Adaptive intelligent learning approach based on visual anti-spam email model for multi-natural language
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Journal of Intelligent Systems 2021; 30: 774–792 Research Article Mazin Abed Mohammed*, Dheyaa Ahmed Ibrahim, and Akbal Omran Salman Adaptive intelligent learning approach based on visual anti-spam email model for multi-natural language https://doi.org/10.1515/jisys-2021-0045 received March 24, 2021; accepted May 26, 2021 Abstract: Spam electronic mails (emails) refer to harmful and unwanted commercial emails sent to corpo- rate bodies or individuals to cause harm. Even though such mails are often used for advertising services and products, they sometimes contain links to malware or phishing hosting websites through which private information can be stolen. This study shows how the adaptive intelligent learning approach, based on the visual anti-spam model for multi-natural language, can be used to detect abnormal situations effectively. The application of this approach is for spam filtering. With adaptive intelligent learning, high performance is achieved alongside a low false detection rate. There are three main phases through which the approach functions intelligently to ascertain if an email is legitimate based on the knowledge that has been gathered previously during the course of training. The proposed approach includes two models to identify the phishing emails. The first model has proposed to identify the type of the language. New trainable model based on Naive Bayes classifier has also been proposed. The proposed model is trained on three types of languages (Arabic, English and Chinese) and the trained model has used to identify the language type and use the label for the next model. The second model has been built by using two classes (phishing and normal email for each language) as a training data. The second trained model (Naive Bayes classifier) has been applied to identify the phishing emails as a final decision for the proposed approach. The proposed strategy is implemented using the Java environments and JADE agent platform. The testing of the perfor- mance of the AIA learning model involved the use of a dataset that is made up of 2,000 emails, and the results proved the efficiency of the model in accurately detecting and filtering a wide range of spam emails. The results of our study suggest that the Naive Bayes classifier performed ideally when tested on a database that has the biggest estimate (having a general accuracy of 98.4%, false positive rate of 0.08%, and false negative rate of 2.90%). This indicates that our Naive Bayes classifier algorithm will work viably on the off chance, connected to a real-world database, which is more common but not the largest. Keywords: anti-spam detection, machine learning techniques, adaptive intelligent learning, multi-natural language, multi-agent system, Naive Bayes classifier * Corresponding author: Mazin Abed Mohammed, Information Systems Department, College of Computer Science and Information Technology, University of Anbar, 31001, Anbar, Iraq, e-mail: mazinalshujeary@uoanbar.edu.iq, tel: +964-7801141441 Dheyaa Ahmed Ibrahim: Communications Engineering Techniques Department, Information Technology Collage, Imam Ja’afar Al-Sadiq University, Baghdad, Iraq, e-mail: Dheyaa.ibrahim@sadiq.edu.iq Akbal Omran Salman: Department of Control & Automation Techniques Engineering, Electrical Engineering Technical College, Middle Technical University, Baghdad, Iraq, e-mail: akbal.o.salman@mtu.edu.iq Open Access. © 2021 Mazin Abed Mohammed et al., published by De Gruyter. This work is licensed under the Creative Commons Attribution 4.0 International License.
Adaptive intelligent learning approach for multi-natural language 775
1 Introduction
One of the most provoking and harmful extensions to internet technology is spam. The effectiveness of
conventional software used for filtering spam has been lessened by the increased amount of spam, which
has overwhelmed anti-spam defenses. The increase in the number of spam-related problems urges the need
for developing tools that are more effective and efficient in controlling such problems [1]. Machine learning
(ML) methods have supplied scientists with a good method to strange spam. ML has been applied success-
fully to classify spam electronic mails (emails) [2–4]. Presently, the risk of phishing emails can be identified
with minimum human involvement, thereby enabling a high level of accuracy and easy control. The
different components of spam emails need to be subjected to processing before their application in the
correct algorithm, after which the algorithm can be applied to email filtering and classification. The algo-
rithm can only be used for this purpose after the email contents are transformed into numeric data; this is
the first step to apply this algorithm to the above purposes. However, the header and the body of the email
can be different and do not reflect the message that the sender is sending to the recipient. Sometimes, the
data contained in the header share similarities with the content in the body of the email. Thus, the accuracy
of email spam filters can be reduced when only headers are used [5]. This process involving the use of only
headers is referred to as preprocessing, and it involves the extraction of features, selections of features,
removing the stop word, and stemming [6]. To increase the efficiency of the spam filter, the preprocessing
step can be employed. The step can be used when feature vectors are trained and tested, considering the
problems that it is faced with. Image spam is a different type of spam, whereby the spammer sends the spam
as a portion of an entrenched file supplement instead of sending messages. The image content like GIF file
format may be included in the spam image, or even a similar kind of file format, usually containing several
random words, which in some cases is referred to as word salad. Sometimes, the image may contain a link
to a website. To avoid detection by conventional anti-spam technologies, an image spammer may combine
such components. Usually, when these images go to the receiver, they are displayed automatically. Sadly,
some of the available spam filters are inadequate to detect such image spam messages as spam. The spam
capture rate declined throughout the messaging security industry due to the rise in more complex image
spam. This increase, in turn, leads to a waste of productivity as well as end-user frustration as the number
of delivered spam increases.
Presently, images form a crucial part of the World Wide Web, as statistics taken from over four million
HTML webpages show that the pictures make up 70.1% of web content. This number means that, on
average, each HTML webpage contains 18.8 images [7]. The text-based methods are characterized by two
main shortcomings [8]. The first shortcoming is associated with using a wide range of tactics by spammers
to create confusion for text-based anti-spam filtering. The second shortcoming is associated with the
diversity of the kind of information contained in emails. The variety has increased due to the continuous
growth of the capacity and the scale of the internet. Presently, emails are not only made up of text but also
multimedia content. These limitations and challenges have reduced the effectiveness of the existing pro-
posed models (anti-spam filters). One of the main issues faced with the existing data is that the emails
include not only the text but also multi-form of data. Similarly, this technique is used by spammers to
disguise spam messages, thereby confusing text-based anti-spam filters through the use of tactics that are
HTML-based [9]. A filtering program may find the unprocessed content of spam emails meaningless.
However, the messages that are concealed can be seen by the recipients. Due to the increasing prevalence
of visual information in emails, it becomes crucial to use this information to ensure that anti-spam filtering
achieves a high level of accuracy. Thus, this study investigates how the use of visual information, especially
images, can be employed in anti-spam filtering. Moreover, a novel intelligent anti-spam technique is
developed in this study to overcome these shortcomings.
Based on the three points of view, a discussion on spam problems and their effect has been provided by
different researchers. Several researchers have highlighted the financial, economic, management, mar-
keting, and business implications of spam, whereas others have focused on studying the effect, which
spam has on privacy, security, and data protection. Many researchers have studied the different anti-spam
filter approaches like IP blocks and ML. Furthermore, many studies have focused on investigating the effect776 Mazin Abed Mohammed et al.
of spam on email account, society, and email reliability. The proposed approach is implemented within the
Java environment using the JADE agent platform. The successful detection and filtering of a wide range of
spams can be achieved when this application is used. In this work, a novel adaptive intelligent learning
approach is introduced based on the visual anti-spam model for multi-natural language capable of addres-
sing these weaknesses and cover Arabic, English, and Chinese languages. Anti-spam filtering method based
on multi-trainable model has been proposed to identify the phishing email. The main contributions of this
article can be summarized as follows:
• To scrutinize an extant anti-spam technology and alongside its limitations.
• To compare the various mutual document processing and identify their strengths and the weaknesses of
the products.
• To propose and implement a novel mutual document processing model that can address the limitations of
the extant mutual document processing model and evaluate the method’s performance.
• To construct a novel visual anti-spam model based on the text of the newly proposed mutual document
processing model.
• To evaluate the performance of the anti-spam model based on the text using both subjective and objective
evaluations.
• To introduce a multi-trainable model that can identify the language type and the phishing email by using
Naive Bayes classifier.
• To propose a new affective model to identify the language by using the text features and the Naive Bayes
classifier as the first model and the outcome of this model to be used as input for the next model.
• To use the training data (phishing and normal email) as a learning stage for the second model and use the
trained model to identify the email situation.
The rest of this article is divided into five sections and several subsections. Section 2 provides the study
of existing literature on methods of classifying anti-spam, followed by Section 3, which describes the
materials and methods used in the research. Section 4 illustrates the theoretical background of the pro-
posed approach that is proposed in this work. In Section 5, the implementation of the method is presented,
and the results of the performance of the proposed model are also given. Finally, Section 6 concludes the
work and highlights the directions of future work.
2 Background and related works
2.1 Email
A messaging system through which messages are transmitted across computer networks electronically is an
email [8]. The messaging system requires the sender of the message to open a message panel, type in the
address of the recipient, the subject of the message, and the email content, and then send the message to
the recipient by clicking the send icon. Free email services such as Yahoo, Hotmail, and Gmail could be
easily accessed by users. They could even obtain an email account by getting registered with the internet
service providers (ISPs). Such email services are not paid for but can only be used with an internet con-
nection. Also, another characteristic of emails is the immediacy with which they are received after being
sent. Using an efficient mail delivery system, communication can be established between email users at an
affordable rate [9].
Email services have emerged as the most commonly used means of communication because they are
reliable, user friendly, and readily available. Thus, corporate bodies and individuals rely on this means of
communication [10]. As noted earlier, the main elements of an email are the header and the body of the
message. The information about the transmission and subject of the mail is found in the header. The
elements of the header are as follows:Adaptive intelligent learning approach for multi-natural language 777
• From: information of the sender like the email address is found here.
• To: contains the receiver’s details like the email address.
• Date: the date when the email is sent to the specific recipient(s) is contained here.
• Received: this part contains the server’s intermediary information and the date when the email message is
processed.
A drastic reduction in communication costs can be achieved using email, a cheap and speedy means of
communication. In addition, email is a very efficient communication tool that can be used for marketing
and, as such, can be leveraged by business corporations [11]. As it is a commonly used channel of adver-
tising, businesses can capitalize upon email. Nevertheless, one of the problems associated with this com-
munication tool is spam, and this is because sending emails is characterized by affordability and simplicity.
The description “spam” is given to unsolicited emails sent in bulk to many users for varying reasons like
phishing and commercial purposes [12].
2.2 The spam phenomenon
There are different definitions of the term “spam.” It is also known as junk mail. In the various definitions,
the difference between legitimate and spam is highlighted. Even though there are different definitions, the
most commonly used is the one, which refers to spam as “unsolicited bulk email” [13–15]. Spam has been
categorized based on the research carried out by Subramaniam et al. [10]. These categories are presented in
Table 1.
Table 1: The categories of spam applications
Categories Descriptions
Health Involves spam emails that promote or advertise fake medications
Promotional products Spam containing counterfeit fashion goods, such as watches, shoes, bags, and clothes
Adult content Spam, which contains pornography or other related contents
Finance and marketing This kind of spam offers loan packages, stock kiting, and tax solutions
Phishing Fraud or phishing spam such as “Spanish Prisoner” and “Nigerian 419,” which are sent to users
with the aim of defrauding them
Malware This kind of spam is sent with the aim of spying on and attacking personal computers
Education This kind of spam is sent to users by offering them fake certificates of online education
Political The spam of political targets like elections by online voting
In general, a broad range of goods and services are often advertised using spam, and changes occur in
the rate of advertisement devoted to a particular class of goods and services as time goes by. Most of the
time, spam is used by online fraudsters to satisfy their needs. A classic example of spamming activity is
phishing, whereby fraudsters search for confidential information, such as details and passwords of credit
cards. Here, the fraudsters imitate official requests from reliable authorities such as banks and service
providers [16]. Another kind of harmful spam is a virus; the operation of a mail server is interrupted by
fraudsters using a massive spam attack [17]. Conclusively, the senders of spam messages do so to steal
people’s confidential information to defraud them by advertising ideas, goods, and services; delivering
harmful software; or temporarily disrupting a mail server. Based on the content of spam, they are catego-
rized into various subjects and a wide range of genres because of the simulation of different classes of
authentic emails, such as memos, order confirmations, and letters [18]. The characteristics of legitimate
email traffic differ from those of spam traffic. However, the spam sent steadily over the time of legal emails
occurs during the day time to provide clear image that is normal email [19].778 Mazin Abed Mohammed et al.
When spammers send spam, they often conceal their identity using a variety of methods. However, their
identity is not hidden while the email addresses are being harvested from online materials, such as papers
or websites. In essence, harvesting activities can be a way to determine the spammers’ activities [20]. It is
important to note that spammers are normally reactive, i.e., any successful anti-spam effort is actively
opposed by spammers [1]. With this, after the deployment of every new method, a decrease in the efficiency
of such a method occurs. The study carried out in ref. [21] analyzed the evolution of spamming techniques,
and the results revealed that with the presence of very efficient filters or other efficient solutions, the
effectiveness of spam can be sabotaged.
2.3 The spammers’ tricks
The ability of spammers to send spam emails depends on their capability to obtain email addresses; they
employ the use of special software to harvest the email addresses from the internet. With this software, the
spammers can systematically gather email addresses from group discussions or websites [22]. Moreover,
many email addresses can be bought or hired by spammers from other specialist co-ops spammers. There is
a variety of tactics used by spammers to avoid being identified through filters. These baits are presented and
briefly described in Table 2.
Table 2: Tactics that spammers use when sending spam [1]
Tricks Descriptions
Zombies or Botnets With these tactics, a large amount of spam, viruses, and malware is sent through
personal computers on the internet
Bayesian sneaking and This kind of trick allows the spammer to write a spam message using words that are
poisoning rarely used in a spam message. In addition, the spam messages do not “poison” the
Bayesian filter database
IP address The spammer acquires and uses a trusted IP address that also has nonpartisan repute
Offshore ISPs Here, offshore ISPs with no measures of security are used by the spammers
Open proxies/open-relay servers This tactic allows spam to be redirected to vulnerable users through the use of servers
Third-party mail back software Here, the spammers employ the use of emails that are wrongly anchored on trustworthy
websites
Falsified header information False header details are added to the spam message
Obfuscation Nonsense creative symbols of HTML tags are used in splitting words with the aim of
masking spam messages
Vertical slicing This trick allows spam messages to be written in vertical direction
HTML manipulation HTML format is manipulated with the aim of preventing the spam message from being
detected
HTML encoding The use of encoding methods, such as Base64, is employed in changing the binary
attachment to plain text characters
JavaScript messages A JavaScript scrap is used in setting the whole content, and when the message is
opened, it gets enacted
ASCII art Glyphs of standard letters are used to write spam messages
Image-based An image is used by spammers to send textual information to users
URL address or redirect URL With this trick, detection is avoided by adding URL address. In some cases,
unimportant portals are used so that the users can be led to the real websites
Encrypted messages Message is encoded but gets unscramble upon achieving the letterbox
2.4 Spam impact
The first spam was discovered on 3 May 1987, where spam emails were transmitted to almost 400 ARPANET
users who were given an open invitation to the then-forthcoming computer hardware demonstrations [23].Adaptive intelligent learning approach for multi-natural language 779
Since then, spam messages have become part of a day-to-day disturbance that users of email services
experience. Currently, the volume of spam emails recorded worldwide is in the range of 53–58%. Down from
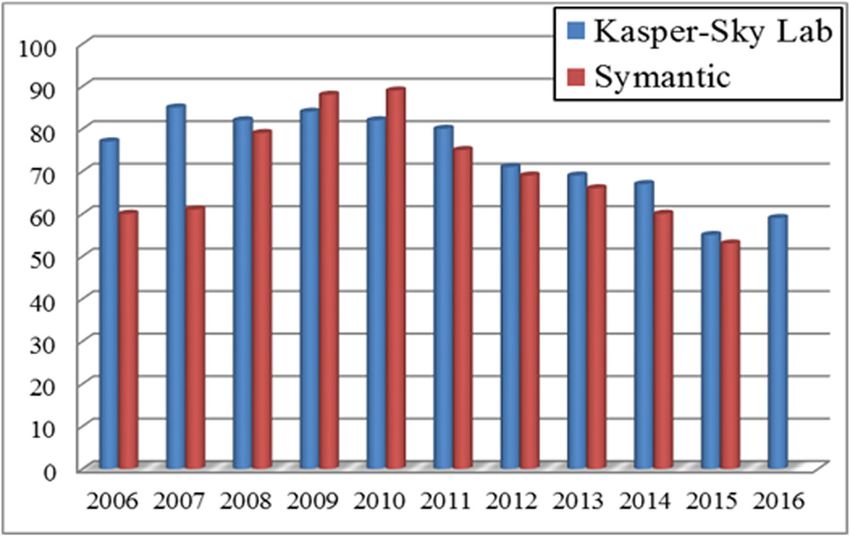
a peak of 88% in 2010 [24], it is still well above its estimated proportion of 10% in 1998 [25]. Figure 1 shows
the average spam distribution from 2006 to 2016.
Figure 1: Average of spam from 2006 to 2016 [1,12].
2.5 Current methods for spam detection
Recently, the problems associated with spam messages have increased because of the increase in email
usage. It has been observed that spam emails have become a major concern as many spam messages with
offensive content are circulated. With this problem, the reliability of email is reduced, thereby reducing the
confidence of email users. As a result, when such spam messages are received, the network bandwidth is
wasted and so is the time spent by users to differentiate between legitimate messages and spam. However,
business owners can benefit from spam marketing since it allows sending of bulk messages at an affordable
rate, thereby leading to the maximization of profits. Several countries have adopted spam as a marketing
tool because of economic gains, although it is limited by the fact that many such messages emanate from
various countries. Hence, it may be difficult to trace the real senders of the spam messages, and this, in turn,
makes it difficult to set laws and regulations associated with the use of spam. Besides using legal
approaches to dealing with spam, researchers have suggested that the models of operation and protocols
should be changed. In the current section, a wide range of available anti-spam techniques are presented.
The research efforts made in this area are commendable, and as a result of the relevance of this subject
matter, more research is being conducted to discover newer spam detection methods. In the work con-
ducted by Nosseir et al. [26], a character-based method was proposed. In the proposed method, the use of a
multi-neural network classifier is employed, and it also involves the training of each neural network based
on a normalized weight derived from the ASCII value of the word characters. Nevertheless, the words can be
camouflaged by the attacker who can use quite a different spelling to write the words or can use visuals to
boycott any detection attempt. Thus, the rate of detection can be lessened. In the work by Aski and Sourati
[27], a rule-based method was proposed, and 23 features have been identified and selected carefully from a
spam dataset that was accumulated personally. Then, a score was designated for each of the criteria.
A comparison between the accumulated score and a threshold value was carried out to determine
whether an email is legitimate or spam. They used three approaches of ML, which are as follows: C4.5
Decision Tree classifier, Multilayer Perceptron, and Naive Bayesian classifier. However, the database used
for the study was insufficient as it contained only 750 spam messages. Their results were not reflective of the
performance in terms of memory and time. In a different study by Feldman et al. [28], the use of term level
was proposed for mining text in emails. The authors suggested that the first step of the mining process780 Mazin Abed Mohammed et al.
should be the preprocessing step, whereby the collection of the document is subjected to preprocessing,
and the important terms are extracted from the documents. After the preprocessing step, each document
will be denoted as a collection of annotations and terms, which the document is characterized by. With this
approach, the frequency at which the terms occur can be obtained. Nevertheless, this approach also has a
limitation, which is its inability to treat a huge number of texts. The literature review also shows that some
researchers have focused on developing approaches that can be used to identify the accounts used for
spamming. One of the approaches proposed for the identification of spamming accounts is the early
detection of spamming (ErDOS) system, which is capable of detecting spamming accounts early. In ErDOS,
the detection of spamming accounts involves the combination of features and content-based detection
techniques, based on patterns of inter-account communication [29]. For future work, the authors suggested
that the work can be further improved to detect spammers’ account in real-time.
Idris et al. [30] proposed a novel method by combining differential evolution and negative selection
algorithms. The proposed novel hybrid model is characterized by a special feature that allows differential
evolution to be implemented in the random generation phase of NSA. Also, the generated detector is
maximized by the model, whereas the overlap detectors are minimized [31]. However, the authors failed
to address other problems such as clickjacking and image spam. This method can be improved by adding a
feature that allows the extraction of regular expressions from the entire text of the messages rather than the
extraction of the contents of the subject header, which is currently used in this approach. Clickjacking, also
referred to as UI redressing or IFrame overlay, is a kind of attack that involves overlaying a button or a field
by harmful links or scripts that are often invisible. This technique is popular in the community of hackers
who deceive to bait users into clicking buttons or links, usually due to the color possessed by the link. It is
often difficult to distinguish between the background color of the page and the color of the link because
they are almost the same. Also, no precautionary measures are put in place by many banking websites and
three of the Alexa top ten websites to combat attacks that are associated with clickjacking [32]. One of the
ways through which clickjacking can be combated is sending a confirmation prompt to users when they
click the target element [33]. Users should be required to mark a checkbox as a way of confirming or to enter
a correct CAPTCHA before the intended button can be clicked.
The “Phishing Email Detection System,” proposed in ref. [34], is developed based on unsupervised and
supervised techniques. This system is equipped with features of reinforcement learning, and it can adapt to
environmental changes. The efficiency of this technique is greater in Zero-Day phishing attacks, but they
are less suitable for spam that is usually used for advertisements. The feature evaluation and reduction
algorithm, the most integral part of the system, allows dynamic selection and ranking of the most relevant
features from emails based on many environmental criteria. Nevertheless, the features that are chosen are
quite unconventional and insufficient. The study conducted by Zhu and Tan presents a feature extraction
that is based on local concentration (LC). They developed their anti-spam framework using this technique
[35], inspired by the “Biological Immune System.” Using the LC approach, each area of a message can be
converted to a corresponding LC feature such that the position-correlated details can be determined from a
message. A sliding window with a fixed length can be used to divide the content of the message. Feature
engineering can be employed to obtain fresh features from extant ones [36]. Hayat et al. [37] presented a
discussion on the implementation of spam filtering, which is based on the improved version of the Naive
Bayes algorithm. Compared to the other systems developed based on the original version of the Naive Bayes
algorithm, the performance of the improved version is better. The model works by comparing the content of
the current set of emails with the previous ones. If a major change is detected, the model makes automatic
adjustments wherever necessary. Thus, a significant improvement is seen in spam detection rate after the
changes are made and updating is completed. In this study, the authors achieved an accuracy rate ranging
from 8 to 9%, depending on a multinomial Naive Bayes algorithm. Usually, the use of support vector
machines (SVMs) has been extensively employed, and their efficiencies have been evident in designing
anti-spam systems based on ML. SVMs are more advantageous than other algorithms as they are capable of
dealing with feature sets that are highly dimensional with several attributes [38]. Additionally, the “kernel
trick,” which is part of SVMs, can be used to change non-linearly separable data into new data that can beAdaptive intelligent learning approach for multi-natural language 781
separated linearly [39]. Nonetheless, the study conducted by Alsmadi and Alhami [40] contended that
when n-Gram-based clustering classification is used, a lower rate of false positives (FPs) can be obtained.
3 Research methodology
This study follows basic steps of research such as data gathering and mutual document processing. The
three major stages involved in this research are presented in Figure 2.
Study the existing methods
and highlight the limitations
Main Research Focuses Identify the evaluation
methods
Specify the requirements of
the proposed method
Document Processing
Technique
Data Collection and Preparation
Evaluate the Technique
Design the model
Design and implement the
proposed model Implement the model
Evaluation Stage
Figure 2: Phases of the research methodology.
3.1 Main research focuses
In the preliminary stage, the anti-spam filtering methods were investigated using the soft computing tech-
niques based on mutual text processing. The researcher’s understanding of the issues associated with extant
anti-spam technology, as mentioned earlier in the problem statement, and the performance assessment of
extant anti-spam technology were also investigated. The requirements for developing a novel efficient visual
anti-spam technology were also defined in this phase, while the text database was prepared. The preparation
of the database involved the establishment of a connection between the email of the researcher and Outlook,
to read the emails of the researcher from the Outlook, and also to be able to save these emails on the PC in the
HTML format. Subsequently, WordPad was used to access the emails so that they can be saved in the text
format. If an email, with the body (HTMIL) in the form within tickets, is identified as spam, the researcher
staged in this way took all the emails within contents. Two kinds of emails were collected for this study:
legitimate emails and spam emails. During the collection of emails, some challenges were faced by the
researcher. The researcher also encountered some limitations, such as the unavailability of text emails
with complete contents in HTML on the internet. The emails that were gathered from the internet were sorted782 Mazin Abed Mohammed et al.
manually, thereby consuming much time. About 2 months were required for this activity. Out of 200 emails
that were gathered, 100 were non-spam and the remaining 100 were spam.
3.2 Data collection and preparation
This phase involved the set up required for the testing of the dataset. In this phase, the message was
examined by linking an email to the Outlook. After this activity, the emails were stored in the HTML format,
while WordPad was employed to save the emails in the form of text files. Thus, the body of the email was
made in the HTML format. The emails were then divided into two groups, i.e., spam and legitimate
messages. After the completion of the setup, the emails were used to perform the testing.
3.3 Design and implement the proposed model
To get a uniform format that can easily be understood by the trainable model, a transforming stage has been
proposed. It is only this way that the emails can be used as input to the trainable model [1]. The data, i.e., the
email contents have been processed to extract the body from the header as two parts. While the general details
of the sender (address of the recipient, subject of email, and details of route) are contained in the header, the
body contains the actual contents of the email. All this information must be extracted using preprocessing
before the emails can be filtered. The body and the header do not contain the same information, and as such
do not provide clues on the information that is conveyed to the receivers by the senders. Thus, depending on
one part of the email might result in a low accuracy rate in terms of email spam filtration.
4 Adaptive intelligent learning approach
The adaptive intelligent agent learning model is operated based on a multi-agent system in which both the
model and the system have interaction within the anti-spam classification domain [1,41]. These agents
function collaboratively to find solutions to problems; working individually will not solve the problems. The
use of agent application increases the system’s flexibility. Besides, with agent application, the system’s
functionality can be segregated, while interaction is enabled between the systems and their modules. In this
work, a novel adaptive intelligent learning approach is introduced, based on the visual anti-spam model for
multi-natural language capable of addressing these weaknesses and cover Arabic, English, and Chinese
languages. A multi-trainable system operates this model that contains different forms of information, i.e.,
images in the proposed trainable anti-spam model. An adaptive intelligent agent learning model is made up
of different stages, as shown in Figure 3.
The processing steps involved in the adaptive intelligent learning model, by the multi-agent system, are
illustrated in Figure 2. Different agents perform different tasks during the spam detection process, which are
as follows: (1) is a representation of the first agent that processes short words, (2) denotes the second agent
saddled with the responsibility of extracting features, (3) represents the third agent, responsible for selecting
the features, (4) denotes the fourth agent responsible for the presentation of the instances, and (5) is the agent
that classifies the email. This shows the different roles played by the different agents in this process.
As mentioned earlier, an email has two main parts: the header and the email body. In both the header and
the body, the information contained must be extracted before the process of filtration; this is done in the
preprocessing stage. There may be differences between the two parts, and they do not provide clues about the
message conveyed in the email. Thus, the accuracy rate of the email spam filter may be reduced if only one
part is used, i.e., either the body or the header. To achieve a higher accuracy rate, both parts should be used.Adaptive intelligent learning approach for multi-natural language 783
Emails in Arabic Emails in English Emails in Chinese
language language language
Feature Extraction
Naive Bayes
classifier
Testing Images Trained Model
Language type decision
Phishing email
Feature Extraction
Normal email
Naive Bayes
Labels
classifier
Trained Model
Train a new model for the
phishing email identification Final decision
Figure 3: The adaptive intelligent learning model.
The concept of mutual document processing is used in describing this process. Utilizing this process, mes-
sages in the email are transformed into a uniform format, which the learning algorithm can comprehend [1].
The concepts associated with the novel mutual document processing are described below.
4.1 Short words form
Contrary to the usage of short forms of words in short message service (SMS), used because of the limited
size of the message, most spammers use short forms of words to confuse spam engines. The study in ref. [42]
noted that some companies have focused on the creation of software that is capable of translating SMS, and784 Mazin Abed Mohammed et al.
an example of one such company is Geneva Software Technologies Limited. With the new SMS trends,
several websites such as Canada’s transl8it.com have been introduced; the company provides SMS transla-
tion services by matching words directly. Moreover, employing this new translation trend, cooperation is
encouraged between companies that provide translation services and service providers. An example of such
a collaboration is the one that exists between Singapore’s GistXL Pte Ltd. and Singtel network. From what is
known, no study has focused on the translation of short-form words to full-form intending to solve this
problem. As mentioned above, it is important to carry out extensive research on short form and stop word
messages. During the document processing stage, the ambiguous words will be eliminated by the anti-spam
filtering or they will be regarded as unknown. For example, the spam cannot deduce any meaning from the
word “LOL,” whereas it means “Laughing out loud.” The authors in ref. [43] published over 1,300 abbre-
viations, as provided in Table 3.
Table 3: List of short-form messages [43]
Short messages Meaning Short messages Meaning
4 For 0.02 My (or your) two cents worth
9 Parent is watching 2 Meaning “to” in SMS
86 Over 19 Zero hand (online gaming)
88 Bye-bye 20 Meaning “location”
88 Hugs and kisses 121 One-to-one (private chat initiation)
404 I do not know 143 I love you
411 Information 1337 Leet, meaning “elite”
411 Information ;S Gentle warning, like “Hmm? What did
you say?”
420 Let’s get high ? Having a question for you
420 Marijuana ? Did not understand your question
459 Love you ?4U Having a question
511 Too much information (more than 411) @TEOTD At the end of the day
555 Sobbing, crying ^^ “Read line” or “message above”
831 I love you (8 letters, 3 words, 1 meaning)Adaptive intelligent learning approach for multi-natural language 785
parse the words (tokens), the words are added to a vector space, and the features space is constructed to
enable classification [46]. The body and header of the emails have been used as input to the proposed
model to extract the wanted features.
4.2.1 Reading and tokenization
Tokenization refers to a process through which a message is reduced to its colloquial component [46]. In
this process, the message is taken and divided into different tokens, also known as words. These words
come from the mail body, even though consideration can be given to the header and subject fields. The
acquired words are added to a vector space so that a feature space can be constructed. All the possible
features can be extracted from message by using the tokenization process, regardless of how relevant they
are. Features that have been transformed to tokens are highly vulnerable to content obscuring, and as such,
they must be subjected to the processes of stemming, reduction of dimensions, and elimination of stop
word. However, no given solution or standard exists that should be used for tokenization of the character
stream. Also, there is no consensus on how this stage should define results due to the lack of shared
knowledge and techniques in this area.
Furthermore, not much attention has been given to assessing the quality of results due to the absence of
assessment methods with standard benchmarks. Another issue associated with this area is using different
languages by the spammer, such as Arabic spam. In modern day Arabic messages, English characters with
numbers are employed. Instead of using Arabic letters that are not present in English, numbers are used, as
presented in Table 4. In such a case, processes of short word form are required (Table 5).
Table 4: Arabic characters examples used as modern Arabic samples for chatting
Arabic character ﺍ ﺏ ﺕ ﺙ ﺝ ﺡ ﺥ ﺩ ﺫ ﺭ ﺯ ﺱ ﺵ ﺹ
English character 2 b T Th G 7 5 d 4 r Z s sh 9
Arabic character ﺽ ﻁ ﻅ ﻉ ﻍ ﻑ ﻕ ﻙ ﻝ ﻡ ﻥ ﻩ ﻭ ﻱ
English character ‘9 6 ‘7 3 ‘3 f 8 k L m N h w ﻱ
Table 5: Three sentences or expressions in Arabic, modern Arabic, and English language that are used for chatting
Arabic Modern Arabic chat English
ﻛﻴﻒ ﺣﺎﻟﻚ؟ kef 7alk How are you?
ﻣﺮﺣﺒﺎ Mar7aba Hello
ﺷﻮ ﺍﺧﺒﺎﺭﻙ Sho a5barak What’s up
The modern Arabic language has become a widely used chatting language, and for this reason, many
spammers have started employing this technique. Based on the current knowledge, no study has been
conducted on this type of spam, but in this study, the researcher found one email in which this kind of
method of spamming was used. Also, this type of method might be adopted for other languages, i.e.,
English language.
4.2.2 Regular expressions
The normal expressions computing are a flexible and brief means through which strings of the text can be
matched, like characters, character patterns, or patterns of words. Formal language is used in writing a786 Mazin Abed Mohammed et al. regular expression, and a regular expression processor can be used to interpret the formal language [1]. Additionally, a parser generator, which enables the identification of parts that correspond to a specification or a program used for the examination of texts, can be used here. Below are some examples of normal expressions that can be used in different sentences or words, i.e., the word “car” might appear in “car- rageen” or “Career.” • The expression “car” when we use it as a single word. • The expression “car” when we use it after the word “red” and “blue.” • One or more digits follow the dollar sign immediately, i.e., 20$ or 222.56$. 4.3 The agent feature selection The selection agent performs the task of reducing the dimensionality of feature vectors [1]. Another function of the selection agent is measuring the frequency of appearance of a specific term or phrase. According to a fixed threshold, the elimination of unimportant and idle words or phrases is also carried out by this agent. This process plays a vital role in improving the classification [44,45]. This process also involves the elimination of common morphological phrases that have similar details and stop words, such as “the,” “a,” and “an.” 4.3.1 Document frequency Document frequency is described as the number of documents, n, in which feature appears. The measure- ment of the features’ weight is taken based on frequency, and if the frequency is less than a fixed threshold, it is eliminated. Moreover, irrelevant features that do not contribute, in any way, to the process of classi- fication are not considered, thereby resulting in the improvement of the classifier’s efficiency [47]. 4.3.2 Mutual information Mutual information is described as a quantity through which the mutual dependence of two variables can be measured. If a feature is independent of a class, it is eliminated from the vector space. The predictions made by mutual information are often accurate, and implementing this mutual information model is easier [47]. 4.3.3 Stemming The process of stemming involves stripping plural words from noun words (e.g., “boys” to “boy”), suffixes from verbs (e.g., “measuring” to “measure”), or other affixes. The process of stemming, which was first introduced in 1980 by Porter, is defined as a process through which inflectional endings and common morphological endings are eliminated from English words. Here, the words are transformed to their stems or roots by applying a set of rules continuously. With this method, the number of features within the space vector can be reduced, while the speed of learning and process of categorization are increased for a wide range of classifiers. Nonetheless, two different words can stem from the same word when stemming is used [47].
Adaptive intelligent learning approach for multi-natural language 787
4.3.4 Stop word removal
The removal of the stop word is concerned with the deletion of common words with high frequency but less
meaning than the keywords. Emails contain many non-informative words like prepositions (e.g., “on,”
“inside”), articles (“the,” “an,” and “a”), and conjunctions (e.g., “but,” “for”), and the size of the vector
space increases by such words. When the vector space increases, it complicates the process of categoriza-
tion. During this process, a list of stop words is produced and is then compared with the vector space to map
the words to remove the list. Stop words make up about 5% of the texts in documents [1,47]. Table 6 shows
some common stop words.
Table 6: Different expressions of the stop words [47]
Couldn’t Hers Nor That’s We’re Yourselves
Between He Me Should Up You’d
Below Having Let’s She’s Until You
Been Hasn’t I’ve She To Won’t
At Had It’s Own This Why
Any Few Is Ours They’d While
And Each I’m Our They Which
Against Doing How’s Only Then When
A Did Herself Not The We’ve
As Further Into Over They’ve Whom
From Aren’t Some Wasn’t They’re Who’s
In Mustn’t He’s By Out You’ve
Table 6 contains a few of the stop words that are often used. Research shows that several other stop
words are eliminated at this stage. It is expected that the proposed system will demonstrate flexibility in
terms of adding and removing stop words.
4.3.5 Noise removal (regular expressions)
Noise in an email is the ambiguous words. The term obfuscation is characterized by the intentional mis-
spelling of words, space, or embedding of unique characters. For example, the word “Viagra” has been
obfuscated to “V1agra,” “V|iagra,” or free into “fr33.” The spammers use this technique so that the spam
filters do not identify such terms [1,46,47]. To differentiate the misspelled terms, the use of the regular
expression is employed in this process.
4.4 The agent feature presentation
This agent exhibits the features in the most suitable format to allow ML filtering. Normally, the features that
are obtained from the email are denoted as “bag of words” or vector space model. The representation of
lexical features is done in numeric or binary form. Suppose that a vector space model represents the
message as M = {M 1, M 2, M 3,…, Mn}vectors, where M 1 … M are the attribute values and the values
are binary (0 or 1); if the attribute value (M) = 0 mean the corresponding word(feature) is not present in
the message, if X1 =, otherwise M1 = 1. Here, the attributes are numerically represented, and X1 indicates
how frequently the feature appears in the email. For instance, if the word “Viagra” appears in the message,
then the feature will be assigned the value 1. Also, the character n-gram model is another representation of
the feature that is often used. With this method, the sequences of characters and term frequency–inverse788 Mazin Abed Mohammed et al.
document frequency (tf − idf) are obtained. The n-gram, also known as the co-occurring set of characters in
a word, is an n-character slice of a word.
Moreover, the constituents of n-gram include qua-gram, bi-gram, and trigram. The (tf − idf) is a
statistical measure with which the significance of a word to a document in feature corpus can be calculated.
Term frequency is used in establishing the frequency of words; the significance of the word to the document
can be determined from the number of times it occurs in the message. Then, the term frequency is multi-
plied with inverse document frequency (idf ), through which the frequency of the occurrence of the words in
all messages is measured [48].
4.5 Adaptive intelligent learning classification approach for virtual anti-spam
model
The classification in the adaptive intelligent learning classification model uses a Naive Bayes classification
algorithm adapted from ref. [1]; this algorithm is employed with three different phases of training and
testing. In the training phase, the agent uses sets of feature vectors that are used in training the classifier in
the previous phase. It includes K-fold cross-validation data allocations. The agent runs the classifier to
distinguish between legitimate emails and spam emails. The proposed virtual anti-spam framework
involves some phases and is explained in this section. The first phase is the training phase, in which the
novel anti-spam model is trained. The training is carried out in two parts – text training and image training.
The part for the text training entails training of text, according to the representation of the features, whereas
the part for image training entails training of images based on feature vector. In the image training part, the
agents have two sets from feature vectors, which are sets from the previous phase; one set contains
pornographic images, whereas the other set is made of non-pornographic images. These sets are saved
and used for training. The part for the text training involves using two sets from feature presentation, and
these sets are from the previous phase; one set comprises spam messages, whereas the other set contains
the legitimate text. The two sets are trained and saved as the dictionary. The second stage tests the novel
visual anti-spam. In the results, the presentations are classified as either legitimate text or spam.
5 Experimental results and evaluation
The adaptive intelligent agent learning classification model for virtual anti-spam model refers to an ML
model through which spam emails are identified using a multi-agent system. A JADE agent platform was
used in the Java environment to implement the proposed model. With this application, spam can be
detected and distinguished from legitimate emails by filtering. The identification accuracy in the testing
stage has been calculated by the summation the true positive (TP) and true negative (TN) of the legitimate
emails and phishing email and divide the outcome of the summation by the total numbers of the emails
(TP + FN + FP + TN) of the legitimate and phishing emails.
Accuracy = (TP + TN)/(TP + FN + FP + TN) (1)
Therefore, the representatives of false negatives (FNs) resulting from the that are classified as untrusted
terms and represents FPs resulting from the classified terms as denotes true positive that results from the
that are correctly identified; denotes TN that results from that are correctly identified. Research evaluation
can be objectively or subjectively described; in this study, the research is evaluated subjectively and
objectively. One of the biggest challenges in this field of research is the objective and subjective assessment
of anti-spam accuracy. The objective assessment involves determining anti-spam accuracy by calculating
given statistical indices based on whether the system can categorize emails successfully as either spam or
legitimate. The subjective evaluation depends on people’s opinions, whereas the objective evaluation is
based on the facts obtained from statistical calculations. Based on the test performed, the results ofAdaptive intelligent learning approach for multi-natural language 789
classification achieved by the proposed model are presented in Table 7. Three runs of the table show the
results of the proposed approach, which achieved high accuracy.
Table 7: The ten-fold cross-validation classification results
Run Emails for the folder Email sum FP FN Accuracy Precision F-measure Recall
1 20 100 0.02 5.15 97.1 99 96.1 95.4
2 40 200 0.02 4.93 97.3 99 96.4 95.8
3 80 400 0.05 4.17 97.6 99 96.9 96.2
4 150 800 0.05 3.89 97.8 99 97.3 96.5
5 250 1,500 0.07 3.05 98.1 99 97.4 96.7
6 350 2,000 0.08 2.90 98.4 98.1 97.65 96.9
As we mentioned earlier, ML techniques involve two main stages: the training stage and the testing
stage. The prediction precision of the classifiers depends exclusively on the data acquired amid the training
task; in case the data obtained are low, the prediction precision becomes low; however, on the off chance
that the data obtained are high, the classifier precision will be high. As expressed above, we utilized the ten-
fold cross-validation method. The Naive Bayes classifier sometimes creates a random forest, and the data
obtained for all the best features are computed utilizing the data obtained from the method explained by
Mitchell [49]. The features with the optimal data obtained are chosen and utilized for building the Naive
Bayes classifier. The mode of a vote for the Naive Bayes model is computed and utilized for the email
prediction process. The data extracted is one of the features ranking measured and highly utilized in
numerous text classification issues nowadays.
The details of our classifier method are described in the next subsection below. The testing of our
classifier approach, utilizing a large dataset size (as shown in Table 7), was done to know the execution of
the Naive Bayes classifier on both small and large databases. As shown in Table 7, the classifier performed
ideally while being tested on a database that has the biggest estimate (having a general accuracy of 98.4%,
an FN rate of 2.90%, and an FP rate of 0.08%). This observation suggests that our classifier algorithm will
work viably on the off chance that is connected to the real-world database, which is more often than not the
largest in measure. Naive Bayes classifier, moreover, accomplished high predictive accuracy (98.4%) com-
pared to the precision of 97% accomplished by Fette et al. [50]. As we can see, the proposed model can
identify the phishing email with an accuracy of 98.4%, and the experiment result has approved that the
proposed model can be used in real-time to detect spam emails. Classification result of Naive Bayes
classifier on the best features with a recent study is presented in Table 8.
Table 8: Classification result of Naive Bayes classifier on the best features with a recent study
Method FP FN Precision F-measure Recall
Fette et al. [50] 0.13 3.62 98.92 97.64 96.38
Our approach 0.08 2.90 99 97.65 96.90
The performance of the classifiers is evaluated based on the retrieval of information (in terms of
accuracy, precision, derived measures, and recall) and the decision theory (in terms of FNs and FPs).
The most relevant metrics that should be used to measure the performance of anti-spam include spam
detection accuracy, spam precision, and recall. The recall indicates the number of spams that are classified
correctly against those that are wrongly classified as a legitimate email, along with the number of spams
that are recognized as spam. Precision indicates the proportion of the number of spams that are classified790 Mazin Abed Mohammed et al.
correctly to the number of all images or texts that are labeled as spam. Accuracy is defined as the ratio of the
number of spams that are correctly classified and legitimate emails to the total number of images or texts
used for testing, i.e., all images and texts that have been classified correctly by the classifier [47]. The
following equations can be used for calculating the aforementioned parameters:
Recall = TP /(TP + FN) (2)
Precision = TP /(TP + FP) (3)
FNs refer to spam images or messages that have been wrongly classified as legitimate messages, while
FPs refer to a legitimate message that has been wrongly classified as a spam message. TP refers to spam
images or messages that have been correctly predicted as spam, while on the other hand, TN refers to the
number of messages or images that are legitimate and correctly detected legitimate.
As stated earlier, the subjective evaluation method is the second type of evaluation used in this study to
evaluate the output, to determine if the visual anti-spam could successfully distinguish between spam and
legitimate emails. The main reason for using the subjective evaluation is that the opinion of experts
regarding the performance of the visual anti-spam can be gathered. Humans interpret things very differ-
ently from the way a machine does because the interpretation of humans is universal and subjective. For
instance, a good result may be achieved by an objective quality criterion, but the same result may not be
good for human interpreters. Additionally, the subjective method is used continuously to measure the
quality of application research, particularly in this study, because humans can naturally detect spam
with higher accuracy than machines. For example, when a subjective evaluation is performed, viewers’
attention is on the differences between the original message and the images or messages that have been
reconstructed. Herein, loss of information can be observed, which cannot be accepted as a result of mis-
interpretation by the machine. Thus, the quality of the visual anti-spam can be rated by viewers so that the
performance of the system can be determined in terms of its accuracy in distinguishing between spam and
non-spam.
6 Conclusion
Spam emails have become a genuine risk to security and the economy worldwide. Increasing the number of
phishing emails has made the issue more complex and updating the blacklist becomes almost impossible.
Thus, in this study, we have displayed a content-based spam email detection method, which has bridged
the current gap distinguished within the previous studies. This study shows how an adaptive intelligent
learning approach, based on the visual anti-spam model for multi-natural language, can be used to detect
unusual situations effectively. This approach is used for spam filtering. With adaptive intelligent learning,
high performance is achieved, along with a low rate of false detection. The result of our study, as presented,
suggests that the classifier performed ideally while testing on the database that has the biggest estimate
(having a general accuracy of 98.4%, an FN rate of 2.90%, and an FP rate of 0.08%). This observation also
suggests that our classifier algorithm will work viably on the off chance that is connected to a real-world
database, which is more often than not the largest in measure. For future works, the suggestion is to
enhance our study by combining this approach with nature-inspired methods such as particle swarm
optimization or ant colony optimization that can dynamically and automatically distinguish the finest
spam emails. Thus, this approach can be utilized to construct a robust spam email detection system
with the highest classification accuracy. The utilization of this model and approach will improve the
predictive accuracy of the classifiers used for the effective identification of spam emails that rely on
spam email features.
Conflict of interest: Authors state no conflict of interest.You can also read

















































