Deep Interpretable Models of Theory of Mind For Human-Agent Teaming
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Deep Interpretable Models of Theory of Mind
For Human-Agent Teaming
Ini Oguntola, Dana Hughes, and Katia Sycara
Abstract— When developing AI systems that interact with mental state, such as reward [6] or rationality [9], more
humans, it is essential to design both a system that can complex models incorporating multiple properties of mental
understand humans, and a system that humans can understand. state (e.g., beliefs over the environment, desires, personality
Most deep network based agent-modeling approaches are 1)
not interpretable and 2) only model external behavior, ignoring characteristics, etc.) in non-toy environments remains largely
internal mental states, which potentially limits their capability unexplored.
arXiv:2104.02938v1 [cs.LG] 7 Apr 2021
for assistance, interventions, discovering false beliefs, etc. To this While modeling ToM of a human is a very challenging
end, we develop an interpretable modular neural framework task for an artificial AI agent, understanding the reasoning of
for modeling the intentions of other observed entities. We such an agent is even more challenging. This paper focuses
demonstrate the efficacy of our approach with experiments on
data from human participants on a search and rescue task on developing human-interpretable ToM models. If a ToM
in Minecraft, and show that incorporating interpretability can model can both infer human mental states and produce
significantly increase predictive performance under the right human-interpretable explanations for its inferences, this 1)
conditions. develops trust with humans it interacts with 2) better enables
I. INTRODUCTION the agent to choose and justify interventions. In addition,
interpretable ToM models would allow system designers to
Human intelligence is remarkable not just for the way it better understand the reasoning and inferences of such an
allows us to navigate environments individually, but also how agent observing and giving advice to humans executing a
it operates socially, engaging with other intelligent actors. task.
Humans naturally build high-level models of those around We perform experiments with human trajectories obtained
them, and are able to make inferences about their beliefs, de- from simulated search and rescue tasks in a Minecraft
sires and intentions (BDI) [1]. These inferences allow people environment, and find that enforcing interpretability can also
to anticipate the behaviors of others, use these predictions to increase predictive accuracy under the right conditions.
condition their own behavior, and then anticipate potential The primary contributions of this paper are the following:
responses.
• We design a modular framework to enable AI agents to
In both psychology and machine learning this is referred
to as theory of mind (ToM) [2], [3], [4], which aims to model have a theory of mind model of a human.1
• We present a method of combining neural and non-
not only the external behavior of other entities but their
internal mental states as well. The developmental psychology differentiable components within our framework.
• We extend this framework for interpretable intent pre-
literature has found that children as young as 4 years old
have already developed a ToM, a crucial ability in human diction with a novel application of concept whiten-
social interaction [5]. ToM can enable discovery of false ing [10].
• We present experimental results with human partic-
or incomplete beliefs and knowledge and can thus facilitate
interventions to correct false beliefs. Therefore, work in ipants and provide both qualitative and quantitative
enabling agents to develop ToM is a crucial step not only in interpretability analyses.
developing more effective multi-agent AI systems but also II. RELATED WORK
for developing AI systems that interact with humans, both
cooperatively and competitively [4]. A. Theory of Mind
With a few exceptions [6], most agent-modeling ap- Theory of mind approaches to agent-modeling have shown
proaches in the reinforcement learning and imitation learning to make inferences that align with those of human observers
literature largely ignore these internal mental states, usually [2]. Early approaches infer human goals and beliefs in
only focusing on reproducing the external behavior [7], [8]. the context of planning with pre-programmed non-scalable
This limits their ability to reason in a deeper way about approaches [11], [12]. Bayesian approaches to ToM [2] are
entities that they interact with. While prior work has explored also difficult to scale to larger environments. Rabinowitz
providing agents with models of some aspect of a human’s et al. used neural networks to learn latent representations
of “mental states”, but only for artificial agents in small
* All authors are with the School of Computer Science, Carnegie
Mellon University, Pittsburgh, PA, USA (ioguntol, danahugh, toy environments [3]. Other work concurrent to this paper
katia)@cs.cmu.edu
* This work is supported by the Defense Advanced Research Projects 1 Our method is general and supports both humans and artificial agents
Agency (DARPA) under Contract No. HR001120C0036, and by the AFR- as observed entities. However, since our experimental evaluation is on
L/AFOSR award FA9550-18-1-0251. human data, we only refer to a human as the entity being observed.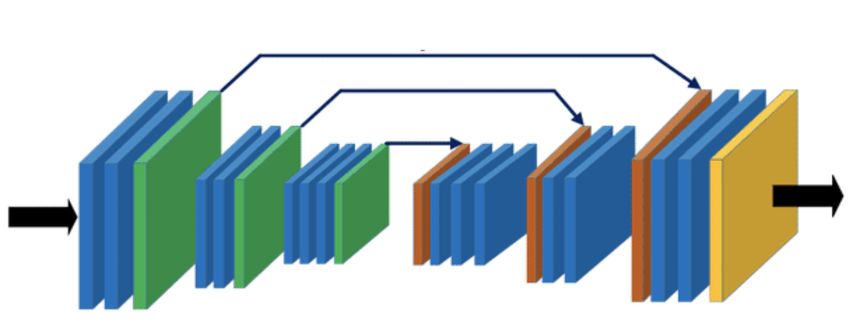
has explored theory of mind modeling of human state and
behavior with graph-theoretic approaches for scenarios such
as autonomous driving [13].
This paper presents a neural ToM approach that supports
reasoning about humans, and provides experimental results
within a complex, realistic environment. In addition, we
explicitly incorporate interpretability into our approach while
still maintaining the performance and scalability benefits of
neural approaches.
B. Imitation Learning
Theory of mind is closely related to imitation learning
and inverse reinforcement learning in that both attempt to
model other agents, and both can be applied to model either
human or artificial agents [14]. Although most imitation
learning methods do not consider interpretability, there are
approaches such as InfoGAIL that take a heuristic approach
towards interpretability by using information theoretic losses
to enforce structure on the latent space and discover modes Fig. 1: Modular theory of mind (ToM) framework.
in observed behavior [15]. Others use human-readable pro-
grammatic polices for agent-modeling rather than black-box
deep networks [16]. III. NEURAL T O M FRAMEWORK
The approach presented in this paper falls under the A. Purpose
umbrella of behavioral cloning [17], [18], with additional
It is important to note that the ToM framework is used by
constraints for modeling internal states via theory of mind
an observer to infer mental states of an observed entity, and
and for interpretable learning.
is not specifically to define the external behavior. The action
C. Deep Interpretability predictions produced by the ToM model can be treated as a
policy to forecast an observed entity’s future behavior, and
Saliency-based methods [19], [20], [21], [22], [23] are
imitation learning can provide a training signal for the ToM
the most popular means of providing post-hoc explanations,
model, but our purpose is not to train an agent to perform a
and aim to highlight the most important input features
task.
by assigning importance weights. However, many common
saliency methods have been found to be independent of both B. Overview
the model and the data, and often have similar resulting
explanations for all inputs, which is undesirable [24], [25]. We developed a modular theory of mind framework for
While saliency maps have also been applied in reinforcement an observing agent to use to infer the mental state of an
learning contexts [26], [27], operating on low-level input observed human. The modules in our network impose an
features (e.g. raw pixels) may not coincide with human ideas inductive bias that reflects the BDI model of agency in folk
of explanation. psychology [1]. Modularizing the framework in this way
Concept-vector post-hoc methods focus on explanations allows for combining heuristic and data-driven components
based on higher-level concepts rather than low-level input (e.g., neural networks). Specifically, we model the decision
features [28], [29], [30], but these also have their own making process of an observed entity as follows:
drawbacks. In general, most post-hoc explanations are based 1) Observations from the environment update a belief
on assumptions of the latent space that may not hold; state (belief model)
for instance, the implicit assumptions that 1) concepts are 2) Given the current trajectory, calculate an intent (desire
(linearly) separable in the latent space, and that 2) each axis model)
in the latent space only represents a single concept. 3) Finally, we predict/generate an action given the belief
Alternatively, others have devised approaches such as state and intent (action model)
concept whitening that focus on learning models that are
interpretable by design [25], [31], [10], i.e. approaches that C. Combining Differentiable and Heuristic Components
shape the latent space during training. These methods have If all three models are differentiable (e.g. neural networks),
been used in classification tasks, e.g. in image classifica- we can train this pipeline end to end with imitation learning
tion for aligning the latent space with predefined human- methods such as behavioral cloning [18] or GAIL [32], [15].
interpetable concepts. In contrast to these approaches, this However, often the action alone is not a strong enough signal
paper develops a variation of concept whitening [10] for to train a model that generalizes well, especially when the
modeling decision-making processes (e.g. theory of mind, overall goal is to model variation in mental states from
imitation learning, reinforcement learning). different entities (e.g. theory of mind).We can mitigate this difficulty by imposing additional
structure on the pipeline. The simplest ways to do this are to
replace one or more of the models with rule-based models,
and/or to impose structural constraints on the input/output
space of these models. For instance, given a planning task we
can structure the belief state as a grid/graph of locations, and
use a rule-based belief model to update this belief state given
an observation. Additionally, we could replace the action
model with A* search [33], and structure the intents from Fig. 2: Encoder-decoder architecture used for the desire and
the desire model as locations of subgoals. inverse-action models in our experiments, inspired by U-Nets
In the setup described above, the belief and action models for image-segmentation [34]. Blue indicates convolutional
are rule-based, and the desire model is the sole trainable layers, green indicates pooling, brown indicates up-sampling,
component. The rule-based belief model does not pose any and yellow is a final linear layer. A more detailed description
issue (one can think of it as simply preprocessing the input can be found in the appendix.
observation). However, we cannot optimize for the final
output in any gradient-based way, as the output of the desire
model is the input to the non-differentiable action model,
creating a dataset of belief-action-intent triples. Finally, we
which produces the final output. And unless we have ground-
train the inverse action model on this dataset to predict
truth intents, we cannot train the desire model in a directly
intents given beliefs and actions.
supervised manner.
Pseudocode for this training process is provided in Algo-
Given belief state b ∈ B, observed action a ∈ A, a set of
rithm 1.
intents I, and non-differentiable action model f : B × I →
2) Training Desire Model: To train the desire model, we
A, we want to learn a desire model g to model a conditional
first collect belief states by running the observations from
distribution p(z | b) such that
human trajectories through the belief model. We also store
E[a | b] = Ez∼g(b) [f (b, z) | b] the corresponding observed actions for each belief state.
We can then generate belief-intent pairs for the desire
where z ∈ I is the intent. However, we may not have access model by sampling intents from our inverse action model
to any samples from such a distribution (i.e. no ground truth z ∼ h(b, a) for each belief-action pair. The target intents are
z ∈ I for given b, a pairs). formed by combining a) the probability distribution from
Alternatively, we can learn to model the distribution the inverse action model over the previous belief state, and
p(z | b, a) with an “inverse action model” h. This density if available b) the next realized intent (from the future, in a
of this distribution is proportional to post-hoc manner).
p(z | b, a) ∝ p(a, z | b) = p(a | b, z) · p(z | b) (1) Finally we train the desire model on this data to predict
intent given belief.
Because we have direct access to f we can sample from Pseudocode for this training process is provided in Algo-
p(a | b, z), and thus given some kind of prior p(z | b) we rithm 2.
can sample from p(z | b, a) to learn h.
Once we have learned an inverse action model h, then
Algorithm 1: Training inverse action model
for each belief-action pair (b, a) we can then simply use h
to sample intents from p(z | b, a), and use these sampled Input: set of human trajectories T = {τ1 , τ2 , . . . },
intents to train the desire model g in a supervised manner. belief model s, action model f
Dbaz → ∅
D. Training for τ ∈ T do
o1 , . . . , o n → τ
Training is done in two stages: the first stage trains the
b0 → Uniform
inverse action model, the second stage trains the desire
for t = 1, . . . , n do
model. In each stage, once we gather the necessary data,
bt → s(bt−1 , ot )
we train using stochastic gradient descent (SGD).
for i = 1, . . . , m do
1) Training Inverse Action Model: To train the inverse zt ∼ p(z | bt )
action model, we first collect belief states by sequentially a = f (bt , zt )
running observations from human trajectories through the Dbaz = Dbaz ∪ {(bt , a, zt )}
rule-based belief model and storing the resulting belief states end
at each timestep. These trajectories can be from human end
participants or potentially even from artificial agents trained end
to perform the task. Initialize neural network parameters θh
Then for each belief state b, we sample an intent z given Use SGD to train h(b, a | θh ) on Dbaz
some prior p(z | b), and create a set of b, z pairs. Next, for
each belief-intent pair, we generate an action a = f (b, z),Algorithm 2: Training desire model Q, we maximize the following objective:
Input: set of human trajectories T = {τ1 , τ2 , . . . }, k
belief model s, inverse action model h
X 1 X
max q>
j ẑxcj (4)
Dbz → ∅ q1 ...qk n
j=1 j xcj ∈Xcj
for τ ∈ T do
(o1 , a1 ), . . . , (on , an ) → τ where ẑxcj denotes the concept-whitened latent representa-
b0 → Uniform tion in the model on a data sample from concept cj . Orthog-
for t = 1, . . . , n do onality can be maintained when optimization is performed
bt → s(bt−1 , ot ) via gradient descent and curvilinear search on the Stiefel
zt ∼ h(bt , at ) manifold [36].
Dbz = Dbz ∪ {(bt , zt )} A more detailed description of concept whitening and the
end optimization algorithm can be found in [10].
end
Initialize neural network parameters θg
B. Concept Whitening for Intent Prediction
Use SGD to train g(b | θg ) on Dbz
We can modify this idea to the context of explanatory
concepts for intent prediction. Specifically, we consider the
desire model (Fig. 2) and insert a concept whitening layer
IV. CONCEPT WHITENING (for more detail see the appendix and Fig. 3).
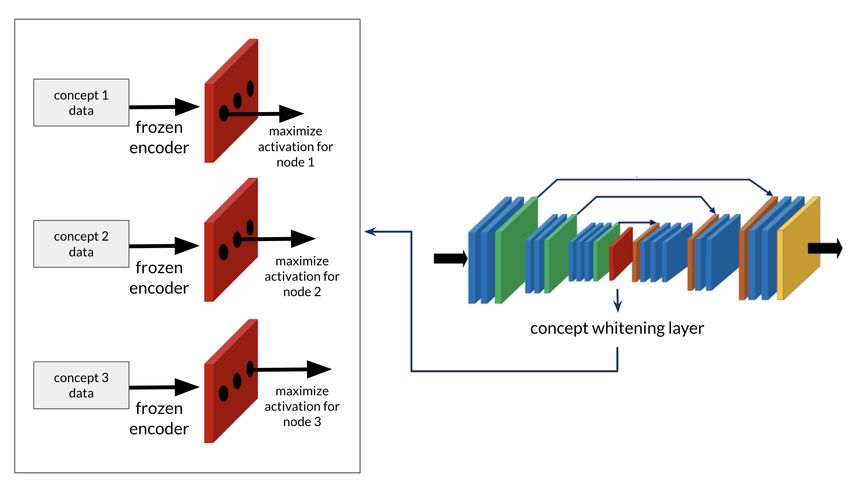
Concept whitening (CW) is a mechanism introduced by First we define a set of concepts C = {c1 , . . . , ck };
Chen et al. [10] for modifying neural network layers to these concepts should correspond to appropriate human-
increase interpretability. Broadly, it aims to enforce structure interpretable reasons or “explanations” for intent prediction
on the latent space by aligning the axes with predefined given the problem domain. We also must be able to identify a
human-interpretable concepts. While this technique was de- subset of timesteps from our trajectories where each concept
veloped for the purpose of image classification, here we applies, either directly from the trajectory data, or from
adapt the idea in the context of intent prediction with the external labels.
desire model. By explicitly defining a set of concepts that Recall that the desire model’s inputs are belief states,
can serve as “explanations” for intent predictions, we can which we can generate sequentially by passing the observa-
use concept whitening to allow for interpretability via iden- tions from each trajectory timestep through the belief model.
tification of the most important concepts for any prediction. Then for each concept cj we consider only the belief states
We also note that although we consider concept whitening from the timesteps where cj is known to apply, and aggregate
in the context that can broadly be categorized as behavioral them into auxiliary dataset Bcj .
cloning, our approach to interpretable agent-modeling is Then training alternates between:
framework agnostic and could potentially be applied to other 1) Optimizing for intent prediction, given a belief state
reinforcement learning and imitation learning contexts. and a ground truth intent
2) Concept-aligning the CW orthogonal matrix Q by
A. Technical Details maximizing the activation along axis j for each auxil-
Given latent representation Z ∈ Rn×d , let ZC ∈ Rn×d iary dataset Bcj
be the mean-centered latent representation. We can calculate Pseudocode for this process is provided in Algorithm 3.
the ZCA-whitening matrix W ∈ Rd×d as in [35], and thus
decorrelate and standardize the data via whitening operation V. EXPERIMENTS
ψ:
A. Task
ψ(Z) = WZC = W(Z − µ1> ) (2)
n
We consider a simulated search and rescue task in a
where µ = n1 i=1 zi is the latent sample mean.
P
Minecraft environment. The scenario simulates a damaged
Now say we are given concepts c1 . . . ck that can be char- building after a disaster, with areas of the building layout
acterized by corresponding auxiliary datasets Xc1 . . . Xck , perturbed with collapsed rubble, wall openings, and fires.
and assume we have an orthogonal matrix Q ∈ Rd×d such There are 34 injured victims within the building who will
that the data from Xcj has high activation on the j-th axis die if left untreated. For convenience and simplicity, victims
(i.e. column qj ). Then the concept-whitened representation are represented as blocks. Out of these victims, 10 of these
is given by: are critically injured and will expire after 5 minutes. These
Ẑ = Q> WZC (3) critical victims take 15 seconds to triage and are worth 30
points. Other victims are considered “non-critical”, but will
Training alternates between optimizing for the main ob- expire after 10 minutes. Non-critical victims take 7.5 seconds
jective (i.e. with the network’s final output) and optimizing to triage and are worth 10 points. The goal of the task is to
the orthogonal matrix Q for concept-alignment. To optimize earn as many points as possible within a 10 minute mission.Fig. 3: Desire model with concept whitening.
Algorithm 3: Training desire model with concept Participants were assessed under 3 knowledge conditions:
whitening 1) No knowledge of critical-victim tradeoff, no knowl-
D→∅ edge of signal meaning
for τ ∈ T do 2) Knowledge of critical-victim tradeoff but not of signal
(o1 , a1 ), . . . , (on , an ) → τ meaning
b0 → Uniform 3) Knowledge of both critical-victim tradeoff and signal
for t = 1, . . . , n do meaning
bt → BM(bt−1 , ot )
zt ∼ IAM(bt , at ) C. Intent Prediction
D = D ∪ {(bt , zt )} We represent intents as (x, y) positions the participant in-
end tends to navigate towards. Specifically, we consider victims,
end doors, and room openings as locations-of-interest, which
for e = 1, ..., num epochs do frames the intent prediction task as predicting either the next
Train DM on D with gradient descent room to be visited or the next victim to be triaged. The
if e mod 5 = 0 then predictions are accumulated at each timestep (∼ 0.5 seconds
for j = 1, ..., k do per timestep) between visits of locations-of-interest, and then
Maximize activation of Bcj on the j-th their mode is evaluated against the ground truth. We evaluate
column of Q (see [10]) on a held-out test set of 20% of participant trajectories.
end
end D. Concepts
end We defined a set of 10 concepts related to mission timer,
knowledge condition, and field of view (see Table I). We
consider 3 subsets:
B. Human Data For Training and Evaluation • Concept Set I is the full concept set
All experiments are performed using a set of 75 trajecto- • Concept Set II omits the knowledge condition concepts
ries previously collected from human participants [37]. Prior • Concept III omits both knowledge condition and mis-
to each mission, participants were given information on the sion timer concepts
task and the original building layout. However, the knowl-
edge conditions of certain participants were manipulated by TABLE I: Concepts
partially withholding information. Some participants were Concept Concept Sets
not informed of the cost-benefit tradeoffs (i.e. the knowledge Mission timer between 0-3 minutes I, II
that critical victims take 15 seconds to rescue and are worth Mission timer between 3-5 minutes I, II
Mission timer between 5-8 minutes I, II
30 points and non-critical victims take 7.5 seconds to rescue Mission timer > 8 minutes I, II
and are worth 10 points). Knowledge was also manipulated Knowledge condition 1 (no triage, no signal) I
via a beep signal that activated whenever the participant was Knowledge condition 2 (triage, no signal) I
Knowledge condition 3 (triage, signal) I
near a room with a victim (1 beep for non-critical victim, 2 Door / opening in field of view I, II, III
beeps for critical victim); certain participants were not told Non-critical victim in field of view I, II, III
the meaning of the signal. Critical victim in field of view I, II, IIIThe field of view and mission timer concepts were labeled (CW + transfer, full concept set). The mean normalized
directly from the data; the knowledge condition concepts are activations for non-critical victims, critical victims, and doors
labeled with external knowledge of the condition for each / openings are visualized in Fig. 4.
participant trajectory. These largely line up with intuition; unsurprisingly, the
presence of an intent in the field of view is an important
E. Results
concept for the model’s prediction of said intent. We also
We compare the accuracy of ToM model intent predictions see variability in the importance of different mission time
under 3 methods: training without CW, training from scratch intervals for different intent predictions, and similarly for
with CW, and transfer learning by initializing a CW model knowledge condition.
with the weights of a pretrained non-CW model. Results are
provided in Table II, where we see that introducing concept B. Quantitative Analysis
whitening for interpretability actually results in increased We also attempt to quantitatively assess how well the
accuracy of the model. concept activation vectors characterize the ToM model’s
intent predictions. Intuitively, we should be able to deduce
TABLE II: Intent Prediction Performance information about what the model’s prediction will be with
high accuracy, using only concept activation vectors as input.
Training Method Intent Prediction Accuracy
Without CW 0.730 This can be framed as a classification problem where,
CW 0.840 given an activation vector, we predict the type of the cor-
CW + Transfer 0.841 responding predicted intent as one of: non-critical victim,
critical victim, or door / opening. Rather than use a complex
model, we can learn a decision tree or SVM, and use
F. Concept Ablation the accuracy as a proxy for the quality of our concept
We also tested the effect of concept selection on perfor- activations. As shown in Table IV, we achieve relatively
mance (Table III). In particular, we omitted the knowledge high accuracies with simple models, which suggests that our
condition (KC) concepts and / or the mission timer concepts, learned concept activations are a good characterization of the
tested concept-whitened ToM models both with and without “decision making process”.
transfer, and found noticeably diminished performance.
Compared to the non-CW model, CW with reduced con- TABLE IV: Classifiying Activations as Intents
cept sets resulted in worse performance, and while transfer
Model Accuracy
from the non-CW model somewhat mitigated this effect, Decision Tree 0.93
we still see a significant drop from the performance with SVM 0.92
full concept set. This demonstrates the importance of good
concept selection for the resulting performance of concept-
whitened ToM model. VII. CONCLUSION
TABLE III: Varying Concept Sets We have presented a modular ToM approach for rea-
soning about humans that can allow for both neural and
Training Method Concept Set Acc. heuristic components. Our approach explicitly incorporates
Without CW N/A 0.730
CW III 0.412 interpretability while still maintaining the performance and
CW II 0.692 scalability advantages of neural approaches. We move be-
CW I 0.840 yond simple toy environments and apply our framework to a
CW + Transfer III 0.549
CW + Transfer II 0.779 more complex, realistic setting, and our experimental results
CW + Transfer I 0.841 demonstrate that enforcing interpretability can also increase
predictive accuracy.
The natural extension of this work is in exploring the
VI. INTERPRETABILITY ANALYSIS benefits of ToM and interpretability in assistance and in-
terventions. A particularly interesting direction would be
A. Qualitative Analysis to explore counterfactuals; that is, examining how intent
We can estimate the concept importance for each predic- prediction changes given a change in concept activation,
tion via the activation for each column of the CW orthogonal and then finding the closest belief state that could result
matrix Q, given by: in the given change. Approaching this through interpretable
concept activations rather than in the belief space could
aj = q>
j ẑb (5)
facilitate interventions to warn about or correct human errors
where ẑx is the concept-whitened latent representation for when working in Human + AI teams.
belief state b. We hope that this work can serve as a starting point for
We can examine the activation vectors a = [a1 . . . ak ] for working towards social intelligence in AI systems that are
different types of intent predictions by the learned model designed to interact with humans.APPENDIX
A. Implementation Details
We consider Minecraft environments that can effectively
be collapsed to 2D representations. The specification for each
of the framework components is given below.
Observations: Observations are represented X × Y
grids, where each (x, y) coordinate contains one of K
different block types.
Belief States: Each belief state b is represented by a
X × Y × K grid, where the value at (x, y, k) represents the
probability of the block at position (x, y) having block type
k.
Belief Model: We use a rule-based belief model that
(a) Mean concept activation for intent prediction of non-critical aggregates observations into our belief state with probability
victim. We can see that the presence of a non-critical victim in the 1, and decay probabilities over time to a uniform distribution
field-of-view is the most activated concept. b+
over block types by b → 1+K after each timestep, where b
is a belief state grid, K is the number of block types, and
is a forgetfulness hyperparameter we set to 0.01.
Intents: We represent each intent as an (x, y) position
the player intends to navigate towards.
Intent Prior: When generating data to train the inverse
action model, for each belief state b, we sample an intent
(x, y) given some prior p(x, y | b), and create a set of
b, (x, y) pairs. We specifically use the prior p(x, y | b) =
1
db (x,y) if we belief a victim or door is at position (x, y),
and 0 otherwise, where db (x, y) is the L1 distance of point
(x, y) from the player’s position.
Action Model: We use A* search as our action model,
A∗ (b, (x, y)) = a, where b is a belief state, (x, y) rep-
(b) Mean concept activation for intent prediction of critical victim. resents the intent, and a is an action from discrete ac-
Here we see zero activation for mission timer above 5 minutes tion set of: left turn, right turn, toggle door,
(which corresponds with critical victims expiring). We also see that toggle lever, triage, or None.
the presence of a critical victim or room opening in field-of-view
is a common reason for predicting intent to triage a critical victim. B. Neural Architectures
Inverse Action Model: The inverse action model takes
as input a belief state b and an action a. It outputs an X × Y
grid of log-probabilities for the intent at each grid cell. It is
designed as an encoder-decoder model, inspired by image-
segmentation approaches, and uses the following architecture
(Fig 2):
• 3 encoder blocks each consisting of a convolutional
layer, followed by max-pooling, ReLU activation and
batch norm
• A bottleneck layer, where the downsampled input is
concatenated with action a and passed through a fully-
connected layer
• 3 decoder blocks each consisting of:
(c) Mean concept activation for intent prediction of opening. The
– a deconvolutional upsampling layer
presence of an opening in the field of view is the most highly
activated concept. We also see that compared to the other mission – a residual connection with the output of the corre-
timer concepts, the last 2 minutes sees the timer become a more sponding encoder block
important reason for predicting intent to go towards a door or – a convolutional layer, followed by ReLU activation
opening. and batch norm
Fig. 4: Mean concept activations for different intent predic- Desire Model: The desire model takes as input a belief
tion types. state b and a character embedding c. It outputs an X × Y
grid of log-probabilities for the intent at each grid cell.
Its architecture (Fig 2) is identical to that of the inverseaction model, except without concatenating the action in [20] D. Smilkov, N. Thorat, B. Kim, F. Viégas, and M. Wattenberg,
the bottleneck layer. When training concept whitening, we “Smoothgrad: removing noise by adding noise,” arXiv preprint
arXiv:1706.03825, 2017.
replace batch normalization after the bottleneck layer with a [21] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and
concept whitening layer. D. Batra, “Grad-cam: Visual explanations from deep networks via
gradient-based localization,” in Proceedings of the IEEE international
R EFERENCES conference on computer vision, 2017, pp. 618–626.
[22] M. T. Ribeiro, S. Singh, and C. Guestrin, “” why should i trust you?”
[1] M. Georgeff, B. Pell, M. Pollack, M. Tambe, and M. Wooldridge, “The explaining the predictions of any classifier,” in Proceedings of the 22nd
belief-desire-intention model of agency,” in International workshop on ACM SIGKDD international conference on knowledge discovery and
agent theories, architectures, and languages. Springer, 1998, pp. 1– data mining, 2016, pp. 1135–1144.
10. [23] S. M. Lundberg and S. Lee, “A unified approach to interpreting model
[2] C. Baker, R. Saxe, and J. Tenenbaum, “Bayesian theory of mind: predictions,” in Advances in Neural Information Processing Systems
Modeling joint belief-desire attribution,” in Proceedings of the annual 30: Annual Conference on Neural Information Processing Systems
meeting of the cognitive science society, vol. 33, 2011. 2017, December 4-9, 2017, Long Beach, CA, USA, I. Guyon, U. von
[3] N. Rabinowitz, F. Perbet, F. Song, C. Zhang, S. A. Eslami, and Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan,
M. Botvinick, “Machine theory of mind,” in International conference and R. Garnett, Eds., 2017, pp. 4765–4774.
on machine learning. PMLR, 2018, pp. 4218–4227. [24] J. Adebayo, J. Gilmer, M. Muelly, I. J. Goodfellow, M. Hardt, and
[4] F. Cuzzolin, A. Morelli, B. Cirstea, and B. J. Sahakian, “Knowing me, B. Kim, “Sanity checks for saliency maps,” in Advances in Neural
knowing you: Theory of mind in ai,” Psychological medicine, vol. 50, Information Processing Systems 31: Annual Conference on Neural
no. 7, pp. 1057–1061, 2020. Information Processing Systems 2018, NeurIPS 2018, December 3-
[5] J. W. Astington and M. J. Edward, “The development of theory of mind 8, 2018, Montréal, Canada, S. Bengio, H. M. Wallach, H. Larochelle,
in early childhood,” Encyclopedia on early childhood development, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., 2018, pp. 9525–
vol. 14, pp. 1–7, 2010. 9536.
[6] R. Choudhury, G. Swamy, D. Hadfield-Menell, and A. D. Dragan, [25] C. Rudin, “Stop explaining black box machine learning models for
“On the utility of model learning in hri,” in 2019 14th ACM/IEEE high stakes decisions and use interpretable models instead,” Nature
International Conference on Human-Robot Interaction (HRI). IEEE, Machine Intelligence, vol. 1, no. 5, pp. 206–215, 2019.
2019, pp. 317–325. [26] R. Iyer, Y. Li, H. Li, M. Lewis, R. Sundar, and K. Sycara, “Trans-
[7] J. N. Foerster, R. Y. Chen, M. Al-Shedivat, S. Whiteson, P. Abbeel, parency and explanation in deep reinforcement learning neural net-
and I. Mordatch, “Learning with opponent-learning awareness,” in works,” in Proceedings of the 2018 AAAI/ACM Conference on AI,
Proceedings of the 17th International Conference on Autonomous Ethics, and Society, 2018, pp. 144–150.
Agents and MultiAgent Systems, AAMAS 2018, Stockholm, Sweden, [27] R. M. Annasamy and K. Sycara, “Towards better interpretability in
July 10-15, 2018, E. André, S. Koenig, M. Dastani, and G. Sukthankar, deep q-networks,” in Proceedings of the AAAI Conference on Artificial
Eds. International Foundation for Autonomous Agents and Multiagent Intelligence, vol. 33, no. 01, 2019, pp. 4561–4569.
Systems Richland, SC, USA / ACM, 2018, pp. 122–130. [28] B. Kim, M. Wattenberg, J. Gilmer, C. Cai, J. Wexler, F. Viegas,
[8] Y. Wen, Y. Yang, R. Luo, J. Wang, and W. Pan, “Probabilistic recursive et al., “Interpretability beyond feature attribution: Quantitative testing
reasoning for multi-agent reinforcement learning,” in 7th International with concept activation vectors (tcav),” in International conference on
Conference on Learning Representations, ICLR 2019, New Orleans, machine learning. PMLR, 2018, pp. 2668–2677.
LA, USA, May 6-9, 2019, 2019. [29] B. Zhou, Y. Sun, D. Bau, and A. Torralba, “Interpretable basis
decomposition for visual explanation,” in Proceedings of the European
[9] R. Shah, N. Gundotra, P. Abbeel, and A. Dragan, “On the feasibility
Conference on Computer Vision (ECCV), 2018, pp. 119–134.
of learning, rather than assuming, human biases for reward inference,”
[30] A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards auto-
in International Conference on Machine Learning. PMLR, 2019, pp.
matic concept-based explanations,” in Advances in Neural Information
5670–5679.
Processing Systems 32: Annual Conference on Neural Information
[10] Z. Chen, Y. Bei, and C. Rudin, “Concept whitening for interpretable
Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Van-
image recognition,” Nature Machine Intelligence, vol. 2, no. 12, pp.
couver, BC, Canada, H. M. Wallach, H. Larochelle, A. Beygelzimer,
772–782, 2020.
F. d’Alché-Buc, E. B. Fox, and R. Garnett, Eds., 2019, pp. 9273–9282.
[11] J. Oh, F. Meneguzzi, and K. Sycara, “Probabilistic plan recognition
[31] P. W. Koh, T. Nguyen, Y. S. Tang, S. Mussmann, E. Pierson, B. Kim,
for proactive assistant agents,” Plan, activity, and intent recognition.
and P. Liang, “Concept bottleneck models,” in International Confer-
Elsevier, Amsterdam, The Netherlands, vol. 10, p. 23, 2014.
ence on Machine Learning. PMLR, 2020, pp. 5338–5348.
[12] J. Oh, F. Meneguzzi, K. Sycara, and T. J. Norman, “Prognostic nor-
[32] J. Ho and S. Ermon, “Generative adversarial imitation learning,” in
mative reasoning,” Engineering Applications of Artificial Intelligence,
NIPS, 2016.
vol. 26, no. 2, pp. 863–872, 2013.
[33] P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the
[13] R. Chandra, A. Bera, and D. Manocha, “Stylepredict: Machine theory
heuristic determination of minimum cost paths,” IEEE transactions on
of mind for human driver behavior from trajectories,” arXiv preprint
Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968.
arXiv:2011.04816, 2020.
[34] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional
[14] J. Jara-Ettinger, “Theory of mind as inverse reinforcement learning,” networks for biomedical image segmentation,” in International Confer-
Current Opinion in Behavioral Sciences, vol. 29, pp. 105–110, 2019. ence on Medical image computing and computer-assisted intervention.
[15] Y. Li, J. Song, and S. Ermon, “Infogail: interpretable imitation learning Springer, 2015, pp. 234–241.
from visual demonstrations,” in Proceedings of the 31st International [35] L. Huang, Y. Zhou, F. Zhu, L. Liu, and L. Shao, “Iterative nor-
Conference on Neural Information Processing Systems, 2017, pp. malization: Beyond standardization towards efficient whitening,” in
3815–3825. Proceedings of the IEEE/CVF Conference on Computer Vision and
[16] A. Verma, V. Murali, R. Singh, P. Kohli, and S. Chaudhuri, “Pro- Pattern Recognition, 2019, pp. 4874–4883.
grammatically interpretable reinforcement learning,” in International [36] Z. Wen and W. Yin, “A feasible method for optimization with orthog-
Conference on Machine Learning. PMLR, 2018, pp. 5045–5054. onality constraints,” Mathematical Programming, vol. 142, no. 1, pp.
[17] M. Bain and C. Sammut, “A framework for behavioural cloning.” in 397–434, 2013.
Machine Intelligence 15, 1995, pp. 103–129. [37] L. Huang, J. Freeman, N. Cooke, M. Cohen, X. Yin, J. Clark,
[18] F. Torabi, G. Warnell, and P. Stone, “Behavioral cloning from ob- M. Wood, V. Buchanan, C. Carrol, F. Scholcover, A. Mudigonda,
servation,” in Proceedings of the Twenty-Seventh International Joint L. Thomas, A. Teo, M. Freiman, J. Colonna-Romano, L. Lapujade,
Conference on Artificial Intelligence, IJCAI 2018, July 13-19, 2018, and K. Tatapudi, “Using humans’ theory of mind to study artificial
Stockholm, Sweden, J. Lang, Ed. ijcai.org, 2018, pp. 4950–4957. social intelligence in minecraft search and rescue,” in (to be submitted
[19] K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep inside convolu- to the) Journal of Cognitive Science, 2021.
tional networks: Visualising image classification models and saliency
maps,” in 2nd International Conference on Learning Representations,
ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Workshop Track
Proceedings, Y. Bengio and Y. LeCun, Eds., 2014.You can also read

















































