Optimisation of multiplet identifier processing on a PLAYSTATION 3
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
CSIRO PUBLISHING www.publish.csiro.au/journals/eg Copublished paper, please cite all three:
Exploration Geophysics, 2010, 41, 109–117; Butsuri-Tansa, 2010, 63, 109–117; Jigu-Mulli-wa-Mulli-Tamsa, 2010, 13, 109–117
Optimisation of multiplet identifier processing on a PLAYSTATION® 3*
Masami Hattori1,2 Takashi Mizuno1
1
Schlumberger K. K. 2-2-1 Fuchinobe Sagamihara, Kanagawa 229-0006, Japan.
2
Corresponding author. Email: mhattori@slb.com
Abstract. To enable high-performance computing (HPC) for applications with large datasets using a Sony®
PLAYSTATION® 3 (PS3) video game console, we configured a hybrid system consisting of a Windows® PC and a
PS3. To validate this system, we implemented the real-time multiplet identifier (RTMI) application, which identifies
multiplets of microearthquakes in terms of the similarity of their waveforms. The cross-correlation computation, which is a
core algorithm of the RTMI application, was optimised for the PS3 platform, while the rest of the computation, including
data input and output remained on the PC. With this configuration, the core part of the algorithm ran 69 times faster than the
original program, accelerating total computation speed more than five times. As a result, the system processed up to
2100 total microseismic events, whereas the original implementation had a limit of 400 events. These results indicate
that this system enables high-performance computing for large datasets using the PS3, as long as data transfer time is
negligible compared with computation time.
Key words: Cell, high-performance computing, microearthquake, microseismic, multiplet, PS3.
Introduction Cell architecture
The Cell Broadband Engine processor (Cell), used in the Sony ®
Cell architecture (Figure 2) includes one general-purpose
PLAYSTATION® 3 (PS3), is a general-purpose processor processor core, called the PowerPC Processor Element (PPE),
with high-computing performance. The theoretical peak and eight Synergistic Processor Elements (SPEs) that are
performance of Cell is over 200 GFLOPS, while that of a processing cores. The PPE is a PowerPC architecture–
3.0-GHz dual-core Pentium® processor is 25 GFLOPS. As an compliant 64-bit processor element. The Linux operating
example of actual performance, Kurzak et al. (2007) reported that system runs on the PPE and controls the eight SPEs. The SPE
Cell showed over 170 GFLOPS performance in a Cholesky is a vector processor having single instruction multiple data
Factorisation task. Williams et al. (2006) demonstrated the (SIMD) capability, processing four floating-point operations
tremendous potential of Cell for scientific computation. In the with one instruction, on all 128 general-purpose registers.
oil industry, IBM® (2008) successfully implemented reverse With two asymmetrical pipelines, the SPE can issue two
time migration on Cell technology, while Hattori and Mizuno instructions at the same time. The SPE cannot directly access
(2007) enabled real-time services by optimising wavefield the main memory. Both program and data must be transferred by
separation on the PS3. direct memory access to a 256-KB local store (LS) in SPE. Neither
Although the high performance of Cell is well known, few the PPE nor the SPE has out-of-order execution or branch
instances have been reported in which the PS3 was used for prediction mechanisms.
high-performance computing (HPC). One of the main reasons is Given these processor characteristics, one can use the key
that the PS3 has only 256 MB of memory, and performance techniques listed in Table 1 to optimise a program on the Cell.
drastically degrades when page swapping occurs. When optimising on the PS3, one must remember that
To best use the PS3 for HPC for application programs that application programs can use only six of the eight SPEs.
require large memory, we configured a hybrid computation
system, shown in Figure 1. On this hybrid system, the
application runs on the Windows PC while delegating
processor-intensive computations to the PS3, which is Multiplet identification
connected through Ethernet. Reservoir seismicity sometimes exhibits swarm-like activity, in
Using this hybrid system, one could optimise various which waveforms of different events show mutual similarity.
geophysical algorithms that require a huge amount of data to Among a group of events, a doublet represents a pair of similar
reside in memory. Such algorithms could include signal events while a multiplet represents a group of at least three events.
processing, forward modelling, and inversion. To validate the It is thought that these events occur close to one another and have a
hybrid system, we chose to implement the real-time multiplet similar source mechanism. One could describe each group as a
identifier (RTMI) application from among a few candidate master (parent) event and slave (child) events. A master event has
applications, because we were facing performance issues with the representative waveform signature for the corresponding
the RTMI implemented on Windows® platforms. event group (family).
*Part of this paper was presented at the 9th SEGJ International Symposium (2009).
ASEG/SEGJ/KSEG 2010 10.1071/EG09050 0812-3985/10/010109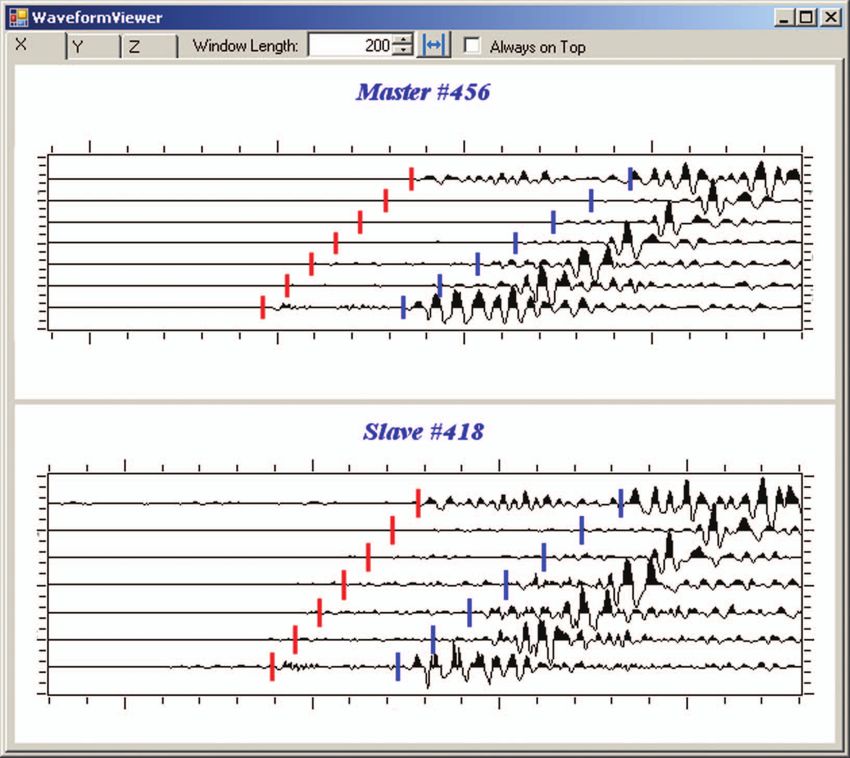
110 Exploration Geophysics M. Hattori and T. Mizuno
(a)
New Event
Cross LAN cable
Private network All Master Events
Multiplets Identify Doublet
Fig. 1. Hybrid high-performance computing system consisting of a
Windows PC and a PLAYSTATION (PS3) connected by Ethernet.
The main program runs on a personal computer (PC), and data is sent to Identify Multiplet
the PS3 to execute intensive computations there. The computation result is
sent back to the PC.
(b)
New Event
All Master Events For each Master Event:
Multiplets
Calculate Trace CCFs
Calculate Receiver CCFs
Calculate Event CCF
Calculate Event CC
Event CCs
Fig. 3 (a) High level processing flow chart for multiplet identification (MI).
For each incoming event, we perform doublet identification (DI) first, then
perform MI. DI is made in terms of the waveform similarity between two
Fig. 2. Cell processor architecture having one PowerPC Processor Element events. (b) Detail of Event CCs calculation in DI. DI is made between each
(PPE) and eight Synergistic Processor Elements (SPEs) connected by a high- master event with the new incoming event. First, we compute cross-
speed bus. correlation functions (CCF) between traces of the events for each
component. These functions are used to compute event CCF, and we take
Table 1. Key optimisation techniques for Cell. the maximum value as Event CC.
1 Run expensive computation on Synergistic Processor Elements (SPEs)
leaving PowerPC Processor Element for controlling SPEs
2) To estimate correlations at the receiver level, or receiver CCF
2 Maximise usage of single instruction multiple data instructions Cij(t), use the following equation:
3 Use as many registers as possible, which could be helped by loop 1 X
unrolling Cij ðtÞ ¼ P Aijk Cijk ðtÞ; ð1Þ
4 Order instructions so that both of the pipelines are filled (dual-issue) k Aijk k
5 Hide direct memory access memory transfer latency with double where Aijk is a weighting function computed from the
buffering
maximum amplitude of the k-th component at the j-th
6 Avoid conditional branches as much as possible
receiver for the i-th event and the new event.
3) Then estimate the event CCF Ci(t), which represents the
Arrowsmith and Eisner (2006) introduced the concept of real- cross-correlation function between events, by using Cij(t)
time processing for multiplet identification. Figure 3a shows a as follows:
high level view of RTMI processing, which involves algorithms
1 X
for doublet and multiplet identification. The process identifies a Ci ðtÞ ¼ P Wij Cij ðtÞ; ð2Þ
doublet in terms of the mutual similarity between waveforms of a W j ij j
new incoming event and master events. Then it updates the
where
multiplets using doublet information. X
Doublet identification is the core of the algorithm. RTMI Wij ¼ Aijk : ð3Þ
spends most of its computational effort on this algorithm. k
Arrowsmith and Eisner (2006) proposed an algorithm that 4) Finally, we get the Event CC from
estimates the similarity of the events using a three-component
and multi-receiver configuration. Our algorithm uses this measure Ci ¼ maxfCi ðtÞg: ð4Þ
for doublet identification. We call this measure Event CC, and
Figure 4 shows how Event CC (Ci) is computed. The algorithm
compute it using the following steps (Figure 3b).
computes Event CC for all pairs between master events and the
1) For each combination of the i-th master and a new incoming new incoming event. Ci represents the probability of a doublet
event, the trace cross-correlation function (trace CCF) for relation between the new event and the i-th event.
the k-th component at the j-th receiver, Cijk(t) is estimated. Arrowsmith and Eisner (2006) define a multiplet as a cluster of
t is the time lag. n events (n 2) in which each event is a doublet with at least one
Multiplet identification using a PS3 Exploration Geophysics 111
Fig. 4. How to calculate Event CC from three-component multi-receiver data (N is number of receivers). Cross-correlation
functions (CCF) are weighted averaged.
other event in the multiplet. They identified multiplets by using the program using a test dataset that simulated a hydraulic fracture
graph theory. However, we use simper logic, as follows: monitoring job with a standard survey configuration of eight
receivers and an event rate of one every 3 s. The study showed that
1) Obtain Ci from doublet identification.
the RTMI processing began running slower as the number of
2) Choose the i-th event that represents the maximum Event
events grew. When 400 events were detected, the processing time
CC. Then check to see if it exceeds the doublet threshold. If it
for a new event took longer than the event rate.
does, this event pair is a doublet.
3) If the signal-to-noise ratio (S/N) of the new incoming event
Programming environment on PS3
is greater than the corresponding master event, then the new
event replaces the master event of the multiplet which Several Linux distributions such as Red Hat, Fedora, and Yellow
includes the corresponding master event. If not, the new Dog support the PS3. Using the software development kit for
incoming event becomes a slave event of the master event. Cell (Cell SDK) distributed by IBM, one can develop programs
4) If the Event CC does not exceed this threshold, then the running on the PS3 in the C or C++ language. Linux programs
incoming event becomes the new master event for a new written in C or C++ would run on PPE simply by recompiling.
multiplet. However, to optimise a program on the PS3, one must consider
offloading time-consuming computations to the SPEs. The Cell
Figure 5a shows the result of RTMI with a real microseismic SDK provides a C/C++ compiler that allows embedding SPU
dataset from a hydraulic fracturing experiment. Seven three- specific instructions in the code as SPU Intrinsic, to build SPE
component receivers installed in the horizontal part of the executables. Using the SPE management library contained in the
borehole recorded the waveforms. Before applying multiplet Cell SDK, PPE programs can manage the SPE executables in a
identification, a 3D continuous microseismic mapping (CMM) similar way to threads. We installed the Fedora 7 operating system
algorithm (Michaud and Leaney, 2008) detected and located and the Cell SDK 3.0 on a PS3, in order to optimise RTMI for
events. The CMM is a global search algorithm having model- the hybrid system.
based phase picks. The colour map at the centre of Figure 5a
shows the Event CC for each of the event pairs. Since Event CC is Optimising CCF computation on PS3
measured between the master event and new incoming event,
Event CC is not measured for all event pairs. At left, Figure 5a To implement the RTMI program on the hybrid system, we
shows the event ID (identification) of the master event, and the profiled the original RTMI program and found that the
slave event belongs to the corresponding master event. Figure 5b ‘Calculate Trace CCFs’ block shown in Figure 3b took ~80%
compares waveforms between event pairs that comprise a of total computation time. Thus we implemented this part of the
master and slave relation, showing that the RTMI algorithm program on the PS3, and made it callable from the RTMI host
derived a reasonable result. program, as shown in Figure 6. The PS3 receives the traces of
RTMI indicates out-of-zone fracture growth because one can the new event and all master events, calculates the CCF for all
observe multiplets when this occurs (Eisner et al., 2006). In traces, and returns them to the host program for Event CC
addition, by using multiplet relocation techniques such as the calculation.
double-difference method (Waldhauser and Ellsworth, 2000), The original code computed the trace CCF in the frequency
one can infer a better image of a fracture network than by using domain. To accelerate the trace CCF computation on the PS3,
conventional event-by-event location processing. we evaluated the FFTW (‘Fastest Fourier Transform in the West’)
library, which was optimised for the Cell processor using all
available SPEs. Calculation of the CCF between traces having
Optimisation of multiplet identification 200 samples was 33 times faster than the original code running on
on the hybrid system the reference Windows® PC (Intel Xeon 5150 2.66 GHz).
However, little room remained for further optimization. Next,
Original implementation we tried to compute the trace CCF in the time domain. Although
We implemented the first version of the RTMI program on the performance of a trace CCF calculation on one SPE was about two
Windows® PC platform. Then we conducted a feasibility study of times slower than performance in the frequency domain with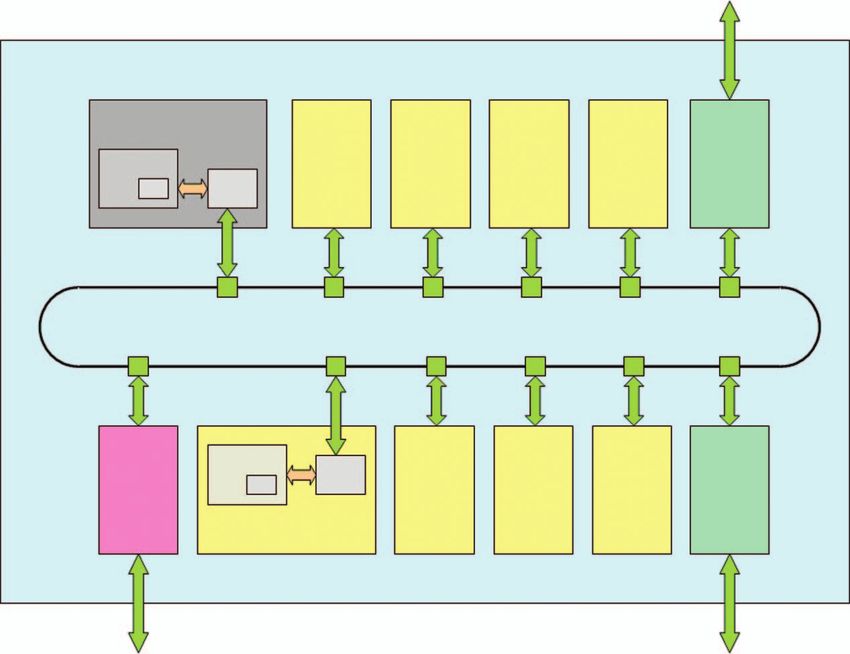
112 Exploration Geophysics M. Hattori and T. Mizuno
(a)
Correlation Coefficients Matrix
Number of events 589
384 400 420 440 460 480
361 1
380 0.8
400 0.6
420 0.4
(456, 418)[0.77550]
440 0.2
460
0
(b)
150 200 250 300
0 0
T2 2T
r r
a4 4a
c c
e6 6e
# #
8 8
150 200 250 300
Time (ms)
150 200 250 300
0 0
T2 2
T
r r
a4 4a
c c
e e
#6 6#
8 8
150 200 250 300
Time (ms)
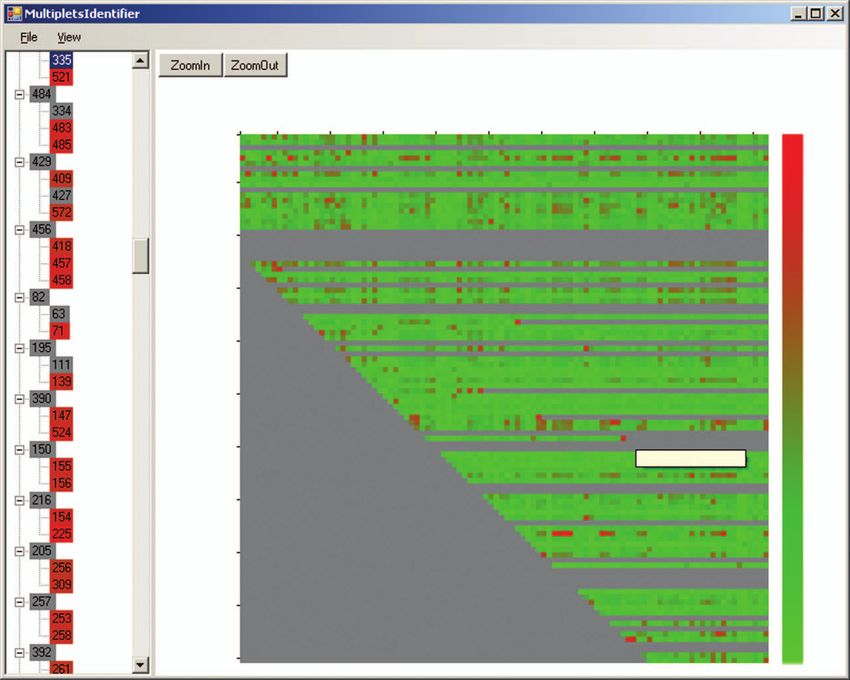
Fig. 5. (a) Multiplet identification viewer showing event families (left) and correlation coefficients matrix
(right). Each event family comprises a master event that is identified with a set of slave (child) events. The
colour of each matrix grid corresponds to the Event CC estimated in DI. (b) Comparison of X component traces
from a master and a slave event with P (red) and S (blue) arrivals (Ci = 0.77).
FFTW, we decided to compute the trace CCF in the time domain As the CCFs are calculated with the traces recorded by a three-
because we could parallelise the multiple trace CCF computation component multi-receiver network, the total number of necessary
with SPEs and SIMD. CCF calculations for doublet identification becomes 3 N M,
Multiplet identification using a PS3 Exploration Geophysics 113
Reducing data transfer by restructuring program
New Event
We measured the performance of the hybrid system, which
delegates the trace CCF computation to the PS3. Figure 9
compares the performance of the original program on
All Master Events For each Master Event:
Multiplets Windows® with performance on the hybrid system. The Trace
Calculate Trace CCFs CCFs Computation of the hybrid system indicates the elapsed
time for trace CCF computation measured on the Windows®
PS3
host. Although the trace CCF computation on the PS3 showed
a performance improvement of 69 times, only a 9 times
Trace CCFs improvement was measured on the Windows® host. Thus,
overall performance improvement was 3.4 times. This occurred
For each Master Event:
because the overhead created by sending and receiving data was
~4 times as large as the trace CCF computation, shown in Figure 10,
Calculate Receiver CCFs
Calculate Event CCF
measured on the PS3.
Calculate Event CC To reduce data transfer to and from the PS3, we restructured
the program, as shown in Figure 11. Keeping master events in the
PS3 reduced data input to the PS3, and delegating the Event
Event CCs CC calculation, which is done on PPE, reduced data output.
Figure 12 shows the performance improvement for RTMI
Fig. 6. Block diagram of Event CCs computation, delegating trace cross- processing using the new hybrid system. The orange bars
correlation functions (CCF) computation to PLAYSTATION® 3. show the elapsed time the RTMI required to process the 100th
event with a test dataset (eight receivers, 0.5-ms sampling rate).
The top one illustrates the original RTMI running on the reference
where N is the number of receivers and M is the number of master Windows® PC, and the bottom one represents the hybrid system.
events that have been identified. To parallelise trace CCF Comparison of the two orange bars indicates that the hybrid
calculations with the six available SPEs (Technique 1), master system improved overall RTMI performance 5.3 times. The
events are divided into two groups (1~M/2 and M/2+1~M) so that yellow bars show the elapsed time of the cross-correlation
two SPEs can perform the CCF calculation for one component. computation. The top represents performance in the original
For example, Figure 7 shows that SPE #1 and SPE #2 computed Windows version, and the bottom represents performance in
the trace CCFs for the X component traces. the host RTMI program of the hybrid system, including data
With SIMD, a single instruction performs four arithmetic transfer time. Comparison of the two yellow bars indicates that the
operations as shown in Figure 8. Each SPE computes the trace Event CC computation in the hybrid system is 36 times faster than
CCF for four receivers at the same time by using the SIMD the Windows® version, even with the data transfer overhead.
instructions (Technique 2). Thus, one can parallelise 24 trace CCF
computation tasks. Appendix 1 shows what the SIMD code looks Discussion
like compared to the scalar code. The trace CCF computation To validate the hybrid system, we also ported the whole RTMI
optimised on the PS3 runs 69 times faster than the original program to the PS3 while making the same optimisation on the
Windows code. trace CCF calculation as the hybrid system. Due to the PS3’s
Fig. 7. Parallelisation of trace cross-correlation functions (CCF) computation with Synergistic Processor Elements (SPEs).
Master events are divided into two groups and two SPEs compute trace CCFs for one component.114 Exploration Geophysics M. Hattori and T. Mizuno
Multiplets New Event
New Master Event
Master Events For each Master Event:
Calculate Trace CCFs
Calculate Receiver CCFs
Calculate Event CCF
Calculate Event CC
PS3
Fig. 8. Scalar operation (left) and single instruction multiple data
instructions (SIMD) operation (right). Four times loop can be a single Event CCs
SIMD instruction.
Fig. 11. Restructured Event CCs calculation to reduce data transfer.
Master events are kept in PLAYSTATION3 (PS3) and Event CCs are
calculated in PS3.
RTMI Program 663
Original
RTMI
Trace CCFs Computation 531
RTMI Program 663
Original
RTMI
Event CCs Computation 548
197
Hybrid
System
59
New 125
Hybrid
0 100 200 300 400 500 600 700 System 15
Time (ms)
Fig. 9. Performance comparison between original real-time multiplet 0 100 200 300 400 500 600 700
identifier (RTMI) (top) and the hybrid system. Trace cross-correlation Time (ms)
functions (CCF) computation becomes nine times faster than the original
implementation. Fig. 12. Performance improvement of real-time multiplet identifier (RTMI)
using the new hybrid system. Core computation becomes 36 times faster than
the original implementation, and overall performance was improved 5.3 times.
transfer overhead to just 10% of the event CC calculation. This
14.0 Receive turned out to be the key to success with the hybrid system.
A benchmark on the test dataset proved that the hybrid RTMI
3.7 Reverse Endian system is capable of processing up to 2100 events in real time
when the event rate is as high as one event every 3 s. However,
7.9 Compute Trace CCF
keeping the master events data revealed another limitation. The
20.0 Send
PS3 can hold only 5000 master events in its main memory when
using standard processing parameters.
2.3 Others Regarding future work, Cell optimization techniques 3 to 6
in Table 1 could further improve the trace CCF calculation. In
addition, one could easily extend the RTMI system using multiple
0 5 10 15 20 25 PS3s, which would improve performance and help overcome
Time (ms) the current limit imposed by the maximum number of master
events held in memory.
Fig. 10. Elapsed time of functions in trace cross-correlation functions (CCF) Using this hybrid system, one could optimise various
computation on PS3, which indicates overhead due to data transfer (send,
geophysical algorithms that require a huge amount of data to
receive, and reverse endian).
reside in memory, as long as data parallelisation can be applied,
and data transfer time is negligible compared to computation
time. In geophysical signal processing algorithms, multi-channel
limited memory, however, the program could not process more filtering, correlation, and deconvolution could be accelerated by
than 500 events. Therefore, we compared the performance at the hybrid system. In forward modelling algorithms, finite
processing the 100th event. In this case, the hybrid system was difference is one of the algorithms that can benefit from this
16% faster than the RTMI program running on the PS3. This system. With the ability to handle huge matrices, finite element
fact indicates that the data transfer overhead is smaller than the algorithms and large-scale linear inversion could be optimised on
performance gain on the Windows® PC to run the rest of the this system as well. In addition, global search is another algorithm
RTMI program. By restructuring the program, we reduced data that could be accelerated using this system.
Multiplet identification using a PS3 Exploration Geophysics 115
Conclusion Hattori, M., and Mizuno, T., 2007, Real-time seismic data processing on
PLAYSTATION® 3: Proceedings of the SEGJ Conference, 117, 92–94.
We implemented the RTMI program on a hybrid system that IBM. Spain-Based Repsol, Barcelona Supercomputing Centre Use IBM
consisted of a host Windows® PC and a PS3 as the computation Technology to Tap Into New Frontiers of Oil Exploration. Press
engine. We delegated the computationally expensive CCF release. Available online at: http://www-03.ibm.com/press/us/en/
computation to the PS3 and optimised it there using various pressrelease/24556.wss [verified January 2010].
techniques. Overall performance of the RTMI program on the Kurzak, J., Buttari, A., and Dongarra, J., 2007, Solving Systems of Linear
hybrid system was more than five times greater than performance Equations on the CELL Processor Using Cholesky Factorization –
of the RTMI program on the Windows® system. Even when we LAPACK Working Note 184, Technical Report UT-CS-07–596:
ported the whole RTMI program to the PS3, implementing Department of Computer Science, University of Tennessee.
the RTMI on the hybrid system showed better performance Michaud, G, and Leaney, S., 2008, Continuous microseismic mapping for
real-time event detection and location: SEG Expanded Abstracts, 27,
because the data transfer overhead is relatively small.
1357–1361.
These results indicate that one could use this hybrid system to Waldhauser, F. M., and Ellsworth, W. L., 2000, A double-difference
optimise other algorithms, as long as the data transfer requirement earthquake location algorithm: Method and application to the northern
remains reasonably small. Hayward fault, California: Bulletin of the Seismological Society of
America, 90, 1353–1368. doi:10.1785/0120000006
Acknowledgments Williams, S., Shalf, J., Oliker, L., Kamil, S., Husbands, P., and Yelick, K.,
We are grateful to Continental Resources Inc. for permission to use their data 2006, The Potential of the Cell Processor for Scientific Computing:
for our study and to publish these results. We thank Junichi Matsuda and Available online at: http://bebop.cs.berkeley.edu/pubs/williams2006-
Akinobu Mita of Fixstars Corporation for their kind assistance with the cell-scicomp.pdf [verified January 2010].
optimisation of the RTMI on the hybrid system. Thanks also to our
colleague Philip Armstrong for useful discussion.
References
Arrowsmith, S. J., and Eisner, L., 2006, A technique for identifying
microseismic multiplets and application to the Valhall Field, North
Sea: Geophysics, 71, V31. doi:10.1190/1.2187804
Eisner, L., Fischer, T., and Le Calvez, J. H., 2006, Detection of repeated
hydraulic fracturing (out-of-zone growth) by microseismic monitoring:
The Leading Edge, 25, 548–554. doi:10.1190/1.2202655 Manuscript received 19 September 2009; accepted 4 December 2009.116 Exploration Geophysics M. Hattori and T. Mizuno
Appendix 1: Scalar code to compute one CCF (left) and SIMD code to compute four CCFs (right).
/* /*
* Scalar code to compute cross correlation function * SIMD version of ComputeCCF()
*/ */
void ComputeCCF( void ComputeCCFVector(
float *Y_m, // in vector float *Y_m, // in
int NY, // in int NY, // in
int Nmin, // in int Nmin, // in
int Nmax, // in int Nmax, // in
float *X_m, // in vector float *X_m, // in
int NX, // in int NX, // in
float *CCF // out vector float *CCF, // out
) )
{ {
/* /*
* -Nmin < nÔ
Multiplet identification using a PS3 Exploration Geophysics 117
2NC[5VCVKQPo ࠍ↪ߚࡑ࡞࠴ࡊ࠶࠻ಣℂߩᦨㆡൻ
ㇱᱜ⟤1᳓㊁㜞ᔒ1
1 ࠪࡘ࡞ࡦࡌ࡞ࠫࠚ㧔ᩣ㧕
ⷐ ᣦ㧦 Ṷ▚⢻ജߪ㜞߇ࡔࡕߩዋߥ SONY® PlayStation®3 ࠍ↪ߡᄢ㊂ߩ࠺࠲ߦኻߒ㜞ᕈ⢻ᛛⴚ⸘▚ࠍߔࠆߚ
ޔWindows PC ߣߩࡂࠗࡉ࠶࠼ࠪࠬ࠹ࡓࠍឭ᩺ߒߚߩߘޕᬌ⸽ߩߚ⸥ޔ㍳ᵄᒻߩ⋧㑐߆ࠄᓸዊ㔡ࡑ࡞࠴ࡊ࠶࠻ࠍ
ࠕ࡞࠲ࠗࡓߢߔࠆࡊࡠࠣࡓ㧔RTMI㧕ࠍ⒖ᬀߒߚޕCPU ࠦࠬ࠻ߩᦨ߽㜞⋧㑐㑐ᢙߩ⸘▚ࠍ PS3 ߢⴕ ࠲࠺ޔI/O ߥ
ߤߘߩઁߩㇱಽߪ PC ߦᱷߒߚߣߎࠈ⋧ޔ㑐㑐ᢙߩ⸘▚ߪ 50 એㅦߊߥࠅޔRTMI ోߢ߽ 7 ߩㅦᐲะ߇ࠄࠇߚޕ
ߘߩ⚿ᨐޔWindows PC ߢߪ 300 ⒟ᐲߩ㔡߹ߢߒ߆ࠕ࡞࠲ࠗࡓߢ߈ߥ߆ߞߚ߽ߩ߇ޔ2100 ߹ߢಣℂน⢻ߣߥߞ
ߚޔߪߩߎޕPC ߣ PS3 㑆ߩ࠺࠲ォㅍᤨ㑆߇⸘▚ᤨ㑆ߦᲧߴలಽዊߐ႐วߦߪࠍࡓ࠹ࠬࠪ࠼࠶ࡉࠗࡂޔᄢ㊂ߩ࠺࠲
ࠍᛒ߁㜞ᕈ⢻ᛛⴚ⸘▚ࡊࡠࠣࡓߦᵴ↪ߢ߈ࠆߎߣࠍ␜ߒߡ߅ࠅޔห᭽ߩࠕࠠ࠹ࠢ࠴ࡖߪࡔࡕߩ㒢ࠄࠇߚઁߩࠕࠢ
࠲ߥߤߦ߽ᔕ↪น⢻ߢࠆޕ
ࠠࡢ࠼㧦ᓸዊ㔡ࡑ࡞࠴ࡊ࠶࠻࡞ࠦࡦࡇࡘ࠹ࠖࡦࠣ2NC[5VCVQPo㜞ᕈ⢻ᛛⴚ⸘▚
稒崎決枪癒決晞 ͤ 旇櫖昢͑ 朞窏夞垚͑ 彆矶稒崡͑ 柣懊沖汞͑ 牢洇筚͑
Masami Hattori 1, Takashi Mizuno1
1 㓦⩒⻚㪎G rUGrUG
殚͑ 檃G ☦ᝢ 㦦ᲢⰎ✾㗦Ⰾ◲3 (PS3) ⋞⪾ ᄦⰞ ㏲☮⯞ Ⰾ⭃㧲⪆ រ⭃ᱣⰪᵦ⩪ ᅺ○ ᅞ╊⯞ ⲛ⭃❶㔾ዊ ⮞㧲⪆
ႶⰒ⭃㎎㦂㗊 (PC)⯲ ⮢ᡞ⭊ ❶✾㗶ᆖ PS3ᳶ ሆ○ᢶ 㧲Ⰾ⊦Ṇ ❶✾㗶⯞ ⲶⰫ㧲⪚. Ⰾ ❶✾㗶⯲ ○⯞ ᄚ⸷㧲ዊ
⮞㨎 㞦㪯ὂ⨫⯲ ⮺╆ᡞḖ Ⰾ⭃㧲⪆ ₒ◒⹚⯲ Ớ㞊㦦Ჵ⯞ ⧦⧞ᕎᜮ ❾❶႞ Ớ㞊㦦Ჵ ❷⅞Ⱚ (RTMI)Ḗ ⚲㨣㧲⪆⧲.
RTMI⯲ 㨏➆ ⧦ᅺṆ⸲Ⱂ ╛㫒╛ᆚ ᅞ╊⯚ PS3 㦦᱅㢖⩪ ㇶⲛ㫮 ᢲ⩢ᅺ Ⱚᵦ⯲ Ⱏ㈶Ჿ⯞ 㢆㨂㧲ᜮ Ḓ ᅞ╊⯚
PC╛⩪▶ ⚲㨣ᢲ⩢. Ⰾ ᅗ⭊⩪ ⧦ᅺṆ⸲⯲ 㨏➆ √∞Ⰾ ⭪ᰲ⯲ ᅗ⭊ 50 Ⰾ╛ ⌂Ṇ ⚲㨣ᢲ⩎ ᅊᆖⲛ⯖ᳶ Ⴖ₶ᢶ
❶✾㗶⯚ ᆖᄊ 400Ⴖ⯲ ❺㫒₰⩪ ㄲṆ㧲⹚ ὕ㧲៲ ᄝ⯞ ㆷ 2100Ⴖዦ⹚⯲ ₒ☦ᡳ ❺㫒⯞ ㄲṆ 㧺 ⚲ Ⱒᄦ 㧲⪚. Ⰾ
ᅊᆖᜮ ⰪᵦⲞ☻❶႞Ⰾ ᅞ╊❶႞⩪ ⋞㨎 ῎❶㧺 ⚲ Ⱒᜮ 㧶 PS3Ḗ Ⰾ⭃㧶 រ⭃ᱣ Ⱚᵦ⯲ ᅺ○ ᅞ╊Ⰾ ႚ㧲ᜮ
ᄝ⯞ ⰲ ⪆ⶖᅺ Ⱒ.
渂殚檺㎖SG ἶ㎇⓻G Ἒ㌆SG ⹎㏢㰖㰚SG ⹎㏢㰚☯SG Ⲗ䕆䝢⩱SGwzZ´G
http://www.publish.csiro.au/journals/egYou can also read

















































