NeighborHunting: A Location-Aware Craigslist
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
NeighborHunting: A Location-Aware Craigslist
Wenbin Fang, Lanyue Lu, Linhai Song and Weiyan Wang ∗
Computer Sciences Department, University of Wisconsin-Madison
Abstract
This report introduces NeighborHunting, a web service that allows users to post advertisements similar
to Craigslist 1 . NeighborHunting has two features that make it more user-friendly than Craigslist. First, it
automatically matches the supply and demand. Second, it detects and displays users’ locations on a map.
For implementation, NeighborHunting is running on Google App Engine that provides elastic computing
resources for great scalability. In this report, we describe the use cases of NeighborHunting, and justify
the design of it. In particular, we use HTML5 local store for client-side caching, and Memcached for
server-side caching. Furthermore, we design an eventual consistency mechanism to improve the overall
performance of NeighborHunting, and adopt sharding approach to handle write contentions in datastore.
Finally, we evaluate the performance of NeighborHunting, where we show that NeighborHunting can
handle more than 3000 requests per second when using the free service of Google App Engine. The
NeighborHunting service can be accessed at http://neighborhunting.appspot.com.
1 Introduction
Craigslist is a popular classified advertisement service, with sections devoted to jobs, housing, personal,
and so forth. It serves over 500 cities in 50 countries, and constantly sits at top 50 in Alexa traffic
rank. The website has minor changes in user interface since its inception in 1995. Therefore, the user
interface is still a web 1.0 thing, and has much room for improvement. We identify two major setbacks
for the usability of Craigslist. First, using Craigslist, users have to manually browse posts to find what
they want, or they have to wait for other people to contact them, if they post something interesting.
Second, users have to consult external map to visually locate the whereabout of the person that they are
interested in.
To address the two setbacks of Craigslist, we design and build NeighborHunting with a syntax-based
match maker, and a location-aware map. The syntax-based match maker automatically matches supply
and demand, according to pre-defined rules. NeighborHunting has a set of default rules, for example, if
User A wants to buy Item 1, and User B wants to sell Item 1, then User A and User B are matched. In
the future, we plan to support rules defined by users. The location-aware map is to help users visually
locate the people they are interested in. Modern web browser (e.g., Firefox 4) and mobile devices (e.g.,
iphone) has geolocation support, which detects the user’s physical location by either IP address or GPS.
∗
Authors by alphabetical order.
1
http://www.craigslist.org
1
We build NeighborHunting on Google App Engine, which is a cloud computing infrastructure. We
benefit from cloud computing in that, we do not need to worry about the hardware administration
issues to scale our service. In addition, Google App Engine provides sufficient services for us to tune
the performance in the cloud. For example, we use memcached to reduce the direct workload to on-
disk data, and use Task Queue and Cron Job API of App Engine to implement an eventual consistency
mechanism, to improve the overall performance. We also benefit from modern client side techniques,
such as geolocation ability in browsers and mobile devices, and the HTML5 local store for caching data
in the browser. We argue that client side techniques are as important as techniques inside the cloud.
The advancement of client side techniques makes cloud computing more usable, which encourages users
to use services in the cloud.
Figure 1(a) illustrates the use case of NeighborHunting. User A and User B use mobile devices to access
NeighborHunting service in the cloud, while User C uses a laptop. The three users post “advertisement” to
NeighborHunting, stating what they need. For example, User B wants to sell an ipad2. NeighborHunting
returns a user other advertisements that match the advertisement posted by her, according to pre-defined
rules. In this example, the pre-define rule is to match “buy” with “sell” that is selling the same item.
For instance, User A and User B are matched, because one of them wants to buy ipad2, and the other
wants to sell ipad2. Users can see a map showing people who post matched advertisements, then they
can decide whether to contact these people by sending emails. Figure 1(b) shows the map that is seen
by User A.
NeighborHunting
I want to
sell ipad2!
B
Buy ipad2 I want to
Date Women date Men!
User A buys ipad2 I want to
User B sells ipad2 Date Women,
User C dates Men User A dates Women
Buy ipad2!
Date Men
Sell iPad2 C
A
B C
A
User A User B User C
(a) Users interact with NeighborHunting. (b) The Map from User A’s point of view.
Figure 1: Use Case of NeighborHunting.
In the remaining of this report, we present the design and implementation of NeighborHunting in
Section 2, and show the evaluation result in Section 3. Finally, we discuss the future work in Section 4.
2 Design and Implementation
This section describes the design and implementation of NeighborHunting. We start with the functional-
ities that NeighborHunting provides, which is from a user’s point of view (Section 2.1). We then describe
2
the architecture of the whole system (Section 2.2), and dive into the details of server side (Section 2.3)
and client side (Section 2.4).
2.1 Functionality
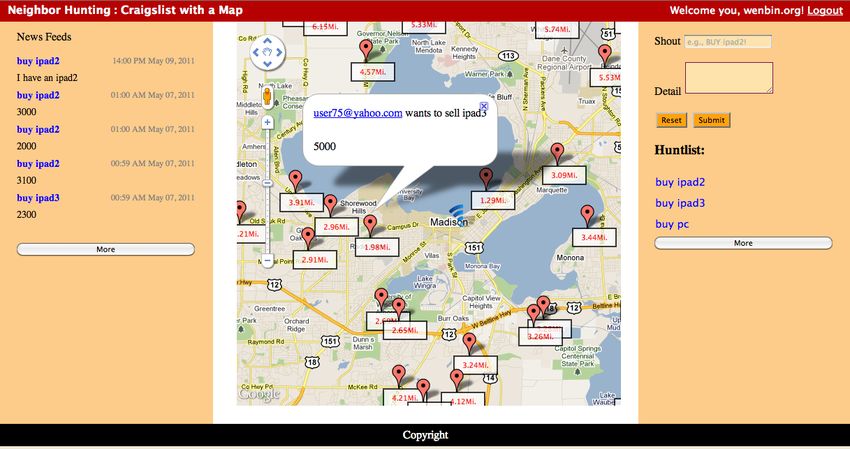
Figure 2 shows the screenshot of NeighborHunting on a web browser. Overall, NeighborHunting has five
major functionalities, from a user’s perspective.
Location Detection. NeighborHunting detects the current user’s location, and marks her location
on the map. Once a user is willing to share her location in our service, her location will be shown on the
map on other user’ browser.
Request Submission. Using NeighborHunting, users enter a “shout” to briefly describe what she
wants. A “shout” is in the format of “action” and “item”, where “action” is a verb, and “item” is a
noun. For example, in the format of “buy pc”, “sell ipad”, etc. NeighborHunting automatically matches
user requests by doing syntax match for “shout”. In addition, users can enter the detailed description
for their requests, such as the specification of a computer.
Requests Matching and Display. NeighborHunting automatically matches different users’ re-
quests, and displays those requests on the map. For example, if you want to “buy pc”, then those
“sell pc” requests match yours. From the map, users can easily tell the distance of other users that are
matched, and then they can click the matched user on the map to see the detailed information, including
the contact information of the matched users.
Hunt List. Users can see a list of their own history requests. By clicking a history request R in
the Hunt List, users focus on peer users’ requests that are only related to the request R. In addition,
users can delete some history request in Hunt List, when a deal is closed or she wants to withdraw the
advertisement from our service.
News Feed. Users can easily see peer users’ latest requests that are related to theirs via News Feed,
which is inspired by Facebook.
Figure 2: Screenshot of NeighborHunting User Interface.
3
2.2 Architecture
Legend:
Location Web 2.0
Detector Utilities Python
HTTP MatchMaker Datastore
request / response
Javascript
Figure 3: Architecture of NeighborHunting.
Figure 3 illustrates the architecture of NeighborHunting, consisting of a server side and a client side,
which communicate with each other via the HTTP protocol.
The server side is responsible for matching requests from different users according to pre-defined rules,
and accessing the backend object datastore that maintains user information, including user requests, user’s
contact information, and user’s locations.
The client side is responsible for detecting and caching the location information of current login user,
rendering a Google map to show matched users’ locations, and initiating data accesses to the server side
by the AJAX technique.
2.3 Server
In this subsection, we will briefly describe the two components on the server side in Section 2.3.1, and
then present the detailed design in the remaining subsections.
2.3.1 Overview
The server consists of two main components, the Match Maker and the Datastore Manager. We implement
the server on Google App Engine.
MatchMaker. The main problem of Craigslist is that a user needs to manually browse a large
amount of posts to find the related matched peers and useful information. This approach does not scale
when there are huge amount of junk posts. To optimize the users’ query accuracy and experience, we
use a rule-based match maker on the server side to filter all the unrelated information and present the
most useful information. For example, if a user wants to buy a personal computer, we will return all
the related sellers who offer personal computers and their contact information. Furthermore, different
matching rules are easily to be plugged into the server.
Datastore. The Google App Engine provides datastore as a persistent storage component, with a
query engine and atomic transactions support. Essentially, accessing datastore is the key to both the
functionality and the performance of the NeighborHunting service. Therefore, we spent a lot of effort to
optimize the datastore access, which will be detailed in the following subsections. For the implementation,
we use the Python APIs of Google App Engine.
In datastore, an entity can be considered as a table in relational database. All essential user data
are stored at Request entity, whose properties include the user ID, the action (e.g., buy, and sell), the
item (e.g., PC and iPad), the detailed content (e.g., description of the product), the users geolocation
4
(latitude and longitude), time stamp, status (whether the request is deleted), and when (a unique id for
paging, details in Section 2.3.4).
2.3.2 Using Memcached to Optimize Hunt List
We retrieve the hunt list of a user from the datastore by issuing the following GQL query:
db.GqlQuery(SELECT * FROM Request WHERE user=:1 and status=False and when
2.3.4 Using Unique Counter for Paging
We display items in the Hunt List or News Feed in the decreasing order of time. In our initial implemen-
tation, we order all items based on the time property in the Request entity. If the main page display 5
items in the list, we record the timestamp of the 5th item as T . When a user clicks the “more” button,
we can retrieve the next 5 items whose timestamp is smaller than T . However, it’s possible that two
items have the same timestamp property in the datastore. If the 6th item has the same time as the 5th
one, we won’t display it in the next 5 items.
To solve this problem, we need to assign a unique id to each request to distinguish requests happening
at the same time. We cannot use primary key of request, because google app engine can not guarantee
the primary key is assigned to requests increasingly. As a result, latest requests may not show up at the
top of the list. What’s worse, we are not able to know the primary key before calling “put” to store
the data in the datastore, so using primary key to construct a unique id is not a good way either. A
better way is that we maintain the global counter of requests in the datastore, for each new request, we
increase this counter by 1 using transaction and use the concatenation of timestamp and counter as the
unique id. This solution is plausible, however, datastore adopts optimistic concurrency control that will
raise frequent rollbacks due to the high contention rate of the global counter update. This will definitely
reduce the concurrency of the application, although shard counters [3] can relieve this problem in some
degree.
We finally adopt a solution in Google I/O [5]. For each user, we maintain the counter of requests
submitted by him. If a user adds an request, we increase the user’s counter by 1 in transaction and con-
catenate timestamp, userid and counter as the unique id. The userid can distinguish requests submitted
by different users, and counter can distinguish requests submitted by same users. Moreover, different
users’ requests will update different counters simultaneously, which doesn’t have data contention problem.
In our implementation, the when property is the unique id of each request that stores the concatenation
of timestamp, userid and counter.
Figure 4 illustrates an example of using the unique counter. The table on the left shows all users’
counters before processing the requests at the bottom. When user1 adds a ”buy ipad” request, we will
update the user1’s counter from 4 to 5 and produce a unique id ”05/04/11@user1@5” without affecting
user2’s counter. At time 05/05/11, user2 adds two requests. We will update user2’s counter in transaction
to guarantee both requests have different ids. As can be seen, all requests have unique ids eventually.
userid counter userid counter
user1 4 user1 5
user2 3 user2 5
05/04/11: user1 buy ipad “05/04/11@user1@5”
05/05/11: user2 sell bike “05/05/11@user2@4”
05/05/11: user2 buy kindle “05/05/11@user2@5”
Figure 4: Example of using unique counter
2.3.5 Using ListProperty to Optimize “Join”
Datastore does not support the conventional join operation as in relational databases. In our design,
we have to do self-join in Request entity for MatchMaker. Our initial implementation tries to address
this limitation as follows. First, for a given user, we retrieve all of her requests from datastore using the
6
same GqlQuery shown in Hunt list section. Then, we use MatchMaker to generate the matched requests.
For each matched request, we submit a GqlQuery to datastore to get the latest updates of this request.
Finally, we aggregate them together and sort them by when property in the Request entity. We denote
this approach as Query-Per-Request. Figure 5 shows an example of Query-Per-Request: to get top 2
news feeds, we generate a Gql query to get the top 2 updates for each request. Then we aggregate the
results and sort them to get the top 2 latest feeds.
Get hunt MatchMaker
list
Get user2's “sell ipad” “buy ipad”
top 2 feeds “buy bike” “sell bike”
SELECT * from Request where SELECT * from Request where
action=”buy” and item = “ipad” top 2 action=”sell” and item = “bike” top 2
(user1, “buy ipad”, 05/06) (user1, “sell bike”, 05/05)
(user4, “sell bike”, 05/06)
Datastore:
(user2, “sell ipad”, 05/04)
(user4, “sell bike”, 05/05)
(user2, “buy bike”, 05/05)
Aggregator
(user1, “sell bike”, 05/05)
(user4, “sell bike”, 05/06)
(user1, “buy ipad”, 05/06)
(user1, “buy ipad”, 05/06)
(user4, “sell bike”, 05/06)
Figure 5: An Example of Query-Per-Request
Aggregating these requests introduces large computation overhead and requires large memory space.
To get the top N items in Hunt List or News Feed, we need to retrieve O(N*M) requests in total, where
M is the number of requests. In practice, most of results are not shown, because each users only see the
top 5 items in either News Feed or Hunt List at the very beginning.
Due to the problems of Query-Per-Request implementation, we redesign the “Join” operation using
Listproperty by using the approach introduced in Google I/O 2009 [6]. Listproperty is a property in the
entity, whose value is a list of items. Each item in the Listproperty is indexed so that given an item, it’s
efficient to retrieve the entities whose Listproperty contains this item. We design an entity RequestIndex
as the inverted index from a request to all matched users. RequestIndex has a Listproperty property,
users. For each request, we store ids of all matched users in users property of it.
We do not put the users property in the Request entity. According to Scudder [4], an entity’s data is
placed in a single column as a byte-encoded ProtocolBuffer. Retrieving the value of any property in an
entity requires deserializing the whole encoded ProtocolBuffer. So the size of an entity affects the accessing
time of it. A request may have thousands of matched users, placing users property at Request entity will
increase the access time. Instead, we design RequestIndex as a child entity of Request. Moreover, we
only get the primary key of matched RequestIndex entities rather than their data to avoid deserialization.
After we get the keys of RequestIndex entities, we call “parent()” to extract their parent entities’ keys
so that we can use those keys to retrieve corresponding Request entities. Using Listproperty, we only
need to issue one query that is unrelated to the number of users’ requests, so this approach scales well.
Also, given a user id, only one datastore access is needed to get the results. Finally, we won’t retrieve
unnecessary results as in Query-Per-Request implementation.
We use the same example in Figure 5 to illustrate how does the Listproperty approach works. We
store “buy bike” requests’ users property with ids of users who have “sell bike” requests, which contains
[“user1”, “user4”]. In this way, to get a user’s news feed, only one Gql query is needed:
db.GqlQuery(”SELECT * FROM RequestIndex where users = :1 and status = False and
when¡:2 order by when desc limit 2”, user, before)
7This query will retrieve top 2 latest requests whose users properties contain current user’s id. In above
example, for user2, we will get (user4, ”sell bike”, 05/06, [users2]) and (user1, ”buy ipad”, 05/06, [user2])
because their users properties contain user2.
2.3.6 Eventual Consistency for Request Insertion and Deletion
When a user inserts or deletes a request, we should make sure two things: On one hand, his recent
updates should be shown in other users’ news feeds. On the other hand, his new feeds should reflect his
recent updates as soon as possible.
To solve the first problem, we design a ListContributor entity to store the mapping between a request
and latest matched user list consistently. When a user adds a new request, its users property will be
set to the latest matched users from ListContributor, so that this request could be found by News Feed
query given the matched user id. When a user deletes a request, we simply set its status property to
True, so the News Feed query will ignore this entity.
Solving the second problem is nontrivial. Synchronously updating News Feed introduces unaccept-
able overhead for large traffic. Figure 6 shows an example to illustrate how complex the synchronous
update is. User3 adds a “buy ipad” request to the datastore, we fetch the latest matched user list from
ListContributor, which contains [user2, user4], and store it in users property of the request. As a result,
this request can be shown at user2 and user4’s news feed. We update the user list of matched request
“sell ipad” to include user3. Once the update is finished, later “sell ipad” requests’ users properties will
include user3, so that user3 could see them in the news feed. Finally, we update the existing “sell ipad”
requests to have latest users properties so that existing requests can be seen by user3.
Datastore: Datastore:
(user2, “sell ipad”, 05/04, [user1]) 4 (user2, “sell ipad”, 05/04, [user1, user3])
(user4, “sell ipad”, 05/05, [user1]) (user4, “sell ipad”, 05/05, [user1, user3])
(user1, “buy ipad”, 05/05, [user2, user4]) (user1, “buy ipad”, 05/05, [user2, user4])
--------------------------------------------------- ---------------------------------------------------
(user3, “buy ipad”, 05/06, [user2, user4]) 1 (user3, “sell ipad”, 05/06, [user2, user4])
--------------------------------------------------- ---------------------------------------------------
(user6, “sell ipad”, 05/07, [user1, user3]) 3 (user6, “buy ipad”, 05/07, [user2])
ListContributor: 2 ListContributor:
(“sell ipad”, [user1]) (“sell ipad”, [user1, user3])
(“buy ipad”, [user2, user4]) (“buy ipad”, [user2, user4])
Figure 6: An example of adding a “buy ipad” request by user3 at 05/06
If we update all of the existing matched requests for each recently-added request in a transaction
before returning to clients, the response time would be unacceptably long, although strong consistency is
maintained. What’s worse, Google App Engine does not allow requests that last for more than 30 seconds
and an entity group can be updated at most 5 times per second. Too many updates will cause datastore
write contention, which causes failure of write operations. These limitation forces us to implement an
“eventually consistent” system to asynchronously update existing matched requests.
In the “eventually consistent” model, for each recently-added or recently-deleted request, we only
update top 10 latest existing matched requests and return to clients immediately so that users can see
some updates at News Feed. Remaining existing requests are updated in the background. In this way,
given a sufficiently long period, all requests will have the latest users properties.
In the implementation, we add two more properties to ListContributor entity: version and up-
dated version. version maintains the latest version number of the record. It will be increased by 1
whenever the record is updated. updated version maintains the smallest version number of all existing
8requests. If updated version is smaller than version, it means some existing requests have out-of-date
data. We also add a version property to RequestIndex entity to maintain the version number of an
request.
ListContributor is updated synchronously, however, RequestIndex is not. To avoid unnecessary up-
dates to RequestIndex table, we invoke batch update jobs lazily rather than invoke them as soon as a
ListContributor entity gets updated. To achieve this, we define a scheduled task (cron job) in Google app
engine which is invoked every 1 minute. When it is invoked, it scans the ListContributor to find out-of-
date entities whose updated version is smaller than version. For every out-of-date entity, the scheduled
task will add a batch update task to task queue to update requests related to it. Two identical tasks will
cause the race conditions of updates in the datastore, we use memcached to guarantee the uniqueness of
tasks most of time. Before adding a task, the cron job will store the task information in the memcached
with entity id as key to “lock” the entity so that later tasks for the same entity can’t be added to the
queue. Once the task finishes, it will “unlock” the entity by removing itself from memcached.
Task queue in Google App Engine provides a queue as a container for tasks. New tasks are inserted
to the tail of the queue. Tasks will be executed in the best effort FIFO order depending on the estimated
latencies of tasks. Since a task cannot run more than 30s, we split the task into small tasks. The first
task invoked by cron job will only update top 20 requests whose version is smaller than the current
version number. When it is done, it will add the second task to the task queue to update the next 20
out-of-date requests. The second task will then add the third task to the task queue, and so forth. We
stop adding new task when the last out-of-date requests get updated. Then, we update ListContributor
entity’s updated version to the version number recorded at the first task, since ListContributor entity may
change during the batch update, and the version number of requests updated by the first task should be
the oldest one.
For every request, most users will view at most 200 updates related to it. To make sure top 200
requests are as consistent as possible, when the task finishes updating the 200th request, it adds a new
task to another queue to update remaining requests. In this way, when the cron job is invoked 1 minute
later, it can add a new task to the first task queue to start updating top 200 requests with consistent
results rather than waiting all requests to be consistent (more than 200 requests).
2.3.7 Handling Write Failures in Datastore
If more than one requests attempt to update a given entity at the same time, at least one of these requests
will fail, because the datastore’s optimistic concurrency control prevents that request from potentially
overwriting the update committed by the previous request [1]. In our implementation, each request needs
to update the “users” property in the same ListContributor entity. The tablet server that holds that
entity will be busy updating data and fails to response to the application if too many same kinds of
requests are added. To solve this problem, we adopt the sharding approach [1] to assign 10 shard entities
for each ListContributor entity in the entity. Then instead of updating the same ListContributor entity
every time, we randomly pick a shard entity to update. In this way, write load will be spread evenly
on 10 shard entities, possibly on 10 different machines, which can highly reduce the chance of datastore
failure. What’s more, when we find that the number of failures per second exceeds a threshold value, we
can adaptively reduce it by increasing the number of shards so that hot entities have more shards than
cold entities.
9get when
property Hunt list
Contributor Request News feed
Map display
update parent
Add/delete requests Legend
Table
ListContributor RequestIndex
scan
Get latest users Task
update
property
Cron job add add add
(per minute) task1 task2 task3 task N
High priority task queue add
taskN+1 taskN+2 taskN+3
add add
Low priority task queue
Figure 7: Entity and Task Interactions in Datastore access
2.3.8 Summary of datastore access
Figure 7 summarizes the of interactions among four entities in NeighborHunting, and two queues of tasks.
We consult Request entity and RequestIndex entity to get Hunt List, News Feed, and the data needed for
displaying locations on the map. When a user adds a request, it will add a new entry in Request entity
whose when property is generated from Contributor entity. Also, ListContributor entity will update the
latest matched user list and the top 10 latest requests are updated in RequestIndex. To resolve the
potential inconsistency, a cron job is woken up every minute, it will scans the ListContributor entity and
add a task for each out-of-date ListContributor entity to high priority task queue to update RequestIndex.
Each task gets the latest value from ListContributor table and updates the 20 corresponding requests in
RequestIndex. When it’s done, it adds another task to the task queue. The new task does similar things
until over 200 requests get latest values. Remaining inconsistent requests will be updated by tasks on low
priority task queue. When all requests have consistent values, the final task changes the updated version
to the latest version number in ListContributor table.
2.4 Client
The client side runs javascript code in web browsers with two major responsibilities: location detection
and Web 2.0 utilities for improving user experience.
2.4.1 Location Detection
Since we focus on improving the users’ social experience, the geolocation information of users is key to
our system. The geolocation API in HTML5 allows users to share their location easily with trusted web
sites. The latitude and longitude can be retrived by JavaScript on the webpage. The geolocation API is
supported by most modern browsers and some mobile devices, such as Firefox 3.5+, Safari 5.0+, Chrome
5.0+, Opera 10.6+, iPhone 3.0+, Android 2.0+, etc.
On client side, when the user accesses our website, the browser will pop out a window to ask the user
for permission to use the geolocation. Once the user agrees, our system will show her location on the
Google map.
The users may experience a long latency to get their geolocation, due to the unstable support for
the geolocation service on browsers. To improve the users experience, we cache the users’ geolocation
on client side HTML5 local store when we can successfully retrieve the geolocation information, where
10HTML5 provides a new way for web pages to store named key-value pairs within the client web browser.
The API is similar to all other key-value stores, where you can store data by put(key, data), and retrieve
that data with the same key by get(key). The key in the local store is just a string to identify the
geolocation, and the value is the latest latitude and longitude. We set a timeout for geolocation service.
After the timeout, we will read from the last geolocation from local store.
2.4.2 Web 2.0 Utilities
Google Map. Google Map API provides a simple solution for map-based applications for both the
desktop and mobile devices. Given the geolocation with latitude and longitude, the location can be
visualized as a mark on Google map.
Once the user submits her request to the server, our server will return the location information of a
list of related matched users. With such information, the client side will visualize all these matched users
on the map. In addition, we allow the user to contact other peers by email, which is shown in the dialog
box on the Google map.
AJAX. We leverage AJAX technique (asynchronous JavaScript and XML) to improve user experience
of NeighborHunting. We use AJAX technique for request submission, displaying HuntList, and News
Feed, where the client-server communication will not cause the whole web page to refresh.
3 Evaluation
In this section, we present the performance evaluation result for NeighborHunting on server side (Sec-
tion 3.1) and client side (Section 3.2).
3.1 Server
3.1.1 Performance of using Listproperty
We conduct an experiment to evaluate the performance of both Query-Per-Request and Listproperty ap-
proaches. In the experiment, we fetch the top 10 news feeds from users with different number of requests.
As shown at Figure 8. The computation time of Query-Per-Request implementation is proportional to
the number of users’ requests. However, ListProperty implementation’s time remains almost constant for
all users, which is the index lookup time plus entity fetch time with primary keys.
3.1.2 Measure the correctness
If it takes a long time to reach consistent state, users will always see the stale data and may miss some
important updates. Thus, it’s necessary to measure how long the system uses to make all the data up to
date.
In this experiment, we randomly insert 8500 updates to the RequestIndex table. These updates are
all related to about 100 different requests in the ListContributor entity. Initially, all the updates have
the latest users property in the ListContributor entity. Then we write a script to increase the version
properties of all requests by 1 to make all 8500 updates have the stale data. When a cron job is invoked,
it will scan ListContributor and start adding tasks to bring data up to date. During this process, we use
a monitor script to compute the percentage of consistent data in the datastore repeatedly. The result is
shown at Figure 9. It takes 174 seconds for our system to update all the data. Consistent rate does not
113.5
Query-Per-Request
Listproperty
3
2.5
Time (Second)
2
1.5
1
0.5
0
10 20 30 40 50
The number of requests
Figure 8: Performance of Query-Per-Request implementation and ListProperty implementation
increase at the first 45 seconds, because the cron job isn’t invoked as soon as the data become inconsistent.
Furthermore, it takes time for cron job to find out-of-date requests and create a update task for it.
100 %
80 %
Percentage of consistent data
60 %
40 %
20 %
0%
2
9
9
5
1
7
0
8
3
7
2
4
10
20
30
40
50
56
63
69
75
82
88
95
10
10
11
12
13
13
15
15
16
16
17
17
0
Running Time (Second)
Figure 9: Total time to reach consistent state
3.1.3 Evaluate Write Failure Handling
We conduct the experiment by creating certain number of threads, to compare the non-shard system
and shard system. Each thread keeps adding a request to the datastore. As shown at Figure 10, when
at most 16 requests are added to the datastore in one second, the write in datastore does not fail too
much. However, when more and more requests are added, the write operation in datastore fails much
more frequently without sharding. In contrast, if we use 10 shard entities, the failure rate is as low as
0.002 failures per second, which greatly improve the reliability of our application.
126
No-shard
10-shard
5
Failures per second
4
3
2
1
0
8 16 32 64
Requests per second
Figure 10: Failure rates of no-shard system and 10-shard system
3.1.4 Throughput in the cloud
We evaluate both read and write throughputs for accessing datastore in Google App Engine, which is the
major limiting factor to the NeighborHunting service’s overal performance. In this experiment, we write
a script to fork 200 curl 3 programs at a client computer to request for NeighborHunting service, which
represents we have 200 clients accessing our service at the same time. We set a timer at the server side,
and measure the throughputs for the datastore write and read. Each curl invocation writes or reads a
record of Request in the datastore.
The read throughput is 3382 requests per second on average, and the write throughput is 13 requests
per second on average without any errors. We can see that, the write throughput is substantially lower
than the read throughput. This matches our workload, where a user is more likely to browse her HuntList,
and News Feed, and to navigate the map to find the matched peers, rather than submitting requests
frequently.
3.2 Client
3.2.1 Effect of local store
We set the timeout of geolocation service to be 5 seconds, which is in practice an acceptable timeout
for interactive applications. If geolocation information is not returned within 5 seconds, then a callback
function will be triggered to read the geolocation from HTML 5 local store.
We evaluate the latency difference between using and not using HTML 5 local store. In the experiment,
a single HTTP request is sent from the client browser to the server side, and we calculate the latency
from the moment that sends geolocation request to the moment that we get the response of a coordinate.
We set the timer in Javascript on the client side. We use Safari 5.0 as the client browser which supports
HTML 5 with local store, but has relatively unstable geolocation service from our experience. Over 10
tests, the average latency is 17.3 seconds without using HTML5 local store, while the average latency is
reduced to 6.5 seconds using local store. This greatly improves the interactiveness for the clients.
3
http://curl.haxx.se
133.2.2 End to end latency
We use HttpWatch 4 to measure the end-to-end latency of neighborhunting, which is from the moment
the browser sends an HTTP request to the server side, to the moment the browser renders the entire web
page. HttpWatch is an integrated HTTP sniffer that measures website performance. The current version
of HttpWatch only supports IE and Firefox, so we conduct our experiment only on the latest version of
these two browsers.
We measure two primary use cases of neighborhunting. One is to browse the web page of neigh-
borhunting after login (denoted as PAGE LOAD), and the other is to submit one request for posting an
advertisement (denoted as REQ SUBMIT). PAGE LOAD represents the read-intensive workload, while
REQ SUBMIT represents the write-intensive workload.
We measure the latency of both PAGE LOAD and REQ SUBMIT for 10 times on IE and Firefox
respectively, and take the average of the result on both browsers, since the result on both browsers is
similar. The latency for PAGE LOAD is 6.6 seconds, while it is 2.3 seconds for REQ SUBMIT. The
reason why REQ SUBMIT latency is lower is because the browser only need to update a small portion of
the web page after users submit a request, thanks to the usage of AJAX technique to avoid the whole-page
refresh.
4 Future Work and Summary
This report presents NeighborHunting, which provides a classified advertisement service that automat-
ically matches user requests, detects and displays user locations. We leverage the state-of-the-art tech-
niques on both client side and server side. Particularly, we use HTML5 local store for client side caching,
and use memcached for server side caching. We use some novel techniques to address the limitation
of datastore, and use Task Queue API of Google App Engine to implement an eventual consistency
mechanism to improve the overall performance.
There are three major improvements for the NeighborHunting service in our mind:
• Semantics-based Matching. Current implementation only supports syntax-based matching, and
the semantics-based matching would collaborate with natural language processing techniques and
machine learning techniques to further improve user experience. By doing so, we can open the
opportunity for users to define their own matching rules, instead of hard-coding in advance.
• Importing Craigslist Data. To integrate external services’ data into NeighborHunting allows users
to access more information, so that they may get what they need more quickly.
• More client-side caching. We cache geolocation in browser’s local store, but we can cache more data,
e.g., the google map’s data as in iPhone. This allows the fully offline usage of our service when the
cloud-side service is down or the internet connectivity is lost. Therefore, client-side caching can be
used to address the cloud-side reliability issue.
References
[1] J. Cooper. Avoiding datastore contention. Google App Engine, 2009.
[2] J. Cooper. How entities and indexes are stored. Google App Engine, 2009.
4
http://www.httpwatch.com/
14[3] J. Gregorio. Sharding counters. Google App Engine, 2008.
[4] J. Scudder. Life of a datastore write. Google App Engine, 2009.
[5] B. Slatkin. Building scalable web applications with google app engine. Google I/O, 2008.
[6] B. Slatkin. Building scalable, complex apps on app engine. Google I/O, 2009.
15You can also read

















































