PDAugment: Data Augmentation by Pitch and Duration Adjustments for Automatic Lyrics Transcription
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

PDAugment: Data Augmentation by Pitch and Duration Adjustments for
Automatic Lyrics Transcription
Chen Zhang1 , Jiaxing Yu1 , LuChin Chang1 , Xu Tan2 , Jiawei Chen3 , Tao Qin2 , Kejun Zhang1
1
Zhejiang University, China
2
Microsoft Research Asia
3
South China University of Technology
zc99@zju.edu.cn, yujxzju@gmail.com, changluchin@gmail.com, xuta@microsoft.com,
csjiaweichen@mail.scut.edu.cn, taoqin@microsoft.com, zhangkejun@zju.edu.cn
arXiv:2109.07940v2 [eess.AS] 17 Sep 2021
Abstract duration, which leads to the sparsity of training data and fur-
ther aggravates the problem of the lack of data. Though a
Automatic lyrics transcription (ALT), which can be regarded straightforward method is to use speech data to enhance the
as automatic speech recognition (ASR) on singing voice, is training data of ALT, the performance gain is not large be-
an interesting and practical topic in academia and industry.
ALT has not been well developed mainly due to the dearth
cause there are significant differences between speech and
of paired singing voice and lyrics datasets for model training. singing voice. For example, the singing voice have some
Considering that there is a large amount of ASR training data, music-specific acoustic characteristics (Kruspe and Fraun-
a straightforward method is to leverage ASR data to enhance hofer 2016; Mesaros and Virtanen 2009) (details can be seen
ALT training. However, the improvement is marginal when in Section 2.2) – the large variation of syllable duration and
training the ALT system directly with ASR data, because highly flexible pitch contours are very common in singing,
of the gap between the singing voice and standard speech but rarely be seen in speech (Tsai, Tuan, and Lee 2018).
data which is rooted in music-specific acoustic characteris-
Previous work has already made some attempts in using
tics in singing voice. In this paper, we propose PDAugment,
a data augmentation method that adjusts pitch and duration speech data to improve the performance of ALT system: Fu-
of speech at syllable level under the guidance of music scores jihara et al. (2006) pretrain a recognizer with speech data and
to help ALT training. Specifically, we adjust the pitch and then built a language model containing the vowel sequences
duration of each syllable in natural speech to those of the cor- in the lyrics to further introduce the knowledge from the mu-
responding note extracted from music scores, so as to narrow sic domain. However, it only took advantage of the semantic
the gap between natural speech and singing voice. Experi- information from lyrics and did not consider the acoustic
ments on DSing30 and Dali corpus show that the ALT system properties of singing voice. Mesaros and Virtanen (2009)
equipped with our PDAugment outperforms previous state- adapted a pre-trained GMM-HMM based speech recognizer
of-the-art systems by 5.9% and 18.1% WERs respectively, to singing voice domain by speaker adaptation technique,
demonstrating the effectiveness of PDAugment for ALT.
but it only shifted the means and variances of GMM compo-
nents based on global statistics without considering the local
Content Areas – automatic lyrics transcription; data information, resulting in very limited improvement. Some
augmentation; automatic speech recognition; singing voice. other work (Kruspe and Fraunhofer 2015; Basak et al. 2021)
tried to artificially generate “song-like” data from speech for
1 Introduction model training. Kruspe and Fraunhofer (2015) applied time
Automatic lyrics transcription (ALT), which recognizes stretching and pitch shifting to natural speech in a random
lyrics from singing voice, is useful in many applica- manner, which enriches the distribution of pitch and duration
tions, such as lyrics-to-music alignment, query-by-singing, in “songified” speech data to a certain extent. Nonetheless,
karaoke performance evaluation, keyword spotting, and so the adjustments are random, so there is still a gap between
on. ALT on singing voice can be regarded as a counterpart of the patterns of “songified” speech data and those of real
automatic speech recognition (ASR) on natural speech. Al- singing voice. Compared to Kruspe and Fraunhofer (2015),
though ASR has witnessed rapid progress and brought con- Basak et al. (2021) further took advantage of real singing
venience to people in daily life in recent years (Graves et al. voice data. It transferred natural speech to singing voice do-
2006; Graves 2012; Chan et al. 2016; Park et al. 2019; Li main with the guidance of real opera data. But it only took
et al. 2020; Xu et al. 2020), there is not an ALT system that the pitch contours into account, ignoring duration, another
has the same level of high accuracy and robustness as the key characteristic. Besides, it directly replaced the pitch con-
current ASR systems. The main challenge of developing a tours with those of the real opera data, without considering
robust ALT system is the scarcity of available paired singing the alignment of the note and syllable, which may result in
voice and lyrics datasets that can be used for the ALT model the low quality of synthesized audio.
training. To make matters worse, compared with ASR, ALT In this paper, we propose PDAugment, a syllable-level
is a more challenging task – the same content accompanied data augmentation method by adjusting pitch and duration
with different melodies will produce different pitches and under the guidance of music scores to generate more con-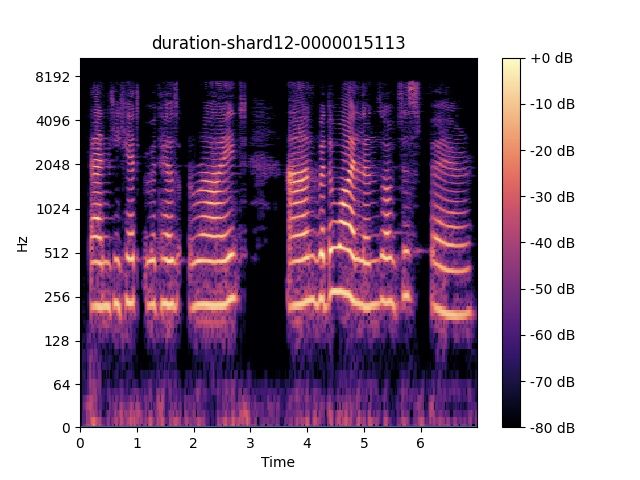
sistent training data for ALT training. In order to narrow the Some work took advantage of the characteristics of mu-
gap between the adjusted speech and singing voice, we ad- sic itself: Gupta, Li, and Wang (2018) extended the length
just the speech at syllable level to make it more in line with of pronounced vowels in output sequences by increasing the
the characteristics of the singing voice. We try to make the probability of a frame with the same phoneme after a certain
speech more closely fit the music score, so as to achieve the vowel frame because there are a lot of long vowels in singing
effect of “singing out” the speech content. PDAugment ad- voice. Kruspe and Fraunhofer (2016) boosted the ALT sys-
justs natural speech data by the following steps: 1) extracts tem by using the newly generated alignment (Mesaros and
note information from music scores to get the pitch and du- Virtanen 2008) of singing and lyrics. Gupta, Yılmaz, and Li
ration patterns of music; 2) aligns the speech and notes at (2020) tried to make use of the background music as extra
syllable level; 3) adjusts the pitch and duration of sylla- information to improve the recognition accuracy. However,
bles in natural speech to match those in aligned note. By they just designed some hard constraints or added extra in-
doing so, PDAugment can add the information of music- formation according to the knowledge from the music do-
specific acoustic characteristics into adjusted speech in a main, and still did not solve the problem of data scarcity.
more reasonable manner, and narrow the gap between ad- Considering the lack of singing voice database, some
justed speech and singing voice. work aimed at providing a relatively large singing voice
Our contributions can be summarized as follows: dataset: Dabike and Barker (2019) collected DSing dataset
• We develop PDAugment, a data augmentation method to from real-world user information. Demirel, Ahlbäck, and
enhance the training data for ALT training, by adjusting Dixon (2020) built a cascade pipeline with convolutional
the pitch and duration of natural speech at syllable level time-delay neural networks with self-attention based on DS-
with note information extracted from real music scores. ing30 dataset and provided a baseline for ALT task. Some
other work leveraged natural speech data for ALT train-
• We conduct experiments in two singing voice datasets:
ing: they based on pre-trained automatic speech recognition
DSing30 dataset and Dali corpus. The adjusted Lib-
models and then made some adaptations to improve the per-
riSpeech corpus is combined with the singing voice cor-
formance on singing voice: Fujihara et al. (2006) built a lan-
pus for ALT training. In DSing30 dataset, the ALT sys-
guage model containing the vowel sequences in the lyrics
tem with PDAugment outperforms previous state-of-the-
but only used the semantic information from lyrics and ig-
art system and Random Aug by 5.9% and 7.8% WERs
nored the acoustic properties of singing voice. Mesaros and
respectively. In Dali corpus, PDAugment outperforms
Virtanen (2009) used speaker adaptation technique by shift-
them by 24.9% and 18.1% WERs respectively. Com-
ing the GMM components only with global statistics but did
pared to adding ASR data directly into the training data,
not consider the local information.
our PDAugment has 10.7% and 21.7% WERs reduction
in two datasets. However, singing voice has some music-specific acous-
tic characteristics which are not in speech, limiting the per-
• We analyze the adjusted speech by statistics and visual- formance when training the ALT system directly with natu-
ization, and find that PDAugment can significantly com- ral speech data. Some work tried to synthesize “song-like”
pensate the gap between speech and singing voice. At the data from natural speech to make up for this gap: Kruspe
same time, the adjusted speech can keep the relatively and Fraunhofer (2015) generated “songified” speech data
good quality (the audio samples can be found in supple- by time stretching, pitch shifting, and adding vibrato. How-
mentary materials). ever, the degrees of these adjustments are randomly selected
within a range, without using the patterns in real music.
2 Background Basak et al. (2021) took use of the F0 contours in real opera
In this section, we introduce the background of this work, data and converted the speech to singing voice through style
including an overview of previous work related to automatic transfer. Specifically, they decomposed the F0 contours from
lyrics transcription and the differences between speech and the real opera data, obtained the spectral envelope and the
singing voice. aperiodic parameter from the natural speech, and then used
these parameters to synthesize the singing voice version of
2.1 Automatic Lyrics Transcription the original speech. Nonetheless, in real singing voice, the
The lyrics of a song provide the textual information of note and the syllable are often aligned, but Basak et al.
singing voice and are as important as the melody when con- (2021) did not perform any alignment of the F0 contours
tributing to the emotional perception for listeners (Ali and of singing voice with the speech signal. This misalignment
Peynircioğlu 2006). Automatic lyrics transcription (ALT) may lead to the change of pitch within a consonant phoneme
aims to recognize lyrics from singing voice. In auto- (in normal circumstances, the pitch only changes between
matic music information retrieval and music analysis, lyrics two phonemes or in vowels), which further causes distortion
transcription plays a role as important as melody extrac- of the synthesized audio and limits the performance of ALT
tion (Hosoya et al. 2005). However, ALT is a more chal- system. Besides, they only adjusted the F0 contours, which
lenging task than ASR – not like speech, in singing voice, is not enough to narrow the gap between speech and singing
the same content aligned with different melodies will have voice.
different pitches and duration, which results in the sparsity In this paper, we propose PDAugment, which improves
of training data. So it is more difficult to build an ALT sys- the above adjustment methods by using real music scores
tem than an ASR system without enough training data. and syllable-level alignment to adjust the pitch and duration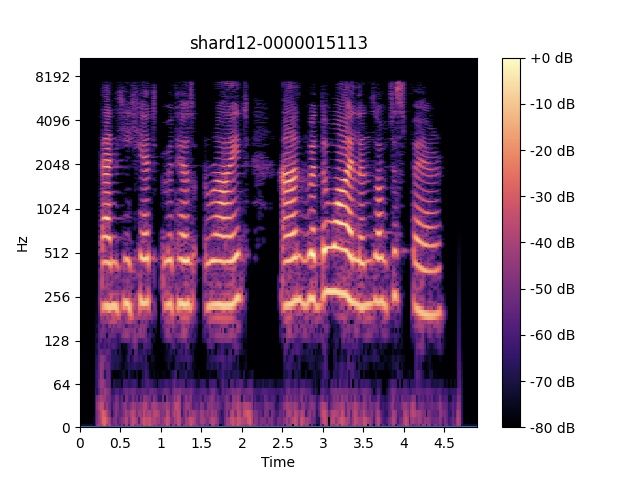
of natural speech, so as to solve the problem of insufficient Property Speech Singing Voice
singing voice data. Pitch Range (semitone) 12.71 14.61
Pitch Smoothness 0.93 0.84
2.2 Speech vs. Singing Voice Duration Range (s) 0.44 2.40
Duration Variance 0.01 0.11
In a sense, singing voice can be considered as a special
form of speech, but there are still a lot of discrepancies
between them (Loscos, Cano, and Bonada 1999; Mesaros Table 1: The differences of acoustic properties between
2013; Kruspe and Fraunhofer 2014). These discrepancies speech and singing voice.
make it inappropriate to transcribe the lyrics from singing
voice using a speech recognition model trained on ASR data
directly. In order to demonstrate the discrepancies, we ran- long vowels or make artistic modifications to the pronunci-
domly select 10K sentences from LibriSpeech (Panayotov ation of some words to make them sound more melodious,
et al. 2015) for speech corpus and Dali (Meseguer-Brocal, though it will result in a loss of intelligibility. Considering
Cohen-Hadria, and Peeters 2019) for singing voice dataset, that some characteristics are hard to be quantified, in this
and make some statistics on them. The natural speech and work, we start with pitch and duration to build a prototype
singing voice mainly differ in the following aspects and the and propose PDAugment to augment ALT training data by
analysis results are list in Table 1. adjusting pitch and duration of speech at syllable level ac-
cording to music scores.
Pitch We extract the pitch contours from singing voice and
speech, and compare the range and smoothness of the pitch. 3 Method
Here we use semitone as the unit of pitch.
Pitch Range Generally speaking, the range of the pitch in In this section, we introduce the details of our proposed
singing voice is larger than that in speech. Loscos, Cano, and PDAugment: a data augmentation method by music score-
Bonada (1999) has pointed out that the frequency range in guided syllable-level pitch and duration adjustments for au-
singing voice can be much larger compared to that in speech. tomatic lyrics transcription. We first describe the overall
For each sentence, we calculate the pitch range (the max- pipeline of the ALT system and then introduce the designs
imum pitch value minus the minimum pitch value in this of each component in PDAugment respectively.
sentence). After averaging the pitch range of overall 10K
sentences in the corpus, the average values are listed in Pitch
Range in Table 1.
Pitch Smoothness The pitch of each frame in a certain sylla-
ble (when it is corresponding to a note) in singing voice re-
mains almost constant whereas in speech the pitch changes
freely along with the audio frames in a syllable. We call the
characteristic of maintaining local stability within a sylla-
ble as Pitch Smoothness. Specifically, we calculate the pitch
difference between every two adjacent frames in a sentence
and average it across the entire corpus of 10K sentences.
The smaller the value of Pitch Smoothness, the smoother the
pitch contour. The results can be seen in Pitch Smoothness
of Table 1.
Duration We also analyze and compare the range and sta-
bility of the syllable duration in singing voice and speech.
The duration of each syllable varying a lot along with the
melody in singing voice. While in speech, it depends on the
pronunciation habits of the certain speaker. Figure 1: The overall pipeline of the ALT system equipped
Duration Range For each sentence, we calculate the differ- with PDAugment.
ence between the duration of the longest syllable and short-
est syllable as the duration range. The average values of the
duration ranges in the entire corpus are shown as Duration
Range in Table 1. 3.1 Pipeline Overview
Duration Variance We calculate the variance of the duration For automatic lyrics transcription, we follow the practice
of syllables in each sentence and average the variances of of existed automatic speech recognition system (Watanabe
all sentences in the whole corpus. The results are listed as et al. 2018) and choose Conformer encoder (Gulati et al.
Duration Variance in Table 1 to reflect the flexibility of du- 2020) and Transformer decoder (Vaswani et al. 2017) as our
ration in singing voice. basic model architecture. Different from standard ASR sys-
Besides the differences in the characteristics we men- tems, we add a PDAugment module in front of the encoder
tioned above, sometimes singers may add vibrato in some as shown in Figure 1, to apply syllable-level adjustments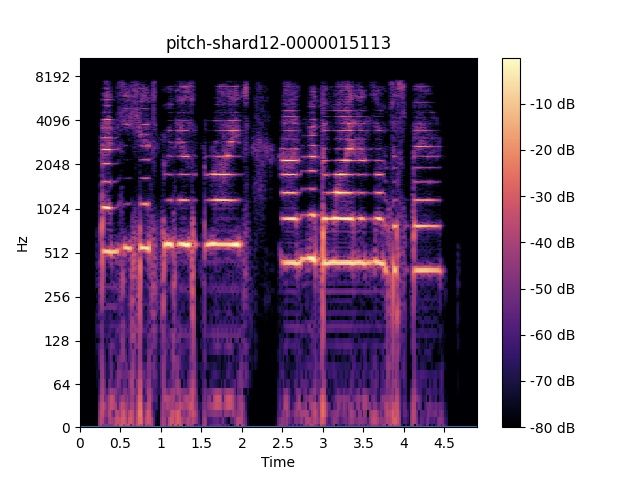
to pitch and duration of the input natural speech accord- singing voice, one syllable is aligned with one note. Only
ing to the information of aligned notes. When the input of when the time length ratio of the syllable in speech and the
ALT system is singing voice, we just do not enable PDAug- note in melody exceeds the predefined thresholds (we set
ment module. When the input is speech, PDAugment mod- the 0.5 as lower bound and 2 as upper bound in practice),
ule takes the note information extracted from music scores we generate one-to-many or many-to-one mappings to pre-
as extra input to adjust the pitch and duration of speech, and vent audio distortion after adjustments.
then adds the adjusted speech into training data to enhance 3) We aggregate the syllable-level alignment of text and
the ALT model. The loss function of the ALT model con- speech, and the syllable-to-note mappings to generate the
sists of decoder loss Ldec , and ctc loss (on top of encoder) syllable-level alignment of speech and note (in melody) as
Lctc (Wang et al. 2020): L = (1 − λ)Ldec + λLctc , where λ the input of the pitch and duration adjusters.
is a hyperparameter to trade-off the two loss terms. Consid-
ering that lyrics may contain more musical-specific expres- 3.3 Pitch Adjuster
sions which are rarely seen in natural speech, the probability
Pitch adjuster adjusts the pitch of input speech at syllable
distributions of lyrics and standard text are quite different.
level according to the aligned notes. Specifically, we use
We train the language model with in-domain lyrics data and
WORLD (Morise, Yokomori, and Ozawa 2016), a fast and
then fuse it with ALT model in the beam search of decoding
high-quality vocoder-based speech synthesis system to im-
stage.
plement the adjustment. The WORLD system3 parameter-
We try to make the speech fit the patterns of singing voice izes speech into three components: fundamental frequency
more naturally as well as to achieve the effect of “singing (F0), aperiodicity, and spectral envelope and can reconstruct
out” the speech by PDAugment, so we adjust the pitch and the speech with only estimated parameters. We use WORLD
duration of speech at syllable level according to those of cor- to estimate the three parameters of natural speech and only
responding notes in music scores instead of applying ran- adjust the F0 contours according to that of corresponding
dom adjustments. To do so, we propose PDAugment mod- notes. Then we synthesize speech with adjusted F0 accom-
ule, which consists of three key components: 1) speech-note panied with original aperiodicity and spectral envelope. Fig-
aligner, which generates the syllable-level alignment to de- ure 2 shows the F0 contours before and after pitch adjuster.
cide what the corresponding note of a certain syllable is for
subsequent adjusters; 2) pitch adjuster, which adjusts the Note
pitch of each syllable in speech according to that of aligned
notes; and 3) duration adjuster, which adjusts the duration of Phoneme ow pax nihng hihz daor
each syllable in speech to be in line with the duration of the
corresponding notes. We introduce each part in the follow-
ing subsections. Speech
3.2 Speech-Note Aligner
According to linguistic and musical knowledge, in singing
voice, syllable can be viewed as the smallest textual unit cor- Augmented
Speech
responds to note. PDAgument adjusts the pitch and duration
of natural speech at syllable level under the guidance of note
information obtained from the music scores. In order to ap-
ply the syllable-level adjustments, we propose speech-note
aligner, which aims to align the speech and note (in melody) Figure 2: The change of F0 contour after pitch adjuster. The
at syllable level. content of this example is “opening his door”.
The textual content can serve as the bridge of aligning
note of melody with the speech. Specifically, our speech- Pitch adjuster calculates the pitch difference between
note aligner aligns the speech with note (in melody) in the speech and note with syllable-level alignment and adjusts
following steps: F0 contours of speech accordingly. Some details are as fol-
1) In order to obtain the syllable-level alignment of text and lows: 1) Considering that the quality of synthesized speech
speech, we first convert the text to phoneme by an open- will drop sharply when the range of adjustment is too large,
source tool1 and then align the text with speech audio by the we need to keep it within a reasonable threshold. Specifi-
Montreal forced aligner (MFA) (McAuliffe et al. 2017) tool2 cally, we calculate the average pitch of the speech and the
at phoneme level. Next, we group several phonemes into a corresponding melody respectively. When the average pitch
syllable according to the linguistic rules (Kearns 2020) and of speech is too different from that of the corresponding
get the syllable-level alignment of text and speech. melody (e.g., exceeding a threshold, which is 5 in our ex-
2) For the syllable-to-note mappings, we set one syllable to periment), we shift the pitch of the entire note sequence to
correspond to one note by default, because in most cases of make the difference within the threshold and use the shifted
note for adjustment, otherwise, keep the pitch of the original
1
https://github.com/bootphon/phonemizer
2 3
https://github.com/MontrealCorpusTools/Montreal-Forced- https://github.com/JeremyCCHsu/Python-Wrapper-for-
Aligner World-Vocodernote unchanged; 2) To maintain smooth transitions in syn- annotation of the dataset provided by Meseguer-Brocal,
thesized speech and prevent speech from being interrupted, Cohen-Hadria, and Peeters (2019)4 and divide the dataset
we perform pitch interpolation for the frames between two into training, development, and test with a proportion of
syllables. 3) When a syllable is mapped to multiple notes, 8:1:1 without any singers overlapping in each partition. We
we segment the speech of this syllable in proportion to the convert all the singing voice waveforms in our experiments
duration of notes and adjust the pitch of each segment ac- into mel-spectrogram following Zhang et al. (2020b) with a
cording to the corresponding note. frame size of 25 ms and hop size of 10 ms.
3.4 Duration Adjuster Natural Speech Dataset Following the common practice
in previous ASR work (Amodei et al. 2016; Gulati et al.
Duration adjuster changes the duration of input speech to 2020; Zhang et al. 2020c), we choose the widely used
align with the duration of the corresponding note. As shown LibriSpeech (Panayotov et al. 2015) corpus as the natural
in Figure 3, instead of scaling the whole syllable, we only speech dataset in our experiments. The LibriSpeech corpus
scale the length of vowels and keep the length of con- contains 960 hours of speech sampled at 16 kHz with 1129
sonants unchanged, because the duration of consonants in female speakers and 1210 male speakers. We use the offi-
singing voice is not significantly longer than that in speech, cial training partition described in Panayotov et al. (2015).
while long vowels are common in singing voice (Kruspe Similar to singing voice, we convert the speech into mel-
and Fraunhofer 2015). There are one-to-many mappings spectrogram with the same setting.
and many-to-one mappings in the syllable-level alignment.
When multiple syllables are mapped to one note, we calcu- Music Score Dataset In this work, we choose the
late the total length of the syllables and adjust the length of FreeMidi dataset5 and only use the pop songs among them6
all vowels in these syllables in proportion. When multiple because almost all of the songs in our singing voice datasets
notes are mapped to one syllable, we adjust the length of the are pop music. The pop music subset of FreeMidi has about
vowel, so that the total length of this syllable is equal to the 4000 MIDI files, which are used to provide note information
total length of these notes. for PDAugment module. We use miditoolkit7 to extract the
note information from MIDI files and then feed them into
h ih z d ao r
the PDAugment module along with natural speech.
Phoneme
Speech Lyrics Corpus In order to construct a language model
with more in-domain knowledge, we deliberately collected
a large amount of lyrics data to build our lyrics corpus for
Augmented
Speech
language model training. Besides the training text of DS-
ing30 dataset and Dali corpus, we collect lyrics of English
Note
pop songs from the Web. We crawl about 46M lines of lyrics
and obtain nearly 17M sentences after removing the dupli-
Figure 3: The change of duration after duration adjuster. The cation. We attach a subset of the collected lyrics corpus in
content of this example is “his door”. The left block shows the supplementary material.
the case of lengthening the duration of speech and the right
shows the case of shortening the duration. 4.2 Model Configuration
ALT Model We choose Conformer encoder (Gulati et al.
2020) and Transformer decoder (Vaswani et al. 2017) as the
4 Experimental Settings basic model architecture in our experiments since the effec-
In this section, we describe the experimental settings, in- tiveness of the structure has been proved in ASR. We stack
cluding datasets, model configuration, and the details of N = 12 layers of Conformer blocks in encoder and N = 6
training, inference, and evaluation. layers of Transformer blocks in decoder. The hidden size of
both Conformer blocks and Transformer blocks are set to
4.1 Datasets 512, and the filter size of the feed-forward layer is set to
2048. The number of the attention head is set to 8 and the
Singing Voice Datasets We conduct experiments on two dropout rate is set to 0.1.
singing voice datasets to verify the effectiveness of our
PDAugment: DSing30 dataset (Dabike and Barker 2019) Language Model Our language model is based on Trans-
and Dali corpus (Meseguer-Brocal, Cohen-Hadria, and former encoder with 16 layers, 8 heads of attention, filter
Peeters 2019). DSing30 dataset consists of about 4K mono- size of 2048, and embedding unit of 128. The language
phonic Karaoke recordings of English pop songs with nearly model is pre-trained separately and then integrated with ALT
80K utterances, performed by 3,205 singers. We use the par- model in the decoding stage.
tition provided by Dabike and Barker (2019) to make a fair
4
comparison with them. Dali corpus is another large dataset https://github.com/gabolsgabs/DALI
5
of synchronized audio, lyrics, and notes. It consists of 1200 https://freemidi.org
6
English polyphonic songs with a total duration of 70 hours. https://freemidi.org/genre-pop
7
Following Basak et al. (2021), we use the sentence-level https://github.com/YatingMusic/miditoolkit4.3 Training Details Method Dev Test
During ALT training, after PDAugment module, we apply Naive ALT 28.2 27.4
the SpecAugment (Park et al. 2019) and speed perturbation. ASR Augmented 20.8 20.5
We use SpecAugment with frequency mask from 0 to 30 Random Aug (Kruspe and Fraunhofer 2015) 17.9 17.6
bins, time mask from 0 to 40 frames, time warp window of Demirel, Ahlbäck, and Dixon (2020) 17.7 15.7
5. The speed perturbation factors are set to 0.9 and 1.1. We PDAugment 10.1 9.8
train the ALT model for 35 epochs on 2 GeForce RTX 3090
GPUs with a batch size of 175K frames. Following Zhang Table 2: The WERs (%) of DSing30 dataset.
et al. (2020a), we use Adam optimizer (Kingma and Ba
2014) and set β1 , β2 , ε to 0.9, 0.98 and 10−9 respectively.
We apply label smoothing with 0.1 weight when calculating Method Dev Test
the Ldec and set the λ described in Section 3.1 to 0.3. We Naive ALT 80.9 86.3
train the language model for 25 epochs on 2 GeForce RTX ASR Augmented 75.5 75.7
3090 GPUs with Adam optimizer. Random Aug (Kruspe and Fraunhofer 2015) 69.8 72.1
Our code of basic model architecture is implemented Basak et al. (2021) 75.2 78.9
based on the ESPnet toolkit (Watanabe et al. 2018)8 . We at- PDAugment 53.4 54.0
tach our code of PDAugment module to the supplementary
materials. Table 3: The WERs (%) of Dali corpus.
4.4 Inference and Evaluation
During inference, we fuse the ALT model with the language demonstrates the difficulty of the ALT task. After adding
model which is pre-trained with lyrics corpus. Following ASR data for ALT training, the performances of ASR Aug-
previous ALT work (Demirel, Ahlbäck, and Dixon 2020; mented setting in both of the two datasets have been im-
Basak et al. 2021), we use the word error rate (WER) as the proved slightly compared to Naive ALT, but still with rel-
metric when evaluating the accuracy of lyrics transcription. atively high WERs, which indicates the limitation of using
ASR training data directly.
5 Results and Analyses When applying the adjustments, a question is that if we
In this section, we first report the main experiment results, adjust the pitch and duration with random ranges without
and then conduct ablation studies to verify the effectiveness note information from music scores, how well will the ALT
of each component in PDAugment, finally analyze the ad- system perform? The results of Random Aug can perfectly
justed speech by statistics and visualization. answer this question. As the results show, Random Aug can
slightly improve the performance compared with ASR Aug-
5.1 Main Results mented, demonstrating that increasing the volatility of pitch
In this subsection, we report the experimental results of and duration in natural speech helps ALT system training,
the ALT system equipped with PDAugment in two singing which is the same as what Kruspe and Fraunhofer (2015)
voice datasets. We compare our results with several basic claimed. PDAugment is significantly better than Random
settings as baselines: 1) Naive ALT, the ALT model trained Aug, which indicates that adjusted speech can better help
with only singing voice dataset; 2) ASR Augmented, the ALT the ALT training with the guidance of music scores.
model trained with the combination of singing voice dataset Besides, it is obvious that PDAugment greatly out-
and ASR data directly; 3) Random Aug (Kruspe and Fraun- performs the previous SOTA in both datasets. Demirel,
hofer 2015), the ALT model trained with the combination of Ahlbäck, and Dixon (2020) in Table 2 performs worse than
singing voice dataset and randomly adjusted ASR data. The PDAugment because of not taking advantage of the massive
pitch is adjusted ranging from -6 to 6 semitones randomly ASR training data. Compared with Basak et al. (2021) in Ta-
and the duration ratio of speech before and after adjustment ble 3 that replaced F0 contours of speech directly, PDAug-
is randomly selected from 0.5 to 1.2. All of 1), 2), and 3) are ment can narrow the gap between natural speech and singing
using the same model architecture as PDAugment. Besides voice in a more reasonable manner and achieve the lowest
the above three baselines, we compare our PDAugment with WERs among all the above methods. The results in both
the previous systems which reported the best results in two datasets show the effectiveness of PDAugment for ALT task
datasets respectively. For DSing30 dataset, we compare our and reflect the superiority of adding music-specific acoustic
PDAugment with Demirel, Ahlbäck, and Dixon (2020) us- characteristics into natural speech.
ing RNNLM9 and the results are shown in Table 2. For Dali
corpus, we compare the results with Basak et al. (2021) and 5.2 Ablation Studies
report the results in Table 3.
As can be seen, Naive ALT performs not well and gets We conduct more experimental analyses to deeply explore
high WERs in both DSing30 dataset and Dali corpus, which our PDAugment and verify the necessity of some design de-
tails. More ablation studies (different language models) can
8
https://github.com/espnet/espnet be found in the supplementary materials. The ablation stud-
9
https://github.com/emirdemirel/ALTA ies are carried out on DSing30 dataset in this section.(a) Original speech sample. (b) After Pitch Adjuster. (c) After Duration Adjuster. (d) After PDAugment.
Figure 4: Spectrograms of speech example after pitch adjuster or/and duration adjuster.
Augmentation Types In this subsection, we explore the Property Original Speech adjusted Speech
effects of different kinds of augmentations (only adjust Pitch Range (semitone) 12.71 14.19
pitch, only adjust duration, and adjust pitch & duration) Pitch Smoothness 0.93 0.69
on increasing the performance of ALT system. We gener- Duration Range (s) 0.44 0.59
ate three types of adjusted speech by enabling different ad- Duration Variance 0.01 0.05
justers of PDAugment module and conduct the experiments
on DSing30. The results are shown in Table 4. Table 5: The differences of acoustic properties between orig-
inal speech and adjusted speech.
Setting DSing30 Dev DSing30 Test
PDAugment 10.1 9.8
- Pitch Adjuster 13.6 13.4 can not completely match that of singing voice. Nonetheless,
- Duration Adjuster 13.8 13.8 adjusted speech is still good enough for ALT model to cap-
- Pitch & Duration Adjusters 20.8 20.5 ture some music-specific characteristics.
Table 4: The WERs (%) of different types of augmentation Visualization of adjusted Speech In order to visually
of DSing30 dataset. All of the settings are trained on DS- demonstrate the effect of PDAugment module, we plot the
ing30 and the original or adjusted LibriSpeech data. spectrograms of speech to compare the acoustic characteris-
tics before and after different types of adjustments.
As we can see, when we enable the whole PDAumgnet An example of our PDAugment output is shown in Fig-
module, the ALT system can achieve the best performance, ure 4. In detail, the spectrogram of the original natural
indicating that the effectiveness of the pitch and duration ad- speech sample is shown in Figure 4a. And we illustrate the
justers. When we disable the pitch adjuster, the WER on spectrograms of purely pitch adjusted, purely duration ad-
DSing30 is 3.6% higher than PDAugment. The same thing justed, both pitch and duration adjusted speech in Figure 4b,
happens when we disable the duration adjuster, the WER Figure 4c, and Figure 4d separately. It is clear that the ad-
is 4.0% higher than PDAugment. And if both the pitch and justed speech audios have different acoustic properties from
duration are not adjusted, which means use the speech data natural speech audios. More example spectrograms and au-
directly for ALT training, the WER is the worst among all dios can be found in the supplementary material.
settings. The results demonstrate that both pitch and dura-
tion adjusters are necessary and can help with improving the
recognition accuracy of the ALT system. 6 Conclusion
In this paper, we proposed PDAugment, a data augmenta-
5.3 Adjusted Speech Analyses tion method by adjusting pitch and duration to make better
Statistics of adjusted Speech Following Section 2.2, we use of natural speech for ALT training. PDAugment trans-
analyze the acoustic properties of the original natural speech fers natural speech into singing voice domain by adjusting
and the adjusted speech by PDAugment, and list the results pitch and duration at syllable level under the instruction of
in Table 5. music scores. PDAugment module consists of speech-note
Combining the information of Table 1 and Table 5, we aligner to align the speech with note, and two adjusters to
can clearly find that the distribution pattern of acoustic prop- adjust pitch and duration respectively. Experiments on two
erties (pitch and duration) after PDAugment is closer to singing voice datasets show that PDAugment can signifi-
singing voice compared with the original speech, which in- cantly reduce the WERs of ALT task. Our method analy-
dicates that our PDAugment can change the patterns of pitch ses explore different types of augmentation, further verify
and duration in original speech and effectively narrow the the effectiveness of PDAugment. In the future, we will con-
gap between natural speech and singing voice. To avoid the sider narrowing the gap between natural speech and singing
distortion of adjusted speech, we limit the adjustment degree voice from more aspects such as vibrato and try to add some
within a reasonable range, so the statistics of adjusted speech music-specific constraints in the decoding stage.References Kruspe, A. M.; and Fraunhofer, I. 2014. Keyword Spotting
Ali, S. O.; and Peynircioğlu, Z. F. 2006. Songs and emo- in A-capella Singing. In ISMIR, volume 14, 271–276.
tions: are lyrics and melodies equal partners? Psychology of Kruspe, A. M.; and Fraunhofer, I. 2015. Training Phoneme
music, 34(4): 511–534. Models for Singing with” Songified” Speech Data. In IS-
Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; MIR, 336–342.
Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Kruspe, A. M.; and Fraunhofer, I. 2016. Bootstrapping a
Q.; Chen, G.; et al. 2016. Deep speech 2: End-to-end speech System for Phoneme Recognition and Keyword Spotting in
recognition in english and mandarin. In International con- Unaccompanied Singing. In ISMIR, 358–364.
ference on machine learning, 173–182. PMLR. Li, B.; Chang, S.-y.; Sainath, T. N.; Pang, R.; He, Y.;
Basak, S.; Agarwal, S.; Ganapathy, S.; and Takahashi, N. Strohman, T.; and Wu, Y. 2020. Towards fast and accurate
2021. End-to-end lyrics Recognition with Voice to Singing streaming end-to-end ASR. In ICASSP 2020-2020 IEEE
Style Transfer. arXiv preprint arXiv:2102.08575. International Conference on Acoustics, Speech and Signal
Chan, W.; Jaitly, N.; Le, Q.; and Vinyals, O. 2016. Lis- Processing (ICASSP), 6069–6073. IEEE.
ten, attend and spell: A neural network for large vocabulary Loscos, A.; Cano, P.; and Bonada, J. 1999. Low-delay
conversational speech recognition. In 2016 IEEE Interna- singing voice alignment to text. In ICMC, volume 11, 27–
tional Conference on Acoustics, Speech and Signal Process- 61.
ing (ICASSP), 4960–4964. IEEE.
McAuliffe, M.; Socolof, M.; Mihuc, S.; Wagner, M.; and
Dabike, G. R.; and Barker, J. 2019. Automatic Lyric Tran- Sonderegger, M. 2017. Montreal Forced Aligner: Trainable
scription from Karaoke Vocal Tracks: Resources and a Base- Text-Speech Alignment Using Kaldi. In Interspeech, vol-
line System. In INTERSPEECH, 579–583. ume 2017, 498–502.
Demirel, E.; Ahlbäck, S.; and Dixon, S. 2020. Automatic
Mesaros, A. 2013. Singing voice identification and lyrics
Lyrics Transcription using Dilated Convolutional Neural
transcription for music information retrieval invited paper.
Networks with Self-Attention. In 2020 International Joint
In 2013 7th Conference on Speech Technology and Human-
Conference on Neural Networks (IJCNN), 1–8. IEEE.
Computer Dialogue (SpeD), 1–10. IEEE.
Fujihara, H.; Goto, M.; Ogata, J.; Komatani, K.; Ogata, T.;
and Okuno, H. G. 2006. Automatic synchronization between Mesaros, A.; and Virtanen, T. 2008. Automatic alignment
lyrics and music CD recordings based on Viterbi alignment of music audio and lyrics. In Proceedings of the 11th Int.
of segregated vocal signals. In Eighth IEEE International Conference on Digital Audio Effects (DAFx-08).
Symposium on Multimedia (ISM’06), 257–264. IEEE. Mesaros, A.; and Virtanen, T. 2009. Adaptation of a speech
Graves, A. 2012. Sequence transduction with recurrent neu- recognizer for singing voice. In 2009 17th European Signal
ral networks. arXiv preprint arXiv:1211.3711. Processing Conference, 1779–1783. IEEE.
Graves, A.; Fernández, S.; Gomez, F.; and Schmidhuber, J. Meseguer-Brocal, G.; Cohen-Hadria, A.; and Peeters, G.
2006. Connectionist temporal classification: labelling un- 2019. Dali: A large dataset of synchronized audio, lyrics
segmented sequence data with recurrent neural networks. and notes, automatically created using teacher-student ma-
In Proceedings of the 23rd international conference on Ma- chine learning paradigm. arXiv preprint arXiv:1906.10606.
chine learning, 369–376. Morise, M.; Yokomori, F.; and Ozawa, K. 2016. WORLD:
Gulati, A.; Qin, J.; Chiu, C.-C.; Parmar, N.; Zhang, Y.; Yu, a vocoder-based high-quality speech synthesis system for
J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. 2020. Con- real-time applications. IEICE TRANSACTIONS on Infor-
former: Convolution-augmented Transformer for Speech mation and Systems, 99(7): 1877–1884.
Recognition. arXiv preprint arXiv:2005.08100. Panayotov, V.; Chen, G.; Povey, D.; and Khudanpur, S. 2015.
Gupta, C.; Li, H.; and Wang, Y. 2018. Automatic Pronunci- Librispeech: an asr corpus based on public domain audio
ation Evaluation of Singing. In Interspeech, 1507–1511. books. In 2015 IEEE international conference on acoustics,
Gupta, C.; Yılmaz, E.; and Li, H. 2020. Automatic Lyrics speech and signal processing (ICASSP), 5206–5210. IEEE.
Alignment and Transcription in Polyphonic Music: Does Park, D. S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.;
Background Music Help? In ICASSP 2020-2020 IEEE Cubuk, E. D.; and Le, Q. V. 2019. Specaugment: A simple
International Conference on Acoustics, Speech and Signal data augmentation method for automatic speech recognition.
Processing (ICASSP), 496–500. IEEE. arXiv preprint arXiv:1904.08779.
Hosoya, T.; Suzuki, M.; Ito, A.; Makino, S.; Smith, L. A.; Tsai, C.-P.; Tuan, Y.-L.; and Lee, L.-s. 2018. Transcrib-
Bainbridge, D.; and Witten, I. H. 2005. Lyrics Recognition ing lyrics from commercial song audio: the first step to-
from a Singing Voice Based on Finite State Automaton for wards singing content processing. In 2018 IEEE Interna-
Music Information Retrieval. In ISMIR, 532–535. tional Conference on Acoustics, Speech and Signal Process-
Kearns, D. M. 2020. Does English Have Useful Syllable ing (ICASSP), 5749–5753. IEEE.
Division Patterns? Reading Research Quarterly, 55: S145– Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones,
S160. L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. At-
Kingma, D. P.; and Ba, J. 2014. Adam: A method for tention is all you need. In Advances in neural information
stochastic optimization. arXiv preprint arXiv:1412.6980. processing systems, 5998–6008.Wang, C.; Wu, Y.; Du, Y.; Li, J.; Liu, S.; Lu, L.; Ren, S.; Ye, G.; Zhao, S.; and Zhou, M. 2020. Semantic Mask for Transformer Based End-to-End Speech Recognition. Proc. Interspeech 2020, 971–975. Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Soplin, N. E. Y.; Heymann, J.; Wiesner, M.; Chen, N.; et al. 2018. Espnet: End-to-end speech processing toolkit. arXiv preprint arXiv:1804.00015. Xu, J.; Tan, X.; Ren, Y.; Qin, T.; Li, J.; Zhao, S.; and Liu, T.-Y. 2020. Lrspeech: Extremely low-resource speech syn- thesis and recognition. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discov- ery & Data Mining, 2802–2812. Zhang, C.; Ren, Y.; Tan, X.; Liu, J.; Zhang, K.; Qin, T.; Zhao, S.; and Liu, T.-Y. 2020a. Denoising Text to Speech with Frame-Level Noise Modeling. arXiv preprint arXiv:2012.09547. Zhang, C.; Tan, X.; Ren, Y.; Qin, T.; Zhang, K.; and Liu, T.-Y. 2020b. UWSpeech: Speech to Speech Translation for Unwritten Languages. arXiv preprint arXiv:2006.07926. Zhang, Q.; Lu, H.; Sak, H.; Tripathi, A.; McDermott, E.; Koo, S.; and Kumar, S. 2020c. Transformer transducer: A streamable speech recognition model with transformer en- coders and rnn-t loss. In ICASSP 2020-2020 IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), 7829–7833. IEEE.
You can also read

















































