Automated Facial Action Unit Recognition in Horses - ZHENGHONG LI - KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

DEGREE PROJECT IN COMPUTER SCIENCE AND ENGINEERING, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2020 Automated Facial Action Unit Recognition in Horses ZHENGHONG LI KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE

Automated Facial Action Unit Recognition in Horses ZHENGHONG LI Master in Machine Learning Date: July 5, 2020 Supervisor: Sofia Broomé Examiner: Hedvig Kjellström School of Electrical Engineering and Computer Science Swedish title: Automatisk igenkänning av ansiktsaktionsenheter hos hästar


iii Abstract In recent years, with the development of deep learning and the applications of deep learning models, computer vision tasks such as human facial action unit recognition have made significant progress. Inspired by these works, we have investigated the possibility of training a model to recognize horse facial action units automatically. With the help of the Equine Facial Action Coding System (EquiFACS) created by veterinarians recently, our aim has been to de- tect EquiFACS units from images and videos. In this project, we proposed a cascade framework for horse facial action unit recognition from images. We firstly trained several object detectors to detect the predefined regions of inter- est. Then we applied binary classifiers for each action unit in related regions. We experimented with different types of neural network classifiers and found AlexNet to work the best in our framework. Additionally, we also transferred a model for human facial action unit recognition to horses and explored strate- gies to learn the correlations among different action units.
iv Sammanfattning Under de senaste åren, med utvecklingen av djupinlärning och dess tillämp- ningar, har datorseendeuppgifter så som igenkänning av mänskliga ansiktsak- tionsenheter gjort stora framsteg. Inspirerad av dessa arbeten har vi undersökt möjligheten att hitta en modell för att automatiskt känna igen hästars ansiktsut- tryck. Med hjälp av Equine Facial Action Coding System som nyligen skapats av veterinärer kan vi upptäcka ansiktsaktionsenheter hos hästar som definieras i detta system från bilder och videor. I detta projekt föreslog vi ett kaskadram- verk för igenkänning av hästens ansiktsaktionsenheter från bilder. Först träna- de vi flera objektdetektorer för att upptäcka de fördefinierade regionerna av intresse. Sedan använde vi binära klassificeringar för varje aktionsenhet i rela- terade regioner. Vi testade olika modeller av klassificerare och fann att AlexNet fungerade bäst i våra experiment. Dessutom överförde vi också en modell för mänsklig ansiktsaktionsenhetsigenkänning till hästar och utforskade strategier för att lära sig korrelationerna mellan olika aktionsenheter.

Contents
1 Introduction 1
1.1 Research Questions . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Contributions and Limitations . . . . . . . . . . . . . . . . . 2
1.3 Societal Impact and Sustainability . . . . . . . . . . . . . . . 2
1.4 Ethical Considerations . . . . . . . . . . . . . . . . . . . . . 3
2 Background 4
2.1 Facial Action Coding System . . . . . . . . . . . . . . . . . . 4
2.1.1 Human Facial Action Coding System . . . . . . . . . 4
2.1.2 Equine Facial Action Coding System . . . . . . . . . 5
2.2 Image Classification . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.1 Generic Image Classification . . . . . . . . . . . . . . 5
2.2.2 Fine-grained Image Classification . . . . . . . . . . . 6
2.3 Object Detection . . . . . . . . . . . . . . . . . . . . . . . . 6
2.4 Facial Feature Point Detection and Head Pose Estimation . . . 7
2.4.1 Facial Feature Point Detection . . . . . . . . . . . . . 7
2.4.2 Head Pose Estimation . . . . . . . . . . . . . . . . . 9
2.5 Facial Action Unit Recognition . . . . . . . . . . . . . . . . . 10
2.5.1 Still Image-Based Models . . . . . . . . . . . . . . . 10
2.5.2 Sequence-Based Models . . . . . . . . . . . . . . . . 11
2.6 Animal Pain Recognition . . . . . . . . . . . . . . . . . . . . 12
2.6.1 Still Image-Based Model . . . . . . . . . . . . . . . . 13
2.6.2 Sequence-Based Model . . . . . . . . . . . . . . . . . 13
3 Methods 14
3.1 Dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2 Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.1 Cascade Framework . . . . . . . . . . . . . . . . . . 14
3.2.2 End-to-end model: DRML . . . . . . . . . . . . . . . 17
v
vi CONTENTS
3.3 Evaluation Methods . . . . . . . . . . . . . . . . . . . . . . . 19
4 Results 20
4.1 Finding the Best Model Based on the Four Relatively Easy
Classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.1.1 Binary Classification for AU101 (Inner Brow Raiser) . 20
4.1.2 Binary Classification for AD1, AU25, and AD19 . . . 23
4.2 Binary Classification for Five Other AUs . . . . . . . . . . . . 25
4.3 Learning Correlations among AUs . . . . . . . . . . . . . . . 26
5 Discussion 30
6 Conclusions 33
Bibliography 34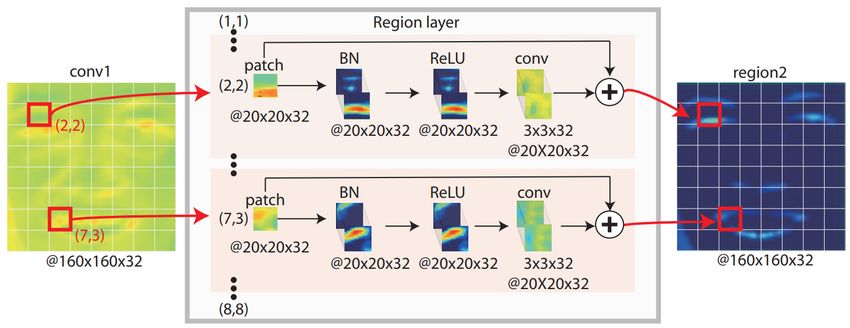
Chapter 1
Introduction
The horse is a highly social species like humans. In human medicine, we
usually analyze the facial expressions of people to assess their emotions. Sim-
ilarly, it is a good way to analyze horse behaviors through horse facial ex-
pressions. Earlier studies show that the facial expressions can be described
as combinations of a number of facial action units according to the observ-
able changes in the skin and related facial muscle movements. In recent years,
a system for the coding of the horse facial action unit called Equine Facial
Action Unit Coding System (EquiFACS) [1] has been created. Based on the
EquiFACS, we can recognize horse facial actions by detecting their facial ac-
tion units.
In the past few years, great progress has been made in the field of computer
vision. As the application of deep learning models such as convolutional neu-
ral networks (CNN) in computer vision, in some tasks such as image classifi-
cation, the accuracies of computer models are even competitive with human
capabilities. Related works for human facial action unit detection have also
made progress in these years. Therefore, we consider finding a model to auto-
matically recognize horse facial actions. This project mainly focuses on how
to detect the facial action units of horses from still images. We tried to transfer
models for human action unit detection to horses, and we also applied classi-
cal CNN model to our task. Finally, we found a cascade framework that works
relatively better and could yield reasonable results.
1.1 Research Questions
The goal of this project is mainly to address the following research questions:
• Is it possible to find a computer vision method to detect horse facial
1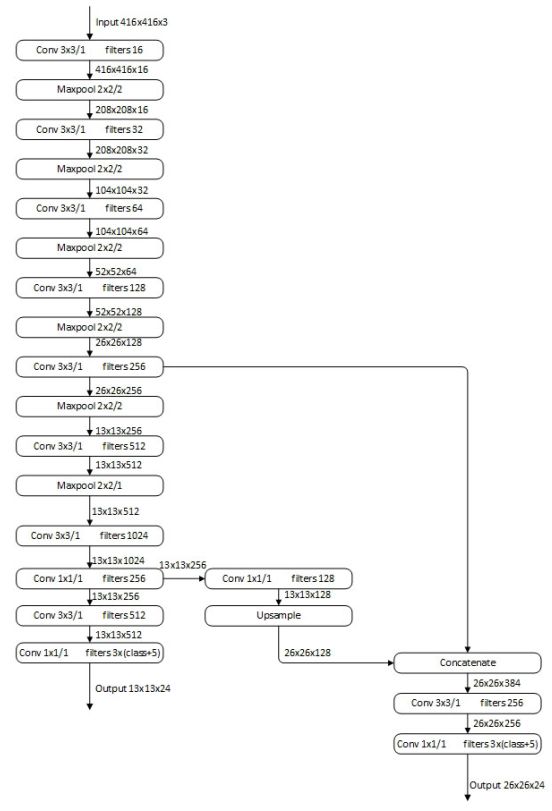
2 CHAPTER 1. INTRODUCTION
action units automatically and accurately from images?
• Are the outputs of our models adequate for horse facial action unit recog-
nition?
For the first question, based on our experiment results shown in Chapter4 Re-
sults, we can say that we have found a model that can realize such goals. For
the second question, this will be further discussed in Chapter5 Discussion.
1.2 Contributions and Limitations
There are three main contributions of our project. First, we proposed a cas-
cade framework for the recognition of horse facial action units. Second, we ex-
plored different classifiers and found the best model for our framework. Third,
we transferred models for human facial action unit recognition to horses and
compared it to our framework.
The main limitation of this project was posed by the size of the dataset. As
there is no published dataset for horse facial action unit recognition, we use an
unpublished dataset provided by veterinarians from the Swedish University of
Agricultural Sciences. This dataset is a small and unbalanced dataset. There-
fore, the amount of data may not support the training of a complex model, and
it also limits the capability of generalization of our models. Another limitation
is caused by the noise of the dataset. Our dataset is originally a video dataset
and we sample one frame per video for our experiments. Because of this, there
exist motion blurs in some frames which will cause our model overfit. In ad-
dition, there is no previous work for horse facial action unit recognition. We
do not have any direct reference for our task and we do not have a baseline for
the evaluation.
1.3 Societal Impact and Sustainability
To our best knowledge, we are the first group to research how to automatically
recognize horse facial action units. Our proposed framework is intended to
help people analyze horse behaviors such as pain recognition. In this way, it
will be more convenient for veterinarians to accurately detect whether a horse
has a disease and help them keep horses in health. Also, we believe that this
work is worth learning for similar tasks for other animals and can potentially
help people and animals live in harmony.CHAPTER 1. INTRODUCTION 3
As for the sustainability, according to the Sustainable Development Goals
adopted by the member countries of the United Nations, our project will mainly
contribute to the Goal 15: life on land. One of the main aspects of this goal is
to halt biodiversity loss on land. Although horse is not an endangered species,
this project could help in the case that the method is transferable to other en-
dangered species. If we can know more about animals’ behaviors, we can
save those species by helping with their well-being and saving their lives from
diseases.
1.4 Ethical Considerations
One consideration is about whether the data used in this project is collected
ethically. In this project, the original dataset for experiments consists of horse
films. These films are provided by veterinarians, and they have ethical permis-
sions to collect them. Moreover, although our project has many positive con-
tributions to our society, there are still some potential unethical impacts such
as the invasion of privacy. As our work could also be transferred for human
facial action unit recognition and human emotion estimation, this technique
may potentially violate people’s privacy.Chapter 2
Background
For many species, facial expressions can be described as combinations of a
number of facial action units defined in related facial action coding systems.
Such coding systems are the basis of facial action unit recognition tasks for
certain species. Before studies for animals, a large number of related studies
for human facial action unit recognition were carried out. Also, generic works
in computer vision fields and specific studies about faces are closely related to
horse facial action unit recognition. In this chapter, we will briefly introduce
related works for our tasks.
2.1 Facial Action Coding System
2.1.1 Human Facial Action Coding System
Facial expression has been a focus of emotion research for over a hundred
years [2]. In 1978, Ekman and Friesen proposed the Facial Action Coding
System (FACS) [3]. Through electrically stimulating individual muscles and
learning to control them voluntarily, each action unit is associated with one
or more facial muscles [4]. In 2002, Ekman et al proposed a new version of
human FACS [5] which has been widely used for human emotion recognition.
FACS 2002 specifies 9 action units in the upper face and 18 in the lower face.
In addition, there are 14 head positions and movements, 9 eye positions and
movements, 5 miscellaneous action units, 9 action descriptors, 9 gross behav-
iors, and 5 visibility codes. FACS is a observer-based measurement of facial
expression, with which we can recognize human facial expression and emotion
more accurately.
4CHAPTER 2. BACKGROUND 5 2.1.2 Equine Facial Action Coding System Inspired by the progress of human FACS, a variety of animal facial action coding system has been created. Since the horse is a highly social species, to enhance the understanding of communication and cognition in horses and provide insights into the effects of domestication, Wathan et al [1] created Equine Facial Action Coding System (EquiFACS). EquineFACS consists of action units (AUs) and action descriptors (ADs), where AUs represent the contraction of a particular facial muscle (or set of muscles) and the resulting facial movements, and ADs represent more general facial movements without specific related facial muscles. For example, AU47 half blink is particularly caused by the muscles around the eyes. But AD1 eye white increase can be caused in various ways such as the movement of the eyeballs, which is not related to facial muscles, and the wide opening of the eyes, which is related to the muscles around the eyes. In addition to the ADs similar to human fa- cial ADs, the movement of the ears of horses is also very important for their facial expression. Such action descriptors are specifically named as ear action descriptors (EADs). This project is to recognize the equine facial actions by recognizing the AUs and ADs defined in EquiFACS. 2.2 Image Classification Recognizing horse facial action units from still images can be considered as a fine-grained image classification task. Image classification task usually can be categorized into two classes, generic or fine-grained classification. The main difference is that fine-grained classification deals with categories that are very similar such as bird species. Usually, models for fine-grained classification are based on models for generic image classification. 2.2.1 Generic Image Classification Before deep learning was widely applied in computer vision, many non-deep learning methods were proposed. These methods usually extracted some man- made features such as histogram of oriented gradients (HOG) and scale-invariant feature transform (SIFT) [6], which features were then used to train non-deep classifiers such as random sample consensus (RANSAC) [7] and support vec- tor machine (SVM) [8]. After Krizhevsky et al. proposed the AlexNet [9], deep convolutional neural networks (CNN) have replaced the traditional meth- ods in image classification fields with their outstanding performance. There-
6 CHAPTER 2. BACKGROUND
fore, this project will be mainly based on deep learning methods.
CNN LeNet-5 [10] was the first convolutional neural networks (CNN). CNNs
typically consist of stacked convolutional layers followed by fully-connected
layers. CNNs are trained by error back-propagation [11]. Besides the
AlexNet mentioned above, other classical CNNs such as VGG [12],
GoogleNet [13], and ResNet[14] have been applied as feature extrac-
tors in various fields.
Capsule To enhance the expressive power of neural networks, Sabour et al
[15] proposed capsules. A capsule is a group of neurons whose activity
vector represents the instantiation parameters of a specific type of entity
such as an object or an object part. Unlike the scalar output of a standard
CNN classifier, the output of a capsule is a vector. The length of the
activity vector is to represent the probability that the entity exists and
the orientation is intended to capture any other relevant attributes of the
object, such as appearance or orientation. Capsules have been applied
in facial action unit detection fields [16].
2.2.2 Fine-grained Image Classification
Fine-grained image classification methods usually can be categorized into two
classes: strongly or weakly supervised methods. Weakly supervised methods
only employ class labels for training, while strongly supervised methods ad-
ditionally employ labeled object bounding boxes for regions of interest [17]
or part annotations [18] for training. For weakly supervised methods, to make
the model focus on the regions of interest, attention mechanisms have been
employed [19, 20]. Besides these methods, a simple alternative way for fine-
grained image classification is to directly apply a generic image classification
model on detected regions of interest.
2.3 Object Detection
As is mentioned above, fine-grained image classification models should focus
on regions of interest. Therefore, object detection can be employed in our tasks
to help localize the regions of interest such as faces, eyes, and nostrils. Then
the following classifiers can be only applied in these regions to improve the
accuracy of the facial action unit recognition. Usually object detection models
can be classified into two categories: anchor-based models and anchor-free
models.CHAPTER 2. BACKGROUND 7
Anchor-based Anchor-based models do the detection task based on the an-
chor box proposals. Usually anchor based methods can be divided into
two categories: one-stage method and two-stage method. One-stage
methods such as YOLOv2 [21]/v3 [22] and SSD [23] generate the an-
chor proposals and the detection in one stage and can be trained in an
end-to-end manner. Two-stage methods such as Faster-RCNN [24] first
generate anchor box proposals via a pre-trained region proposal network
(RPN) and then use ROI-Pooling and detection networks on the region
proposals for the final detection.
Anchor-free Anchor-free methods directly predict the bounding boxes with-
out anchor box proposals and are faster than anchor-based models in
most cases. Traditional anchor-free models such as YOLOv1 [25] are
not able to reach the accuracies of anchor-based models. Recently, many
advanced anchor-free models have been proposed, such as CornerNet
[26] and SAPD [27] whose accuracies are highly competitive with anchor-
based methods at obviously faster speed. Specifically, SPAD uses soft-
weighted anchor points and soft-selected pyramid levels for the feature
pyramids to balance the speed and accuracy for anchor-free detectors
and reached the state-of-the-art performance for object detection.
2.4 Facial Feature Point Detection and Head
Pose Estimation
As is mentioned above, part annotations are usually employed in fine-grained
image classification. Facial feature points is the part annotations that are usu-
ally applied in facial action unit detection frameworks. After the facial feature
points have been detected, regions that are relevant to facial action units such
as eyes, nostrils, and mouth can be cut out for classification. Head pose es-
timation can be used for image rectification and it is usually combined with
facial feature point detection.
2.4.1 Facial Feature Point Detection
Facial feature point detection is widely used in many applications such as face
recognition, facial expression analysis, and 3D face modeling. Existing meth-
ods are categorized into two primary categories according to whether there is
the need of a parametric shape model: parametric shape model-based methods
and nonparametric shape model-based methods [28].8 CHAPTER 2. BACKGROUND
Parametric models rely on some particular distributions and models such
as multivariate Gaussian distributions or Gaussian mixtures. The number of
parameters in a parametric model is fixed. One of the most common point dis-
tribution models is proposed by Cootes and Taylor [29]. Parametric models
can be further divided into two categories: local part model-based methods
and holistic model-based methods. Local part model-based methods, e.g. Ac-
tive Shape Models [30], usually detect each facial feature point around some
regions locally and then these detected points are constrained by a global shape
model. Holistic model-based methods, e.g. Active Appearance Models [31],
usually estimate the location of facial feature points from a holistic texture
representation combined with a global shape model.
Nonparametric models are not based on specific shape distributions. Such
methods are usually categorized into four categories according to the con-
nection between shape and appearance: exemplar-based methods, graphical
model-based methods, cascaded regression based methods, and deep learning-
based methods. Exemplar-based methods [32] generally find the constraint for
the configuration of facial feature points by exemplar shapes in the training set.
Graphical model-based methods [33] generally constrain the configuration of
facial feature points via graphical models such as tree structures or Markov
random fields. Cascaded regression-based methods [34] directly estimate a
regression function from image appearance in a coarse-to-fine manner with-
out explicitly learning any shape model or appearance model. Deep learning-
based methods either learn the nonlinear shape and appearance variation or
learn the nonlinear mapping from the face appearance to the face shape. Some
specific deep learning-based methods have been effectively applied in animal
facial feature point detection:
Interspecies [35] is a specific transfer learning method that transfer knowl-
edge gained from human faces to animal faces. Instead of directly fine-
tuning a network trained to detect keypoints on human faces to animal
faces, Rashid et al. proposed a more effective method that warps the ani-
mal images to human-like images first and then fine-tunes the pretrained
human facial feature point detector for animals. This approach has three
main steps: (1) finding nearest neighbor human faces that have similar
pose to each animal face; (2) using the nearest neighbors to train an
animal-to human warping network; and (3) using the warped (human-
like) animal images to fine-tune a pretrained human key point detector
for animal facial keypoint detection.
DeepLabCut [36] is a toolbox for extracting the geometrical configurationCHAPTER 2. BACKGROUND 9
of multiple animal body parts, which can be used for animal facial fea-
ture point detection. The idea is to find an effective model to detect the
keypoints of animal body parts with a small amount of data for training.
This model is mainly based on a subset of DeeperCut [37]. Both of these
two algorithms are mainly based on variations of ImageNet-pretrained
[38] ResNet with readout layers that predict the location of a body part.
The network of DeepLabCut is actually a pretrained ResNet backbone
followed by a series of deconvolutional layers. This model can be easily
trained for animal facial feature point detection with a small number of
training images (≈ 200).
2.4.2 Head Pose Estimation
Head pose estimation is to infer the orientation of a person’s (or an animal’s)
head relative to the view of a camera. Since the heads in images are usually
not upright, head pose estimation can help us rectify the image for further
feature extraction. Head pose estimation is closely related to facial feature
point detection. Some head pose estimation methods can be transferred to
facial feature point detection. Meanwhile, some other head pose estimation
methods are based on the detected facial feature points. Head pose estima-
tion methods generally consist of eight categories [39]: appearance template
methods, detector array methods, nonlinear regression methods, manifold em-
bedding methods, flexible models, geometric methods, tracking methods, and
hybrid methods. Among these methods, nonlinear regression methods, flexi-
ble models, and geometric methods are closely related to facial feature point
detection:
Nonlinear regression methods Nonlinear regression methods estimate pose
by learning a nonlinear functional mapping from the image space to one
or more pose directions. Nonlinear regression methods are closely re-
lated to cascaded regression-based methods for facial feature point de-
tection. For example, [34] for facial feature point detection is based
on Cascade Pose Regression (CPR) [40] method for pose estimation.
Specifically, CPR starts with a loosely specified initial guess and pro-
gressively find the target regression function in a coarse-to-fine man-
ner. Each refinement is carried out by a different regressor, and each
regressor performs simple image measurements that are dependent on
the output of the previous regressors. This method mainly changes the
parameter error in CPR to the alignment error and employs new shape
indexed features for facial feature point detection.10 CHAPTER 2. BACKGROUND
Flexible models Flexible models are fit to the facial structure of the individ-
ual in the image plane. Head pose is estimated from feature-level com-
parisons or from the instantiation of the model parameters. A common
flexible model for head pose estimation is the AAM [31] which is also
used for facial feature point detection. Once the model has converged
to the feature locations, an estimate of head pose can be obtained by
mapping the appearance parameters to a pose estimate [41].
Geometric methods Geometric methods use head shape and the precise con-
figuration of local features to estimate pose. A straightforward way is
to use five facial feature points (the outside corners of each eye, the out-
side corners of the mouth, and the tip of the nose), the facial symmetry
axis is found by connecting a line between the midpoint of the eyes and
midpoint of the mouth [42]. Moreover, some simple shapes can also be
used for head pose estimation. For example, for near-frontal faces, the
yaw of a face can be reliably estimated by creating a triangle between
the eyes and the mouth and finding its deviation from a pure isosceles
triangle [43].
2.5 Facial Action Unit Recognition
We will now go through methods in the literature for detecting facial action
units. Since most of the animal FACS were not created until recent years, there
are still only very few studies for animal facial action unit recognition. Instead,
many studies in human facial action unit recognition have been done which
are worthy of reference for animal facial action unit recognition. Recently,
deep learning has been widely applied in facial action unit recognition. These
models can be classified into two categories with respect to the inputs: still
image-based models or sequence-based models.
2.5.1 Still Image-Based Models
Still image-based models usually attempt to focus on important regions of the
image such as eyes and mouth to detect relative AUs. Regional learning meth-
ods and attention mechanisms are usually employed in these models.
DRML [44] is the first algorithm that jointly uses CNN with regional learning
methods and multi-label sigmoid cross-entropy loss for facial action unit
detection. As AUs are active on sparse facial regions, the authors useCHAPTER 2. BACKGROUND 11
a regional learning method for facial action unit detection by inserting
a region layer into a classical CNN for image classification. The input
feature map from the lower convolutional layer to the region layer is uni-
formly divided into 8 × 8 patches, and each patch will be applied with
a convolution layer to get a re-weighted patches. The output is a con-
catenation of all re-weighted patches. Finally, the multi-label sigmoid
cross-entropy loss is employed for training.
ARL [45] is an end-to-end deep learning based attention and relation learn-
ing framework for facial action unit recognition. The framework con-
tains three parts. The first part is for hierarchical and multi-scale region
learning. The three intermediate layers for 8 × 8, 4 × 4 and 2 × 2 patches
are cascaded, and the output of each intermediate layer will be concate-
nated and then summed element-wise with the output of the input layer.
The second part is for channel-wise attention learning first, followed by
spatial attention learning. The third part is for pixel-wise relation learn-
ing via a fully-connected CRF model.
Capsule Network [16] for facial action unit recognition is a method to utilize
the higher expressive power of capsules than standard neurons to detect
AUs. Similar to the CapsNet [15], the proposed network consists of
three parts. The first part is convolutional layers which are employed as
a mid level feature extractor. The second part is two capsule layers. The
primary capsules further develop image features and transform scalar
inputs from the convolution layers to vector representations. The class
capsules collate the vector outputs of the primary capsules to form the
final class predictions. The third part is a reconstruction model for visu-
alizing the properties learned by the class capsules and regularizing the
overall network.
2.5.2 Sequence-Based Models
Compared to still image-based models, sequence-based models can utilize
both spatial and temporal information for facial action unit recognition. The-
oretically, some AUs are very hard to be discriminated from still frames. For
example, AU43 eye closed and AU45 blink in FACS 2002 (similarly AU143
eye enclosure and AU145 blink in EquiFACS) are quite similar actions and
the main differences are the action speed and the duration of the eye closed.
Therefore, the temporal dependence is significant for identifying some AUs.12 CHAPTER 2. BACKGROUND
Long Short-Term Memory (LSTM) [46] methods are commonly employed for
temporal feature modeling.
CNN+LSTM [47] is a hybrid network to model the spatial representation,
temporal dependence, and AU correlation for facial action unit detec-
tion. Specifically, spatial representations of each frame are extracted by
a CNN. Then, LSTMs are stacked on top of the CNNs to model tempo-
ral dependence. Finally, two fully connected layers with shared param-
eters are placed on top of both CNNs and LSTMs as a fusion network
to aggregate spatial and temporal correlations and produce per-frame
prediction.
ROI [48] is a deep learning framework for AU detection with region of inter-
est (ROI) adaptation, integrated multi-label learning, and optimal LSTM-
based temporal fusing. The authors use 20 ROI Nets for 20 selected face
regions respectively. The ROIs are localized via an ensemble of regres-
sion trees method [49] for facial landmark detection. Then the output
of a VGG feature extractor will be cropped for each ROI Net for more
specific feature extraction. The output of each ROI Net will be concate-
nated as an input of the LSTM. Finally, the LSTM will learn the temporal
dependencies and make the prediction via multi-label learning.
TCAE [50] is a self-supervised model that learns representations for AU de-
tection from videos without manual annotations. Since the transforma-
tion between two face images is caused by both facial actions and head
motions, the authors propose a Twin Cycle Autoencoder (TCAE) to dis-
entangle the facial action related movements and the head motion related
ones. Specifically, TCAE is trained to respectively change the facial ac-
tions and head poses of the source face to those of the target face. After
the training process, the obtained encoder for AU related movements
can be employed for AU detection by stacking a linear classifier on the
top.
2.6 Animal Pain Recognition
Animal pain recognition is a further task that is closely related to animal fa-
cial action unit detection. Since pain is usually a sign of diseases, animal
pain recognition can help us for in improving animal welfare. As for horses,
Gleerup et al. [51] found that horses displayed specific facial expressions when
in pain. As very few studies have been done in this field, only two specificCHAPTER 2. BACKGROUND 13 methods will be discussed in the following subsection. Similar with the facial action unit detection models, one is a still image-based model while the other is a sequence-based model. 2.6.1 Still Image-Based Model Lu et al. [52] proposed one of the earliest work for animal pain recognition. They detect the facial action units of sheep first and then use the features of AUs for pain estimation. This method consists of five main steps: face detec- tion, facial landmark detection, feature-wise normalization, feature descriptor and pain level estimation. Firstly, the frontal face is detected by Viola-Jones object detection framework [53]. Then, CPR is employed to detect sheep facial landmarks. Next, feature-wise normalization is carried by rectifying the im- age based on the facial landmarks and cropping the regions of interest. Then, HOG is used for the feature descriptors. Finally, an SVM is applied to estimate the pain scores of sheep. 2.6.2 Sequence-Based Model Broomé et al. [54] proposed the first work for equine pain recognition from videos via a deep recurrent two-stream architecture. The framework of the proposed model is mainly based on a Convolutional LSTM (C-LSTM) model [55], where the fully-connected matrix multiplications involving the weight matrices in the LSTM equations are replaced with convolutions. The authors further expand it to a two-stream [56] (spatial stream on RGB and temporal stream on optical flow) C-LSTM network, referred to as C-LSTM-2. The out- puts of the two streams are fused by element-wise multiplication or addition for the final classification.
Chapter 3
Methods
3.1 Dataset
The dataset we are working on is an unpublished dataset for automated equine
facial action unit detection. There are 21066 labeled video clips for 31 ac-
tion units (AUs) or action descriptions (ADs), and we randomly sampled one
frame from each clip for our experiments. However, the distribution of labeled
examples is quite uneven. For instance, there are at most 5280 labeled clips
for EAD104 ear rotator, but only one labeled clips for AU160 lower lip relax.
Only 11 categories (Table 3.1) have more than 200 labeled clips, which are
considered as the least required number of examples for training, validation,
and test. Note that because of the lack of annotations for the horse individ-
uals in the videos, we cannot guarantee that the horses in the test set do not
appear in the training set. To make the results reasonable for most classes, we
randomly separate 70 percent of the labeled clips for training, 15 percent for
validation, and 15 percent for the test. In this way, except for AU5, each class
will have at least 50 positive examples for validation or test. We also moved
the clips that overlap with each other to the same set to avoid the frames that
are closely correlated appearing in different sets.
3.2 Algorithm
3.2.1 Cascade Framework
Considering the quite uneven distribution of the labeled examples in the dataset,
directly applying a multi-label learning method may not work well, as it will
be easy to get stuck in a local minimum where the model always predicts the
14CHAPTER 3. METHODS 15
Table 3.1: Selected Action Units
Code Action Units Labels
AD1 Eye white increase 395
AD19 Tougue show 451
AD38 Nostril dilator 729
AU101 Inner brow raiser 1933
AU145 Blink 3888
AU25 Lips part 484
AU47 Half blink 1826
AU5 Upper lid raiser 209
AUH13 Nostril lift 354
EAD101 Ears forward 4813
EAD104 Ear rotator 5280
Figure 3.1: A raw example of AD1 eye white increase in our dataset
dominant AUs to be true and predicts the others to be false. Therefore, we
choose to employ multiple binary classifiers for these action units. Also, such
binary classification for each action unit is a fine-grained image classification
task so that directly applying networks for common image classification tasks
will fail to reach acceptable results. Noticing that the horse face is usually too
small in a raw frame (Figure 3.1), and inspired by the framework for sheep pain
estimation [17], we proposed our cascade framework (Figure 3.2) for horse fa-
cial action unit recognition. For each input image, we first detect the horse face
and cut it out. Then we extract eye regions and the lower face regions from
the detected face regions. (Because the eye regions and the lower face regions
are too small in raw frames, the detectors are not able to detect these regions
directly.) Finally, classical CNNs for image classification will be employed
as binary classifiers for related AUs in these regions. Note that each part is
trained separately.16 CHAPTER 3. METHODS
Figure 3.2: Our Cascade Framework for Horse Facial Action Unit Recognition
(Each part is trained separately.)
Object Detector: YOLOv3-tiny
YOLOv3 [22] is a widely applied object de-
tector. In our project, we employed its light
implementation YOLOv3-tiny (Figure 3.3),
which is easier to be transferred to a small
dataset to detect regions of interest, such as
faces and eyes. YOLOv3 employs Darknet-
53 as the feature extractor and refers to the
feature pyramid for detection, i.e., small fea-
ture maps for large objects and large fea-
ture maps for small objects. YOLOv3 gen-
erates three sizes of feature maps, and each
of them contains three anchors, including
the sizes and positions of predicted bound-
ing boxes, objectness scores for each bound-
ing box, and predicted classes. YOLOv3 also
employs nine bounding box priors and com-
bines them with the anchors for the final pre-
diction. Compared to YOLOv3, YOLOv3-
tiny uses a smaller feature extractor and only
generates two sizes of feature maps, which
makes it easier to train. Figure 3.3: Architecture of
Yolov3-tiny (figure from [57])CHAPTER 3. METHODS 17
Binary Classifier: AlexNet
After the eye detector or lower face detector,
the detected region will be resized as 64 × 64. Then we can directly apply
generic image classification models for action unit binary classification. We
tried AlexNet, VGG, and ResNet, and we found that the AlexNet reached the
best performance among these three. The specification of the modified archi-
tecture of AlexNet can be found in Table 3.2. Note that for the experiments in
face regions, the architectures are the same as the models for ImageNet, and
the size of the input is always 224 × 224.
Table 3.2: Modified Archtecture of AlexNet for Binary Classification
Stage Filter Output Shape
input image - 64 × 64 × 3
conv1 5 × 5 × 64, stride=2, padding=2 32 × 32 × 64
maxpool 2×2 16 × 16 × 64
conv2 3 × 3 × 192, stride=1, padding=1 16 × 16 × 192
maxpool 2×2 8 × 8 × 192
conv3 3 × 3 × 384, stride=1, padding=1 8 × 8 × 384
conv4 3 × 3 × 256, stride=1, padding=1 8 × 8 × 256
conv5 3 × 3 × 256, stride=1, padding=1 8 × 8 × 256
maxpool 2×2 4 × 4 × 256
avgpool 1/2 input_W × 1/2 input_H 2 × 2 × 256
fc_1 4096 4096
fc_2 2048 2048
output 1 1
3.2.2 End-to-end model: DRML
Besides our framework, we also conducted experiments on the Deep Region
and Multi-label Learning model (DRML) for facial action unit recognition.
DRML model is a classical deep model for human facial action unit detection,
and we tried to transfer it to our task. (Note that because the pre-trained DRML
was not publicly available, in the following experiments, we trained the DRML
model from a random initialization.) As the facial action units (AUs) are ac-
tive in sparse facial regions, the authors use the regional learning method for
facial action unit detection. Moreover, to learn potential correlations between
AUs, multi-label learning can be applied in facial action unit recognition. The18 CHAPTER 3. METHODS
authors realize these functions by insert a region layer into a common convo-
lutional neural network and use a multi-label sigmoid cross-entropy loss for
training. The network architecture is shown in Figure 3.4.
Figure 3.4: The architecture of DRML model (figure from [44])
The region layer is shown in Figure 3.5. A input feature map from conv1
is uniformly divided into 8 × 8 patches, and each patch will be forwarded to a
convolution layer to get a re-weighted patches. The output is a concatenation
of all re-weighted patches.
Figure 3.5: Region layer for deep region learning (figure from [44])
Let the number of AUs be C, the number of samples be N , the ground
truth Y ∈ {−1, 0, 1}N ×C , Yi,j indicate the (i, j)-th element of Y , and the
predictions Ŷ ∈ RN ×C . The loss function is :
N C
1 XX
L(Y , Ŷ ) = − {[Ync > 0] log Ŷnc + [Ync < 0] log(1 − Ŷnc )} (3.1)
N n=1 c=1
where [x] is an indicator function returning 1 if the statement x is true and 0CHAPTER 3. METHODS 19
otherwise. In our experiments, we did not include zero examples, i.e., Y ∈
{−1, 1}N ×C .
3.3 Evaluation Methods
It is common to employ confusion matrix (Table 3.3) to analyze the perfor-
mance of a binary classifier or a detector.
Table 3.3: Confusion Matrix
Predict Classes
Classes = Yes Classes = No
Actual Classes Classes = Yes True Positive (TP) False Negative (FN)
Classes = No False Positive (FP) True Negative (TN)
Based on the confusion matrix, we usually calculate four values for the
result evaluation, accuracy, precision, recall, and F1 score. These values can
be calculated by:
TP + TN
Accuracy = (3.2)
TP + FP + TN + FN
TP
P recision = (3.3)
TP + FP
TP
Recall = (3.4)
TP + FN
2 ∗ P recision ∗ Recall
F 1 score = (3.5)
P recision + Recall
Accuracy is the most intuitive performance measure, and it is a ratio of
correctly predicted observation to the total observations. Precision is the ratio
of correctly predicted positive observations to the total predicted positive ob-
servations. Recall is the ratio of correctly predicted positive observations of
all positive observations in the actual class. F1 score is the weighted average
of precision and recall. Usually, F1 score is used to evaluate detectors. In our
tasks, we use F1 score to evaluate multi-label classifiers and use both F1 score
and accuracy to evaluate the binary classifiers.Chapter 4
Results
According to veterinarians, four out of the eleven selected AUs are theoret-
ically easier to be recognized from still images: AU101 (inner brow raiser),
AD1 (eye white increase), AU25 (lips part), and AD19 (tongue show). The
reason is that in these regions, there is no other AU that is mutually exclusive
with them and their changes are relatively easy to be recognized. Therefore,
we started with these four AUs to find a model that works for our tasks and
then applied the found model to the others. Finally, we tried to let our models
learn the correlations among the four relatively easy AUs.
4.1 Finding the Best Model Based on the Four
Relatively Easy Classes
We started with the simplest task that we used a number of binary classifiers
for AU detection. As we have the most labeled examples for AU101 (inner
brow raiser) among these four classes, we firstly did experiments on AU101 to
find the most reasonable model. Then, we apply it to the other classes to test
whether the found model can work for other AUs.
4.1.1 Binary Classification for AU101 (Inner Brow Raiser)
According to the EquiFACS [1], the main appearance changes of AU101 is
that the skin above the inner corner of the eye is pulled dorsally and obliquely
towards the medial frontal region (Figure 4.1). Therefore, we believe that the
best feature to learn is the angular shape of the inner brow.
To help train the binary classification models, we balanced the positive ex-
amples and negative examples in training. For the consistency of our results,
20CHAPTER 4. RESULTS 21
we also balanced the positive and negative examples in the validation set and
test set. In this way, the accuracy and F1 score results for a random classifier
are both at 50 percent. The same was done for the experiments of binary classi-
fication for other AUs. Although for the detection task, we are more interested
in F1 score than accuracy, it is not as suitable for our binary classification ex-
periments as accuracy. Because some models failed in the following binary
classification experiments, sometimes a state that almost always predicts true
will get the highest F1 score. (In this case, the precision is 50 percent while
the recall is 100 percent, and thus, the F1 score is 66.7 percent.) Based on our
observation, we found that the result of accuracy is more stable in our exper-
iments. Therefore, we chose accuracy as the criterion for the model selection
in our binary classification experiments.
Figure 4.1: An example of the appearance changes of AU101 (figure from [1])
Face Region Crops
We first employed the DRML model for binary classification only on cropped
face regions and compared the results to the classification on the original im-
ages. We then compared the results of the DRML model to AlexNet, VGG,
and ResNet on the face region. The classification accuracies are shown in Ta-
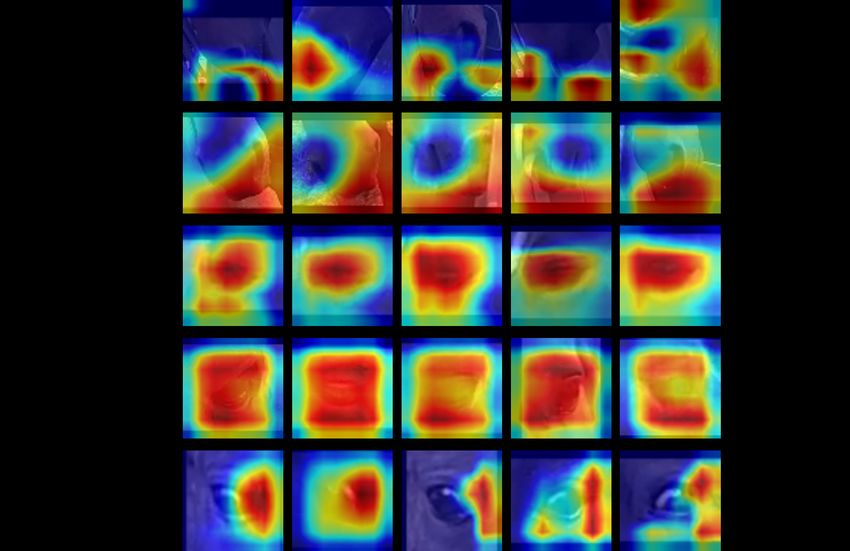
ble 4.1. We also employed Grad-CAM [58] to analyze which are the regions
of interest that the network learns. Grad-CAM is a tool that uses the gradients
of any target concept flowing into the final convolutional layer to produce a
coarse localization map highlighting the important regions in the image for
predicting the concept. The results are shown in Figure 4.2, the red regions
yield the higher classification scores.
Although directly applying the DRML model to original frames obtained22 CHAPTER 4. RESULTS
Table 4.1: Accuracies and F1 Scores of Binary Classifications of AU101
Validation Test
Model
Accuracy F1 Score Accuracy F1 Score
DRML 68.7 68.5 69.4 68.3
DRML (face) 63.7 62.0 60.6 57.7
AlexNet (face) 64.2 65.3 64.3 64.6
VGG19 (face) 60.9 60.3 60.4 59.8
ResNet34 (face) 54.4 56.3 54.4 55.6
the best accuracy, the network only seldom focuses on face regions. The rea-
son is that the examples of AU101 are not evenly distributed among different
scenes and different individuals in our dataset. As we have mentioned above
that we randomly separate the training, validation, and test set because of the
lack of the annotations of individuals, the distribution of the examples are
similar in these three sets. Therefore, the correlations among the AU101, in-
dividuals, and backgrounds are relatively strong and easy to learn. Thus, the
DRML model tends to learn these correlations, which is not a desirable behav-
ior. To let the model focus on the faces, we cropped the face region out with
the help of the face detector. However, even though we trained the DRML
only on face regions, it seldom focuses on eye regions, which are considered
to be the expected regions of interest. Instead, it learns the correlations among
other face regions and sometimes also focuses on the remaining background
patches. Similarly, AlexNet and VGG19 also only rarely focused on the eye
region. ResNet34 failed to learn valid features in this task.
Eye Region Crops
Since directly applying models to face regions, they cannot focus on the re-
gion that we expect it to learn, we then trained an eye detector to force the
models to learn the features of eye regions. We trained the eye detector on the
detected face region because eye regions in original frames are too small to fit
the bounding box prior.
In this case, since we do not need to use the deep region layer in the DRML
model, we replaced the deep region layer with a simple 3 × 3 convolution
layer. We applied this modified model to the eye regions, and we also applied
AlexNet, VGG, and ResNet in this experiment. The results are shown in Table
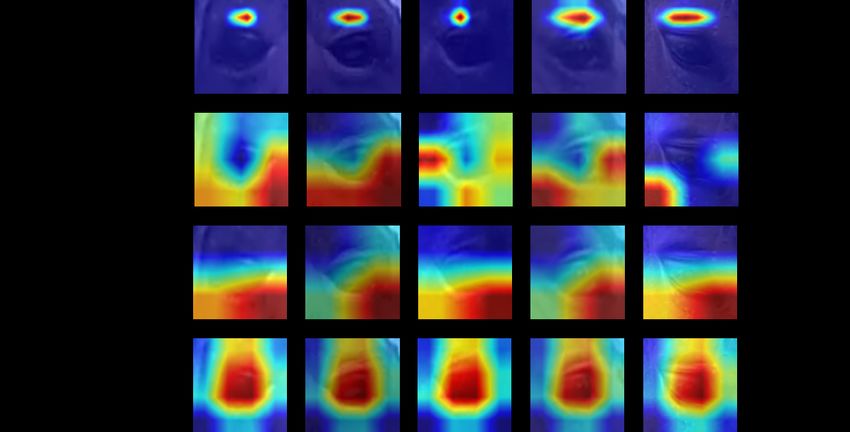
4.2 and Figure 4.3.
As is mentioned above, the expected region of interest should be the innerCHAPTER 4. RESULTS 23 Figure 4.2: Heat map of the models for AU101 on original frames and face regions. Images in the same columns are from the same frames. brow. However, none of these models can always focus on this region. AlexNet reaches the best accuracy among these models because it can always focus on the region above the eye, which is considered to be strongly correlated with AU101. The result of AlexNet on the eye region is competitive with the best result we get above, but it is much more reasonable. Compared to AlexNet, the other three only focus on regions with weak correlations to AU101. VGG19 seems to find good regions, but actually, it mainly focuses on eyeballs, which is not related to AU101. A possible reason why ResNet and VGG have worse performance than AlexNet is that the dimension of the feature maps is too high. In the original DRML model, the highest dimension is only 32. Perhaps AU features are actually in a lower dimension. Also, the amount of our labeled data may not be enough for the training of deep networks, such as ResNet and VGG. 4.1.2 Binary Classification for AD1, AU25, and AD19 Based on the results for AU101, we decided to choose AlexNet as the binary classifier in our cascade framework. We then applied our framework for the
24 CHAPTER 4. RESULTS
Table 4.2: Accuracies and F1 Scores of Binary Classifications of AU101 in
Eye Regions
Validation Test
Model
Accuracy F1 Score Accuracy F1 Score
AlexNet(eye) 64.6 65.0 66.7 67.6
DRML_replace(eye) 58.4 54.6 56.6 54.9
ResNet34(eye) 56.3 54.4 55.6 54.4
VGG19(eye) 54.9 53.0 54.2 55.4
Figure 4.3: Heat map of the models for AU101 on eye region. The order of
rows are the same as Table 4.2. Images in the same columns are from the same
frames.
other three easy classes. The results are shown in Table 4.3 and Figure 4.4.
AD1 Eye White Increase The main feature of AD1 should be the eye white
on the eyeball. In our experiment, our framework usually can find in-
creased eye white. But sometimes it turns to focus on the corners of the
eyes. Since sometimes AD1 is caused by the wider opened eyes, the
angle of the corners of eyes also correlated with AD1. Therefore, the
results for AD1 are acceptable.
AU25 Lips Part AU25 and the following AD19 are in the mouth region. Since
the mouth is very close to the nostril on horse faces, we detect them to-
gether as the lower face region. We can see that in most cases, the model
could focus on the lips, but sometimes it pays attention to the nostrils,CHAPTER 4. RESULTS 25
Table 4.3: Accuracies and F1 Scores of AlexNet for Binary Classifications of
AD1 (Eye White Increase), AU25 (Lips Part), and AD19 (Tongue Show)
Validation Test
Action Units
Accuracy F1 Score Accuracy F1 Score
AD1 (eye) 70.2 70.4 72.0 73.4
AU25 (lower face) 67.0 63.1 70.9 69.1
AD19 (lower face) 67.9 68.1 65.9 65.9
Figure 4.4: Heat maps of AlexNet for AD1 (Eye White Increase), AU25 (Lips
Part), and AD19 (Tongue Show)
which are not strongly correlated with lips.
AD19 Tongue Show There are roughly two cases of AD19. One is that the
mouth opens obviously, and the tongue sticks out of the mouth. In this
case, our framework can focus on the tongue. The other case is that the
tongue is only slightly exposed. In this case, our model fails to focus
on the tongue but tends to pay attention to the corners of the mouth.
Similar to AD1, the shapes of the corners of mouth are also correlated
with AD19, so these results are acceptable.
4.2 Binary Classification for Five Other AUs
The above experiments have indicated that our framework is effective for the
four relatively easy classes. In this section, we extended the model to five other
classes: AD38 (nostril dilator), AUH13 (nostril lift), AU145 (blink), AU47
(half blink), and AU5 (upper lid raiser). The results are shown in Table 4.4
and Figure 4.5.26 CHAPTER 4. RESULTS
Table 4.4: Accuracies and F1 Scores of AlexNet for Binary Classifications of
AD38 (Nostril Dilator), AUH13 (Nostril Lift), AU145 (Blink), AU47 (Half
Blink), and AU5 (Upper Lid Raiser)
Validation Test
Action Units
Accuracy F1 Score Accuracy F1 Score
AD38 (lower face) 70.0 67.4 72.0 68.4
AUH13 (lower face) 68.1 71.9 66.7 70.9
AU145 (eye) 67.9 70.5 66.6 69.7
AU47 (eye) 56.6 55.4 54.6 56.5
AU5 (eye) 72.7 73.9 72.8 71.2
Lower Face Region AD38 (nostril dilator) and AUH13 (nostril lift) are both
founded in the lower face region. We employed the same detector as
AU25 and AD19 here. We can see that our model could pay attention to
the nostrils in most cases and the accuracies and F1 scores are accept-
able.
Eye Region For AU145 (blink), theoretically, we cannot detect it from still
images because the main differences between AU143 (eye enclosure)
and AU145 are the duration of the eye closed. However, we get a good
result for AU145 here because in the original dataset, we only have 61
labeled clips for AU143, which is not enough for training, and we did not
include them in our experiment dataset. The bias of our dataset causes
this "good" result. For AU47 (half blink), our framework currently does
not for this class. The reason for this result may be that the differences
between AU47 and no action are too small, and AU47 is sometimes con-
fused with AU145. For AU5 (upper lid raiser), our model can correctly
focus on the eyelid regions.
4.3 Learning Correlations among AUs
In the above experiments, we train the models separately for binary classifi-
cations to learn the features for each AU. Actually, there exist some poten-
tial correlations among different AUs that could be leveraged. For example,
some AUs usually appear together, such as AU25 (lips part) and AD19 (tongue
show), especially when the tongue is extended out of the mouth. Also, in re-
lated works for human facial action unit recognition, it has been shown that
learning the correlations among AUs could contribute to the performance ofCHAPTER 4. RESULTS 27
Figure 4.5: Heat maps of AlexNet for AD38 (Nostril Dilator), AUH13 (Nostril
Lift), AU145 (Blink), AU47 (Half Blink), and AU5 (Upper Lid Raiser)
models. For example, in the DRML paper, the author mentioned that they
employed multi-label learning to learn the correlations among AUs. There-
fore, we tried to synthesize these binary classifiers together to learn such cor-
relations. We concatenated the outputs of the avgpool layers of each binary
classifier and trained a multi-layer perceptron (MLP) via multi-label learning
(Figure 4.6). We compared the test result of the synthesized classifier with
the result of testing each binary classifier separately. We also carried out ex-
periments with the DRML model and trained it in two ways. One is directly
training it on all classes via multi-label learning and testing it on the whole
test set, and the other is training and testing it separately on each class.
We carried out these experiments for the four relatively easy classes. Since
the distribution of examples for the four classes is quite uneven and examples of
AU101 are roughly five times more than the other three, it will cause the train-
ing to get stuck in a local minimum where the model always predicts AU101
with probability one and keep the probability of others as zero. To balance
the training set, we randomly copied the examples of the other three classes
to make the number of examples in each class the same as AU101. Consider-
ing that there can be some states where all of the four AUs do not appear, we
also added fully negative examples to make positive examples for each class as28 CHAPTER 4. RESULTS
Figure 4.6: Synthesized framework for learning correlations among AUs
(Only MLP was trained due to the limited computational resources.)
one-fifth of the training set. Moreover, we balanced the validation set and test
set by randomly deleting positive examples and adding fully negative exam-
ples to make positive examples for each class as one-fifth of each set. F1 score
is employed here for the evaluation of the detection task. In this experiment,
the F1 score of the random case is 28.6 percent. (In the random case, for each
AU, the precision is 20 percent, and the recall is 50 percent.)
Note that we used the same test set to evaluate each model, and failed cases
of the region detectors are also included in the results. If a region detector fails,
all related AUs will be predicted as false. For the synthesized model, we only
forwarded the images where both regions can be detected. If only one region
is detected, this region will only be forwarded to related binary classifiers and
tested separately. The results of the final classifications are shown in Table
4.5.
Table 4.5: F1 Scores of Synthesized Classifiers and Separate Classifiers for
the Four Relatively Easy Classes
Architecture Mean AD1 AD19 AU101 AU25
DRML (multi-label) 39.6 38.8 34.4 34.0 51.4
DRML (separate) 36.2 45.8 27.7 33.2 38.3
AlexNet (regions, synthesized) 44.6 45.7 40.0 49.4 43.1
AlexNet (regions, separate) 45.0 45.6 41.1 48.2 45.2
We can see that the DRML model trained via multi-label learning has a
better performance than when trained separately, which shows that multi-label
learning can help the DRML model learn the correlations among differentCHAPTER 4. RESULTS 29 AUs. However, for our framework, the synthesized classifier does not out- perform the separate classifiers. A possible reason is that only training the final MLP is not effective enough to learn the correlations, as in the DRML model, both the convolutional layers and fully connected layers are trained via multi-label learning. Finally, our framework outperforms the DRML model for the detection of these four relatively easy classes. Note that although in the previous experiments for AU101, the DRML model trained on raw frames had a better performance than our framework, our framework outperforms the DRML model for AU101 in this experiment. As we have discussed above, the DRML model tends to learn background information. Compared to the experiments in Section 4.1 where the positive and negative examples are bal- anced, the proportion of negative samples for each AU in this experiment is higher. In this way, the correlations between the backgrounds and each AU became weaker so that our framework works better than the DRML model in this experiment.
Chapter 5
Discussion
In this chapter, we will briefly summarize and discuss some key points of our
project and future works that can possibly improve our project.
Making the models focus on correct regions is very important for horse
facial action unit detection. Because our dataset is a small dataset and the
AUs are not evenly distributed in the dataset, there are some artifacts such as
the correlation between the background and the AUs. Therefore, at the begin-
ning of the experiments for AU101, the DRML models for raw frames reached
the highest accuracy. However, when the proportion of the negative examples
for each AU became higher in the experiments in Section 4.3 compared to the
experiments in Section 4.1, such an unreasonable correlation became weaker.
Finally, our framework forcing the classifiers to focus on correct regions out-
performs the DRML models, which shows the importance of the attention of
models to correct regions.
The accuracy of our framework still needs to be improved for practical
applications. To evaluate whether our model is adequate for horse facial ac-
tion unit detection, we should compare the experiment results to a baseline.
Since there is no previous work for this task, it will be good to use a human
baseline, which indicates how difficult it is for humans to recognize horse fa-
cial action units. As we do not have such a baseline yet, we choose an alter-
native way to evaluate our model by comparing the results of our experiments
to human facial action unit recognition. For example, the mean F1 score of
the DRML model on the BP4D dataset [59] (a human facial action unit detec-
tion dataset) for 12 AUs is 48.3 percents, which is much higher than ours for
horses. Therefore, the accuracy of our model is still needed to be improved for
30You can also read

















































