How repertoire data is changing antibody science - The ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
JBC Papers in Press. Published on May 14, 2020 as Manuscript REV120.010181
The latest version is at https://www.jbc.org/cgi/doi/10.1074/jbc.REV120.010181
How repertoire data is changing antibody science
Claire Marks1 and Charlotte M. Deane1 *
From the 1 Department of Statistics, University of Oxford, 24-29 St Giles’, Oxford, OX1 3LB
*To whom correspondence should be addressed: Charlotte M. Deane, Department of Statistics,
University of Oxford, 24-29 St Giles’, Oxford, OX1 3LB, deane@stats.ox.ac.uk
Keywords: Antibody, bioinformatics, immunology, protein sequence, protein structure, adaptive
immunity, B cell receptor (BCR), Observed Antibody Space database, structural annotation,
next-generation sequencing
Running title: How repertoire data is changing antibody science
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
ABSTRACT generated and how it responds to antigens. We also
consider how structural information can be used to
Antibodies are vital proteins of the immune sys- enhance these data and may lead to more accurate
tem that recognize potentially harmful molecules depictions of the sequence space, and to applica-
and initiate their removal. Mammals can efficiently tions in the discovery of new therapeutics.
create vast numbers of antibodies with different
sequences capable of binding to any antigen with
high affinity and specificity. Since they can be de- Introduction
veloped to bind to many disease agents, antibod-
ies can be used as therapeutics. In an organism, Antibodies are proteins that play a key role in the
after antigen exposure, antibodies specific to that adaptive immune response. They are produced by
antigen are enriched through clonal selection, ex- B cells, and are either secreted or are membrane-
pansion and somatic hypermutation. The antibod- bound (in the latter case they are known as B cell
ies present in an organism therefore report on its receptors, or BCRs). They are able to neutralize
immune status, describe its innate ability to deal and initiate the removal of foreign entities (known
with harmful substances, and reveal how it has as antigens) from the body by binding to them (1).
previously responded. Next-generation sequencing The ability of the immune system to respond to
technologies are being increasingly used to query a huge range of antigens originates in the diver-
the antibody, or B cell receptor (BCR), sequence sity of the antibodies that can be generated - anti-
repertoire, and the amount of BCR data in public bodies can be produced that bind to nearly every
repositories is growing. The Observed Antibody antigen, with both high specificity and affinity (2).
Space database, for example, currently contains This property has made antibodies highly success-
over a billion sequences from 68 different stud- ful as therapeutics; to date 87 have been approved
ies. Repertoires are available that represent both for use in the clinic across a number of disease ar-
the naive state (i.e. antigen-inexperienced) and that eas and many more are undergoing clinical trials
after immunization. This wealth of data has cre- (3, 4). Antibodies are currently the largest class of
ated opportunities to learn more about our immune biotherapeutic (5).
system. In this review, we discuss the many ways It is estimated that the human antibody reper-
in which BCR repertoire data has been or could toire contains around 1013 unique sequences (6).
be exploited. We highlight its utility for providing This diversity is a result of how the proteins are
insights into how the naive immune repertoire is encoded in the genome. Antibodies are composed
1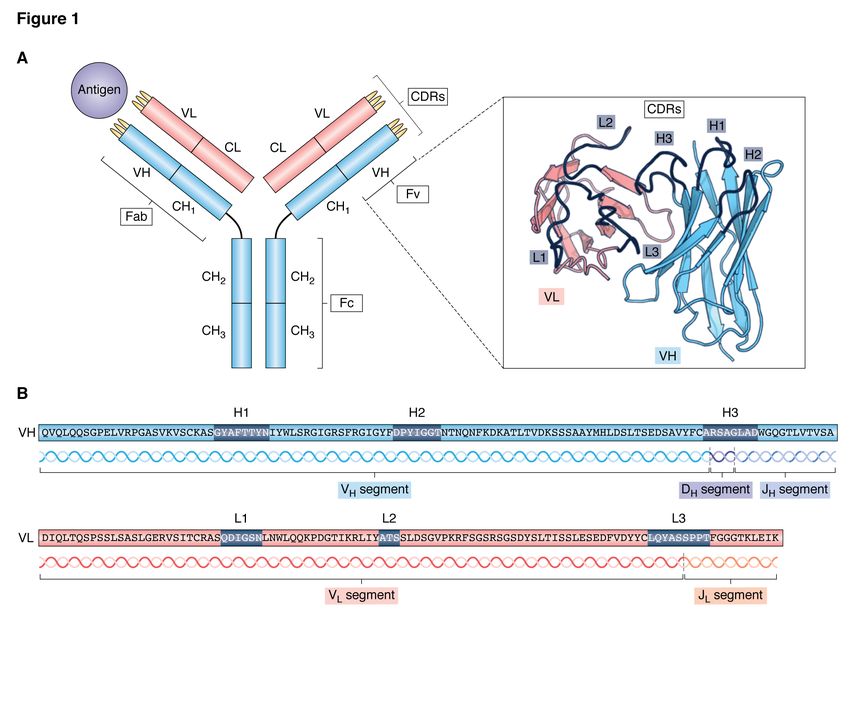
of two types of protein chain; known as the heavy to antigen binding properties (11, 12).
and light chains (Figure 1). Each of these is en- Upon exposure to an antigen, antibodies that
coded by multiple gene segments that are spliced are able to bind to it do so and are thus selected
together using a process called V(D)J recombina- from the repertoire (clonal selection) (13). Having
tion (7). The sequence for the light chain variable a large repertoire of antibodies present in the body
region (Fv) is made up of two segments: the vari- at any time increases the chance that at least one
able segment (V), and the joining segment (J). The has the ability to bind to the antigen, even if only
heavy chain is encoded from variable, joining, and weakly, thereby allowing the initiation of an appro-
diversity (D) segments. There are many genes for priate immune response. B cells producing binding
each of the V, D and J segments, which can be antibodies undergo cycles of proliferation (clonal
matched up in different combinations to produce expansion) with simultaneous somatic hypermuta-
a diverse range of antibody sequences. Further di- tion (9) to produce antibodies with higher affinity.
versity is introduced through the insertion or dele- The antibody repertoire is consequently enriched
tion of nucleotides at the segment junctions (8) and with antibodies that bind to the target antigen.
somatic hypermutation (a process through which
The antibodies present in an organism there-
the number of random mutations that occur is in-
fore describe both its current and past immune sta-
creased) (9). The majority of the variation in se-
tus; what it is able to respond to, and what it has
quence occurs in the complementarity determining
previously dealt with. Whereas previously only a
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
regions, or CDRs - there are three of these on each
handful of sequences could be obtained at a time,
of the heavy and light chains. The most variable of
technological advances mean that large snapshots
these is the H3 loop (the third CDR on the heavy
of this repertoire can now be obtained using next-
chain), since the DNA encoding it is found at the
generation sequencing (NGS) approaches. This
join between the V, D and J segments. By creating
technique of BCR repertoire sequencing was first
a large, diverse repertoire of antibody sequences,
described by Glanville et al. in 2009 (14), and since
an individual is able to react to almost any antigen
then the volume of data available has increased ex-
it may encounter.
ponentially (Figure 2). As it is the H3 loop that
The ability of an antibody to bind to its tar- mostly determines binding properties, many stud-
get antigen is governed by its three-dimensional ies have focussed only on sequencing this region.
structure. Knowledge of an antibody’s structure However, BCR repertoires containing full-length
therefore allows for a deeper understanding of sequences are increasingly being produced - com-
its physicochemical properties than can be gained monly only the heavy chain (15), but some stud-
from sequence alone. The general structure of ies have focussed only the light chain (e.g. 16, 17),
an antibody is depicted in Figure 1. The heavy and some data sets include both (e.g. 18, 19). Re-
and light variable domains both adopt a beta- cent advances in sequencing technology have led
sandwich structure known as the immunoglobu- to a small but growing number of repertoires that
lin fold. Framework (non-CDR) regions are very also include native pairing information (i.e. which
highly conserved between different antibodies; in heavy chain sequences belong with which light
accordance with the observed variability of anti- chain sequences).
body sequences, the structural diversity that allows The largest repertoire sequencing study to date,
binding to many different targets occurs mainly in by Briney et al (20), alone resulted in a set of over
the CDRs. These correspond to loops in the three- 300m heavy chain sequences. In addition, many
dimensional structure, which are responsible for algorithms and pipelines have now been created
most of the antigen binding interactions (10). For that preprocess the generated data ready for anal-
five of the six CDRs (H1, H2, L1-L3), structural ysis, performing tasks such as translation from nu-
diversity is limited - only a few different shapes cleotides to amino acids, error estimation and cor-
have been observed, forming a set of discrete con- rection, and sequence numbering (21). Recently,
formational classes known as canonical structures. efforts have been made to create standardised,
However, as described above, the H3 loop is much publicly-available repositories for this sequencing
more variable in sequence than the other CDRs, data, for example iReceptor (22), VDJServer (23),
and consequently is also more structurally diverse. ImmuneDB (24), and others (25–29). This has pro-
It is thought that the H3 loop contributes the most vided researchers with easy access to a vast number
2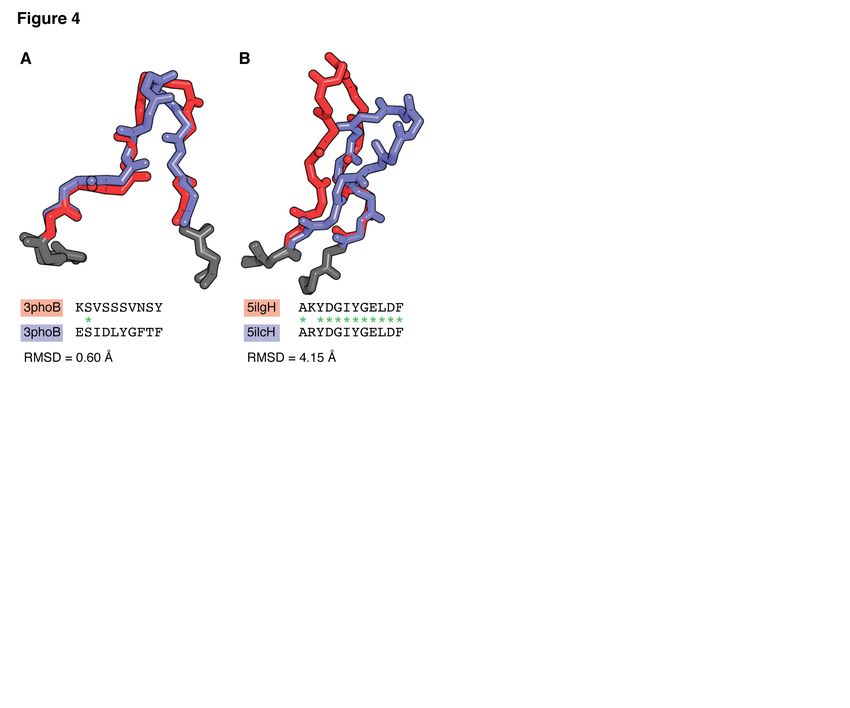
of sequences and created opportunities for large- repertoire snapshots, on the other hand, gives a
scale data mining. The Observed Antibody Space much more detailed picture, and can provide valu-
(OAS) database, for example, which collates full- able insights into how the immune system works.
length variable region sequences, currently con- It can be used to explain how in its naive state (i.e.
tains over 1 billion sequences spanning 68 different before exposure to a given antigen) it is capable
studies (28). of protecting against such diverse threats, and can
The studies included in OAS cover many dif- give a deeper understanding of the processes that
ferent repertoire characteristics. Sequences are produce higher affinity antibodies after antigen ex-
available for six different species, with the major- posure.
ity (64%) being human. Diseased states are rep- Sequencing data has been used to learn more
resented - i.e. repertoires from individuals who about the underlying mechanisms that shape the
have been exposed to a specific antigen – as well as repertoire, such as V(D)J recombination (32, 33).
healthy ones (meaning the individual has not been Increasing amounts of large-scale sequence data,
exposed to the antigen of interest, and also has not along with the development of computational tools
suffered from a disorder of the immune system). that annotate sequences with their V(D)J gene ori-
Repertoires from vaccination studies also feature gins (34–37), has allowed trends in this process
(e.g. HIV, Hepatitis B, flu etc.), and in some cases, to be identified. It has been shown that the pro-
OAS has the repertoires of the same individual cess is intrinsically biased; the available V, D and
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
both pre- and post-immunisation. While the snap- J segments in the genome are not used with the
shots of the repertoire achieved through sequenc- same frequency, and therefore some combinations
ing are actually small relative to the potential num- are observed more commonly than others (14, 38–
ber of antibodies present in an organism (for exam- 41). Mathematical models of V(D)J recombination
ple datasets in OAS contain between 20,000 and have been developed that reproduce the natural bi-
300 million redundant sequences), and most stud- ases (42, 43). It has been proposed that this has the
ies feature only the heavy chain or have no pairing potential to aid in the discovery of new antibody
information, the data available still provides oppor- therapeutics - replicating the underlying architec-
tunities to investigate many different aspects of the ture of observed human repertoires should lead to
immune response. In this review, we explore what the creation of more human-like (and hence less
can be done with the wealth of antibody sequence immunogenic) screening libraries (44).
data stored in repositories such as OAS. We give
examples of how this data has been used to give During the proliferation of B cells in clonal se-
insights into the workings of the immune system, lection, the rate of mutation is increased up to 106-
look at how it can be enhanced with structural in- fold (45) compared to normal cells, due to somatic
formation, explore how it offers new avenues for hypermutation (as described earlier). Variations on
therapeutic antibody discovery and development, the original antigen-binding antibody sequence are
and consider what advances may be made in the therefore generated, and higher affinity antibodies
future. are iteratively produced. Repertoire data has been
used to analyse this process (46–50). This has
increased our understanding of mutation frequen-
Biological insights from antibody cies, substitution bias, and the location of mutation
repertoire data hotspots, and hence how the repertoire reacts to an
antigenic stimulus. For example, researchers have
Until the advent of BCR repertoire sequencing, an- demonstrated that memory cells of different iso-
tibody sequences were analysed in much smaller types experience different selection pressures (46),
numbers (normally a few hundred B cells per ex- and that substitution profiles vary between V genes
periment (15)); only a tiny fraction of the esti- (47), are dependent on neighbouring bases, and are
mated total repertoire. This approach can be use- conserved across individuals (48). As in the case
ful when investigating a few key antibodies, for of V(D)J recombination, these insights have en-
example those that bind to an antigen of interest abled accurate models of somatic hypermutation to
(e.g. 30, 31), but cannot give an in-depth view of be established (49, 50). These models have led to
the repertoire as a whole (for example, little can the creation of software that simulates repertoires
be learned about its diversity). Analysis of larger (51), and mean that more accurate B-cell lineages
3can be established (49). These phylogenies have (63). Antibodies belonging to the same clonotype
the potential to be used in the identification of an- are assumed to share the same precursor sequence
tibodies with high binding affinities (50). (i.e. they arose from the proliferation of the same B
Researchers have also investigated the inter- cell) and are therefore predicted to bind to the same
play between all the processes that dictate reper- epitope. This is therefore a method of monitoring
toire diversity to ascertain how much is genetically the clonal selection and expansion that occurs after
predetermined and how much is antigen-driven; exposure to an antigen, and can be used to identify
analysis indicates that both are important factors the antibodies that bind to a particular target.
but genetics are more influential (39). Further re-
Since the repertoires of many individuals have
search has compared the repertoires of humans and
now been sequenced, we can compare them to
other species (52, 53), revealing that immune sys-
identify which characteristics of the repertoire are
tem development is broadly similar across different
shared and which are unique to each organism. The
mammals (53), and that mice BCR repertoires tend
idea of ‘public sequences’ has recently been pro-
to be closer to germline sequences than those of
posed - a set of sequences or clonotypes that are
humans (52). The effect of disease on the immune
observed in the repertoires of two or more indi-
system has also been studied (54), and has indi-
viduals (20, 44, 61, 64–66). One may expect that
cated that repertoire analysis can have more prac-
this is rare, due to the enormous potential num-
tical applications - for example, it can be used to
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
ber of sequences (estimated at 1013 ), and the rel-
monitor the diversity of the repertoire before and
atively small proportion of those sequences sam-
after an organ transplant (55), and machine learn-
pled in current datasets (the largest samples from
ing methods have been used to predict vaccination
a single individual currently have on the order of
status or the presence of disease (56–58).
106 sequences). However, while repertoires are
The overall architecture of the antibody reper- largely unique to the organism (67), it has been
toire can be investigated by inferring relationships shown that individuals share more heavy chain se-
between sequences; i.e. by predicting which ones quences than would be expected by coincidence.
originated from the same precursor antibody and Briney et al. (20), in their recent large-scale study,
hence which bind to the same antigen. One ap- showed that in the repertoires of ten individuals,
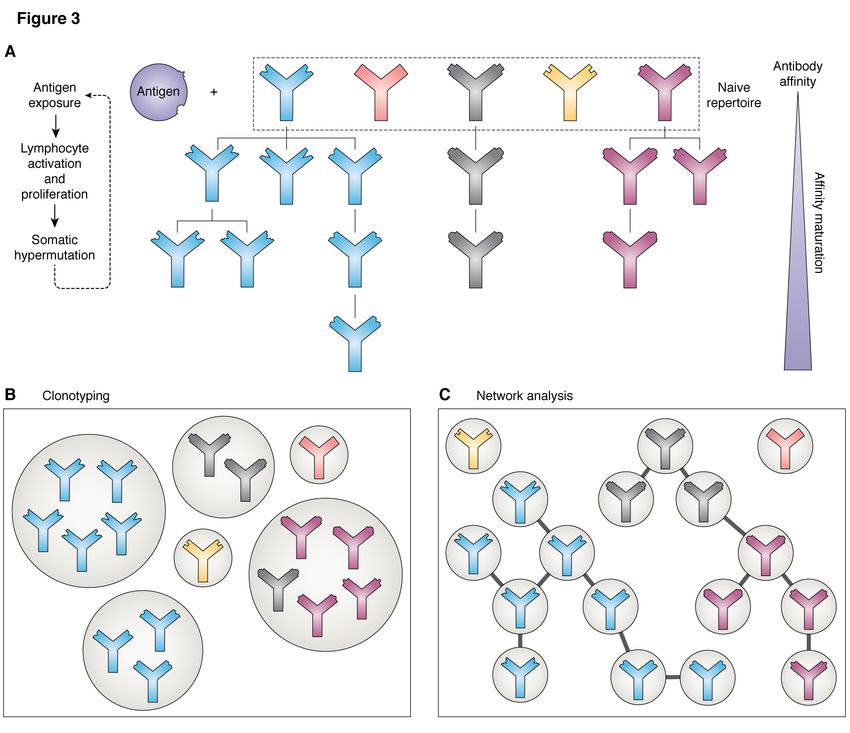
proach is to consider the repertoire as a network, on average 0.95% of clonotypes were shared be-
with each sequence being a separate node and the tween at least two subjects, and 0.022% were com-
presence of an edge between them indicating an mon to all ten. The pool of subjects contained both
evolutionary relationship (44). These relationships men and women, individuals from both Caucasian
are normally defined based on sequence identity, and African American ethnic backgrounds, and a
for example two sequences can be connected if variety of blood types; the authors report that the
they differ by one amino acid in their H3 region repertoires did not cluster based on these factors.
(44). Common network analysis metrics can then The work of Soto et al. (64) indicates this public
be used to explore the repertoire architecture - for subrepertoire could be even larger, making up be-
example, the degree distribution (the degree of a tween 1 and 6% of the whole. Greiff et al. (68)
node is the number of edges it is connected to) can have used machine learning techniques, trained on
reveal the presence or absence of clonal expansion publically-available datasets such as those in OAS,
(33), since highly connected nodes are likely to to predict the public or private nature of a given se-
represent sequences derived from a common pre- quence with 80% accuracy, hinting that this prop-
cursor during affinity maturation. erty is not random and that there are fundamen-
Clonotyping is another related way of investi- tal characteristics of the sequences that separate
gating the diversity of repertoires, and in particular the two subsets. In their network-based analy-
how they change upon antigen exposure. Similar sis of antibody H3 sequences, where each node
antibody sequences are clustered into ‘clonotypes’; is a unique H3 sequence, Miho et al (44) demon-
these are generally defined as sequences originat- strated that public clonotypes were amongst the
ing from the same V and J genes, and with H3s that most connected nodes (i.e. they are similar in se-
are the same length and similar in sequence (nor- quence to many other nodes), and that most pri-
mally a sequence identity of 80 - 100%) (59–62), vate clonotypes (74%) were connected to at least
although alternative approaches have been used one public one. The removal of public clono-
4types from the network therefore changed the un- determination is time-consuming and hence low-
derlying repertoire architecture, however the sys- throughput; as such it can be used to probe the
tem was robust to the removal of a large number chemistry of a select few sequences (77, 78), but
of randomly-selected clonotypes. This implies that it cannot yet be used to structurally characterise a
public clonotypes are key in maintaining functional BCR repertoire.
immunity against antigens, while the presence of Computational modelling offers an alternative.
other clonotypes is able to fluctuate over time. It has been shown that the majority of antibody se-
Light chain data has also been analysed; VL se- quences from BCR repertoires can be mapped to
quences are less diverse than their VH counterparts known structures (75). A number of algorithms
(52, 69, 70), and so the percentage of the repertoire have been developed that predict the structure of
comprising public sequences is much larger. For an antibody’s Fv region from its sequence (79–92).
instance, Soto et al., in a 3-individual experiment, Due to the conserved nature of the antibody frame-
observed that 20 to 34% of light chains (of both work structure (see Figure 1), and the existence of
kappa and lambda types) were shared by at least canonical classes, these tools generally rely on ho-
two people (64). mology modelling - i.e. an existing structure with
Overall, the presence of shared clonotypes high sequence identity to a segment of or to the
across different individuals, while small, may sig- whole target is used as a template. Normally the
nal the existence of a baseline common functional- structure is considered as separate regions; first the
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
ity of the immune system. This core subset of the frameworks of the VH and VL, and then the six
repertoire may be responsible for an organism’s re- CDRs. Separate templates may be chosen for the
sponse to common antigens (66), and it has been VH and VL, however if a single template is avail-
hypothesised that these public clonotypes are more able with high sequence identity to both chains,
likely to display low levels of immunogenicity and only one is required (79). In this case, the ori-
be more versatile binders, and hence may be useful entation of the two chains can be directly copied
starting points in therapeutic development (71, 72). from the chosen template, otherwise a further tem-
plate that is similar in sequence to both chains is re-
quired, or the orientation between the chains must
Combining sequence with structure
be predicted (93). The framework can be mod-
Although much can be learned from sequences elled with very high accuracy, typically with an
alone, it is the three-dimensional structure of the RMSD of below 1 Å - in the second Antibody
antibody that determines how it interacts with an Modelling Assessment (AMA-II), a blind test of
antigen and therefore governs its binding proper- prediction accuracy, VH and VL were modelled
ties (1, 73). It is known that CDRs belonging to the with an average backbone-atom root mean square
same canonical class (i.e. that have nearly identi- distance (RMSD) of 0.65 Å and 0.50 Å respec-
cal structures) can have very different sequences, tively (88, 89, 91, 94–97). Prediction of the ori-
and conversely H3 loops with similar sequences entation of the two domains was more challenging,
can adopt different conformations (Figure 4) (74). however, with predicted tilt angles differing from
Therefore, by considering sequence alone (e.g. in the true angle by 5◦ to 12◦ (94).
clonotyping), antibodies may be grouped together Once a framework template has been selected,
that have structurally dissimilar binding sites, and CDR structures can then be predicted, again us-
vice versa (75). It is therefore crucial to consider ing templates through knowledge-based loop mod-
structure as well as sequence to allow more accu- elling algorithms. As mentioned previously, in the
rate comparisons to be made and to properly un- majority of cases CDRs L1-L3, H1 and H2 adopt a
derstand antibody function. limited number of known conformations known as
Antibody structures can be obtained experi- canonical classes (98–100). As a result they can be
mentally, normally through X-ray crystallography predicted accurately and quickly using this tech-
or NMR. However, the sequence-structure gap is nique. Templates are selected from a database of
large - while OAS consists of over a billion se- known CDR structures based on sequence iden-
quences, SAbDab, a database of publicly-available tity and the geometry of the anchor residues (the
antibody structures (76), currently contains ∼4000 residues on either side of the CDR). The database
entries. This is because experimental structure of CDR structures can either include all known
5structures, or can be limited to the known con- required to reduce developability issues. Since an-
formations for the predicted canonical class of the tibody properties can be predicted with greater ac-
target (79, 81). Average RMSDs achieved during curacy with the inclusion of structural data (110),
AMA-II ranged from 0.50 Å for L2, to 1.6 Å for models representing the repertoire have the poten-
L3 (94). tial to improve strategies such as directed design by
H3 can also be modelled using this method, using them as inputs to other computational tools,
however its sequence and structural diversity com- for example predictors of the sets of residues on the
pared to the other CDRs makes prediction more antibody and antigen that are involved in binding
challenging (101). The H3 loop has also been (known as the epitope and paratope respectively),
shown to be structurally distinct from typical pro- and developability predictors.
tein loops (102); researchers have therefore de- One problem with modelling the antibody se-
veloped specialised software to model H3 loops quences obtained through repertoire sequencing is
more accurately (103–106). Ab initio techniques, that they are normally not paired, i.e. we don’t
which create potential loop conformations without know which VH belongs with which VL. Native
knowledge of templates, are often used here, ei- pairings are important in creating accurate mod-
ther in isolation or in combination with knowledge- els that represent the repertoire, and will affect the
based strategies as a hybrid algorithm (103). De- properties of the antibody, such as its folding, sta-
spite the existence of H3-specific prediction algo- bility, expression, and binding. Pairing is currently
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
rithms, H3 modelling remains challenging, achiev- thought to be mostly random (20, 65), meaning that
ing RMSDs normally in the region of 2-3 Å (75, most VH chains are capable of associating with
94). In addition, ab initio methods typically re- most VLs. Prediction of true pairings is there-
quire much longer run times than knowledge-based fore difficult. Techniques currently used to propose
methods, and therefore H3 prediction is currently likely pairings include comparing all the potential
the main bottleneck for accurate modelling of BCR interfaces to those observed in known structures
repertoires. Attempts have been made to circum- (72, 107), pairing based on the relative frequency
vent this issue, either by imposing an H3 length of the sequences (111), or by constructing phyloge-
cutoff (long loops are modelled less accurately due netic trees (112). Recently, experimental methods
to the absence of experimental data) (107) or by for immunoglobulin sequencing that preserve na-
only considering those H3 sequences that can be tive pairings have been developed (113); as these
confidently modelled using a knowledge-based al- techniques become more widespread the amount of
gorithm (72, 75, 108). While this may introduce paired data will increase and these approximations
some biases into the analysis – for example, long will no longer be required.
H3 loop structures will be under-represented in Producing complete models of the antibody
model libraries – it increases the confidence we variable region can be time-consuming - for exam-
have in the models that are considered, and sub- ple, in the study by de Kosky et al. (109), Roset-
sequently in the conclusions that are drawn. taAntibody took 570,000 CPU hours to produce
Several studies have used antibody modelling 2,000 models. Even for algorithms that are con-
to enhance the information given by BCR reper- sidered to be fast, execution times would be pro-
toires. De Kosky et al. (109) modelled 2,000 hibitive - ABodyBuilder, for example, takes on av-
VH/VL pairs using RosettaAntibody (83, 84), lim- erage 567 CPU hours per 1,000 sequences (79).
iting their sequences to those with high identity An alternative, faster method of characterising a
templates available. They analysed the physico- repertoire is the structural annotation of sequences.
chemical properties of the antibodies, such as sol- Instead of running a complete modelling protocol,
vent accessible surface area and hydrophobicity, sequences can be quickly matched up to their pre-
and were able to demonstrate how these properties dicted templates using sequence identity. The con-
change with antigen experience and link their ob- formations of the CDRs can be assigned by either
servations to germline usage. Raybould et al. (107) exploiting a knowledge-based loop modelling al-
used ABodyBuilder (79) to predict the structures gorithm (75) or a canonical class predictor (for the
of a large subset of a BCR repertoire (∼19, 000 se- non-H3 CDRs) (100, 108). Sequences can there-
quences), and compared these models to those of a fore be structurally annotated in much greater num-
set of therapeutics to deduce which properties are bers than could be done using modelling tools. It
6has been shown that the majority of sequences can dated through sequencing of the mouse BCR reper-
be mapped to an existing structure in this way (75). toire (115). Sequencing techniques have been used
Structural Annotation of Antibodies (SAAB) to characterise phage display libraries, to monitor
(75) and its successor SAAB+ (108) are algo- their diversity and hence evaluate their capability
rithms that have been used to annotate millions of isolating antibodies that bind to different anti-
of sequences with their proposed template struc- gens (116). Screening libraries can also be de-
tures, allowing thorough analysis of repertoire- signed using BCR repertoire data - Zhai et al. (117)
wide structural properties. For example, Kovalt- and Prassler et al. (118) have shown how this is
suk et al. (108) investigated structural changes that possible, by reproducing the observed amino acid
occur with B cell differentiation. Clustering based usages at each sequence position. Both groups
on their proposed H3 templates resulted in the sep- found that the antibodies in their libraries exhib-
aration of antibodies from different stages of the ited better expression levels than other synthetic li-
immune response, indicating that there are struc- braries, with high genetic diversity, and they were
tural changes that occur as the response progresses. able to isolate high-affinity antibodies for a range
The effect of ageing on the repertoire has also been of different antigens.
studied in this way, revealing that older individuals It is now becoming possible to identify binders
have a higher number of antibodies that are struc- directly from BCR repertoire data. If an antibody
turally distinct from the germline (114). that binds to the target antigen is already known,
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
The idea of public sequences has been ex- approaches such as clonotyping can be used to
tended to that of public structures. Instead of identify more potential binders with closely related
searching for sequences that are observed in the sequences, expanding the pool of candidates that
repertoires of multiple individuals, we can look in- can be taken forward for further study. Known
stead for antibodies with shared backbone confor- binders are not essential, however. The immu-
mations, which may be a greater indicator of com- nisation of an organism with an antigen, as ex-
mon functionality. Sequence-only analyses have plained previously, leads to the enrichment of the
shown that the shared space is present but only repertoire with antibodies that bind to that anti-
makes up a small percentage of the overall reper- gen. Therefore by analysing how often a given se-
toire (20), however by incorporating structure it quence or clonotype appears in the repertoire after
can be seen that the public repertoire is likely to antigen exposure, specific antibodies can be iden-
be much larger (72, 108). tified. This approach can be used to either find
antibodies that might work as therapeutics, or to
monitor the immune response during the devel-
BCR repertoire sequencing and opment of vaccines (66, 119–123). The reper-
therapeutic discovery toires of multiple individuals that have been ex-
posed to the same antigen can be investigated to
Discovering antibodies specific to an anti- find potential binders, by identifying common fea-
gen of interest tures that hint at shared functionality, for exam-
Currently, potential therapeutic antibodies are ple identical H3 sequences (124). The volume
commonly discovered in two ways: through the of data produced also means that deep learning
immunisation of an animal, such as a mouse, with techniques can be used effectively; for example
the target antigen and subsequent extraction of the Mason et al. (125) have generated neural net-
antibodies it produces; and through phage display, works that classify antibodies as HER2-binders or
where viruses displaying antibodies on their sur- non-binders based on sequence, and thereby suc-
face are screened against the target antigen. High- cessfully identified 30 antigen-specific antibodies.
throughput sequencing of the antibody repertoire BCR repertoire sequencing experiments have been
has been used successfully to enhance both ap- carried out to discover binders for a wide range
proaches. For example, researchers have geneti- of antigens, including HIV (71, 112, 126, 127),
cally engineered mice such that they contain hu- ebola (128), hepatitis B (66, 129), and many oth-
man antibody genes - the antibodies produced by ers (78, 111, 117, 119, 121, 124, 129–134).
these mice are therefore less likely to be immuno- Following the isolation of binders in this way,
genic. The ‘humanness’ of the repertoire was vali- a small number can be taken forward as starting
7points for further development (78), or a larger tors (110, 137–145), paratope predictors (73, 146–
number can be employed as a targeted screening 151), and docking algorithms (152–166). As com-
library (111). A comparison between repertoire putational methods continue to improve and be-
mining and phage display has demonstrated that come faster, this approach will become more accu-
the antibodies isolated by each method are not nec- rate and more feasible, potentially making an en-
essarily the same, and therefore it could be benefi- tirely in silico antibody discovery platform a real-
cial to use the two techniques together (130). ity.
Much of the data from these experiments has However, issues arise due to most sequencing
been deposited in public sequence repertoires (28), experiments focussing on only the heavy chain,
meaning it can be exploited by other researchers in and unknown native pairings even when both the
their therapeutic discovery pipelines, for example heavy and light chains are sequenced. Antibod-
to provide new lead molecules. It has recently been ies with high affinity and specificity are identi-
shown that there is a close sequence match to many fied more often when the true VH/VL pairings are
known therapeutic antibodies in the OAS database known (167), however this is not achievable with
(135). Of 242 antibodies that are either currently most of the available data. As previously stated,
used as therapeutics or undergoing clinical trials single-cell approaches that retain pair information
(Phase II or later), sequences with over 90% iden- have been developed (113), however the method is
tity were available for 90 H chains and 158 light not as high-throughput as other sequencing tech-
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
chains. Notably, for H3, which is thought to con- niques and so less data is currently available. In
tribute the most to an antibody’s binding proper- future this is likely to change, but for now other
ties, 54 perfect matches were found. Given the approaches must be applied. For experiments re-
huge number of potential sequences, this is sig- sulting in both heavy and light chain sequences,
nificantly more than would be expected by chance pairings can be exhaustively tested for plausibil-
alone in a sequence database of this size (around ity (72, 136) or by observing relative frequencies
1bn sequences), and implies that artificially devel- (111). Alternatively, especially when light chains
oped sequences are not dissimilar from their nat- have not been sequenced, it may be possible to
ural counterparts. It therefore follows that natural use an artificial light chain with the ability to as-
sequence repertoires could potentially be mined for sociate with a range of heavy chains (168). The
new therapeutic leads, perhaps removing the need concept of public sequences may also help here;
for large-scale screening experiments at the begin- a subset of the public light chain sequences could
ning of an antibody discovery project. be used as a pairing library, as these sequences are
clearly widely used and are therefore more likely to
Structural annotations and modelling can also form successful pairings. In general, known public
be applied to discover antigen-specific antibodies. sequences may be a good place to start when at-
Krawczyk et al. (75) annotated approximately 3.4 tempting to discover a new therapeutic, for exam-
million sequences from individuals who had been ple in the design of a screening library, since they
exposed to the influenza virus with their proposed are likely to have low immunogenicity and be of
templates, and therefore whose repertoires were high importance in the immune response to many
enriched with influenza-specific binders. They dis- common antigens.
covered that many of the templates assigned came
from known influenza-binding antibodies. They
therefore propose that sharing of a similar struc- Using BCR repertoire data to identify un-
tural template could be an indication of similar desirable properties during therapeutic de-
specificity. Assuming that a structure of an an- velopment
tibody specific to a given antigen or epitope is
known, antibodies can be selected from a reper- Binding affinity is not the only feature of a poten-
toire if they are predicted to have a high degree tial therapeutic that needs to be optimised. In addi-
of structural similarity to it. Other computational tion to being biologically active, it must be safe to
tools can also be exploited to find potential thera- administer to humans and be able to withstand the
peutics: a large set of models generated from reper- stresses of the production process; i.e. the antibody
toire data can be used as an in silico screening li- should have good ‘developability’ (169). Antibod-
brary (72, 136) in conjunction with epitope predic- ies discovered through the immunisation of an or-
8ganism (such as a mouse) against the target antigen therefore been developed that predict these risk
cannot be used directly as therapeutics, since they factors (e.g. 177–181, 185). While some of these
would be identified as non-native by the human attempt to predict solely from sequence, the major-
immune system and would therefore cause an un- ity require structural knowledge - for instance, it is
wanted response themselves (170). Changes made important to know which residues are located on
to potential therapeutics during the development the antibody surface (178, 179). The tools can be
process can also introduce non-human-like char- exploited during the identification of binders as de-
acteristics. It is therefore desirable to be able to scribed above to minimise issues further along the
quantify the similarity of a sequence to those from therapeutic development pipeline.
natural human repertoires (its ‘humanness’), and to The properties described above can also be
propose changes that could be made to a sequence examined by calculating repertoire-wide distribu-
to make it more human and hence less likely to be tions. As a simple example, consider the lengths
rejected by a patient. This ‘humanisation’ process of the CDRs. Using sequence repertoires, the dis-
can be guided through comparisons to human BCR tribution of observed lengths can be obtained. If a
repertoires, since they are natural and represent given length falls outside the range of this distri-
what is ‘allowed’ and what is safe in an organism bution, it can be assumed that this property is ‘un-
(see Figure 5). Previous work has used small sets natural’ and therefore the antibody is more likely
of reference sequences (such as known germline to have undesirable characteristics in vivo. Ray-
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
sequences) to infer humanness (171–173), but the bould et al. (107) used this approach, alongside
growth of BCR repertoire sequencing has created the generation of antibody model libraries, to con-
new opportunities. The amount of data now avail- textualise known therapeutic sequences against hu-
able allows not only the identification of which man repertoires. They were therefore able to define
amino acids are allowed at which positions, but five developability guidelines that predict whether
also the investigation of residue couplings and co- a given antibody will be successful as a therapeutic,
variation (174). Recently, Wollacott et al. (174) based on total CDR length, patches of hydropho-
described a machine learning-based humanisation bicity, patches of positive and negative charge,
method, trained on large sets of sequence data, and and the overall surface charge of VH and VL do-
demonstrated that it outperformed other methods mains. Testing the guidelines on sequences from
at evaluating the humanness of antibodies from se- two antibody discovery projects showed that this
quence. approach successfully highlighted candidates with
known developability issues.
The chemical properties of a potential thera- In summary, by representing the allowed an-
peutic can also cause problems, such as instabil- tibody sequence space, BCR repertoires can be
ity, self-association, high viscosity, polyspecificity, used to guide the antibody discovery and devel-
and poor expression (169). These characteristics opment process towards more successful therapeu-
can be determined experimentally, however this is tic candidates. Using developability or humanness
time-consuming and hence low-throughput, mean- prediction algorithms in conjunction with in silico
ing the examination of thousands or millions of screening of BCR repertoires should be of great
sequences from a BCR repertoire is not feasible. benefit to the therapeutic development community,
However, some of these properties can be predicted and as sequence repositories continue to grow and
from the amino acid sequence of the antibody. computational techniques become more sophisti-
For example, a number of sequence motifs have cated, we can expect more advances to be made.
been identified that indicate sites of potential post-
translational modification (79, 175); hydrophobic
residues in the CDRs are thought to lead to high ag- Conclusions
gregation, viscosity, and polyspecificity (169, 176–
181); patches of electrostatic charge on the anti- Advances in next-generation sequencing and its in-
body surface have been linked to high clearance creasing use in characterising the immune system
rates and poor expression (182, 183); and asym- has led to the exponential growth of the number of
metric charges of the heavy and light variable do- known antibody sequences. Subsequently there is
mains result in self-association and high viscosity now a wealth of information, which has increased
(177, 184). A number of computational tools have opportunities for large-scale data mining. The
9amount of data presents its challenges, however. select likely binders.
Curated, publicly-available sequence repositories Currently, it is possible for the computational
such as the Observed Antibody Space database approaches such as those described in this review
(OAS) are addressing the problem of storage and to be used in tandem with experimental work. For
accessibility, but changes may have to be made as example, after a potential binder is identified ex-
we learn more about the needs of researchers wish- perimentally, clonotyping can be used to select
ing to use the data. The increase in the amount of similar antibodies from a repertoire, thereby ex-
data will also create computational obstacles; we panding the pool of candidates for further study.
must continue to develop methods that can anal- In the long term, however, the objective of many
yse huge numbers of sequences in a time- and researchers is to make the discovery of new thera-
resource-efficient manner. peutic antibodies completely computational, with
Repertoire data can be used to gain a deeper little or no human input. Consolidating all the
understanding of human immune system, includ- knowledge gained from large-scale repertoire anal-
ing the mechanisms that drive repertoire diversity, ysis may enable the creation of an in silico immune
and its response to antigen exposure. Comparisons system, or at the least a completely human-like
between individuals have detected the presence of synthetic repertoire that can be screened to iden-
a core set of shared sequences or clonotypes known tify potential therapeutics. While it is too soon to
as the public repertoire, potentially of great impor- say whether an entirely in silico protocol would
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
tance in protecting against common antigens. produce better results than an experimental one,
The antigen-binding properties of antibodies it would remove the need for expensive and time-
are governed by their structures. Sequence-similar consuming experimental work, and would mean
antibodies may adopt different structures, and vice the immunisation of animals is no longer required.
versa; by using sequence alone these subtleties are There are many obstacles to achieve this, perhaps
not discerned. The incorporation of structural in- most importantly in the initial selection of antibod-
formation into repertoire analyses, through anno- ies that bind to a specific antigen of interest - im-
tation or modelling, therefore allows more accu- provements in structural modelling, docking, and
rate comparisons to be made and hence provides a binding affinity prediction in particular will help
better representation of the repertoire space. Ongo- this.
ing improvements in modelling algorithms, in par- Even though there is a large quantity of data
ticular increased speed and accuracy of H3 struc- already available, there is a vast amount of the
ture prediction, will mean that larger subsets of antibody sequence space that remains unknown.
the repertoire can be analysed in this manner, and For example, at around one billion sequences (in-
with more reliability. An increase in the number of cluding redundant sequences), the Observed Anti-
available templates would also improve structural body Space database represents less than 0.01% of
modelling - repertoire data itself may be used in the potential total number (predicted to be around
this process, to highlight areas of sequence space 1013 non-redundant sequences). Efforts should
for which structures are currently lacking. also be made to sequence repertoires with differ-
Large-scale sequencing data can also be of ent attributes, for example ethnic background - cur-
great benefit during the discovery of antibodies rently this is not routinely disclosed, making anal-
for therapeutic use. Clonal selection and expan- ysis of its effect on the repertoire difficult. The
sion leads to the enrichment of the repertoire with continued growth of available sequence informa-
antigen-binders post exposure; these can be identi- tion should mean that currently unknown parts of
fied and used as starting points for further develop- sequence space are investigated, and therefore we
ment. The presence of sequence-similar antibod- should be able to analyse the workings of the im-
ies to known therapeutics in OAS (75) indicates mune system and predict antibody/repertoire prop-
that it should be possible to mine these repositories erties more accurately. Importantly, with the devel-
for new therapeutic leads without performing spe- opment of experimental techniques that preserve
cific experiments. For example, in silico screening the native VH-VL pairings, we will no longer have
libraries could be developed, by combining BCR to rely on approximations and exhaustive combina-
repertoire data with modelling protocols and other torics to achieve an accurate view of what binding
computational tools (e.g. docking algorithms) to sites are present. Overall, access to large-scale se-
10quencing data has provided many opportunities to and improve our ability to design biotherapeutics,
deepen our understanding of the immune system and will surely continue to do so.
Conflict of Interest
The authors declare that they have no conflicts of interest with the contents of this article.
References
[1] Sela-Culang, I., Kunik, V., and Ofran, Y. (2013) The structural basis of antibody-antigen recog-
nition. Front. Immunol. 4, 302
[2] Saper, C. B. (2009) A Guide to the Perplexed on the Specificity of Antibodies. J. Histochem.
Cytochem. 57, 1–5
[3] Ecker, D. M., Jones, S. D., and Levine, H. L. (2015) The therapeutic monoclonal antibody market.
mAbs 7, 9–14
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
[4] Raybould, M. I. J., Marks, C., Lewis, A. P., Shi, J., Bujotzek, A., Taddese, B., and Deane, C. M.
(2019) Thera-SAbDab: the Therapeutic Structural Antibody Database. Nucleic Acids Res. 48,
D383–D388
[5] Kaplon, H. and Reichert, J. M. (2019) Antibodies to watch in 2019. mAbs 11, 219–238
[6] Greiff, V., Miho, E., Menzel, U., and Reddy, S. T. (2015) Bioinformatic and Statistical Analysis
of Adaptive Immune Repertoires. Trends Immunol. 36, 738–749
[7] Tonegawa, S. (1983) Somatic generation of antibody diversity. Nature 302, 575–581
[8] Jeske, D. J., Jarvis, J., and Capra, J. D. (1984) Junctional Diversity. J. Immunol. 133, 1090–1092
[9] Schramm, C. A. and Douek, D. C. (2018) Beyond hot spots: Biases in antibody somatic hyper-
mutation and implications for vaccine design. Front. Immunol. 9, 1876
[10] Collis, A. V., Brouwer, A. P., and Martin, A. C. (2003) Analysis of the antigen combining site:
Correlations between length and sequence composition of the hypervariable loops and the nature
of the antigen. J. Mol. Biol. 325, 337–354
[11] Xu, J. L. and Davis, M. M. (2000) Diversity in the CDR3 Region of V. Immunity 13, 37–45
[12] Kuroda, D., Shirai, H., Jacobson, M. P., and Nakamura, H. (2012) Computer-aided antibody
design. Protein Eng. Des. Sel. 25, 507–21
[13] Burnet, F. M. (1960) Theories of immunity. Perspect. Biol. Med. 3, 447–458
[14] Glanville, J., Zhai, W., Berka, J., Telman, D., Huerta, G., Mehta, G. R., Ni, I., Mei, L., Sundar,
P. D., Day, G. M., Cox, D., Rajpal, A., and Pons, J. (2009) Precise determination of the diversity
of a combinatorial antibody library gives insight into the human immunoglobulin repertoire. Proc.
Natl. Acad. Sci. U.S.A. 106, 20216–20221
[15] Georgiou, G., Ippolito, G. C., Beausang, J., Busse, C. E., Wardemann, H., and Quake, S. R.
(2014) The promise and challenge of high-throughput sequencing of the antibody repertoire. Nat.
Biotechnol. 32, 158–168
[16] Ota, M., Duong, B. H., Torkamani, A., Doyle, C. M., Gavin, A. L., Ota, T., and Nemazee, D.
(2010) Regulation of the B Cell Receptor Repertoire and Self-Reactivity by BAFF. J. Immunol.
185, 4128–4136
11[17] Zhou, T., Zhu, J., Wu, X., Moquin, S., Zhang, B., Acharya, P., Georgiev, I. S., Altae-Tran, H. R.,
Chuang, G. Y., Joyce, M. G., DoKwon, Y., Longo, N. S., Louder, M. K., Luongo, T., McKee, K.,
Schramm, C. A., Skinner, J., Yang, Y., Yang, Z., Zhang, Z., Zheng, A., Bonsignori, M., Haynes,
B. F., Scheid, J. F., Nussenzweig, M. C., Simek, M., Burton, D. R., Koff, W. C., Mullikin, J. C.,
Connors, M., Shapiro, L., Nabel, G. J., Mascola, J. R., and Kwong, P. D. (2013) Multidonor
analysis reveals structural elements, genetic determinants, and maturation pathway for HIV-1
neutralization by VRC01-class antibodies. Immunity 39, 245–258
[18] Vander Heiden, J. A., Stathopoulos, P., Zhou, J. Q., Chen, L., Gilbert, T. J., Bolen, C. R., Barohn,
R. J., Dimachkie, M. M., Ciafaloni, E., Broering, T. J., Vigneault, F., Nowak, R. J., Kleinstein,
S. H., and O’Connor, K. C. (2017) Dysregulation of B Cell Repertoire Formation in Myasthenia
Gravis Patients Revealed through Deep Sequencing. J. Immunol. 198, 1460–1473
[19] Gidoni, M., Snir, O., Peres, A., Polak, P., Lindeman, I., Mikocziova, I., Sarna, V. K., Lundin,
K. E., Clouser, C., Vigneault, F., Collins, A. M., Sollid, L. M., and Yaari, G. (2019) Mosaic
deletion patterns of the human antibody heavy chain gene locus shown by Bayesian haplotyping.
Nat. Commun. 10, 628
[20] Briney, B., Inderbitzin, A., Joyce, C., and Burton, D. R. (2019) Commonality despite exceptional
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
diversity in the baseline human antibody repertoire. Nature 566, 393–397
[21] López-Santibáñez-Jácome, L., Avendaño-Vázquez, S. E., and Flores-Jasso, C. F. (2019) The
pipeline repertoire for Ig-Seq analysis. Front. Immunol. 10, 899
[22] Corrie, B. D., Marthandan, N., Zimonja, B., Jaglale, J., Zhou, Y., Barr, E., Knoetze, N., Breden,
F. M., Christley, S., Scott, J. K., Cowell, L. G., and Breden, F. (2018) iReceptor: A platform
for querying and analyzing antibody/B-cell and T-cell receptor repertoire data across federated
repositories. Immunol. Rev. 284, 24–41
[23] Christley, S., Scarborough, W., Salinas, E., Rounds, W. H., Toby, I. T., Fonner, J. M., Levin, M. K.,
Kim, M., Mock, S. A., Jordan, C., Ostmeyer, J., Buntzman, A., Rubelt, F., Davila, M. L., Monson,
N. L., Scheuermann, R. H., and Cowell, L. G. (2018) VDJServer: A cloud-based analysis portal
and data commons for immune repertoire sequences and rearrangements. Front. Immunol. 9, 976
[24] Rosenfeld, A. M., Meng, W., Luning Prak, E. T., and Hershberg, U. (2018) ImmuneDB, a novel
tool for the analysis, storage, and dissemination of immune repertoire sequencing data. Front.
Immunol. 9, 2107
[25] Chailyan, A., Tramontano, A., and Marcatili, P. (2012) A database of immunoglobulins with
integrated tools: DIGIT. Nucleic Acids Res. 40, 1230–1234
[26] Swindells, M. B., Porter, C. T., Couch, M., Hurst, J., Abhinandan, K. R., Nielsen, J. H., Macin-
doe, G., Hetherington, J., and Martin, A. C. (2017) abYsis: Integrated Antibody Sequence and
Structure—Management, Analysis, and Prediction. J. Mol. Biol. 429, 356–364
[27] Zhang, W., Wang, L., Liu, K., Wei, X., Yang, K., Du, W., Wang, S., Guo, N., Ma, C., Luo,
L., Wu, J., Lin, L., Yang, F., Gao, F., Wang, X., Li, T., Zhang, R., Saksena, N. K., Yang, H.,
Wang, J., Fang, L., Hou, Y., Xu, X., and Liu, X. (2019) PIRD: Pan Immune Repertoire Database.
Bioinformatics btz614
[28] Kovaltsuk, A., Leem, J., Kelm, S., Snowden, J., Deane, C. M., and Krawczyk, K. (2018) Ob-
served Antibody Space: A Resource for Data Mining Next-Generation Sequencing of Antibody
Repertoires. J. Immunol. 201, 2502–2509
[29] DeWitt, W. S., Lindau, P., Snyder, T. M., Sherwood, A. M., Vignali, M., Carlson, C. S., Green-
berg, P. D., Duerkopp, N., Emerson, R. O., and Robins, H. S. (2016) A public database of memory
and naive B-cell receptor sequences. PLoS ONE 11, 1–18
12[30] Wrammert, J., Smith, K., Miller, J., Langley, W. A., Kokko, K., Larsen, C., Zheng, N. Y., Mays,
I., Garman, L., Helms, C., James, J., Air, G. M., Capra, J. D., Ahmed, R., and Wilson, P. C. (2008)
Rapid cloning of high-affinity human monoclonal antibodies against influenza virus. Nature 453,
667–671
[31] Yu, X., Tsibane, T., McGraw, P. A., House, F. S., Keefer, C. J., Hicar, M. D., Tumpey, T. M.,
Pappas, C., Perrone, L. A., Martinez, O., Stevens, J., Wilson, I. A., Aguilar, P. V., Altschuler,
E. L., Basler, C. F., and Crowe Jr, J. E. (2008) Neutralizing antibodies derived from the B cells of
1918 influenza pandemic survivors. Nature 455, 532–536
[32] Frost, S. D., Murrell, B., Hossain, A. S. M., Silverman, G. J., and Pond, S. L. (2015) Assigning
and visualizing germline genes in antibody repertoires. Phil. Trans. R. Soc. B 370, 20140240
[33] Miho, E., Yermanos, A., Weber, C. R., Berger, C. T., Reddy, S. T., and Greiff, V. (2018) Computa-
tional strategies for dissecting the high-dimensional complexity of adaptive immune repertoires.
Front. Immunol. 9, 224
[34] Gadala-Maria, D., Yaari, G., Uduman, M., and Kleinstein, S. H. (2015) Automated analysis of
high-throughput B-cell sequencing data reveals a high frequency of novel immunoglobulin V
gene segment alleles. Proc. Natl. Acad. Sci. U.S.A. 112, E862–E870
Downloaded from http://www.jbc.org/ by guest on August 20, 2020
[35] Gupta, N. T., Vander Heiden, J. A., Uduman, M., Gadala-Maria, D., Yaari, G., and Kleinstein,
S. H. (2015) Change-O: A toolkit for analyzing large-scale B cell immunoglobulin repertoire
sequencing data. Bioinformatics 31, 3356–3358
[36] Corcoran, M. M., Phad, G. E., Bernat, N. V., Stahl-Hennig, C., Sumida, N., Persson, M. A.,
Martin, M., and Hedestam, G. B. (2016) Production of individualized v gene databases reveals
high levels of immunoglobulin genetic diversity. Nat. Commun. 7, 13642
[37] Marcou, Q., Mora, T., and Walczak, A. M. (2018) High-throughput immune repertoire analysis
with IGoR. Nat. Commun. 9, 561
[38] Feeney, a. J., Tang, a., and Ogwaro, K. M. (2000) B-cell repertoire formation: role of the recom-
bination signal sequence in non-random V segment utilization. Immunol. Rev. 175, 59–69
[39] Greiff, V., Menzel, U., Miho, E., Weber, C., Riedel, R., Cook, S., Valai, A., Lopes, T., Radbruch,
A., Winkler, T. H., and Reddy, S. T. (2017) Systems Analysis Reveals High Genetic and Antigen-
Driven Predetermination of Antibody Repertoires throughout B Cell Development. Cell Rep. 19,
1467–1478
[40] Weinstein, J. A., Jiang, N., White, R. A., Fisher, D. S., and Quake, S. R. (2009) High-throughput
sequencing of the zebrafish antibody repertoire. Science 324, 807–810
[41] Glanville, J., Kuo, T. C., Von Büdingen, H. C., Guey, L., Berka, J., Sundar, P. D., Huerta, G.,
Mehta, G. R., Oksenberg, J. R., Hauser, S. L., Cox, D. R., Rajpal, A., and Pons, J. (2011) Naive
antibody gene-segment frequencies are heritable and unaltered by chronic lymphocyte ablation.
Proc. Natl. Acad. Sci. U.S.A. 108, 20066–20071
[42] Elhanati, Y., Sethna, Z., Marcou, Q., Callan, C. G., Mora, T., and Walczak, A. M. (2015) Inferring
processes underlying B-cell repertoire diversity. Phil. Trans. R. Soc. B 370, 20140243
[43] Elhanati, Y., Marcou, Q., Mora, T., and Walczak, A. M. (2016) RepgenHMM: A dynamic pro-
gramming tool to infer the rules of immune receptor generation from sequence data. Bioinfor-
matics 32, 1943–1951
[44] Miho, E., Roškar, R., Greiff, V., and Reddy, S. T. (2019) Large-scale network analysis reveals the
sequence space architecture of antibody repertoires. Nat. Commun. 10, 1321
13You can also read

















































