Explainable Machine Learning for Scientific Insights and Discoveries
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Received January 21, 2020, accepted February 11, 2020, date of publication February 24, 2020, date of current version March 11, 2020.
Digital Object Identifier 10.1109/ACCESS.2020.2976199
Explainable Machine Learning for Scientific
Insights and Discoveries
RIBANA ROSCHER 1,2 , (Member, IEEE), BASTIAN BOHN 3 ,
MARCO F. DUARTE 4, (Senior Member, IEEE), AND JOCHEN GARCKE 3,5
1 Institute of Geodesy and Geoinformation, University of Bonn, 53115 Bonn, Germany
2 Institute of Computer Science, University of Osnabrueck, 49074 Osnabrück, Germany
3 Institute for Numerical Simulation, University of Bonn, 53115 Bonn, Germany
4 Department of Electrical and Computer Engineering, University of Massachusetts Amherst, Amherst, MA 01003, USA
5 Fraunhofer Center for Machine Learning and Fraunhofer SCAI, 53757 Sankt Augustin, Germany
Corresponding author: Jochen Garcke (jochen.garcke@scai.fraunhofer.de)
This work was supported in part by the Fraunhofer Cluster of Excellence Cognitive Internet Technologies, and in part by the
Sonderforschungsbereich 1060-The Mathematics of Emergent Effects-funded by the Deutsche Forschungsgemeinschaft.
ABSTRACT Machine learning methods have been remarkably successful for a wide range of application
areas in the extraction of essential information from data. An exciting and relatively recent development is the
uptake of machine learning in the natural sciences, where the major goal is to obtain novel scientific insights
and discoveries from observational or simulated data. A prerequisite for obtaining a scientific outcome is
domain knowledge, which is needed to gain explainability, but also to enhance scientific consistency. In
this article, we review explainable machine learning in view of applications in the natural sciences and
discuss three core elements that we identified as relevant in this context: transparency, interpretability,
and explainability. With respect to these core elements, we provide a survey of recent scientific works that
incorporate machine learning and the way that explainable machine learning is used in combination with
domain knowledge from the application areas.
INDEX TERMS Explainable machine learning, informed machine learning, interpretability, scientific
consistency, transparency.
I. INTRODUCTION In the natural sciences, the main goals for utilizing
Machine learning methods, especially with the rise of neural ML are scientific understanding, inferring causal relation-
networks (NNs), are nowadays used widely in commercial ships from observational data, or even achieving new sci-
applications. This success has led to a considerable uptake entific insights. With ML approaches, one can nowadays
of machine learning (ML) in many scientific areas. Usually (semi-)automatically process and analyze large amounts
these models are trained with regard to high accuracy, but of scientific data from experiments, observations, or other
there is a recent and ongoing high demand for understanding sources. The specific aim and scientific outcome represen-
the way a specific model operates and the underlying reasons tation will depend on the researchers’ intentions, purposes,
for the decisions made by the model. One motivation behind objectives, contextual standards of accuracy, and intended
this is that scientists increasingly adopt ML for optimizing audiences. Regarding conditions for an adequate scientific
and producing scientific outcomes. Here, explainability is a representation, we defer to the philosophy of science [4].
prerequisite to ensure the scientific value of the outcome. In This article provides a survey of recent ML approaches that
this context, research directions such as explainable artificial are meant to derive scientific outcomes, where we specif-
intelligence (AI) [1], informed ML [2], or intelligible intelli- ically focus on the natural sciences. Given the scientific
gence [3] have emerged. Though related, the concepts, goals, outcomes, novel insights can be derived to deepen under-
and motivations vary, and core technical terms are defined in standing, or scientific discoveries can be revealed that were
different ways. not known before. Gaining scientific insights and discoveries
from an ML algorithm means gathering information from its
The associate editor coordinating the review of this manuscript and output and/or its parameters regarding the scientific process
approving it for publication was Massimo Cafaro . or experiments underlying the data.
This work is licensed under a Creative Commons Attribution 4.0 License. For more information, see http://creativecommons.org/licenses/by/4.0/
42200 VOLUME 8, 2020R. Roscher et al.: Explainable ML for Scientific Insights and Discoveries
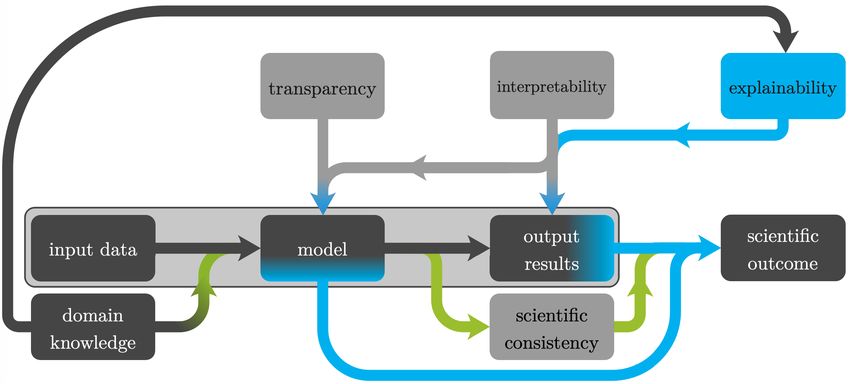
FIGURE 1. Major ML-based chains from which scientific outcomes can be derived: The commonly used, basic ML chain (light gray box)
learns a black box model from given input data and provides an output. Given the black box model and input-output relations, a scientific
outcome can be derived by explaining the output results utilizing domain knowledge. Alternatively, a transparent and interpretable model
can be explained using domain knowledge leading to scientific outcomes. Additionally, the incorporation of domain knowledge can
promote scientifically consistent solutions (green arrows).
One should note that a data-driven effort of scientific dis- consistency. Section III highlights several applications in the
covery is nothing new, but mimics the revolutionary work of natural sciences that use these concepts to gain new scientific
Johannes Kepler and Sir Isaac Newton, which was based on insights, while organizing the ML workflows into character-
a combination of data-driven and analytical work. As stated istic groups based on the different uptakes of interpretabil-
by [5], ity and explainability. Section IV closes the paper with a
Data science is not replacing mathematical physics discussion.
and engineering, but is instead augmenting it for
the twenty-first century, resulting in more of a II. TERMINOLOGY
renaissance than a revolution. Several descriptive terms are used in the literature about
What is new, however, is the abundance of high-quality data explainable ML with diverse meanings, e.g., [6]–[11].
in the combination with scalable computational and data Nonetheless, distinct ideas can be identified. For the pur-
processing infrastructure. pose of this work, we distinguish between transparency,
The main contribution of this survey is the discussion interpretability, and explainability. Roughly speaking, trans-
of commonly used ML-based chains leading to scientific parency considers the ML approach, interpretability con-
outcomes that have been used in the natural sciences (see siders the ML model together with data, and explainability
Fig. 1). The three elements transparency, interpretability, considers the model, the data, and human involvement.
and explainability play a central role. These concepts will be
defined and discussed in detail in this survey. Another essen- A. TRANSPARENCY
tial component is domain knowledge, which is necessary to An ML approach is transparent if the processes that extract
achieve explainability, but can also be used to foster scientific model parameters from training data and generate labels from
consistency of the model and the result. We provide diverse testing data can be described and motivated by the approach
examples from the natural sciences of approaches that can be designer. We say that the transparency of an ML approach
related to these topics. Moreover, we define several groups of concerns its different ingredients: the overall model structure,
ML chains based on the presence of the components from the individual model components, the learning algorithm,
Fig. 1. Our goal is to foster a better understanding and a and how the specific solution is obtained by the algorithm.
clearer overview of ML algorithms applied to data from the We propose to distinguish between model transparency,
natural sciences. design transparency, and algorithmic transparency. Gener-
The paper is structured as follows. Section II dis- ally, to expect an ML method to be completely transparent in
cusses transparency, interpretability, and explainability in all aspects is rather unrealistic; usually there will be different
the context of this article. While these terms are more degrees of transparency.
methodology-driven and refer to properties of the model As an example, consider kernel-based ML appro-
and the algorithm, we also describe the role of additional aches [12], [13]. The obtained model is transparent as it is
information and domain knowledge, as well as scientific given as a sum of kernel functions. The individual design
VOLUME 8, 2020 42201R. Roscher et al.: Explainable ML for Scientific Insights and Discoveries
component is the chosen kernel. Choosing between a linear Overall, we argue that transparency in its three forms does
or nonlinear kernel is typically a transparent design deci- to a large degree not depend on the specific data, but solely
sion. However, using the common Gaussian kernel based on on the ML method. But clearly, the obtained specific solution,
Euclidean distances can be a non-transparent design decision. in particular the ‘‘solution path’’ to it by the (iterative) algo-
In other words, it may not be clear why a given nonlinear rithm, depends on the training data. The analysis task and the
kernel was chosen. Domain specific design choices can type of attributes usually play a role in achieving design trans-
be made, in particular using suitable distance measures to parency. Moreover, the choice of hyper-parameters might
replace the Euclidean distance, making the design of this involve model structure, components, or the algorithm, while
model component (more) transparent. In the case of Gaussian in an algorithmic determination of hyper-parameters the spe-
process (GP) regression, the specific choice of the kernel cific training data comes into play again.
can be built into the optimization of the hyper-parameters
using the maximum likelihood framework [13]. Thereby, B. INTERPRETABILITY
design transparency crosses over to algorithmic transparency. For our purposes, interpretability pertains to the capabil-
Furthermore, the obtained specific solution is, from a mathe- ity of making sense of an obtained ML model. Generally,
matical point of view, transparent. Namely, it is the unique to interpret means ‘‘to explain the meaning of’’ or ‘‘present
solution of a convex optimization problem that can be in understandable terms;’’1 see also [6]–[8]. We consider
reproducibly obtained [12], [13], resulting in algorithmic explanation distinct from interpretation, and focus here on
transparency. In contrast, approximations in the specific solu- the second aspect. Therefore, the aim of interpretability is
tion method such as early stopping, matrix approximations, to present some of the properties of an ML model in terms
stochastic gradient descent, and others, can result in (some) understandable to a human. Ideally, one could answer the
non-transparency of the algorithm. question from [16]: ‘‘Can we understand what the ML algo-
As another example, consider NNs [14]. The model is rithm bases its decision on?’’ Somewhat formally, [10] states:
transparent since its input-output relation and structure can An interpretation is the mapping of an abstract
be written down in mathematical terms. Individual model concept (e.g., a predicted class) into a domain that
components, such as a layer of a NN, that are chosen based on the human can make sense of.
domain knowledge can be considered as design transparent. Interpretations can be obtained by way of understandable
Nonetheless, the layer parameters — be it their numbers, size, proxy models, which approximate the predictions of a more
or nonlinearities involved — are often chosen in an ad-hoc complex approach [7], [8]. Longstanding approaches involve
or heuristic fashion and not motivated by domain knowl- decision trees or rule extraction [17] and linear models.
edge; these decisions are therefore not design transparent. In prototype selection, one or several examples similar to
The learning algorithm is typically transparent, e.g., stochas- the inspected datum are selected, from which criteria for the
tic gradient descent can be easily written down. However, outcome can be obtained. For feature importance, the weights
the choice of hyper-parameters such as learning rate, batch in a linear model are employed to identify attributes that
size, etc., has a more heuristic, non-transparent algorithmic are relevant for a prediction, either globally or locally. For
nature. Due to the presence of several local minima, the solu- example, [18] introduced the model-agnostic approach LIME
tion is usually not easily reproducible; therefore, the obtained (Local Interpretable Model-Agnostic Explanations), which
specific solution is not (fully) algorithmically transparent. gives interpretation by creating locally a linear proxy model
Our view is closely related to Lipton [9], who writes: in the neighborhood of a datum, while the scores in layer-wise
Informally, transparency is the opposite of opac- relevance propagation (LRP) are obtained by means of a
ity or ‘‘black-boxness’’. It connotes some sense of first-order Taylor expansion of the nonlinear function [10].
understanding the mechanism by which the model A sensitivity analysis can be used to inspect how a model
works. Transparency is considered here at the level output (locally) depends upon the different input parame-
of the entire model (simulatability), at the level of ters [19]. Such an extraction of information from the input
individual components such as parameters (decom- and the output of a learned model is also called post hoc
posability), and at the level of the training algo- interpretability [9] or reverse engineering [8]. Further details,
rithm (algorithmic transparency). types of interpretation, and specific realization can be found
An important contribution to the understanding of ML in recent surveys [7], [8], [20].
algorithms is their mathematical interpretation and deriva- Visual approaches such as saliency masks or heatmaps
tion, which help to understand when and how to use these show relevant patterns in the input based on feature impor-
approaches. Classical examples are the Kalman filter or tance, sensitivity analysis, or relevance scores to explain
principal component analysis, where several mathematical model decisions, and are employed in particular with deep
derivations exist for each and enhance their understanding. learning approaches for image classification [10], [21], [22].
Note that although there are many mathematical attempts to [23] introduces a formal notion for interpreting NNs where
a better understanding of deep learning, at this stage ‘‘the a set of input features is deemed relevant for a classi-
[mathematical] interpretation of NNs appears to mimic a type
of Rorschach test,’’ according to [15]. 1 https://www.merriam-webster.com/dictionary/interpret
42202 VOLUME 8, 2020R. Roscher et al.: Explainable ML for Scientific Insights and Discoveries
fication decision if the expected classifier score remains As written in [8], ‘‘[in explainable ML] these definitions
nearly constant when randomising the remaining features. assume implicitly that the concepts expressed in the under-
The authors prove that under this notion, the problem of standable terms composing an explanation are self-contained
finding small sets of relevant features is NP-hard, even and do not need further explanations.’’
when considering approximation within any non-trivial fac- On the other hand, we believe that a collection of inter-
tor. This, on the one hand, shows the difficulty of algo- pretations can be an explanation only with further contex-
rithmically determining interpretations; on the other hand, tual information, stemming from domain knowledge and
it justifies the current use of heuristic methods in practical related to the analysis goal. In other words, explainability
applications. usually cannot be achieved purely algorithmically. On its
In unsupervised learning, the analysis goal can be a better own, the interpretation of a model — in understandable terms
understanding of the data, for example, by an interpretation of to a human — for an individual datum might not provide
the obtained representation by linear or nonlinear dimension- an explanation to understand the decision. For example,
ality reduction [24], [25], or by inspecting the components of the most relevant variables might be the same for several data;
a low-rank tensor decomposition [26]. however, it is possible that the important observation for an
Note that, in contrast to transparency, to achieve inter- understanding of the overall predictive behavior is that when
pretability the data is always involved. Although there are ranking variables with respect to their interpretation, different
model-agnostic approaches for interpretability, transparency lists of relevant variables are determined for each datum.
or retaining the model can assist in the interpretation. Further- Overall, the result will depend on the underlying analysis
more, method-specific approaches depend on transparency. goal. ‘‘Why is the decision made?’’ will need a different
For example, layer-wise relevance propagation for NNs explanation than ‘‘Why is the decision for datum A different
exploits the known model layout [10]. to (the nearby) datum B?’’.
While the methods for interpretation allow the inspection In other words, for explainability, the goal of the ML
of a single datum, [27] observes that it quickly becomes very ‘‘user’’ is very relevant. According to [20], there are essen-
time consuming to investigate large numbers of individual tially four reasons to seek explanations: to justify decisions,
interpretations. As a step to automate the processing of the to (enhance) control, to improve models, and to discover
individual interpretations for a single datum, they employ new knowledge. For regulatory purposes it might be fine to
clustering of heatmaps of many data to obtain an overall have an explanation by examples or (local) feature analysis,
impression of the interpretations for the predictions of the ML so that certain ‘‘formal’’ aspects can be checked. But, to attain
algorithm. scientific outcomes with ML one wants an understanding.
Finally, note that the interpretable and human level under- Here, the scientist is using the data, the transparency of the
standing of the performance of an ML approach can result method, and its interpretation to explain the output results (or
in a different choice of the ML model, algorithm, or data the data) using domain knowledge and thereby to obtain a
pre-processing later on. scientific outcome.
Furthermore, we suggest differentiating between scien-
C. EXPLAINABILITY
tific explanations and algorithmic explanations. For scientific
While research into explainable ML is widely recognized as explanations, [30] identifies five broad categories to classify
important, a joint understanding of the concept of explain- the large majority of objects that are explained in science:
ability still needs to evolve. Concerning explanations, it has data, entities, kinds, models, and theories. Furthermore, it is
also been argued that there is a gap of expectations between observed that the existence of a unifying general account
ML and so-called explanation sciences such as law, cognitive of scientific explanation remains an open question. With an
science, philosophy, and the social sciences [28]. algorithmic explanation, one aims to reveal underlying causes
While in philosophy and psychology explanations have to the decision of an ML method. This is what explainable ML
been the focus for a long time, a concise definition is not aims to address. In recent years, a focus on applying interpre-
available. For example, explanations can differ in complete- tation tools to better explain the output of an ML model can
ness or the degree of causality. We suggest to follow a model be observed. This can be seen in contrast to symbolic AI tech-
from a recent review relating insights from the social sciences niques, e.g., expert or planning systems, which in contrast are
to explanations in AI [29], which places explanatory ques- often seen as explainable per se. Hybrid systems of both sym-
tions into three classes: (1) what–questions, such as ‘‘What bolic and, so-called, connectionist AI, e.g., artificial NNs, are
event happened?’’; (2) how–questions, such as ‘‘How did that investigated to combine advantages from both approaches.
event happen?’’; and (3) why–questions, such as ‘‘Why did For example, [31] proposes ‘‘object-oriented deep learning’’
that event happen?’’. From the field of explainable AI we with the goal to convert a NN to a symbolic description to
consider a definition from [10]: gain interpretability and explainability. They state that gen-
An explanation is the collection of features of the erally in NNs, there is inherently no explicit representation
interpretable domain, that have contributed for a of symbolic concepts like objects or events, but rather a
given example to produce a decision (e.g., classifi- feature-oriented representation, which is difficult to explain.
cation or regression). In their representation, objects could be formulated to have
VOLUME 8, 2020 42203R. Roscher et al.: Explainable ML for Scientific Insights and Discoveries
disentangled and interpretable properties. Although not com- For the purpose of this article, we follow [2], who arrange
monly used so far, their work is one example of a promising different types of knowledge along their degree of formality,
direction towards a higher explainability of models. from the sciences, over (engineering or production) process
In the broader context, other properties that can be rel- flow to world knowledge and finally individual (expert’s)
evant when considering explainability of ML algorithms intuition. Knowledge can be assigned to several of the types
are safety/trust, accountability, reproducibility, transferabil- in this incomplete list.
ity, robustness and multi-objective trade-off or mismatched In the sciences, knowledge is often given in terms of mathe-
objectives, see e.g. [6], [9]. For example, in societal contexts, matical equations, such as analytic expressions or differential
reasons for a decision often matter. Typical examples are equations, or as relations between instances and/or classes in
(semi-)automatic loan applications, hiring decisions, or risk the form of rules or constraints. Its representation can, for
assessment for insurance applicants, where one wants to example, be in the form of ontologies, symmetries, or similar-
know why a model gives a certain prediction and how one ity measures. Knowledge can also be exploited by numerical
might be affected by those decisions. In this context, and also simulations of models or through human interaction.
due to regulatory reasons, one goal is that decisions based As ingredients of an ML approach, one considers the
on ML models involve fair and ethical decision making. The training data, the hypothesis space, the training algorithm,
importance to give reasons for decisions of an ML algorithm and the final model. In each of these, one can incorporate
is also high for medical applications, where a motivation additional knowledge. Feature engineering is a common and
is the provision of trust in decisions such that patients are longstanding way to incorporate knowledge into the training
comfortable with the decision made. All this is supported by data, whereas using numerical simulations to generate (addi-
the General Data Protection Regulation, which contains new tional) training data is a modern phenomena. One common
rules regarding the use of personal information. One compo- way to integrate knowledge into the hypothesis space is by
nent of these rules can be summed up by the phrase ‘‘right choosing the structure of the model. Examples of this include
to an explanation’’ [32]. Finally, for ML models deployed for defining a specific architecture of a NN or by choosing a
decision-support and automation, in particular in potentially structure of probability distributions that observes existing
changing environments, an underlying assumption is that or non-existing links between variables. An example for the
robustness and reliability can be better understood, or more training phase is modifying the loss function according to
easily realized, if the model is interpretable [9]. additional knowledge, for example by adding a consistency
One should also observe that explanations can be used term. Finally, the obtained model can be put in relation to
to manipulate. For illustration, [33] distinguishes between existing knowledge, for example by checking known con-
the intuitive scientist, who seeks to make the most accu- straints for the predictions.
rate or otherwise optimal decision, and the intuitive lawyer,
who desires to justify a preselected conclusion. With that E. SCIENTIFIC CONSISTENCY
in mind, one often aims for human-centric explanations of
A fundamental prerequisite for generating reliable outcomes
black-box models. There are simple or purely algorithmic
for scientific applications is scientific consistency. This
explanations, e.g., based on emphasising relevant pixels in
means that the result obtained is plausible and consistent with
an image. In so-called slow judgements tasks, an explanation
existing scientific principles. The selection and formulation
might more easily enforce confirmation biases. For example,
of the scientific principles to be met is based on domain
using human-centric explanations as evaluation baselines can
knowledge, where the manner of integration is the core
be biased towards certain individuals. Further, a review of
research question in areas such as informed ML. In the chain
studies of experimental manipulations that require people
of Fig. 1, scientific consistency can be considered a priori at
to generate explanations or imagine scenarios indicates that
the model design stage or a posteriori by analysing the output
people express greater confidence in a possibility, although
results. As pointed out by [2], scientific consistency at the
false, when asked to generate explanations for it or imagine
design stage can be understood as the result of a regularization
the possibility [34].
effect, where various ways exist to restrict the solution space
D. DOMAIN KNOWLEDGE to scientifically consistent solutions. Reference [37] identi-
As outlined, domain knowledge is an essential part of explain- fies scientific consistency besides interpretability as one of
ability; it is also essential for treating small data scenarios or the five major challenges we need to tackle to successfully
for performance reasons. A taxonomy for the explicit inte- adopt deep learning approaches in the geosciences. Refer-
gration of knowledge into the ML pipeline, dubbed informed ence [35] underlines the importance of consistency by defin-
ML, is proposed by [2]. Three aspects are involved: ing it as an essential component to measure performance:
• type of knowledge, One of the overarching visions of [theory-guided
• representation and transformation of knowledge, and data science] is to include [. . . ] consistency as a
• integration of knowledge into the ML approach. critical component of model performance along
See also the related works of [35], who use the term theory- with training accuracy and model complexity.
guided data science, or physics-informed learning by [36]. This can be summarized in a simple way by the
42204 VOLUME 8, 2020R. Roscher et al.: Explainable ML for Scientific Insights and Discoveries
TABLE 1. Group 1 includes approaches without any means of interpretability. In Group 2, a first level of interpretability is added by employing domain
knowledge to design the models or explain the outcomes. Group 3 deals with specific tools included in the respective algorithms or applied to their
outputs to make them interpretable. Finally, Group 4 lists approaches where scientific insights are gained by explaining the machine learning model itself.
following revised objective of model performance models [2]. Besides the purpose of explainability, integrating
[. . . ]: Performance ∝ Accuracy + Simplicity + domain knowledge can help with model tractability and reg-
Consistency. ularization in scenarios where not enough data is available.
They discuss several ways to restrict the solution space to It might also increase the performance of a model or reduce
physically consistent solutions, by (1) designing the model computational time.
family, such as specific network architectures; (2) guiding In Table 1, we specify the four major groups and several
a learning algorithm using, e.g., specific initializations, con- subgroups in more detail. We expect that examples for addi-
straints, or (loss) regularizations; (3) refining the model out- tional subgroups can be found, but that will not affect our
put, e.g., using closed-form equations or model simulations; core observations. In particular, we distinguish between the
(4) formulating hybrid models of theory and ML, and (5) following components:
augmenting theory-based models using real data such as data Transparency We consider a model to be design-transparent
assimilation or calibration. if the model, or a part of it, was chosen for specific
Overall, the explicit restriction of the solution space to sci- reasons, usually due to knowledge from the application
entifically consistent and plausible solutions is not a require- domain. We call a model algorithmically transparent if
ment to achieve valuable scientific outcomes. Neglecting this the determination of the solution is obvious and trace-
restriction, however, means that a consistent and plausible able. In view of reproducible science, it is not surprising
solution cannot be guaranteed, even if an optimal result has that essentially all the examples we found can be con-
been achieved from a mathematical point of view. sidered to be model-transparent.
Interpretability We take a closer look at two types of inter-
III. SCIENTIFIC OUTCOMES FROM MACHINE LEARNING pretability. First, we consider model components, such
In this section, we review examples that use ML and strive for as neurons in a NN or obtained latent variables, to be
different levels of transparency, interpretability, or explain- interpretable if they are represented in a way that can
ability to produce scientific outcomes. To structure the dif- be further explained, e.g., with domain knowledge. Sec-
ferent ML chains following Fig. 1, we define common groups ond, the scientific outcome, i.e., the decision of the
and describe representative papers for each. The core ingre- model, can be interpreted using the input, e.g., by using
dient is the basic ML chain, in which a model is learned heatmaps.
from given input data and with a specific learning paradigm, Integration of domain knowledge We will look at several
yielding output results utilizing the learned model. In order ways in which domain knowledge can be integrated.
to derive a scientific outcome, either the output results or On the one hand, domain knowledge is needed to explain
the model is explained, where interpretability is the prereq- — either to explain the scientific outcome or to derive
uisite for explainability. Moreover, transparency is required scientific findings from the model or individual model
to explain a model. Generally, providing domain knowledge components. On the other hand, domain knowledge can
to an algorithm means to enhance the input data, model, be integrated to enforce scientifically plausible and con-
optimizer, output results, or any other part of the ML algo- sistent results. This can be done in different ways; cf. [2].
rithm by using information gained from domain insights Besides the integration of domain knowledge during the
such as laws of nature and chemical, biological, or physical learning process of the model, it can also be used for
VOLUME 8, 2020 42205R. Roscher et al.: Explainable ML for Scientific Insights and Discoveries
post-hoc checks, where the scientific plausibility and predicts the spread of diseases on barley plants in micro-
consistency of the results is checked and possibly invalid scopic hyperspectral images by generating highly probable
results are removed. image-based appearances over the course of several days.
The following collection of research works is a They use cycle-consistent generative adversarial networks to
non-exhaustive selection from the literature of the last few learn how an image will change from one day to the next or
years, where we aim to cover a broad range of usages of ML to the previous day, albeit without any biological parameters
with a variety of scientific outcomes. Furthermore, we focus involved. Reference [42] presents an approach for the design
on examples that utilize an extensive amount of scientific of new functional glasses that comprises the prediction of
domain knowledge from the natural sciences. Due to the characteristics relevant for manufacturing as well as end-use
recent uptake of NNs in the sciences, these tend to be the properties of glass. They utilize NNs to estimate the liquidus
dominating ML approach in current literature. Nonetheless, temperatures for various silicate compositions consisting of
many of the described ML workflows or the approaches to up to eight different components. Generally, the identification
integrate domain knowledge can be performed with other ML of an optimized composition of the silicates yielding a suit-
methods as well. Note that the choice of a group for a given able liquidus temperature is a costly task and is oftentimes
article is not always a clear judgement, particularly in view of based on trial-and-error. For this, they learn from several
how and where domain knowledge is employed, and in what hundred composites with known output properties and apply
form, and to what extent, an explanation is derived. the model to novel, unknown composites. In their workflow,
they also consider, outside of the ML chain, other quantities
of interest that are derived by physics-driven models. Refer-
A. SCIENTIFIC OUTCOMES BY EXPLAINING OUTPUT
ence [43] proposes a nonlinear regression approach employ-
RESULTS
ing NNs to learn closed form representations of partial differ-
Many works address the derivation of outcomes by learning ential equations (PDEs) from scattered data collected in space
an ML model and generalizing from known input-output and time, thereby uncovering the dynamic dependencies and
relations to new input-output pairs. This represents the lowest obtaining a model that can be subsequently used to forecast
degree of explainability without the need for a transparent future states. In benchmark studies, using Burgers’ equation,
or interpretable model. In the case that a scientifically use- nonlinear Schrödinger equation, or Navier-Stokes equation,
ful outcome is to be estimated, most of these approaches the underlying dynamics are learned from numerical simula-
so far solely explain what the outcome is from a scientific tion data up to a specific time. The obtained model is used
point of view (scientific explanation), but cannot answer the to forecast future states, where relative L2 -errors of up to
question of why this specific outcome was obtained from an the order of 10−3 are observed. While the method inherently
algorithmic point of view (algorithmic explanation). Other models the PDEs and the dynamics themselves, the rather
approaches attempt to scientifically explain the output in general network model does not allow the drawing of direct
terms of the specific corresponding input, given a learned scientific conclusions on the structure of the underlying pro-
model. Here, interpretation tools are utilized, where the cess.
model is used only as a means to an end to explain the result Group 1b: These models are not only model- but also
and it is not explicitly analyzed itself. design-transparent to some extent, where the design is chosen
and motivated with certain intentions.
1) PREDICTION OF INTUITIVE OUTCOMES Besides the simple prediction network presented by [39]
The derivation of intuitive physics is a task that is often con- in Group 1a, they also propose a network called PhysNet
sidered in papers from the following group. Intuitive physics to predict the trajectory of the wooden blocks in case the
are everyday-observed rules of nature that help us to predict tower is collapsing. It is formulated as a mask prediction net-
the outcome of events even with a relatively untrained human work trained for instance segmentation, where each wooden
perception [38]. block is defined as one class. The construction of Phys-
Group 1a (Basic ML Chain): A black-box approach, or at Net is made design-transparent in the sense that the net-
most model-transparent approach, is used to derive an out- work is constructed to capture the arrangement of blocks
come. It is not interpretable and cannot be explained. The by using alternating upsampling and convolution layers, and
outcome is not or only minimally explainable from a scientific an increased depth to reason about the block movement,
point of view. as well. PhysNet outperforms human subjects on synthetic
For example, [39] uses video simulations to learn intu- data and achieves comparable results on real data. Refer-
itive physics, e.g., about the stability of wooden block tow- ence [44] designed a multi-source NN for exoplanet tran-
ers. They use ResNet-34 and GoogLeNet and formulate a sit classification. They integrate additional information by
binary classification task to predict whether these towers adding identical information about centroid time-series data
will fall. In a similar way, but with more complex scenes to all input sources, which is assumed to help the network
or differently shaped objects, [40] predicts the physical sta- learn important connections, and by concatenating the output
bility of stacked objects using various popular convolu- of a hidden layer with stellar parameters, as it is assumed they
tional neural network (CNN) architectures. Reference [41] are correlated with classification. Reference [45] introduces a
42206 VOLUME 8, 2020R. Roscher et al.: Explainable ML for Scientific Insights and Discoveries
framework that calculates physical concepts from color-depth reasoning. Like a layman in the corresponding scientific field,
videos that estimates tool and tool-use such as cracking a the methods presented so far do not learn a model that is able
nut. In their work, they learn task-oriented representations to capture and derive scientific properties and dynamics of
for each tool and task combination defined over a graph phenomena or objects and their environment, as well as their
with spatial, temporal, and causal relations. They distinguish interactions. Therefore, the model cannot inherently explain
between 13 physical concepts, e.g., painting a wall, and why an outcome was obtained from a scientific viewpoint.
show that the framework is able to generalize from known to Reference [52] labels these respective approaches as bottom-
unseen concepts by selecting appropriate tools and tool-uses. up, where observations are directly mapped to an estimate
A hybrid approach is presented by [46] to successfully model of some behavior or some outcome of a scenario. To tackle
the properties of contaminant dispersion in soil. The authors the challenge of achieving a higher explainability and a better
extract temporal information from dynamic data using a long scientific usability, several so-called top-down classification
short-term memory network and combine it with static data in and regression frameworks have been formulated that infer
a NN. In this way, the network models the spatial correlations scientific parameters. In both cases, only the scientific expla-
underlying the dispersion model, which are independent of nation is sought.
the location of the contaminant. Reference [47] has proposed Group 2a: In these ML models, domain knowledge is incor-
a data-centric approach for scientific design based on the porated, often to enforce scientific consistency. Therefore,
combination of a generative model for the data being con- the design process is partly transparent and tailored to the
sidered, e.g., an autoencoder trained on genomes or proteins, application. The outcome is explainable from a scientific
and a predictive model for a quantity or property of interest, point of view since scientific parameters and properties are
e.g., disease indicators or protein fluorescence. For DNA derived, which can be used for further processing.
sequence design, these two components are integrated by For example, [53] detects and tracks objects in videos in
applying the predictive model to samples from the generative an unsupervised way. The authors use a regression CNN and
model. In this way, it is possible to generate new synthetic introduce terms during training that measure the consistency
data samples that optimize the value of the quantity or prop- of the output when compared to physical laws which specif-
erty by leveraging an adaptive sampling technique over the ically and thoroughly describe the dynamics in the video.
generative model; see also [48]. In this case, the input of the regression network is a video
Group 1c: Here, in addition to Group 1b, the design sequence and the output is a time-series of physical parame-
process is influenced by domain knowledge regarding the ters such as the height of a thrown object. By incorporating
model, the cost function, or the feature generation process domain knowledge and image properties into their loss func-
with the particular aim to enhance scientific consistency and tions, part of their design process becomes transparent and
plausibility. explainability is gained due to comparisons to the underlying
For example, [49], [50] use physics-informed approaches physical process. However, the model and the algorithms
for applications such as fluid simulations based on the incom- are not completely transparent since standard CNNs with an
pressible Navier-Stokes equations, where physics-based ADAM minimizer are employed. Although these choices of
losses are introduced to achieve plausible results. The idea model and algorithms are common in ML, they are usually
in [49] is to use a transparent cost function design by refor- motivated by their good performance, and not because there
mulating the condition of divergence-free velocity fields into is any application-driven reasoning behind it; thus, there is no
an unsupervised learning problem at each time step. The design transparency on this aspect. Furthermore, the reason
random forest model used in [50] to predict a fluid particle’s why such choice works for this highly nonconvex problem
velocity can be viewed as a transparent choice per se due is currently not well understood from a mathematical point
to its simple nature. Reference [51] classifies land use and of view; therefore, no algorithmic transparency is present.
land cover and their changes based on remote sensing satellite Reference [54] introduces Physics101, a dataset of over
timeseries data. They integrate domain knowledge about the 17,000 video clips containing 101 objects of different char-
transition of specific land use and land cover classes, such as acteristics, which was built for the task of deriving physical
forest or burnt areas, to increase the classification accuracy. parameters such as velocity and mass. In their work, they
They utilize a discriminative random field with transition use the LeNet CNN architecture to capture visual as well as
matrices that contain the likelihoods of land cover and land physical characteristics while explicitly integrating physical
use changes to enforce, for example, that a transition from laws based on material and volume to aim for scientific
burnt area to forest is unlikely. consistency. Their experiments show that predictions can be
made about the behavior of an object after a fall or a collision
2) PREDICTION OF SCIENTIFIC PARAMETERS AND using estimated physical characteristics, which serve as input
PROPERTIES to an independent physical simulation model. Reference [55]
Although the approaches just described set up prediction as a introduces SMASH, which extracts physical collision param-
supervised learning problem, there is still a gap between com- eters from videos of colliding objects, such as pre- and
mon supervised tasks, e.g., classification, object detection, post collision velocities, to use them as inputs for existing
and prediction, and actual understanding of a scene and its physics engines for modifications. For this, they estimate the
VOLUME 8, 2020 42207R. Roscher et al.: Explainable ML for Scientific Insights and Discoveries position and orientation of objects in videos using constrained were used to learn the deviation of properties calculated least-squares estimation in compliance with physical laws by computational models from the experimental analogues. such as momentum conservation. Based on the determined By employing the chemical Tanimoto similarity measure and trajectories, parameters such as velocities can be derived. building a prior based on experimental observations, design While their approach is based more on statistical parameter transparency is attained. Furthermore, since the prediction estimation than ML, their model and algorithm building pro- results involves a confidence in each calibration point being cess is completely transparent. Individual outcomes become returned, the user can be informed when the scheme is being explainable due to the direct relation of the computations to used for systems for which it is not suited [59]. In [60], the underlying physical laws. 838 high-performing candidate molecules have been identi- Reference [56] introduces Newtonian NNs in order to fied within the explored molecular space thanks to the newly predict the long-term motion of objects from a single color possible efficient screening of over 51,000 molecules. image. Instead of predicting physical parameters from the In [61], a data-driven algorithm for learning the coef- image, they introduce 12 Newtonian scenarios serving as ficients of general parametric linear differential equations physical abstractions, where each scenario is defined by phys- from noisy data was introduced, solving a so-called inverse ical parameters defining the dynamics. The image, which problem. The approach employs GP priors that are tailored to contains the object of interest, is mapped to a state in one the corresponding and known type of differential operators, of these scenarios that best describes the current dynamics resulting in design and algorithmic transparency. The combi- in the image. Newtonian NNs are two parallel CNNs: one nation of rather generic ML models with domain knowledge encodes the images, while the other derives convolutional in the form of the structure of the underlying differential filters from videos acquired with a game engine simulating equations leads to an efficient method. Besides classical each of the 12 Newtonian scenarios. The specific coupling benchmark problems with different attributes, the approach of both CNNs in the end leads to an interpretable approach, was used on an example application in functional genomics, which also (partially) allows for explaining the classification determining the structure and dynamics of genetic networks results of a single input image. based on real expression data. A tensor-based approach to ML for uncertainty quantifi- Group 2c: These ML models are similar to the models cation problems can be found in [57], where the solutions to in Group 2a, but besides enforced scientific consistency parametric convection-diffusion PDEs are learned based on a and plausibility of the explainable outcome, an additional few samples. Rather than directly aiming for interpretability post-hoc consistency check is performed. or explainability, this approach helps to speed up the pro- In [62], a deep learning approach for Reynolds-averaged cess of gaining scientific insight by computing physically Navier-Stokes (RANS) turbulence modelling was presented. relevant quantities of interest from the solution space of Here, domain knowledge led to the construction of a network the PDE. As there are convergence bounds for some cases, architecture that embedded invariance using a higher-order the design process is to some extent transparent and benefits multiplicative layer. This was shown to result in significantly from domain knowledge. more accurate predictions compared to a generic, but less An information-based ML approach using NNs to solve interpretable, NN architecture. Further, the improved predic- an inverse problem in biomechanical applications was pre- tion on a test case that had a different geometry than any of sented in [58]. Here, in mechanical property imaging of soft the training cases indicates that improved RANS predictions biological media under quasi-static loads, elasticity imag- for more than just interpolation situations seem achievable. ing parameters are computed from estimated stresses and A related approach for RANS-modeled Reynolds stresses for strains. For a transparent design of the ML approach, domain high-speed flat-plate turbulent boundary layers was presented knowledge is incorporated in two ways. First, NNs for a in [63], which uses a systematic approach with basis tensor material model are pre-trained with stress-strain data, gen- invariants proposed by [64]. Additionally, a metric of pre- erated using linear-elastic equations, to avoid non-physical diction confidence and a nonlinear dimensionality reduction behavior. Second, finite-element analysis is used to model the technique are employed to provide a priori assessment of the data acquisition process. prediction confidence. Group 2b: These ML models are highly transparent, which means that the design process as well as the algorithmic 3) INTERPRETATION TOOLS FOR SCIENTIFIC OUTCOMES components are fully accessible. The outcome of the model Commonly used feature selection and extraction methods is explainable and the scientific consistency of the outcome is enhance the interpretability of the input data, and thus can enforced. lead to outcomes that can be explained by interpretable input. For organic photovoltaics material, an approach utilizing Other approaches use interpretation tools to extract infor- quantum chemistry calculations and ML techniques to cali- mation from learned models and to help to scientifically brate theoretical results to experimental data was presented explain the individual output or several outputs jointly. Often, by [59], [60]. The authors consider previously performed approaches are undertaken to present this information via experiments as current knowledge, which is embedded within feature importance plots, visualizations of learned represen- a probabilistic non-parametric mapping. In particular, GPs tations, natural language representations, or the discussion of 42208 VOLUME 8, 2020
R. Roscher et al.: Explainable ML for Scientific Insights and Discoveries examples. Nonetheless, human interaction is still required to the biomarkers themselves are also ‘‘surrogates’’ of the opti- interpret this additional information, which has to be derived mal descriptors [68], [69]. The biomarker design promotes ante-hoc or with help of the learned model during a post-hoc spatially compact pixel selections, producing biomarkers for analysis. disease prediction that are focused on regions of the brain. Group 3a: These ML approaches use interpretation tools These are then assessed by expert physicians. As the analysis to explain the outcome by means of an interpretable repre- is based on high-dimensional linear regression approaches, sentation of the input. Such tools include feature importance transparency of the ML model is assured. Reference [70] plots or heatmaps. introduces DeepTune, a visualization framework for CNNs, While handcrafted and manually selected features are typi- for applications in neuroscience. DeepTune consists of an cally easier to understand, automatically determined features ensemble of CNNs that learn multiple complementary repre- can reveal previously unknown scientific attributes and struc- sentations of natural images. The features from these CNNs tures. Reference [65], for example, proposes FINE (feature are fed into regression models to predict the firing rates of importance in nonlinear embeddings) for the analysis of neurons in the visual cortex. The interpretable DeepTune cancer patterns in breast cancer tissue slides. This approach images, i.e., representative images of the visual stimuli for relates original and automatically derived features to each each neuron, are generated from an optimization process and other by estimating the relative contributions of the original pooling over all ensemble members. features to the reduced-dimensionality manifold. This proce- Classical tools such as confusion matrices are also used dure can be combined with various, possibly intransparent, as interpretation tools on the way to scientific outcomes. nonlinear dimensionality reduction techniques. Due to the In a bio-acoustic application for the recognition of anurans feature contribution detection, the resulting scheme remains using acoustic sensors, [71] uses a hierarchical approach to interpretable. jointly classify on three taxonomic levels, namely the fam- Arguably, visualizations are one of the most widely used ily, the genus, and the species. Investigating the confusion interpretation tools. Reference [21] gives a survey of visual matrix per level enabled for example the identification of analytics in deep learning research, where such visualization bio-acoustic similarities between different species. systems have been developed to support model explanation, Group 3b: These models are design-transparent in the interpretation, debugging, and improvement. The main con- sense that they use specially tailored components such as sumers of these analytics are the model developers and users attention modules to achieve increased interpretability. The as well as non-experts. Reference [66] uses interpretation output is explained by the input using the specially selected tools for image-based plant stress phenotyping. The authors components. train a CNN model and identify the most important feature In [72], [73] attention-based NN models are employed to maps in various layers that isolate the visual cues for stress classify and segment histological images, e.g., microscopic and disease symptoms. They produce so-called explanation tissue images, magnetic resonance imaging (MRI), or com- maps as sums of the most important features maps indicated puted tomography (CT) scans. Reference [72] found that the by their activation level. A comparison of manually marked employed modules turned out to be very attentive to regions visual cues by an expert and the automatically derived expla- of pathological, cancerous tissue and non-attentive in other nation maps reveals a high level of agreement between the regions. Furthermore, [73] builds an attentive gated network automatic approach and human ratings. The goals of their that gradually fitted its attention weights with respect to approach are the analysis of the performance of their model, targeted organ boundaries in segmenting tasks. The authors the provision of visual cues that are human-interpretable to also used their attention maps to employ a weakly super- support the prediction of the system, and a provision of vised object detection algorithm, which successfully created important cues for the identification of plant stress. Ref- bounding boxes for different organs. erences [39] and [67] use attention heatmaps to visualize Interpretability methods have also been used for applica- the stackability of multiple wooden blocks in images. They tions that utilize time-series data, often by way of highlighting conduct a conclusion study by applying localized blurring features of the sequence data. For example, [74] applies to the image and collecting the resulting changes in the attention modules in NNs trained on genomic sequences for stability classification of the wooden blocks into a heatmap. the identification of important sequence motifs by visualizing Moreover, [67] provides a first step towards a physics-aware the attention mask weights. They propose a genetic archi- model by using their trained stability predictor and heatmap tect that finds a suitable network architecture by iteratively analysis to provide stackability scores for unseen object sets, searching over various NN building blocks. In particular, for the estimation of an optimal placement of blocks, and to they state that the choice of the NN architecture highly counterbalance instabilities by placing additional objects on depends on the application domain, which is a challenge if top of unstable stacks. no prior knowledge is available about the network design. As another example, ML has been applied to functional It is cautioned that, depending on the optimized architec- magnetic resonance imaging data to design biomarkers that ture, attention modules and expert knowledge may lead to are predictive of psychiatric disorders. However, only ‘‘sur- different scientific insights. Reference [75] uses attention rogate’’ labels are available, e.g., behavioral scores, and so modules for genomics in their AttentiveChrome NN. The VOLUME 8, 2020 42209
You can also read

















































