US-ATLAS Collaboration with Google for High Energy Physics Applications in the HL-LHC Era - CERN Indico
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

US-ATLAS Collaboration with Google for High Energy Physics Applications in the HL-LHC Era J. Elmsheuser, A. Klimentov, T. Wenaus P. Calafiura Brookhaven National Laboratory Lawrence Berkeley National Laboratory D. Malon, P. Van Gemmeren A. Hanushevsky Argonne National Laboratory Stanford Linear Accelerator Laboratory R. Gardner F. Barreiro, K. De University Chicago University Texas at Arlington K. Bhatia, K. Kissel J. Wells Google Oak Ridge National Laboratory *Draft white paper submitted to DOE on October 19, 2018 *version 1.0 on February 06, 2019 *version 2.0 on February 14, 2019 *version 3.0 on March 19, 2019

1. Introduction 3
1.1 Recent Accomplishments 4
2. Research Goals and Impact 5
2.1 Track 1: Data management across hot/cold storage 5
2.2 Track 2: Machine learning and quantum computing 8
2.2.1 Machine Learning ATLAS priorities 9
2.2.1.1 Pattern recognition for tracking 10
2.2.1.2 GAN for fast detector simulation 11
2.2.2 ATLAS Quantum Computing Investigations 12
2.3 Track 3: Optimized I/O and data formats for object storage 13
2.3.1 ROOT File Mechanics 14
2.3.4 Possible ROOT I/O Approaches in Google Cloud 15
2.3.4.1 Caching with Object Storage 15
2.3.4.2 Event Streaming and Data Flow 15
2.3.5 Economics 16
2.4 Track 4: End-user analysis conducted worldwide at PB scale. 16
2.5 Track 5: US WLCG sites elastic extension via commercial facilities 16
3. Project Team, Management and Organization 17
3.1 Project Management 17
3.2 Deliverables 18
3.2.1 Phase I (2019-2022): 18
4. Project Resource Allocation 19
5. References 20
6. Acknowledgements 21
1. Introduction
The high luminosity LHC (HL-LHC) run will begin operations in the year 2026 with expected
data volumes to increase by at least an order of magnitude as compared with present systems (see
Figure 1). Extrapolating from existing trends in disk and compute pricing, and assuming fixed
infrastructure budgets, the implications for end-user analysis of the data are significant. The risk
is that the current system architecture and tools will not be able provide the abstractions and data
management capabilities to scale to meet the expected growth, thereby hampering the scientific
advances produced by worldwide physics community.
Figure 1: Expected growth of both data and compute as HL-LHC begins operation: over 10x for
both raw and derived data, and 60x for compute systems as compared with resources used in
2016. 1
This challenge cannot be solved by simply extending the current LHC computing model. New
state-of-art technologies need to be applied and potentially developed, leveraging the
investments and research already being conducted in the commercial sector. Google has since
its inception been at the forefront of large-scale data management and processing, creating the
original map-reduce systems that led to the development of the Big Data industry. More
recently, Google has designed and built custom processors to accelerate machine learning,
developed a commercial quantum computing system, and provides access to these and other
advances through a public cloud infrastructure. We believe that working with researchers and
1
ATLAS computing model evolution,
https://indico.cern.ch/event/672240/contributions/2749960/attachments/1538486/2411477/ATLAS_Googel_CM_Oc
t2017.pdf
engineers at Google to adapt and apply these advanced techniques can address some of the
challenges posed by HL-LHC operational requirements.
Specifically, we have identified five key technical challenges that we believe need to be explored
for the HL-LHC, which can benefit from US ATLAS-Google partnership:
1. Advanced data management across hot/warm/cold data sources;
2. integration of machine learning and quantum computing for particle track reconstruction,
filtering and data handling;
3. HEP data formats and I/O optimizations for object storage systems;
4. scaling end-user analysis across systems globally over heterogeneous computing
infrastructure (WLCG grid sites, commercial cloud resources, HPCs);
5. supporting local elasticity and autonomy of resources at WLCG sites.
This is a R&D proposal which covers an important subset of many other R&D activities US
ATLAS is planning to conduct for the HL-LHC. We will coordinate with but do not imply to
subsume other collaborations that US ATLAS Labs and Universities are participating in with
Google (in particular ESnet and other DOE ASCR projects). Coherency will be reached via
common weekly meetings with project PIs and US ATLAS S&C management, and through open
technical meetings (usually 2-3 times per year). The total effort US ATLAS will dedicate to
HL-LHC challenges in the near term is expected to be about 15 FTEs (9 FTE within US ATLAS
Ops program and 8 FTE supported by NSF, labs, and Universities). The five topics have been
chosen to leverage technical knowledge from Google and the expertise of our authors -- who
have leading positions at five National Labs -- and other collaborators.
1.1 Recent Accomplishments
ATLAS initiated a collaboration with Google in 2017 focused on a “Data Ocean” project2 in
order to demonstrate how storage and compute resources from Google could be seamlessly
integrated with the ATLAS distributed computing environment. Led by K.De (UTA) and
A.Klimentov (BNL), a proof-of-concept (PoC) project was initiated with the following goals:
a. to allow ATLAS to explore the use of different computing models to prepare for
High-Luminosity LHC,
b. to allow ATLAS user analysis to benefit from Google Cloud Platform, and
c. to provide Google with demanding scientific use-cases in order to evaluate and improve
their current and future R&D efforts and product offerings.
2
ATLAS & Google — "Data Ocean" R&D Project, ATLAS note ATL-SOFT-PUB-2017-002
https://cds.cern.ch/record/2299146/, 29 Dec 2017
The major accomplishments of the project have been presented at several conferences, including
Google Cloud Next3 and Computing in High Energy Physics4 conferences. The PoC phase has
demonstrated the successful integration of distributed data management and workflow
management software developed in HEP (ATLAS PanDA and Rucio packages) with Google
computing infrastructure (Google Cloud Storage and Google Compute Engine). The integration
with GCS transparently adds GCS to the set of supported backend storage systems and enable its
use in orchestrating data activity with secure authentication and authorization. Google Compute
Engine (GCE) was also integrated with the ATLAS Production and Distributed Analysis System
(PanDA). The heterogeneous computing infrastructure was successfully used for ATLAS
Monte-Carlo production and lepton isolation end-user physics analysis. The five topics proposed
in this white paper builds on the successful conclusion of the PoC.
2. Research Goals and Impact
The overall goal for this proposal is to develop and integrate new state-of-the-art technologies
that will enable end-user physicists to easily and rapidly access and process HL-LHC data even
as the data volumes threaten to overwhelm them. The design principles we are operating under
include:
● Leverage “smart” tools where possible that obviate the need for the management of
tedious and complex tasks by the end user,
● Favor autonomy over centralization to enable the exploration of new methods and
analysis by the distributed user community.
Consistent with the goals above, we describe five tracks of potential collaboration below. These
tracks are matched to the five technical challenges identified earlier. These tracks may not end up
being the areas that we continue to work in 1-2 years - we may find other related areas to have
the highest impact for HL-LHC. We consider these tracks as starting points for R&D
explorations. We expect to narrow the tracks down to a couple of areas for intensive research
after initial explorations, based on available effort, expertise, common interest and the best fit to
HL-LHC challenges. However, since we are pushing the boundaries of technology and not just
evaluating existing technologies, we plan to remain open to all topics in our early explorations.
3
M. Lassnig, M. Rocklin, K. Bhatia, “Scientific Computing with Google Cloud Platform: Experiences from the
Trenches in Particle Physics and Earth Sciences”, July 2018
https://cloud.withgoogle.com/next18/sf/sessions/session/156666
4
M. Lassnig, “The ATLAS & Google "Data Ocean" Project for the HL-LHC era”, July 2018,
https://indico.cern.ch/event/587955/contributions/2947395/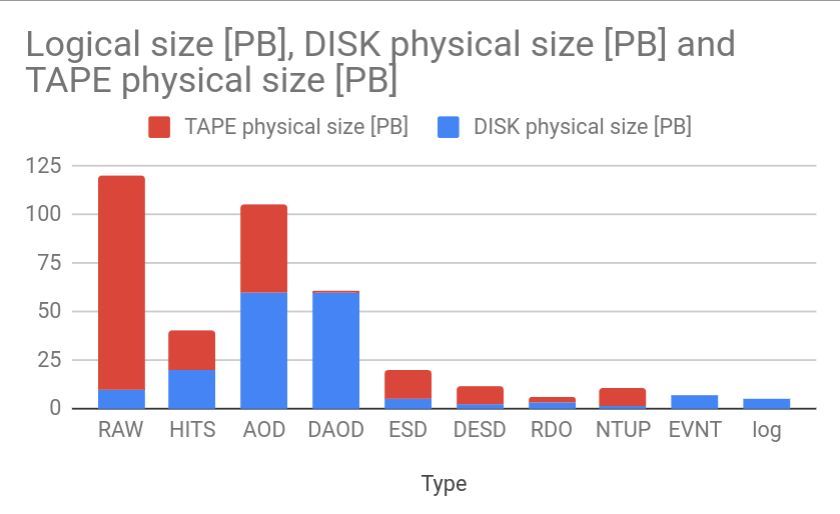
2.1 Track 1: Data management across hot/cold storage
HEP needs to manage its datasets across a variety of mediums based on the types of data and its
uses: from tape (or other cold storage technologies) to disk (spinning and ssd), to caches
(including world wide accessed data in clouds and “data lakes”) to content delivery networks.
Figure 2: (left, 2a) shows the different types of data products, from raw (both physical and
simulated) through Analysis Object Data (AOD) and Derived AOD (DAOD), along with (right,
2b) total data volumes across the WLCG sites.
At present the ATLAS experiment at CERN is storing detector and simulation data in different
data types (raw and derived) across more than 150 Grid sites world-wide. Figure 2a above shows
the progression of data types from raw (physical or simulated), to processed (AOD), to derived
(DAOD). In total about 250 PB of disk and 250 PB of tape storage is used. Figure 2b shows the
storage breakdown of tape and disk by different data types. The different data types have
different access frequencies by different ATLAS workflows (WF) which can be classified in a
temperature schema. The RAW detector data is kept on disk only for several weeks and at the
same time archived on tape (2 copies shared between 11 centers worldwide) and only
re-processed once per year - this is so-called “cold” data, because access to RAW samples isn’t
foreseen for bulk physics analysis needs. On the other side there is the frequently accessed and
popular AOD and DAOD data which are primary physics outputs of the RAW data processing
and that are used by many physics researchers - this data can be classified as “hot” or depending
on the version as “medium warm” data and finally cold (or even obsolete) if a new version of
(D)AOD data is produced by an improved version of reconstruction software. DAOD and AOD
samples are read only datasets for the physics community that is comprised of a few thousands
researchers worldwide.
Data can be accessed in a variety of mediums, from data streamed from remote locations, to data
cached on local “scratch” space using spinning disk or ssds. Data can be cached at the nodelevel, and at the site level, with Tier 0 and Tier 1 sites providing the majority of cold storage
capability. On average, datasets have fairly low replication factor, roughly 2. However, the hot
datasets can easily be replicated at a rate an order of magnitude higher.
Data placement decisions can dramatically impact computing efficiency and costs. Disk is
relatively expensive compared to tape. Even for disk, there are different types of disk drive
technologies that vary considerably in price and performance. Slow data access can dramatically
increase costs for computation. In addition to raw storage capability, there are also additional
data services, such as BigTable, that provide fast indexing and caching in memory that may
improve computing speeds and therefore may reduce costs.
The current method for data placement requires local decisions made by explicit requests of the
data users. One approach is to push the data placement decisions down into the software layers
to optimize global costs, like we used to have for Run 1, and provide a seamless and transparent
flow between various data tiers, and across the 150+ sites. Such an automated system would be
easier for researchers to use since they would not need to be aware of the various data storage
locations and capabilities. In addition, this system would be more efficient (fewer copies of the
data), and performant (be able to better serve data to the compute systems) since it would have a
global view of usage across users and sites.
We propose to focus on the challenges involved with storing “hot” and “medium-warm” data of
AOD and DAOD data types. Specifically:
● Determine what is “hot” data to allow additional replicas for faster processing. The
classification could be done using machine learning (ML) algorithms.
● Transfer and cache the frequently accessed “hot” DAOD data on the Google storage.
● Redistribute “hot” DAOD within Google zones (or/and zones) based on the geographical
physics analysis pattern.
● Access this “hot” data stored on Google storage remotely from different Grid sites
world-wide.
● Cost models for the amounts cached data, transfers volumes in and out of the Google
cloud and update frequencies should be determined.
● Determine methods for accessing data securely, both from on-premise and in the cloud.
● How are the datasets stored from an organizational perspective in Cloud
○ E.g., 1 cloud repo per site, a global cloud repo, a cloud repo per continent, etc
● How to manage data lifecycle in cloud repo?
○ E.g., Would it always be deleted when data becomes cold, would it be moved
from SSD to disk, or would it be moved from standard GCS buckets to cold-line
buckets?● How to treat storage in cloud vs on-premise disk storage?
○ Is cloud storage just an extension of the existing disk caches or is it only a replica
of the existing disk subsystems? To extend the amount of disk capacity available,
it makes sense to treat it similarly to existing disk caches; thus allowing more data
to be stored on disk globally.
Currently ATLAS stores the AOD and DAOD in ROOT file format in file sizes of 1-10 GB.
These files are grouped in datasets which hold 10-10k number of files. Together with the Track3
it will be explored if caching “hot” data on the Google storage could be done in different
efficient ways.
We also want to address questions related to the recent trends in tape drives and tape media
market. Currently only one company produces drives, and two companies produce media. What
realistically can we do in 3-4 years if the tape market collapses, how much will ‘cold storage’
cost to the HEP community, how will data be migrated automatically between cold and hot
storage? These questions were raised by WLCG management at the recent Technical
Interchange Meeting between Google/OpenLab/WLCG and HEP experiments at CERN5.
The above topics aren’t ATLAS specific. We anticipate that other HEP experiments may benefit
from ML algorithms to determine data popularity and automatically manage the migration
between different types of storage.
2.2 Track 2: Innovative Algorithms for next-generation Architectures
The “DOE Inventory of HEP Computing Needs” estimated a projected cost of $600M±150M
over the next decade for computing resources at the three DOE experimental frontiers. With
effective use of HPC resources, this cost can be reduced to $275M±70M, dominated by CPU6. A
pre-condition to using next-generation HPCs effectively is to be able to run the most
resource-intensive algorithms (e.g. pattern recognition) on a variety of parallel architectures that
will be optimized for Machine Learning (ML) workflows. Looking further into the future, in the
post-Moore era, Quantum Computing (QC) has the potential to dramatically transform the
computing capabilities of HEP and all data sciences.
5
WLCG/ATLAS/OpenLab/Google Technical Interchange Meeting, CERN Jan 28-29 2019
https://indico.cern.ch/event/791289/
6
Jim Siegrist, DOE HEP Status at HEPAP, 28 March 2018,
https://science.energy.gov/~/media/hep/hepap/pdf/201804/JSiegrist_20180514_DOE_HEP_Status.pdf2.2.1 Machine Learning ATLAS priorities HEP has already proven itself to be a successful early adopter of ML techniques at small scales - collaboration with Google, a pioneer in ML hardware and algorithms at large scale, would accelerate future evolution of the overall HEP computing paradigm towards a successful HL-LHC. Recent ASCR reports7 have emphasized the need for domain knowledge to be effectively incorporated into ML innovations. HEP applications of ML include automation of distributed data and job management including data placement for worldwide analysis, particle track reconstruction, jet reconstruction, and fast simulation. We have a strong mandate from DOE to identify use cases and workflows that can exploit GPU-rich machines, and ML is an excellent candidate for using GPUs in bulk. It remains to be understood what the computing demands are in realistic ML applications, at both training and inference stages. However, the resource demands for ML have been growing exponentially in the past few years, after being flat for many years previously. Continuing fast growth in co-processor usage is expected as ML matures to enhance and replace traditional CPU intensive applications. ATLAS is engaged in a wide range of Machine Learning activities. Using ML techniques for the analysis of LHC data goes back almost a decade, with adoption of neural networks for discrimination of signal from background used in numerous published searches for new physics. Today the ATLAS Machine Learning group is one of the largest and most active software groups in the collaboration, and in collaboration with the Core Software and the Workflow Management groups to bring ML workflows to production. In the US, under the auspices of DOE ASCR SCIDAC8 and ECP programs9, CompHEP CCE center, and NSF IRIS-HEP institute there are multiple cross-cutting research initiatives bringing together LHC physicists and Computer Scientists at universities and National Labs. As ML techniques become widely adopted by ATLAS and LHC in general, they are also becoming increasingly resource intensive and could benefit from new approaches. Google expertise in running large-scale multi-user facilities dedicated to ML workflows, and in 7 ASCR ML Brochure: https://science.energy.gov/~/media/ascr/pdf/programdocuments/docs/2018/ScientificMachineLearningAI-Brochure. pdf 8 For example, SCIDAC program for ML in Cosmology: https://press3.mcs.anl.gov/cpac/projects/scidac/, the RAPIDS Computer Science Institute: https://rapids.lbl.gov/ 9 ECP Exalearn Co-Design Center: https://www.exascaleproject.org/ecp-announces-new-co-design-center-to-focus-on-exascale-machine-learning-techn ologies/
distributed ML may enable ATLAS physicists to increase the power of the ML models they use
for their analyses. However, the highest potential for future growth lies in the use of machine
learning for the most CPU intensive tasks - like pattern recognition for tracking and calorimetry,
and simulations. We plan to focus on these work areas in our partnership with Google, to enable
efficient utilization of alternative architectures with GPUs and TPUs, to offload work from
CPUs, thereby reducing the CPU shortage anticipated for the HL-LHC. Early R&D and
prototypes with edge-TPUs provided by Google, before they are available commercially, will
benefit LHC evaluation of this new technology. Various promising techniques that we will
jointly explored are described below.
2.2.1.1 Pattern recognition for tracking
Reconstruction of particle tracks in HEP detectors traditionally uses finely tuned combinatorial
search algorithms based on Kalman Filters or Gaussian mixtures which are inherently serial.
These algorithms are not well suited for modern computing architectures. Tracking will become
a cost driver in computing for HL-LHC, if we continue with these traditional algorithms. An
additional challenge is the increasing density of images at the HL-LHC (still very sparse
compared to photo ~1% occupancy). We face increasing performance requirements in terms of
accuracy: as the LHC moves from its discovery stage to high-statistics precision measurements it
will likely be necessary to identify more tracks in a more challenging regime (significantly
curved trajectories). In the figure below we show the increasing complexity of particle tracks as
we move to higher luminosities at the LHC.
2010, =5 2018, =40 2026, =200
Figure 3: Charged particles observed in one ATLAS event (data record of an LHC bunch
crossing), in three LHC configurations. Simulated data.
The HEP.TrkX project, among others, has prototyped ML track finding models based on
Geometric Deep Learning10 that should scale better with event complexity and are much easier to
parallelize than conventional track finding algorithms. A recent trackml Kaggle challenge11,
brought contributions from diverse computing science and data science communities and
provides a public, curated dataset and metrics for future R&D. Building on these early
explorations, HEP experts aided by Google experts will develop cross-cutting open source
10
See e.g.: https://arxiv.org/abs/1810.06111
11
https://www.kaggle.com/c/trackml-particle-identificationpattern recognition ML models that scale close to linear with event complexity and that target
ML-optimized architectures such as GP-GPUs and Google TPUs.
2.2.1.2 GAN for fast detector simulation
ATLAS needs to simulate the response of its detector to the passage of particles of given
characteristics. Traditionally there are two strategies to achieve this: run a first-principles
MonteCarlo simulation of the interaction of the particle with the detector, or parametrize the
errors with which a particle is measured by a detector and fluctuate by that amount the observed
value around the true value of a particle property. An alternative approach which is gaining
traction within HEP is to train a Generative Adversarial Network to generate randomized
detector responses to a given particle12. The goal is to provide a new approach to detector
response simulation that has the same CPU performance of fast parameterized simulations, with
an accuracy comparable to full, first principles detector simulation programs like Geant4. Early
prototypes have shown promising results, the challenge is obtain realistic detector responses,
including in the tail of the experimental distributions
2.2.2 ATLAS Quantum Computing Investigations
Beyond ML, Quantum Computing is a new technology that is rapidly advancing. Google is on
the forefront of the development of a universal quantum computing machine1314 and is currently
testing a 72-qbit system named Bristlecone15. Google continues to develop their hardware
towards a goal of quantum supremacy16 and are building software libraries that can be compiled
for the quantum processors. OpenFermion17 and Cirq18 are two high-level python-based toolkits
to explore applications in molecular modeling and simulation.
Given DOE’s existing investments in developing QC, our proposal here is to build a software
library in the same vein as OpenFermion but focused on the algorithms and abstractions that are
appropriate for HEP workloads. HEP researchers from BNL, LBNL, UTA, CERN and Tokyo
University are interested in exploring how particle physics applications can be developed. The
12
https://github.com/hep-lbdl/CaloGAN;
https://indico.cern.ch/event/587955/contributions/2937595;
https://indico.cern.ch/event/587955/contributions/2937509/
13
See https://research.googleblog.com/search/label/Quantum%20Computing for Google’s announcements.
14
R. Barends, A. Shabani, John M. Martinis, and others, “Digitized adiabatic quantum computing with a
superconducting circuit”, Nature, June 8 2016, https://www.nature.com/articles/nature17658
15
See https://ai.googleblog.com/2018/03/a-preview-of-bristlecone-googles-new.html
16
S. Boixo, S. Isakov, V. Smelyanskiy, R. Babbush, N. Ding, Z. Jiang, M. Bremner, J. Martinis, H. Neven
Characterizing Quantum Supremacy in Near-Term Devices, https://arxiv.org/abs/1608.00263
17
https://github.com/quantumlib/OpenFermion
18
https://github.com/quantumlib/Cirqlibrary would provide high-level physics-focused abstractions and compile into the
machine-specific implementations. The library could target multiple Quantum Computers,
including Google’s Bristlecone and DOEs Quantum Testbed systems under development.
Access to experts and systems at Google, as well as joint development of software for QC, would
accelerate the adoption of quantum computing for HEP-related applications.
The HEP community has started exploring quantum computing applications broadly19. The US
is at the forefront of these studies thanks to the DOE HEP QuantiSED program, which is funding
HEP research projects from quantum simulation of black holes and QCD interactions, to
quantum machine learning and pattern recognition. It is the subject of debate and speculation
just when quantum machines (either quantum annealers, or gate-based quantum computers) will
reach the scale where they would be the preferred approach - in some cases this will require
error-corrected quantum machines that are 5-10 years out at the current rate of progress. But it is
certainly not too soon to begin developing quantum algorithms and libraries for particle
simulation and reconstruction, which would run on classical simulators as well as quantum
machines. OpenFermion is one such effort, targeted at molecular modeling. A similar effort for
fundamental particles and HEP would be timely and relevant. Some of the proponents of this
project have started exploring the application of quantum machine learning techniques to the
tracking problem within the QuantiSED program in collaboration with groups in the US, Canada,
and Japan. Early results20 are encouraging and grant further investigation. Google expertise in
hybrid optimization approaches such as quantum variational algorithms, quantum approximate
optimization algorithms, and quantum machine learning may prove extremely valuable for
HL-LHC or FCC applications. It is by no means certain that quantum technology will be
perfected sufficiently by the time it would be needed, but at the current rate of progress, there is a
decent chance, and it would be regrettable not to pursue the algorithmic and work-flow research
necessary, which will take some time. ATLAS and Google will use these studies as a first use
case for a QC HEP library similar to OpenFermion.
Google will provide access to their production quantum systems through the Google Cloud
Platform, and assist in developing the software libraries and compilers. CERN OpenLab is
collecting use-cases and we will have an opportunity to play a leading role in joint
Google/OpenLab/ATLAS QC project, thanks to the experience from DOE QuantiSED projects
19
“Next Steps for Quantum Science in HEP”, https://indico.fnal.gov/event/17199/ ;
“Quantum Computing for High Energy Physics Workshop”, https://indico.cern.ch/event/719844/
20
“QUBO for Track Reconstruction on D-Wave”, https://indico.fnal.gov/event/18104/contribution/61;
“Quantum Associative Memory in HEP Track Pattern Recognition”, https://arxiv.org/abs/1902.004982.3 Track 3: HEP data formats and Input/Output optimization for
distributed object storage
Optimized Input/Output is a topic of interest across the sciences. DOE ASCR has organized
several workshops to define priorities for storage systems and Input/Output to support extreme
scale science21. We will pursue pioneering R&D (complimentary to ongoing research in DOE
ASCR) to evaluate techniques applicable for heterogeneous distributed object storage (grids,
clouds, and HPC). R&D will be conducted in partnership with CERN OpenLab and the ROOT
team. We will explore whether HEP experiments may benefit from data stored as objects, and
not necessarily ROOT trees or ROOT objects. For example HDF5, widely used for numerical
datasets, is itself developing a cloud and HPC service that works with kubernetes and is
cloud/HPC agnostic. A key issue here is that object storage systems have high latency for
access, making HEP data analysis use cases inefficient.
ROOT22 file formats are compressed numerical events that are not optimized for high latency
distributed object storage systems. Asynchronous cached dataflows could enable us to exploit
non-ROOT formats optimal for storage without change to ROOT-based formats used by analysis
clients.
2.3.1 ROOT File Mechanics
ROOT file format, is similar to a mash-up of HDF5 and Parquet. In practice, it’s far more
sophisticated than either format. ROOT files primarily persist arbitrary C++ objects (i.e.
anything that can be typed) arranged in columnar order along with an index to locate individual
ones. ROOT allows compression via various algorithms (currently ZLib, LZMA and LZ4),
streaming attributes from a configurable number of events into baskets and deflating them.
ATLAS achieves a compression ratio of typically 3-4 for its data stored via ROOT. ROOT also
resolves references between objects so that it can store and later recreate complex object
relationships.
Analysis of the data does not require reading back the whole file. Recall that researchers are only
interested in a subset of attributes for a selection of events. A ROOT file contains many (1,000 -
21
For example, Extreme Heterogeneity 2018, ASCR workshop report:
https://science.energy.gov/~/media/ascr/pdf/programdocuments/docs/2018/2018-09-26d-Extreme_Heterogeneity_B
RN_report.pdf
22
https://root.cern.ch/100,000) events and each event consists of many objects and attributes to describe it. Individual
objects for adjacent events (10 - 100) are compressed together into column-wise baskets (the
details of this are configurable) . However, not all objects are particularly relevant to a desired
transformation. Indeed, a researcher creates a “query” using object variables to essentially
retrieve only these objects meeting some criteria, as well as the ones they reference, for further
analysis. The ROOT framework computes which branches contain the desired variables and then
reads the baskets in each branch into memory so that the “query” can be applied to what,
ostensibly, is only the part of the event of interest. Since not all data need to be read from a
ROOT file, a typical analysis only reads a third of the file. Furthermore, to speed-up the reading
of baskets, the ROOT framework also employs an internal read ahead cache.
External access optimization of ROOT files becomes challenging because:
a) ROOT file format is complicated and there are many layout options affecting access
patterns which are not externally visible, and
b) Access patterns can widely vary depending on the particular analysis being performed
and there is no easy way to externally predict the pattern.
The research questions that we plan to address are:
1. Are there better ways to employ cloud object stores with ROOT files?
2. What is the best policy for branch placement in cloud storage?
3. What are the best optimization options for access diverse access patterns for the same
data that vary across a short timeline.
4. Is there a better way to compress and decompress ROOT files other than using internal
compression?
5. Can hierarchical storage (i.e. cold and hot storage) models be efficiently applied to
sub-file storage units and is such a model cost-effective?
6. Is there a better file format for cloud object stores that can also supply the same view for
analysis that ROOT files provide?
7. If the best format significantly differs from the current analysis mode, is the cost savings
sufficient to overcome the cost of changing the analysis regime?
2.3.4 Possible ROOT I/O Approaches in Distributed Object Store
2.3.4.1 Caching with Object Storage
In all of the analysis, GCS is not suitable for direct access by applications using ROOT file
format. This is simply due to the random reads that the application requires. A solution to this
problem is to front GCS with a cache. The cache reads relatively large segments of data from
GCS to storage suitable for random access and delivers the data from its cache. This model is
proven to be effective (e.g. RAL issuing this model to effectively increase Ceph object-storeperformance). This model is not without its drawbacks. Optimal performance can only be achieved when the transfer size is well suited to what the application actually will use. That is very hard to determine ahead of time. Additionally, a cache is only as good as the data within it is reused. That is also problematic as there is no way to determine what data will actually be reused. Ad hoc studies have shown that for ATLAS analysis reuse occurs within seven or more days.. That may require the cache to be far larger than cost warrants. Using detailed monitoring data to model cache size is required here. Even then, this assumes that analysis relative to data access is stable which may be completely wrong. Alternatively, it is possible to completely cache all the required files ahead of time; essentially a copy-to-scratch approach. This has also been proven to work in Google Cloud. Other than being workable it is not clear this would be particularly cost-effective. 2.3.4.2 Event Streaming and Data Flow One way to isolate storage choice and its associated cost is to prohibit the application from directly using any particular type of storage. This can be accomplished using an event streaming model where a service is interposed between the application and whatever storage the data may reside in. The service is responsible for effectively using the storage to deliver individual events to the application (note an application here may be hundreds of parallel jobs). Event streaming is only effective if the application tells the service which events it wants. Since the application may reside on hundreds of nodes running in parallel, the service would need to know the physical layout. This is essentially a data flow problem with several solutions. Even then, it is only optimized to a particular application which may not offer sufficient benefit. One could foresee that certain applications would perform no better with a streaming model than without. The issue here is that the service really needs to have a global view of all applications to maximize the probability of efficient I/O handling. Whether this could be done at a tolerable level of complexity is an open question. 2.3.5 Economics Thus far, most of the attention has been on using the low cost storage option and ways that make it I/O workable for ROOT files. This may not be the best endeavor. GCS storage has relatively high latency per access and each access comes with a fixed charge. Cost may become significant in a random access regime with each access transferring a relatively small amount of data. Furthermore, the increased occupancy time due to latency may drive cost even higher. Using a higher upfront cost storage model more amenable to ROOT file usage may, in fact, be more economical. This approach requires run-time modeling and a multivariate analysis to determine the optimal storage configuration versus run-time performance; work that has yet to be done.
2.4 Track 4: End-user analysis conducted worldwide at PB scale.
End-user data analysis and software distribution: distributed analysis is the focus of the initial
collaboration between Google and ATLAS. We will continue to commission all distributed
analysis capabilities within the existing ATLAS workload management system on the Google
infrastructure and enable users to conduct physics analysis world-wide with data located in the
Google cloud storage.
1. Investigate interactive physics analysis at PB scale using GCP. Google storage for
analysis outputs: analysts spend a lot of time and effort dealing with the ‘tails’ of missing
output data after a distributed analysis run, generally due to inaccessible sites. Outputs
are sent to the Google cloud as a high availability, globally accessible cache so analysts
have access to 100% of their outputs. This is a high value way to use Google storage:
small volume, the hottest of hot data, limited lifetime, and leverages the good global
access.
2. Containers: efficient containerization of all HEP payloads and container management and
orchestration for distributed systems. Coupling this R&D to the well developed analysis
containerization work going on in analysis preservation (Lukas Heinrich et al).
Leveraging Google expertise in container orchestration (Kubernetes).
2.5 Track 5: US WLCG sites elastic extension via commercial facilities
The current tiered model for WLCG consists of dedicated resources at each tier that are
committed to the global resource pool. Higher tiers provide more dedicated resources that are
more persistent, while lower tiers provide fewer resources that are perhaps shared with other
campus projects and have are less persistent in nature.
Many sites today have elastic compute contracts capabilities with commercial cloud providers.
Google, for example, has extensive relationships and contracts with many of the universities
where physics researchers are homed. Given these existing capabilities, these sites may wish to
leverage GCP for their user’s needs.
To do so, we need integration of Cloud with WLCG computing facilities: in addition to
leveraging cloud directly through WLCG, a number of sites have expressed interest in
independently using cloud for their needs, but integrating into the WLCG infrastructure.
The first studies have been conducted by the ATLAS collaborators from U of Tokyo in
coordination with us. U Tokyo computing facilities (for ATLAS) are extended using Google CE.Additional R&D is needed to determine how to support third party billing and provisioning in
workload management system.
3. Project Team, Management and Organization
The project team will be formed as a joint National Labs / Google team. Staff Lab scientists will
be engaged in the project at least 30% and postdocs and assistant scientists at least 75% . The
overall project coordination will be BNL, UTA and Google. Co-leading PIs : K.Bhatia (Google),
A.Klimentov (BNL) and K.De (UTA), with the assistance of co-PIs : T.Wenaus (BNL),
P.Calafiura (LBNL), A.Hanushevsky (SLAC) and P. Van Gemmeren (ANL). The leading PIs
team worked together for more than year during PoC project phase and brought it to the success.
The work packages (tracks), funding and timeline correspond to Phase I of the project
2019-2022). Phase I results should be demonstrated before LHC Run-3, and a decision on pre
HL-LHC Phase II (2022-2025) will be made in 3 years from now.
3.1 Project Management
We propose to conduct project in two phases. Phase I (2019-2022) and Phase II (2022-2025).
The project progress will be reviewed regularly and project team will communicate closely. WP
technical meetings will be conducted weekly and the group of PIs will meet bi-weekly, along
with other project members, to review progress and status. We are planning to have all-hands
meeting twice per year. We will also present project results to HEP community at the major
HEP and computing conferences (CHEP, IHEP and ACAT). We are also planning joint
workshops with WLCG R&D DOMA (Data Organization, Management and Access)23 for
research topics and with CERN OpenLab for joint technologies evaluation (two days technical
interchange meeting between Google / OpenLab / WLCG / LHC Experiments was conducted in
January 2019)24.
We have identified five research tracks to be developed over the next 3 years (Phase I) and the
first deliverables will be ready before LHC Run 3. It will give us an opportunity to verify them at
scale and to do fine tuning before the LHC Run 4 (HL-LHC).
Although the whole team will work collaboratively towards shared project goals the work
packages, the leading Institution and the PI with primary responsibility for each work package
are indicated below:
23
DOMA project https://twiki.cern.ch/twiki/bin/view/LCG/DomaActivities
24
WLCG/ATLAS/OpenLab/Google TIM in Jan 2019 : https://indico.cern.ch/event/791289/Track Work Package PI Institutions
Track 1 Data management across hot/cold storage Klimentov BNL*, SLAC, ANL
Track 2 Innovative algorithms for next-generation
architectures Calafiura LBNL*, BNL, UTA, ORNL
Track 3 HEP data formats and I/O Hanushevsky SLAC*, BNL, ANL
Track 4 End-user analysis Wenaus BNL*, SLAC, UTA
Track 5 US WLCG sites extension with GCP TBD BNL*, ANL, UC, UTA
These five tracks optimally organize the required work. The participants in this proposal will
work together on the software development, deployment, validation and testing. While the
developers will be physically located at different locations, they will communicate frequently
and meet regularly via US ATLAS Computing and SW meetings and workshops. This mode of
collaborative software development has been established between all the partner development
teams during the past few years, and has worked well for the Big PanDA and LCF for HEP
projects. The collaboration between developers and Google teams have also been extremely
fruitful and it was demonstrated during PoC phase.
3.2 Deliverables
3.2.1 Phase I (2019-2022):
Year 1: We will develop a detailed work plan, define development and scientific goals, and
specify metrics of success. The first year will be used for technology evaluation and early
prototyping. During the first year we will concentrate on Track 1 and 4, by the end of the year
we will have proof of principle demonstrator for Track 1 and Track 4. It is related to the fact that
these two tracks are in the most advanced state aft PoC phase. For Track 2 the initial ML
algorithms will be developed and tested at DOE LCF (Titan, Summit) and Google TPUs. For
track 3 we will concentrate on studying ways how to employ cloud object stores with ROOT
files and a policy of ROOT branches placement in cloud storage and ROOT files
compression/decompression research question.
Year 2 : Full scale demonstrator for Track 1 and 4. Integration topics between Track 1 and
Track 3 (we will study how “cold/hot” model can be efficiently applied for sub-file storage units
and is it a cost-effective. By the end of the year we will have working prototypes for Track 1
and 4. The technical solution will be integrated with the HEP computing and ready for LHC Run
3. We will have proof-of-principle demonstrator for track 2 and the first prototype of US WLCG
site extencion with GCP. For Track 2 ML tracking algorithms will be integrated with the core
HEP SW and data popularity algorithms will be in production for data migration between
“hot/cold” storage.Year 3 : Integration between different tracks. A full scale scientific demonstrator. All basic
solutions will be implemented and ready to work at scale during LHC Run 3.
4. Project Resource Allocation
Project computing resources will have two main components. National Labs computing
resources and Google computing resources. The FTE breakdown is listed below in Table 1. We
estimate that approximately 7 full time research scientists and computing professionals will be
needed to carry out work proposed during Phase I.
This proposal includes funding for Google professional services, as a subcontract to Brookhaven
National Laboratory. This funding will provide dedicated personnel by Google professional
services to participate. In addition to the personnel, Google will provide access to advanced
technology, including TPUs and production quantum accelerators, extensive cloud credits that
can be used for development and testing, and access to additional non-dedicated personnel
include technical systems architects and engineering specialists as needed throughout the project.
The dedicated resources, however, are an essential component of this project as the existing
CERN environment is complex and requires a consistent engagement. This is a common model
for any large enterprise cloud engagement. This is a similar arrangement to Google’s work with
LSST.
Google personnel will work together with National Lab physicists and computing scientists.
Google staff engaged in the project will be supported via funding provided to BNL. It is also
anticipated that UC and UTA participation will be paid via the WP leading Lab (ANL, BNL or
LBNL).
Work Package US ATLAS Ops Google Requested Total
Program
Data 0.75 0.5 1 2.25
management
across hot/cold
storage
Machine 1 0.5 1 2.5
learning and
quantum
computingHEP data 0.5 0.5 0.5 1.5
formats and I/O
for distributed
object stores
End-user 0.5 0.25 0.25 1.0
analysis
US WLCG sites 0.5 0.5 0.25 1.25
extension with
GCP
Total 3.25 2.25 3 8.5
Table 2. FTE required to complete work packages, per year, for the 2-3 year duration of the
project. Additional 1 FTE is involved in coordination of project.
5. Acknowledgements
This white paper was enriched by discussions with members of BNL CSI (Computer Science
Initiative), ATLAS International Collaboration, and CERN OpenLab.You can also read

















































