Self-Supervised Learning - Xiaohang Zhan MMLab, The Chinese University of Hong Kong June 2020
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Self-Supervised Learning Xiaohang Zhan MMLab, The Chinese University of Hong Kong June 2020
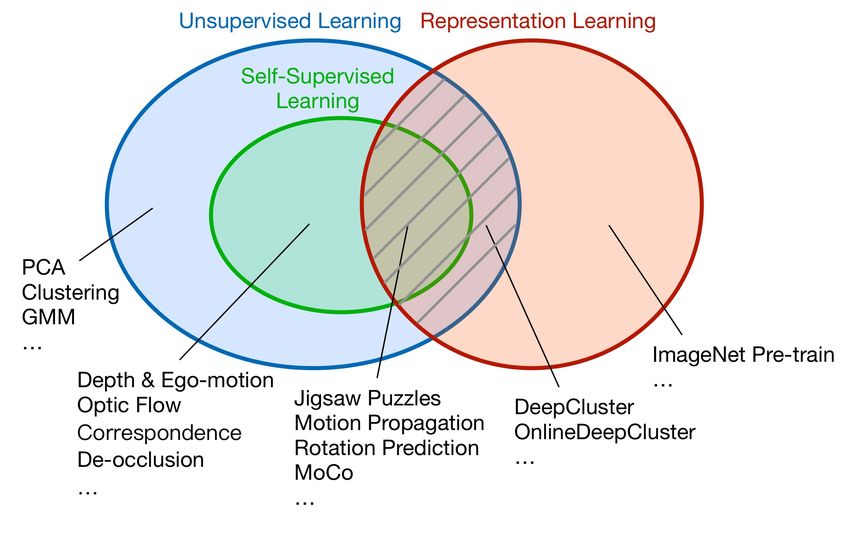
What is Self-Supervised Learning?

What is Self-Supervised Learning? self-supervised proxy task Self-Supervised Learning (step 1) CNN Annotation free To learn unlabeled data initialize something new Does image in- painting belong (step 2) CNN to self-supervised learning? target task data target task A typical pipeline

Self-Supervised Proxy/Pretext Tasks Image Colorization Solving Jigsaw Puzzles Image In-painting 90° 270° Rotation Prediction Instance Discrimination Counting Motion prediction Moving foreground segmentation Motion propagation

Why does SSL learn new information?

Prior • Appearance prior • Physics prior 90° 270° Image Colorization Image In-painting Rotation Prediction • Motion tendency prior • Kinematics prior Low-entropy priors are more predictable. Motion prediction Motion propagation (Fine-tuned for seg: 39.7% mIoU) (Fine-tuned for seg: 44.5% mIoU)

Coherence • Spatial coherence • Temporal coherence Correct order Wrong order Solving Jigsaw Puzzles Temporal order verification

Structure Image i Image j Instance Discrimination (Contrastive Learning) Intra-image Intra-image • NIPD Transform Transform • CPC • MoCo • SimCLR • … Pull together Push apart Pull together

Structure Both are optimal for Instance Discrimination. Why does the final optimized feature space Color: category look like the second case? Number: image index Optimal solution #1 Optimal solution #2

What to consider in proxy task design?
Shortcuts • Continuity Solving Jigsaw Puzzles
Shortcuts • Solution regarding continuity Solving Jigsaw Puzzles
Shortcuts • Chromatic Aberration • Coma • Distortion • Vignetting Do not apply heavy vignetting effects in your photos!!! Barrel-type Pincushion-type
Shortcuts • Solution regarding aberration After aberration correction Solving Jigsaw Puzzles
Ambiguity • Appearance prior • Physics prior 90° 270° Image Colorization Image In-painting Rotation Prediction • Motion tendency prior • Kinematics prior 1. Low-entropy priors are less ambiguous. 2. Any other solutions? Motion prediction Motion propagation (Fine-tuned for seg: 39.7% mIoU) (Fine-tuned for seg: 44.5% mIoU)
Difficulty Easy mode Normal mode Difficult mode Hell mode How to design the difficulty of the task?
Summary 1. Learning from unlabeled data is feasible through: a) prior b) coherence c) structure 2. In designing proxy tasks, you have to consider: a) shortcuts b) ambiguity c) difficulty
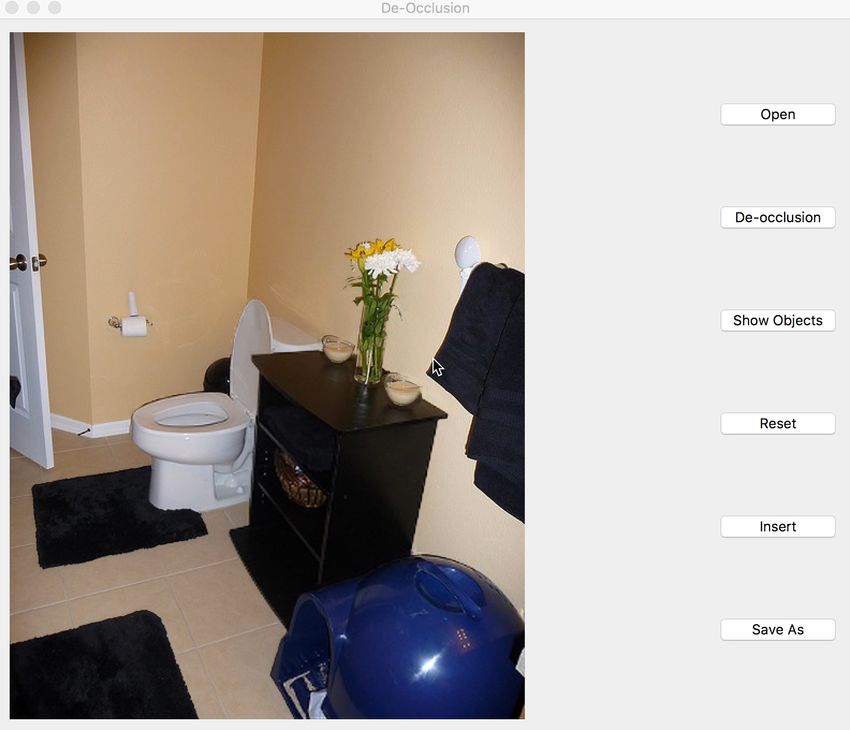
Self-Supervised Scene De-occlusion Xiaohang Zhan1, Xingang Pan1, Bo Dai1, Ziwei Liu1, Dahua Lin1, Chen Change Loy2 1 MMLab, The Chinese University of Hong Kong 2 Nanyang Technological University CVPR 2020 Oral
What We Have • A typical instance segmentation dataset: RGB image Modal masks & Category labels
Scene De-occlusion Real-world scene Intact objects with invisible parts Background + ordering graph
Tasks to Solve Occluders of an object visible (modal) intact (amodal) 1. Pair-wise ordering recovery 2. Amodal completion 3. Content completion Invisible regions
Amodal Completion What’s the shape of the blue objects? Full completion Ground truth amodal masks as supervision What if we do not have the ground truth?
Partial Completion full completion equivalent unavailable Trim down M-1 M0 M0 M1 M1 M2 partial partial partial completion completion completion A surrogate object trainable
To Do ✓Partial completion mechanism • Complete part of an object occluded by a given occluder, without amodal annotations. ?Ordering recovery • Predict the occluders of an object. ② ① Among objects ①,②,③,④, who are its occluders? ③ ④
Partial Completion Regularization partial partial completion completion A surrogate A surrogate object object Training case 1 Training case 2 Trained with case 1: Trained with case 1 & 2: always encourages if the target object looks like to be increment of pixels occluded by the surrogate object: complete it else: keep unmodified
Train Partial Completion Net-Mask (PCNet-M) category B A Case 1 A\B input instance A A B\A B A Case 2 PCNet-M Target random instance B inputs to PCNet-M
Dual-Completion for Ordering Recovery A2 A2 (a) A1 A1 A1’ A2 A2 A2’ (b) A1 PCNet-M A1 (inference) (a) Regarding A1 as the target and A2 as the surrogate occluder, the incremental area of A1: ∆ $# | & (b) Regarding A2 as the target and A1 as the surrogate occluder, the incremental area of A2: ∆ $& | # Decision: ∆ $ < ∆ $ ⇒ A1 is above A2
To Do ✓Partial completion • Complete part of an object occluded by a given occluder, without amodal annotations. ✓ Ordering recovery • Predict the occluders of an object. ? Amodal completion • Predict the amodal mask of each object given its occluders.
Ordering-Grounded Amodal Completion (inference)
Why All Ancestors? ✓
To Do ✓Partial completion • Complete part of an object occluded by a given occluder, without amodal annotations. ✓ Ordering recovery • Predict the occluders of an object. ✓ Amodal completion • Predict the amodal mask given occluders. ? Content completion • Is it the same as image inpainting?
Train Partial Completion Net-Content (PCNet-C) Which object the missing region belongs to. The missing region.
Amodal-Constrained Content Completion occluders amodal mask intersection modalinputs mask to PCNet-C erased image PCNet-C decomposed object (inference)
Compared to Image Inpainting image inpainting erased image our content completion modal mask erased image
Scene De-occlusion Real-world scene Objects with invisible parts Background + ordering graph
Todo list ✓Partial completion • Complete part of an object occluded by a given self-supervised training framework occluder, without amodal annotations. ✓ Ordering recovery • Predict the occluders of an object. ✓ Amodal completion progressive inference scheme • Predict the amodal mask given occluders. ✓ Content completion • Slightly different from image inpainting.
Evaluations Ordering Recovery Amodal Completion
Modal Dataset to Amodal Dataset train PCNet-M apply Order-grounded infer Amodal Completion dataset with dataset with modal instances pseudo amodal instances
Pseudo Amodal Masks v.s. Manual Annotations Using manual annotations Using our pseudo annotations Maybe in the future, we do not need to annotate amodal masks anymore!
Qualitative Amodal Completion Results modal convexR ours GT
Demo: Scene Re-organization Watch the video here: https://xiaohangzhan.github.io/projects/deocclusion/
Future Directions with Self-Supervised Scene De-occlusion • Data augmentation / re-composition for instance segmentation. • Previous: InstaBoost [ICCV’2019] • Ordering prediction for mask fusion in panoptic segmentation. • Occlusion-aware augmented reality. No need for extra annotations!
What’s the Intrinsic Methodology? Trim down M-1 M0 A carefully designed Inspiration Proxy: partial completion inference scheme Essence: prior of shape Target: scene de-occlusion
Messages to take away 1. Our world is low-entropy, working in rules. 2. The visual observations reflect the intrinsic rules. 3. Deep learning is skilled in processing visual observations.
Thank you!
Discussions Can it solve mutual occlusion? No. Can it solve cyclic occlusion? Yes.
You can also read