2020 GUIDE TO DATA-DRIVEN LENDING - How data transformation and machine learning are creating a new profit center for banks - Blue Orange Digital
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

2020 GUIDE TO DATA-DRIVEN LENDING
How data transformation and machine learning are
creating a new profit center for banks.
blueorange.digital
Table of Contents 2.4 Predictive Analytics: Transforming Decision Making 19
Section 1: Introduction 05 2.4.1 Prediction is Now Cheap 19
Summary 05 2.4.2 Advanced Analytics Examples 20
Where We’re Going 06 2.4.3 Prediction Can Change Business Models 21
Section 2: Tour de Data 08 2.4.4 What Does This Mean for Banks 22
2.1 Distilling the Buzzwords 08 Section 3: Data-Driven Loan Pricing 25
2.1.1 AI Lowers the Cost of Prediction 08 3.1. Traditional Loan Pricing 25
2.1.2 What is Machine Learning? 08 3.1.1 Loan Pricing 25
2.2 Cloud Computing 09 3.1.2 Traditional Pricing Methods 25
2.2.1 How the Cloud Works 09 3.1.3 Problems with Traditional Risk Measures 26
2.2.2 Cloud Computing Overview 10 3.2 Machine Learning Approach 28
2.2.3 Cloud Benefits for Banks 11 3.2.1 What Big Banks are Doing with ML 28
2.3 Modern Data Architecture and Why it Matters for Banks 13 3.2.2 Why Lending is a Perfect Problem for Machine Learning 29
2.3.1 Framework 13 3.2.3 Advantages and Disadvantages of ML 29
2.3.2 Data Architecture Matters for BI 13 3.2.4 How ML Improves Lending 30
2.3.3 Legacy Architecture: An Evolved System 14 3.2.5 Thinking like a Data Scientist 32
2.3.4 What the Heck is a Data Lake? 16 3.2.6 Machine Learning Models for Lending 33
2.3.5 Why Do Data Lakes Matter? 17
2.3.6 The Modern Data Pipeline 18
2 3
3.3 Lending Club Case Study 36
3.3.1 Defining an Objective 36
3.3.2 Exploring and Cleaning Data 37
3.3.3 Modeling 38
3.3.4 How to Evaluate an ML Model 38
3.3.5 Results of High/Low Risks Loans 39
3.3.6 FICO Model 41
3.3.7 Discussion 43
Section 4: Bringing it Home 45
4.1 Determining if Your Bank is Ready for Predictive Analytics 45
4.1.1 Is Predictive Analytics a Good Fit for Your Business? 45
4.1.2 Do You Have Good Data Infrastructure? 46
4.1.3 Do You Have the Right Team? 46
4.2 Leading Change 48
01
Section 5: Conclusion 51
Introduction
4 05
1 Introduction Where We’re Going
The purpose of this whitepaper is to share how modern data can work for banks. Not every
community bank is going to have the data access or institutional buy-in to implement a
Summary machine learning derived approach to lending. But understanding the opportunities and
implications of modern data is accessible to everyone. A number of trends are converging
Over the last 10 years, we’ve seen businesses fundamentally change how they make that will categorically transform how the banking industry operates. Loan pricing, while
decisions. Business leaders are able to uncover new patterns in complexity. Find signals in a powerful for driving profitability, is just a single example of these predictive applications.
world with more noise. This ultimately improves their ability to understand, then influence
desired outcomes. The paper is broken down into 3 main sections:
1. A tour of modern data to provide the necessary background of the historical changes
This dramatic shift in how organizations operate can be attributed to a simple thing: data.
underway.
But changing into a data-driven organization is no small feat. Today “data is the new oil”
2. The details of data-driven loan pricing.
powering improved business insight with an incredible combination of vast new data
3. Implementing predictive analytics at your institution.
sources, cheap computing, and ever-stronger algorithms to dissect them. Like industrial
transformation a century ago, adjusting to this world requires new tools, infrastructure, and
mindsets.
With all this opportunity, it’s an exciting time to look at the future of banking. The industry is
being transformed by data analytics and cloud computing. The advent of predictive analytics
has made data-driven problem solving accessible to all banks. The winners in this new
competitive landscape will be the ones who rapidly embrace advanced prediction. They will
invest heavily in machine learning and the modern data architecture to support. Improving
loan pricing and profitability is an excellent use case for these tools.
By unifying internal and external data sets and applying readily available predictive tools
(off the shelf models, 3rd party business intelligence software, internal upskilling), banks can
increase loan profitability and reduce risk. But even if your bank isn’t ready to immediately
invest in a data lake and machine learning, there are specific steps you can take to both
instill data-driven decision making in your department and more profitably price loans.
06 07
Section 2: Tour de Data
2.1 Distilling the Buzzwords
2.1.1 AI Lowers the Cost of Prediction
“AI serves a single, but transformative, economic purpose: it significantly lowers
the cost of prediction” --Ajay Agrawal
AI lowers the cost of prediction. From here on out, when you hear AI or Machine Learning,
think cheap prediction. Once you start to see challenges in this light and ask what data
do we have or can we acquire to reframe a business question as a predictive one, you
have already taken the most important conceptual step to applying data-driven decision
making at your institution. Today advances in machine learning and cloud computing have
democratized access to advanced predictive problem-solving.
Take customer lifetime value. Many banks don’t even know the economic value of a specific
customer. How likely are they to purchase a new product, open another account, respond
to an email offer, or leave for another institution altogether? But understanding this number
is the key to making informed decisions about how to allocate internal resources and
prioritize customers. It can also serve as a driver of strategic consensus, cross-departmental
collaboration, and better customer experience. Accurate prediction and customer
02
segmentation underpin a data-driven flywheel.
2.1.2 What is Machine Learning?
Machine Learning (ML) is a type of computer algorithm (or multiple algorithms) that can
repeatedly apply statistical models and analyze the results to find patterns in data. What
makes machine learning algorithms valuable are the feedback loops--a well-designed
Tour de Data algorithm continues to learn from new input data to increase the accuracy of the solution it
comes up with. ML discovers correlations in the data to make these predictions.
08 09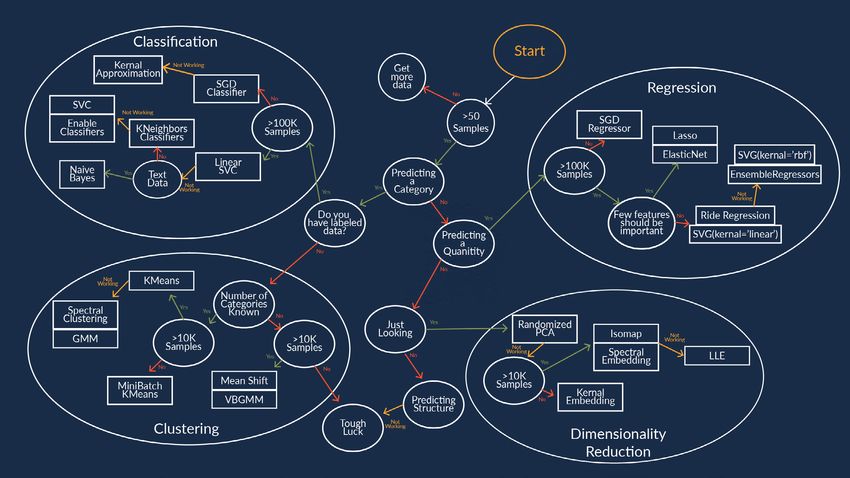
2.2.2 Cloud Computing Overview
Service Models
Take Fraud detection. Humans cannot efficiently review and classify the volume and velocity There are 3 levels of cloud computing services that correspond to the level of user
of today’s transactional data. There are two major problems: effectively scanning billions of management required.
transactions to determine whether they are fraudulent and detecting new forms of fraud.
• IaaS (Infrastructure as a Service)
Machine learning algorithms are trained against large amounts of existing data to discover
IaaS are the building blocks of cloud IT. These are virtual resources that resemble the
patterns that correlate to fraudulent behavior. Then the models are applied against current ones in physical data centers and allow users to create custom computing environments.
transaction data to detect fraud in real-time and identify new forms of fraud far more Servers, storage drives, networking tools (virtual routers & firewalls) are examples of low-
effectively than deploying a team of humans on the same task. level resources.
• PaaS (Platform as a Service)
2.2 Cloud Computing PaaS involves pre-configured platforms where the user is not responsible for the
underlying infrastructure. This allows users to deploy and maintain their own
applications and custom development environments without worrying about
provisioning servers or security maintenance. A managed database is a good example.
2.2.1 How the Cloud Works
• SaaS (Software as a Service)
Cloud computing is the on-demand availability SaaS software tools and applications are hosted in the cloud, giving users full access to
software via a web browser or mobile app. Salesforce is a dominant example of a CRM
of computer resources as a managed service
software service delivered over the web, where some customization may be required but
over the internet. Rather than devoting
the user doesn’t think about any of the underlying implementation details.
expertise to running on-premises data
infrastructure, banks can focus on what they do Deployment Models
best--serving customers--while companies like
Because many organizations transition to the cloud with existing on-premise software
Amazon and Microsoft maintain the underlying
resources, there are 3 different models for cloud deployment.
infrastructure. But the advantages of the cloud
go far beyond specialization. The ability to Cloud Hybrid On-Prem
immediately spin up services that most banks Full cloud deployment is done A hybrid deployment is done Maintaining in-house cloud
could not develop internally, scale on-demand, when all parts of a solution (both when a solution integrates both infrastructure (also known as a
and pay only for what you use with world-class high-level services and low-level cloud and on-premise resources. private cloud) is a deployment
infrastructure components) A common scenario would be model for optimizing legacy
security creates incredible strategic and tactical
run in the cloud. An example when the data must be stored in IT infrastructure with cloud
flexibility, and in the process trades Capex of a fully deployed AWS-based a self-maintained, private data tools. While still requiring
guesses for fully utilized operational expenses. A solution is Starling Bank, which center, while data processing expert knowledge for system
new server or service is literally a click away. took a cloud-first approach to applications run in the cloud. maintenance, it provides
develop its infrastructure. Cloud The former provides operational full control of resources and
services and applications that stability and compliance, while optimization strategies. Union
integrate seamlessly provide the latter offers the agility and Bank has integrated a private
great flexibility and scaling. The scalability needed for customer- cloud solution to improve
added bonus of off-loading on- facing applications. This application delivery times and
premise maintenance makes this deployment model is a common automate already established IT
deployment model very popular. step in most cloud adoption processes.
strategies since it allows for
an incremental, step-by-step
migration.
10 11
• Lower Capital Expenses for Computing Infrastructure
“With the new private cloud infrastructure in place, the bank has already
Cloud Computing enables the pay-as-you-go model, where the fixed costs of cutting
started seeing significant benefits. Deploying new applications, which edge infrastructure are effectively amortized over millions of purchasers. Resources
previously required 8-12 weeks, can now be executed in just a few hours. that previously required the acquisition and maintenance of hardware, equipment,
This allows IT to speed time to market for new applications, enhancing the and physical infrastructure can instead be invested directly in provisioning computing
bank’s ability to serve its internal and external customers.” resources, when and if they are needed. This allows organizations to focus on projects
that differentiate their business and lets the cloud vendor handle the underlying
infrastructure.
2.2.3 Cloud Benefits for Banks • Cloud Solutions as Incremental Systems
The major cloud vendors (Amazon Web Services, Microsoft Azure, Google Cloud Platform) “Moving to the cloud” is not a process that happens overnight. The full transformation
are continually increasing their service offerings to cover business and technical needs requires a carefully planned, multi-stage implementation strategy. Banks can start out
across industries. This has enabled institutions to focus on their differentiated value rather with an in-house experimental phase, use expert knowledge for the assessment of cloud
than struggle with technical maintenance issues (often at a lower cost as well). These opportunities, and perform a thorough comparison of available cloud services in an
benefits play out in multiple ways: easily reversible way. This empirical knowledge lays the foundation for further steps in
the cloud adoption strategy.
• Reliability & Data Security
• Scalability & Flexibility
Cloud Vendors use state-of-the-art tools and knowledge. They invest heavily in research
and development of security protocols, encryption standards, and novel data access The ability to scale on-demand makes cloud-based solutions extremely versatile.
schemes, with the additional ability to fully isolate your data in a private cloud. This Software and hardware resources can be scaled up and down depending on current
allows them to provide very high standards of customer data safety, even for industries business needs. For large enterprises, this helps optimize operational costs. For small
that require high levels of data security (e.g. military, trading, insurance). The fact that startups (or startup-style projects within banks), it allows for rapid testing and enables
data is stored redundantly in the cloud also ensures the protection of customer data accommodating a large number of users on short notice. Such agility is a fundamental
against natural disasters and an easier data recovery process. business need in today’s competitive market.
• Unified Data
Cloud-based solutions make it far easier to integrate multiple data types and managed
services, which gives banks greater ownership and control of their data. Regardless of
file formats or database schemas, data that was once stored in isolated silos can now
be kept in a single location. The simple decision of unifying the data in the cloud (while
keeping the same variety of formats) enables more effective data analytics. The unified
approach gives banks that bring their disparate data to the cloud more insight and
access to their data sources.
12 13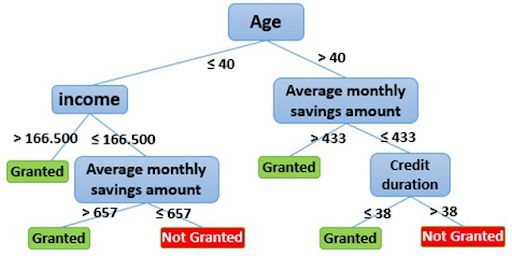
2.3 Modern Data Architecture and Why it Matters for Banks
2.3.1 Framework
2.3.3 Legacy Architecture: An Evolved System
Data architecture is admittedly an abstract topic. But it matters because without having a
flexible, performant architecture any attempts at integrated analytics will be immediately This is your brain...on a legacy data pipeline.
stopped in their tracks. Legacy architectures, rarely update spreadsheets, unintuitive UIs,
and siloed data storage leave employees, customers, and leadership in a reactive state.
Many vendors offer single solution dashboards to address specific needs, but often this
further compounds the foundational problem: disparate data systems only provide a partial
picture.
However, the new cloud paradigm and tools offer a compelling solution. Banks can own
their data, directly answer business questions, easily combine internal and external data
sources, and have the flexibility to ask new questions and bring on new vendors without
being constrained by past architectural decisions. Beyond a commitment to a major cloud
provider, you are not locked into traditional bank data vendors with their siloed business
models.
2.3.2 Data Architecture Matters for BI
Business intelligence is best defined by its end goal: Making better business decisions. In
Wikipedia’s parlance, BI “enables more effective strategic, tactical, and operational insights
and decision-making” [3]. To do this, we need two things: available data and a way to
understand it.
Making good, well-informed decisions is the goal. Performing queries, drawing graphs,
training models and making predictions are some of the ways we can move towards this
goal. But without accurate, accessible, and relevant data there is nothing to apply analytics
on. For these tools to be truly meaningful and effective, your whole organization needs to
deploy a modern data architecture. Figure 1: Legacy Dataflow (Blue Orange Sales team design)
Traditional BI has required businesses to invest in sophisticated infrastructure and
Figure 1 shows how a typical legacy data pipeline would look. This is not a planned system,
expensive development projects. This approach incurs continual support costs and make it
but the result of evolving business needs. As more and more external services are added,
difficult to be responsive to changing business needs. Think of having to request a monthly
and more independent internal teams make use of the data, the architecture evolves into a
sales report from IT or internally manage a server network, which all too often devolves into
complex tangled spider web of data connections. Each team has to figure out what data is
this.
available, where to find it, what each column and field actually means (the data semantics),
Major advances in tooling, along with sophisticated data processing, have democratized and do its best (using custom code and legacy ETL software) to pull it all together so they
the job of analytics, moving it from IT departments to business stakeholders. Let’s start by can perform their computations.
learning how the traditional approach to BI data processing evolved.
14 15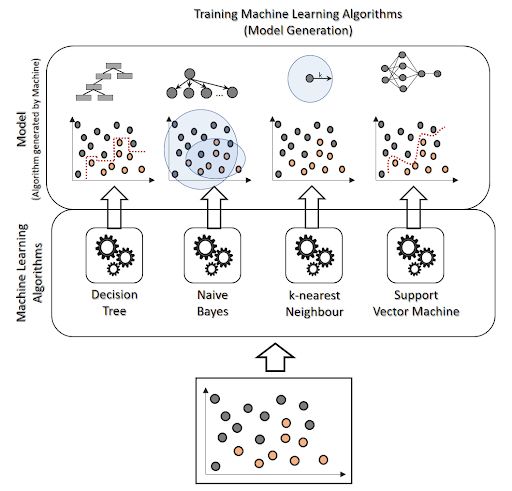
This works initially. However, as the company grows it becomes increasingly hard to 2.3.4 What the Heck is a Data Lake?
manage. The process is very error-prone and requires significant, costly coordination and
effort from each team. The end result is fragile and inaccurate. If any service, whether In order to avoid the issues detailed above, many banks have considered or (often tragically)
internal or external changes at all, the code either breaks or, worse yet, produces inaccurate tried to implement a data warehouse. Data warehouses pair well with ETL, an extraction
results. technique that formats data before putting it into storage. Much like a giant database where
data is stored in a standard format, warehouses conform data to constraints to be queried
On top of the architectural and design challenges, much more data is produced today than more easily. However, over time, these constraints create usability challenges that replicate
the systems were initially designed for, further stressing the legacy approach. Traffic is many of the legacy issues for organizations that want to implement advanced predictive
increasing, analytics are becoming more prevalent and information-rich, and media is now analytics.
ubiquitous (e.g. screenshots, recording mouse movements, images, and video). If that isn’t So how is a data lake different? An
analogy might help here. There are two
enough, large third party data sources, both free and premium, are also needed to enrich Order Matters: ETL vs ELT
prototypical drawers in most kitchens: a
internal data sets. Every addition requires more code, more ETL operations, and ultimately
ETL stands for Extract, Transform, and Load and utensil drawer where each type of utensil
much more processing.
represents any technique used to get the data you has its own special place and that catch-
Processing all this data cost-effectively is the next challenge. Employing advanced need in the format and shape you need to perform all-drawer where you throw everything
your task — before loading it into storage. First you else you need. The former is a data
processing on this growing mass data makes server loads difficult to balance. Similar to a extract the data, for example by reading data from warehouse; the latter, a data lake.
power grid, designing computing power to meet peak load requirements means that full disk, performing an HTTP call or an API call. Next you
utilization only occurs for part of the day or week. The result is expensive server allocations transform it through one or more of the following: A data lake can be thought of like a giant
that often sit idle. filtering the data, selecting fields of interest, joining
directory or file system. Data lakes pair
several disparate data sources together, enriching
well with ELT, an extraction technique
Finally, since the data is stored and only made available through proprietary services the data by performing a calculation to produce
new fields, cleaning it, filling in missing values, or that doesn’t alter the data before storing
(designed by and for engineers), leveraging this data relies on direct support from it. This simple-sounding difference
identifying errors and correcting them. The load is
engineering and IT. Any special information, query, or graph required by a decision-maker the final phase by which you load the data into your has big implications. Anybody in the
will need coordination and assistance from an engineer or data scientist. Even data discovery target storage, be it a data lake, data warehouse or organization can store their data there, in
becomes a major hurdle. Management, and even the engineers who run the system, whatever tickles your fancy. The key point is that any format, schema, or order.
your data will be immediately ready for use.
struggle to know what data is available, what data would prove useful, what the data means,
and how to access it. The result is simplistic, slow decision making and a slow-moving But now you might ask, “Isn’t it easier to
ELT (Extract, Load, Transform) is a variation of this
organization. find a fork if all the forks are organized
idea. Rather than transforming the data prior to
the load phase, and effectively storing the result of together?” Well, yes, it is easier to find
the process described above, you perform these a fork, but finding and counting forks is
LEGACY CHALLENGES manipulations when you need the data. just scratching the surface of modern
To summarize the challenges facing a legacy data pipeline: analytics.
• Hard to scale - difficult data discovery, data access, etc. With today’s cheap and powerful computing, grouping things in whatever way you want is
• Error-prone nearly instant. The data doesn’t need to be stored in a specific format, which opens the door
• Exclusive data access to specialists to endless types of data analytics. Modern tools such as Spark/Hadoop can process any
• Expensive to maintain organizational data out of a unified environment and analyze it in any given way. Like a knife
• Redundancy of data and code to fork or a fork to fork-from-3-years-ago. Ok...we may have worn out this analogy.
• Wasteful and costly computing allocation
16 17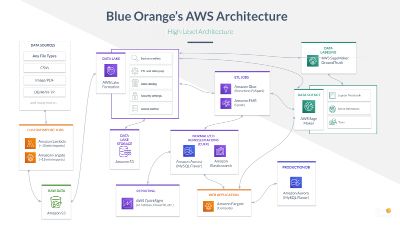
2.3.5 Why Do Data Lakes Matter? A bank with modern data architecture has reliable, accurate data pipes running all the
way from the user fumbling through your web site, to adding third party information and
The data lake pattern is the preferred architectural solution for 2020 because it provides services, conducting analysis, joining disparate data sources, performing enrichments,
a low cost, flexible, and scalable way to store large amounts of diverse data. All your distributing that data to internal servers, training and deploying machine learning models,
bank data that is now sitting in dozens of siloed, vendor-specific systems is stored in and finally pulling all this data together again to allow the decision-maker to interact,
a central location that you own, so it’s readily available to be categorized, processed, visualize, query and explore it in order to make the best choice. Specific data is collected,
analyzed, enriched, and consumed by downstream analysts and operational teams. By modeled, transformed, and visualized to be put in an actionable business context.
using ‘metadata’ to tag data rather than coerce it into a predetermined warehouse format,
broader types of data can be used effectively for business intelligence. When a business Here is a map of modern AWS data architecture for banks. It looks complicated, but the
question arises, the data lake can be queried for relevant data in any format, and this beauty is that these are all high-end data services that you don’t have to build. AWS has
smaller set of data is rapidly available to be analyzed and help answer that specific question. created impressive tools at every stage of the data lifecycle that can be pulled together,
revolutionizing how banks think about and use their data.
From an executive perspective, the main advantage of a data lake is that it delivers strategic
flexibility. Owning your data in a cloud data lake provides high levels of security, portability,
and access to better tools. It doesn’t constrain future changes in business strategy because
the raw data is still there. If you decide on a new BI or reporting tool, just write a job to
structure the data in that format. If next year’s annual plan calls for a completely new
initiative that requires answers to questions you didn’t know you needed to ask when the
data lake was stood up, fine. If a new source of customer data starts growing exponentially,
you can handle it. The data lake approach provides a solid architectural foundation to build
on for the future, even if you don’t know exactly what that future entails.
Strategic Flexibility Cheaper
Takeaway: Data Flexibility Single Source of Truth
Future Proofed Better BI Integration
2.3.6 The Modern Data Pipeline Your data is stored in its raw, persistent form in an AWS data lake built on Lake Formation.
The data you need for a specific job is pulled out, transformed, normalized, and sent to
The deeper purpose of deploying a data lake is to simplify decision making across the an analytics engine in real-time. Let’s say you have already purchased a loan analyzing
institution. It provides the foundation for advanced analytics and the control to use the software that you love. We write a ‘job’ that transforms a representation of your loan data
vendors you value without being locked-in. After building dozens of data lakes for Fortune into a schema the software can use. But the underlying data in the single source of truth
500 companies to startups, we at Blue Orange have seen a fundamental shift in the past doesn’t change. The next level is actually applying modern data science tools like EMR and
year that democratizes access to cutting edge data tools. In terms of cloud computing, we SageMaker to implement machine learning models and predictive analytics. Once the data
are “standing on the shoulders of giants,” and banks of any size can be the beneficiaries. pipeline is built, you just rent the processing time.
18 192.4 Predictive Analytics: Transforming Decision Making
2.4.1 Prediction is Now Cheap
2.4.2 Advanced Analytics Examples
Making accurate predictions about the future is a fundamental business need because it
helps leaders make the right decisions for their organization. However, traditional BI tools Let’s take a closer look at a few examples of advanced analytics in banking to understand
and subjective interpretations are no longer enough to gain actionable insights from the how the industry is learning to capitalize on customer and product data. Banks and financial
vast amounts of data that are deluging today’s banks. In a data-centric world, powerful institutions that have embraced digital transformation are successfully employing modern
machine learning technologies are already driving enterprise performance. Companies large machine learning tools for a variety of tasks.
and small are rapidly embracing the transformative economic purpose of ML: It significantly
lowers the cost of prediction.
Customer Acquisition
The technological advances of the past decades and the increasing focus on data-driven
solutions played a huge role in lowering these prediction costs: Predictive models improve the efficiency of the sales process and enable more accurate
lead qualification. Hidden data features can be isolated and help identify ideal customer
• Data collection (from humans, machines, and software) is now a common practice profiles or implement probabilistic lead scoring models. This allows sales teams to focus
and across industries and the volume allows for more powerful and accurate models. their attention on the most valuable prospects.
• Predictive software tools are becoming increasingly specialized and provide rapid Personalized Marketing
solutions for previously expensive tasks.
Predictive analytics enable personalized interactions with prospective customers. By
• Academia and the industry are continually researching and developing new AI tools revealing novel data patterns, response modeling empowers marketing teams to reach
that have created a flourishing ecosystem. specific groups with personalized content and more effective cross-selling offers.
• Commodity hardware is also becoming cheaper and modern computational units
Customer Segmentation
needed for Machine Learning (such as GPUs and CPUs) lower the processing times of
previously intensive tasks. Data insights allow better segmentation of customer groups. Modern clustering techniques
can make sense of online & offline customer behavioral patterns. Predicting customer
• The multitude of data-oriented cloud tools makes it possible for any organization to
lifetime value and churn allows banks to effectively tailor customer service and offers for
tackle cutting edge machine learning challenges. From big data acquisition to building
subsets of their customers with an understanding of potential impacts on the bottom line.
complex processing pipelines and training deep learning models, there are countless
opportunities at a low cost, pay on-demand manner.
Revenue Forecasting
These advances make possible what was previously unimaginable. Heterogeneous data Machine learning tools are modern alternatives for cash flow management. Integrating
sources can be integrated and modern learning architectures deployed with the click of a multiple data sources (marketing, sales, operation & customer data) has been shown to
button. This allows companies to regularly leverage machine technologies for data analysis provide more accurate demand predictions for lending and financial products.
and in turn, the insights obtained from these data approaches are transforming industries.
Advanced predictive analytics has never been as affordable as it is right now and the costs
(both in money and time) are still going down.
20 21These are just a few applications in the financial sector where predictive ML has been Here’s a fun thought experiment. How accurate would Amazon’s product recommendation
successfully used to leverage the power of data. There are hundreds of additional engine need to be before they just started shipping your boxes of items they think you’ll
opportunities for predictive analytics in every line of business in a bank. Wherever a data- want rather than waiting for you to order? 60%...70%? At some point, the entire business
based process exists, that data can be leveraged to optimize it. Better prediction improves model flips and it would be more profitable for Amazon to shift its business model to
the bank customer experience, enhances revenue, and reduces operational costs. ship-then-shop. People would be happy that a spatula showed up to replace their old one
and if they didn’t want to keep it a courier would take it away for free the next day. With a
sufficiently accurate prediction of what shoppers will buy, the risk of shipping an unwanted
product is smaller than the chance the shopper decides to keep the product.
Once Amazon’s strategy proved successful and they secured the first-mover advantage, it is
expected that competitors would try to follow. Relying on predictive technology for strategic
business decisions becomes the only way to stay ahead. This example shows how advanced
prediction can go beyond the strategy of a single organization to impact the economics of
an entire industry.
2.4.4 What Does this Mean for Banks?
There are multiple ways that financial institutions can pursue predictive analytics as part of
their data-driven transformation strategy. Here are some examples:
Automation
2.4.3 Prediction Can Change Business Models
Predictive analytics enables financial institutions to increase efficiency and achieve
The trend is similar across industries: predictive analytics is a major asset in the hands of operational agility by automating recurring processes. Traditional back-office processes
any organization that wishes to transform itself. Moreover, increased predictive accuracy are tedious, labor-intensive and error-prone. Accounts payable, customer service tasks,
may even change the business model itself. and even loan approval are examples of rule-based processes where AI solutions could
improve manual worker performance. Automating these manual tasks and reducing human
In retail, a powerful example is related to Amazon’s advanced analytics strategy and the involvement has a direct impact on operational performance, staffing, and expenses.
resulting superior prediction. With a recommendation engine that is based on increasing
amounts of data and heterogeneous sources (online behavior, social metadata, offline Unbiased Indicators
shopping history), Amazon is steadily improving how accurately they can predict what
shoppers will buy. Since accurate indicators can provide a more complete picture of an organization’s health,
it is critical to interpret performance values by means of well-established, reliable statistical
tools. Advanced analytics provides banks with the opportunity to accurately aggregate KPIs
and discover hidden trends that would otherwise remain unknown.
22 23By replacing man-made features with automated ML-enhanced predictions, the relevant
features are learned from the data itself and the resulting insights are less biased. This
translates to higher model accuracy and better-informed decision making.
Data-Driven Decisions
The main purpose of predictive analytics is to make sense of raw data and turn it into
meaningful insights that enable smarter decisions. The biggest advantage of modern
predictive analytics is the possibility of handling heterogeneous data sources. For example,
a marketing campaign may not achieve the expected outcome when based on an
incomplete customer profile. Pulling in third-party data (such as social media information,
shopping behavior, online transaction history) can help reveal and target ideal customer
segments. Successful strategies and informed decisions are easier to find when aided by
data analytics.
Real-time Analytics
Predictive analytics should not only be performed on historical data. There are many
situations in which real-time analytics can solve an important business use case. A great
banking example is fraud prevention, which detects cybercrime as (or even before) it even
occurs. By modeling user behavior and performing anomaly detection, fraud monitoring
tools can employ machine learning continuously. Other related examples of real-time
predictive analytics also include money laundering detection and stock market surveillance
software.
03
Data-Driven Loan Pricing
24 25Section 3: Data-Driven Loan Pricing Price Leadership
In a competitive world, the bank in our example above may not be able to charge 8% if
3.1. Traditional Loan Pricing another bank is offering the borrower the same loan at 6.5%. With deregulation, alternative
lending sources, and fully online banks, it is difficult to maintain traditional cost plus profit
margins. The alternative is to use a price leadership model to establish a bank’s cost of
3.1.1 Loan Pricing credit. A prime lending rate is set for the bank’s most creditworthy borrowers, which
serves as the benchmark rate for other loans. One of the challenges for banks who assume
One of the greatest challenges for lenders is figuring out the interplay between credit this model is minimizing funding and operating costs while keeping the risk premium
score, term length, and collateral to determine the risk premium. Fundamentally, a loan is a competitive. A low prime rate may result in additional lending but accumulate hidden
contract that allows people to trade money across time. The interest rate that the borrower operational and credit risks.
pays should account for both the opportunity cost of money to the lender and the risk
of default. In this section we will focus on risk scoring, and, in particular, using machine Credit Risk Pricing
learning to create a more nuanced determination of credit risk.
A credit score or risk-based pricing method focuses on the differential characteristics of a
borrower to assign the risk or default premium to the loan. Under the credit risk model,
3.1.2 Traditional Pricing Methods the decision of lenders to issue credit is heavily influenced by the credit score of the
borrower and the credit report provided by the largest US credit offices--Equifax, Experian,
There are three main pricing models lenders use today: cost plus, price leadership, and
and TransUnion. FICO (Fair Isaac Corporation) is the most popular credit scoring program,
credit scoring/risk-based pricing.
ranging from 300 to 850. The rating algorithms of FICO are designed to forecast consumer
behavior with a statistically determined default rate. The model assumes that a borrower
Cost Plus with a subprime credit score of 620 may have trouble repaying on loan based on their past
borrowing and payment history. Applying a credit scoring system allows banks to assign
Cost plus pricing is the simplest model as it assumes there is no market pressure from other
a default premium and use cutoff scores to compete for certain borrower groups and
lenders. The interest rate is determined by four components:
reject or offer higher prices to potentially riskier borrowers. On the flip side, prospective
• Funding Cost: How much it costs the bank to raise the loaned funds borrowers with a high credit score will typically be rewarded by banks for their responsible
behavior with a lower-priced loan.
• Operating Costs: Bank overhead and servicing costs
• Risk Premium: Compensation for default risk of the loan
3.1.3 Problems with Traditional Risk Measures
• Profit margin: Assures bank receives an adequate return
While traditional loan pricing methods have been functioning for decades, there are 4 key
For example, someone comes into the bank asking for a small $1000 loan. If the cost of problems that emerge from the way they measure loan risk:
funds is 3%, operating costs are 1%, the default risk premium is 2% and the bank needs a
2% profit margin, then the bank sums it up and offers to lend at 8%. Done and done.
26 271) Limited features
Assessments of creditworthiness are based on a limited number of features defined by the
model. For example, FICO uses payment history, credit utilization, length of credit history,
new credit, and credit mix as its primary categories. This approach leads to more general
decisions not tailored to the needs of the specific borrower. There are clearly other features
that would influence loan pricing if they were able to be considered.
2) Disqualification of qualified borrowers
Disqualification of potentially creditworthy persons because they are unable to meet certain
criteria is also problematic. A person’s credit history, for example, has a significant impact
on the final score. This often excludes young people or people from other countries who
would have the financial ability to assume the debt. Another example would be unduly
penalizing someone who has one or more late payments in the past due to explicable
circumstances that are no longer present. Judging someone’s creditworthiness based
3.2 Machine Learning Approach
primarily on outdated or unexamined factors can lead to false lending assumptions, which
is a loss for both the lender and borrower. 3.2.1 What Big Banks are Doing with ML
3) FICO primacy The four biggest banks in the US are actively applying machine learning today:
• JP Morgan Chase: Contract Intelligence - COIN
In the credit scoring industry, the FICO scoring system has little competition. Since most
lenders receive the FICO score of the borrower from the same 3 major credit offices, if a • Bank of America: Chatbot, fraud detection, trading
certain lender refuses a potentially creditworthy borrower for a loan, they are likely to be • Wells Fargo: Blockchain, improved analytics, NLP, chatbots
rejected elsewhere. This overemphasis on FICO results in the inability to meet the demands
of the customer (as that is what the borrower ultimately is for banks). • Citigroup: Document digitization using CV and NLP. Chatbots for customer service
and anomaly fraud detection on transactions
JP Morgan’s project is the most revealing because it involves the full-scale automation of
4) Increasing customer demands white-collar jobs. The company created a contract review software using Natural Language
Processing algorithms that replaces 360,000 hours of annual legal contract review. They
The demands of consumers for speed, accuracy, and ease of use have increased
have been able to reduce the time spent on this job to a matter of seconds using machine
exponentially due to the technological revolution witnessed over the past 10 years. Existing
learning.
credit issuers and credit offices need to meet the needs of today’s consumers or will be
replaced by newly formed companies paying better attention to the experience of their
customers. This demand for customized, personal approaches is both an opportunity for
banks to differentiate now and will become table stakes in the years ahead.
28 293.2.2 Why Lending is a Perfect Problem for Machine Learning Disadvantages
• Exclusion Risk: Lending dependent on ML bears financial exclusion risks. ML models
Machine learning algorithms are designed to find patterns in data. Simply put, there are far
are trained using available data that may not necessarily be representative of all
more data sources available to provide an edge in lending than are currently being used
classes of borrowers the lender is considering. If the training set is missing critical
by banks. For example, an individual’s primary financial institution has years of customer
variables for a specific borrow, the model may not perform well.
data that hold statistical correlations which would bear on future loans if the additional
information could be analyzed. Community banks already incorporate “non-standard”, i.e. • Privacy Issues: Credit rating based on ML could cause problems with consumer
local or relational, data to make lending decisions. Internal and external data sources can protection, ethical issues, and privacy by incorporating untoward alternative data
be systematically applied to underwriting decisions, improving both profitability and lending sources.
assessment accuracy.
• Shifting Macro Environment: A major change in the environment could make
historical data irrelevant for assessing new customers. Historical sample analysis
3.2.3 Advantages and Disadvantages of ML may not generalize for new applicants due to significant structural changes (such as
changes in financial development, macroeconomic policies, and industries).
Before diving in, it makes sense to understand the relative strengths and weaknesses of
machine learning models for bank credit risk analysis. • Applicant Gaming: If a factor becomes generally known as a credit indicator,
borrowers will often try to artificially improve it. While this happens today with FICO
Advantages
scores (applicants focus on inflating their score when seeking a mortgage), ML-based
• Makes smaller loans viable. ML makes it feasible and affordable for small lenders models would not be immune. For example, if borrowers discovered that the number
to determine credit risk. Banks will often refrain from investigating a small borrower’s of social media connections was valued by the algorithm, they could expand the size
credit because of the size of the loan. Reducing the cost of conducting a credit review of their network to achieve a better credit rating, thus gaming the system.
is a major financial consideration.
• Increases the value of “soft’ information. ML allows lenders to go beyond debt, 3.2.4 How ML Improves Lending
income, and repayment history. While those variables are critical they are not the
whole story on a borrower’s debt-servicing capacity. Think of machine learning as a power tool. If there is enough data (electricity), ML will
significantly outperform manual tools (historical statistics). It’s not like current lending
• Identifies nonlinear relationships. By searching for small sample partitioning approaches are bereft of data and analytics. Even the most basic lending model uses
relationships, ML models can capture local relationships between risk indicators and historical data to determine a projected default rate in order to calculate the risk premium.
credit risk outcomes that are not identified by traditional models or human agents. The difference is that ML approaches generate far more predictive accuracy, which can be
directed towards multiple aspects of a lending problem. This becomes a difference in kind
• Reduces information asymmetry: ML can reduce the asymmetry of information when applied in the right way.
between the lender and the borrower. Moral hazard and adverse selection problems
are less likely to arise when the lender incorporates more reliable information.
30 31Opening New Markets Increased Control 3.2.5 Thinking Like a Data Scientist
With increased competition in the lending Another way ML helps banks is by
So you’re convinced that machine learning offers significant advantages compared to
space, banks are looking to create a increasing control over formerly
traditional loan pricing and risk methods. How do you get started?
differentiated offering without increasing independent aspects of the lending
risk or sacrificing profitability. Data-driven problem. Take the 4 criteria of the cost- The first step to applying ML is beginning to think like a data scientist. The diagram below is
ML approaches can identify good borrowers plus model: Funding cost, operating cost, the bread and butter of how Blue Orange data scientists approach problems. Exploring the
among populations that were previously risk premium, and profit margin. They are amount and type of the data you have allows you to identify patterns where data is valuable
dismissed as high-risk. Increased predictive actually interdependent and banks can and determine the best method for analyzing it. Most business questions involve regression
accuracy permits a nuanced understanding allocate the increased predictive accuracy or classification, which we will explore in the next section.
of credit risk that opens up these new of machine learning to optimize along any
markets. dimension. ML-driven loan approval would
lower operating costs, better credit risk
A good analogy is junk bonds when they prediction allows for more accurate and
were first popularized in the 1980s. This was competitive risk premiums, and selective
a specific submarket where the risk/return lending for profitability would increase
ratio for lenders was out of whack. Due to ROE. How and where to make the tradeoff
historical norms and bondholders failing between those factors is a business
to incorporate new information, there decision. This decision itself (and the
were essentially free risk-adjusted returns consequences of favoring different criteria)
available to data-savvy lenders. Obviously, and be optimized with data.
this thinking can be taken too far when
speculative dynamics come into play, but
early movers who are willing to go beyond
the consensus with data often reap outsized
rewards.
At a higher level, there are 4 stages to implement an effective machine learning solution.
32 33Logistic Regression
1) Discover: We start by understanding a company’s business objective and exploring the
Regression involves predicting a quantity by figuring out which features are important for
initial data. We need to figure out what data is available to determine if machine learning is
the outcome. Logistic regression is a method for estimating the probability of an event
a viable solution. Robust, production level ML solutions typically require a range of tools and
occurring with binary data. This works great for predicting loans because the outcome data
a deep assessment of internal capabilities.
(default/repay or approve/deny) is binary.
2) Structure: Data gathering, cleaning, formatting, imputing, over/subsampling. ML demands
In the example below, specific borrower features are given different weights depending
significant computing power and access to highly available data, which is why building a
on how well they predict the loan being approved. The weighted sum correlates to the
modern data pipeline is a prerequisite for successful machine learning projects.
probability of approval and places the borrower at a point on the S-shaped curve (0 to 1).
3) Model: This is where the magic happens. Our Ph.D. data scientists experiment with Once the probability crosses a certain threshold determined by the model (say .6), the loan
models, tune hyperparameters, and train specific features in order to increase accuracy is considered likely to be approved and categorized as such.
beyond traditional statistical and business intelligence tools. ML models are used to capture
new insights and unlock the value of client data.
4) Integrate: The greatest ML model is useless unless it is implemented well. Technically,
we deploy the model to production and monitor it for accuracy, functionality, and
improvements. Strategically, we actively review the results and additional use cases with the
client team for feedback. The full technical stack is focused on ensuring business outcomes.
By approaching business questions with an understanding of the data science development
path, bank leaders are able to vastly improve the technical capabilities and implementation
outcomes of their teams.
Decision Trees
3.2.6 Machine Learning Models for Lending
A decision tree is a model that predicts the value of a target variable by learning simple
At the highest level, ML models use inputs (like income, age, and loan duration) to estimate decision rules inferred from the data features. It adopts a hierarchical structure like a
if a person should get a loan or not. Each of these variables has a different weight in the flowchart that starts from a root node, progresses to lower nodes through possible states
final decision. The models become more accurate over time by improving the distribution of or decisions (represented as a branch), and ends at the terminal node that shows the
input weights to better predict outcomes. consequence of the entire branch. Decision trees have the advantage of being used for both
regression and classification models.
Let’s dive in and explore 3 types of machine learning techniques that apply to lending:
Logistic Regression, Decision Trees, and Ensemble Learning. One of the advantages of decision trees is how well they can be understood by non-experts.
Consider the not granted decision on the left. If the borrower is under 40, has an income
below $166500, and saves less than $657 per month, then they don’t get approved for a
loan. This can seem similar to a heuristic or scorecard method, but the prioritization of
features is determined by the model itself for the greatest predictive accuracy.
34 353.3 Lending Club Case Study
The Lending Club is a private company founded in 2006 that loans money peer-to-peer. The
amount could be between 1K to 40K USD and the standard loan period is 36 months. The
platform has grown from $33 million in loan originations in 2009 to $10.9 billion in 2018.
The average LendingClub borrower has a FICO score of 699, 17.7% debt-to-income ratio
(excluding mortgage), 16.2 years of credit history, $73,945 of personal income and takes out
Ensemble Learning
an average loan of $14,553 that they typical use for debt consolidation or paying off credit
Ensemble learning is a method that combines the results of multiple machine learning cards.
models into one prediction. Imagine you have to answer a challenging question (like should
Lending Club has released a public dataset which has allowed us to compare the predictive
you approve a loan). Would you rather ask a single expert opinion or get the aggregate
accuracy of a machine learning model to one based on FICO. This approach has general
answer from a group of experts? Ensemble learning gives you the latter.
applicability to bank lending and allows us to take you through the process of building a
This is a more robust solution and provides more accurate results. In the example below real-world machine learning model step by step.
4 different ML models are combined to find a better solution. The downsides are that the
resulting model is less interpretable, the computation and design time is high, and model 3.3.1 Defining an Objective
selection is challenging. Nevertheless, if you have access to a data scientist, we have found
that Ensemble Learning is a superior method for lending accuracy. The first step of an ML project is to define the objective.
With Lending Club, borrowers with higher FICO credit scores (more stable and less risky) get
lower interest rates on their loans, whereas borrowers with lower credit scores (less reliable
and riskier) get higher rates. These loans are grouped in tranches from A (low risk) to E (high
risk). Loans with higher interest rates are more enticing from the investor’s point of view
because they provide a higher investment return. On the other hand, they pose a higher risk
of default. Therefore, a machine learning model that could predict which of the high-interest
loans are more likely to be repaid would bring added investment value while minimizing the
associated repayment risks.
Our objective is to build a machine learning scoring model that outperforms FICO with a
focus on high risk/high profit loans.
Now let’s see machine learning in action.
36 373.3.2 Exploring and Cleaning Data 5. Search for and remove outliers in the entire dataset.
6. Apply techniques to handle missing values. Options include setting a removal
threshold or imputing the value using the min/median flag.
Exploration
7. Search for multicollinearity and correlations among columns. That means finding the
We start by segregating the loans based on payment status. A Lending Club loan can have variables which are highly linearly related. The best practice is to remove them or set
one of six statuses: Current, Fully Paid, Grace Period, Late, Default, Charged Off. We group a threshold and keep only those that fulfill the condition.
these into two sets of loans: good or bad.
After completing these steps, our data gets filtered to only 20K rows by 85 columns.
Good loans
3.3.3 Modeling
• Current: All pending payments are up to date.
• Fully paid: The loan was fully reimbursed either at the expiration date or as a result of As discussed in the ML models section (3.2.6), we chose an ensemble learning method
an advance payment. (which combines several machine learning techniques into one predictive model) because
• Grace Period: Loan payment is due but within the 15 day grace period. it out performed any single model. The Gradient Boost Model (GBM) is a series of weak
predictive models based on decision trees used for regression and classification problems
Bad loans like lending.
• Late (16-30)/(31-120): Loan has not been current for either 16-30 or 31-120 days. This model is very efficient for handling features with many categories. GBM uses a mean
• Default: Loan has not been paid for an extended period (more than 120 days). encoding that replaces each categorical feature with only one numerical feature. Traditional
• Charged Off: There is no longer a reasonable expectation of further payments. one-hot encoding generates a lot of features, which leads to shallow decisions trees and
makes the classification complicated. In Boosting, each new tree is a fit on a modified
version of the original data set.
Preparation
To make sure that our model can generalize to new data, we split the dataset into three
The next step is preparing the data for analysis. The dataset has nearly 500,000
parts: train, validation, and test. The first two are used for training and to validate that our
observations and contains 150 measurable pieces of data that can be used for analysis. That
model is doing well. The test set is a portion of the original data that was not used to build
means we start with a dataset of 0.5M rows by 150 columns. It’s necessary to reduce the
the model. Running the model against it lets us see how the model will perform in the
feature dimensions and remove duplicates and errors to effectively analyze it.
presence of completely unknown data.
Preparation Steps:
3.3.4 How to Evaluate an ML Model
1. Remove syntax errors such as capital letters, underscores, whitespaces.
2. Verify the name of columns and check for uniqueness and semantic similarity. So how do we actually measure if our model is effective? By using a Confusion Matrix. A
3. Decide if the date is going to be considered with or without time. confusion matrix is a method that allows us to visualize the output of an algorithm. The
4. Standardize data types across all the columns such as decimals, integers, strings, etc. columns represent the actual values and the rows represent the predicted values. Looking
at the boxes lets us see how many predictions our model got right and wrong (and in what
way).
38 39You can also read

















































