Go Figure! A Meta Evaluation of Factuality in Summarization
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Go Figure! A Meta Evaluation of Factuality in Summarization
Saadia Gabriel♠ Asli Celikyilmaz♣ Rahul Jha♣ Yejin Choi♠♦ Jianfeng Gao ♣
♠
Paul G. Allen School of Computer Science & Engineering, University of Washington
♣
Microsoft Research
♦
Allen Institute for Artificial Intelligence
{skgabrie,yejin}@cs.washington.edu
{aslicel,rajh,jfgao}@microsoft.com
Abstract
Text generation models can generate factually
inconsistent text containing distorted or fabri-
arXiv:2010.12834v1 [cs.CL] 24 Oct 2020
cated facts about the source text. Recent work
has focused on building evaluation models to
verify the factual correctness of semantically
constrained text generation tasks such as docu-
ment summarization. While the field of factu-
ality evaluation is growing fast, we don’t have
well-defined criteria for measuring the effec-
tiveness, generalizability, reliability, or sensi-
tivity of the factuality metrics. Focusing on
these aspects, in this paper, we introduce a
meta-evaluation framework for evaluating fac-
tual consistency metrics. We introduce five
necessary, common-sense conditions for ef-
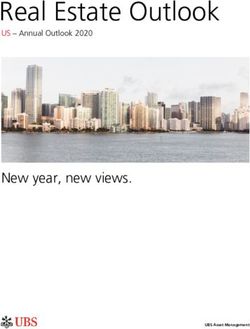
Figure 1: Example of a ground-truth CNN/DailyMail sum-
fective factuality metrics and experiment with mary and transformed summary where key spans of the
nine recent factuality metrics using synthetic ground-truth summary (highlighted in green) contain factual
and human-labeled factuality data from short errors (highlighted in red). Even though the transformed
news, long news and dialogue summarization summary is less factual, the commonly used ROUGE summa-
rization metric assigns higher values to that summary over the
domains. Our framework enables assessing
ground-truth summary when we compare against the original
the efficiency of any new factual consistency article as a reference.
metric on a variety of dimensions over mul-
tiple summarization domains and can be eas-
ily extended with new meta-evaluation criteria. with up to 30% factual inconsistencies (Kryscinski
We also present our conclusions towards stan- et al., 2019; Falke et al., 2019a; Zhu et al., 2020).
dardizing the factuality evaluation metrics. Commonly used metrics for measuring quality
of generated text fail to capture structural aspects
1 Introduction
of language and poorly correlate with human judge-
The goal of text generation systems is to produce ments (Hashimoto et al., 2019; Clark et al., 2019).
text that is fluent, coherent, relevant, as well as As shown by Figure 1, simple transformations like
factually correct. Recent progress in neural ap- copying filler terms from the source text and intro-
proaches to building semantically constraint text ducing logical negations to transform a factually
generation systems has shown tremendous improve- grounded summary into a factually inconsistent
ments in this direction (Liu and Lapata, 2019; Guo summary can lead to a higher ROUGE score for
et al., 2018; Durmus et al., 2020; Wang et al., 2020). the less factual summary when we compare the
However, an important issue in text generation sys- candidate summaries against the original source
tems is that they can yield factually inconsistent document.
text, caused by somewhat distorted or fabricated The last few years has observed an increase in
facts about the source text. Especially in document research papers on factual consistency evaluation
summarization tasks, the models that abstract away metrics due to these reasons. A number of metrics
salient aspects, have been shown to generate text have been proposed for measuring factuality viaproxy objectives like question-answering (QA) and 2 Factuality Metric Meta Evaluation
facet overlap (Scialom et al., 2019; Durmus et al.,
2020; Mao et al., 2020), raising a number of new Since reference summaries may be an incomplete
research questions including: “Do these metrics representation of the salient facts3 in a source doc-
capture multiple aspects and dimensions of factu- ument or unavailable, we consider factuality in
ality in summarization?” and “Do these metrics terms of how well candidate summaries are factu-
capture factuality across a broader spectrum of ally grounded with respect to the source document
domains?” It is unclear which of these metrics are rather than reference summaries. We also assume
suitable for evaluating the types of text generation that source documents are factually valid, without
methods. We think that answering these questions the use of external sources or databases for fact ver-
is key to determining the usability and effectiveness ification. We define a summary as having factual
of recent factuality metrics, especially when con- inconsistency level i if there are i errors present (i.e.
sidering previously under-explored summarization a summary with no errors will have a factual incon-
domains like dialogue summarization. sistency level 0, a summary with 1 error will have
In this work, we propose the first evalua- an inconsistency level 1, etc).4 In section 2.1, we
tion framework, GO-FIGURE1 , a meta-evaluation propose a set of necessary conditions for defining
framework for assessing the effectiveness of fac- an effective factuality metric including theoretical
tuality metrics across multiple dimensions and constraints on metric values and commonsense con-
domains - extreme news summarization, multi- ditions. In sections 3.2.1 and 3.2.2 we describe the
sentence news summarization, and dialogue sum- construction of diagnostic datasets to test these con-
marization.2 While most of the prior work in fac- ditions in both a simulated and generated setting.
tual consistency concentrated on one dataset and In section 2.2 we elaborate on how the conditions
domain, our framework allows us to test the ro- defined by our framework can be practically ap-
bustness and accuracy of proposed metrics for eval- plied to measure sensitivity of metrics to changes
uating factual consistency across domains to de- in factuality.
termine if metrics truly generalize. We primarily
2.1 How do we define a “good” factuality
focus on summarization rather than open-ended
metric?
generation, since the source document provides a
natural grounding for factuality. We define a set of five conditions for a text genera-
Our contributions are as follows: (i) a set of di- tion metric M (D, Si ) that can effectively measure
agnostics for measuring sensitivity of metrics to factual consistency of a summary Si with respect
different levels of factual inconsistency (i.e. are to a source document D:
there statistically significant differences between Boundedness (Condition I). We define this for-
metric results for less factual generations vs. more mally such that if Sf is a completely factual sum-
factual generations?), as well as sensitivity of met- mary and Sr is a completely factually inconsistent
rics to types of factual errors (i.e. which lexical and summary,5 we expect that
semantic changes do metrics better capture?), (ii)
a synthetic evaluation dataset of context/summary M (D, Sr ) ≤ M (D, Si ) ≤ M (D, Sf ). (1)
pairs from three summarization domains for mea-
suring effectiveness of new factuality metrics. The In other words, the metric values should be
evaluation dataset contains different levels of in- reasonably bounded and these bounds should
jected factual errors to simulate errors made by relate to the factuality of candidate summaries.
generation models, and finally (iii) an evaluation
dataset of summaries generated by transformer- 3
Following Kryscinski et al. (2019), we define facts as
based models (Raffel et al., 2019; Rothe et al., salient spans in a source document, i.e. spans of text high-
2019) annotated with types of factual errors. This lighting key information pertaining to entities in the source
documents, actions that were performed, statistical reporting,
provides a test-bed capturing the real distribution etc. These spans either support or refute claims in summaries.
of errors made by generation models. 4
For the simulated data, it is not always possible to intro-
duce i errors (See section 3.2.1). In this case, i is the maximum
1
General Outline for Factuality In Generative number of errors.
UndeRstanding Evaluation. 5
We define a summary that is completely factually incon-
2
We will publicly release code for our evaluation frame- sistent as a summary that contains no facts that overlap with
work and diagnostic datasets soon. the facts in the source document.Stat XSUM CNNDM SAMSUMM
Avg #Words (summ/source) 22.06/393.72 63.41/758.13 20.72/94.61
Avg #Entities (summ/source) 2.82/40.87 6.63/51.75 3.76/10.6
Avg #Pronoun words (summ/source) 0.43/13.16 2.09/30.55 0.94/7.45
Avg #Verbs (summ/source) 2.49/46.75 7.65/84.39 2.99/10.75
Avg #Adjectives (summ/source) 1.44/27.56 3.55/46.13 1.01/4.85
Table 1: Dataset statistics for summaries (summ) and source documents (source) in the evaluation sets. Corresponding values
for summaries are given on the left and values for source documents are given on the right.
Sensitivity (Condition II). We define fac- factually consistent than a summary Sj , then we
tual inconsistency level as a measure that indicate expect that
the differences between metric results, e.g.,
between less factual generations vs. more factual H(D, Si ) ≥ H(D, Sj ). (3)
generations. We calculate the sensitivity score
for a given metric based on the magnitude of where, H is the human judgement score on factu-
the slope of the best-fit line between the factual ality. In other words, the metric should correlate
inconsistency level and average metric values (i.e. with human judgements of factuality.
the estimated rate at which metric values change
with the level of factual inconsistency): 2.2 Testing Factuality Metric Validity
PL
(i − L̄)(M̄i − M̄ ) For the purposes of testing boundedness (Condition
Sensitivity = | i=0PL | (2) I), we define the Lower Bound for a metric M as
2
i=0 (i − L̄)
M (D, Sr ) where D is the source document and
In Eq. (2), L is the maximum error level, L̄ is the Sr is a randomly sampled summary from the cor-
average error level, M̄i is the average value for the pus. We define the Upper Bound for the metric as
metric at error level i and M̄ is the average value M (D, Sf ), where Sf is the reference ground-truth
for the metric across all error levels. summary.
If a metric is sensitive to changes in factuality, it To test sensitivity (Condition II), we report sen-
should hold that there is a statistically significant sitivity score (Eq. 2) and measure whether the
difference between M̄i and M̄i+1 . differences between metric results are different for
various levels of factual inconsistency, and whether
Robustness (Condition III). The metric these differences are statistically significant. For
should be robust to types of factual errors, i.e. this test, we measure the correlation (Pearson’s r)
it should be able to capture both intrinsic entity between the factual inconsistency level of the sum-
errors and other types of factual errors like pronoun maries (i.e. the number of injected errors) and the
errors. See Table 3 for a list of some factual error average metric score. Then we measure statistical
types we consider. significance using the p-value from a two-tailed
hypothesis test. We check whether metrics satisfy
Generality (Condition IV). The metric robustness and generality (Conditions III and IV)
should be generalizable across domains, i.e. if by separately running this analysis over multiple
it satisfies the previously defined conditions on factual error types and domains/tasks. We measure
a domain A, it is expected that it also satisfies commonsense by checking the correlation between
these conditions on a domain B. We acknowledge factual consistency levels determined using manual
there will likely be corner cases for which this annotation and metric values.
is not true for any metric as well as domains for
which factuality itself is difficult to define (story 3 Evaluation Datasets
generation, for example), so we only consider the
domains for which factual consistency evaluation We evaluate the factual consistency metrics on two
is most obviously applicable. categories of datasets: (i) available summariza-
tion datasets on varying domains, (ii) diagnostic
Commonsense (Condition V). If human datasets that are both simulated to evaluate different
annotators judge a summary Si to be more levels of factuality and model generated datasets.Dataset Train Dev Test Domain 3.2 Diagnostic Datasets
XSUM 204,045 11,332 11,334 Short news
CNNDM 287,227 13,368 11,490 Long news To test the ability of proposed metrics to fulfill
SAMSUM 14,732 818 819 Dialogues our predefined conditions, we set up two diagnos-
tic datasets consisting of (i) transformed reference
Table 2: Summarization domains for evaluation. summaries with simulated factuality errors that al-
low us to induce and measure factual consistency
in a controlled setting and (ii) summaries generated
3.1 Summarization Datasets by state-of-the-art transformer summarization mod-
els that allows us to measure the effectiveness of
In this work we consider summarization domains
metrics in a real data setting.
to cover a broad range of topics, lengths of ground-
truth summaries and levels of abstractiveness. In
particular, we focus on accurately measuring fac- 3.2.1 Simulated Datasets
tuality in the context of news and dialogue sum-
For each of the considered domains in section 3.1,
marization, which is key for preventing spread of
we sample 500 source document / reference sum-
misinformation in two different domains. For ex-
mary pairs. We then inject simulated factual errors
ample, in dialog summarization, it is important
into the reference summaries based on randomly se-
that a machine-generated summary of an exchange
lecting entities, including pronoun words, or verbs
between a politician and a reporter at a press confer-
and adjectives to induce a desired level of factual
ence is factually consistent, and doesn’t hallucinate
inconsistency. We define the full list of errors we
details about what was said. We considered the
inject using transformations in Table 3.6
following three summarization domains (see Table
2 for dataset statistics): We notice that some transformations did not pro-
Short News. To test the ability of metrics to mea- duce any change in the reference summary due to a
sure factuality in the extreme news summarization lack of lexical features that can be changed (See Ta-
domain, we use the XSUM dataset (Narayan et al., ble 1 for the distribution of the entity words, verbs
2018) which contains over 200k BBC news articles and adjectives). For example, the XSUM reference
paired with 1-sentence summaries. summary “Warm, humorous, gutsy, sparky, soul-
ful, determined and fun.” contains no entities or
Long News. We also test metrics on longer multi-
verbs that can be transformed. In addition, some
sentence summaries from the CNN/DailyMail
transformations may have more of an effect on
dataset (Nallapati et al., 2016), which tend to be
factuality than others (e.g. for the XSUM sum-
more extractive than summaries in XSUM dataset.
mary “You may know Bob best as the paramedic
Dialogues. In contrast to news, dialogue summa- Finlay Newton in the BBC’s Casualty,” exchang-
rization resources are relatively scarce. We use the ing “Idris” for “Bob” would change a smaller ratio
recently released SAMSUM corpus (Gliwa et al., of the summary content words than exchanging
2019) to test metrics on dialogue summarization. “Idris” for “Finlay Newton”). Due to these reasons,
SAMSUM consists of English language conver- we generate five different versions of each set of
sations written by linguists in the style of chat our diagnostic data when randomly selecting refer-
messenger dialogues and aligned multi-sentence ence summary transformations and assessing the
summaries. aggregated results (See Table 4 for the distribution
Compared to CNN/DailyMail dataset, XSUM of errors).
is considered more abstractive based on the pro-
We control the factuality of transformed sum-
portion of the novel n-grams in gold summaries
maries by setting the maximum number of random
in comparison to the source documents (Narayan
transformations to 1, 2, or 3 injected errors, rep-
et al., 2018). Compared to structured news docu-
resenting three different levels of factual inconsis-
ments, the SAMSUM dialog dataset is unstructured
tency for sensitivity evaluations (Condition II).
and contains chats between varying interlucators
and the text is first-person directed speech, while
6
the summaries are written in third-person point of See the Appendix for details. For verb negation, we focus
on simple negations using “not” (e.g. “I agree” → “I do not
view, which makes them highly abstractive in na- agree,” rather than more complex negation (e.g. “I agree” →
ture. “I disagree” or “I agree” → “I beg to differ” ).Reference Type Description Example
Irish Taoiseach (PM) Leo Varadkar has engaged in An entity appearing in the Canadian Taoiseach (PM) Leo Varadkar has engaged in
some “sock diplomacy” in his first meeting with Intrinsic entity error source document is used some “sock diplomacy” in his first meeting with
Canadian Prime Minister Justin Trudeau in Dublin. (int) incorrectly. Irish Prime Minister Justin Trudeau in Dublin.
Irish Taoiseach (PM) Leo Varadkar has engaged in An entity appearing in French Taoiseach (PM) Leo Varadkar has engaged in
some “sock diplomacy” in his first meeting with Extrinsic entity error the candidate summary does some “sock diplomacy” in his first meeting with
Canadian Prime Minister Justin Trudeau in Dublin. (ext) not appear in the source document. Canadian Prime Minister Justin Trudeau in Dublin.
Irish Taoiseach (PM) Leo Varadkar has engaged in A pronoun in the candidate summary Irish Taoiseach (PM) Leo Varadkar has engaged in
some “sock diplomacy” in his first meeting with Pronoun error is used incorrectly. some “sock diplomacy” in her first meeting with
Canadian Prime Minister Justin Trudeau in Dublin. (pro) For example, (her/she instead of him/he). Canadian Prime Minister Justin Trudeau in Dublin.
Irish Taoiseach (PM) Leo Varadkar has engaged in There are verb negations in Irish Taoiseach (PM) Leo Varadkar has not engaged in
some “sock diplomacy” in his first meeting with Negation error the candidate summary that some “sock diplomacy” in his first meeting with
Canadian Prime Minister Justin Trudeau in Dublin. (verb) contradict the source document. Canadian Prime Minister Justin Trudeau in Dublin.
Irish Taoiseach (PM) Leo Varadkar has engaged in An adjective or adverb appearing Irish Taoiseach (PM) Leo Varadkar will engage in
People who have been prescribed powerful anxiety Sentiment error in the candidate summary People who have been prescribed weak anxiety
or pain relief drugs are being warned about a new (sent) contradicts the source document. or pain relief drugs are being warned about a new
drug-driving law. drug-driving law.
Table 3: Table of possible factual errors.
Dataset Level 1 Avg. Level 2 Avg. Level 3 Avg. Avg. % Transformed
(L1/L2/L3/All)
XSUM (Entity) 0.59 1.14 1.61 58.84 / 76.44 / 86.28 / 73.85
XSUM (Non-Entity) 0.48 0.93 1.28 48.32 / 74.00 / 85.40 / 69.24
CNNDM (Entity) 0.75 1.48 2.17 74.92 / 85.68 / 94.48 / 85.03
CNNDM (Non-Entity) 0.50 1.05 1.62 79.44 / 93.32 / 97.04 / 89.93
SAMSUM (Entity) 0.59 1.16 1.70 58.96 / 77.32 / 87.56 / 74.61
SAMSUM (Non-Entity) 0.49 0.91 1.28 48.52 / 72.80 / 84.12 / 68.48
Table 4: Analysis of simulated diagnostic dataset (we average across 5 different sets (runs) of randomized transformations
for the same 500 reference summaries). We provide results for the average number of induced factuality errors for factual
inconsistency level 1 (L1), level 2 (L2) and level 3 (L3), as well as the percentage (%) of summaries that were transformed for
each level and across all levels (All). We split the diagnostic dataset into two subsets based on whether simulated errors are
related to entities (Entity) or non-entity changes like verb negation (Non-Entity).
3.2.2 Model-Generated Datasets proving coherency rather than factual consistency
To assess the performance of various metrics on (e.g. BERTScore (Zhang et al., 2020) and BLEURT
actual generated text, we use a version of the (Sellam et al., 2020)), and standard summarization
T5 encoder-decoder summarization model (Raf- evaluation metrics (e.g. ROUGE (Lin, 2004)). The
fel et al., 2019) that was pretrained on news sum- following is the list of metrics we used for factual
marization data and generate summary text using consistency evaluation:
either greedy decoding, beam search or a sample- QA-Based Quality Score. Given a source or
based decoding strategy like top-k (Fan et al., 2018) reference document D and candidate summary Si ,
and Nucleus sampling (Holtzman et al., 2020). We QA-based evaluation metrics assign a generation
conduct a fine-grained human evaluation of fac- quality score to Si to measure the ability of a QA
tuality over generated summaries to assess effec- system by accurately answering questions gener-
tiveness of our sensitivity analysis at highlighting ated from D or Si . We use the SummaQA (Scialom
metric strengths and weaknesses for generated sum- et al., 2019) and FEQA (Durmus et al., 2020) met-
maries (See section 5.2). rics. For the SummaQA metric, questions are gen-
erated from the source document D and the candi-
4 Factuality Metrics for Evaluation date summary Si is used as input to the QA system.
Alternatively, FEQA generates questions from Si
We mainly focus on meta-evaluating most recently and uses D to answer these questions.
proposed factual consistency metrics which use The generation quality score is typically the ag-
two types of proxy natural language understand- gregated F1 score measuring the similarity between
ing (NLU) objectives aimed at implicitly capturing ground-truth answers for questions generated from
factuality in generated text: question-answering D and the answers predicted by the QA system.
(QA) and a masked token prediction cloze task. SummaQA also generally includes the aggregated
We also measure the factual-awareness of sum- model confidence probabilities for predictions.
marization metrics that are aimed primarily at im- Masked LM Prediction (Cloze Task) Score.Given a source document D and candidate sum- that focused specifically on factuality are more sen-
mary Si , Cloze-based evaluation metrics assign sitive to changes in factuality compared to the stan-
a generation quality score to Si by measuring dard lexical overlap or contextual semantic simi-
the ability of a NLU system to accurately predict larity metrics, all of these metrics except BLANC-
masked tokens in the source document, given ac- Tune, ROUGE-1 and ROUGE-L satisfy the bound-
cess to the information in Si . We use two variants edness condition (Tables 5 and 6). Additionally,
of BLANC (Vasilyev et al., 2020), BLANC-Help all metrics except SummaQA confidence scores
and BLANC-Tune. BLANC-Help uses both D and (SummaQA-C) are sensitive for entity errors on the
Si as input to a pretrained masked token prediction dialogue dataset (See Table 7). For CNNDM we
model, while BLANC-Tune only uses D as input find that all the metrics except BLANC-TUNE and
to a model that has been finetuned on the candi- FEQA are sensitive to factual consistency to some
date summary. Both metrics are aimed at capturing degree when we consider entity errors (The most
fluency, informativeness and factual correctness of sensitive metric is SUMMAQA-F1 with a sensi-
summaries. tivity score of 1.02), though the actual sensitivity
Semantic Similarity. Semantic similarity met- effect size is very low for ROUGE and BERTScore
rics measure the overlap between contextual em- (S < .01). For XSUM, SummaQA-F1 has the
beddings of a source or reference document D and highest sensitvity score (0.34), but only FEQA,
candidate summary Si . We use BERTScore (Zhang ROUGE-1, ROUGE-2 and BERTScore are nega-
et al., 2020), which has been shown to correlate tively correlated with factual inconsistency with
better with human judgements of coherency than p ≤ 0.05. This indicates that when factual incon-
standard summarization metrics and similarly to sistency of summaries is relatively low, factuality
n-gram metrics on factual consistency of CNNDM metrics have high variance in terms of effective-
summaries (Wang et al., 2020). ness at detecting differences in the levels of factual
Lexical Overlap. Finally, we test ROUGE (Lin, inconsistency. (Overall at least 26% of summaries
2004), which is the standard metric used for eval- are factually correct for XSUM and at least 15%
uating summarization. ROUGE measures the n- are correct for CNNDM - see Table 4 for details.)
gram overlap between a source or reference docu- ROUGE is not always a valid factuality met-
ment D and candidate summary Si . We evaluate ric. Even when we remove the limitations on lexi-
results using ROUGE-1 and ROUGE-2, as well as cal overlap metrics posed by reference summaries
ROUGE-L, which measures longest common sub- (Novikova et al., 2017), we find that there is high
sequence overlap. We follow prior work that con- variation across domains in the performance of
sidered ROUGE in factual consistency evaluations source document-referenced ROUGE metrics at
(Wang et al., 2020), though it has also been pre- identifying factual inconsistency. While most other
viously noted that ROUGE can underweight good metrics fulfil our boundness and sensitivity condi-
summarization examples (Novikova et al., 2017). tions, ROUGE-1 and ROUGE-L fail to be bounded
(e.g. XSUM summaries with a factual inconsis-
5 Meta-Analysis of Factuality Metrics
tency level of 3 have an average ROUGE-1 score of
5.1 Controlled Data Experiments 10.92 while the upper bound is 10.61) or sensitive
in the case of non-entity-based errors, with metric
We conduct controlled experiments on the simu-
values actually increasing as factual inconsistency
lated datasets as introduced in 3.2.1, mainly to
increases (ROUGE-1 has correlations of 0.98 and
measure the sensitivity of the factuality metrics
0.96 on XSUM and CNNDM respectively, while
on various simulated factuality errors. We provide
ROUGE-L has correlations of 1 and 0.91). This
the results of the sensitivity analysis over our sim-
implies that standard lexical overlap metrics are
ulated data on the XSUM domain in Table 5, on
able to pick up on obvious lexical errors like those
CNNDM in Table 6 and on SAMSUM in Table 7.
indicated by entity changes, but are inadequately
All reported results are aggregated from metric val-
sensitive to subtler changes like those captured by
ues computed over five different sets of random
verb negation.
transformations (See section 3.2.1 for details).
Differences between factuality and standard QA vs. Cloze. While masked token prediction
metrics are fragile when factuality is high. Our (cloze task) metrics improve over ROUGE when it
results collectively suggest that, while the metrics comes to detection of non-entity-based errors onCLOZE QA STANDARD CONTEXTUAL
BLANC-Help BLANC-Tune SummaQA-C SummaQA-F1 FEQA R-1 R-2 R-L BERTScore
Upper Bound 5.99 1.73 9.64 4.48 27.87 10.61 2.56 9.32 83.76
Level 1 5.73 / 5.98 1.74 / 1.71 9.44 / 9.44 3.80 / 4.31 23.20 / 26.94 10.49 / 10.76 2.54 / 2.56 9.22 / 9.42 83.53 / 83.56
Level 2 5.46 / 5.99 1.59 / 1.78 9.27 / 9.35 3.40 / 4.22 20.05 / 26.55 10.40 / 10.86 2.51 / 2.54 9.16 / 9.49 83.36 / 83.38
Level 3 5.30 / 5.97 1.58 / 1.76 9.16 / 9.23 3.13 / 4.14 15.81 / 26.06 10.33 / 10.92 2.49 / 2.52 9.10 / 9.55 83.21 / 83.26
Lower Bound 1.67 0.25 8.69 1.40 7.07 6.72 0.01 0.06 80.97
Sensitivity 0.22 / 0.01 0.08 / 0.02 0.14 / 0.11 0.34 / 0.09 0.04 /0.10
0.20 1.2
0.05
0.15 1.0
Distribution of Metric Values
Distribution of Metric Values
Distribution of Metric Values
0.00 0.8
0.10 0.05 0.6
0.05 0.10 0.4
0.2
0.00 0.15
0.0
0.20
0.05 0.2
0.25
0 1 2 3 0 1 2 3 0 1 2 3
Level of Factuality (# of Errors) Level of Factuality (# of Errors) Level of Factuality (# of Errors)
BLANC-Help BLANC-Tune FEQA
(Pearson’s R = 0.15, p = 0.15) (Pearson’s R = 0.01, p = 0.89) (Pearson’s R = -0.07, p = 0.60)
0.20 0.88
0.20 0.86
0.15
Distribution of Metric Values
Distribution of Metric Values
Distribution of Metric Values
0.15
0.84
0.10 0.10
0.82
0.05
0.05
0.80
0.00
0.00 0.05 0.78
0 1 2 3 0 1 2 3 0 1 2 3
Level of Factuality (# of Errors) Level of Factuality (# of Errors) Level of Factuality (# of Errors)
SummaQA-C SummaQA-F1 BERTScore
(Pearson’s R = -0.22, p = 0.02) (Pearson’s R = -0.22, p = 0.03) (Pearson’s R = -0.03, p = 0.76)
Figure 2: Distribution of metric values evaluated in this work. The evaluations are on human annotated generated XSUM
dataset sample summaries across factuality levels for three different metric types: cloze task, question-answering and contextual
metrics. The colored bounds indicate the variation across 100 samples. The colors indicate levels of factuality errors. The results
shown are for all errors except “other” and “false quote.”
60 Error Types attack, say doctors,”. Here, the actual implication
(0) - int
50 (1) - pro
in the ground truth summary is that blood tests can
40
(2) - ext
(3) - verb
lead to better diagnosis of heart attacks and less
30
(4) - other unnecessary hospitalization rather than preventing
(5) - sent
20
(6) - false quote heart attacks. We find that these types of false quote
10
errors appear more frequently in XSUM summaries
than any other type of errors except the extrinsic
0 1 2 3 4 5 6
entity errors (ext).
Figure 3: Distribution of factual error types in T5 generated
XSUM summaries. The factual error types are described in Figure 2 shows the distribution of metric values
Table 3. ext: extrinsic entity error, int: intrinsic entity error, across factuality levels for 100 sampled XSUM
pro:pronoun error, neg: negation error, sent:sentiment error,
false quote: hallucinated quotes summaries (excluding “other” and “false quote”
errors). Table 8 lists the correlation and p-values
from Figure 2 including the ROUGE scores. We
(as described in Table 3) also appear in the anno- find that all of the metrics except Cloze task met-
tated generated summaries. We also discovered a rics and ROUGE-2 are negatively correlated, and
new category of error we define for human evalu- SummaQA metrics show a statistically significant
ation, “false quote”, which describes an instance correlation. This is in line with our findings on
of a hallucinated quote in the generated summary. the simulated data (form Table 5), where we found
For example, in a model generated XSUM sum- that SummaQA also performed best in terms of
mary is the claim “A blood test may help to save sensitivity score (SummaQA metrics were nega-
a man from having heart attacks, says a British tively correlated with factual inconsistency with
medical journal,” when the ground-truth summary a p-value of 0.07 compared to 0.05 for FEQA),
is “A blood test can more than halve the number of and cloze task metrics were not always bounded
people admitted to hospital with a suspected heart or sensitive and BLANC-Tune and ROUGE-2 hadMetric Correlation p-value periments run using our Go-Figure Meta Evalua-
BLANC-Help 0.15 0.15
tion:
BLANC-Tune 0.01 0.89
SummaQA-C -0.22 0.02* The simulated data analysis highlights the
SummaQA-F1 -0.22 0.03* same trends in best- and worst-performing fac-
FEQA -0.07 0.60 tuality metrics as human analysis. Metrics with
R-1 -0.06 0.57 low sensitivity scores on our simulated XSUM data
R-2 0.13 0.20 perform poorly on human-annotated XSUM data,
R-L -0.03 0.74 regardless of correlation with factual consistency
BERTScore -0.03 0.76 on simulated data. Conversely, high sensitivity
scores on simulated data may be an indicator of
Table 8: Correlation for annotated XSUM generated sum- better performance on human-annotated data. For
maries (without “other” and “false quote” errors).
the purposes of determining the most reliable
Metric Correlation p-value
factuality metric, this suggests that simulated
data is sufficient given that some metrics (e.g.
BLANC-Help 0.10 0.33 SummaQA) have high sensitivity. In case of
BLANC-Tune 0.01 0.94
metrics like BERTScore and ROUGE, variance
SummaQA-C -0.17 0.09
in performance between simulated and generated
SummaQA-F1 -0.20 0.05*
FEQA < 0.01 0.99 data is less predictable due to low sensitivity.
R-1 0.02 0.82
R-2 0.14 0.15 Analysis on human annotated data is still
R-L 0.05 0.64 necessary when evaluating metrics. While
BERTScore 0.06 0.53 BLANC-Help metric values decrease with factual
inconsistency on simulated data, the metric is
Table 9: Correlation for annotated XSUM generated sum- positively correlated with factual inconsistency
maries (with all error types).
on generated data. The differences between
factuality metrics and lexical overlap metrics are
the least correlations on entity-based errors. How- also more clearcut when considering generated
ever, in our analysis on generated data, we notice summaries as opposed to transformed reference
a difference in results for FEQA, ROUGE-1 and summaries. All ROUGE metrics may increase as
ROUGE-L metrics. We find that these metrics are factual consistency decreases when we consider
sensitive with a score less than 0.05 on simulated the full set of error types (See Table 9), and while
XSUM data with entity-based errors, but are not ROUGE-2 is the most promising lexical overlap
significantly sensitive on generated data (though metric on simulated summaries in our simulated
these metrics are negatively correlated). These find- experiments, it is also positively correlated with
ings indicate that the magnitude of the sensitivity factual inconsistency when we remove “other”
score from the simulated data analysis as well as and “false quote” errors. This emphasizes the
statistical significance may be key to predicting importance of a human-annotated test set as part of
results on generated data. When we consider all the Go-Figure meta evaluation.
errors (Table 9), we find relatively less variation in
most of the metric scores between factuality lev- The effectiveness of factuality metrics is
els for the generated summaries, though there is most clear when factual consistency is low.
some evidence that SummaQA metric values may While factuality metrics have higher sensitivity
be weakly correlated with factuality level. scores than standard lexical overlap or contextual
metrics, our analyses show that ROUGE-2 and
5.3 Discussion of Meta Evaluation BERTScore metric values appear to be correctly
Our analyses show that in contrast to prior work on correlated with factual consistency score on
factual consistency that mostly concentrated on one reference summaries transformed with simulated
specific domain and dataset, our Go-Figure frame- factual inconsistencies. However, these metrics do
work is effective at testing whether performance of not perform well on generated summaries, where
metrics generalize across domains. there is more room for factual inconsistency.
We highlight the following key points from ex-Limitations. Even though we define levels compare correlation of various summarization
of factual inconsistencies, our framework assumes metrics with human judgements of factuality.
that the correctness of a factual claim is binary, We expand upon these prior analyses by also
rather than scaled. However, it is possible that introducing a concretely defined framework for
generated summaries are factually consistent but evaluating current and future factuality metrics.
unfaithful in meaning because they carry different In contrast to earlier works, we also consider
implications than ground-truth summaries. For a broader range of domains (notably dialogue
example the T5 summary “The UK should remain summarization).
a member of the European Union?” and the
matching ground-truth summary “Should the UK 7 Conclusion
remain a member of the EU?,” both are factually
We show that our meta-evaluation framework can
consistent and on-topic given the underlying
be used to effectively evaluate sensitivity and valid-
news article but the slight change in the phrasing
ity of factual consistency metrics with only refer-
of the question for the T5 generated summary
ence summaries, rather than requiring computation-
makes it appear to be a leading question rather
ally intensive testing across summarization model
than the more impartial framing of the original
variants to identify metric strengths and shortcom-
summary. This relates to subjectivity of generated
ings. The theoretically grounded nature of our met-
text, including generated misinformation (Zellers
ric conditions also allows for potential extensions
et al., 2019). Measuring shifts in faithfulness due
to other use cases and text generation settings like
to subjectivity is not explicitly captured by the
data-to-text generation.
current conditions of our framework.
In particular, our findings from application of the
framework to summarization highlight that current
6 Related Work metrics are capable of capturing obvious lexical
errors (e.g. entity errors) in summaries, but strug-
Factuality in Summarization. Recent efforts
gle with errors related to more subtle aspects of
by NLP researchers have drawn attention to the
semantics (e.g. negation and false quotes). Pro-
issue of factual errors and hallucinations in the
posed future directions for improving the ability
output of neural summarization models (Cao et al.,
of metrics to capture a broader spectrum of factual
2018; Massarelli et al., 2019; Zhao et al., 2020).
inconsistencies include modification of QA metrics
The work of Kryscinski et al. (2019) used similar
like SUMMAQA and FEQA to use more contextual
simulated data collection to ours for improving
question generation (QG) systems (e.g. common-
factual consistency of models, though their
sense QG (Shwartz et al., 2020) that allows for
simulated data is only used for training rather than
more nuanced fact-checking).
evaluation, while Dusek et al. (2017) introduced
a reference-less model-based generation quality
Acknowledgments
metric based on adversarial training with simulated
examples. A number of works have highlighted The authors thank Yichen Jiang and Shiyue Zhang
the effectiveness of QA and cloze task objectives for feedback on implementation, Hannah Rashkin
for evaluating or improving factuality on specific and Tom McCoy for help with MSR GPU clusters,
domains (Eyal et al., 2019; Huang et al., 2020). Rowan Zellers and Elizabeth Clark for pointers to
We aim to evaluate these metrics more broadly. related work, as well as other members of the UW
NLP, MSR AI and MSR MSAI communities for
Evaluation Framework. Prior work con- helpful comments.
cerning evaluation of automatic metrics for
NLG systems has mainly focused on general
evaluations of output quality or coherence and References
fluency (Callison-Burch et al., 2007; Graham, Chris Callison-Burch, Cameron Fordyce, Philipp
2015; Fabbri et al., 2020), rather than factuality. Koehn, Christof Monz, and Josh Schroeder. 2007.
Recent work has started to explore evaluating (meta-) evaluation of machine translation. In Pro-
ceedings of the Second Workshop on Statistical Ma-
factuality and faithfulness in summarization (Falke chine Translation, pages 136–158, Prague, Czech
et al., 2019b; Goodrich et al., 2019; Celikyilmaz Republic. Association for Computational Linguis-
et al., 2020). In particular, Maynez et al. (2020) tics.Ziqiang Cao, Furu Wei, W. Li, and Sujian Li. 2018. International Conference on Knowledge Discovery
Faithful to the original: Fact aware neural abstrac- & Data Mining.
tive summarization. In AAAI.
Yvette Graham. 2015. Re-evaluating automatic sum-
Asli Celikyilmaz, Elizabeth Clark, and Jianfeng Gao. marization with BLEU and 192 shades of ROUGE.
2020. Evaluation of text generation: A survey. In Proceedings of the 2015 Conference on Empiri-
ArXiv, abs/2006.14799. cal Methods in Natural Language Processing, pages
128–137, Lisbon, Portugal. Association for Compu-
Elizabeth Clark, Asli Celikyilmaz, and Noah A. Smith. tational Linguistics.
2019. Sentence mover’s similarity: Automatic eval-
uation for multi-sentence texts. In ACL. Han Guo, Ramakanth Pasunuru, and Mohit Bansal.
Esin Durmus, He He, and Mona Diab. 2020. FEQA: A 2018. Soft layer-specific multi-task summarization
question answering evaluation framework for faith- with entailment and question generation. In Pro-
fulness assessment in abstractive summarization. In ceedings of the 56th Annual Meeting of the Associa-
Proceedings of the 58th Annual Meeting of the Asso- tion for Computational Linguistics (Volume 1: Long
ciation for Computational Linguistics, pages 5055– Papers), pages 687–697, Melbourne, Australia. As-
5070, Online. Association for Computational Lin- sociation for Computational Linguistics.
guistics.
T. Hashimoto, Hugh Zhang, and Percy Liang. 2019.
Ondrej Dusek, Jekaterina Novikova, and V. Rieser. Unifying human and statistical evaluation for natu-
2017. Referenceless quality estimation for natural ral language generation. ArXiv, abs/1904.02792.
language generation. ArXiv, abs/1708.01759.
Ari Holtzman, Jan Buys, M. Forbes, and Yejin Choi.
Matan Eyal, Tal Baumel, and Michael Elhadad. 2019. 2020. The curious case of neural text degeneration.
Question answering as an automatic evaluation met- ArXiv, abs/1904.09751.
ric for news article summarization. In Proceed-
ings of the 2019 Conference of the North American Luyang Huang, Lingfei Wu, and Lu Wang. 2020.
Chapter of the Association for Computational Lin- Knowledge graph-augmented abstractive summa-
guistics: Human Language Technologies, Volume 1 rization with semantic-driven cloze reward. In Pro-
(Long and Short Papers), pages 3938–3948, Min- ceedings of the 58th Annual Meeting of the Asso-
neapolis, Minnesota. Association for Computational ciation for Computational Linguistics, pages 5094–
Linguistics. 5107, Online. Association for Computational Lin-
guistics.
A. R. Fabbri, Wojciech Kryscinski, B. McCann,
R. Socher, and D. Radev. 2020. Summeval: Wojciech Kryscinski, B. McCann, Caiming Xiong,
Re-evaluating summarization evaluation. ArXiv, and R. Socher. 2019. Evaluating the factual con-
abs/2007.12626. sistency of abstractive text summarization. ArXiv,
abs/1910.12840.
Tobias Falke, Leonardo F. R. Ribeiro, Prasetya Ajie
Utama, Ido Dagan, and Iryna Gurevych. 2019a. Chin-Yew Lin. 2004. ROUGE: A package for auto-
Ranking generated summaries by correctness: An in- matic evaluation of summaries. In Text Summariza-
teresting but challenging application for natural lan- tion Branches Out, pages 74–81, Barcelona, Spain.
guage inference. In ACL. Association for Computational Linguistics.
Tobias Falke, Leonardo F. R. Ribeiro, Prasetya Ajie
Yang Liu and Mirella Lapata. 2019. Hierarchical trans-
Utama, Ido Dagan, and Iryna Gurevych. 2019b.
formers for multi-document summarization. ACL.
Ranking generated summaries by correctness: An in-
teresting but challenging application for natural lan- Yuning Mao, Liyuan Liu, Qi Zhu, Xiang Ren, and Ji-
guage inference. In Proceedings of the 57th Annual awei Han. 2020. Facet-aware evaluation for extrac-
Meeting of the Association for Computational Lin- tive summarization. In ACL.
guistics, pages 2214–2220, Florence, Italy. Associa-
tion for Computational Linguistics. Luca Massarelli, F. Petroni, Aleksandra Piktus, Myle
Angela Fan, M. Lewis, and Yann Dauphin. 2018. Ott, Tim Rocktäschel, Vassilis Plachouras, F. Sil-
Hierarchical neural story generation. ArXiv, vestri, and S. Riedel. 2019. How decoding strate-
abs/1805.04833. gies affect the verifiability of generated text. ArXiv,
abs/1911.03587.
Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and
Aleksander Wawer. 2019. Samsum corpus: A Joshua Maynez, Shashi Narayan, Bernd Bohnet, and
human-annotated dialogue dataset for abstractive Ryan T. McDonald. 2020. On faithfulness and
summarization. ArXiv, abs/1911.12237. factuality in abstractive summarization. ArXiv,
abs/2005.00661.
B. Goodrich, V. Rao, Mohammad Saleh, and Peter J.
Liu. 2019. Assessing the factual accuracy of gener- George A. Miller. 1995. Wordnet: A lexical database
ated text. Proceedings of the 25th ACM SIGKDD for english. Commun. ACM, 38(11):39–41.Ramesh Nallapati, Bowen Zhou, C. D. Santos, Çaglar Tianyi Zhang, V. Kishore, Felix Wu, K. Weinberger,
Gülçehre, and B. Xiang. 2016. Abstractive text sum- and Yoav Artzi. 2020. Bertscore: Evaluating text
marization using sequence-to-sequence rnns and be- generation with bert. ArXiv, abs/1904.09675.
yond. In CoNLL.
Z. Zhao, Shay B. Cohen, and B. Webber. 2020. Reduc-
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. ing quantity hallucinations in abstractive summariza-
2018. Don’t give me the details, just the summary! tion. ArXiv, abs/2009.13312.
Topic-aware convolutional neural networks for ex-
treme summarization. In Proceedings of the 2018 Chenguang Zhu, William Hinthorn, Ruochen Xu,
Conference on Empirical Methods in Natural Lan- Qingkai Zeng, Michael Zeng, Xuedong Huang, and
guage Processing, Brussels, Belgium. Meng Jiang. 2020. Boosting factual correctness of
abstractive summarization.
Jekaterina Novikova, Ondrej Dusek, A. Curry, and Ver-
ena Rieser. 2017. Why we need new evaluation met-
rics for nlg. In EMNLP.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine
Lee, Sharan Narang, Michael Matena, Yanqi Zhou,
W. Li, and Peter J. Liu. 2019. Exploring the limits
of transfer learning with a unified text-to-text trans-
former. ArXiv, abs/1910.10683.
Sascha Rothe, Shashi Narayan, and A. Severyn. 2019.
Leveraging pre-trained checkpoints for sequence
generation tasks. Transactions of the Association for
Computational Linguistics, 8:264–280.
Thomas Scialom, Sylvain Lamprier, Benjamin Pi-
wowarski, and Jacopo Staiano. 2019. Answers
unite! unsupervised metrics for reinforced summa-
rization models. In EMNLP/IJCNLP.
Thibault Sellam, Dipanjan Das, and Ankur Parikh.
2020. BLEURT: Learning robust metrics for text
generation. In Proceedings of the 58th Annual Meet-
ing of the Association for Computational Linguistics,
pages 7881–7892, Online. Association for Computa-
tional Linguistics.
Noam Shazeer and Mitchell Stern. 2018. Adafactor:
Adaptive learning rates with sublinear memory cost.
In ICML.
Vered Shwartz, Peter West, Ronan Le Bras, Chan-
dra Bhagavatula, and Yejin Choi. 2020. Unsuper-
vised commonsense question answering with self-
talk. EMNLP.
Oleg V. Vasilyev, Vedant Dharnidharka, and J. Bo-
hannon. 2020. Fill in the blanc: Human-free
quality estimation of document summaries. ArXiv,
abs/2002.09836.
Alex Wang, Kyunghyun Cho, and Mike Lewis. 2020.
Asking and answering questions to evaluate the fac-
tual consistency of summaries. In Proceedings of
the 58th Annual Meeting of the Association for Com-
putational Linguistics, pages 5008–5020, Online.
Association for Computational Linguistics.
Rowan Zellers, Ari Holtzman, Hannah Rashkin,
Yonatan Bisk, Ali Farhadi, F. Roesner, and Yejin
Choi. 2019. Defending against neural fake news. In
NeurIPS.A Appendices If a summary is judged to be factually incorrect,
annotators are allowed to select the number and
A.1 Simulated Data Transformations
type of errors they observe using a predefined list
We inject errors into reference summaries by first of factual errors. A screenshot of the error types
using a part-of-speech tagging model and named and examples shown in the annotation task is given
entity recognition system (spacy)7 to extract enti- in Figure 4. Summaries were manually evaluated
ties, verbs, and adjectives from these summaries. and labeled for factual inconsistency by a graduate
For each named entity, we keep track of the label student.
type (e.g. ORG, GPE, etc).
Intrinsic entity errors. To inject intrinsic entity
errors into a summary S, we construct a dictionary
of all unique entities appearing in the source doc-
ument for S only, organized by entity label type.
We then swap a random entity in the reference sum-
mary for a different entity of the same label type in
the constructed dictionary.
Extrinsic entity errors. For extrinsic entity er-
rors, we use the same dictionary construction for all
unique entities appearing in all the corpus source
documents. To change a random adjective, we
use WordNet (Miller, 1995) to obtain the synsets
for that adjective and swap the adjective for its
antonym.
Pronoun entity errors. Pronoun errors are in-
troduced with a preset list of commonly used pro-
nouns. We randomly extract a pronoun set (e.g.
she/her) from the text using the preset list and swap
it with another random pronoun set (e.g. he/him).
Verb Negation. We use a rule-based system for
verb negation based on verb tense, and predict tense
based on the suffix and preceding words.
A.2 T5 Training
We fine-tune the T5-base model trained on news
summaries for each domain using the AdaFactor
optimizer (Shazeer and Stern, 2018) with a learning
rate of 0.001 and a batch size of 8.
A.2.1 Human Annotation Layout
For human annotation of factual consistency in
summaries, we show annotators the source docu-
ment, reference summary and a candidate summary
that should be assessed for factuality. We then ask
a factuality question with three choices:
• Yes (i.e. the summary is factual)
• No (i.e. the summary contains factual incon-
sistencies)
• Not Sure (i.e. the summary is too incoherent
to judge)
7
https://spacy.io/Figure 4: Examples of factual errors given in annotation task.
You can also read