DEVELOPMENTAL DIFFERENCES IN PROBABILISTIC REVERSAL LEARNING: A COMPUTATIONAL MODELING APPROACH - JUSER
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
ORIGINAL RESEARCH
published: 18 January 2021
doi: 10.3389/fnins.2020.536596
Developmental Differences in
Probabilistic Reversal Learning: A
Computational Modeling Approach
Eileen Oberwelland Weiss 1,2,3,4* , Jana A. Kruppa 1,2,3,4 , Gereon R. Fink 2,5 ,
Beate Herpertz-Dahlmann 6 , Kerstin Konrad 2,3,4 and Martin Schulte-Rüther 1,2,3,4,7
1
Translational Brain Research in Psychiatry and Neurology, Department of Child and Adolescent Psychiatry,
Psychosomatics, and Psychotherapy, University Hospital Aachen, Aachen, Germany, 2 Cognitive Neuroscience, Institute
of Neuroscience and Medicine (INM-3), Jülich Research Centre, Jülich, Germany, 3 Institute of Neuroscience and Medicine
(INM-11), Jülich Research Centre, Jülich, Germany, 4 Child Neuropsychology Section, Department of Child and Adolescent
Psychiatry, Psychosomatics, and Psychotherapy, University Hospital Aachen, Aachen, Germany, 5 Department of Neurology,
University Hospital Cologne, Cologne, Germany, 6 Department of Child and Adolescent Psychiatry, Psychosomatics,
and Psychotherapy, University Hospital Aachen, Aachen, Germany, 7 Department of Child and Adolescent Psychiatry
and Psychotherapy, University Medical Center Göttingen, Göttingen, Germany
Cognitive flexibility helps us to navigate through our ever-changing environment and has
often been examined by reversal learning paradigms. Performance in reversal learning
can be modeled using computational modeling which allows for the specification of
biologically plausible models to infer psychological mechanisms. Although such models
are increasingly used in cognitive neuroscience, developmental approaches are still
Edited by:
scarce. Additionally, though most reversal learning paradigms have a comparable design
Andrew S. Kayser,
University of California, regarding timing and feedback contingencies, the type of feedback differs substantially
San Francisco, United States between studies. The present study used hierarchical Gaussian filter modeling to
Reviewed by: investigate cognitive flexibility in reversal learning in children and adolescents and the
James R. Schmidt,
Université de Bourgogne, France effect of various feedback types. The results demonstrate that children make more
Henry W. Chase, overall errors and regressive errors (when a previously learned response rule is chosen
University of Pittsburgh, United States
instead of the new correct response after the initial shift to the new correct target),
*Correspondence:
but less perseverative errors (when a previously learned response set continues to be
Eileen Oberwelland Weiss
e.weiss@fz-juelich.de used despite a reversal) adolescents. Analyses of the extracted model parameters of
the winning model revealed that children seem to use new and conflicting information
Specialty section:
This article was submitted to
less readily than adolescents to update their stimulus-reward associations. Furthermore,
Decision Neuroscience, more subclinical rigidity in everyday life (parent-ratings) is related to less explorative
a section of the journal choice behavior during the probabilistic reversal learning task. Taken together, this study
Frontiers in Neuroscience
provides first-time data on the development of the underlying processes of cognitive
Received: 27 February 2020
Accepted: 15 December 2020 flexibility using computational modeling.
Published: 18 January 2021
Keywords: cognitive flexibility, executive functioning, development, reinforcement learning, feedback processing
Citation:
Weiss EO, Kruppa JA, Fink GR,
Herpertz-Dahlmann B, Konrad K and
Schulte-Rüther M (2021)
INTRODUCTION
Developmental Differences
in Probabilistic Reversal Learning:
In an ever-changing environment, it is essential to shift strategies and adapt response patterns
A Computational Modeling Approach. based on received feedback. Probabilistic reversal learning tasks have been effectively used to assess
Front. Neurosci. 14:536596. cognitive flexibility, since they require participants to learn rules in an uncertain environment while
doi: 10.3389/fnins.2020.536596 remaining flexible in response to changing rules, a capacity particularly relevant to socio-emotional
Frontiers in Neuroscience | www.frontiersin.org 1 January 2021 | Volume 14 | Article 536596
Weiss et al. Developmental Differences in Reversal Learning
behavior (Cools et al., 2002; Remijnse et al., 2005; Ghahremani they provide more ecological validity with respect to unstable
et al., 2010; Nashiro et al., 2012; Hauser et al., 2015b; Izquierdo learning environments. Furthermore, due the diverse nature
et al., 2016). In a probabilistic reversal learning task, participants of the employed tasks across developmental ages, conclusions
learn to identify the target amongst various simultaneously with respect to developmental effects remain speculative. Hence,
presented stimuli based on received feedback. After participants directly comparing children and adolescents using a probabilistic
have successfully learned to identify the target, a reversal reversal learning task is essential to bring about a clearer
will occur, and the previously non-rewarded stimulus will understanding of the development of cognitive flexibility.
become the new target. Importantly, the stimulus-feedback Second, probabilistic reversal learning tasks inherently bring
contingencies are not fixed and deterministic, but probabilistic, about relatively high numbers of errors. Therefore, probabilistic
i.e., a stimulus receives a certain rewarding feedback not with reversal learning tasks need a more nuanced measurement
each presentation or choice, but only with a certain probability. of how participants integrate information throughout the
In addition, reversal learning has been found to be impaired task than simple observable error rates. Computational
in various neurological and psychiatric conditions including models of behavior specify parameters that are independent
obsessive compulsive disorder (OCD; Verfaillie et al., 2016; of task structure (as in the case of probabilistic reversal
Hauser et al., 2017; Tezcan et al., 2017), Huntington’s Disease learning task the trial-and-error structure typically results
(Nickchen et al., 2016), schizophrenia (Culbreth et al., 2016; in high number of errors), and are therefore better suited
Reddy et al., 2016), Parkinson’s disease (Buelow et al., 2015), to approximate the underlying mechanisms governing the
Attention-Deficit/Hyperactivity disorder (ADHD; Hauser et al., observed behavior (i.e., error patterns). Computational modeling
2015a), and autism spectrum disorder (ASD; Lionello-DeNolf could bridge the gap between observable behavior and internal
et al., 2010; D’Cruz et al., 2013; Costescu et al., 2014; D’Cruz mechanisms by using biologically plausible models to infer
et al., 2016). Despite these numerous studies on cognitive the psychological mechanisms underlying typical and deficient
flexibility, it remains difficult to draw exact conclusions about learning processes (e.g., Weeda et al., 2014; Palminteri et al.,
the development of the underlying learning processes mainly due 2016; Schuch and Konrad, 2017).
to three crucial factors: (1) In the existing studies participants A relatively simple approach is to use reinforcement learning
varied in age from young childhood to adulthood with only models which assume that future choices are optimized via
one study systematically comparing learning processes at various maximization of favorable outcomes being acquired using a fixed
ages during development (Crawley et al., 2019), although it learning rate and reward prediction errors (Rescorla and Wagner,
is known that cognitive flexibility changes over the course of 1972). However, such simplistic models do not consider learning
development (e.g., Crone and van der Molen, 2004; Yurgelun- under uncertainty. During probabilistic reversal learning though,
Todd, 2007; Van Der Schaaf et al., 2011; Ionescu, 2012; Luking individuals have to learn in a highly unstable environment,
et al., 2014). (2) Most current studies made their conclusions implicating that the learning rate adjusts according to its
based on error scores as an observable index of reversal estimates of environmental volatility. More recently, hierarchical
learning. However, these do not provide nuanced information Gaussian filter models (HGF), which are hierarchical Bayesian
needed to infer how the underlying mechanisms of cognitive learning models, have been used to model individual learning
flexibility (as measured by reversal learning) are implemented. under multiple forms of uncertainty (Mathys et al., 2011), since
(3) The feedback used in the existing studies differed from they can dynamically adjust their learning rate according to
winning pieces of candy to points and money with not a their estimates of environmental volatility (i.e., the probability
single study comparing the effect of these different types of contingencies may change at any point), its uncertainty about
feedback on reversal learning. Yet, we know that behavior the current state, and/or any perceptual uncertainty (Jiang
heavily depends on the received feedback and that feedback et al., 2014). Thus, they also provide more temporally rich
processing also changes during the course of development information about the dynamics of learning by considering trial-
(e.g., Eppinger and Kray, 2009; van den Bos et al., 2012; Van by-trial information instead of averaged error rates and reaction
Duijvenvoorde et al., 2013). We will shortly outline these three times. For instance, Hauser et al. (2014) could demonstrate
aspects before proposing how to overcome these limitations in that adolescents with ADHD performed marginally worse than
the current study. their typically developing (TD) peers in standard measures of
First, existing developmental studies on cognitive flexibility, behavior (i.e., error rates, RTs) while computational modeling
including behavioral and neuroscientific studies, typically only revealed that although both groups had similar learning rates,
included either children or adolescents, but by comparing the ADHD group had more “explorative” tendencies in their
between studies developmental differences between age-groups choice-behavior resulting in less efficient task performance.
can be found. That is, younger children usually make many errors In sum, computational models might thus provide the more
and show preservative behavior (Landry and Al-Taie, 2016), while nuanced measurement that is needed for probabilistic reversal
adolescents often show more riskiness resulting in poor decisions learning tasks to understand the underlying mechanisms and
(Van Der Schaaf et al., 2011; Blakemore and Robbins, 2012; its development.
Hauser et al., 2015b), possibly due to a hypersensitive system Third, even though most (probabilistic) reversal learning tasks
for processing rewards (Somerville et al., 2010). However, these have a comparable design with respect to timing and feedback
studies did not use probabilistic reversal learning tasks, which contingencies, the type of feedback differs substantially between,
may better capture the essence of cognitive flexibility because but not within studies (Cools et al., 2002; Remijnse et al., 2005;
Frontiers in Neuroscience | www.frontiersin.org 2 January 2021 | Volume 14 | Article 536596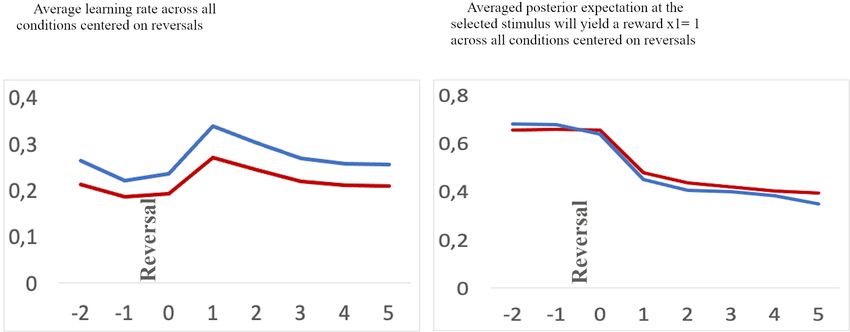
Weiss et al. Developmental Differences in Reversal Learning
Ghahremani et al., 2010; Nashiro et al., 2012; D’Cruz et al., 2013; the study. Participation was compensated by money irrespective
Hauser et al., 2014; Buelow et al., 2015). Since previous studies of task performance. All participants were seated in a quiet lab.
on feedback processing have revealed different effects, drawing
an unambiguous conclusion here is yet impossible. While one
Probabilistic Reversal Learning Task
study demonstrated that children show better results in a go/no-
We designed a probabilistic reversal learning task in which
go task with monetary compared to social reward (Kohls et al.,
participants had to learn to identify the target amongst two
2009), others have not found this effect, but investigated children
stimuli presented simultaneously on the screen (see Figure 1)
and adolescents (Demurie et al., 2011). More homogenously,
based on feedback.
previous studies in clinical samples (i.e., participants with
Participants received 75% contingent feedback (i.e., rewarding
ASD and ADHD) demonstrated that non-social reward (e.g.,
feedback upon correct choice and non-rewarding feedback
arrows, money) appears to be more effective than social reward
upon incorrect choice) and 25% non-contingent feedback (i.e.,
(Demurie et al., 2011; Stavropoulos and Carver, 2014). Hence,
non-rewarding feedback upon correct choice and rewarding
directly examining the effect of different types of feedback in
feedback upon incorrect choice). After participants reached a
children and adolescents may bring a clearer understanding
learning criterion, the other stimulus, which was previously
of the development of feedback processing in the domain of
not rewarded, became the new rewarded target without giving
cognitive flexibility.
notice to the participant (i.e., reversal). The learning criterion
The main aim of this study was to investigate developmental
was reached when participants had completed at least six
differences in learning processes underlying cognitive flexibility
to ten trials (randomly assigned during each reversal block)
and the effect of various types of feedback using a probabilistic
and had identified the target correctly in three consecutive
reversal learning task in children and adolescents. The secondary
trials. Participants were familiarized with the task and stimuli
aim was to explore possible relationships with subclinical
before testing. They were informed that after a while a
measures of ASD symptomatology, with a specific interest in
reversal of targets could occur, and that feedback was given
restrictive and repetitive behavior, since it has been proposed
probabilistically but they were given no explicit information
that impairments in cognitive flexibility may contribute to this
about the learning criterion or the ratio of contingent and
domain (South et al., 2005; D’Cruz et al., 2013). We therefore (1)
non-contingent feedback. During the practice session, feedback
tested a sample of children and adolescents in order to compare
was given exactly as during the experiment but without
both age groups; (2) used various kinds of feedback including
any reversal.
social (i.e., an actor posing thumbs up and smiling versus an actor
All participants were seated approximately 30 cm in front of
gazing straight with a neutral expression), individual (i.e., favorite
the computer and presented with identical stimuli (see Figure 1).
hobby of each participant versus pixelated video of the hobby),
The stimuli were of identical size (approximately 9.5 cm × 9.5 cm
and control (i.e., a check mark versus a cross) feedback within
and 17◦ visual angle) and were presented simultaneously to the
participants performing a probabilistic reversal learning task;
left and right side of a fixation cross on the screen. The position
and (3) used reinforcement learning and HGF models to infer
of the targets switched randomly with replacement, thus it was
the psychological mechanisms underlying the learning processes
possible that the target appeared on the same position multiple
and potential individual differences. Finally, we also included
times in row. All participants completed three runs of the
measures of subclinical ASD symptomatology.
probabilistic reversal learning task with varying feedback per run;
i.e., social, individual, and control feedback, in a counterbalanced
order. The feedback videos were presented visually for 2000 ms.
Five different videos in each feedback condition were used. Each
MATERIALS AND METHODS
run included 12 reversals or a maximum of 240 trials. For a
detailed overview of the timing of one trial see Figure 1. If
Participants participants did not react within 1500 ms, the fixation cross
In total, 28 TD children (all male, 8–12 years of age, mean
turned red and subsequently the next trial started. All missed
age = 10.33 years) and 25 TD adolescents (all male, 13 to 17 years
of age, mean age = 15.57 years) were included in the final analyses.
An additional two children participated in the study, but were not
included in the analyses because they were not able to complete
all experimental runs due to fatigue/non-compliance.
All participants had no indication of developmental delay or
other psychiatric disorders as assessed by a structured screening
interview on the phone and the Child Behavior Checklist (CBCL,
Achenbach, 1991; all T < 65). Only participants with sufficient
cognitive abilities were included [IQ > 80, short version of the
Wechsler Intelligence Scale for children or Grundintelligenztest FIGURE 1 | Illustration of two target stinmuli (boxes) and timing. Participants
were presented with the stimuli for 1500 ms in which they had to give their
Skala (CFT-20R; Weiß, 2006)]. The study was approved by the
response via a key press. Then the reward video (illustrated here by the green
ethics committee of the university. All participants and/or their check mark) was presented for 2000 ms. Subsequently, the next trial began.
caregivers gave written informed consent/assent to participate in
Frontiers in Neuroscience | www.frontiersin.org 3 January 2021 | Volume 14 | Article 536596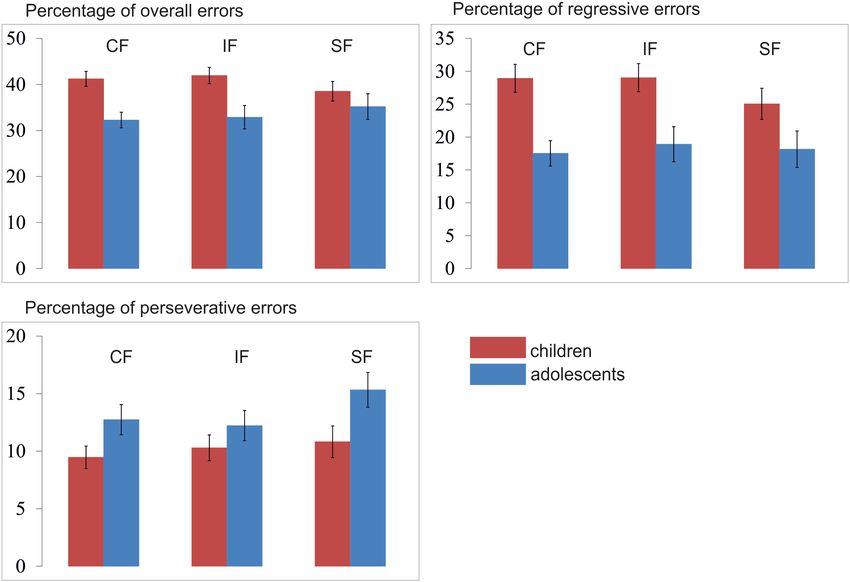
Weiss et al. Developmental Differences in Reversal Learning
trials were excluded from final analyses. The maximum numbers Control Feedback (CF) Video
of total misses per condition did not exceed 17. The rewarding feedback videos depicted a green tick mark (see
Figure 2E) and the non-rewarding feedback (see Figure 2F)
Social Feedback (SF) Video videos depicted a blue cross, both appearing on colored
Videos are part of a larger pool that has been designed fractal images. Five different backgrounds were selected so that
for previous studies on social reward (Kohls et al., 2013; the same number of different videos was presented for all
Chevallier et al., 2016). Five individuals were used, both for the feedback conditions.
rewarding and non-rewarding feedback. The rewarding feedback The software Presentation 9 (Neurobehavioral Systems,
videos depicted individuals looking straight at the participants, Albany, CA, United States1 ) was used for stimulus presentation
smiling, and giving thumbs up (see Figure 2A) whereas the and response collection. After task completion all participants
non-rewarding feedback videos depicted the individuals gazing rated each video (in total 30 videos) on a 10-point Likert scale
straight at the participant with a neutral facial expression and no ranging from 0 (non-rewarding) to 10 (very rewarding).
hand movement (see Figure 2B).
Questionnaires
Individualized Feedback (IF) Video The parent of each participant filled out the Social Responsiveness
Five video clips depicting a favorite activity of daily living of Questionnaire (SRS, Constantino et al., 2003). This questionnaire
the participant were created (e.g., computer game, movie, series, is designed to assess the severity of autism spectrum symptoms
sports club etc.; see Figure 2C) and used as the rewarding from subclinical characteristics to highly impaired social skills.
feedback videos. For the non-rewarding feedback, the rewarding We were specifically interested in the subscale “restrictive
feedback videos were manipulated so that they were completely interests and repetitive behavior,” since it reflects rigid behavior
unrecognizable to the participant (see Figure 2D), while keeping and stereotypes typically observable in children with ASD, but
basic visual stimulation identical. We used Adobe Premiere Pro also subclinical variance in TD children.
CS5.5 to add three effects to each video in order to make it
unrecognizable: (1) Gaussian Blur (165), (2) Mosaic (horizontal Analyses
29 and vertical 25), and (3) Sharpen (764). All behavioral data were analyzed using MATLAB 8.1 and IBM
SPSS Statistics 21. First, Mann-Whitney tests were computed
to compare the parameter estimates of the model. Second,
General Linear Model (GLM; univariate and repeated-measures)
analyses were computed in order to assess main effects
and interactions of various error rates (within-group factors:
Social/Individualized/Control Feedback; between-group factor:
age-group). Post hoc t-tests were performed to determine
differences between conditions. Additional ANOVAs with a
variable specifying the order of each feedback (i.e., social feedback
as first, second or third run, individual feedback as first, second
or third run and control feedback as first, second or third run) as
a factor were computed to check for order effects.
We made the data and code for the model and descriptive
analyses publicly available: Open Science Foundation2 .
Computational Models
We then computed a simplistic anti-correlated Rescorla-Wagner
(RW) model, which has also been used to infer learning
in probabilistic reversal learning tasks (Gläscher et al., 2009;
Hauser et al., 2014) and two versions of a hierarchical Gaussian
filter (HGF) model, which specifically considers learning in an
uncertain environment as in the case of a probabilistic reversal
learning task (Hauser et al., 2014). We compared all three
models (see below) using Bayesian model comparison to quantify
which of these models best explained the observable behavior (a)
separately within both age groups and (b) across age groups.
Anti-correlated rescorla-wagner (RW) learning model
FIGURE 2 | Examples of feedback videos. (A) Rewarding social feedback The RW model has a fixed learning rate across the whole
video, (B) non-rewarding social feedback video, (C) rewarding individualized
feedback video, (D) non-rewarding individualized feedback video, (E)
experiment. The reward prediction error (RPE) δ at each trial
rewarding control feedback video, and (F) non-rewarding control feedback 1
http://www.neurobs.Com
video. 2
https://osf.io/6hbw4
Frontiers in Neuroscience | www.frontiersin.org 4 January 2021 | Volume 14 | Article 536596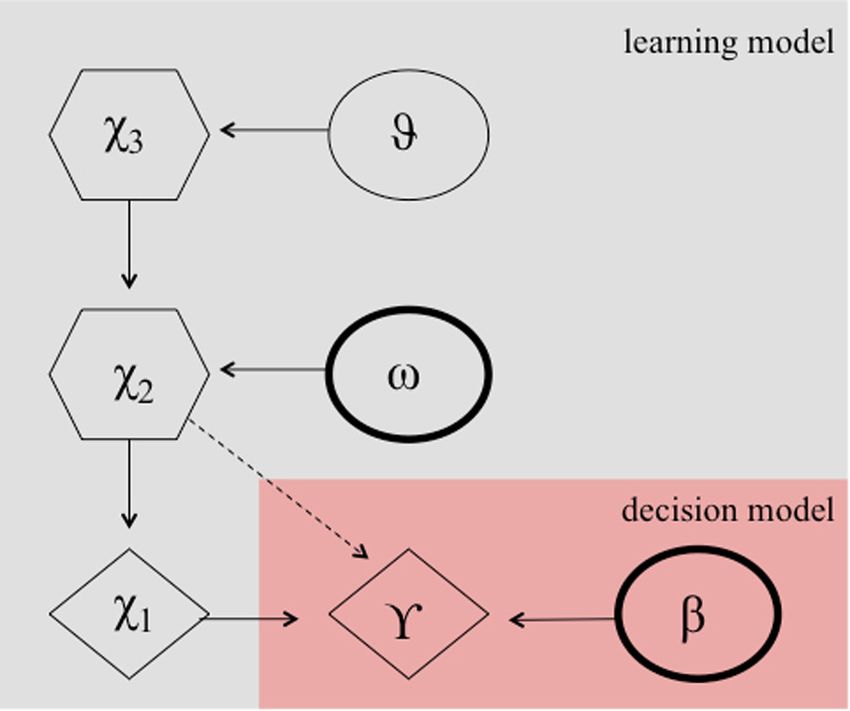
Weiss et al. Developmental Differences in Reversal Learning
(t) was computed as the difference between the anticipated random walks. That is, a transition or updating of a state in
(V(t) chosen ) and the received (R(t) ) outcome: time is determined probabilistically, with the walk’s step size
given by certain parameters and the next highest level’s state
(t)
δ(t) = R(t) − Vchosen within the hierarchy (Mathys et al., 2011). State x1 denotes a
binary environmental state, indicating which stimulus is being
Previous studies have suggested that individuals also use rewarded. State x2 is associated with a kind of internal belief of a
the counterfactual information where always one choice is value representation (that a target is being rewarded upon choice)
correct, the other is incorrect, to update their stimulus-reward and is being transformed to the probability that x1 is rewarded by
association. Therefore, we applied the anti-correlated RW model, a logistic sigmoid transformation.
an extension of the standard RW model, where the values of both
options, chosen and unchosen (i.e., box 1 and box 2, see Figure 1) (t)
(t) (t) (t) x1 (t) (t)
were updated using the RPE δ: p x1 |x2 = s x2 (1 − s x2 )1−x1
(t+1) (t)
Vchosen = Vchosen + αδ(t) with s (x) := (1/(1 + e−x )). State x2 evolves over time and is
determined by a Gaussian random walk. The update of state x2
in time from time point t-1 to time point t is characterized by a
(t+1) (t) (t)
Vunchosen = Vunchosen − αδ(t) normal distribution, i.e., at each time point t. The value of x2 is
(t−1) t
normally distributed with mean x2 and variance ekx3 +ω
where α depicts the learning rate, which is constant
throughout the experiment. (t) (t−1) t
p(x2 ) ∼ N(x2 , ekx3 +ω )
Hierarchical gaussian filter (HGF) models Since the variance of this random walk can be taken as a
It can be argued that the numerous reversals in the paradigm measure of the volatility of x2 , the log-volatility kx3t + ω has
constitute an unstable environment, which requires the learning two components, one phasic and the other tonic: x3 is a state-
rate to adapt according to the individuals estimates of dependent (phasic) log-volatility, which (together with the free
the environmental volatility. Perseverative errors, resembling parameter ω, i.e., subject-specific volatility), determines the
cognitive inflexibility, might then result from either a smaller updating of x2 . κ is a scaling factor and was fixed to 1 as in Vossel
learning rate, which might be plausible due to a smaller degree et al. (2013) and Hauser et al. (2014). The state x3 is normally
of cognitive maturation in children, or a lower capacity to (t−1)
distributed with mean x3 and variance ϑ. ϑ is a free parameter
quickly adapt the learning rate to a changing environment or
and can be regarded as a subject- specific meta-volatility.
both. Accordingly, a hierarchical Gaussian filter (HGF) model
(Mathys et al., 2011, see Figure 3) has been shown to provide (t) (t−1)
p(x3 ) ∼ N(x3 , ϑ)
the best model fit for explaining behavior during a probabilistic
reversal learning task in adolescence (e.g., in comparison to a The variational inversion of the model yields subject-specific
simple RW model), using an identical task as in the current Gaussian belief trajectories about x2 and x3 , represented by
study (Hauser et al., 2014). Hence, we computed two HGF their means µ2, µ3 and variances (or, equivalently, precisions)
models, one according to Hauser et al. (2014) including the σ2, σ3 (π2, π3 ). This inversion reveals that the trial-by-trial
estimation of the model parameter theta ϑ, and one with the update equations highly resemble the update equations from RW
model parameter theta ϑ fixed. Our rational for this additional model:
(t) (t)
model was that the task structure was not designed with variance δ1 = R(t) − s(µ̂2 )
in volatility, because contingencies always switched after the
(t) (t−1)
association was learned. This in turn might preclude an unbiased where µ̂2 = µ2 is the trial-by-trial mean of the Gaussian
(t) (t)
subjects-specific estimate of theta ϑ. We chose ϑ to be fixed prior at the second level and R(t) := x1 . µ̂2 is updated by a
to −3.5066 (empirically derived from the mean estimate of the precision-weighted RPE
whole group of participants from the HGF model containing
(t+1) (t) (t) (t)
this parameter). In contrast to the more simplistic RW model, µ̂2 = µ2 = µ̂2 + σ2 δt1
the HGF models employ a flexible learning rate, which adapts (t)
to changes in the volatility of the environment and according to where σ2 is the trial-by-trial variance at level 2. It can be
the beliefs of the participant about the current value of an object. expressed by a ratio of precision estimates π̂
It thus fully complies with the Bayesian brain hypothesis, which (t)
assumes that the brain always learns in a Bayes-optimal fashion, (t) π̂1
σ2 = (t) (t)
given individually different priors (Dayan et al., 1995; Friston, π̂2 π̂1 + 1
2010). Note, the exact formulation, the model inversion, and
the complete update equations are described elsewhere (Mathys (t) 1
π̂2 := (t−1)
(t−1)
et al., 2011). In short, the HGF model is a generative Bayesian σ2 + eµ3 +ω
model consisting of a set of probabilistic assumptions governing
learning from sensory stimuli. The model describes a hierarchy (t) 1
π̂1 := (t−1) (t−1)
of three hidden states (x1 , x2 , x3 ) that evolve in time as Gaussian s(µ2 )(1 − s(µ2 )
Frontiers in Neuroscience | www.frontiersin.org 5 January 2021 | Volume 14 | Article 536596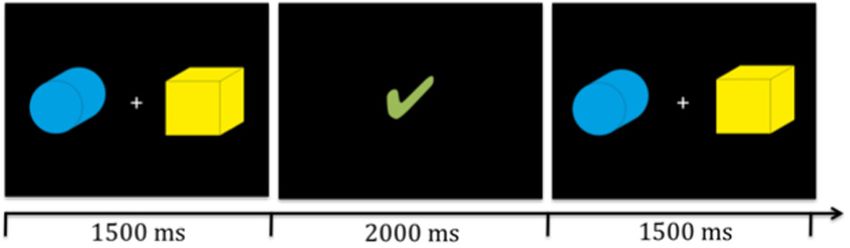
Weiss et al. Developmental Differences in Reversal Learning
governs to what extent new (conflicting) information is used
to update the estimation of the prediction strength. A smaller
ω would indicate that new information (i.e., received feedback)
is used less readily to update existing internal beliefs (i.e.,
beliefs about which stimulus is being rewarded). (c) The meta-
volatility parameter ϑ indicates how variable the state-dependent
volatility estimate (x3 ) is, and thus can be regarded as a
subjects’ tendency to believe volatility is changing over time. For
both HGF models, all parameters were estimated separately for
the three feedback conditions. Furthermore, we also extracted
individual “learning rates” (i.e., weighting of RPE updates) per
trial and computed the average learning rate per participant.
In both HGF models, RPE updating is governed by the trial-
by-trial variance at x2 and highly resembles the learning rate
α from Rescorla-Wagner models. Taken together, the model
parameters of interest and the learning rate indicate how well
participants learn and how efficiently they are able to integrate
the feedback information to their current beliefs, given a model-
FIGURE 3 | Hierarchical Gaussian filter model according to Hauser et al.
based approach.
(2014). Markovian states are denoted by X1 to X2 and ω, and β are the free We performed Bayesian model selection (BMS) for groups
parameters. These parameters determine the actual choice behavior (γ) across all participants and for each age group separately. To
probablisticly. further investigate learning and decision-making impairments,
we compared the parameter estimates of the model that
performed best across all subjects using Mann-Whitney tests.
For the update equations at level 3 and for the derivation of the
equations, please refer to Mathys et al., 2011. Behavioral Analyses of Error Patterns
Both HGF learning models were combined with a softmax We also performed a standard analysis of error types, to compare
decision model [commonly used for reversal learning and against earlier studies (D’Cruz et al., 2013). In addition to the
decision-making tasks (e.g., Niv et al., 2012; Diaconescu et al., percentage of overall errors, we further distinguished between
2014; Hauser et al., 2014, 2017; Boehme et al., 2016)], i.e., a two specific types of errors: (1) regressive errors are made
model describing how internal beliefs of value representations are when participants choose the previously reinforced target (now
translated into binary decisions (e.g., left or right button press). incorrect choice) after having already chosen the new and correct
target at least once, and (2) perseverative errors are made when
1
p (A) = participants continue to choose the previously reinforced target
1 + e−β(VA −VB ) (now incorrect choice) before they chose the new and correct
where p (A) denotes the probability of choosing object A and β target. Regressive errors thus indicate failure to retain a newly
is a free parameter. identified and correct pattern while perseverative errors indicate
Using this combination of learning and decision model, failure to quickly shift the response after a reversal.
the following free parameters can be estimated: (a) decision
parameter β (i.e., the free parameter of the softmax decision
function), (b) volatility parameter ω, and (c) meta-volatility RESULTS
parameter ϑ, (fixed to −3.5066 or estimated). (a) The decision
function parameter β determines to what extent the internal Model Comparison
beliefs of value representations are directly translated into Using Bayesian Model Selection (BMS) for groups (Stephan
behavior which favors the best option or how strong the choice et al., 2009; Rigoux et al., 2014), we found that the HGF model
is influenced by randomness. A smaller β would indicate more with meta-volatility parameter ϑ being fixed performed better
“decision noise” or randomness, but implicitly result in stronger compared to the HGF including an estimation of the meta-
behavioral tendencies to explore options which are currently non- volatility parameter ϑ and the anti-correlated RW model across
favored by the internal model. Thus, β can also be considered all subjects as well as for both age groups separately (i.e., children
an indication of the exploration-exploitation dimension of the and adolescents; Px = 0.95; Px is the exceedance probability), thus
participant’s behavior. A higher β would indicate a more frequent the probability that the HGF including a fixed meta-volatility
exploitation of the best option (Cohen Jonathan and Aston- parameter ϑ performs better than the other two models included
Jones, 2005; Cohen et al., 2007; Hauser et al., 2014), which we in the comparison is 95% (see Table 1).
hypothesize might be valid for individuals with less subclinical To further validate our model selection, we aimed to recover
rigid and repetitive behavior. (b) The subject-specific volatility the selected model in a simulated data set. We therefore simulated
parameter ω allows for individual differences in the updating data sets for children and adolescents using the estimated
of the internal beliefs of stimulus-reward associations and thus parameters from the wining model and applied the same model
Frontiers in Neuroscience | www.frontiersin.org 6 January 2021 | Volume 14 | Article 536596Weiss et al. Developmental Differences in Reversal Learning
TABLE 1 | Exceedence probability for the model comparison between the HGF for the choice of stimulus A. On the other hand, children had a
model with meta-volatility parameter ϑ being fixed, the HGF including an
smaller learning rate during reversals, along with a slower value
estimation of the meta-volatility parameter ϑ and the anti-correlated RW model.
representation update.
Exceedence Probability
HGF ϑ being fixed Across all 0.95
Percentage of Overall Error
versus conditions All error rates were normally distributed. A mixed 3 × 2 ANOVA
RW analysis with type of feedback (Social/Individualized/Control
HGF ϑ being fixed Across all 0.99 Feedback) as within-group factor and the between-group factor
versus conditions age-group (Children/Adolescents) revealed a significant feedback
HGF ϑ being estimated x age-group interaction [F(2,102) = 5.65; p = 0.006] and a
main effect for age-group [F(1,51) = 8.57; p = 0.005], see
Figure 6A. Post hoc independent-samples t-test revealed that
children (M = 40.42%; SD = 7.95) made significantly more errors
fitting and selection procedure as to the actual data set. These
than adolescents (M = 33.44%; SD = 9.4; t(51) = 2.93; p = 0.005).
additional analyses further confirmed that the HGF including
Additional post hoc independent-samples t-tests further revealed
a fixed theta was the best fitting model. For more detailed
that children made significantly more errors in the control
description and analyses see Supplementary Material.
(children: M = 41.22%; SD = 8.77; adolescents: M = 32.27%; SD
7.61; t(51) = 3.95; p < 0.001) and individual feedback condition
Model Parameter Comparison (children: M = 41.94%; SD = 9.38; adolescents: M = 32.87%; SD
For a complete overview of the model parameter comparison see 11.38; t(51) = 3.17; p = 0.003), but not in the social feedback
Table 2. Mann-Whitney tests comparing the model parameters condition (children: M = 38.12%; SD = 8.51; adolescents:
and average learning rate across participants and conditions M = 33.19%; SD 12.45; t(51) = 1.01; p = 0.319). There was no
revealed that TD children and adolescents showed no significant order effect, neither for the social [F(1,51) = 0.02; p = 0.977], or
overall difference in the decision parameter (β: children, 5.96 the individual [F(1,51) = 0.25; p = 0.778] or the control feedback
[4.18]; adolescents, 5.91 [4.01]; U = 344; z = −1.443; p > 0.05). [F(1,51) = 0.41; p = 0.669].
We also found no significant differences between age
groups for the overall subject-specific volatility estimate across Percentage of Regressive Errors
conditions (ω: children, 0.77 [0.81]; adolescents, 0.50 [0.79]; A regressive error is defined as an error whereby participants
U = 269; z = −1.443; p > 0.05). However, detailed inspection choose the previously reinforced response after having already
of group differences between specific conditions revealed that chosen the new and correct choice at least once. The regressive
the subject-specific volatility estimate ω differed between age- errors thus indicate how well someone retains the new
groups in the control feedback condition (ω: children, 1.01 [1.13]; and correct pattern after having identified the new target
adolescents, 0.34 [0.80]; U = 222; z = −2.281; p = 0.023), but at least once correctly. A mixed 3 × 2 ANOVA analysis
less pronounced for the other conditions (individual feedback with type of feedback (Social/Individualized/Control Feedback)
condition: children 0.83 [1.01] and adolescents 0.58 [0.87]; as a within-group factor and the between-group factor age-
U = 317; z = −0.588; p > 0.05 and social feedback condition: group (Children/Adolescents) revealed no significant interaction
children 0.47 [1.11] and adolescents 0.58 [0.89]; U = 347; [F(2,102) = 2.27; p = 0.114] nor a main effect for condition
z = −0.53; p > 0.05). [F(1,102) = 2.74; p = 0.074], but a significant main effect for
Children and adolescents did not differ in their average age-group (F1,51) = 10.84; p = 0.002) (see Figure 6B). Post hoc
learning rate across conditions (children, 0.21 [0.12]; adolescents, independent samples t-test revealed that children (M = 27.67%;
0.26 [0.12]; U = 220; z = −0.160; p > 0.05), but in the control SD = 10.99) made significantly more regressive errors than
feedback condition (children, 0.18 [0.16]; adolescents, 0.28 [0.12]; adolescents (M = 18.19%; SD = 9.82; t(51) = 3.29; p = 0.002).
U = 182; z = −2.36; p = 0.018), though not in the individual There was no order effect, neither for the social [F(1,51) = 0.07;
feedback (children, 0.21 [0.13]; adolescents, 0.26 [0.16]; U = 293; p = 0.932], or the individual [F(1,51) = 1.10; p = 0.341] or the
z = −0.585; p > 0.05) and social feedback condition (children, control feedback [F(1,51) = 0.70; p = 0.501].
0.24 [0.12]; adolescents, 0.25 [0.12]; U = 291; z = −0.417;
p > 0.05). Percentage of Perseverative Errors
To further illustrate the impact of differential model A perseverative error is defined as a trial in which participants
parameters on the dynamics of internal beliefs, we extracted chose the previously reinforced response despite ongoing
individual estimates of hierarchical states within the HGF model negative feedback before they chose the new and correct target.
on a trial-by-trial basis. We first extracted the averaged learning The perseverative errors thus indicate how fast someone shifts
rate and the current value representation across conditions the response after a reversal. A mixed 3 × 2 ANOVA analysis
aligned to reversal trials and two trials before and six trials with type of feedback (Social/Individualized/Control Feedback)
thereafter (Figures 4, 5B). We then averaged a sequential series as within-group factors and the between-group factor age-
of trials, aligned to reversal trials. The learning rate of adolescents group (Children/Adolescents) revealed no significant interaction
increased rapidly at the time of reversal and decreased quickly [F(2,102) = 1.51; p = 0.231], but a significant main effect for
thereafter, along with a quick decline in the value representation feedback condition [F(2,102) = 3.77; p = 0.030] and age-group
Frontiers in Neuroscience | www.frontiersin.org 7 January 2021 | Volume 14 | Article 536596Weiss et al. Developmental Differences in Reversal Learning
TABLE 2 | Model parameter and learning rate comparison using Mann-Whitney tests across participants and conditions.
Children Adolescents Significance
Decision parameter β – Across all conditions 5.96 [4.18] 5.91 [4.00] U = 344; z = −1.443
mean [SD] p > 0.05
Subject-specific volatility Across all conditions 0.77 [0.81] 0.50 [0.79] U = 269; z = −1.443
estimate ω- mean [SD] p = 0.149
Control feedback 1.01 [1.13] 0.34 [0.80] U = 222; z = −2.281
p = 0.023
Social feedback 0.47 [1.11] 0.58 [0.89] U = 347; z = −0.53
p > 0.05
Individualized Feedback 0.83 [1.01] 0.58 [0.87] U = 317; z = −0.588
p > 0.05
Learning rate Across all conditions 0.21 [0.12] 0.26 [0.12] U = 220; z = −0.160
- mean [SD] p > 0.05
Control feedback 0.18 [0.16] 0.28 [0.12] U = 182; z = −2.36
p > 0.05
Social feedback 0.24 [0.12] 0.25 [0.12] U = 291; z = −0.417
p = 0.018
Individualized Feedback 0.21 [0.13] 0.26 [0.16] U = 293.5; z = −0.585
p > 0.05
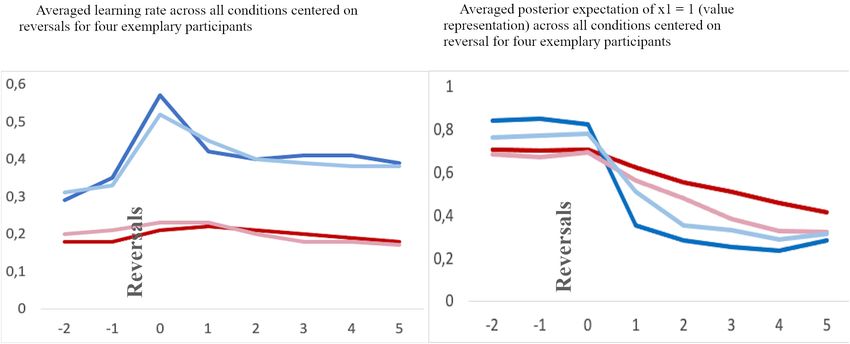
FIGURE 4 | (A) Average learning rate. (B) Value representation [1: stable internal belief that stimulus (A) is being rewarded, and 0: stable internal beliedf that stimulus
(B) is being rewarded] for a time frame aligned to reversals [two trials before a reversal (–2 and –1), and six trials after a reversal (0–5) across all conditions]. Blue:
adolescents, red: children. Note, the values at a specific trial (e.g. 0, the reversal trial) indicate the changes in values after feedback has been received.
[F(1,51) = 4.67; p = 0.035] were observed (see Figure 6C). First, using the empirically determined mean estimated parameters
post hoc independent-samples t-test revealed that adolescents from the model estimation step (see Supplementary Material for
(M = 13.43%; SD = 5.30) made significantly more perseverative details of the simulation). These recovered error rates revealed a
errors than children across all conditions (M = 10.20%; SD = 5.56; comparable pattern as the empirical error rates described above
t(51) = 2.16; p = 0.035). Second, post hoc paired-sample t-test (see section “Percentage of Regressive Errors” and “Percentage
revealed that across age groups significantly more errors were of Perseverative Errors ”). That is, adolescents made more
made during the social feedback (M = 12.82%; SD = 0.10) perseverative errors than children, and at the same time less
than during the control feedback condition (M = 10.91%; regressive errors than children.
SD = 0.01; t(51) = 2.56; p = 0.014) and the individual feedback
condition (M = 11.11%; SD = 0.06; t(51) = 2.14; p = 0.037),
but no significant difference between the control and individual Valence Rating of Feedback Videos
feedback conditions (t(51) = 0.32; p = 0.745). There was no order A mixed 3 × 2 × 2 ANOVA analysis with type of feedback
effect, neither for the social [F(1,51) = 0.15; p = 0.864], or the (Social/Individualized/Control Feedback) and valence
individual [F(1,51) = 1.50; p = 0.232] or the control feedback (Rewarding/Non-rewarding) as within-group factors and
[F(1,51) = 1.50; p = 0.232]. the between-group factor age-group (Children/Adolescents)
revealed a significant main effect for valence [F(1,51) = 256.92;
Error Rates in Simulated Models p < 0.001], but no significant three-way interaction
We further aimed to recover the empirical differences in error [F(1,44) = 0.445; p = 0.644], main effect for age-group
rates between children and adolescents in a simulated data set, [F(1,51) = 1.84; p = 0.182], or main effect of type of feedback
Frontiers in Neuroscience | www.frontiersin.org 8 January 2021 | Volume 14 | Article 536596Weiss et al. Developmental Differences in Reversal Learning
FIGURE 5 | Exemplary averaged learning rate (A) and valye representation (B) across all feedback conditions for two children (red lines) and two adolescents (blue
lines) aligned to reversal trials (“0”) and two trials before and 5 trials thereafter.
FIGURE 6 | Mean percentage of (A) overall errors, (B) regressive errors, and (C) perseverative errors per condition and age group. CF, control feedback; IF,
individualized feedback; SF, social feedback.
[F(1,51) = 0.500; p = 0.610]. As intended, participants rated model parameters and a clinical measure of “restrictive interests
the rewarding feedback videos (M = 6.99; SD = 1.39) as more and repetitive behavior” measured by a subscale of the Social
rewarding [t(51) = 16.05, p < 0.001] than the non-rewarding Responsiveness parent-questionnaire [SRS-RRB]. This subscale
feedback videos (M = 2.39; SD = 1.39). reflects rigid behavior and stereotypes typically observable in
children with ASD, but also subclinical variance in typically
Correlational Analyses developing (TD) children.
First, we computed correlational analyses between the (a)
extracted model parameters and the learning rate and (b) errors Model Parameters and Errors
in order to gain further insight into the relation between the The exploration-exploitation estimate β correlated with the
model parameters and measurable behavior (i.e., error rates) percentage total errors (r = −0.292; p = 0.034), but not
to ensure face validity of the parameter value interpretations. with perseverative errors (r = 0.114; p = 0.421) or regressive
Second, we computed correlational analyses between extracted errors (r = −0.094; p = 0.507). The subject-specific volatility
Frontiers in Neuroscience | www.frontiersin.org 9 January 2021 | Volume 14 | Article 536596Weiss et al. Developmental Differences in Reversal Learning
estimate ω did not correlate with the percentage of total mechanisms underlying cognitive flexibility (Jiang et al., 2014)
errors (r = −0.11; p = 0.424), regressive errors (r = −0.23; under multiple forms of uncertainty (e.g., perceptual uncertainty
p = 0.109), or perseverative errors (r = 0.227; p = 105). All and environmental volatility) (Mathys et al., 2011). The HGF
results remain significant when Bonferroni corrected. The overall approach can model how the brain flexibly integrates information
average learning rate correlated negatively with the percentage across different time scales to predict change by dynamically
of total errors (r = −0.289; p < 0.05), but not with regressive updating predictions based on integrating past information with
errors (r = −0.166; p > 0.05) or with perseverative errors recent observations (see for review: Jiang et al., 2014). In the
(r = 0.14; p > 0.05). specific case of probabilistic reversal learning, this implies that
the participants use the given feedback to improve future choices
Level of Social Responsiveness (SRS-2) via maximization of favorable outcomes.
The SRS Total score was marginally correlated with the parameter Second and with respect to the parameter ω, our results
β (r = 0.27; p = 0.059) and the SRS-RRB score was positively suggest that children had a bias toward a slower update of their
correlated with the parameter β (r = 0.32; p = 0.025), suggesting estimation of the prediction strength for a rewarding outcome
a link between the shape of the decision function translating than adolescents as reflected by a smaller individual volatility
value representation into behavior and inflexibility in everyday parameter in the control feedback condition. This is also related
behavior. The subject-specific volatility estimate ω did not to a smaller learning rate in the control feedback condition
correlate with the SRS-RRB (r = 0.01; p = 0.954). (see section “Model Parameter Comparison” and Figure 4A for
the learning rate specifically around a reversal). Thus, our data
suggest that children use new and conflicting information less
DISCUSSION readily and less immediately than adolescents to update their
internal beliefs of stimulus-reward associations, resulting in less
Cognitive flexibility is an essential skill that allows us to cope efficient learning in the context of an unstable environment (see
with the demands of a continuously changing environment and Figure 4), specifically when the feedback is a simple cross or
moreover is deficient in a broad range of neurodevelopmental check mark (control feedback). This conclusion is consistent with
and psychiatric disorders. We investigated the (1) developmental previous accounts suggesting a less efficient updating based on
differences from childhood to adolescents in probabilistic feedback (Eppinger and Kray, 2009; Hämmerer and Eppinger,
reversal learning as an index of cognitive flexibility (2) using a 2012; Van Duijvenvoorde et al., 2013, 2008). It is plausible that
computational modeling approach (3) comparing various types this mechanism also underlies the higher overall and the higher
of feedback. In addition to mere differences in error rates, the regressive error rate in children as compared to adolescents.
analysis of model parameters provides a more nuanced picture of Children, who update their internal beliefs of stimulus-reward
the psychological processes underlying performance differences association slower, are also likely to make more errors. Note
during development from childhood to adolescence. that on the other hand a “too fast” updating could also result
First, children made more overall errors than adolescents, in increased number of errors. Thus, it is rather necessary to
which is in line with previous studies demonstrating an have an optimal updating “speed.” This is particularly relevant
improvement of executive functioning from childhood to for regressive errors in later stages after a reversal, since with
adolescence (Blakemore and Choudhury, 2006), including slower learning rates children are slower in reaching a level of
decision-making (Crone et al., 2003; Kerr and Zelazo, 2004; internal beliefs where the correct option is clearly represented as
Overman, 2004; Van Duijvenvoorde et al., 2012), cognitive favorable (see Figures 4A,B). In other words, they seem to have
flexibility (Crone et al., 2004; Alvarez and Emory, 2006; Zelazo a less stable representation of the stimulus-reward association,
and Carlson, 2012), and (probabilistic) feedback learning (Van which in turn might result in more changes of response choice
Duijvenvoorde et al., 2008; Eppinger and Kray, 2009; Hämmerer and hence in less preservative but more regressive errors. The
and Eppinger, 2012; Van Duijvenvoorde et al., 2013). However, findings of (i) the negative correlation between overall average
the exact mechanisms underlying developmental differences learning rate and the number of total and regressive errors, but
in cognitive flexibility from childhood to adolescence to date (ii) no correlation with perseverative errors as well as (iii) the
remain poorly understood and are difficult to infer from negative correlation between the parameter ω and the number
error patterns alone. Hence, previous studies provided various of total and regressive errors, but (iv) positive correlation with
explanations for behavioral differences in cognitive flexibility perseverative errors further substantiates this conclusion. On the
during development, such as difficulties in distinguishing other hand, fast updating in adolescents after each reversal results
informative and non-informative feedback (see for a discussion: in relatively few overall errors as well as few regressive errors since
Kirkham and Diamond, 2003), differences in monitoring the correct option is clearly represented as favorable soon after a
(Davies et al., 2004; van Leijenhorst et al., 2006), inhibitory reversal with only a short period of “doubt” (see Figures 4, 5).
(Huizinga et al., 2006) or cognitive control mechanisms (Van Third, slight differences between conditions could be
Duijvenvoorde et al., 2008). Modeling approaches might thus observed. First, the difference between children and adolescents
help to understand how participants integrate information was most pronounced for both total number of errors and the
throughout the task by providing a more stringent mapping parameter ω during the control feedback condition. Second, with
between model parameters and assumed psychological processes. respect to overall errors we found less prominent differences
Specifically, the HGF modeling has been successfully used to infer between children and adolescents during the social feedback
Frontiers in Neuroscience | www.frontiersin.org 10 January 2021 | Volume 14 | Article 536596Weiss et al. Developmental Differences in Reversal Learning
conditions. Third, we also found more perseverative errors et al., 2004; van Leijenhorst et al., 2006), suggesting a top-
during social feedback compared to control and individualized down modulation of learning. Our results support the idea of
feedback across age-groups. On the one hand, it might be developmental differences in hierarchical top-down processing,
hypothesized that specifically in real life settings social feedback since we observed superiority of the HGF model in comparison
is typically more consistent and that contingencies usually do not to a simple bottom-up learning model in both age-groups, but
change as fast as during this laboratory setting, resulting in slower further development and “shaping” of the model parameters
updating of a value contingency. On the other hand, it might also with increasing age. The latter may be associated with cortical
be plausible that social feedback generates a stronger association maturation or accumulated experience (e.g., estimating the
resulting in more “difficulties” to reverse an association and learn environment as more volatile in adolescence than in childhood)
a new one. Presumably, additional motivational mechanisms that occurs from childhood to adolescence.
may come into play for social and individual feedback conditions Yet, in future investigations, neuroimaging methods such
whereas the control feedback condition might best reflect “pure” as functional magnetic resonance imaging (fMRI) should be
reversal learning to reveal general mechanisms. used to reveal differential developmental neural mechanisms
Lastly, we observed a relationship between external measures associated with respective model parameters. Previous studies
of everyday behavior and modeling parameters, suggesting that have attributed differences in probabilistic feedback learning
our findings may extend, at least to a certain degree, beyond the to regional and connectivity changes of the prefrontal cortex
specific paradigm in a laboratory setting. We found a correlation (Hämmerer and Eppinger, 2012; van den Bos et al., 2012) that
between the specific decision-making model parameter beta and undergoes prominent changes during adolescence (e.g., Paus,
a measure of rigidity in everyday life (i.e., SRS-RBB). Thus, 2005; Crone and Dahl, 2012; Konrad et al., 2013) and is associated
there could be a link between rigidity and a tendency to always with cognitive control, monitoring, and inhibitory mechanisms.
stick to the potentially best option as favored by an acquired However, it would be crucial to investigate to what extent the
internal model, i.e., exploit the inferred contingencies. This is Bayesian modeling approach may add to that knowledge by
in line with the interpretation of the parameter beta in terms of relating developmental changes in model parameters to specific
implicit exploration/exploitation behavior (Cohen Jonathan and functional brain changes. For example, Hauser et al. (2015b)
Aston-Jones, 2005; Cohen et al., 2007; Hauser et al., 2014) and demonstrated that adolescents and adults performed comparably
would be a maladaptive behavior in highly volatile environments. in a probabilistic reversal learning task. However, differences in
This relationship may provide one possible explanation of modeling parameters indicated that adolescents learned faster
how impairments in cognitive flexibility translate into behavior. from negative feedback, which was associated with altered brain
Further studies in patients with high levels of behavioral rigidity activation within the anterior insula.
(e.g., Obsessive-compulsive disorder, Autism spectrum disorder Furthermore, the modeling approach to reversal learning
or Anorexia nervosa) are needed to explore this hypothesis. is particularly promising to study participants with various
Taken together, we could show for the first time that neurodevelopmental and/or psychiatric disorders to investigate
hierarchical Bayesian modeling (here: HGF-model) is a valid atypical development and the disturbance of cognitive flexibility
approach to assess developmental effects in reversal learning. We and reward processing during development and its impact on
observed that the subject-specific volatility parameter changes various domains. Specifically, we found a correlation between the
during typical development from childhood to adolescence and model parameter beta and a measure of subclinical rigidity in
that children in general have a smaller learning rate. Differences everyday life. Children and adolescents with varying psychiatric
in these parameters may explain the typical differences in error disorders, including ASD, OCD, and ADHD, show deficits in
patterns in children and adolescents during a probabilistic cognitive flexibility and reward processing (Demurie et al., 2011;
reversal learning task, and are associated with overall cognitive Kohls et al., 2011; Hauser et al., 2014; Verfaillie et al., 2016; Tezcan
flexibility. That is, children might be less sure which stimulus et al., 2017). Appropriate model-based approaches provide
will most probably be rewarded, because they use the feedback the opportunity to augment standard behavioral analyses and
less readily and immediately to adapt their behavior. Adolescents, provide a closer link to underlying psychological mechanisms
on the other hand, used the feedback they received in a more and their underlying neural substrates.
efficient way, since after having established stronger stimulus
response associations they changed their response choice when
their stimulus-reward association had been updated quickly and DATA AVAILABILITY STATEMENT
efficiently. In line with this interpretation, Van Duijvenvoorde
The datasets generated for this study are available on request to
et al. (2013) showed that children and adolescents are not
the corresponding author.
generally impaired in probabilistic feedback monitoring, but
are specifically impaired in updating their stimulus-reward
association based on received probabilistic feedback. ETHICS STATEMENT
Developmental differences in performance on decision-
making or feedback learning have often been attributed to less The studies involving human participants were reviewed and
mature frontal brain development in children, resulting in less approved by the Ethics Committee of the University Hospital
developed control, monitoring and/or inhibitory capabilities in RWTH Aachen. Written informed consent to participate in this
children compared to adolescents (e.g., Crone et al., 2004; Davies study was provided by the participants’ legal guardian.
Frontiers in Neuroscience | www.frontiersin.org 11 January 2021 | Volume 14 | Article 536596You can also read

















































