Synthetic Data - Anonymisation Groundhog Day
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Synthetic Data – Anonymisation Groundhog Day
Theresa Stadler Bristena Oprisanu Carmela Troncoso
EPFL UCL EPFL
arXiv:2011.07018v6 [cs.LG] 24 Jan 2022
Abstract the board [11, 13, 14, 42, 44, 47, 58, 59]. A large number of
1 publications, case studies, and real-world examples demon-
Synthetic data has been advertised as a silver-bullet solu-
strate that high-dimensional, sparse datasets are inherently
tion to privacy-preserving data publishing that addresses the
vulnerable to privacy attacks. The repeated failures to protect
shortcomings of traditional anonymisation techniques. The
the privacy of microdata releases reflect a fundamental trade-
promise is that synthetic data drawn from generative models
off: information-rich datasets that are valuable for statistical
preserves the statistical properties of the original dataset but,
analysis also always contain enough information to conduct
at the same time, provides perfect protection against privacy
privacy attacks [45].
attacks. In this work, we present the first quantitative eval-
In this landscape, practitioners and researchers see in syn-
uation of the privacy gain of synthetic data publishing and
thetic data a promising approach to open data sharing that
compare it to that of previous anonymisation techniques.
addresses the privacy issues of previous anonymisation at-
Our evaluation of a wide range of state-of-the-art genera-
tempts [2, 5, 10, 15, 16, 46, 61, 62, 64, 66–68, 72, 74]. Synthetic
tive models demonstrates that synthetic data either does not
data is presented as “the next, best step in sanitized data re-
prevent inference attacks or does not retain data utility. In
lease” [5] that addresses a wide variety of privacy-sensitive
other words, we empirically show that synthetic data does
use cases from deriving aggregate insights [55, 73] to out-
not provide a better tradeoff between privacy and utility than
lier analysis [40, 63]. Synthetic datasets are promised to pre-
traditional anonymisation techniques. Furthermore, in con-
serve the statistical properties of the original data but “contain
trast to traditional anonymisation, the privacy-utility tradeoff
no personal data” [61] and hence “enable the protection of
of synthetic data publishing is hard to predict. Because it is
personally identifiable information” [15]. In this work, we
impossible to predict what signals a synthetic dataset will pre-
present a rigorous, quantitative assessment of such claims and
serve and what information will be lost, synthetic data leads
challenge the common perception of synthetic data as the
to a highly variable privacy gain and unpredictable utility loss.
holy grail of privacy-preserving data publishing.
In summary, we find that synthetic data is far from the holy
grail of privacy-preserving data publishing. Previous works. Previous studies on the privacy properties
of synthetic data publishing overestimate its benefits over
traditional anonymisation for multiple reasons. A common
1 Introduction argument to support claims about the privacy benefits of syn-
thetic data is that it is ‘artificial data’ and therefore no direct
The rise of data-driven decision making as the prevailing link between real and synthetic records exists. Hence, many
approach to advance science, industrial production, and gov- argue, synthetic data by design protects against traditional
ernance generates a need to share and publish data [20,21,65]. attacks on microdata releases such as linkage [19, 58] or at-
At the same time, growing concerns about the implications tribute disclosure [19,39]. Consequently, many studies rely on
that data sharing has for individuals and communities call similarity tests between real and synthetic records to measure
for data publishing approaches that preserve fundamental the privacy leakage of synthetic datasets [10, 67, 68]. As we
rights to privacy. Yet, how to share high-dimensional data in show in this paper, these studies severely underestimate the
a privacy-preserving manner remains an unsolved problem. privacy risks of synthetic data publishing. We introduce two
Attempts to anonymise micro-level datasets have failed across new privacy attacks that demonstrate that, despite its artifi-
1 When citing this work, please note that a peer-reviewed version of this cial nature, synthetic data does not protect all records in the
paper will be published at USENIX Security 2022. There are some minor original data from linkage and attribute inference.
editorial differences between the two versions. More recent works analyse the vulnerability of genera-
1tive models against model-specific extraction attacks [8, 26, 2 Synthetic data and generative models
28]. Due to their focus on white-box attacks against non-
parametric models for synthetic image generation these works In this section, we formalise the process of synthetic data
do not provide the right framework to assess the privacy risks generation. Table 1 in the Appendix summarises our notation.
of synthetic data sharing in the tabular data domain. In con- Let R be a population of data records where each record
trast, our attacks treat the data synthesis method as a black- r ∈ R contains k attributes: r = (r1 , · · · , rk ). We denote the
box, focus on tabular data publishing, and allow us to directly unknown joint probability distribution over the data domain
compare the privacy leakage of synthetic data to that of tradi- of the population as DR . We refer to R ∼ DRn , a collection
tional anonymisation techniques. of n data records sampled independently from DR , as raw
Other approaches rely on formal privacy guarantees for dataset which defines the data distribution DR .
the generative model training process to prevent privacy at- Synthetic data generation. The goal of a generative model
tacks [1, 6]. While formal definitions of privacy are a clear is to learn a representation of the joint probability distribu-
improvement over the heuristic privacy models of traditional tion of data records DR . The model training algorithm GM(R)
anonymisation, their guarantees are often hard to interpret and takes as input a raw dataset R, learns Dg(R) , a representa-
difficult to compare to alternative anonymisation techniques. tion of the joint multivariate distribution DR , and outputs a
Here, we propose a framework that enables data holders to trained generative model g(R). The model g(R) is a stochastic
empirically evaluate the privacy guarantees of differentially function that, without any input, generates synthetic records
private synthetic data publishing and to directly compare its s i , distributed according to Dg(R) . We denote the process of
tradeoffs to that of traditional anonymisation techniques. sampling a synthetic dataset S = (ss1 , · · · , s m ) of size m as
S ∼ Dg(R) m . We write g(R) ∼ GM(R) instead of g(R) ← GM(R)
Contributions. In this paper, we quantitatively assess to indicate that the training algorithm can be a stochastic and
whether (differentially private) synthetic data produced by non-deterministic process.
a wide range of common generative model types does provide
a higher gain in privacy than traditional sanitisation at a lower Approximation by features. It is tempting to assume that
cost in utility. Our results demonstrate that: the model Dg(R) provides a perfect representation of the data
distribution DR and that synthetic data “carries through all
(I) Synthetic data drawn from generative models without ex- of the statistical properties, patterns and correlations in the
plicit privacy protection does not protect outlier records from [input] data” [27]. The trained model, however, only provides
linkage attacks. Given access to a synthetic dataset, a strategic a lower-dimensional approximation of the true data distribu-
adversary can infer, with high confidence, the presence of a tion. It retains some characteristics but can never preserve all
target record in the original data. of them. Which characteristics are captured, and how they ap-
proximate DR , is determined by the generative model choice.
(II) Differentially private synthetic data that hides the signal of Statistical models, such as Bayesian networks [35], or Hidden
individual records in the raw data protects these targets from Markov models [23], provide an explicit, parametric model of
inference attacks but does so at a significant cost in utility. DR . The features these models extract from their training data
Worse, in contrast to traditional anonymisation techniques, is determined upfront. Non-parametric models, such as gen-
synthetic datasets do not give any transparency about this erative adversarial networks (GANs) [25] or variational auto
tradeoff. It is impossible to predict what data characteristics encoders (VAEs) [33], do not estimate a parametric likelihood
will be preserved and what patterns will be suppressed. function to generate new samples from Dg(R) . Which features
of the input data are most relevant and how the model approx-
(III) Our empirical evaluation of the existing implementations
imates DR is implicitly determined during training [24].
of two popular differentially private generative model training
algorithms reveals that certain implementation decisions vio- The features a generative model uses to approximate DR
late their formal privacy guarantees and leave some records define which of the statistical properties of the raw data R are
vulnerable to inference attacks. We provide a novel implemen- replicated by a synthetic dataset S ∼ Dg(R) sampled from the
tation of both algorithms that addresses these shortcomings. trained model. Statistical models provide some control over
what features will be preserved. However, it is not possible
(IV) We make our evaluation framework available as an open- to exclude that a synthetic dataset reproduces characteristics
source library. Our implementation allows practitioners and of the original data other than the features explicitly captured
researchers to quantify the privacy gain of publishing a syn- by the model. For instance, synthetic data generated through
thetic in place of a raw or sanitised dataset and compare the independent sampling from a set of 1-way marginals is ex-
quality of different anonymisation mechanisms. The frame- pected to preserve a dataset’s independent frequency counts.
work includes implementations of two relevant privacy attacks However, if the raw data contains strong correlations between
and can be applied to any type of generative model training attributes, these correlations are likely to be replicated in the
algorithm. synthetic data even under independent sampling.
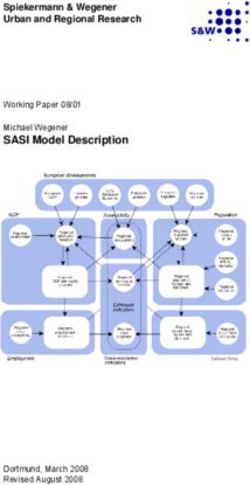
22.1 Generative models in this study shows that this has become an appealing proposition [15,
46, 61, 62, 64, 72, 74]. Here, we introduce a novel evaluation
In Sections 4.3 and 6.2, we empirically evaluate the privacy
framework that allows data holders to quantitatively assess
gain of synthetic data publishing for five existing generative
claims about the privacy benefits of synthetic data sharing.
model training algorithms. We implemented three generative
models without explicit privacy protection and two models Synthetic data as an anonymisation mechanism. Synthetic
with differential privacy guarantees. We chose models rele- data providers often present synthetic data as a novel “data
vant to the tabular data sharing use case and to cover a wide anonymisation solution” [74] that addresses the shortcom-
range of model architectures. We further considered their ings of traditional sanitisation techniques, such as generalisa-
computational feasibility for high-dimensional datasets and tion [39, 58] or perturbation [43]. Data holders are promised
whether a working implementation was available. Table 2 in that publishing a synthetic in place of the raw dataset prevents
Appendix 8.2 lists our parametrisation of these models. the leakage of private information about individuals in the
IndHist. The IndHist training algorithm from Ping et raw data previously observed in sanitised datasets [43, 58].
al. [50] extracts marginal frequency counts from each data To evaluate this claim, that synthetic data generation is an
attribute and generates a synthetic dataset S through inde- effective anonymisation mechanism, we hence need to assess
pendent sampling from the learned marginals. Continuous whether synthetic data addresses the privacy risks that origi-
attributes are binned. The number of bins is a configurable nally motivated the use of data anonymisation techniques.
model parameter. These are the risk of linkability and inference [3]. Previ-
ous anonymisation methods such as k-anonymity [58] or l-
BayNet. Bayesian networks capture correlations between at-
diversity [39] have failed to provide robust protection against
tributes by factorising the joint data distribution as a product
these attacks for high-dimensional, sparse datasets [43]. So
of conditionals. The degree of the network model is a model
far, however, there is no evidence that synthetic data provides
parameter. The trained network provides an efficient way to
better protection against these attacks at a lower cost in utility
sample synthetic records from the learned distribution (see
than traditional sanitisation techniques.
Zhang et al. [71] for details). We use the GreedyBayes imple-
mentation provided by Ping et al.’s DataSynthesizer [50]. A number of recent papers have tackled related problems
but focus primarily on non-parametric models for synthetic
PrivBay. PrivBayes [71] is a differentially private Bayesian
image generation and adversaries with white-box or query
network model. Both, the Bayesian network and the con-
access to the model [8,26,28]. However, like sanitisation, syn-
ditional distributions, are learned under ε-differentially pri-
thetic data is primarily seen as a tool for privacy-preserving
vate algorithms. A synthetic dataset can be sampled from the
tabular data sharing, i.e., to enable data holders to publish a
trained model without any additional privacy budget cost. We
single copy of synthetic data as opposed to the trained model
use the GreedyBayes procedure provided by Ping et al. [50]
or a set of statistics [15, 46, 64, 72, 74]. In our framework, we
to train a differentially private version of BayNet such that a
hence assume that the adversary only has access to a syn-
PrivBay-trained model with ε → ∞ corresponds to a BayNet-
thetic dataset and can not repeatedly query the trained model
model without formal guarantees.
or observe its parameters.
CTGAN. CTGAN [66] uses mode-specific normalisation of tab-
ular data attributes to improve the approximation of complex
distributions through GANs. CTGAN further uses a condi-
tional generator and training-by-sampling to get better perfor-
3.1 Evaluation framework
mance on imbalanced datasets. The goal of our framework is to quantitatively assess whether
PATEGAN. PATEGAN builds on the Private Aggregation of publishing a synthetic dataset S in-place of the raw data R
Teacher Ensembles (PATE) framework [48] to achieve DP for reduces the privacy risks for individuals in the raw data with
GANs [32]. PATEGAN replaces the discriminator’s training respect to the relevant privacy concerns. We model each pri-
procedure with the PATE mechanism. The trained model vacy concern as an adversary A that given a raw or synthetic
provides (ε, δ)-DP with respect to the discriminator’s output. dataset aims to infer a secret about a target record r t from
the population R . For each adversary, we define an advan-
3 Quantifying the privacy gain of synthetic tage measure AdvA that captures by how much including
an individual’s record in the published data increases this
data publishing individual’s privacy risk. In Section 4.1 and 6.2, we define
The promise of synthetic data is that it allows data holders to adversaries and advantage measures that model the risk of
publish (synthetic) datasets that are useful for analysis while, linkability and inference, respectively.
at the same time, protect the privacy of individuals in the Privacy gain. We assess the privacy gain of publishing a
raw data against powerful adversaries [2, 5, 10, 16, 66–68]. synthetic dataset S in place of the raw data R for target record
The increasing number of applications of synthetic data tools rt as the reduction in the adversary’s advantage when given
3access to S instead of R link a target record to a single record, or group of records,
in a sensitive dataset. Linkage enables adversaries to attach
PG , AdvA (R, r t ) − AdvA (S, r t ) . (1) an identity to a supposedly de-identified record [43, 58] or to
A high privacy gain indicates that publishing S in place of simply establish the fact that this particular record is present
R substantially reduces the privacy risk modelled by adversary in a sensitive dataset [29].
A for target record r t . A low gain, in contrast, implies that Related work. The risk of linkability has been demonstrated,
the data holder’s decision to publish S or R has no impact in theory and practice, for a large variety of data types: tab-
on the privacy loss for target record r t , i.e., the adversary’s ular micro-level datasets [43, 58], social graph data [42, 44],
advantage remains the same. aggregate statistics [51], and statistical models [57]. Linkage
The privacy gain hence allows us to assess whether syn- attacks on tabular microdata usually intend to link a target
thetic data is, as promised, an effective anonymisation mech- record (connected to an identity) to a single record in a sensi-
anism. A good anonymisation mechanism should result in a tive database from which direct identifiers have been removed.
high privacy gain for all records in the population and under Membership inference attacks (MIAs) are linkage attacks
any potential privacy adversary. A low gain in privacy indi- which target the output of statistical computations run on sen-
cates that the anonymisation mechanism does not provide a sitive datasets, such as aggregate statistics [29, 51] or trained
significant improvement over publishing the raw data. ML models [57]. ML-oriented MIAs have been extensively
Comparison to previous evaluation approaches. In con- studied on predictive models, such as binary or multi-label
trast to model-specific evaluation techniques [30], our frame- classifiers [37, 56, 57, 69]. Recently, this work has been ex-
work treats the data generating mechanism as a complete tended to GANs and VAEs [8, 26, 28].
black-box and evaluates the privacy risks of synthetic data
publishing rather than an adversary’s inference power when
given query or white-box access to a model [26, 53]. As 4.1 Formalizing linkability as membership in-
opposed to privacy evaluations based on similarity met- ference
rics [10, 67, 68], the framework provides data holders with a
In a linkage attack, the adversary aims to learn whether a
direct measure of how well the synthetic data defends against
record is present in a sensitive dataset. Following works by
the privacy risks of data sharing. This makes the evaluation
Yeom et al. [69] and Pyrgelis et al. [51], we hence model the
results easily interpretable and relatable to relevant data pro-
risk of linkability as a membership privacy game between
tection regulations [3]. We design and implement the frame-
an adversary A and a challenger C . The challenger plays the
work in a modular fashion. This ensures that the framework
role of a data holder that publishes a dataset X that is made
is not limited to a specific threat model [53] or the privacy
available to the adversary. This dataset could either be a raw
risks modelled in this paper. Instead, it can be adapted to any
dataset R or a sanitised or synthetic version of R, denoted as
privacy concern specific to the data holder’s use case. The
S. The goal of the adversary A is to infer whether a target
proposed evaluation method is independent of the data gener-
record r t , chosen by the adversary, is present in the sensitive
ation method. Thus, it can be used to evaluate the privacy gain
dataset R based on the published dataset X and some prior
of synthetic data generated by models trained without any ex-
knowledge P .
plicit privacy protection, models trained under formal privacy
guarantees [1, 6], or traditional anonymisation techniques. Fig. 1 presents the linkability game for the case where
S is a synthetic dataset sampled from a generative model
Worst-case vs. average-case evaluation. Finally, previous stud- trained on R. Later, we discuss how the challenger’s protocol
ies have shown that the privacy risks of data sharing are not changes when the game models sanitisation. First, A picks
uniformly distributed across the population [36,38,54]. While a target record r t and sends it to C . C draws a raw dataset R
individuals that are representative of a large majority of the of size n − 1 from the distribution defined by the population
population are often protected from privacy attacks, outliers R , and a secret bit st ∼ {0, 1}. If st = 0, C draws a random
or members of minorities largely remain vulnerable. Our record r ∗ from the population (excluding the target) and adds
framework allows to assess privacy risks both at an aggregate it to the raw dataset. If st = 1, C adds the target r t to the
population-level and on a per-record basis. This enables us raw dataset. Then, C trains a generative model on the raw
to demonstrate that synthetic data provides disparate privacy data R, and samples a synthetic dataset S of size m from the
gain across population subgroups. trained model. C picks at random whether to send back to the
adversary the raw data R or the synthetic data S. A receives
4 Does synthetic data mitigate the risk of link- the dataset and makes a guess about the target’s presence in R,
ability? ŝt ← A L (X, b, r t , P ). The adversary wins the game if ŝt = st .
As in Yeom et al. [69], we assume an equal prior over the
A major privacy concern in the context of privacy-preserving target’s membership in R and define the linkage adversary’s
data sharing is the risk of linkability. Linkage attacks aim to advantage as:
4A (P ) C (R ) plain how we implement this binary classifier in Section 4.2.
# Pick Target Privacy gain. For each target chosen by the adversary, we
1: rt ∈ R instantiate the game multiple times and measure the adver-
2: rt
sary’s advantage conditioned on the challenger’s choice of
X. Under our definition of privacy gain in Eq. 1 and with
# Sample raw data
AdvL (R, r t ) = 1, the privacy gain of publishing a synthetic
3: R ∼ DRn−1
dataset S in place of the raw data with respect to the risk of
# Draw secret bit linkability is given as:
4: st ∼ {0, 1}
5: If st = 0 : PG = 1 − AdvL (S, r t ) (4)
# Add a random record
A privacy gain of PG = 0 indicates that the adversary infers
6: r ∗ ∼ DR \rrt
the target’s presence in R with perfect accuracy regardless of
7: R ← R ∪ r∗ whether given access to the raw or synthetic data. If on the
8: If st = 1 : other hand, observing the synthetic data S gives the adversary
# Add target no advantage in inferring the target’s presence (AdvL (S, r t ) =
9: R ← R ∪ rt 0), then PG = 1.
# Train model
10 : g(R) ∼ GM(R) 4.2 A black-box membership inference attack
# Sample synthetic
11 :
m
S ∼ Dg(R) We implement the adversary’s strategy as a generic black-box
MIA that is independent of the generative model architecture.
# Draw public bit
12 : b ∼ {0, 1} Related work. Existing MIAs on generative models focus
13 : if b = 0 : X ← R almost exclusively on non-parametric deep learning models
for synthetic image generation [8, 26, 28, 41]. These works
14 : else : X ← S
mostly investigate the privacy risks of either model-specific
15 : X, b white-box attacks or set membership attacks that assume the
adversary has access to the entire universe of training records
# Make a guess and come to the conclusion that black-box MIAs that target
16 : ŝt ← A L (X, b, r t , P ) specific records perform only slightly better than random
baseline guessing [26, 28]. Unfortunately, previous attacks
Figure 1: Linkability privacy game. do not provide a good basis to evaluate the privacy gain of
synthetic data publishing. Non-parametric models for non-
tabular data cover only a very small set of use cases [15, 46,
72, 74], white-box attacks do not adequately reflect the data
h i sharing scenario, and set inference attacks are not suitable to
AdvL (X, r t ) , 2P A L (X, b, r t , P ) = st − 1 (2) assess individual-level privacy gain.
= P [ŝt = 1|st = 1] − P [ŝt = 1|st = 0] (3) Shadow model attack. In order to win the linkability game
(see Fig. 1) when she receives a synthetic dataset S, the ad-
where X can be a raw R or synthetic dataset S. The prob- versary needs a distinguishing function A L (·) that enables
ability space of AdvL is defined by the random choices of her to infer the membership of r t in the raw data R used to
R ∼ DR and st ∼ {0, 1} and the randomness of the synthetic train the generative model that output S. As in many previous
data generation mechanism and the adversary’s guess. works, we cast membership inference as a supervised learn-
Adversarial strategy. The adversary’s guess function A L (·) ing problem and instantiate the adversary’s guess function
takes as input a target record r t , the information published by with a machine learning classifier trained on data produced
the challenger, X and b, and some prior information P and by generative shadow models [51, 57].
outputs a guess about the target’s presence in R. The adver- As Shokri et al. [57], we assume that, as part of her prior
sary’s strategy to make a guess changes depending on the data knowledge P , the adversary has access to the training algo-
published. rithm GM(·), the size of the raw and synthetic datasets n and m,
If C publishes X = R, the adversary simply checks whether and to a reference dataset RA ∼ DRl that comes from the same
rt ∈ R and has a probability of 1 to win the game distribution as the target model’s training data R ∼ DRn and
(AdvL (R, rt ) = 1). may or may not overlap with R. Given this prior knowledge
If X = S, the adversary performs a binary classification task P and a target record rt , the adversary uses the following
on a set of features extracted from the synthetic data S. We ex- procedure to learn A L : First, the adversary samples multiple
5training sets Ri of size n from the reference dataset RA . On criterion performing best across datasets, generative models,
each set Ri , the adversary trains a generative model g(Ri ) us- and feature sets. In the remainder of the paper we focus on
ing the training procedure GM(Ri ). From each of the trained results obtained using this classifier.
models, the adversary samples multiple synthetic datasets S
of size m and assigns them the label st = 0. The adversary 4.3 Empirical evaluation
repeats the same procedure on the same training sets, this time
including the target, R0i = Ri ∪ r t , and assigns the generated We first evaluated the expected privacy gain with respect to the
synthetic datasets the label st = 1. Finally, the adversary trains risk of linkability under the three generative models trained
a classifier A L on the labelled datasets. The trained classifier without any formal privacy (see Section 2.1) on two com-
takes as input a synthetic dataset S and outputs a guess ŝt mon benchmark datasets: Adult and Texas. Both are tabular
about the target’s presence in R: ŝt ← A L (S, r t , P ). datasets that contain a mix of numerical and categorical at-
tributes. A detailed description of their characteristics can be
Feature extraction. Existing MIAs on predictive models
found in Appendix 8.3.
leverage patterns in the confidence values output by a trained
model that differ between two classes, members and non- Experiment procedure. We aim to assess whether synthetic
members [57]. Mounting a successful black-box MIA on a data produced by a wide range of generative model types does,
generative model is much more challenging [26]. The attacker as claimed, provide robust protection against linkage attacks.
needs to identify the influence that a single target record has If synthetic data is a “valid, privacy-conscious alternative to
on the high-dimensional data distribution Dg(R) as opposed raw data” [5], then its privacy gain should be close to PG = 1
to a low-dimensional confidence vector. Moreover, the output for all target records regardless of the attacker’s strategy. We
sampling process introduces additional uncertainty and the evaluate two groups of targets: five records randomly chosen
adversary only has access to a single output example. from the population and five manually chosen outlier records
representative of population minorities and most likely to be
In other words, the adversary needs to be able to distin-
vulnerable to linkage attacks [43]. As outliers, we selected
guish between two distributions, Dg(R∪rr ∗ ) and Dg(R∪rrt ) , given
m . To reduce the effect of high- records that either have rare categorical attribute values or
a single observation S ∼ Dg(X)
numerical values outside the attribute’s 95% quantile. For
dimensionality and sampling uncertainty, the adversary can instance, in the Texas dataset we show the privacy gain for
apply feature extraction techniques. Instead of training a clas- two records that have high total charges and one record with
sifier directly on S, the adversary learns to distinguish feature high total non-covered charges outside the attribute’s 95%
vectors extracted from synthetic datasets produced by models quantile, and two records with an unusually high risk mortality
trained with and without the target, respectively. A feature set and illness severity. For the Adult dataset we followed the
can be described as a function f (X) = f that takes as input same procedure to select outlier records.
a set of records X from the high-dimensional data domain At the beginning of each experiment, we sample a fixed
and outputs a numerical vector f that maps X into a lower- reference dataset RA of size l from the population and use it to
dimensional feature space. Whether the attack using feature train the adversary’s distinguisher. For each target record, we
set f is successful depends on two factors: First, whether train multiple attack models using the shadow model training
the target’s presence has a detectable impact on any of the procedure described in Section 4.2. To assess privacy gain,
features in f , and second, whether the synthetic dataset has we repeatedly instantiate the linkability game described in
preserved these features from the raw data and hence pre- Fig. 1 for each of our ten targets.
served the target’s signal.
Disparate gain. Fig. 2 shows the average privacy gain across
Implementation. We implement the distinguisher function multiple instantiations of the linkability game for five outlier
A L as an instantiation of our framework’s PrivacyAttack targets and five randomly chosen targets for the Texas (top
class (see Appendix 8.2). We leverage the object-oriented row) and Adult (bottom row) datasets, respectively. Each
structure of the library to create multiple attack versions that dataset, raw and synthetic, contained n = m = 1000 records.
share the same training procedure but use different attack The adversary was trained on a reference dataset of l =
models and feature extraction techniques. As feature extrac- 10, 000 records using 10 shadow models.
tors, we implemented a naive feature set with simple sum- We find that in both datasets privacy gain is unevenly dis-
mary statistics FNaive , a histogram feature set that contains tributed across target records. While the control group of
the marginal frequency counts of each data attribute FHist , randomly chosen target records ( ) achieves close to perfect
and a correlations feature set that encodes pairwise attribute protection (PG ≈ 1), other records ( ) remain highly vulnera-
correlations FCorr (see Appendix 8.2). ble to our linkage attack. The privacy gain for the majority of
As attack models, we implemented a Logistic Regression, outlier targets is substantially smaller than PG = 1 (ideal case).
Random Forests and K-Nearest Neighbours classifier. All For instance, under an attack using the naive feature set FNaive
attack models yielded similar results with a Random Forests 4 out of the 5 selected targets in the Texas dataset achieve
classifier with 100 estimators using the Gini impurity splitting an average gain smaller than 0.8 across all three generative
6FNaive FHist FCorr
1.4
Second, which characteristics a synthetic dataset might pre-
1.2 serve is not constrained to the features explicitly represented
1.0
0.8 by the model. For instance, even the simplest statistical model
PG
0.6
0.4 IndHist might unexpectedly preserve features targeted by
0.2
0.0 the attack: Synthetic data produced through independent at-
1.4
tribute sampling by an IndHist-model trained on the Adult
1.2 dataset leaves some target records vulnerable to linkage at-
1.0
0.8 tacks using the correlations feature set FCorr . Non-parametric
PG
0.6
0.4 models, such as CTGAN, do not even provide a parametric spec-
0.2
0.0 ification for the data’s density function. This makes it even
IndHist BayNet CTGAN IndHist BayNet CTGAN IndHist BayNet CTGAN harder to predict what set of features the model will preserve
and an attack might target.
Figure 2: Expected per-record privacy gain for outliers and
Previous assessments of the privacy risks of synthetic
random records for the Texas (top row) and Adult (bottom
data publishing based on aggregate population measurements
row) datasets under three different attacks using three distinct
severely underestimate the risk of linkage attacks [22, 26, 28].
feature sets. Error bars represent the standard deviation.
Our experimental evaluation reveals that synthetic data does
not provide uniform protection against strategic adversaries,
and some outliers remain highly vulnerable.
models. More worryingly, 1 out of the 5 targets tested ( ) con-
sistently receives a privacy gain close to 0 (PG < 0.005) from
synthetic data produced a by CTGAN-trained model. These re- 5 Does differentially private synthetic data
sults indicate that, contrary to claims by previous works [26], mitigate the risk of linkability?
publishing the synthetic in place of the raw data does not
protect outlier targets from linkage attacks. In the previous section, we demonstrate that non-private data
Unpredictable gain. Which records remain at risk varies synthesis algorithms are largely unsuitable as privacy mech-
across generative model type and the adversary’s feature set. anisms. This is not an unexpected finding as none of the
In the Texas dataset, an attack using the FNaive feature set evaluated models were originally designed as anonymisation
on CTGAN-produced synthetic data results in a privacy gain mechanisms. In this section, we thus extend our analysis to
below PG < 0.3 for 3 out of the 5 outlier targets ( , , ). The two model training algorithms explicitly designed to protect
same attack on the same targets is less effective on synthetic the privacy of a model’s training set, PrivBay and PATEGAN.
data produced by IndHist-trained models. The same group We evaluate to which extent their formal privacy guarantees
of targets reaches a maximum gain of PG = 0.77. Attacks on improve the privacy gain of synthetic data publishing with
the Adult dataset are most successful under the correlations respect to the risk of linkability.
feature set FCorr . Here, IndHist-trained models provide a Differentially private generative models. Model training
minimum gain of PG = 0.64 ( ) under FNaive . The minimum algorithms based on the differential privacy model protect
gain provided by the same model drops below PG < 0.32 the privacy of the training data through formal guarantees for
if the attacker uses FCorr as input to the attack and leaves a the lower-dimensional approximation of the full-dimensional
different target ( ) most vulnerable. data distribution [6,22,32,71]. Synthetic datasets drawn from
Conclusions. These results are extremely problematic from differentially private models preserve these privacy guaran-
the point of view of a data holder seeking to use synthetic tees under the post-processing guarantee [17].
data generation as a privacy mechanism. Ideally, data hold- The model training algorithm PrivBay learns a differen-
ers should be able to predict, given a fixed dataset R and a tially private Bayesian network that approximates the relation-
generative model training algorithm GM(·), the minimum gain ship between data attributes via the exponential mechanism
in privacy they can achieve. Our experiment shows, however, and computes the conditionally independent marginals in the
that this is next to impossible: The level of protection a gener- subspaces of the Bayesian network via the Laplace Mecha-
ative model provides depends on how much information the nism [71]. PATEGAN, a differentially private GAN, ensures
model’s output leaks about the features targeted by the attack. that the discriminator’s decisions are not affected by the pres-
This means that we can only predict privacy gain if we can ence of a single record in the model’s training set by more
(1) predict what features a potential adversary will target and than the defined ε-bound [32].
(2) whether the synthetic data has preserved these features
from the raw data. In practice, neither of these factors is pre- 5.1 Empirical evaluation
dictable. First, like traditional linkage attacks on microdata
releases, a strategic adversary might use any set of features We used the experimental procedure described in Section 4.3
that are likely to be influenced by the target’s presence [43]. to evaluate the privacy gain of PrivBay and PATEGAN. We
7Original Adjusted
1.6
1.4
categories or a shift in the ranges of continuous attributes in
1.2 synthetic datasets sampled from the trained model.
1.0
0.8 To avoid this leakage, we patched the PrivBay and
PG
0.6
0.4 PATEGAN implementations so that both models obtain meta-
0.2
0.0 data as an independent input to their training process. In our
1.6
1.4 experiments with the Texas dataset, we used the publicly
1.2
1.0 available data description to define possible categorical val-
0.8
ues and a disjoint subset of the data (population records from
PG
0.6
0.4
0.2
a different year) to obtain an estimate of the expected ranges
0.0 of numerical attributes. For the Adult dataset, where no com-
BayNet PrivBay PATEGAN BayNet PrivBay PATEGAN
parable metadata is available, we used the dataset to estimate
Figure 3: Per-record privacy gain for five outlier targets categories and ranges and generalised each range to hide the
records from the Texas (top row) and Adult (bottom row) exact value of outlier targets.
datasets under an attack using the FHist feature set. Fig. 3 right shows the results of our evaluation under the
patched implementations. For most outliers, privacy gain is
now bounded by its differential privacy guarantee. For those
integrated the implementations of these algorithms provided targets where the expected gain remains below its bound,
by Ping et al. [12] and Jordon et al. [70] into our framework the remaining gap can likely be explained either by other
and ran the linkability game defined in Fig. 1. aspects of the model’s implementation that violate theoretical
assumptions and we were not able to find in our analysis, or
Differential privacy violations. Fig. 3 left shows the results due to correlations between the datasets used to derive the
of this experiment for the Texas (top row) and Adult (bottom necessary metadata and the model’s training set. Further work
row) datasets under an attack using the histogram feature set is needed to fully understand this problem.
FHist – the overall most effective attack. Both differentially
Conclusions. Differentially private generative models can
private models were trained with privacy parameter ε = 0.1.
provide a significantly higher privacy gain with respect to
Surprisingly, we find that neither the original implementation
linkage attacks than traditional data synthesis algorithms. To
of PrivBay nor PATEGAN reliably prevents linkage attacks.
achieve the desired protection it is necessary that, besides a
Two out of the five outliers in the Texas dataset achieve close
theoretically sound design, the models’ implementation and
to no gain ( and with PG < 0.1). This low gain violates
operational environment does not break any of the privacy def-
the theoretical lower bound on privacy provided by Yeom
inition’s theoretical assumptions. Our evaluation confirms that
et al. [69] (shown as a dashed line in Fig. 3). The bound
otherwise there is no guarantee that outliers will be protected
given by Yeom et al. [69] limits the expected advantage of the
from linkage attacks.
membership inference adversary to AdvL ≤ eε − 1 which
While in our experimental setup we were (mostly) able
implies PG ≥ 0.89 for ε = 0.1.
to avoid undesired privacy leakage through metadata, it is
Unexpected leakage. To understand these findings, we con- unlikely that in practice data holders will be able to follow
ducted an in-depth analysis of the design and implementation our example. Data holders likely do not have access to either
of both algorithms. Alongside some minor bugs, our anal- a disjoint subset or a public dataset from the same distribution
ysis revealed that, while both models on paper fulfil their that would allow them to define metadata that fits the raw
formal privacy definitions, their available implementations data they would like to share. Synthetic data sharing is often
did not. Both PrivBay and PATEGAN require metadata about a motivated by the unique value of sensitive dataset that are
model’s training set to operate. For instance, data holders need limited in size. This implies that, in practice, data holders
to specify upfront the range of numerical attributes and the might struggle to achieve the desired strict privacy guarantees,
possible values of categorical attributes. To improve usabil- or face a large utility loss when either using public data or
ity, the existing implementations of PrivBay and PATEGAN splitting the available data to derive the necessary metadata.
learn this metadata directly from the input dataset. This pro- In Section 6.3, we empirically demonstrate this tradeoff.
cess, in which algorithmic decisions are based on the raw
data, violates important assumptions of the differential privacy
model [18]. This discovery explained our previous results: 6 Does synthetic data improve the privacy-
Both models extracted crucial information from their input utility tradeoff of sanitisation?
data in a process not covered by the formal privacy guarantee.
As a result, targets with rare categorical attributes or whose Synthetic data is often presented as “a new, better alternative
presence affects the ranges of numerical attributes remained to sanitised data release [...] that not only maintains the nu-
highly vulnerable to our attack. Their presence in a model’s ances of the original data, but does so without endangering
training set became detectable due to the occurrence of new important pieces of personal information” [5]. Our results in
8FNaive FHist FCorr
previous sections show that synthetic data fulfils the latter part 1.4
1.2
of this promise only partially. Data synthesis algorithms with- 1.0
0.8
PG
out any formal privacy guarantees leave outliers vulnerable 0.6
0.4
to linkage attacks. Differentially private generative models, 0.2
0.0
although hard to implement, reduce these risks. This makes San BayNet ε : 10 ε : 1 ε : 0.1 San BayNet ε : 10 ε : 1 ε : 0.1 San BayNet ε : 10 ε : 1 ε : 0.1
differentially private synthetic data generation look like a
promising alternative to traditional sanitisation. The ques- Figure 4: Per-record privacy gain for five outlier target records
tion remains, however, whether synthetic data can achieve a from the Texas dataset under three different attacks using
higher gain in privacy at a lower cost in utility compared to three distinct feature sets.
traditional sanitisation.
In this section, we assess the privacy-utility tradeoff of syn-
PG ≥ 0.8 under all three feature sets). Others remain highly
thetic data publishing and compare it to that of traditional
vulnerable to linkage attacks and receive a substantially lower
sanitisation. For our comparison, we implement a sanitisa-
gain ( , , with PG ≤ 0.3 for at least one attack).
tion procedure described by NHS England [46] and assess its
BayNet improves the privacy gain for the latter group: The
privacy gain with respect to the risk of linkability (see Sec-
three targets that under sanitisation receive close to no pro-
tion 4.1) and the risk of inference formalised in Section 6.2.
tection from linkage attacks using the naive feature set FNaive
NHS Sanitisation procedure. A sanitisation procedure S ← obtain a higher minimum gain ( , , with PG ≥ 0.48). Dif-
San(R) is a deterministic function that applies a set of pre- ferentially private model training further improves protection
defined row-level transformations to the input data R to pro- and minimum gain increases as ε decreases (PG = 0.77 for
duce a sanitised dataset S that fulfils a heuristic privacy defi- target under ε = 10 and PG = 0.97 under ε = 1.0). This in-
nition [58]. Common transformations are generalisation, per- dicates that synthetic data produced by either model (BayNet
turbation, or deletion of single rows [3]. Following the de- and PrivBay) hides changes in the raw data features caused
tails given in [46], we implemented a simple sanitisation by the target’s presence and prevents the adversary from in-
procedure San that reduces the granularity of categorical at- ferring the target’s secret. This gain in privacy, however, is
tributes through grouping, generalises any granular timing or not constant across the population. One out of the five targets
geographical information, removes any rows with rare cate- actually loses protection from linkage attacks when sharing a
gorical values, caps numerical values to the attribute’s 95% synthetic instead of the sanitised dataset ( with PG = 0.62
quantile, and enforces k-anonymity for a pre-defined set of for BayNet and PG = 0.91 for PrivBay with ε = 10 instead
demographic attributes. of PG = 1.0 for San under FCorr ).
This variability in privacy gain highlights one of the major
6.1 Privacy gain with respect to linkability drawbacks of synthetic data sharing as a privacy mechanism:
unpredictability. Due to the deterministic nature of row-level
To compare the privacy gain of sanitised and synthetic data sanitisation, the privacy gain of traditional anonymisation
publishing, we repeat the experimental procedure from Sec- is largely predictable. The high gain in privacy for and
tion 4.3. We adapt the game so that the challenger C , instead under San is constant across all three feature sets. In contrast,
of generating a synthetic dataset S from a trained model g(R) the privacy gain under BayNet and PrivBay is much more
(lines 10 to 11 in Fig. 1), produces a sanitised version of variable. Before model fitting and an empirical analysis, it is
R through a pre-defined sanitisation procedure S ← San(R). not possible to predict whether an individual record’s signal
When the adversary receives a sanitised dataset (b = 1), she will be preserved and what will be its minimum privacy gain.
first attempts literal record linkage. Only if the adversary can
not uniquely identify a record that matches the target, she 6.2 Privacy gain with respect to attribute in-
attempts classification. As in previous sections, we first train ference
the adversary on a reference dataset RA and then instantiate
the game multiple times for each of the selected targets. The risk of linkability is not the only concern in the con-
Fig. 4 compares the results of this experiment for the five text of privacy-preserving data sharing (see Section 3). Data
outlier targets from the Texas dataset for three different data anonymisation also aims to protect individuals in the raw data
sharing mechanisms: traditional sanitisation San with k = from inference attacks. The risk of inference describes the
10, synthetic data produced by BayNet-trained models, and concern that an adversary might “deduce, with significant
differentially private synthetic data sampled from PrivBay probability, the value of an attribute from the values of a set
models with varying ε values. The same experiment on the of other attributes” [3].
Adult dataset yields similar results.
6.2.1 Formalising attribute inference
As expected, the privacy gain of row-level sanitisation tends
to be binary: Target records that are likely to be removed from To evaluate privacy gain with respect to attribute inference,
the shared dataset receive close to perfect gain ( and with we define a privacy game similar to the attribute inference
9experiment proposed by Yeom et al. [69]. attribute inference as:
In the attribute inference game, shown in Fig. 5, the
adversary only has access to a partial target record r˜t =
AdvI (X, r˜t ) , P [r̂s = rs |st = 1] − P [r̂s = rs |st = 0] (5)
(r1 , · · · , rk−1 ) and aims to infer the value of a sensitive, un-
known attribute rs . At the start of the game, the adversary where r̂s = A I (X, b, r˜t , P ) is the adversary’s guess about
picks a target from the population R̃ , a set of records from the the target’s sensitive attribute rs given dataset X and prior
same domain as R but with the sensitive attribute removed. knowledge P .
The challenger receives the partial target record and assigns
it a secret value rs ← φ(r˜t ) where φ represents the projection Adversarial strategy. The procedure to estimate AdvI and
of a partial record from R̃ into the domain of the sensitive the adversary’s strategy to make a guess about the target’s sen-
attribute according to the distribution DR . C then follows sitive value depends on the domain of the sensitive attribute
the same procedure as in the linkability game. The adversary rs , the value of the public bit b and whether S is a synthetic
obtains the dataset X and the public bit b and outputs a guess or sanitised dataset.
about the target’s sensitive attribute value r̂s . This game can When C publishes a raw or sanitised dataset, the adver-
be easily adapted for sanitisation by replacing lines 12 and sary first attempts to infer the missing value via record link-
13 to produce a sanitised version of R through a pre-defined age [16,39,52]. If the adversary can link the target to a unique
sanitisation procedure, S ← San(R). record in the dataset X based on its known attributes, she
can
reconstruct the target’s missing value with probability
P A I (X, b, r˜t , P ) = rs |st = 1 = 1.
A (P ) C (R ) When linkage fails, i.e., C publishes a raw dataset without
the target, a sanitised dataset that hides the target’s presence
# Pick Target
or a synthetic dataset, the adversary uses the published data to
1: r˜t ∈ R̃ r˜t
2: train a supervised ML model to predict the target’s sensitive
# Assign sensitive
value based on the known attributes r˜t . To learn a mapping
3: rs ← φ(r˜t )
from known to sensitive attributes, the adversary splits the
4: r t ← (r˜t , rs ) dataset X into two parts: A feature matrix X̃ that contains the
# Sample raw data values for all attributes known to the adversary and a vector x s
5: R ∼ DRn−1 with the corresponding sensitive attribute values. Depending
# Draw secret bit on the domain of x s , the adversary can either train a regression
6: st ∼ {0, 1} or classification model using X̃ as input features and xs as
7: If st = 0 : labels. The trained attack model, denoted as h(·), takes as
input a partial record containing the set of known attributes
# Add random record
and outputs a guess about the label x̂s ← h(x̃).
8: r ∗ ∼ DR \rrt
9: R ← R ∪ r∗
Implementation. We implement the adversary A I as an in-
stantiation of our framework’s PrivacyAttack class (see
10 : If st = 1 :
Appendix 8.2). For continuous sensitive attributes with rs ∈ R,
# Add target we implement the attack h(·) using a simple linear regression
11 : R ← R ∪ rt model provided by the sklearn library [49]. We centre all
# Train model features extracted from the input data and fit a linear model
12 : g(R) ∼ GM(R) without intercept. The model fits linear coefficients that min-
# Sample synthetic imise the root mean squared error between the observed and
m
13 : S ∼ Dg(R) predicted target values. We analytically calculate the adver-
# Draw public bit sary’s probability of success P [r̂s = rs |st ] as the likelihood
14 : b ∼ {0, 1} of the true value under the learned linear coefficients (see
15 : if b = 0 : X ← R Appendix 8.4 for details). For categorical attributes, we use a
16 : elif b = 1 : X ← S
simple Random Forests classifier as attack model and estimate
17 : X, b the attack’s success via its classification accuracy.
# Make a guess
18 : r̂ ← A I (X, b, r˜ , P )
Empirical evaluation. Fig. 6 shows the privacy gain of the
s t
three data release mechanisms, sanitisation via San and syn-
Figure 5: Attribute inference privacy game thetic data produced by BayNet and PrivBay-models with
varying ε values, for the five outlier targets from the Texas
dataset for two distinct sensitive attributes. We chose one con-
Similar to Eq. 2, we define the adversary’s advantage to tinuous (LengthOfStay) and one categorical attribute (Race)
assess the leakage of publishing dataset X with respect to that might be considered sensitive patient information.
10LengthOfStay Race
1.2 that the anonymised data still contains enough information
1.0
0.8 specific to the target record to give the adversary a significant
0.6 advantage or it implies that already publishing the raw data
PG
0.4
0.2 did not incur a significant privacy loss. Where necessary, our
0.0
−0.2 framework allows data holders to make a distinction between
−0.4 those two cases based on the reported privacy loss. In both
San BayNet ε : 10 ε : 1.0 ε : 0.1 San BayNet ε : 10 ε : 1.0 ε : 0.1
cases, however, a low gain signals that publishing the syn-
Figure 6: Per-record privacy gain for five outlier target records thetic or sanitised data does not provide any improvement
from the Texas dataset for two distinct sensitive attributes. over publishing the raw data R. We also observe that there are
records for which privacy gain is high: the dataset published
Race in place of the raw data successfully hides information about
1.0 these records. While this might be good news for privacy, it
0.8 comes, as we show in the next sections, at a cost in utility.
0.6
AdvI
0.4
0.2
6.3 Utility loss comparison
0.0 The promise of synthetic data is that its improvement in pri-
Raw San BayNet PrivBay vacy gain over traditional sanitisation comes at a negligible
cost in utility. In this section, we empirically evaluate the
Figure 7: Probability of success and advantage for an at- utility loss of synthetic data sharing and compare it to that of
tribute inference attack on attribute Race on the Texas dataset. row-level sanitisation.
P [r̂s = rs |st = 0], P [r̂s = rs |st = 1], and AdvI . Data
Utility metrics. Besides its potential privacy benefits, sharing
shown for PrivBay with ε = 1.
a synthetic in-place of the original dataset incurs certain risks,
such as the risk of false conclusions [2] or the risk of exacer-
bating existing biases in the data [9]. The goal of our utility
For the continuous attribute LengthOfStay, synthetic data
evaluation is to assess to which extent the privacy gain of
produced by either BayNet or PrivBay provides close to per-
synthetic data observed in previous sections (see Section 6.1
fect gain for all five targets while row-level sanitisation via
and 6.2) increases these risks and reduces data utility.
San marginally reduces the adversary’s advantage for three
The concepts of utility and utility loss of course are highly
out of the five targets ( , , with PG ≤ 0.2). This implies
dependent on the data use case and different utility metrics
that, in contrast to the sanitised datasets, synthetic data does
might yield vastly different results [55, 66]. Therefore, in
not preserve the targets’ signal. Even when the generative
practice data holders should conduct their own evaluation
model’s training set includes the target record, synthetic data
based on appropriate utility definitions when weighing off the
sampled from the trained model does not contain any patterns
risks and benefits of (anonymised) data sharing.
that allow the adversary to infer the target’s sensitive value
In this work, we chose a set of simple utility function that
and hence AdvI (S, r t )
AdvI (R, r t ). When the attack targets
aim to cover a wide range of synthetic data use cases sug-
the categorical attribute Race, the privacy gain of synthetic
gested in the literature and reported to us by practitioners.
data publishing does not significantly increase over that of
First, we evaluate in Section 6.3.1 the utility of synthetic data
sanitised data publishing. Even differentially private gener-
for use cases that rely on aggregate population metrics, such
ative model training with ε = 0.1 does not guarantee a high
as reporting of summary statistics or training machine learn-
privacy gain.
ing models [55, 73]. Second, in Section 6.3.2, we turn to one
To explain this low gain, we plot in Fig. 7 for the target of the main selling points brought forward by proponents
marked as the adversary’s probability of success on dataset of synthetic data as a privacy technology: That it enables
X when the target is in the dataset ( st = 1), when it is the analysis of more fine-grained statistical patterns than ag-
not ( st = 0), and the resulting adversary’s advantage ( gregate query release mechanisms, including the analysis of
AdvI ). The figure shows that the low privacy gain observed outliers. Financial fraud and medical anomaly detection are
in Fig. 6 results from the fact that the adversary’s advantage two of the most commonly suggested synthetic data use cases
is already small when the adversary receives the raw data R. largely based on the analysis of outliers [40, 63].
Thus, publishing a sanitised or synthetic data instead of the The latter class of use cases further motivates us to focus on
raw data does not lead to any substantial gain in privacy for the privacy gain and utility loss of outlier records. A simple
this target. way to improve privacy gain for these most vulnerable records
Conclusions. Depending on the attribute targeted by the at- would be to remove them from the dataset, as the high privacy
tack, the privacy gain of synthetic and sanitised data publish- gain for targets and under San in Fig. 4 demonstrates.
ing varies substantially. A low gain in privacy either indicates Directly removing vulnerable records from the raw data in-
11You can also read