Grayscale Enhancement Colorization Network for Visible-infrared Person Re-identification
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 1
Grayscale Enhancement Colorization Network for
Visible-infrared Person Re-identification
Xian Zhong, Member, IEEE, Tianyou Lu, Wenxin Huang, Student Member, IEEE, Mang Ye, Xuemei Jia,
and Chia-Wen Lin, Fellow, IEEE,
Abstract—Visible-infrared person re-identification (VI-ReID)
is an emerging and challenging cross-modality image matching
problem because of the explosive surveillance data in night-
time surveillance applications. To handle the large modality
gap, various generative adversarial network models have been
developed to eliminate the cross-modality variations based on
a cross-modal image generation framework. However, the lack
of point-wise cross-modality ground-truths makes it extremely
challenging to learn such a cross-modal image generator. To
address these problems, we learn the correspondence between
single-channel infrared images and three-channel visible images
by generating intermediate grayscale images as auxiliary in-
formation to colorize the single-modality infrared images. We
propose a grayscale enhancement colorization network (GECNet)
to bridge the modality gap by retaining the structure of the
colored image which contains rich information. To simulate the
infrared-to-visible transformation, the point-wise transformed
grayscale images greatly enhance the colorization process. Our
experiments conducted on two visible-infrared cross-modality Fig. 1. Comparison of existing generation methods and our col-
person re-identification datasets demonstrate the superiority of orization method. (a) The existing methods generate colored images
the proposed method over the state-of-the-arts. from infrared images directly without pixel-wise single-channel to
three-channel correspondences; (b) the proposed method enhances
Index Terms—Person Re-identification, Visible-infrared, Col-
the colorization network by utilizing grayscale images as intermediate
orization, Cross-modality, Grayscale Enhancement
auxiliary information.
I. I NTRODUCTION
in the visible light environment, focus on analyzing the
P ERSON re-identification (Re-ID) aims at searching for
the same person across different cameras [1]–[12]. Due to
the fast-growing deployment of surveillance systems in urban
appearance discrepancy caused by occlusions, illuminations,
various poses, etc. However, at nights or in practical low-
light environments, effective appearance information may not
areas, person Re-ID has attracted widespread attention in the be available in the captured images, which greatly challenges
computer vision community [13], [14]. Most of the current the applicability of Re-ID in practice. To adapt to practical
research works on Re-ID, which have made abundant progress environments at nights, additional modalities of images, such
as near-infrared/infrared imaging or depth cameras, are often
Manuscript received on October 28, 2020. This work was supported in utilized. This increases the need for challenging cross-modality
part by Department of Science and Technology, Hubei Provincial People’s
Government under Grant 2017CFA012, Fundamental Research Funds for the visible-infrared person Re-ID (VI-ReID) task, which requires
Central Universities of China under Grant 191010001, Hubei Key Laboratory cross-modality matching between the daytime visible and
of Transportation Internet of Things under Grant 2018IOT003, 2020III026GX, nighttime infrared images.
National Natural Science Foundation of China under Grant 62066021, and
Ministry of Science and Technology, Taiwan, under Grants MOST 109-2634- Recent advances in generative adversarial networks (GANs)
F-007-013. (Corresponding author: Wenxin Huang) provide a powerful solution for bridging the modality gap in
Xian Zhong is with School of Computer Science and Technology and Hubei
Key Laboratory of Transportation Internet of Things, Wuhan University of cross-modal image generation. In particular, numerous studies
Technology, Wuhan, China. e-mail: (zhongx@whut.edu.cn) have attempted to use GANs to augment training samples to
Tianyou Lu is with School of Computer Science and Technology, Wuhan solve modality discrepancy problems [15]–[17] in VI-ReID.
University of Technology, Wuhan, China. e-mail: (ksdsh0829@gmail.com)
Wenxin Huang is with School of Computer Science and Information Specifically, a novel cross-modality GAN was proposed in [15]
Engineering, Hubei University, Wuhan, China. e-mail: (wenxinhuang wh@ to cope with the problem of insufficient training samples for
163.com) cross-modality identification. The method proposed in [16]
Mang Ye is with the School of Computer Science, Wuhan University,
Wuhan, China. E-mail: (mangye16@gmail.com) transfers two of the modalities into a unified space and pro-
Xuemei Jia is with School of Computer Science and Technology, Wuhan poses a two-branch GAN to solve the cross-modality problem.
University of Technology, Wuhan, China. e-mail: (jiaxuemei@whut.edu.cn) To match between visible images and infrared ones with
Chia-Wen Lin is with Department of Electrical Engineering and Institute
of Communications Engineering, National Tsing Hua University, Hsinchu, modality discrepancy through feature representation learning,
Taiwan. e-mail: (cwlin@ee.nthu.edu.tw) an alignment GAN was proposed in [17] to address the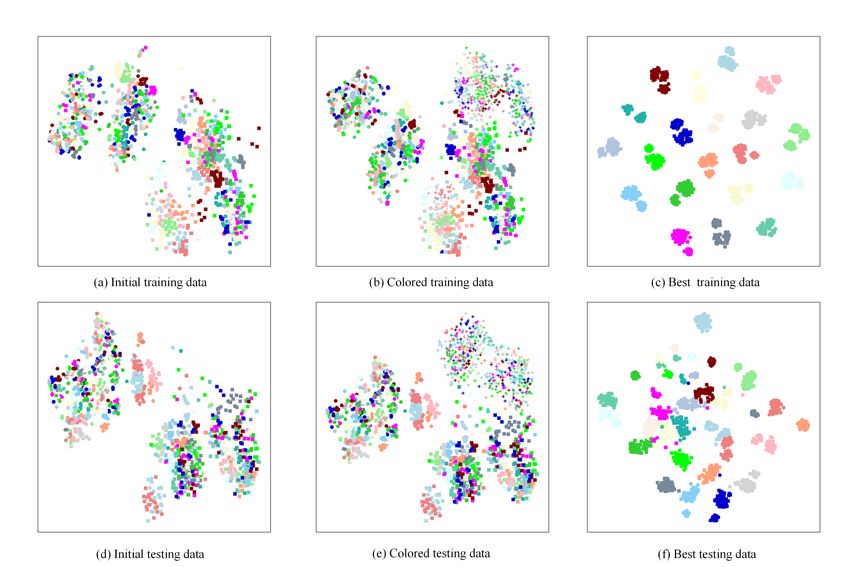
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 2
the single-channel infrared images, providing rich appearance
information; 2) it improves the colorization process by utiliz-
ing the aligned single to three-channel supervision obtained
from the point-wise transformation of grayscale images. The
main contributions are summarized as follows:
• We analyze the importance of point-wise transforma-
tion ground-truths with grayscale images for the cross-
modality generator training under practical settings, e.g.,
there is no point-wise one-to-one infrared-visible pairwise
correspondence on SYSU-MM01 dataset.
• We introduce a GECNet by incorporating a structure
preservation and reconstruction process. It is designed
to make color infrared images similar to corresponding
visible images with the same identity.
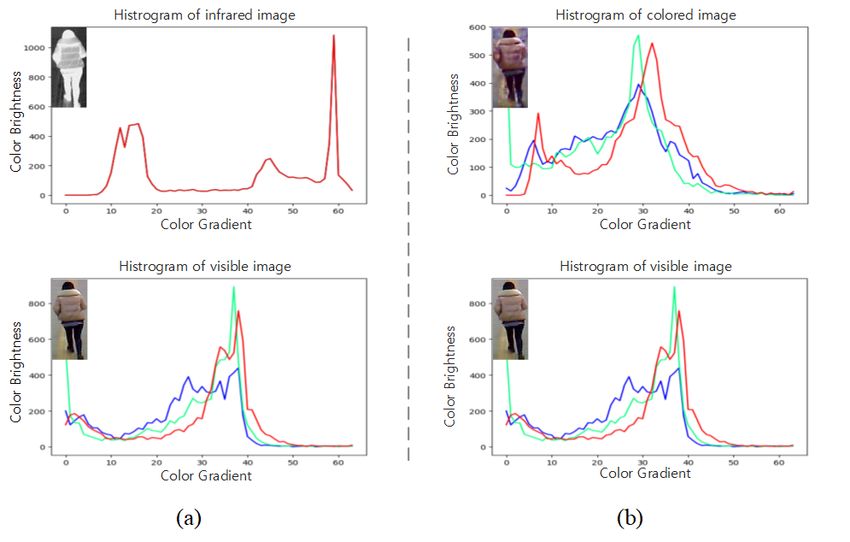
Fig. 2. Comparison of RGB three-channel brightness-gradient his- • We validate the proposed strategy on two cross-modality
tograms of infrared-visible and colored-visible image pairs with the datasets on different baseline methods, achieving consis-
same identity in RegDB dataset. (a) There is an obvious modality tent improvements under various settings.
gap between the infrared image with the red channel only and the
visible image with three channels; (b) since the colored image has Compared with the preliminary conference version in [1],
similar three-channel distributions, the gap is effectively bridged. this journal version has been significantly extended in three
aspects: 1) we give an insightful analysis of the colorization
misalignment problem in the generation process, which can mechanism for the cross-modal person Re-ID problem; 2)
alleviate the cross-modality change in the pixel space and the we propose a grayscale enhancement module, which provides
intra-modality discrepancy in the feature space simultaneously, reliable and informative supervision, to guide the cross-modal
and learn identity-consistent features. As shown in Fig. 1, image generation process; 3) we present comprehensive anal-
existing generation methods resort to using infrared images yses and evaluations to demonstrate the superiority of the
to generate colored images directly. However, since there is proposed method.
usually no point-wise single-channel to three-channel ground- The rest of this paper is organized as follows. Section II
truths, it is hard to evaluate whether the generated images surveys recent work most related to our method. We then
are good or not. Meanwhile, without such cross-modality present our method in detail in Section III. Comprehensive
supervision, the image generation process also faces varying performance evaluation results are shown in Section IV. Fi-
uncertainty. nally, we draw our conclusion in Section V.
As shown in Fig. 2, the visible images and infrared images
are essentially different in various aspects, making the cross- II. RELATED WORK
modal Re-ID task a challenging problem. Hence, it is highly A. Infrared-visible Person Re-ID
desirable to solve the problem of visible-infrared cross-modal Different from traditional single-modal person Re-ID
matching for practical night-time surveillance applications. schemes [18]–[21], current multi-modal person Re-ID schemes
Specifically, the lack of point-wise transformation ground- mainly focus on visible-infrared and text-image cross-modality
truths makes the cross-modal image generation challenging. matching. In the text-image person search, [22] proposed that
The main reason is that it is difficult to identify whether the the recurrent neural network of the gate structure-controlled
generated images are good or not without pair-wise visible- neurological attention mechanism (GNA-RNN) achieves the
infrared supervision. To address the problem, we propose to optimal performance in character search. [23] proposed a
characterize the relation between the single-channel infrared two-stage identity-aware text-visual matching framework. [24]
and three-channel visible images, and colorize infrared images introduced a two-path network with a novel bi-directional two-
accordingly. To this end, we devise a grayscale enhancement constrained top-ranking loss to learn discriminative feature
colorization network (GECNet) to perform the colorization. representations. [25] introduced distribution loss function and
The basic idea behind GECNet is that we utilize the point- correlation loss function to align the embedding features across
wise transformed grayscale images from the visible modality visible and infrared modalities. [26] modeled the affinities of
as the single-channel ground-truth. The synthetic grayscale different modality samples according to the shared features
images offer reliable cross-modality supervision for training and then transfer both shared and specific features among
the colorization network. In addition, we introduce a structure- and across modalities. [27] presented a modality collaborative
preserving network to maximize the distances between iden- ensemble learning to improve the cross-modality Re-ID per-
tities while minimizing the cross-modality distance between formance in both classifier and feature levels. A dual attentive
the colored images and visible images of the same identity. aggregation learning method by incorporating with the part
To further boost performance, a feature-level fusion module is and graph attention is presented in [28]. Generally, cross-
devised to supplement the transfer process of colorization. modality image generation methods provide a good direction
Our proposed GECNet framework has two major advan- to address the modality discrepancy at the image level. In
tages: 1) it minimizes the cross-modality gap by colorizing addition, other advanced cross-modality matching models can
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 3
Fig. 3. Two-branch framework of proposed GECNet, where the orange and green lines represent the infrared and visible branches, respectively,
and ⊕ represents the feature fusion operation. The grayscale images are point-wise transformed from visible images and fed into colorization
Siamese GAN along with the infrared images. The colored image features and the original infrared image features are then fused and
measured with the visible image features.
be applied to further improve the performance when high- and complete text to the general semantic vector space [35]–
quality images are generated. [39]. [35] used a deep convolutional neural network (CNN) to
encode images and used a recurrent neural network (RNN) to
encode texts, thus constructing a visual-semantic embedding
B. Image Generation in Re-ID
space with triplet ranking loss. [36] used the hard negatives in
GAN was originally proposed and had received more and structured prediction in the triplet loss function and combined
more attention in the field of computer vision and artificial with fine-tuning and enhanced data. [37] suggested that it
intelligence research . To the best of our knowledge, more could be an effective method to incorporate the generation
and more researches used GAN to solve cross-modality VI- objects into the cross-view feature embedding learning. [38]
ReID problems. In VI-ReID, [29] presented a deep zero- presented stacked cross attention to discover complete poten-
padding network to learn the invariant feature representations. tial alignments, using image regions and words in sentences
[16] proposed a new two-stage differential reduction learning as contexts.
method to bridge modality gaps. [17] proposed a novel and
end-to-end alignment GAN, which can exploit pixel alignment
D. Colorization
and feature alignment jointly. The method proposed in [30]
presented a thermal multispectral person Re-ID framework. In the past decade, due to the extensive applications of au-
[31] generated person images with different camera styles tomatic colorization in the grayscale image and the restoration
by utilizing the cycle GAN (CycleGAN) with label smooth of aging and degradation image, colorization has been deeply
regularization. CycleGAN with self-similarity and domain studied. Specifically, [40] proposed an algorithm for coloriz-
similarity constraints is also utilized in [32]. [33] exploited ing images by texture synthesis, where the colorization is
the CycleGAN to generate images under different illumination accomplished by matching the texture and semantics of objects
conditions. With a similar idea, [34] proposed to transfer GAN between the existing visible image and the infrared image to
to bridge the gap in the field. However, to solve the prob- be rendered. The colorization method proposed in [41] devises
lems of different poses, lighting, and camera styles, all these a loss function to compensate for the difference between the
methods focus on generating colored images based on infrared weighted average of each pixel and its neighboring pixels. In
images. Without the single-channel to three-channel ground- the adversarial convolutional network in [42]. An image of a
truths, the image generation process is quite challenging and common theme is included throughout the training process,
unstable. which requires highly processed data as a semantic mapping
of the input data. WaterGAN [43] is mainly designed for
underwater visual data repair, and requires a lot of training
C. Deep Cross-modality Matching data to realize.
In the process of text-image matching, a series of rich This paper proposes a learning framework for infrared
research explores the method of mapping the entire image image colorization and feature fusion to optimize the feature
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 4
TABLE I
S UMMARY OF SYMBOLS USED IN THIS PAPER .
Symbol Symbol Meaning
λ1 weighting parameter of cross-entropy loss
λ2 weighting parameter of triplet loss
ω soft weight value
α margin of triplet loss
xV
i visible image
xG
i grayscale image
G generative model
D discriminative model
ImageNet as a feature extractor for further fine-tuning. We
utilize off-the-shelf feature extractors to extract the features
of two heterogeneous modalities. The network parameters of
the two paths are optimized separately to extract modality-
specific features. Subsequently, two loss functions are devised
to supervise network training. The main symbols and their
Fig. 4. Illustration of the distinctions of GECNet (a) without and (b) associated meanings used in this paper are listed in Table I
with grayscale enhancement. Both grayscale and infrared images are for clarity.
used to enhance the trained model. It can be seen that (a) the colored
image obtained using the original GECNet may be noisy, which can
be effectively mitigated by the grayscale enhancement in (b). C. Pixel-wise Transformation
According to the characteristics of the dataset collection,
representation and distance metric for VI-ReID, as shown in there is no pixel-wise correspondence between the three-
Fig. 3. The aim is to generate synthetic colored images by channel visible image and the single-channel infrared image.
extracting the key information of infrared images and then To address this problem, each visible image is uniformly trans-
match the synthetic colored images with the real visible images formed into an intermediate single-channel grayscale image to
by the proposed feature model. approximate a single-channel infrared image. For each visible
image xVi , its grayscale image xGi is generated by:
III. P ROPOSED M ETHOD xG V
L = g(xR,G,B ) (1)
A. Motivation
where g is a grayscale transformation function, which per-
In SYSU-MM01 dataset, pedestrian pairs lack pixel-wise forms pixel-level accumulation on the original red (R), green
structural information across different cameras and time, mak- (G), and blue (B) channels. The cumulative formula is:
ing infrared images unable to find the corresponding visible
images, which greatly increases the difficulty in colorizing L = R × 299/1000 + G × 587/1000 + B × 114/1000 (2)
infrared images. To enhance the colorization network under the The generated intermediate grayscale images retain the origi-
supervision of the pixel-wise single-channel to three-channel nal structural information and can significantly improve cross-
correspondences, we transform visible images into grayscale modal Re-ID performance.
images which are similar to the form of infrared images and
feed the image pairs together into the colorization Siamese
D. Grayscale Enhancement Colorization Network
GAN (SiGAN) [44] for training. As demonstrated in Fig. 4,
our algorithm introduces grayscale images in the colorization To retain the structure information of the colored image, the
process, which effectively mitigates the noise caused by the proposed GECNet is trained on pairs of infrared images with
lack of structural information. two different identities or the same identity. GECNet consists
of two identical generators and a discriminator sharing the
same model parameters, which is inspired by the Siamese
B. Framework network and the deep convolutional GAN (DCGAN) [47].
Our framework consists of two parts. One is based on While training GECNet, the generator pair is used to color
colorization SiGAN to bridge the modality gap between the a pair of infrared images to generate visible images, and the
visible and infrared image domains, and the other is a func- discriminator is used to determine whether the pair of visible
tional fusion network to reduce the appearance discrepancy, images are real or fake. We introduce an identity-aware loss
mainly refer to the super-resolution (SR) method based on function with three loss terms to effectively learn color and
deep learning [44]–[46]. Specifically, we use ResNet in our identity representation, including adversarial loss, reconstruc-
framework as a backbone network for visible and infrared tion loss, and structure-preserving contrastive loss. In addition
branches. In the VI-ReID task, owing to the lack of sufficient to the traditional reconstruction and adversarial loss used in
training data, we pre-train the convolutional layers, the four GAN training, contrastive loss aims to increase the energy of
bottleneck layers, and the fully connected (FC) layer on different-identity pairs and reduce the energy of same-identity
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 5
pairs, so as to effectively improve the authenticity of colored the reconstructed viewpoint substitute but also minimizes the
images. loss LG between the grayscale-enhanced pair.
Generator (G) represents the cross-modality image gener- The reconstruction loss of the generator is defined as the
ation process, which contains five convolutional units [48] L2 norm of the difference between predicted and ground-truth
and five convolution-transpose units. In particular, we inte- averaged over all pixels:
grate with residual blocks to speed up the convergence and n
improve the training effect, where batch normalization (BN) 1X
LRec (G) = kG(xIi )(p) − (xVi )(p) k22
is performed after each layer and leaky rectified linear unit n p=1
(ReLU). The BN or activation function is not used in the last n (9)
1X
layer of the network. + kG(xG
i )
(p)
− (xVi )(p) k22
n p=1
Discriminator (D) is a fully convolutional network, con-
sisting of a series of 3 × 3 convolutional layers, where each
where xIi means infrared image, xG i means grayscale image,
convolutional layer is followed by a max-pooling layer, and the
xVi is its visible version, p denotes the pixel index, n denotes
number of channels doubles after each downsampling. Behind
the total number of pixels, and G means the infrared-to-color
all convolutional layers are BN and leaky ReLU activation.
mapping function.
After the last layer, convolution is used to map features
Finally, the overall loss function is a combination of the
to a one-dimensional output, which is a normalized value
adversarial loss, reconstruction loss, and structural-preserving
indicating whether the input image is real or fake, where the
contrastive loss:
input of the discriminator is a colored image from a generator
or sensor. LGECN et = LGAN + LC + LRec (10)
To learn structure-preserving features while training
SiGAN, we incorporate the contrastive loss term into the loss By optimizing the above losses, we obtain a network that
function. We replace random noise z with input infrared image can convert infrared image xIi or grayscale image xG
i to its
xIi . As a result, given grayscale image pair, xG G corresponding visible image xVi . With this method, all the
i and xj , and
V V
the pairwise visible pair, xi and xj , the adversarial loss images from different modalities will share the same image
incorporated in GAN training is formulated below: space, which greatly reduces the modality gap at the pixel
level.
LGAN (D, G) = ED (log D(xG
i ))
(3)
+ EG (log(1 − D(G(xIi )))) E. Feature Fusion
where G(xIi )is the colored version of image xIi ,
D(x) is the By transforming infrared images into visible images, the
probability of the data sample x being verified, and D(x) = 1 appearance differences between different modalities can be
indicates that x is verified as a real sample; otherwise D(x) = effectively mitigated by feature embedding networks. Specif-
0. ically, together with the colored images, we use state-of-the-
When we add grayscale images, the formula becomes: art visible-infrared method AGW [2] as the baseline network
for cross-modality representation learning, and use generalized
LGAN (D, G) = ED (log D(xVi )) mean (GeM) pooling [49] to replace the original pooling layer.
+ EG (log(1 − D(G(xIi )))) (4) Actually, for each batch of training image samples, the visible
+ EG (log(1 − D(G(xG
i ))))
images and infrared images only share partial parameters,
which is detailed in AGW. Meanwhile, since visible and
The contrastive loss is used to embed the binary identity colored images share similar appearance characteristics, we
label to supervise the training of the generator pair as follows: use two feature extractors with the same shared parameters to
LC (G) = (1 − y)LI (Ew (G(xIi ), G(xIj ))) map their features to a common latent space.
To complement the loss of information caused by the
+ yLG (Ew (G(xIi ), G(xIj ))) colorization of infrared images, an attention model is used
(5)
+ (1 − y)LI (Ew (G(xG G
i ), G(xj ))) to extract the original infrared image features. A soft weight
+ yLG (Ew (G(xG G value is assigned to the spatial distribution of features, and the
i ), G(xj )))
weight value is achieved by setting:
where
Ew = kx1 − x2 k11 (6) f = (1 − ω) FC(xC I
i ) + ω softmax(xi ) (11)
1 where FC represents the FC layer, xC I
i and xi respectively rep-
LI = (max(0, m − Ew ))2 (7) resent the colored feature and infrared feature, and softmax(·)
2
represents the softmax function.
1 Based on existing person Re-ID methods, we adopt two
LG = (Ew )2 (8)
2 widely-used loss functions including cross-entropy loss and
where m = 0.5, and Ew denotes the L1 norm in the pixel triplet loss as a learning objective. The basic idea of the cross-
domain. It is worth noting that the contrastive loss term not entropy is to treat each person identity as a distinct class and
only minimizes the marginal loss LI between xIi and xIj of to treat images of the same identity person from different
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 6
TABLE II
C OMPARISON OF RANK -r ACCURACY (%) AND M AP (%) PERFORMANCES WITH THE STATE - OF - THE - ARTS ON R EG DB. B OLD AND
BLUE NUMBERS ARE THE BEST AND SECOND - BEST RESULTS RESPECTIVELY.
Visible to Infrared Infrared to Visible
Approach Venue
r=1 r = 10 r = 20 mAP r=1 r = 10 r = 20 mAP
HCML [50] AAAI 18 24.44 47.53 56.78 20.08 21.70 45.02 55.58 22.24
BDTR [24] IJCAI 18 34.62 - - 33.46 34.21 - - 32.49
MAC [51] ACM MM 19 36.43 62.36 71.63 37.03 36.20 61.68 70.99 36.63
D2 RL [16] CVPR 19 43.4 66.1 76.3 44.1 - - - -
HSME [52] AAAI 19 50.85 73.36 81.66 47.00 50.15 72.40 81.07 46.16
AlignGAN [17] ICCV 19 57.9 - - 53.6 56.3 - - 53.4
eBDTR [53] TIFS 20 34.62 58.96 68.72 33.46 34.21 58.74 68.64 32.49
CoSiGAN [1] ICMR 20 47.18 65.97 75.29 46.16 - - - -
MSR [54] TIP 20 48.43 70.32 79.95 48.67 - - - -
EDFL [55] Neurocomputing 20 52.58 72.10 81.47 52.98 51.89 72.09 81.04 52.13
X-Modal [56] AAAI 20 62.21 83.13 91.72 60.18 - - - -
CMSP [57] IJCV 20 65.07 83.71 - 64.50 - - - -
AGW [2] arXiv 20 70.05 - - 66.37 69.13 - - 65.22
Hi-CMD [58] CVPR 20 70.93 86.39 - 66.04 - - - -
cm-SSFT [26] CVPR 20 72.3 - - 72.9 71.0 - - 71.7
CoAL [59] ACM MM 20 74.12 90.23 94.53 69.87 - - - -
GECNet (VRC [60]) 73.83 88.30 91.60 72.72 72.72 88.88 92.82 70.47
GECNet (RTUG [61]) 74.90 89.56 93.16 73.34 73.83 88.30 91.60 71.72
GECNet (DCGAN [62]) 75.78 89.32 93.25 73.78 73.25 87.86 91.75 71.79
GECNet 82.33 92.72 95.49 78.45 78.93 91.99 95.44 75.58
TABLE III
C OMPARISON OF RANK -r ACCURACY (%) AND M AP (%) PERFORMANCES WITH THE STATE - OF - THE - ARTS ON SYSU-MM01. B OLD
AND BLUE NUMBERS ARE THE BEST AND SECOND - BEST RESULTS RESPECTIVELY.
All Search Indoor Search
Approach Venue
r=1 r = 10 r = 20 mAP r=1 r = 10 r = 20 mAP
TONE [50] AAAI 18 12.52 50.72 69.60 14.42 20.82 69.86 84.46 26.38
HCML [50] AAAI 18 14.32 53.16 69.17 16.16 24.52 73.25 86.73 20.08
cmGAN [15] IJCAI 18 26.97 67.51 80.56 31.49 31.63 77.23 89.18 42.19
BDTR [24] IJCAI 18 27.23 - - 29.29 32.46 - - 42.46
TCMDL [63] TCSVT 19 16.91 58.83 76.64 19.30 21.60 71.38 87.91 32.27
HSME [52] AAAI 19 20.68 32.74 77.95 23.12 - - - -
D2 RL [16] CVPR 19 28.90 70.60 82.40 39.56 28.12 70.23 83.67 29.01
SDL [8] TCSVT 19 32.56 80.45 90.67 29.20 - - - -
MAC [51] ACM MM 19 33.26 79.04 90.09 36.22 36.43 62.36 71.63 37.03
HPILN [64] IET-IPR 19 41.36 84.78 94.31 42.95 45.77 91.82 98.46 56.52
AlignGAN [17] ICCV 19 42.4 85.0 93.7 40.7 45.9 87.6 94.4 54.3
eBDTR [53] TIFS 20 27.82 67.34 81.34 28.43 32.46 77.42 89.62 42.46
Hi-CMD [58] CVPR 20 34.94 77.58 - 35.94 - - - -
CoSiGAN [1] ICMR 20 35.55 81.54 90.43 38.33 - - - -
MSR [54] TIP 20 37.35 83.40 93.34 38.11 39.64 89.29 97.66 50.88
LZM [65] SPIC 20 45.00 89.06 - 45.94 49.66 92.47 - 59.81
AGW [2] arXiv 20 47.50 - - 47.65 54.17 - - 62.97
GECNet (VRC [60]) 48.38 84.35 91.98 46.65 54.30 91.21 96.69 62.07
GECNet (RTUG [61]) 48.25 84.54 92.06 48.27 54.71 90.72 96.92 62.14
GECNet (DCGAN [62]) 48.67 84.80 92.32 48.40 55.16 90.76 96.69 62.69
GECNet 53.37 89.86 95.66 51.83 60.60 94.29 98.10 62.89
modalities as the same class. Triplet loss aims at making cross- where [x]+ ≡ max(x, 0) truncates negative numbers to zero
modal features as close for the same person while separating while keeping positive numbersP the same and s(·, ·) calculates
them far apart for different persons in the embedded space. the Euclidean distance. The xb I part represents all negatives
j
Triplet loss uses hinge-based triplet ranking loss with in infrared image xb Ij given visible image xVi , the xb V part
P
j
margin α for similarity learning:
squares up all negative images x b Vj given infrared image xIi . If
xVi and xIi are closer to each other in the embedded space than
X
Ltri = xIj ))]+
[α − s(f (xVi ), f (xIi )) + s(f (xVi ), f (b
x̂Ij any negative pair margin α, the hinge loss is zero. In practical
X applications, to improve the discriminability and avoid fitting
+ xVj ), f (xIi ))]+
[α − s(f (xVi ), f (xIi )) + s(f (b to easy samples, only the hard negative values in the mini-
x̂V
j batch stochastic gradient descent (SGD) process are usually
(12)
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 7
Fig. 6. Performance evaluation of rank-1 accuracy (%) and mAP (%)
with various weighting parameter λ1 and λ2 on RegDB (left) and
SYSU-MM01 (right). The left one sets λ1 = 1 and λ2 ∈ [0, 1] for
RegDB, and the right one sets λ2 = 1 and λ1 ∈ [0, 1] for SYSU-
MM01.
B. Evaluation Metrics
We utilize the standard evaluation criteria employed in
Fig. 5. Examples of 64 × 128 image generated from RegDB and most of the previous VI-ReID task work [15], [16], [53].
SYSU-MM01 dataset. Each row indicates the same person, with three We measure evaluation metrics rank-r matching accuracy and
kinds of images, (a) infrared image, (b) visible image, and (c) colored mean average precision (mAP). The rank-r calculates the
image. percentage of testing samples that find the correct result in
the top r search outcomes of the query sample. We report
considered, instead of summarizing all the negative samples.
the results of rank-1, rank-10, and rank-20, respectively. The
Cross-entropy loss is employed for identity learning and is
metric mAP is an average of the maximum recalls for each
written as:
n B class in multiple types of tests. For a fair comparison, all
1 XX
Lce = − log pi,n (13) our results do not use any re-ranking or multi-query fusion
B n=0 i=0 techniques.
where B is the number of images in the training minibatch,
pi,n is the predicted probability that the i-th input belongs to C. Training Details
the n-th ground-truth class: Our model is implemented on the PyTorch platform. Our
pi,n = softmax(W fi,n + b) (14) experiments use ResNet-50 as the feature extraction backbone,
utilizing a single-center random crop size of 144 × 288.
where W and b are the trainable classifier weights. We adopt SGD to optimize the network, and the momentum
Overall Learning Objective is a combination of cross- parameter is set to 0.9. The total number of training epochs
entropy and triplet losses as following: is 60. We start training with a learning rate of 0.01 for 30
L = λ1 Lce + λ2 Ltri (15) epochs and then decrease the learning rate to 0.001 for another
30 epochs. The batch size employed in all experiments is 64.
where λ1 and λ2 are the weighting parameters for the cross- We evaluate the effect of weight parameters λ1 and λ2 for
entropy loss and the triplet loss. the two loss terms in (15) from 0 to 1. When configured with
the triplet loss, we adopt the hard mining strategy and set the
IV. E XPERIMENTAL R ESULTS margin α to 0.2 for both datasets. Given an input testing image,
A. Datasets we use the output of the shared FC layer as the final feature
representation for Re-ID. After each epoch, the embedding
We evaluate our method on two publicly available datasets,
model is evaluated on the validation set. The finished colored
RegDB [66] and SYSU-MM01 [29].
images are shown in Fig. 5.
RegDB, captured by dual (visible and infrared) cameras,
contains a total of 412 persons, each with 10 pairs of visible
and infrared images. We randomly divided the dataset into two D. Comparison with the State-of-the-arts
halves according to the evaluation protocol in [24] for training We report the results for the VI-ReID task on RegDB
and testing. and SYSU-MM01 in Table II and Table III, respectively.
SYSU-MM01, captured by six cameras (including four Several representative VI-ReID methods are compared, in-
visible cameras and two infrared cameras), contains a total cluding HCML [50], BDTR [24], MAC [51], D2 RL [16],
of 491 persons, and each person is captured by at least two HSME [52], AlignGAN [17], eBDTR [53], CoSiGAN [1],
different cameras. The training set contains 395 persons, with MSR [54], EDFL [55], X-Modal [56], CMSP [57], AGW [2],
a total of 22,258 visible images in Cam 1, Cam 2, Cam 4, and Hi-CMD [58], cm-SSFT [26], CoAL [59], cmGAN [15],
Cam 5, and 11,909 infrared images in Cam 3 and Cam 6. The TCMDL [63], SDL [8], HPILN [64], and LZM [65].
testing set contains 96 persons, with 3,803 infrared images The results in Table III and Table II show that the proposed
for the query, and 301 randomly selected visible images as GECNet, involving infrared image colorization, grayscale en-
the gallery set. hancement, and feature fusion, significantly outperforms the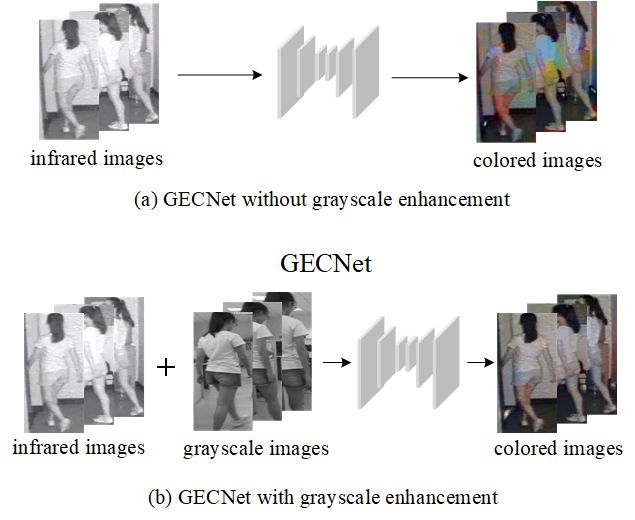
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 8
TABLE IV
P ERFORMANCE COMPARISON OF RANK -1 ACCURACY (%) AND M AP (%) WITH DIFFERENT VARIANTS OF OUR METHOD ON R EG DB
AND SYSU-MM01, WHERE THE BASELINE IS ADOPTED FROM [2]. B OLD AND BLUE NUMBERS ARE THE BEST AND SECOND - BEST
RESULTS RESPECTIVELY.
RegDB SYSU-MM01
Baseline Colorization Grayscale Fusion Visible to Infrared Infrared to Visible All Search Indoor Search
r=1 mAP r=1 mAP r=1 mAP r=1 mAP
X × × × 70.05 66.37 69.13 65.22 47.50 47.65 54.17 62.97
X X × × 75.78 73.78 73.25 71.79 48.67 48.40 55.16 62.69
X X X × 77.04 74.04 76.32 73.67 50.03 49.63 57.23 62.55
X X × X 77.38 74.46 76.78 74.07 51.51 50.68 58.43 62.71
X X X X 82.33 78.45 78.93 75.58 53.37 51.83 60.60 62.89
TABLE V
P ERFORMANCE COMPARISON OF RANK -1 ACCURACY (%) AND M AP (%) WITH DIFFERENT VARIANTS OF OUR METHOD ON R EG DB
AND SYSU-MM01, WHERE THE BASELINE IS ADOPTED FROM [24]. B OLD AND BLUE NUMBERS ARE THE BEST AND SECOND - BEST
RESULTS RESPECTIVELY.
RegDB SYSU-MM01
Baseline Colorization Grayscale Fusion Visible to Infrared Infrared to Visible All Search Indoor Search
r=1 mAP r=1 mAP r=1 mAP r=1 mAP
X × × × 34.62 33.46 34.21 32.49 27.23 29.29 32.46 42.46
X X × × 43.66 42.68 43.17 41.55 29.56 32.98 33.97 42.76
X X X × 46.70 45.51 46.30 44.72 34.37 37.46 36.11 42.92
X X × X 47.18 46.16 46.01 45.03 35.55 38.33 37.65 42.89
X X X X 50.14 48.97 49.46 48.08 35.80 37.95 38.03 43.12
Fig. 7. Visualization of feature distributions of gray-scale, infrared, and visible images in the first two prominant dimensions of the initial,
colored, and the results of the best training/testing data. A total of ten persons are randomly selected from SYSU-MM01 set. Here, each color
represents an identity, and each shape represents a modality. (a)–(c) and (d)–(f) are obtained using training and testing data on SYSU-MM01,
respectively.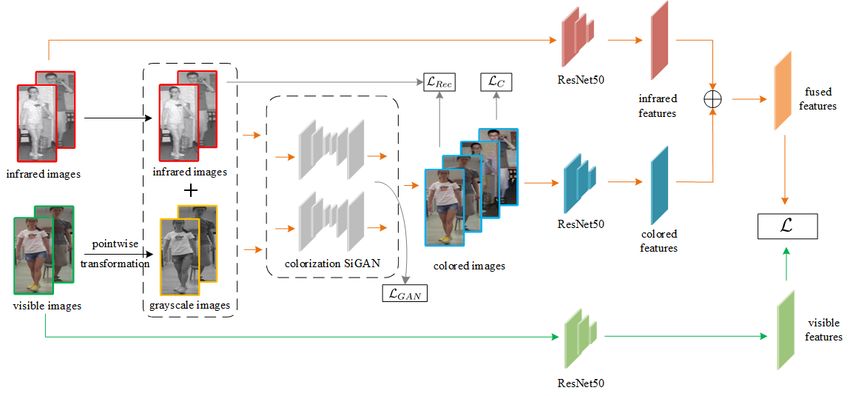
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 9
TABLE VI
P ERFORMANCE VALUATION OF RANK -1 ACCURACY (%) AND
M AP (%) FOR FIVE DIFFERENT VALUES OF WEIGHTING
PARAMETER ω ON R EG DB AND SYSU-MM01, RESPECTIVELY.
B OLD NUMBERS ARE THE BEST RESULTS .
RegDB SYSU-MM01
ω
r=1 mAP r=1 mAP
0.1 79.34 75.30 52.87 50.93
0.3 82.33 78.45 53.37 51.83
0.5 81.02 77.85 52.73 51.34
0.7 81.46 78.14 52.63 50.67
0.9 80.83 77.71 51.98 50.30
state-of-the-art methods, especially on RegDB, showing that
GECNet is remarkably effective for VI-ReID tasks. From the
view of methodology, several observations can be made. Our
proposed GECNet significantly outperforms the second-best
method AGW [2] by 5.87% and 4.18% in terms of rank-1
Fig. 8. Visualization of Baseline (first row) and our method (sec-
and mAP score, respectively, which further demonstrates the ond row). Red and blue bins indicate the negative and positive
effectiveness of our model for VI-ReID. distributions respectively. The x-axis value represents the matching
similarity, the closer to 1 represents the more similar, and the y-axis
value represents the number of images with current similarity. The
E. Further Evaluation and Analysis performance of our algorithm in the training and testing sets is much
1) Ablation Study: We design four variants of our model better than the baseline.
and conduct experiments with two different baselines, [2] and
[24], to evaluate the effectiveness of the individual modules accuracy by incorporating the Re-ID feature into adversarial
proposed in our work. The settings include the baseline, training. Finally, all settings can improve rank and mAP
colorization, grayscale enhancement, and feature fusion. The accuracy by using re-ranking. Similarly, the results on SYSU-
results of these settings in single-shot are shown in Table IV MM01 shown in Table IV also draw the same conclusion
and Table V. as that for RegDB, but the impact of colorization is slightly
We further discuss visible-to-infrared and infrared-to-visible lower.
Re-ID on RegDB and “all search” and “indoor search” on Compare to DCGAN [62], the major advantage is that
SYSU-MM01. As can be seen from Table IV and Table V, we explicitly model the identity preservation constraint in
the results of the “all search” are not as good as the results the colorizing process. In addition, we incorporate a Siamese
of the “indoor search”, while Visible-to-infrared is better than network strategy for two different modalities, which allows
infrared-to-visible. The main reason is that the background of modality-specific information mining. Table II and Table III
indoor images is relatively simple and easy to recognize, and compare SiGAN with colorization using DCGAN, showing
visible images have more information. that SiGAN outperforms the DCGAN-based approach.
From Table IV, we can see that the baseline achieves We propose a GECNet to bridge the cross-modality gap by
70.05% rank-1 accuracy on RegDB, which is directly trained colorizing the single-channel infrared images, which provid-
on [2] with both visible and infrared modalities using triplet ing rich appearance information. Moreover, it improves the
loss and cross-entropy classification loss. The colorization colorization process by utilizing the aligned single to three-
module achieves 76.16% rank-1 accuracy, leading to 6.1% im- channel supervision obtained from the point-wise transforma-
provements over the baseline. This is because the colorization tion of grayscale images. In order to verify the effectiveness
can effectively mitigate the domain gap between visible and of our colorization method, we have additionally compared
infrared modalities by converting the infrared feature maps the colorization methods of VRC [60] and RTUG [61] on two
to the colored feature maps, which is close to the middle datasets, as shown in Table II and Table III. It demonstrates
layer feature map of visible input. With the help of this that our colorization method is better than others for visible-
scheme, the Re-ID backbone can learn infrared information infrared cross-modality applications.
from colorizing images. Furthermore, the colorization with 2) Selection of Weighting Parameters: We evaluate the
grayscale enhancement obtains 77.04% rank-1 accuracy. This selection of weighting parameter λ1 and λ2 of the cross-
validates that fusing with grayscale images can enhance the entropy loss and the triplet loss. The cross-entropy loss and
ability of colored images to mine useful information from triplet loss have different impacts on cross-modality person
infrared channels to improve the performance of VI-ReID. The Re-ID learning. Generally, the cross-entropy loss is more
colorization with grayscale enhancement and feature fusion important for large-scale datasets, which offer enough sam-
obtains 82.33% rank-1 accuracy, which is the highest with- ples for identity discrimination. In contrast, the triplet loss
out re-ranking. The grayscale augmented images can further generally makes greater impact on small-scale RegDB datasets
improve the image generation performance and person Re-ID due to closer sample relations. Similar observations were also
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 10 Fig. 9. Top-10 retrieved results of some example queries with the proposed method on SYSU-MM01. Green and red bounding boxes indicate the correct and incorrect matches, respectively (best viewed in color). reported in [53]. Specifically, we set λ1 = 1 and adjust the respectively setting ω to five different values, 0.1, 0.3, 0.5, weighting parameter λ2 ∈ [0, 1] on the small dataset RegDB. 0.7, and 0.9. Table VI shows the effect of soft weight on the In contrast, we set λ2 = 1 on the large dataset SYSU-MM01, performance of the VI-ReID task. Since ω = 0.3 performs and adjust the weighting parameter λ1 ∈ [0, 1]. The results the best on both datasets, we select that to achieve fast on the two datasets are shown in Fig. 6. convergence. We can observe that the triplet loss can effectively improve 4) Visualization of Learned Images and Features: To bet- the performance of VI-ReID. For the small dataset RegDB, we ter understand the pixel and feature alignment modules, we assign a smaller value to the triplet loss, where the weighting evaluate the feature-level views of training and testing sets parameter λ2 is set to 0.3 in our experiment. A larger λ2 on SYSU-MM01. We obtain the T-SNE [67] distributions is likely to disrupt the learning process, so the performance of learned feature vectors in Fig. 7. Gray-scale images and will drop sharply. On the contrary, for the large dataset infrared images only contain a single channel, and visible RGB SYSU-MM01, we assign a smaller value λ1 to the cross- images involve three channels. The circles represent gray- entropy loss. We can observe that using an appropriate λ1 can scale images, the plus signs represent infrared images, and improve performance, while a larger λ1 will hurt performance. the squares represent visible RGB images. The distributions This problem can be addressed by using the triplet loss as illustrate that the characteristics of infrared and gray-scale supervision to initialize the pre-trained parameters, which images are more similar. To obtain the distributions, a total further demonstrates the importance of the triplet loss for of ten identities are randomly selected from SYSU-MM01. cross-modality person Re-ID. In fact, the curves in Fig. 6 show Figs. 7.(a), (b), and (c) visualize the feature distributions that it is not hard to learn the (sub)optimal values of hyper- with the initial, colored, and best results of the training parameters λ1 and λ2 for different target domains by using sets, respectively, and Figs. 7.(d), (e), and (f) visualize the gradient-ascent methods. Moreover, even using the same set distributions with the initial, colored, and best testing sets of hyper-parameters, our method still outperforms the state- respectively. Fig. 7.(b) adds colored feature on the basis of of-the-arts. Fig. 7.(a). The results demonstrate that our proposed model not 3) Selection of Soft Weight: We study the selection of only reduces the cross-modality variations but also maintains soft weight ω with the proposed ranking loss in (11), by the identity-consistency of features.
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 11
We use another method in Fig. 8 to visualize the pos- modality gap issue in VI-ReID from the cross-modal image
itive/negative distribution of the training and testing sets generation perspective.
with the baseline [2] and our methods. This further explains
why our method outperforms the baseline in terms of the R EFERENCES
distributions of the training and testing sets. Since grayscale
[1] X. Zhong, T. Lu, W. Huang, J. Yuan, W. Liu, and C. Lin, “Visible-
enhancement is used for colorization in our method, it sepa- infrared person re-identification via colorization-based Siamese gener-
rates the two distributions of the infrared-visible positive and ative adversarial network,” in Proc. ACM Int. Conf. Multim. Retrieval,
negative pairs further apart compared to the baseline. As a 2020, pp. 421–427.
[2] M. Ye, J. Shen, G. Lin, T. Xiang, L. Shao, and S. C. H. Hoi, “Deep
result, the use of grayscale enhanced colored images improves learning for person re-identification: A survey and outlook,” arXiv
the versatility of the training and testing set, showing stronger abs/2001.04193, 2020.
discriminating power to distinguish visible and infrared im- [3] Y. Sun, L. Zheng, Y. Yang, Q. Tian, and S. Wang, “Beyond part models:
Person retrieval with refined part pooling (and A strong convolutional
ages. baseline),” in Proc. Springer European Conf. Comput. Vis., 2018, pp.
5) Indoor Search on SYSU-MM01: We evaluate the 501–518.
[4] Z. Zheng, L. Zheng, and Y. Yang, “Pedestrian alignment network for
method in the “indoor search” mode of SYSU-MM01. In large-scale person re-identification,” IEEE Trans. Circuits Syst. Video
particular, the gallery set excludes images from two outdoor Technol., vol. 29, no. 10, pp. 3037–3045, 2019.
cameras and uses the same probe set as Cam 3 and Cam [5] Z. Huang, Z. Wang, W. Hu, C. Lin, and S. Satoh, “DoT-GNN: Domain-
transferred graph neural network for group re-identification,” in Proc.
6. A detailed description of this evaluation protocol can be ACM Int. Conf. Multim., 2019, pp. 1888–1896.
found in [29]. Compared with the previous single search mode, [6] Q. Leng, M. Ye, and Q. Tian, “A survey of open-world person re-
this protocol is less challenging. Compare to the competing identification,” IEEE Trans. Circuits Syst. Video Technol., vol. 30, no. 4,
pp. 1092–1108, 2020.
methods, the results shown in Table III demonstrate that our [7] L. Wu, R. Hong, Y. Wang, and M. Wang, “Cross-entropy adversarial
method again outperforms the competing baseline under this view adaptation for person re-identification,” IEEE Trans. Circuits Syst.
evaluation protocol. Video Technol., vol. 30, no. 7, pp. 2081–2092, 2020.
[8] K. Kansal, A. V. Subramanyam, Z. Wang, and S. Satoh, “SDL:
6) Top Retrieved Examples: We display the top ten retrieval Spectrum-disentangled representation learning for visible-infrared per-
results of five randomly selected query examples on SYSU- son re-identification,” IEEE Trans. Circuits Syst. Video Technol., vol. 30,
MM01 in Fig. 9. The similarity score between the visible no. 10, pp. 3422–3432, 2020.
[9] F. Yang, Z. Wang, J. Xiao, and S. Satoh, “Mining on heterogeneous
image and the infrared image is recorded at the top of each manifolds for zero-shot cross-modal image retrieval,” in Proc. AAAI
image. We observe that due to the large modality gap between Conf. Artif. Intell., 2020, pp. 12 589–12 596.
the visible and infrared images, it is very difficult for a person [10] Z. Wang, Z. Wang, Y. Zheng, Y. Wu, W. Zeng, and S. Satoh, “Beyond
intra-modality: A survey of heterogeneous person re-identification,” in
to distinguish those who are the correct match for the queries Proc. Int. Joint Conf. Artif. Intell., 2020, pp. 4973–4980.
by naked eyes. The challenging task plays an important role [11] Z. Wang, W. Liu, Y. Matsui, and S. Satoh, “Effective and efficient:
in night surveillance applications. Even though there are some Toward open-world instance re-identification,” in Proc. ACM Int. Conf.
Multim., 2020, pp. 4789–4790.
incorrect retrieval results in the ranking, the top ones still show [12] K. Zhou, Y. Yang, A. Cavallaro, and T. Xiang, “Learning general-
a similarly textured or structured appearance. The visualization isable omni-scale representations for person re-identification,” arXiv
results verify the superiority of our method. abs/1910.06827, 2019.
[13] W. Huang, R. Hu, C. Liang, Y. Yu, Z. Wang, X. Zhong, and C. Zhang,
7) Different Query Settings on RegDB: We also evaluate “Camera network based person re-identification by leveraging spatial-
the performances under two different query settings, visible-to- temporal constraint and multiple cameras relations,” in Proc. Int. Conf.
infrared matching and infrared-to-visible matching on RegDB. Multim. Model., 2016, pp. 174–186.
[14] C. Luo, Y. Chen, N. Wang, and Z. Zhang, “Spectral feature transforma-
We can observe from Table II that our method achieves close tion for person re-identification,” in Proc. IEEE/CVF Int. Conf. Comput.
performance for both query settings, where the difference is Vis., 2019, pp. 4975–4984.
less than 2%. The rank-1 matching accuracy is about 78% [15] P. Dai, R. Ji, H. Wang, Q. Wu, and Y. Huang, “Cross-modality person
re-identification with generative adversarial training,” in Proc. Int. Joint
and the mAP is about 76% in both settings. Meanwhile, our Conf. Artif. Intell., 2018, pp. 677–683.
method outperforms the competing methods under both set- [16] Z. Wang, Z. Wang, Y. Zheng, Y. Chuang, and S. Satoh, “Learning to re-
tings, demonstrating its robustness and flexibility in practical duce dual-level discrepancy for infrared-visible person re-identification,”
in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2019, pp. 618–
night-time applications with different query settings. 626.
[17] G. Wang, T. Zhang, J. Cheng, S. Liu, Y. Yang, and Z. Hou, “Rgb-
infrared cross-modality person re-identification via joint pixel and fea-
V. C ONCLUSION ture alignment,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp.
3622–3631.
We proposed a colorization-based GECNet model to gen- [18] H. Luo, Y. Gu, X. Liao, S. Lai, and W. Jiang, “Bag of tricks and a
erate the synthetic visible versions of input infrared images. strong baseline for deep person re-identification,” in Proc. IEEE/CVF
In the colorization process, GECNet converts the input visible Conf. Comput. Vis. Pattern Recognit. Worksh., 2019, pp. 1487–1495.
[19] S. Zhou, J. Wang, D. Meng, Y. Liang, Y. Gong, and N. Zheng,
images to their corresponding grayscale images and incorpo- “Discriminative feature learning with foreground attention for person
rate them as a part of training samples. GECNet aims to learn re-identification,” IEEE Trans. Image Process., vol. 28, no. 9, pp. 4671–
the identity-aware representation to minimize the discrepancy 4684, 2019.
[20] K. Zhou, Y. Yang, A. Cavallaro, and T. Xiang, “Omni-scale feature
between the colored image and its corresponding visible image learning for person re-identification,” in Proc. IEEE/CVF Int. Conf.
while matching the identity. In addition, we have also proposed Comput. Vis., 2019, pp. 3701–3711.
a feature fusion module to retain the features of the original [21] S. Zhou, J. Wang, J. Wang, Y. Gong, and N. Zheng, “Point to set
similarity based deep feature learning for person re-identification,” in
infrared image and the rich texture and semantics provided Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2017, pp. 5028–
by the visible version. Our method effectively addresses the 5037.IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, 2021 12
[22] S. Li, T. Xiao, H. Li, B. Zhou, D. Yue, and X. Wang, “Person search [46] P. Yi, Z. Wang, K. Jiang, Z. Shao, and J. Ma, “Multi-temporal ultra dense
with natural language description,” in Proc. IEEE/CVF Conf. Comput. memory network for video super-resolution,” IEEE Trans. Circuits Syst.
Vis. Pattern Recognit., 2017, pp. 5187–5196. Video Technol., vol. 30, no. 8, pp. 2503–2516, 2020.
[23] S. Li, T. Xiao, H. Li, W. Yang, and X. Wang, “Identity-aware textual- [47] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation
visual matching with latent co-attention,” in Proc. IEEE/CVF Int. Conf. learning with deep convolutional generative adversarial networks,” in
Comput. Vis., 2017, pp. 1908–1917. Proc. Int. Conf. Learn. Rep., 2016.
[24] M. Ye, Z. Wang, X. Lan, and P. C. Yuen, “Visible thermal person re- [48] O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional net-
identification via dual-constrained top-ranking,” in Proc. Int. Joint Conf. works for biomedical image segmentation,” in Proc. Springer Int. Conf.
Artif. Intell., 2018, pp. 1092–1099. Medical Image Comput. Comput.-Assist. Intervention, 2015, pp. 234–
[25] Y. Hao, N. Wang, X. Gao, J. Li, and X. Wang, “Dual-alignment feature 241.
embedding for cross-modality person re-identification,” in Proc. ACM [49] F. Radenovic, G. Tolias, and O. Chum, “Fine-tuning CNN image
Int. Conf. Multim., 2019, pp. 57–65. retrieval with no human annotation,” IEEE Trans. Pattern Anal. Mach.
[26] Y. Lu, Y. Wu, B. Liu, T. Zhang, B. Li, Q. Chu, and N. Yu, “Cross- Intell., vol. 41, no. 7, pp. 1655–1668, 2019.
modality person re-identification with shared-specific feature transfer,” [50] M. Ye, X. Lan, J. Li, and P. C. Yuen, “Hierarchical discriminative
in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2020, pp. learning for visible thermal person re-identification,” in Proc. AAAI Conf.
13 376–13 386. Artif. Intell., 2018, pp. 7501–7508.
[27] M. Ye, X. Lan, Q. Leng, and J. Shen, “Cross-modality person re- [51] M. Ye, X. Lan, and Q. Leng, “Modality-aware collaborative learning
identification via modality-aware collaborative ensemble learning,” IEEE for visible thermal person re-identification,” in Proc. ACM Int. Conf.
Trans. Image Process., vol. 29, pp. 9387–9399, 2020. Multim., 2019, pp. 347–355.
[52] Y. Hao, N. Wang, J. Li, and X. Gao, “HSME: Hypersphere manifold
[28] M. Ye, J. Shen, D. J. Crandall, L. Shao, and J. Luo, “Dynamic
embedding for visible thermal person re-identification,” in Proc. AAAI
dual-attentive aggregation learning for visible-infrared person re-
Conf. Artif. Intell., 2019, pp. 8385–8392.
identification,” in Proc. Springer European Conf. Comput. Vis., 2020.
[53] M. Ye, X. Lan, Z. Wang, and P. C. Yuen, “Bi-directional center-
[29] A. Wu, W. Zheng, H. Yu, S. Gong, and J. Lai, “Rgb-infrared cross- constrained top-ranking for visible thermal person re-identification,”
modality person re-identification,” in Proc. IEEE/CVF Int. Conf. Com- IEEE Trans. Inf. Forensics Secur., vol. 15, pp. 407–419, 2020.
put. Vis., 2017, pp. 5390–5399. [54] Z. Feng, J. Lai, and X. Xie, “Learning modality-specific representa-
[30] V. V. Kniaz and A. N. Bordodymov, “Long wave infrared image col- tions for visible-infrared person re-identification,” IEEE Trans. Image
orization for personre-identification,” in Proc. Photogrammetric Com- Process., vol. 29, pp. 579–590, 2020.
put. Vis. Tech. for Video Surveillance, Biom. and Biomed. worksh., 2019, [55] H. Liu, J. Cheng, W. Wang, Y. Su, and H. Bai, “Enhancing the
pp. 111–116. discriminative feature learning for visible-thermal cross-modality person
[31] Z. Zhong, L. Zheng, Z. Zheng, S. Li, and Y. Yang, “Camera style adap- re-identification,” Neurocomputing, vol. 398, pp. 11–19, 2020.
tation for person re-identification,” in Proc. IEEE/CVF Conf. Comput. [56] D. Li, X. Wei, X. Hong, and Y. Gong, “Infrared-visible cross-modal
Vis. Pattern Recognit., 2018, pp. 5157–5166. person re-identification with an X modality,” in Proc. AAAI Conf. Artif.
[32] W. Deng, L. Zheng, Q. Ye, G. Kang, Y. Yang, and J. Jiao, “Image- Intell., 2020, pp. 4610–4617.
image domain adaptation with preserved self-similarity and domain- [57] A. Wu, W. Zheng, S. Gong, and J. Lai, “RGB-IR person re-identification
dissimilarity for person re-identification,” in Proc. IEEE/CVF Conf. by cross-modality similarity preservation,” Int. J. Comput. Vis., vol. 128,
Comput. Vis. Pattern Recognit., 2018, pp. 994–1003. no. 6, pp. 1765–1785, 2020.
[33] X. Li, A. Wu, and W. Zheng, “Adversarial open-world person re- [58] S. Choi, S. Lee, Y. Kim, T. Kim, and C. Kim, “Hi-CMD: Hierar-
identification,” in Proc. Springer European Conf. Comput. Vis., 2018, chical cross-modality disentanglement for visible-infrared person re-
pp. 287–303. identification,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit.,
[34] L. Wei, S. Zhang, W. Gao, and Q. Tian, “Person transfer GAN to 2020, pp. 10 254–10 263.
bridge domain gap for person re-identification,” in Proc. IEEE/CVF [59] X. Wei, D. Li, X. Hong, W. Ke, and Y. Gong, “Co-attentive lifting
Conf. Comput. Vis. Pattern Recognit., 2018, pp. 79–88. for infrared-visible person re-identification,” in Proc. ACM Int. Conf.
[35] R. Kiros, R. Salakhutdinov, and R. S. Zemel, “Unifying visual- Multim., 2020, pp. 1028–1037.
semantic embeddings with multimodal neural language models,” arXiv [60] R. Zhang, P. Isola, and A. A. Efros, “Colorful image colorization,” in
abs/1411.2539, 2014. Proc. Springer European Conf. Comput. Vis., 2016, pp. 649–666.
[36] F. Faghri, D. J. Fleet, J. R. Kiros, and S. Fidler, “VSE++: Improving [61] R. Zhang, J. Zhu, P. Isola, X. Geng, A. S. Lin, T. Yu, and A. A. Efros,
visual-semantic embeddings with hard negatives,” in Proc. BMVA British “Real-time user-guided image colorization with learned deep priors,”
Mach. Vis. Conf., 2018. ACM Trans. Graphics, vol. 36, no. 4, pp. 119:1–119:11, 2017.
[37] J. Gu, J. Cai, S. R. Joty, L. Niu, and G. Wang, “Look, imagine and match: [62] P. L. Suarez, A. D. Sappa, and B. X. Vintimilla, “Infrared image
Improving textual-visual cross-modal retrieval with generative models,” colorization based on a triplet DCGAN architecture,” in Proc. IEEE/CVF
in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2018, pp. Conf. Comput. Vis. Pattern Recognit. Worksh., 2017, pp. 212–217.
7181–7189. [63] P. Zhang, J. Xu, Q. Wu, Y. Huang, and J. Zhang, “Top-push constrained
[38] K. Lee, X. Chen, G. Hua, H. Hu, and X. He, “Stacked cross attention modality-adaptive dictionary learning for cross-modality person re-
for image-text matching,” in Proc. Springer European Conf. Comput. identification,” IEEE Trans. Circuits Syst. Video Technol., vol. 30, no. 12,
Vis., 2018, pp. 212–228. pp. 4554–4566, 2020.
[64] Y. Zhao, J. Lin, Q. Xuan, and X. Xi, “HPILN: A feature learning frame-
[39] Z. Niu, M. Zhou, L. Wang, X. Gao, and G. Hua, “Hierarchical multi-
work for cross-modality person re-identification,” IET Image Process.,
modal LSTM for dense visual-semantic embedding,” in Proc. IEEE/CVF
vol. 13, no. 14, pp. 2897–2904, 2019.
Int. Conf. Comput. Vis., 2017, pp. 1899–1907.
[65] E. Basaran, M. Gökmen, and M. E. Kamasak, “An efficient framework
[40] T. Welsh, M. Ashikhmin, and K. Mueller, “Transferring color to for visible-infrared cross modality person re-identification,” Signal Pro-
greyscale images,” ACM Trans. Graphics, vol. 21, no. 3, pp. 277–280, cess. Image Commun., vol. 87, p. 115933, 2020.
2002. [66] D. T. Nguyen, H. G. Hong, K. Kim, and K. R. Park, “Person recognition
[41] A. Levin, D. Lischinski, and Y. Weiss, “Colorization using optimization,” system based on a combination of body images from visible light and
ACM Trans. Graphics, vol. 23, no. 3, pp. 689–694, 2004. thermal cameras,” Sensors, vol. 17, no. 3, p. 605, 2017.
[42] K. Nazeri and E. Ng, “Image colorization with generative adversarial [67] L. Van Der Maaten and G. Hinton, “Visualizing data using t-sne,” J.
networks,” arXiv abs/1803.05400, 2018. Mach. Learn. Res., vol. 86, no. 9, pp. 2579–2605, 2008.
[43] J. Li, K. A. Skinner, R. M. Eustice, and M. Johnson-Roberson, “Wa-
terGAN: Unsupervised generative network to enable real-time color
correction of monocular underwater images,” IEEE Robotics Autom.
Lett., vol. 3, no. 1, pp. 387–394, 2018.
[44] C. Hsu, C. Lin, W. Su, and G. Cheung, “SiGAN: Siamese generative
adversarial network for identity-preserving face hallucination,” IEEE
Trans. Image Process., vol. 28, no. 12, pp. 6225–6236, 2019.
[45] K. Jiang, Z. Wang, P. Yi, G. Wang, T. Lu, and J. Jiang, “Edge-enhanced
GAN for remote sensing image superresolution,” IEEE Trans. Geosci.
Remote. Sens., vol. 57, no. 8, pp. 5799–5812, 2019.You can also read

















































