Efficient Hair Damage Detection Using SEM Images Based on Convolutional Neural Network
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
applied
sciences
Article
Efficient Hair Damage Detection Using SEM Images Based on
Convolutional Neural Network
Qiaoyue Man *, Lintong Zhang and Youngim Cho
Department of Computer Engineering, Gachon University, Seongnam 1342, Korea;
zhanglintong1@naver.com (L.Z.); yicho@gachon.ac.kr (Y.C.)
* Correspondence: manqiaoyue@gachon.ac.kr
Abstract: With increasing interest in hairstyles and hair color, bleaching, dyeing, straightening, and
curling hair is being widely used worldwide, and the chemical and physical treatment of hair is
also increasing. As a result, hair has suffered a lot of damage, and the degree of damage to hair has
been measured only by the naked eye or touch. This has led to serious consequences, such as hair
damage and scalp diseases. However, although these problems are serious, there is little research on
hair damage. With the advancement of technology, people began to be interested in preventing and
reversing hair damage. Manual observation methods cannot accurately and quickly identify hair
damage areas. In recent years, with the rise of artificial intelligence technology, a large number of
applications in various scenarios have given researchers new methods. In the project, we created a
new hair damage data set based on SEM (scanning electron microscope) images. Through various
physical and chemical analyses, we observe the changes in the hair surface according to the degree of
hair damage, found the relationship between them, used a convolutional neural network to recognize
and confirm the degree of hair damage, and categorized the degree of damage into weak damage,
moderate damage and high damage.
Citation: Man, Q.; Zhang, L.; Cho, Y. Keywords: hair damage detection; convolution neural network; data analysis
Efficient Hair Damage Detection
Using SEM Images Based on
Convolutional Neural Network. Appl.
Sci. 2021, 11, 7333. https://doi.org/ 1. Introduction
10.3390/app11167333
Hair is an important part of human body image. Modern people’s aesthetic desires for
beauty, along with the continuous growth and diversification of hair and the continuous
Academic Editor: Fabio La Foresta
development of hair shape, color, and texture allows people to use their own personality
to change their image to follow the ever-changing trends. Hair is composed of 1–8%
Received: 11 June 2021
Accepted: 3 August 2021
external hydrophobic lipid epidermis, 80–90% α-helix or β-sheet conformation of parallel
Published: 9 August 2021
polypeptide chains to form water-insoluble keratin, less than 3% melanin pigment, and
0.6–1.0% trace elements, 10–15% moisture, etc. The normal cuticle has a smooth appearance,
Publisher’s Note: MDPI stays neutral
reflecting light and limiting friction between hair shafts. It is responsible for the shine and
with regard to jurisdictional claims in
texture of hair. The keratin layer of hair becomes fragile and cracked under the influence
published maps and institutional affil- of the external environment, temperature, humidity, along with chemical and physical
iations. treatments, thus affecting hair quality. Although most people’s hair is prone to various
damage problems because hair is inconvenient to observe, it is impossible to conduct a
detailed analysis, and there are few studies related to hair damage.
With the widespread application of photomicrography in the field of hair microstruc-
Copyright: © 2021 by the authors.
ture analysis, it has become easier to observe hair details that were difficult to clearly
Licensee MDPI, Basel, Switzerland.
observe with traditional microscopes. Clinically, microscopic analysis can be used as a
This article is an open access article
tool to assess hair damage, as an indicator of health status, by identifying the morpho-
distributed under the terms and logical characteristics of hair damage, and it can be analyzed in a qualitative manner.
conditions of the Creative Commons Hair’s exposure to various chemical agents and physical effects, such as detergents, dyes,
Attribution (CC BY) license (https:// combing, ultraviolet rays, etc., will affect hair. Researchers have conducted related studies
creativecommons.org/licenses/by/ accordingly. However, there is limited research that quantifies the degree of hair damage
4.0/). based on the morphological characteristics of hair. Traditionally, it is difficult to distinguish
Appl. Sci. 2021, 11, 7333. https://doi.org/10.3390/app11167333 https://www.mdpi.com/journal/applsci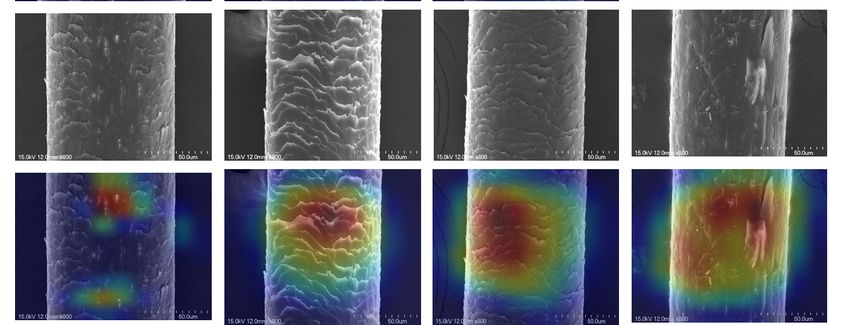
Appl. Sci. 2021, 11, 7333 2 of 14
detergents, dyes, combing, ultraviolet rays, etc., will affect hair. Researchers have
Appl. Sci. 2021, 11, 7333 2 of 13
conducted related studies accordingly. However, there is limited research that quantifies
the degree of hair damage based on the morphological characteristics of hair.
Traditionally, it is difficult to distinguish hair damage in detail using only manual
hair damagewith
observation in detail using microscope.
an optical only manualWith observation with an optical
the development microscope.
of microscopy With
techniques
the
anddevelopment
the application of microscopy
of scanning techniques
electron and the application
microscopy (SEM) ofinscanning
multipleelectron
fields, mi-
the
croscopy
microscopic (SEM) in multiple
details of hair fields, the microscopic
are easier to find. For details
example,of hair are easier
Coroaba A et toal.find. For
[1] used
example,
scanningCoroaba
electron Amicroscopy
et al. [1] used scanning
(SEM), electron microscopy
energy-dispersive X-ray (SEM), energy-dispersive
spectroscopy (EDX), and
X-ray
other spectroscopy
physical and(EDX),chemicaland methods
other physical and chemical
to identify methods
the effects to identify
of alopecia the effects
areata on the
of
structure and composition of human hair. Lima et al. [2] used a heating iron to heatused
alopecia areata on the structure and composition of human hair. Lima et al. [2] hair
aand
heating
observediron hair
to heat hair under
images and observed
a scanning hair imagesmicroscope
electron under a scanning electron
to evaluate micro-
the damage
scope
to the to evaluateand
epidermis thecortex
damage to the
of the hairepidermis
fiber by heatandloss.
cortex of the hair
Although thesefiber by heat
manual loss.
methods
Although
use scanningthese manualmicroscope
electron methods use scanning
imaging electron to
technology microscope
analyze hairimaging technology
microscopic images,to
analyze
they do hair microscopic
not perform images,
detailed they do not
quantitative perform detailed
classification quantitative classification
of hair damage.
of hairIndamage.
this paper, we propose a novel hair damage detection network. Based on artificial
In this paper,
intelligence we propose
algorithms, were aused
novel to hair damage
analyze detection
scanning network.
electron Based on
microscope artificial
(SEM) hair
intelligence algorithms, were used to analyze scanning electron microscope
surface image damage (Figure 1) to automatically identify and categorized the damage. (SEM) hair
surface imagetime,
At the same damage (Figure 1) to
we established automatically
a new hair damageidentify and
data set categorized
based on SEMthe damage.
microscopic
At the same time, we established a new hair damage data
image data. To summarize, the contributions of this work are as follows: set based on SEM microscopic
image data. To summarize, the contributions of this work are as follows:
We created a new hair microscopy data set based on SEM (Scanning Electron
• We created a new hair microscopy data set based on SEM (Scanning Electron Micro-
Microscope) image data and performed a quantitative analysis to classify the degree
scope) image data and performed a quantitative analysis to classify the degree of hair
of hair damage under the categories: weak damage, moderate damage, and high
damage under the categories: weak damage, moderate damage, and high damage.
damage.
• We proposed a novel and effective convolutional network model for hair damage
We proposed a novel and effective convolutional network model for hair damage
detection: RCSAN-Net (residual channel spatial attention network).
detection: RCSAN-Net (residual channel spatial attention network).
• We designed and introduced a channel and spatial attention mechanism into the hair
We designed and introduced a channel and spatial attention mechanism into the hair
damage detection model to gather hair features to improve the accuracy of detection
damage detection model to gather hair features to improve the accuracy of detection
and recognition.
and recognition.
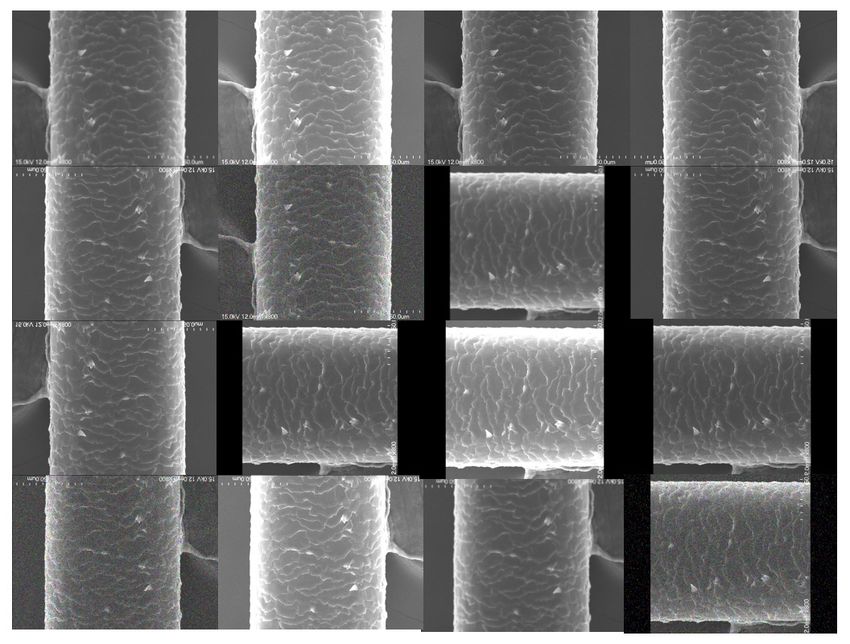
Figure1.
Figure 1. Scanning
Scanningelectron
electronmicroscope
microscope (SEM)
(SEM) imaging
imaging to observe
to observe hair hair magnification
magnification 800× 800×
micrographs.
micrographs.
2. Related Work
2. Related Work
Hair micro-detail detection and recognition can find use in many disciplines such
Hair micro-detail detection
as medicine and forensics. In the and recognition
context can find
of forensic use inmicroscopic
science, many disciplines such as
hair analysis
medicine
(a andmethod)
qualitative forensics.
hasInshown
the context of discrimination
effective forensic science, microscopic
[3,4], hair
and detailed analysis (a
examination
qualitative
of method)
hair under has shown
the microscope effectivefor
is helpful discrimination [3,4], and detailed
forensic identification. examination
Clinically, microscopicof
analysis can be used as a tool to assess hair damage, as an indicator of health status [5,6],
but the analysis needs to be performed under certain conditions. Hair is subjected to
various physical and chemical agents, including detergents, dyes, combing, and ultraviolet
rays, which will change the structure of the hair [7–9]. The morphological characteristics of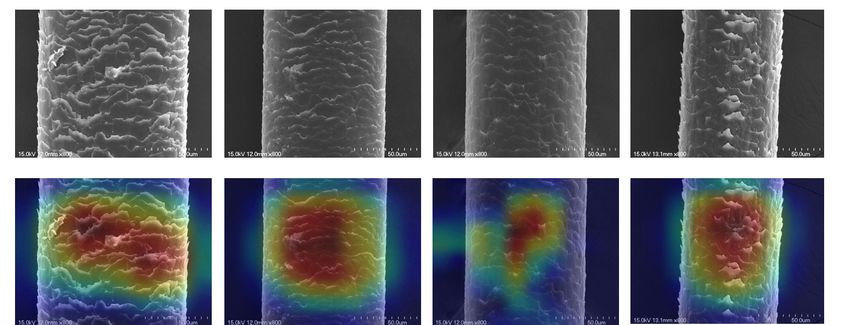
Appl. Sci. 2021, 11, 7333 3 of 13
damaged hair can be detected by qualitative methods for clinical research. Most studies
focus on the identification of hair damage, and few studies quantify the degree of hair
damage based on morphological characteristics [10–12]. It is worth noting that Kim et al.
proposed a classification system for hair damage. The system is divided into five damage
levels, expounding the influence of external factors on hair damage [13]. After that, Lee et al.
extended it to 12 classifications [14]. Observing the images of hair from a scanning electron
microscope (SEM), the researchers assessed the severity of hair structure irregularities
subjectively and refined the degree of hair damage into 12 levels. In these studies, visual
assessment was used as the main qualitative technique for hair damage. Few people have
developed a more objective hair damage analysis and identification system, most of the
research focuses on the manual analysis of morphological features detected by optical
microscope and analysis using commercial software [15,16], while there are few studies on
automatic and efficient detection of hair damage.
The detection and recognition of microscopic hair features is a challenging task. In
recent decades, with the continuous development of microscopic examination technology,
the microstructure of the hair that can be observed is clearer, and more precise, and
the sample preparation is simple and high-resolution, which makes the study of the
microscopic morphology of hair more in-depth. The manual detection method is still
the most important practical detection method, but it usually takes at least one year to
train qualified professional detection personnel. This is time-consuming and laborious
because it requires the microscopist to observe the fiber morphology under the microscope
for a long time, and the subjective and detection accuracy depends on the experience
of the microscopist. For example, Enrico et al. [17], used SEM image data to study the
relationship between hair damage that may be caused by repeated cosmetic treatments
and the absorption of cocaine from a wettable solution into the hair matrix (simulating
external contamination). Over the years, researchers have been developing a fast and
accurate method to automatically detect the degree of hair damage and have made many
useful attempts. These methods mainly include optical microscope and scanning electron
microscope (SEM) observation analysis of microscopic hair images, and the application of
image processing and computer vision technology to autonomously and efficiently detect
the degree of hair damage.
In recent years, with the emergence of convolutional neural networks and a large
number of applications, Methods based on image processing and computer vision are the
current research hotspot, greater number of researchers have focused on the field of hair
detection. For example, Umar Riaz. et al. [18] proposed a convolutional model that uses
convolutional neural network algorithms from an unconstrained perspective and uses
only texture information to achieve complete hair analysis (detection, segmentation, and
hairstyle classification). Chang. et al. [19] proposed a smart scalp inspection and diagnosis
system based on deep learning used to detect and diagnose four common scalp and hair
symptoms (dandruff, folliculitis, hair loss, and oily hair). As a part of scalp health care,
it is used for scalp and hair physiotherapy, and is an effective inspection and diagnosis
system. In the early days, people mainly used image processing technology to measure the
geometric parameters of hair, such as hair diameter and hair uniformity. Recently, some
scholars have begun to use computer vision technology to extract abstract detailed features
from hair microscopic images in order to recognize them. For example, Jiang et al. [20].
Proposed a convolutional network algorithm based on artificial intelligence: XI-Net, which
performs feature analysis, extraction, and classification of hair microscopic SEM images to
deal with forensic criminal investigation cases. According to this algorithm, the forensic
scientist can quickly extract the desired hair detail features, and the investigation efficiency
is greatly improved, speeding up the detection of the case.
algorithm, the forensic scientist can quickly extract the desired hair detail features, and
the investigation efficiency is greatly improved, speeding up the detection of the case.
Appl. Sci. 2021, 11, 7333 4 of 13
3. Materials and Methods
3.1.3.Convolutional
Materials and Neural
MethodsNetwork
3.1.With the emergence
Convolutional NeuralofNetwork
Lenet [21], a great success in handwriting font recognition,
convolutional networks began
With the emergence of Lenet a new chapter
[21], a greatinsuccess
automatic image recognition.
in handwriting Since
font recognition,
AlexNet
convolutional networks began a new chapter in automatic image recognition.deep
[22] won the ImageNet [23] image recognition algorithm award, Since
convolutional
AlexNet [22]neuralwon the networks
ImageNet have [23]dominated image classification.
image recognition With this
algorithm award, deeptrend,
convo-
research
lutionalhas shifted
neural fromhave
networks engineering
dominated manual functions to With
image classification. engineering network
this trend, research
architectures. For example, VGG-Net [24] proposed a modular network
has shifted from engineering manual functions to engineering network architectures. design methodFor
that uses stacking
example, VGG-Net the same type of network
[24] proposed a modular block strategy,
network which
design simplifies
method the workflow
that uses stacking the
of same
network design and simplifies the transfer learning of
type of network block strategy, which simplifies the workflow of networkdownstream applications.
design and
Inception
simplifies [25],
theexpands the depthofand
transfer learning width onapplications.
downstream the convolutional layer,
Inception extracts
[25], expands thethe
information
depth andof multiple
width on thescales in the image,
convolutional andextracts
layer, obtainsthe
more features. of
information Atmultiple
the samescales
time, in
thethe
1×1image,
size convolutional
and obtains more layerfeatures.
is used At forthe
dimensionality
same time, thereduction, which reduceslayer
1×1 size convolutional the is
amount
used for ofdimensionality
calculation. ResNet
reduction, [26,27]
whichintroduces
reduces the skip
amountconnections, which
of calculation. ResNetgreatly
[26,27]
alleviates
introducestheskip
problem of vanishing
connections, which gradients in deepthe
greatly alleviates neural
problemnetworks and allows
of vanishing the in
gradients
network to learn
deep neural improved
networks featurethe
and allows representations.
network to learn Properly
improved changing
feature the type and
representations.
number
Properlyof layers
changing in the
theresidual
type and block
number (Figure 2) caninimprove
of layers the performance
the residual block (Figure of 2)
the
can
network.
improve ResNet has becomeofone
the performance theofnetwork.
the mostResNetsuccessful
has CNN
become architectures and has
one of the most been
successful
CNN architectures
adopted and has been
by various computer visionadopted by various computer vision applications.
applications.
Figure
Figure 2. Different
2. Different residual
residual block
block frameworks
frameworks in ResNet
in ResNet (a): (a): Multiple
Multiple batch
batch normnorm calculations
calculations are are
used. (b):(b):
used. only oneone
only batch norm
batch calculation
norm is performed
calculation in the
is performed residual
in the block.
residual block.
3.2. RCSAN-Net: Residual Channel Spatial Attention Network
We proposed the RCSAN network as shown in Figure 3 based on the residual net-
work [28]. We deal with complex and difficult-to-detect hair damage feature regions by
stacking multiple residuals and a residual attention block formed by combining attention
blocks, thereby establishing an efficient network framework for hair damage detection.
target area. In our attention mechanism model, each module was divided into two parts:
residual block and channel-spatial combined attention block. The residual block
convolutional network extracts the global features of the image, and then enters the
attention module to pay attention to the local detailed features. However blindly adding
the number of attention models does not improve the overall network performance. In
Appl. Sci. 2021, 11, 7333 5 of 13
our network model, we use skip connection to connect the residual block and the attention
module.
Figure3.3.RCSAN:
Figure RCSAN:Residual
Residual Channel Spatial Attention
Channel Spatial Attentionnetwork.
network.
The RCSAN
After network
our model was constructed
receives the image,by it stacking multiple
uses standard residual attention
convolution modules.
calculation to
Previous
generate a feature map in the early stage, enters the attention mechanism module, extracts[29]
studies usually only focused on one type of attention, such as scale attention
orthe
spatial attentionand
multi-channel [30], and information
spatial could not extract thefeature,
about the precisegenerates
features an
of attention
the targetfeature
area. In
our attention mechanism model, each module was divided into two parts: residual
map, and then enters the next round of calculation. Attention to the feature extraction block
and channel-spatial
process is shown in combined
Figure 4. attention block. The residual block convolutional network
extracts the global features of the image, and then enters the attention module to pay
attention to the local detailed features. However blindly adding the number of attention
models does not improve the overall network performance. In our network model, we use
skip connection to connect the residual block and the attention module.
After our model receives the image, it uses standard convolution calculation to gen-
erate a feature map in the early stage, enters the attention mechanism module, extracts
Appl. Sci. 2021, 11, 7333 the multi-channel and spatial information about the feature, generates an attention feature 6 of 14
map, and then enters the next round of calculation. Attention to the feature extraction
process is shown in Figure 4.
Figure 4. Attention mechanism, interaction between features and attention masks.
Figure 4. Attention mechanism, interaction between features and attention masks.
3.3. Attention Mechanism Module
3.3. Attention
As we Mechanism Moduleplays an important role in human perception. Humans
all know, attention
useAsa we
series
all of partsattention
know, to glimpse and an
plays selectively
importantfocus
roleon
inthe prominent
human parts in
perception. order use
Humans
to better capture the visual structure. In the convolutional neural network, adding
a series of parts to glimpse and selectively focus on the prominent parts in order to anbetter
attention mechanism can effectively improve the performance of a CNN in large-scale
capture the visual structure. In the convolutional neural network, adding an attention
classification tasks.
mechanism can effectively improve the performance of a CNN in large-scale classification
tasks.
When processing hair SEM microscopic image data, due to the small differences in
hair surface characteristics, ordinary algorithm models cannot accurately identify the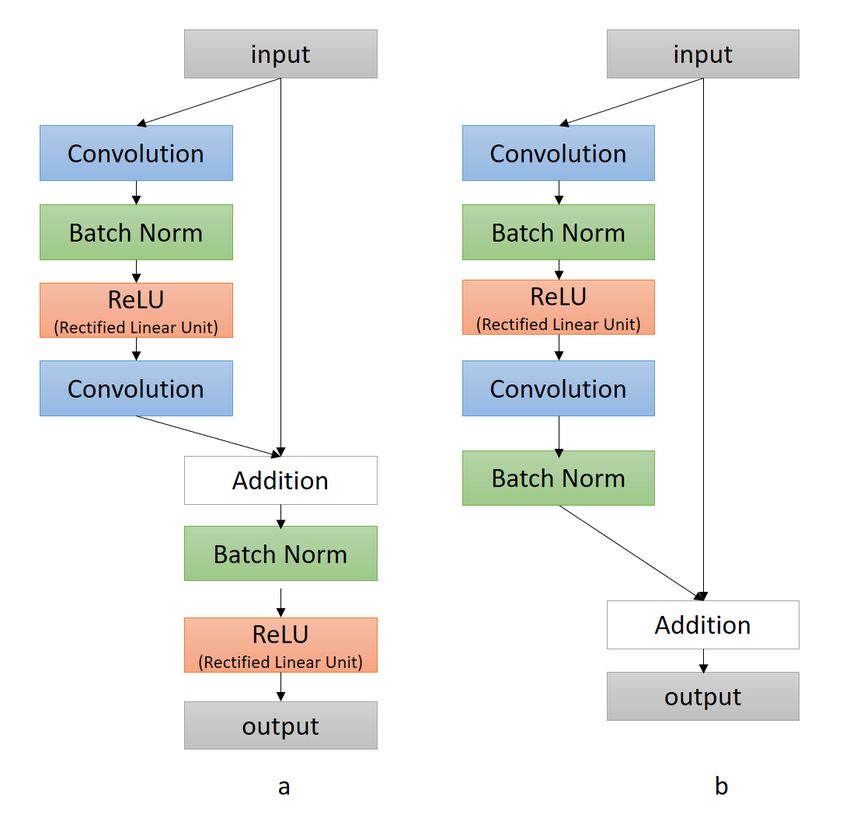
3.3. Attention Mechanism Module
As we all know, attention plays an important role in human perception. Humans use
a series of parts to glimpse and selectively focus on the prominent parts in order to better
Appl. Sci. 2021, 11, 7333 capture the visual structure. In the convolutional neural network, adding an attention 6 of 13
mechanism can effectively improve the performance of a CNN in large-scale classification
tasks.
When processing hair SEM microscopic image data, due to the small differences in
When processing
hair surface hair SEM
characteristics, microscopic
ordinary image
algorithm data,cannot
models due toaccurately
the small differences
identify thein
hair surface characteristics, ordinary algorithm models cannot accurately identify
subtle differences in hair damage. In this study, we designed an attention mechanism the subtle
module suitable for hair microscopic images. To improve the accuracy of hairmodule
differences in hair damage. In this study, we designed an attention mechanism SEM
suitable for image
microscopic hair microscopic images.
detection and To improve
damage the accuracy ofThe
feature identification. hairattention
SEM microscopic
module
image detection
includes, a channeland damage
attention feature
module identification.
and Themodule.
spatial attention attention module includes, a
channel attention module and spatial attention module.
3.3.1. Channel Attention Module
3.3.1. Channel Attention Module
Each channel graph of a feature can be regarded as a class-specific response, and
Each channel graph of a feature can be regarded as a class-specific response, and
different semantic responses are related to each other. By taking advantage of the
different semantic responses are related to each other. By taking advantage of the interde-
interdependence
pendence between between
channelchannel mappings,
mappings, we can emphasize
we can emphasize interdependent
interdependent feature
feature mappings
mappings and improve specific semantic feature representations. Therefore, we
and improve specific semantic feature representations. Therefore, we added a channel added a
channel attention module to enhance the interdependence between feature channels.
attention module to enhance the interdependence between feature channels. The structure The
structure of the channel
of the channel attentionattention
module, module,
is shownisinshown
Figurein5.Figure 5.
Figure 5. Channel attention module.
We reshape the original feature A ∈ RC ×H ×W into A ∈ RC ×N perform matrix multipli-
cation between the transpose of Ai and Aj , and then pass the softmax function to generate
the attention feature K ∈ RC ×C . In addition, perform matrix multiplication between the
transposes of K and A and reshape their results to RC ×H ×W . The final output Channel
attention feature map Mc (F) ∈ RC ×H ×W was as follows:
C
Mc ( F ) = β ∑ k ij Ai + A j
(1)
i =1
where Kij measures the jth channel’s impact on the ith channel, and the scale parameter β
gradually learns a weight from zero. The final feature of each channel is the weighted sum
of the features of all channels and the original features, which models the remote semantic
dependence between feature maps.
3.3.2. Spatial Attention Module
Different from channel attention, the focal point of spatial attention is the specific
area information part of the feature map, which supplements the channel attention. The
spatial attention map is generated by using the spatial relationship between the elements.
The structure of the spatial attention module, as shown in the Figure 6. When calculating
spatial attention, in order to retain the feature information from channel attention to the
maximum, we adopt a dual pooling method combining maximum pooling and average
pooling to generate two 2-dimensional feature maps: Fa and Fm. They are connected to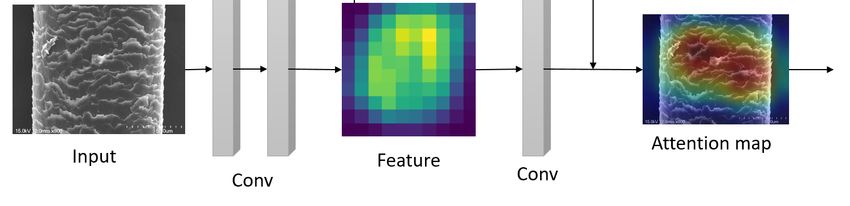
Different from channel attention, the focal point of spatial attention is the specific
area information part of the feature map, which supplements the channel attention. The
spatial attention map is generated by using the spatial relationship between the elements.
The structure of the spatial attention module, as shown in the Figure 6. When calculating
Appl. Sci. 2021, 11, 7333 spatial attention, in order to retain the feature information from channel attention to the
7 of 13
maximum, we adopt a dual pooling method combining maximum pooling and average
pooling to generate two 2-dimensional feature maps: Fa and Fm. They are connected to
generate effective feature descriptors, and after standard convolutional layer calculations,
generate aeffective
generate feature descriptors,
spatial attention feature map and (F) ∈
Msafter standard
RH×W: convolutional layer calculations,
generate a spatial attention feature map Ms (F) ∈ RH ×W :
Ms (F) = σ (f7×7([avgpool(f); maxpool (f)])) (2)
7×7
Where σ denotes the M s (F) = σfunction
sigmoid (f ([avgpool(f
and f7×7);ismaxpool (f )]))
the filter (2)
size in the convolution
operation.
where σ denotes the sigmoid function and f 7×7 is the filter size in the convolution operation.
Figure 6.
Figure Spatial attention
6. Spatial attention module.
module.
4. Results
4. Results
l. Sci. 2021, 11, 7333 4.1. Datasets 8o
4.1. Datasets
We collected hair samples from 50 men and 50 women in the 20–60 age group and used
We collected
a Hitachi S-4700 SEMhair(scanning
samples from 50 men
electron and 50 women
microscope) in the
to generate hair20–60 age group
microscopic and
images.
used
First, athe
Hitachi
sampleS-4700 SEM
hair was (scanning
screened, electronand
classified, microscope) to section
cut. The hair generatewas hair microscopic
attached to the
images.
conductive First, the
tape sample
coated hair
with was
carbon screened,
on both classified,
sides and and
4700) was used to scan the coated hair sample at 15 kV. Scans of multiple sections
fixed on cut.
the The
metal hair section
aluminum was
rod, of ea
attached
and to theisconductive
platinum used as the tape
metal coated
target.with
The carbon
spray on bothmachine
coating sides and fixed onsputtering
performed the metal
axis were performed, to ensure that the changes in the surface of the hair sample se
aluminum
coating under rod,a and
highplatinum
vacuum. is usedanasSEM
Then, the metal
(model:target. TheS-4700)
Hitachi spray wascoating
usedmachine
to scan
wereperformed
uniform and not
sputtering isolated.
coating The
under damage
a high to the
vacuum. hair
Then, shaft
an SEMunder the
(model:
the coated hair sample at 15 kV. Scans of multiple sections of each axis were performed,
scanning
Hitachi S- electr
microscope
to ensurewas that divided
the changes into three
in the grades:
surface of theweak damage,
hair sample seen moderate
were uniform damage,
and not and hi
damage (Figure
isolated. 7). Wetoused
The damage the hairtheshaft
degree
underofthecuticle
scanningdamage as the criterion
electron microscope to judge h
was divided
into three grades: weak damage, moderate damage, and high damage
damage. The sample with no obvious cracks on the cuticle of the hair surface was defin (Figure 7). We used
the degree of cuticle damage as the criterion to judge hair damage. The sample with no
as having weak damage; the sample with severe cracking and warping of the cuticle w
obvious cracks on the cuticle of the hair surface was defined as having weak damage; the
defined as having
sample with severe moderate
cracking and damage;
warping cuticles that was
of the cuticle haddefined
almostas completely
having moderate disappear
from damage;
the sample, were
cuticles that defined
had almost ascompletely
having high damage.
disappeared from the sample, were defined
as having high damage.
Figure 7. Classification of hair damage.
Figure 7. Classification of hair damage.
We collected the data of 500 hair samples from 100 testers, each hair data sample was
evenly divided into three equal parts, and the 5 mm segment in the center was selected for
We collected the data of 500 hair samples from 100 testers, each hair data sample w
evenly divided into three equal parts, and the 5 mm segment in the center was select
for observation, and classified as a weak damage, moderate damage, and high dama
image. Five hundred images for each hair damage category were produced. Since t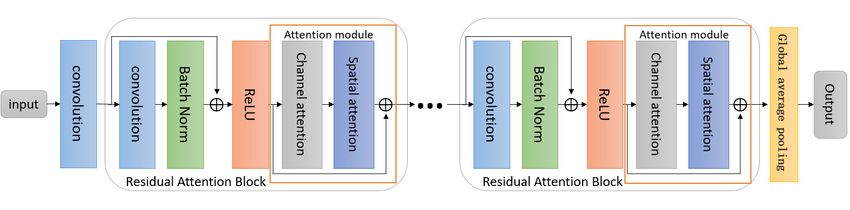
Appl. Sci. 2021, 11, 7333 8 of 13
observation, and classified as a weak damage, moderate damage, and high damage image.
Five hundred images for each hair damage category were produced. Since the collection of
hair SEM microscopic images is complicated and expensive, it is impossible to collect data
on a large scale. To this end, we used data enhancement algorithms to enhance the collected
hair SEM images, as shown in the Figure 8. For example, we used image inversion, rotation,
cropping, adding Gaussian noise and other algorithms. We created a hair SEM data set
that has a total of 15,000 microscopic hair images of various types, containing:
• Five thousand microscopic images of weakly damaged hair.
Appl. Sci. 2021, 11, 7333 • Five thousand microscopic images of moderately damaged hair. 9 of 14
• Five thousand microscopic images of highly damaged hair.
Figure 8. Hair
Figure 8. Hair SEM
SEM microscopic
microscopic image
image data
data augmentation.
augmentation.
4.2. Implementation Details
4.2. Implementation Details
In the experiment, we divided the data into a training set and a test set, 80% as a
In the experiment, we divided the data into a training set and a test set, 80% as a
training set and 20% as a test set. We crop the image size to 224 × 224 by using center crop-
training
ping. Theset and 20%
network wasastrained
a test set.
usingWea stochastic
crop the image sizedescent
gradient to 224 ×algorithm
224 by using
(SGD)center
[31].
cropping. The network was trained using a stochastic gradient descent algorithm
We set the initial learning rate to 0.1 and it was gradually decreased. We used a Nesterov (SGD)
[31]. We set[32]
momentum the of
initial learning
0.9 and a 10-4rate to 0.1
weight and without
decay it was gradually
dampeningdecreased. Weweights.
for all the used a
Nesterov momentum [32] of 0.9 and
Our model parameters are shown in Table 1. a 10-4 weight decay without dampening for all the
weights. Our model parameters are shown in Table 1.
4.3. Comparison with Other Advanced Methods
Table 1. The Configuration parameters of SACN-Net.
We chose other excellent network models, for example, the classic AlexNet algorithm,
the widely used
LayerVGG network model,Output the lightweight
size CNN network MobileNet, and
Attention
the excellentConv1
performance ResNet and other state-of-the-art
112 × 112 methods
7 × 7, 64,compare
to stride 2 with
our proposed model algorithm. The model we proposed is based on ResNet50. In the
Max pooling 56 × 56 3 × 3 stride 2
performance test comparison, we compared the 34-layer and 50-layer ResNet networks.
(1 × 1, 64)
The experiments shown in Table 2 show that our proposed SACN-Net has better accuracy
compared Residual Unit models.
to the other 56 × 56 (3 × 3, 64) × 1
In the model test, we also added a test of the attention module, (1 × 1, 256)
Figure 9 shows the
Attention Module 56 × 56 Attention
attention characteristics of the hair damage area, and a comparative test of the × 1channel
(1 × 1, 128)
attention module only, the single use space attention module, and the channel space atten-
tion module combined
Residual Unit with the position change
28 × 28method regarding the(3overall performance
× 3, 128) ×1
(1 × 1, 512)
Attention Module 28 × 28 Attention × 1
(1 × 1, 256)
Residual Unit 14 × 14 (3 × 3, 256) × 1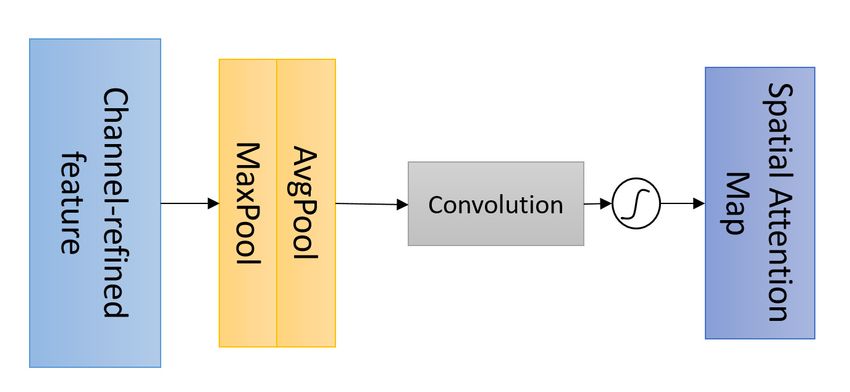
Appl. Sci. 2021, 11, 7333 9 of 13
of the model. We chose to use different attention modules in the model, and there was a
big gap in performance, using a single attention module because it could not accurately
identify the target, in the fusion of multiple attention modules, the location of each attention
module will also result in performance differences.
Table 1. The Configuration parameters of SACN-Net.
Appl. Sci. 2021, 11, 7333 Layer Output Size Attention 10 of 14
Conv1 112 × 112 7 × 7, 64, stride 2
Max pooling 56 × 56 3 × 3 stride 2
4.3. Comparison with Other Advanced Methods (1 × 1, 64)
Residualother
We chose 56 ×models,
Unit excellent network 56 for example, (3 ×the
3, 64) ×1
classic AlexNet
(1 × 1, 256)
algorithm, the widely used VGG network model, the lightweight CNN network
Attention
MobileNet, Module
and the 56 ×ResNet
excellent performance 56 Attention × 1 methods to
and other state-of-the-art
compare with our proposed model algorithm. The model we proposed (1 × 1, 128) is based on
Residual Unit 28 × 28 (3 × 3, 128) × 1
ResNet50. In the performance test comparison, we compared the 34-layer and 50-layer
(1 × 1, 512)
ResNet networks. The experiments shown in Table 2 show that our proposed SACN-Net
Attention Module 28 × 28 Attention × 1
has better accuracy compared to the other models.
(1 × 1, 256)
Residual Unit
Table 2. Comparison of accuracy of different14 × 14
models. (3 × 3, 256) × 1
(1 × 1, 1024)
Mode
Attention Module 14 × 14 Accuracy
Attention x1
AlexNet 0.8310
(1 × 1, 512)
Residual UnitVGG16 7×7 × 3, 512) × 3
(30.9053
(1 × 1, 2048)
Inception 0.9239
Global average pooling 1×1 7 × 7 stride 1
MobileNet 0.9143
ResNet34 0.9255
Table 2. Comparison of accuracy of different models.
ResNet50 0.9474
SACN-Net
Mode 0.9838
Accuracy
AlexNet
In the model test, 0.8310
we also added a test of the attention module, Figure 9 shows the
VGG16 0.9053
attention characteristics of the hair damage area, and a comparative test of the channel
attention module only, the single use space attention module,
Inception and the channel space
0.9239
attention module MobileNet
combined with the position change method 0.9143regarding the overall
performance of theResNet34
model. We chose to use different attention0.9255
modules in the model, and
there was a big gap in performance, using a single attention module because it could not
ResNet50 0.9474
accurately identify the target, in the fusion of multiple attention modules, the location of
SACN-Net 0.9838
each attention module will also result in performance differences.
Figure
Figure9.9.Attention
Attentionto
tothe
the feature mapof
feature map ofhair
hairdamage
damage area.
area.
InInTop-1,
Top-1,in
inthe
the benchmark
benchmark test
testasasshown
shown in in
Table 3, we
Table found
3, we that the
found thatperformance is
the performance
the best based on the channel first and then the spatial attention module.
is the best based on the channel first and then the spatial attention module.
Table 3. Classification error (%) on SEM Hair dataset.
Attention Type Top-1 Err. (%)
Channel Attention 5.03Appl. Sci. 2021, 11, 7333 10 of 13
Table 3. Classification error (%) on SEM Hair dataset.
Attention Type Top-1 Err. (%)
Channel Attention 5.03
Spatial Attention 4.25
Channel & Spatial Attention 2.92
Spatial & Channel Attention 2.47
Appl. Sci. 2021, 11, 7333 11 of 14
5. Discussion
We focused on how to detect hair damage autonomously and efficiently. We cre-
ated a system based on artificial intelligence convolutional neural network that could
care and maintenance,
autonomously medical
detect the degree of health diagnosis
hair damage. This and
couldother directions.
be used We daily
for personal are currently
care
developing a handheld machine that can detect the degree of hair damage,
and maintenance, medical health diagnosis and other directions. We are currently develop- using the hair
damage
ing detection
a handheld algorithm
machine that canto quickly
detect diagnose
the degree hair
of hair damage.
damage, using When collecting
the hair damage hair
samples, algorithm
detection we only considered adults 20–60
to quickly diagnose years old,
hair damage. and collecting
When did collect hair
hair samples
samples, wefrom
minors
only or people
considered over20–60
adults 60. The reason
years old, andwas
didthat people
collect hair in this age
samples fromrange care
minors ormore
people about
over
daily60.
hairThe
carereason was that
and have morepeople in this age
hair damage. rangethid
In turn, carehelped
more about daily
our hair hair care
damage sample
and have more
collection. We hair damage.
observed SEMIn turn, thid helped
(scanning our hair
electron damage sample
microscope) images,collection. We the
considering
observed
possible SEM (scanning
influence electron
of hair colormicroscope)
on the degree images, considering
of hair damage,the possible
and influencesome
we collected
of hair color on the degree of hair damage, and we collected some
brown, brown and red hair samples. After observation and analysis, we found brown, brown and that
red the
hair samples. After observation and analysis, we found that the relationship
relationship between hair color and hair damage is weak. When making the data set, we between hair
color and hair damage is weak. When making the data set, we compared the microscopic
compared the microscopic characteristics of hair at 400× and 800× (Figure 10). First, we
characteristics of hair at 400× and 800× (Figure 10). First, we used the 400× hair image
used the 400× hair image under SEM observation. The display effect was not satisfactory,
under SEM observation. The display effect was not satisfactory, the hair surface texture
the hair surface texture could not be displayed accurately, and it was difficult to use for
could not be displayed accurately, and it was difficult to use for model training. Finally,
model
we chosetraining.
the 800× Finally, we chose
hair image as the the 800× hair
standard of theimage as the
data set and standard
made ourof owntheSEM
datahair
set and
made our
data set. own SEM hair data set.
Figure 10.Comparison
Figure10. Comparisonofofhair’s
hair’smicroscopic
microscopicdetails under
details different
under magnifications.
different magnifications.
In
In the
the model,
model, we explored the
we explored proposed attention
the proposed attention mechanism
mechanism model
model to find the
to find the best
best performance of the model. After many revisions, it is found that the dual attention
performance of the model. After many revisions, it is found that the dual attention
mechanism module, especially the channel first attention method, has the highest efficiency
mechanism module, especially the channel first attention method, has the highest
in identifying hair damage features. Figure 11 shows the attention feature extraction of our
efficiency in identifying hair damage features. Figure 11 shows the attention feature
attention mechanism module.
extraction of our attention mechanism module.Appl.
Appl. Sci.
Sci. 11,7333
2021,11,
2021, 7333 11 of12
13of 14
Figure
Figure 11.
11. Attention to damaged
Attention to damagedhair
hairarea.
area.
6. Conclusions
6. Conclusions
In this
In this paper,
paper,wewecreated
createdan an
SEMSEM based microscopic
based hair image
microscopic data set
hair image of 50set
data male andmale
of 50
50 female hair samples in the 20–60 year age range and divided the data into
and 50 female hair samples in the 20–60 year age range and divided the data into weak weak damage,
moderate damage, and high damage according to the degree of damage to the cuticle on
damage, moderate damage, and high damage according to the degree of damage to the
the surface of the hair. We mainly focused on the degree of hair damage. When collecting
cuticle on the surface of the hair. We mainly focused on the degree of hair damage. When
hair samples, we adopted a random collection method. The samples include hair samples
collecting hair samples, we adopted a random collection method. The samples include
such as dyed hair, curly hair, and straight hair. During microscopic observation, the middle
hair samples
section of eachsuch as dyed
hair was used as hair, curly hair, area.
the observation and Westraight hair.
reduced theDuring microscopic
variability of the
observation, the middle section of each hair was used as the observation
samples. We also proposed a new residual convolutional network based on the spatial area. We reduced
the variability of the samples. We also proposed a new residual convolutional
attention module and verified it with our data set. Experiments showed that our network network
based
model on the spatial
is effective attention
and robust. module
In this article,and
we verified it withtheour
only discussed dataofset.
degree hairExperiments
damage,
showed thatdiagnosis
without the our network
of themodel
cause isof effective and robust.
the hair damage. In this
In future article,we
research, wewill
only discussed
focus on
the
thedegree
cause ofofhair
hairdamage
damage, without
and analyze theit.diagnosis of the cause of the hair damage. In future
research, we will focus on the cause of hair damage and analyze it.
Author Contributions: Conceptualization, Q.M. and Y.C.; methodology, software, Q.M.; validation,
Author Contributions:
Q.M., Y.C. Conceptualization,
and L.Z.; formal analysis, Q.M.;Q.M. and Y.C.; methodology,
investigation, software,
Q.M.; resources, Q.M.;
Q.M.; data validation,
curation,
Q.M.,
Q.M.;Y.C. and L.Z.; formal
writing—original analysis,
draft Q.M.; Q.M.;
preparation, investigation, Q.M.; resources,
writing review Q.M.;
and editing, data
Q.M., curation,
Y.C. Q.M.;
and L.Z.;
writing—original
visualization, Q.M.;draft preparation,
supervision, Q.M., Q.M.;
Y.C. andwriting reviewadministration,
L.Z.; project and editing, Q.M.,
Q.M.,Y.C.;
Y.C.funding
and L.Z.;
visualization, Q.M.;
acquisition, Q.M., Y.C.supervision, Q.M.,read
All authors have Y.C. and
and L.Z.;toproject
agreed administration,
the published version ofQ.M., Y.C.; funding
the manuscript.
acquisition, Q.M., Y.C. All authors have read and agreed to the published version of the manuscript.
Funding: This research was supported by the MSIT (Ministry of Science and ICT), Korea, under
Funding:
the ITRC This research Technology
(Information was supported by theCenter)
Research MSIT (Ministry of Science(IITP-2021-2017-0-01630)
support program and ICT), Korea, under the
ITRC
supervised by the IITP and 2018R1D1A1A09084151 by NRF, and supported by (IITP-2021-2017-0-01630)
(Information Technology Research Center) support program the Korea Agency for
supervised byTechnology
Infrastructure the IITP and 2018R1D1A1A09084151
Advancement by NRF,
(KAIA) grant funded andMinistry
by the supported by the
of Land, Korea Agency
Infrastructure
for
andInfrastructure Technology Advancement (KAIA) grant funded by the Ministry of Land,
Transport 20DEAP-B158906-01.
Infrastructure and Transport 20DEAP-B158906-01.
Institutional Review Board Statement: Not Applicable.
Institutional Review Board Statement: Not Applicable.
Informed Consent Statement: Not Applicable.
Informed ConsentStatement:
Data Availability Statement: Not
Not Applicable.
Applicable.
Data Availability
Conflicts Statement:
of Interest: Notdeclare
The authors Applicable.
no conflict of interest.
Conflicts of Interest: The authors declare no conflict of interest.
ReferencesAppl. Sci. 2021, 11, 7333 12 of 13
References
1. Coroaba, A.; Chiriac, A.E.; Sacarescu, L.; Pinteala, T.; Minea, B.; Ibanescu, S.; Pertea, M.; Moraru, A.; Esanu, I.; Maier, S.S.; et al.
New insights into human hair: SAXS, SEM, TEM and EDX for Alopecia Areata investigations. PeerJ 2020, 8, e8376. [CrossRef]
2. Lima, C.R.R.D.C.; De Couto, R.A.A.; Freire, T.B.; Goshiyama, A.M.; Baby, A.R.; Velasco, M.V.R.; Constantino, V.R.L.; Matos, J.D.R.
Heat-damaged evaluation of virgin hair. J. Cosmet. Dermatol. 2019, 18, 1885–1892. [CrossRef]
3. National Research Council USA. 2009 Strengthening Forensic Science in the United States: A Path Forward; National Academy Press:
Wasington, DC, USA, 2009.
4. Birngruber, C.; Ramsthaler, F.; Verhoff, M.A. The color(s) of human hair—Forensic hair analysis with SpectraCube® . Forensic Sci.
Int. 2009, 185, e19–e23. [CrossRef]
5. Rice, R.H.; Wong, V.J.; Price, V.H.; Hohl, D.; Pinkerton, K.E. Cuticle cell defects in lamellar ichthyosis hair and anomalous hair
shaft syndromes visualized after detergent extraction. Anat. Rec. 1996, 246, 433–441. [CrossRef]
6. Zhang, Y.; Alsop, R.J.; Soomro, A.; Yang, F.-C.; Rheinstädter, M.C. Effect of shampoo, conditioner and permanent waving on the
molecular structure of human hair. PeerJ 2015, 3, e1296. [CrossRef] [PubMed]
7. Richena, M.; Rezende, C.A. Effect of photodamage on the outermost cuticle layer of human hair. J. Photochem. Photobiol. B Biol.
2015, 153, 296–304. [CrossRef] [PubMed]
8. Takada, K.; Nakamura, A.; Matsuo, N.; Inoue, A.; Someya, K.; Shimogaki, H. Influence of oxidative and/or reductive treatment
on human hair (I): Analysis of hair-damage after oxidative and/or reductive treatment. J. Oleo Sci. 2003, 52, 541–548. [CrossRef]
9. Lee, Y.; Kim, Y.-D.; Hyun, H.-J.; Pi, L.-Q.; Jin, X.; Lee, W.-S. Hair Shaft Damage from Heat and Drying Time of Hair Dryer. Ann.
Dermatol. 2011, 23, 455–462. [CrossRef] [PubMed]
10. Kaliyadan, F.; Gosai, B.B.; Al Melhim, W.N.; Feroze, K.; Qureshi, H.A.; Ibrahim, S.; Kuruvilla, J. Scanning electron microscopy
study of hair shaft damage secondary to cosmetic treatments of the hair. Int. J. Trichol. 2016, 8, 94–98. [CrossRef]
11. McMullen, R.L. Image analysis tools to quantify visual properties of hair fiber assemblies. In Practical Modern Hair Science; Evans,
T., Wickett, R.R., Eds.; Allured Publishing: Carol Stream, IL, USA, 2012; pp. 295–332.
12. Ahn, H.J.; Lee, W.-S. An ultrastuctural study of hair fiber damage and restoration following treatment with permanent hair dye.
Int. J. Dermatol. 2002, 41, 88–92. [CrossRef]
13. Kim, Y.-D.; Jeon, S.-Y.; Ji, J.H.; Lee, W.-S. Development of a classification system for extrinsic hair damage: Standard grading of
electron microscopic findings of damaged hairs. Am. J. Dermatopathol. 2010, 32, 432–438. [CrossRef]
14. Lee, S.Y.; Choi, A.R.; Baek, J.H.; Kim, H.O.; Shin, M.K.; Koh, J.S. Twelve-point scale grading system of scanning electron
microscopic examination to investigate subtle changes in damaged hair surface. Skin Res. Technol. 2016, 22, 406–411. [CrossRef]
15. Verma, M.S.; Pratt, L.; Ganesh, C.; Medina, C. Hair-MAP: A prototype automated system for forensic hair comparison and
analysis. Forensic Sci. Int. 2002, 129, 168–186. [CrossRef]
16. Park, K.H.; Kim, H.J.; Oh, B.; Lee, E.; Ha, J. Assessment of hair surface roughness using quantitative image analysis. Skin Res.
Technol. 2018, 24, 80–84. [CrossRef]
17. Gerace, E.; Veronesi, A.; Martra, G.; Salomone, A.; Vincenti, M. Study of cocaine incorporation in hair damaged by cosmetic
treatments. Forensic Chem. 2017, 3, 69–73. [CrossRef]
18. Muhammad, U.R.; Svanera, M.; Leonardi, R.; Benini, S. Hair detection, segmentation, and hairstyle classification in the wild.
Image Vis. Comput. 2018, 71, 25–37. [CrossRef]
19. Chang, W.-J.; Chen, L.-B.; Chen, M.-C.; Chiu, Y.-C.; Lin, J.-Y. ScalpEye: A Deep Learning-Based Scalp Hair Inspection and
Diagnosis System for Scalp Health. IEEE Access 2020, 8, 134826–134837. [CrossRef]
20. Xiaojia, J.; Mengjing, Y.; Yongzhi, Q.; Ya, H. Hair Microscopic Image Classification Method Based on Convolutional Neural
Network. In Proceedings of the 2019 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS),
Shenyang, China, 12–14 July 2019; pp. 433–438.
21. LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86,
2278–2324. [CrossRef]
22. Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf.
Process. Syst. 2012, 25, 1097–1105. [CrossRef]
23. Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the
2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [CrossRef]
24. Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556.
25. Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with
convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26
July 2017. [CrossRef]
26. Targ, S.; Almeida, D.; Lyman, K. Resnet in Resnet: Generalizing Residual Architectures. arXiv 2016, arXiv:1603.08029.
27. He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the 14th European Conference
on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645.
28. He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016.
29. Chen, L.-C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. arXiv 2015,
arXiv:1511.03339.Appl. Sci. 2021, 11, 7333 13 of 13
30. Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025.
31. Zinkevich, M.; Weimer, M.; Li, L.; Smola, A. Parallelized stochastic gradient descent. In Proceedings of the Advances in Neural
Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010.
32. Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings
of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147.You can also read

















































