would have spent $4M if a key system is unavailable. For example, if Delta
2012 EMC Proven Professional Knowledge Sharing 16Airlines is unable to process reservations for eight hours while two drives are being rebuilt from
backup tape, they could lose a portion of their customer base. If the business is an online
reseller, there could also be a loss of web revenue. A military operation such as mid-air jet
refueling could put lives or even a nation at risk.
Another approach, while clearly more expensive, is to make multiple full copies of data.
Snapshots probably won’t help since if there are multiple drive failures, the loss of primary data
could render snapshots worthless.
Let’s examine some other approaches.
Erasure Coding
While RAID 5 and RAID 6 have their place in a storage frame, using them with 4TB and larger
drives dramatically increases the risk of data loss. Can “erasure codes” provide better
protection? Invented by Irving Reed and Gustave Solomon in 1960, their Reed-Solomon
erasure code was popular with telecommunications workloads, especially on long distance
transmissions and noisy circuits. A form of Forward Error Correction (FEC), their approach grew
in popularity with the entertainment industry’s introduction of the compact disc in 1982 as
erasure coding became “…the first example of the introduction of Reed-Solomon codes in a
consumer product.”28 DVDs came to market in 1995 and also used Reed-Solomon erasure
coding29 to allow us to enjoy music and movies, even when the discs get scratched.
Erasure coding breaks the data into fragments and adds extra blocks capable of rebuilding any
defective blocks such as those caused by an unreadable sector. They say you can literally drill a
hole in a DVD and it will play fine because of Reed-Solomon coding. A disk drive rebuild, which
might have taken days with RAID 5 or RAID 6, can now be accomplished in minutes. Here is an
example from Permabit’s RAIN-EC (Erasure Coding) white paper on how it works:30
now is the time for all good men to come to the aid of their country
A B C D P Q
now is the time for all good men t o come to the aid of their country
A chunk can be rebuilt from any 4 remaining chunks.
P=A+B+C+D
Q = A + 2B + 3C + 4D
Example: If A=1, B=2, C=3 and D=4, then P=10 and Q=30. If A and B are lost, then:
A = 2P - Q + C +2D = 1
B=P-A-C-D=2
2012 EMC Proven Professional Knowledge Sharing 17In this simple example, the data “now is the time for all good men to come to the aid of their country” is broken into four data chunks with two additional protection chunks. If “now is the time ” and “for all good men t” is lost, they can be quickly rebuilt from calculations using the P and Q chunks without a lengthy rebuild of an entire drive or two. The Reed-Solomon data protection approach is used in solutions from EMC (Atmos®31 and Isilon®32), CleverSafe33, Amplidata34, Permabit and others. With Atmos, GeoParity35 breaks data into chunks (or fragments), adds erasure codes, and geographically separates them on different disks and different frames. In this GeoParity example, data is broken into nine chunks and protected by adding three more chunks, allowing there to be three simultaneous drive failures without data loss. Protection is written as 9/12.36 Isilon’s FlexProtect is another Reed-Solomon erasure coding method that protects against multiple drive or node failures and can employ a 14/16 scheme, the same efficiency as RAID 6 (14+2). Their OneFS® operating system breaks a file into 8KB blocks, and the block is striped across however many nodes are in the protection scheme. FlexProtect can rebuild the failed chunk quickly without hot spares by writing the new chunk to another drive that has free space. It can also handle multiple failures up to the degree of protection specified by the administrator. With very small files, OneFS uses mirrored protection. Cleversafe spreads the chunks over many geographically separated nodes without overlap. They add physical and node location metadata to form a dispersal pattern for the data, all derived from Reed-Solomon. They use a 10/16 arrangement that if spread amongst three data centers, could construct the data if one data center was unavailable. The downside to erasure coding is that it needs linear algebra calculations which take longer to compute than simple RAID 6 double parity. Also, the overhead is high for small writes. When used with geographically separated storage frames, WAN latency also becomes an issue. It is a good fit for microsecond response time object-based systems, such as social networking and some forms of cloud computing, but not practical for millisecond response time-oriented 2012 EMC Proven Professional Knowledge Sharing 18
applications like OLTP. As multi-core processors gain power, erasure coding may become
universally popular.
What About Solid State Disks?
Up to this point, we’ve been discussing
HDDs. SSDs use memory chips, and while
they don’t have any moving parts, they can
also be subject to problems reading data. In
some companies, the introduction of SSDs
has led to the mothballing of their HDDs.
SSDs are delivering 10X-100X higher
performance without the issues of motors
that lock up or heads that scratch a platter’s
surface. However, they have a different set of issues – again, no free lunch. SSDs are known
for having a limited lifetime of write activity, so SSD controllers avoid premature failure by
spreading out write activity to excess capacity in the drive using a “wear-leveling” algorithm.
From a performance standpoint, the SSD has a higher write I/O rate when the drive is newer,
not because the drive is wearing out, but because of the drive’s reserve capacity
management37.
The nature of Single-Level Cell (SLC) and Multi-Level Cell (MLC) designs result in an increasing
BER as the drive handles more write activity38. Enterprise-quality SSDs have a BER of 1015 or
even 1016, so their reliability is on par if not better than fibre-channel and SAS drives, at least
when they are new. SLCs, which are twice as the cost of MLCs, have around 10-20 times the
expected life as MLCs39. For example, STEC’s small card MLC SSD is rated at 10,000
program/erase operations while the SLC version is 100,000. Companies such as STEC, using
wear leveling, extend a drive’s life to 2 million program/cycles40.
SSDs are also packaged as PCIe server plug-in 4KB Random Reads IOPS
15K RPM HHD 175-210
cards. Without the host bus adapter packetizing
Intel X25-M 3.5” SATA 35,000
overhead for use with the fibre-channel OCZ 2x SuperScale Z-Drive R4 PCI-Express SSD 1,200,000
transport, they leverage the PCI bus and deliver even more impressive results than “disk form
factor” SSDs. For example, a 15K HDD can deliver 175-210 IOPS with 4KB random reads,
2012 EMC Proven Professional Knowledge Sharing 19while an Intel X25-M 3.5” SATA drive can deliver 35,000 4KB random reads, and a OCZ 2x SuperScale Z-Drive R4 PCI-Express SSD can deliver 1,200,000 4KB random reads41. But PCIe SSDs are often not used in pairs, and even if they did, the PCIe bus clearly does not have the capabilities of a RAID controller. However, it doesn’t rule out a software RAID service42. Currently, the only way to protect the device is to incorporate extra components on the single card. Clearly, if the server fails while the card is being written to, or the card itself has a serious malfunction, there could be data loss. It is also not immune to BER issues. In storage arrays, because of their performance profile, SSDs can often be seen doing the bulk of the I/O intensive work. For example, if you want your Oracle transaction databases to “fly”, put your redo logs and indexes on SSD. However, as these devices handle more and more write activity, their error rate increases and they fail more frequently. Every write brings them one step closer to their end-of-life. Some businesses, such as those that process stock transactions, require 1-2 ms SSD response time. They could be in big trouble and possibly lose billions of dollars if these devices fail and are unable to process a trade. When used with traditional RAID and thin provisioning, data is striped evenly across the SSDs in the RAID group. That means as a group, their error rate collectively increases, and given they are likely of the same vintage, will all tend to wear out at the same time. So while it was a good practice to level out the I/O load with HDDs, it is the worst thing you could do with SSDs. You want your SSD in a RAID group to have uneven wear so they all don’t fail at the same time. One way being explored to deal with this issue is called Differential RAID43. Differential RAID attempts to understand the age of each drive in terms of write cycles and unevenly distribute that activity so all the drives don’t have unrecoverable errors at the same time. It balances the high BER of older devices in the group with low BER of newer drives. As drives are replaced using hot spares, it redistributes the data to minimize the risk of a multiple drive failure in the group. It may also move the parity to different locations since the parity portion of the drive by definition gets involved in every write in a RAID group. This chart shows the efficacy of differential RAID over RAID 5. 2012 EMC Proven Professional Knowledge Sharing 20
Charts from the same differential RAID study also show it can extend the useful life of SSDs, and require less error correction overhead: MLC devices have it worse than SLC devices. While MLC is significantly cheaper than SLC, the MLC’s lifespan of write activity is often found to be only 10% of the write cycles of SLC. That is why most storage vendors opt for SLCs in their storage frames – they cost more, but are far more reliable. As the industry creates denser SSDs (Moore’s Law), the BER is also increasing. This places a bigger demand on error correction algorithms to ensure data integrity. SandForce’s SSD controller with RAISE44 (Redundant Array of Independent Silicon Elements) technology achieves a BER of 1029. RAISE uses chips on the circuit board in a similar manner to drives in a RAID group. Micron also raised the protection bar with ClearNAND45. Instead of a smarter controller, Micron put the ECC controller on the drive itself. Again, if you lose the circuit board, you lose data, so additional protection is still required, but the device itself is more robust. When faced with a design choice, using four x 100GB SSDs collectively have a lower BER impact on reliability than a single 400GB SSD if utilized the same way, in addition to getting 4X 2012 EMC Proven Professional Knowledge Sharing 21
the performance at less than 4X the price. Rebuild times will be lower and four drives will give you the ability to have some type of RAID protection. Triple parity The idea behind triple parity is simple. Single parity RAID 5 does a fine job with small to medium size HDDs. Double parity RAID 6 offers improved protection for larger drives. Continuing this very efficient paradigm, a triple parity design can make sense with 4TB and larger drives, especially with their even longer rebuild times. Adam Leventhal in “Triple-Parity RAID and Beyond”46 went as far as calling it RAID 7. While there is no “official” RAID 7 standard, it is designed to survive three simultaneous errors without losing data. Mr. Leventhal’s RAID 7 chart, which uses the nomenclature RAID-7.3 for triple parity, shows it provides RAID 6 levels of protection through 2019 when factoring in future drive capacities and ever present bit error rates. RAID 7 will not shorten rebuild times, and it may even increase them a little. However, triple parity allows a very risk-free future for HDDs. Clearly, three parity drives impose a high space overhead, but as disk prices continue to fall, perhaps reaching $40 for a 14TB47 disk, it might be a fair trade-off. Triple parity is a good fit for very large RAID groups, such as RAID 7(16+3), where the overhead of three parity drives can be better amortized. When used on small RAID 7(4+3) layouts, it imposes a high parity overhead for just four data disks, and perhaps that data would be better served by RAID 1 by adding one more drive. RAID 1 Keeping two copies of data is the best way to ensure reliability. If one drive begins to fail or completely fails, 100% of the data can be copied very quickly from the surviving good drive to a spare or replacement drive. Copying data is much faster than rebuilding a drive from parity. Plus, there is the hidden benefit that many storage systems offer – parallel disk reading. For example, the Dynamic Mirror Service Policy of an EMC VMAX allows it to retrieve data from whichever disk whose heads are “closest” to the requested data. This advanced feature can literally increase throughput by up to 25%48. Disk writes can also occur faster since there is no parity to calculate. The downside to RAID 1 is you need double the capacity, along with twice 2012 EMC Proven Professional Knowledge Sharing 22
the power, cooling, footprint, and so on. However, with drive prices continuing to fall, the reliability can’t be beat and the only way to get better performance is with SSDs. There are two basic ways of implementing RAID 1; physical mirroring of one drive to another and distribution of mirrored members throughout a system. Mirroring of one drive to another is straight-forward while distribution can be accomplished in many ways. If a disk pool is used, chunks of data can be spread between members of that RAID 1 type. For example, IBM’s XIV breaks a block of data into 1MB chunks and protects them with RAID 1. The XIV goal is to “…randomly distribute each mirrored data “chunk” across data modules, making sure that no mirrored copy of a chunk exists within the same module as the original.”49 Most of these intra-frame dispersal chunk approaches do well when the storage frame is underutilized. When they become full, it can be difficult for the storage frame to find free capacity on other disk spindles. As a result, the dispersal pattern tends to lump logical pieces on the same drive. Whether physical mirroring or dispersal is used, you are balancing RAID 1’s better protection and performance against the frugality and lesser protection of parity RAID. Big Data Big data is all about processing large, unstructured datasets that often fall outside the traditional relational database environment. Unstructured data is the catch-all for e-mail, Word-Excel- PowerPoint, blog contents, sensor data, searches, social networking, charts and pictures, voice data, video, and so forth, while structured data is typically transactional and stored in a relational database. Unstructured data is usually ingested into your storage frame with NAS/Ethernet and structured often enters with block mode/fibre channel, so not only will data types change, so will the reliance on network topologies. With most of the growth coming from big data, does this mean everything will be unstructured? No, of course not. Structured data, databases, and block mode fibre channel still provides unmatched performance and will continue to be the backbone of business transactions. Even with drives getting larger every year, higher performance “smaller” 10K and 15K RPM drives will continue to be manufactured and play a significant role in storing structured data. SSDs will also help with their unparallel transactional I/O rates and by 2015-2020, they will become ubiquitous in servers and storage frames. 2012 EMC Proven Professional Knowledge Sharing 23
Forrester Research offers a graphic50 that ties the big data definition to multiple criteria. They point out that a large data volume by itself does not necessarily classify it as big data, but when you couple it with other factors, it soon becomes clear the data cannot be processed in a traditional manner. A big data example is from a large, futuristic department store. Let’s say a shopper with a GPS smart phone or loyalty shopper card spends twenty minutes browsing before purchasing bath towels. Transactional data captured in a traditional database is the sale of the towels. Big data captured their GPS location as they traversed aisles and noted they also spent ten minutes in front of the frying pan display. Big data could be used automatically to summon a clerk to demonstrate the frying pan or send the shopper an immediate, electronic, personal sale coupon for it. A pioneer in big data, Google analyzes an enormous amount of Internet data every few days to update search engine indices. This type of problem doesn’t fit into a typical relational database, so they created MapReduce to break the voluminous task into parallel efforts on hundreds or thousands of customized, inexpensive servers with as few as two disk drives as shown earlier. Two disks fit a RAID 1 scenario yielding high performance and high availability. When big data is processed by highly scalable, massively parallel architectures such as EMC’s Greenplum™ Data Computing Appliance (DCA), big data can still leverage RAID since the underlying data protection relies on relatively small drives and dispersal. Greenplum uses twelve 600GB 10K drives in a segment server initially protected with RAID 2012 EMC Proven Professional Knowledge Sharing 24
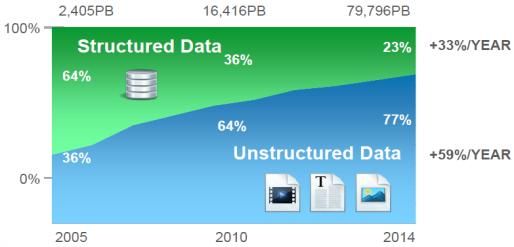
5(5+1). The data is then mirrored elsewhere to perhaps dozens of their Data Computing Appliances51. When your big data is petabytes in size, it practically and economically mandates the use of the largest disk drives available. As we have seen, the rebuild times of big drives in large RAID 6 groups increase the risk of data loss and over time would render RAID 6 impractical. If you needed to store one petabyte of data with RAID 6(14+2), you would need 320 x 4TB drives. With ten petabytes of usable data, you need 3,200 drives. There would almost be a guarantee of data loss. EMC’s Isilon can hold 15 petabytes in a single file system and protect it, as we’ve seen earlier, without the need for traditional RAID. Conclusion Since 1988, RAID has stood watch over our data, guarding it from loss. Mirrored RAID 1, single parity RAID 5, and double parity RAID 6 have done a yeoman’s job providing superior performance and great protection technology. But the battle is shifting, and the 2020 storage world will look completely different. So can we continue to wage tomorrow’s storage protection battles with yesterday’s technology? IDC says an organization in 2012 has about 30% of its data classified as structured data with the rest being unstructured52. Structured data needs fast response time while unstructured is not transactional in nature. Unstructured data can be stored on larger, slower drives since it usually has less stringent response time requirements. IDC predicts structured data will represent an even smaller percentage of stored data, dropping to 23% by 2014. With IDC’s prediction of digital information growing annually by a factor of 44 through 202053, 90% of your data could be unstructured. As discussed, unstructured data can be economically stored on very large, slower, compressed, and even deduplicated drives. Today that is a 4TB drive, but over time, the standard will be 8TB, 12TB, and even 16TB drives. And as we’ve seen, protecting many very large drives is RAID’s Achilles heel. With today’s BER and 4TB drives protected by RAID 6, the risk of data 2012 EMC Proven Professional Knowledge Sharing 25
loss ranges from low to medium. The chances of annual data loss with larger drives can exceed 40%. RAID has evolved over the last 24 years from single parity RAID 5 protection to double parity RAID 6. Along the way, additional technologies such as Reed-Solomon FEC have helped RAID evolve. RAID may not totally disappear by 2020 if storage arrays can offer multiple protection mechanisms. Mirrored RAID would still prove an effective way to boost I/O performance and maintain a low risk profile. Parity RAID should still excel with structured data on small to moderate size drives since it is fast and reliable. As storage processors become faster and bandwidth to the drives increases, larger drives will be rebuilt faster and with less impact on the rest of the storage frame. Protection technologies such as a dispersed RAID, which requires more mathematical computations to store and retrieve data than simple parity calculations, could find their way into the mainstream. Perhaps by then, a storage system will automatically apply “classic” RAID or dispersed RAID based on the nature of the data. Stay tuned! 2012 EMC Proven Professional Knowledge Sharing 26
You can also read

















































