Scalable Privacy-Preserving Distributed Learning
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Proceedings on Privacy Enhancing Technologies ; 2021 (2):323–347 David Froelicher*, Juan R. Troncoso-Pastoriza, Apostolos Pyrgelis, Sinem Sav, Joao Sa Sousa, Jean-Philippe Bossuat, and Jean-Pierre Hubaux Scalable Privacy-Preserving Distributed Learning Abstract: In this paper, we address the problem of privacy-preserving distributed learning and the eval- 1 Introduction uation of machine-learning models by analyzing it in The training of machine-learning (ML) models usually the widespread MapReduce abstraction that we extend requires large and diverse datasets [133]. In many do- with privacy constraints. We design spindle (Scalable mains, such as medicine and finance, assembling suffi- Privacy-preservINg Distributed LEarning), the first dis- ciently large datasets has proven difficult [128] and of- tributed and privacy-preserving system that covers the ten requires the sharing of data among multiple data- complete ML workflow by enabling the execution of a providers. This is particularly true in medicine, where cooperative gradient-descent and the evaluation of the patients’ data are spread among multiple entities: For obtained model and by preserving data and model confi- example, for rare diseases, one hospital might have only dentiality in a passive-adversary model with up to N −1 a few patients, whereas a medical study requires hun- colluding parties. spindle uses multiparty homomor- dreds of them to produce significant results. Data shar- phic encryption to execute parallel high-depth compu- ing among many entities, which can be located in multi- tations on encrypted data without significant overhead. ple countries, is hence required. However, when the data We instantiate spindle for the training and evaluation are sensitive and/or personal, they are particularly dif- of generalized linear models on distributed datasets and ficult to share. Data sharing is highly restricted by legal show that it is able to accurately (on par with non- regulations, such as GDPR [43] in Europe. The financial secure centrally-trained models) and efficiently (due to and reputational consequences of a data breach often a multi-level parallelization of the computations) train make the risk of data sharing higher than its potential models that require a high number of iterations on benefits. Hence, it is often impossible to obtain suffi- large input data with thousands of features, distributed cient data to train ML models that are key enablers in among hundreds of data providers. For instance, it medical research [90], financial analysis [115], and many trains a logistic-regression model on a dataset of one other domains. million samples with 32 features distributed among 160 To address this issue, privacy-preserving solutions data providers in less than three minutes. are gaining interest as they can be key-enablers for Keywords: federated learning, multiparty homomor- ML with sensitive data. Many solutions have been pro- phic encryption, decentralized system, generalized lin- posed for secure predictions that use pre-trained mod- ear models els [12, 17, 45, 61, 78, 104–106]. However, the secure DOI 10.2478/popets-2021-0030 training of ML models, which is much more computa- Received 2020-08-31; revised 2020-12-15; accepted 2020-12-16. tionally demanding, has been less studied. Some cen- tralized solutions [7, 15, 23, 29, 50, 60, 63, 66] that rely on homomorphic encryption (HE) were proposed. They have the advantage of being straightforward to implement but require individual records to be trans- ferred out of the control of their owners, which is of- ten not possible, e.g., due to data protection legisla- tion [62, 77]. Also, the data are moved to a central *Corresponding Author: David Froelicher: Laboratory for Data Security (LDS), EPFL, E-mail: repository, which can become a single point of failure. david.froelicher@epfl.ch Secure multiparty computation solutions (SMC) pro- Juan R. Troncoso-Pastoriza, Apostolos Pyrgelis, posed for this scenario [3, 28, 42, 44, 57, 88, 95], of- Sinem Sav, Joao Sa Sousa, Jean-Philippe Bossuat, ten assume that a limited number of computing par- Jean-Pierre Hubaux: Laboratory for Data Security (LDS), ties are honest-but-curious and non-colluding. These as- EPFL, E-mail: name.surname@epfl.ch sumptions might not hold when the data are sensitive
Scalable Privacy-Preserving Distributed Learning 324 and/or when the parties have competing interests. In uses the MapReduce abstraction [31] that is often used contrast, homomorphic encryption-based (HE) or hy- to define distributed ML tasks [27, 118]. MapReduce de- brid (HE and SMC) solutions [41, 131] that assume a fines parallel and distributed algorithms in a simple and malicious threat model (e.g., Anytrust model [123]) fo- well-known abstraction: prepare (data preparation), cus on limited ML operations (e.g., the training of reg- map (distributed computations executed independently ularized linear models with low number of features) and by multiple nodes or machines), combine (combination are not quantum secure. Recent advances in quantum of the map results, e.g., aggregation) and reduce (com- computing [47, 56, 114, 127] have made this technology putation on the combined results). We build on and ex- a potential threat, in a not-so-far future, for existing tend this abstraction to determine and delimit which cryptographic solutions [89]. Google recently announced information, e.g., map outputs, have to be protected to that they have reached "quantum-supremacy" [49]. Even design a decentralized privacy-preserving system for though quantum computers are still far from being able ML training and prediction. The model is locally trained to break state-of-the-art cryptoschemes, we note that by the DPs (map) and the results are iteratively com- certain data (e.g., genomics) remain sensitive over a long bined (combine) to update the global model (reduce). period and will be at risk in the future. We exploit the partitioned (distributed) data to enable Finally, federated learning, a non-cryptographic ap- DPs to keep control of their respective data, and we proach for privacy-preserving training of ML models, distribute the computation to provide an efficient so- has recently gained interest. The data remain under lution for the training of ML models on confidential the control of their owners and a server coordinates data. After the training, the model is kept secret from the training by sending the model directly to the data all entities and is obliviously and collectively used to owners, which then update the model with their data. provide predictions on confidential data that are known The updated models from multiple participants are av- only to the entity requesting the prediction. We remark eraged to obtain the global model [68, 82]. Recent works that differential-privacy-based federated-learning solu- have shown that sharing intermediate models with a co- tions [2, 22, 34, 55, 59, 64, 72, 99, 111, 117] follow the ordinating server, or among the participants, can lead same model, i.e., they can be defined according to the to various privacy attacks, e.g., extracting participants’ MapReduce abstraction. However, most solutions intro- inputs [54, 122, 132] or membership inference [84, 92]. duce a trade-off between accuracy and privacy [58], and To address these problems, multiple works [72, 83, 111] do not provide data and model confidentiality simulta- rely on a differentially private mechanism to obfuscate neously. On the contrary, our solution uses a different the intermediate values. However, this obfuscation de- paradigm in which, similarly to non-secure solutions, creases the data and model utility, whereas the training the accuracy is traded off with the performance (e.g., of accurate models requires high privacy budgets and number of iterations), but not with privacy. the achieved privacy level remains unclear [58]. We propose spindle (Scalable Privacy-preservINg Existing cryptographic distributed solutions are Distributed LEarning), a system that enables the practical with only a small number of parties and most privacy-preserving, distributed (cooperative) execution of the aforementioned solutions focus either on training of the widespread stochastic mini-batch gradient- or on prediction. They neither consider the complete descent (SGD) on data that are stored and controlled by ML workflow nor enable the training of a model that multiple DPs. spindle builds on a state-of-the-art mul- remains secret and enables oblivious prediction on con- tiparty, lattice-based, quantum-resistant cryptographic fidential data. In many cases, the trained model is as scheme to ensure data and model confidentiality, in the sensitive as the data on which it is trained, and the use passive-adversary model in which all-but-one DPs can of the model after the training has to be tightly con- be dishonest. spindle is meant to be a generic and trolled. ML is used in very competitive domains and a widely-applicable system that supports the SGD-based balance has to be found between collaboration and com- training of many different ML models. This includes, petition [90, 113]. For example, entities that collaborate but is not limited to, support vector machines, graph- to train a ML model should equally benefit from the ical models, generalized linear-models and neural net- resulting model. works [33, 48, 69, 116, 130]. For concreteness and com- In this paper, we address the problem of privacy- parison with existing works, we instantiate spindle for preserving learning and prediction among multiple par- the training of and prediction on generalized linear mod- ties, i.e., data providers (DPs), that do not trust each els (GLMs) [93], (e.g., linear, logistic and multinomial other. To address this issue, we design a solution that logistic regressions). GLMs are easily interpretable, cap-
Scalable Privacy-Preserving Distributed Learning 325 ture complex non-linear relations (e.g., logistic regres- To the best of our knowledge, spindle is the first opera- sion), and are widely-used in many domains such as tional system that provides the aforementioned features finance, engineering, environmental studies and health- and security guarantees. care [76]. In a realistic scenario where a dataset of 11,500 samples and 90 features is distributed among 10 DPs, spindle efficiently trains a logistic regression model in less than 54 seconds, achieving an accuracy of 83.9%, 2 Related Work equivalent to a non-secure centralized solution. The dis- tribution of the workload enables spindle to efficiently Privacy-Preserving Training of Machine Learn- cope with a large number of DPs (parties), as its execu- ing Models. Some works have focused on securely out- tion time is practically independent of it. spindle han- sourcing the training of linear ML models to the cloud, dles a large number of features, by optimizing the use of typically by using homomorphic encryption (HE) tech- the cryptosystem’s packing capabilities, and by exploit- niques [7, 15, 29, 50, 63, 66, 100]. For instance, Graepel ing single-instruction multiple-data (SIMD) operations. et al. [50] outsource the training of a linear classifier by It is able to perform demanding training tasks, with high employing somewhat HE [38], whereas Aono et al. [7] number of iterations and thus high-depth computations, approximate logistic regression, and outsource its com- by relying on the multiparty cryptoscheme’s ability to putation to the cloud by using additive HE [97]. Jiang collectively refresh a ciphertext with no significant over- et al. [60] present a framework for outsourcing logistic head. As shown by our evaluation, these properties en- regression training to public clouds by combining HE able spindle to support training on large and complex with hardware-based security techniques (i.e., Software data such as imaging or medical datasets. Moreover, Guard Extensions). In spindle, we consider a substan- spindle scalability over multiple dimensions (features, tially different setting where the sensitive data are dis- DPs, data) represents a notable improvement with re- tributed among multiple (untrusted) data providers. spect to state-of-the-art secure solutions [41, 131]. Along the research direction of privacy-preserving In this work, we make the following contributions: distributed learning, most works operate on the two- server model, where data owners encrypt or secret-share – We analyze the problem of privacy-preserving dis- their data among two non-colluding servers that are tributed training and of the evaluation of ML models responsible for the computations. For instance, Niko- by extending the widespread MapReduce abstraction laenko et al. [95] combine additive homomorphic en- with privacy constraints. Following this abstraction, cryption (AHE) and Yao’s garbled circuits [125] to we instantiate spindle, the first operational and ef- enable ridge regression on data that are horizontally ficient distributed system that enables the privacy- partitioned among multiple data providers. Gascon et preserving execution of a complete machine-learning al. [42] extend Nikolaenko et al. work [95] to the case workflow through the use of a cooperative gradient of vertically partitioned datasets and improve its com- descent on a dataset distributed among many data putation time by employing a novel conjugate gradient providers. descend (GD) method, whereas Giacomelli et al. [44] – We propose multiple optimizations that enable the further reduce computation and communication over- efficient use of a quantum-resistant multiparty (N- heads by using only AHE. Akavia et al. [3] improve party) cryptographic scheme by relying on parallel the performance of Giacomelli et al. protocols [44] by computations, SIMD operations, efficient collective performing linear regression on packed encrypted data. operations and optimized polynomial approximations Mohassel and Zhang [88] develop techniques to han- of the models’ activation functions, e.g., sigmoid and dle secure arithmetic operations on decimal numbers, softmax. and employ stochastic GD, which, along with multi- – We propose a method for the parameterization of party-computation-friendly alternatives for non-linear spindle by capturing the relations among the secu- activation functions, supports the training of logistic rity and the learning parameters in a graphical model. regression and neural network models. Schoppmann et – We evaluate spindle against centralized and decen- al. [108] propose data structures that exploit data spar- tralized secure solutions and demonstrate its scalabil- sity to develop secure computation protocols for nearest ity and accuracy. neighbors, naive Bayes, and logistic regression classifi- cation. spindle differs from these approaches as it does
Scalable Privacy-Preserving Distributed Learning 326 not restrict to the two non-colluding server model, and ML prediction, where a party (e.g., a cloud provider) focuses instead on N-party systems, with N>2. holds an already trained ML model on which another Other distributed and privacy-preserving ML ap- party (e.g., a client) wants to evaluate its private input. proaches employ a three-server model and rely on secret- In this setting, Bost et al. [17] use additive HE tech- sharing techniques to train linear regressions [13], logis- niques to evaluate naive Bayes and decision tree classi- tic regressions [26], and neural networks [87, 119]. How- fiers, whereas Gilad-Bachrach et al. [45] employ fully ho- ever, such solutions are tailored to the three-party server momorphic encryption (FHE) [16] to perform prediction model and assume an honest majority among the com- on a small neural network. The computation overhead puting parties. An honest majority is also required in the of these approaches has been further optimized by using recent work of Rachuri and Suresh [103], who improve multi-party computation (MPC) techniques [104, 106], on Mohassel and Rindal [87] performance by extending or by combining HE and MPC [61, 78, 102]. Riazi its techniques to the four-party setting. Other works fo- et al. [105] evaluate deep neural networks by employ- cus on the training of ML models among N-parties (N ing garbled circuits and oblivious transfer, in combina- > 4), with stronger security assumptions, i.e., each party tion with binary neural networks. Boemer et al. [12] trusting itself. For instance, Corrigan-Gibbs and Boneh propose nGraph-HE2, a compiler that enables service [28] present Prio, which relies on secret-sharing to en- providers to deploy their trained ML models in a able the training of linear models, and Zheng et al. [131] privacy-preserving manner. Their method uses HE, or propose Helen, a system that uses HE [97] and verifiable a hybrid scheme that combines HE with MPC, to com- secret sharing [30] to execute ADMM [19] (alternating pile ML models that are trained with well-known frame- direction method of multipliers, a convex optimization works such as TensorFlow [1] and PyTorch [98]. The approach for distributed data), which supports regular- scope of our work is broader than these approaches, as ized linear models. Similarly, Froelicher et al. [41] em- spindle accounts not only for the private evaluation ploy HE [35], along with encoding techniques, to enable of machine-learning models but also for their privacy- the training of basic regression models and provide au- preserving training in the distributed setting. ditability with the use of zero-knowledge proofs. spin- dle enables better scalability in terms of the number of model’s features, size of the dataset and number of data providers, and it offers richer functionalities by relying 3 Secure Federated Training and on the generic and widely-applicable SGD. Evaluation Another line of research considers the use of dif- ferential privacy for training ML models. Early works We first introduce the problem of privacy-preserving [2, 22] focus on a centralized setting where a trusted distributed training and evaluation of machine-learning party holds the data, trains the ML model, and per- (ML) models. Then, we present a high-level overview forms the noise addition. Differential privacy has also and architecture of a solution that satisfies the security been envisioned in distributed settings, where to col- requirements of the presented problem. In Section 4, lectively train a model, multiple parties exchange or we present spindle, a system that enables the pri- send differentially private model parameters to a cen- vacy preserving and distributed execution of a stochas- tral server [34, 55, 72, 111]. However, the training of tic gradient-descent. We instantiate our solution for the an accurate collective model requires very high privacy training and evaluation of the widely-used Generalized budgets and, as such, it is unclear what privacy protec- Linear Models [93]. In the rest of this paper, matrices tion is achieved in practice [54, 58, 122]. To this end, are denoted by upper-case-bold characters and vectors some works consider hybrid approaches where differen- by lowercase-bold characters; the i-th row of a matrix tial privacy is combined with HE [64, 99], or multi-party X is depicted as X[i, ·], and its i-th column as X[·, i]. computation techniques [59, 117]. We consider differen- Similarly, the i-th element of a vector y is denoted by tial privacy as an orthogonal approach; these techniques y[i]. We provide a list of recurrent symbols in Table 6 can be combined with our solution to protect the re- (see Appendix G). sulting models and their predictions from inference at- tacks [39, 112], see Section 8.1. Privacy-Preserving Prediction on ML Models. Another line of work is focused on privacy-preserving
Scalable Privacy-Preserving Distributed Learning 327
3.1 Problem Statement
We consider a setting where a dataset (Xn×c , yn ), with
Xn×c a matrix of n records and c features, and yn Fig. 1. spindle’s Model. Thick arrows represent a possible (effi-
a vector of n labels, is distributed among a set of cient) query-execution flow.
data providers, i.e., S = {DP1 , . . . , DP|S| }. The dataset
is horizontally partitioned, i.e., each data provider 3.2 Solution Overview
DPi holds a partition of ni samples (X (i) , y (i) ), with
P|S|
i=1 ni = n. A querier, which can also be a data To address the problem of privacy-preserving dis-
provider (DP), requests the training of a ML model on tributed learning, we leverage the MapReduce abstrac-
the distributed dataset (Xn×c , yn ) or the evaluation of tion, which is often used to capture the parallel and
an already trained model on its input (X 0 , ·). repetitive nature of distributed learning tasks [27, 118].
We assume that the DPs are willing to contribute We complement this abstraction with a protection
their respective data to train and to evaluate ML models mechanism P (·); P (x) denotes that value x has to be
on the distributed dataset. To this end, DPs are all inter- protected to satisfy data and model confidentiality (Sec-
connected and organized in a topology that enables effi- tion 3.1). We present the extended MapReduce ab-
cient execution of the computations, e.g., in a tree struc- straction in Protocol 1. In prepare, the data providers
ture as depicted in Figure 1. Even though the DPs wish (DPi ∈ S) pre-process their data (X (i) , y (i) ), they agree
to collaborate for the execution of ML workflows, they on the learning parameters and on one data provider
do not trust each other. As a result, they seek to protect that plays the role of DPR and is then responsible for
the confidentiality of their data (used for training and the execution of reduce. As explained later, DPR only
evaluation) and of the collectively learned model. More manipulates protected data and is subject to the same
formally, we require that the following privacy proper- security constraints as any other DP. We discuss the
ties hold in a passive-adversary model in which all-but- choice of DPR and its availability in Section 8. Each
one DPs can collude, i.e., the DPs follow the protocol, DPi then iteratively (g iterations) trains its local model
but up to |S| − 1 DPs might share among them the in- (P (W (i,j) ) at iteration j) on its data in map. They
formation they observe during the execution, to extract combine their local models in combine (through an
information about the other DPs’ inputs. application-dependent function C(·)), and update the
(·,j)
(a) Data Confidentiality: The training data of each global model P (WG ) in reduce. To capture the com-
data provider DPi , i.e., (X (i) , y (i) ) and the querier’s plete ML workflow, we extend the MapReduce archi-
evaluation data (X 0 , ·) should remain only known to tecture with a prediction phase in which predictions
their respective owners. To this end, data confidential- P (y 0 ) are computed from the querier’s protected evalu-
ity is satisfied as long as the involved parties (DPs and ation data P (X 0 ) by using the (protected) global model
querier) do not obtain any information about other par- P (WG (·,g) ) obtained during the training.
ties’ inputs other than what can be deduced from the
Protocol 1 Extended MapReduce Abstraction.
output of the process of training or evaluating a model.
(·,g)
training: S receives query from Querier and outputs P (W G )
(b) Model Confidentiality: During the training pro-
1: Each DPi has (X (i) , y (i) )
cess, no data provider DPi should gain more informa- 2: DPs appoint DPR and agree on learning params. – prepare
tion about the model that is being trained than what it
3: Each DPi ∈ S initializes its local model W (i,0)
can learn from its own input data (X (i) , y (i) ). During
4: for j = 1, . . . , g do
prediction, the querier should not learn anything more
5: Each DPi ∈ S computes: – map
about the model than what it can infer from its input (·,j−1)
P (W (i,j) ) ← Map((X (i) , y (i) ), P (WG ), P (W (i,j−1) ))
data (X 0 , ·) and the corresponding predictions y 0 .
6: Each DPi sends P (W (i,j) ) to DPR – combine
We remark here that input correctness and com-
7: DPR : P (W (·,j) ) ← C(P (W (i,j) )), ∀ DPi ∈ S
putation correctness are not part of the problem re- – reduce
quirements, i.e., we assume that DPs input correct data 8: DPR : P (WG (·,j) )←Red(P (WG (·,j−1) ), P (W (·,j) ))
and do not perform wrong computations. We discuss prediction: DP receives P (X 0 ) from Querier and uses
R
possible countermeasures against malicious DPs in Sec- P (WG (·,g) ) to compute P (y 0 ) that is sent back to the Querier
tion 8.1.Scalable Privacy-Preserving Distributed Learning 328 convergence depending on the distributed parameters; 4 SPINDLE Design e.g., the number of iterations and the update func- tion for the global weights [18, 120, 121, 129]; and (iv) Following the extended MapReduce abstraction de- it has been shown to work well even in the case of scribed in Section 3.2, we design a system, named non-independent-and-identically-distributed (non-i.i.d.) spindle, that enables the privacy-preserving execu- data partitions [81, 120, 121]. The data providers (DPs), tion of the widely applicable cooperative gradient de- each of which owns a part of the dataset, locally perform scent [120, 121] – which is used to minimize many cost multiple iterations of the SGD before aggregating their functions in machine-learning [69, 116, 130]. We instan- model weights into the global model weights. The global tiate this system for the training of and prediction on weights are included in subsequent local DP computa- Generalized Linear Models [93]. To implement the pro- tions to avoid that they learn, or descend, in the wrong tection mechanism P (·), it builds on a multiparty fully direction. For simplicity, we present spindle with the homomorphic encryption scheme. We introduce these synchronous CSGD version, where the DPs perform lo- concepts in Section 4.1. Then, in Section 4.2, we describe cal model updates simultaneously. For each DPi , the how spindle instantiates the phases of the extended local update rule at global iteration j and local itera- MapReduce abstraction and how we address the collec- tion l is: tive data-processing on the distributed dataset through (·,j -1) secure and interactive protocols. We demonstrate how w(i,j,l) =w(i,j,l-1) − αζ(w(i,j,l-1) ; B (l) ) − αρ(w(i,j,l-1) − wG ), training is performed, notably by executing the gradient (·,j−1) (1) where wG are the global weights from the last descent operations under homomorphic encryption, and global update iteration j − 1, α is the learning rate and how predictions are executed on encrypted models. We ρ, the elastic rate, is the parameter that controls how present the detailed cryptographic operations in Sec- much the data providers can diverge from the global tion 5 and analyze spindle’s security in Appendix C. model. The set of DPs S performs m local iterations between each update of the global model that is up- dated at global iteration j with a moving average by: 4.1 Background (·,j) (·,j−1) P|S| (i,j,m) wG = (1 − |S|αρ)wG + αρ i=0 w . (2) Cooperative Gradient-Descent. We rely on a dis- Generalized Linear Models (GLMs). GLMs [93] tributed version of the popular mini-batch stochastic are a generalization of linear models where the lin- gradient-descent (SGD) [69, 116, 130]. In the standard ear predictor, i.e., the combination Xw of the feature version of SGD, the goal is to minimize minw [F (w) := matrix X and weights vector w, is related to a vec- Pn (1/n) φ=1 f (w; X[φ, ·])], where f (·) is the loss func- tor of class labels y by an activation function σ such tion defined by the learning model, w ∈ Rc are the that E(y) = σ −1 (Xw), where E(y) is the mean of y. model parameters, and X[φ, ·] is the φth data sam- In this work, we consider the widely-used linear (i.e., ple (row) of X. The model is then updated by m it- σ(Xw) = Xw), logistic (i.e., σ(Xw) = 1/(1 + e−Xw )) and multinomial (i.e., σ(Xwλ ) = eXwλ /( j∈cl eXwj ), P erations w(l) = w(l−1) − α[ζ(w(l−1) ; B (l) )], for l = 1, . . . , m, with α the learning rate, B (l) a randomly for λ ∈ cl) regression models. We remark that for multi- sampled sub-matrix of X of size b × c, and ζ(w; B) = nomial regression, the weights are represented as a ma- B T (σ(Bw) − I(z)), where z is the vector of labels cor- trix Wc×|cl| , where c is the number of features, cl is the responding to the batch B. The activation function σ set of class labels and |cl| its cardinality. In the rest of and I(·) are both model-dependent, e.g., for a logistic the paper, unless otherwise stated, we define the oper- regression σ is the sigmoid and I(·) is the identity. ations on a single vector of weights w and we note that We rely on the cooperative SGD (CSGD) pro- in the case of multinomial regression, they are repli- posed by Wang and Joshi [120, 121], due to its prop- cated on the |cl| vectors of weights, i.e., each column of erties; in particular: (i) modularity, as it can be syn- Wc×|cl| . chronous or asynchronous, and can be combined with Multiparty Homomorphic Encryption. For the classic gradient-descent convergence optimizations such protection mechanism of spindle, we rely on a mul- as Nesterov accelerated SGD [94]; (ii) applicability, as tiparty (or distributed) fully-homomorphic encryption it accommodates any ML model that can be trained scheme [91] in which the secret key is distributed among with SGD and enables the distribution of any SGD the parties, while the corresponding collective public key based solution; (iii) it guarantees a bound on the error- pk is known to all of them. Thus, each party can inde-
Scalable Privacy-Preserving Distributed Learning 329
pendently compute on ciphertexts encrypted under pk (Distributed) Operations: A vector v of cleartext val-
but all parties have to collaborate to decrypt a cipher- ues can be encrypted with the public collective key
text. In spindle, this enables the data providers (DPs) pk and can be decrypted with the collaboration of all
to train a collectively encrypted model, that cannot be DPs (DDec(·) protocol, in which each DPi uses its se-
decrypted as long as one DP is honest and refuses to par- cret key ski ). The DPs can also change a ciphertext
ticipate in the decryption. As we show later, this multi- encryption from the public key pk to another public
party scheme also enables DPs to collectively switch the key pk 0 without decrypting the ciphertext, by relying
encryption key of a ciphertext from pk to another pub- on the DKeySwitch(·) protocol. Each DP can indepen-
lic key without decrypting. In spindle, a collectively dently add, multiply, rotate (i.e., inner-rotation of v),
encrypted prediction result can thus be switched to the rescale Rescale(·) or relinearize Relin(·) a vector en-
querier’s public key, so that only the querier can decrypt crypted with pk. When two ciphertexts are multiplied
the result. together, the result has to be relinearized Relin(·) to
Mouchet et al. [91] propose a multiparty version of preserve the ciphertext size. After multiple Rescale(·)
the Brakerski Fan-Vercauteren (bfv) lattice-based ho- operations, hvi has to be refreshed by a collective pro-
momorphic cryptosystem [38] and introduce interactive tocol, i.e., DBootstrap(·), which returns a ciphertext at
(distributed) protocols for key generation DKeyGen(·), level L. The dot product DM(·) of two encrypted vectors
decryption DDec(·), and bootstrapping DBootstrap(·). of size a can be executed by a multiplication followed
We use an adaptation of this multiparty scheme to the by log2 (a) inner-left rotations and additions. We list all
Cheon-Kim-Kim-Song cryptosystem (ckks) [25] that the operations used in spindle and their properties in
enables approximate arithmetic, and whose security is Appendix A.
based on the ring learning with errors (rlwe) prob-
lem [80]. ckks (See Appendix A) enables arithmetic
over CN/2 ; the plaintext and ciphertext spaces share the 4.2 SPINDLE Protocols
same domain RQ = ZQ [X]/(X N + 1), with N a power
of 2. Both plaintexts and ciphertexts are represented by We first describe spindle’s operations for training a
polynomials of N coefficients (degree N − 1) in this do- Generalized Linear Model following Protocol 1. In this
main. A plaintext/ciphertext encodes a vector of up to case, the model W is a vector of weights that we denote
N/2 values. by w, and map corresponds to multiple local iterations
Parameters: The ckks parameters are denoted by of the gradient descent. Recall that in the case of multi-
the tuple (N, ∆, η, mc), where N is the ring dimen- nomial regression, all operations are repeated for each
sion, ∆ is the plaintext scale, or precision, by which label class λ ∈ cl.
any value is multiplied before being quantized and en-
crypted/encoded, η is the standard deviation of the
noise distribution, and mc represents a chain of moduli 4.2.1 TRAINING
{q0 , . . . , qL } such that Πι∈{0,...,τ } qι = Qτ is the cipher-
text modulus at level τ , with QL = Q, the modulus of PREPARE. The data providers (DPs) collectively
fresh ciphertexts. Operations on a level-τ ciphertext hvi agree on the training parameters: the maximum num-
are performed modulo Qτ , with ∆ always lower than ber of global g and local m iterations, and the learn-
the current Qτ . Ciphertexts at level τ are simply vec- ing parameters lp = {α, ρ, b}, where α is the learn-
tors of polynomials in RQτ , that we represent as hvi ing rate, ρ the elastic rate, and b the batch size. The
when there is no ambiguity about their level, and use DPs also collectively initialize the cryptographic keys for
{hvi, τ, ∆} otherwise. After performing operations that the distributed ckks scheme by executing DKeyGen(·)
increase the noise and the plaintext scale, {hvi, τ, ∆} (see Appendix A). Then, the DPs initialize their local
has to be rescaled (see the ReScale(·) procedure defined weights and pre-compute operations that involve only
in Appendix A) and the next operations are performed their input data (αX (i) I(y (i) ) and αX (i)T ). We discuss
modulo Qτ −1 . When reaching level 0, hvi has to be boot- in Appendix F how the DPs can collaborate to stan-
strapped. The security of the cryptosystem depends on dardize or normalize the distributed dataset (if needed)
the choice of N , Q and η, which in this work are param- and check that their respective inputs are consistent,
eterized to achieve at least 128-bits of security. e.g., they have data distribution homogeneity.Scalable Privacy-Preserving Distributed Learning 330 Protocol 2 map. Protocol 3 Activation Function σ(·). (·,j−1) Each DPi outputs hw(i,j) i ← Map ((X (i) , y (i) ), hwG i, Func. σ(hui or hU i, t) returns the activated hσ(u)i or hσ(U )i hw(i,j−1) i) 1: if t is Linear then hσ(u)i = hui 1: hw(i,j,0) i = hw(i,j−1) i 2: else if t is Logistic then 2: for l = 1, . . . , m : 3: hσ(u)i = apSigmoid(u) 3: Select batch (B, z) of b rows in (X (i) , y (i) ) 4: hu[k]i = DM(B[k, ·], hw(i,j,l−1) i), for k = 1, . . . , b 4: else if t is Multinomial, input is a matrix hUc×|cl| i then 5: hmi = apMax(hU i) 5: hv[e]i = DM(αB[·, e]T , σ(hui)), for e = 1, . . . , c Pb 6: for λ ∈ cl: 6: µ[e] = k=1 αB[·, e]T I(z[k]), for e = 1, . . . , c 7: hU 0 [λ, ·]i = hU [λ, ·]i − hmi 7: hw(i,j,l) i= hw(i,j,l−1) i+µ-hvi 8: hσ(U [λ, ·])i=M(apSoftN(hU 0 [λ, ·]i), apSoftD(hU 0 [λ, ·]i)) -αρ(hw(i,j,l−1) i-hwG (·,j−1) i) 8: hw(i,j) i = RR(hw(i,j,m) i) approximation that is computed by the multiplication of two CAs, one for the nominator ex (apSoftN(·)) and MAP. As depicted in Protocol 2, the DPs execute one for the denominator P1 xj (apSoftD(·)), each com- m iterations of the cooperative gradient-descent local e puted on different intervals. The polynomial approxima- update (Section 4.1). The local weights of DPi (i.e., tion computation is detailed in Protocol 6 (Appendix hw(i,j,l−1) i) are updated at a global iteration j and a B). To avoid an explosion of the exponential values in local iteration l by computing the gradient (Protocol 2, the softmax, a vector hmi that contains the approxi- lines 4, 5, and 6) that is then combined with the cur- (·,j−1) mated max (apMax(·)) value of each column of hU i is rent global weights hwG i (Protocol 2, line 7) fol- subtracted from all input values, i.e., from each hU [λ, :]i lowing Equation 1. These computations are performed with λ = 0, ..., |cl|. Similar to softmax, the approxima- on batches of b samples and c features. To ensure that tion of the max function requires two CAs, and is de- the update of DPi ’s local weights, i.e., the link between tailed in Appendix B. the ciphertexts hw(i,j−1) i = hw(i,j,0) i and hw(i,j,m) i, does not leak information about the DP’s local data, COMBINE. The map outputs of each DPi , i.e., hw(i,j,m) i is re-randomized RR(·) at the end of map, i.e., hw(i,j) i, are homomorphically combined ascending a DPi adds to it a fresh encryption of 0. Note that in Pro- tree structure, such that each DPi aggregates its en- tocol 2, line 5 the activation function σ(·) is computed crypted updated local weights with those of its children on the encrypted vector hui (or a matrix hU i in the and sends the result to its parent. In this case, the com- case of multinomial). The exponential activation func- bination function C(·) is the homomorphic addition op- tions for logistic (i.e., sigmoid) and multinomial (i.e., eration. At the end of this phase, the DP at the root of softmax) regressions have to be approximated to poly- the tree DPR obtains the encrypted combined weights nomial functions to be evaluated on encrypted data by hw(·,j) i. using the homomorphic properties of ckks. We rely on a REDUCE. DPR updates the encrypted global weights (·,j) least-square polynomial approximation (LSPA) for the hwG i, as shown in Protocol 4. More precisely, it sigmoid, as it provides an optimal average mean-square computes Equation 2 by using the encrypted sum of error for uniform inputs in a specific interval, which is the DPs’ updated local weights hw(·,j) i (obtained from (·,j−1) a reasonable assumption when the input distribution combine), the previous global weights hwG i, the is not known. For softmax, we rely on Chebyshev ap- pre-defined elastic rate ρ and the learning rate α. After proximation (CA) to minimize the maximum approxi- g iterations of the map, combine, and reduce, DPR (·,g) mation error and thus avoid that the function diverges obtains the encrypted global model hwG i and broad- on specific inputs. The approximation intervals can be casts it to the rest of the DPs. empirically determined by using synthetic datasets with Protocol 4 Reduce. distribution similar to the real ones, by computing the (·,j) (·,j−1) DPR computes hwG i ← Red(hwG i, hw(·,j) i, ρ, α) minimum and maximum input values over all DPs and (·,j) (·,j−1) 1: hwG i = (1 − αρ|S|)hwG i + αρhw(·,j) i features, or by relying on estimations based on the data distribution [53]. Protocol 3 takes as input an encrypted vector/matrix hui or hU i and the type of the regression t (i.e., linear, logistic or multinomial). If t is linear, the 4.2.2 PREDICTION protocol simply returns hui. Otherwise, if t is logistic, it computes the activated vector hσ(u)i by using the The querier’s input data (X 0 , ·) is encrypted with the sigmoid’s LSPA (apSigmoid(·)). If t is multinomial, it collective public key pk. Then, hX 0 ipk is multiplied (·,g) computes the activated matrix hσ(U )i using the softmax (DM (·, ·) with the weights of the trained model hwG i
Scalable Privacy-Preserving Distributed Learning 331
and processed through the activation function σ(·) to form a ReScale(·) only when this condition is met after
obtain the encrypted prediction values hy 0 i (one predic- a series of consecutive operations.
tion per row of X 0 ). The prediction results encrypted Relinearization. Letting the ciphertext size increase
under pk are then collectively switched by the DPs to after every multiplication would add to the subsequent
the querier public key pk 0 using DKeySwitch(·), so that operations an overhead that is higher than the relin-
only the querier can decrypt hypk0 i.
0 earization. Hence, to maintain the ciphertext size and
Protocol 5 prediction. degree constant, a Relin(·) operation is performed af-
DPR gets hXn0 0 ×c i from Querier and computes hyn
0 i using
0 ter each ciphertext-ciphertext multiplication. We here
(·,g)
hwG i note that a Relin(·) operation can be deferred if do-
(·,g)
1: hy 0 [p]i = σ(DM(hX 0 [p, ·]i, hwG i)), for p = 0, ..., n0 ing so incurs in lower computational complexity (e.g.,
2: hy 0 ipk0 = DKeySwitch(hy 0 i, pk0 , {ski }) if additions performed after the ciphertext-ciphertext
multiplications reduce the number of ciphertexts to re-
linearize).
5 System Operations Bootstrapping. In the protocols of Section 4.2, we ob-
serve that the data providers’ local weights and the
We describe how spindle relies on the properties of model global weights (hwi and hwG i, resp.) are the
the distributed version of ckks to efficiently address only persistent ciphertexts over multiple computations
the problem of privacy-preserving distributed learning. and iterations. They are therefore the only ciphertexts
We first describe how we optimize the protocols of Sec- that need to be bootstrapped, and we consider three ap-
tion 4.2 by choosing when to execute cryptographic proaches for this. With Local bootstrap (LB), each
operations such as rescaling and (distributed) boot- data provider (DP) bootstraps (calling a DBootstrap(·)
strapping. Then, we discuss how to efficiently perform protocol) its local weights, every time they reach level τb
the map protocol that involves a sequence of vector- during the map local iterations and before the combine.
matrix-multiplications and the evaluation of the activa- As a result, the global weights are always combined with
tion function, in the encrypted domain. fresh encryptions of the local weights and only need
to be bootstrapped after multiple reduce. Indeed, re-
duce involves a multiplication by a constant hence a
5.1 Cryptographic Operations Rescale(·). With Global bootstrap (GB), we use the
interdependency between the local and global weights,
As explained in Section 4.1 (and Appendix A), cipher- and we bootstrap only the global weights and assign
text multiplications incur the execution of other cryp- them directly to the local weights. The bootstrapping is
tographic operations hence increase spindle’s computa- performed on the global weights during reduce. Thus,
tion overhead. This overhead can rapidly increase when we modify training so that map operates on the (boot-
the same ciphertext is involved in sequential operations, strapped) global weights, i.e., hw(i,j−1) i = hwG (·,j−1) i,
i.e., when the operations’ multiplicative depth is high. for a DPi at global iteration j. By following this ap-
As we will describe in Section 7, spindle relies on the proach, the number of bootstrap operations is reduced,
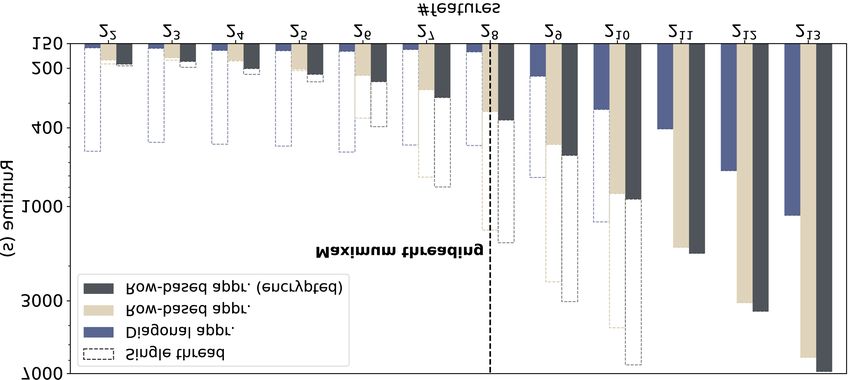
Lattigo [85] lattice-based cryptographic library, where a with respect to the local approach, because it is per-
ciphertext addition or multiplication requires a few ms, formed by only one DP and depends only on the num-
whereas Rescale(·), Relin(·), and DBootstrap(·), are 1- ber of global iterations. However, it modifies the learn-
order, 2-orders, and 1.5-orders of magnitude slower than ing method, and it offers less flexibility, as the number
the addition, respectively. These operations can be com- of local iterations in map is constrained by the num-
putationally heavy, hence their execution in the proto- ber of ciphertext multiplications required in each iter-
cols should be optimized. Note that we avoid the use ation and by the available ciphertext levels. With Hy-
of the centralized traditional bootstrapping, as it would brid bootstrap (HB), both GB and LB approaches
require a much more conservative parameterization for are combined to reduce the total number of bootstrap-
the same security level, resulting in higher computa- ping operations. The global weights are bootstrapped at
tional overheads (see Section 7). each global iteration (GB) and the DPs can still perform
Lazy Rescaling. To maintain the precision of the en- many local iterations by relying on the LB. In our exper-
crypted values and for efficiency we rescale a ciphertext iments (Section 7.2), we observed that the effect on the
{hvi, τ, ∆} only when ∆ is close to qτ . Hence, we per- trained model’s accuracy depends mainly on the dataScalable Privacy-Preserving Distributed Learning 332 RBA Dup. RowP ⟨w⟩ = RowP x (b) x (d) ⍺BT b x + RotLc x B= b = = = (g) = (a) = = c RotL2c c (f) + (h) = RotL&Add1 (c) RotR&Add1 (e) ⟨v⟩ ⟨u⟩= σ = Log2(b) Log2(c) Log2(c) Log2(b) Ciphertext Rotations DA ⟨w⟩ = RotLi (c’) (a’) i,j (b’) i,j σ N1=P2(max(c,b))/N2 0,0 0,0 i,j RotLN1⋅j 0 ≤ i ≤ N1, 0 ≤ j ≤ N2 Diag. + 0,0 + B= b 1,0 x 1,0 0,1 = ⍺BT= c Repeat ⟨v⟩ N2= ⌊ P2 (max �, � ) ⌋ rotRN1⋅j 0,1 + 0,1 = (A) c 1,1 1,1 RotLN1⋅j ⟨u⟩ b (A) N1-1 N2-1 Ciphertext Rotations Fig. 2. Packing approaches for executing Protocol 2, lines 4 and 5. We assume that c · b < N/2 and show an example with c = b = 4. Dash elements are plaintext values, everything else is encrypted. Dup duplicates and adds, rowP packs the rows in one ciphertext, RotL(/R)&Addi rotates the encrypted vector by i, 2i, 4i, . . . to the left(/right) and at each step, aggregates the result with the pre- vious ciphertext, RotL(/R)j rotates a vector left(/right) by j positions. P2 (x) returns the next power of 2 larger than x. and that, in most cases, enabling DPs to perform more and the DP computation capabilities. Figure 2 depicts local iterations (LB and HB) between two global up- spindle’s packing approaches for a toy example of the dates yields better accuracy. Even though LB incurs at computation of hui (Protocol 2, line 4) whose result is least |S| more executions of the DBootstrap(·), the DPs activated (i.e., σ(hui)) before used in the computation execute them in parallel and thus amortize the overhead of hvi (Protocol 2, line 5), for a setting with c = b = 4. on spindle’s execution time. However, if the training of For clarity, we assume that a vector of c (number of fea- a dataset requires frequent global updates, then GB (or tures) or b (batch size) elements can be encoded in one HB) achieves a better trade-off, see Section 7.2. Taking ciphertext (or plaintext), i.e., max(c, b) ≤ N/2. into account these cryptographic transformations and Row-Based Approach (RBA). This approach was the strategy to optimize their use in spindle, we ex- proposed by Kim et al. [63]. The input matrices (B plain how to optimize the required number of ciphertext and αB T ) are packed row-wise, and multiple rows are operations. packed in one plaintext ((a) in the upper part of Fig- ure 2), i.e., the number of plaintexts required to en- code the input matrix is d c·b·2 N e. Each plaintext is then 5.2 MAP Vector-Matrix Multiplications multiplied with a ciphertext containing the replicated weights’ vector (b), such that the number of replicas is As described in Section 4.1, each ckks ciphertext en- equal to the number of rows in B. To obtain the results crypts (or packs) a vector of values, e.g., 8,192 elements of the dot products between each weights’ vector and if the ring dimension is N = 214 . This packing enables row of B, a partial inner sum is performed by adding us to simultaneously perform operations on all the vec- the resulting ciphertext with rotated versions of itself tor values, by using a Single-Instruction Multiple Data (c). The values in between the dot product results are (SIMD) approach for parallelization. To execute com- eliminated (i.e., masked) through a multiplication with putations among values stored in different slots of the a binary vector (d), and the dot product results are du- same ciphertext, e.g., an inner sum, we rely on cipher- plicated in the ciphertext (e) such that it can be ac- text rotations that have a computation cost similar to a tivated (σ(·)) and used directly for the multiplication relinearization (Relin(·)). Recall that for the execution with αX T (f ). The result is then rotated and added to of stochastic gradient-descent, each local iteration in itself (g) such that it can be masked (h) to obtain hvi. map involves two sequential multiplications between en- As shown in Figure 2, the total number of vector multi- crypted vectors and cleartext matrices (Protocol 2, lines plications is d c·b·2 N e · 4, whereas the number of ciphertext 4 and 5). As a result, packing is useful for reducing the c·b·2 rotations is d N e · 2 · (log(b) + log(c)). This approach number of vector multiplications and rotations needed has a multiplicative depth of am + 4, where am denotes to perform these operations. To this end, spindle in- the depth of the activation function σ(·). tegrates two packing approaches and automatically se- Diagonal Approach (DA). This approach was pre- lects the most appropriate approach at each DP during sented by Halevi and Shoup [51] as an optimized ho- the training. We now describe these two approaches and momorphic vector-matrix-multiplication evaluation. It how to choose between them, depending on the settings, optimizes the number of ciphertext rotations by trans- i.e., the learning parameters, the number of features,
Scalable Privacy-Preserving Distributed Learning 333 forming the input plaintext matrix B. In particular, B , , Xnxc , is diagonalized, and each line is rotated ((a0 ) in lower Δ part of Figure 2) so that they can be independently [ ! , ! ] multiplied with the (rotated) weights’ vector (b0 ). The resulting ciphertexts are aggregated and rotated to ob- Fig. 3. System parameters graph. Circles and dotted circles repre- tain hui (c0 ), and a similar approach is used to com- sent learning and cryptographic parameters, respectively. pute hvi after the activation. As shown in Figure 2, then discuss two modular functionalities of spindle, DA only executes 2 · ((N1 − 1) + (N2 − 1)) rotations on namely data outsourcing and model release. the encrypted p vector, with N1 = P 2 (max(c, b))/N2 and Parameter Selection. spindle relies on the configu- N2 = b P 2 (max(c, b))c, where P 2 (x) returns the next ration of (a) cryptographic parameters that determine power of 2 larger than x. This approach involves N1 · N2 its security level, and (b) learning parameters that af- plaintext-ciphertext multiplications on independent ci- fect the accuracy of the training and evaluation of the phertexts and does not require any masking, which re- models. Both are tightly linked, and we capture these sults in a multiplicative depth of am + 2. Therefore, this relations in a graph-based model, displayed in Figure 3, approach consumes fewer levels than RBA. where vertices and edges represent the parameters and In both approaches, the number of rotations and their interdependence, respectively. For simplicity, we multiplications depends on the batch size b and the present a directed graph that depicts our empirical number of features c. DA almost always requires more method for choosing the parameters (see Appendix G, multiplications than RBA and uses more rotations af- Table 6 for notation symbols). We highlight that the ter a certain c (e.g., if b = 8, the break-even happens at corresponding non-directed graph is more generic and c = 64). However, as DA is embarrassingly parallelizable simply captures the main relations among the parame- for both multiplications and rotations (with rotations ters. We observe two main clusters: the cryptographic being the most time-consuming operations), the com- parameters on the upper part of the graph (dotted cir- putations can be amortized on multiple threads. Taking cles), and the learning parameters (circles) on the lower this into account, spindle automatically chooses, based one. The input data and their intrinsic characteristics, on c, b, and the number of available threads, the best i.e., the number of features c or precision (bits of preci- approach at each DP. We analyze these trade-offs in sion required to represent the data), are connected with Section 7. both clusters that are also interconnected through the plaintext scale ∆. As such, there are various ways to configure the overall system parameters. 5.3 Optimized Activation Function In our case, we decide to first choose N (ciphertext polynomial degree), such that at least c elements can be As described in Section 4.2, to enable their execution packed in one ciphertext. Q (ciphertext modulus) and under FHE, we approximate the sigmoid (apSigmoid(·)) η (fresh encryption noise) are then fixed to ensure a and softmax (apMax(·), apSoftN(·), apSoftD(·)) activa- sufficient level of security (e.g., 128-bits) following the tion functions with least-squares and Chebyshev poly- accepted parameterization from the homomorphic en- nomial approximations (PA), respectively. We adapt the cryption standard whitepaper [4]. The scale ∆ is con- baby-step giant-step algorithm introduced by Han and figured to provide enough precision for the input data Ki [52] to enable the minimum-complexity computation X, and mc (moduli chain) and L (number of levels) of degree-d polynomials (multiplicative depth of dlog(d)e are set accordingly. The intervals [ai , gi ] used for the for d ≤ 7, and with depth dlog(d) + 1e otherwise). Pro- approximations of the activation functions are defined tocol 6 in Appendix B computes the (element-wise) ex- according to X. The approximation degrees d are then ponentiation of the encrypted input vector before recur- set depending on these intervals and the available num- sively computing the polynomial approximation. ber of levels L. The remaining learning parameters (α, ρ, b, g, m) are agreed upon by the data providers based on their observation of their part of the dataset. Note 6 System Configuration that the minimum values for the learning rate α and elastic rate ρ are limited by the scale ∆, and if they are We discuss how to parameterize spindle by taking into too small the system might not have enough precision account the interdependencies between the input data, to handle their multiplication with the input data. and the learning and cryptographic parameters. We
Scalable Privacy-Preserving Distributed Learning 334 Data Outsourcing. spindle’s protocols (Section 4.2) early on the number of DPs |S| and the number of iter- seamlessly work with data providers (DPs) that either ations, and logarithmically on the number of features c have their input data X in cleartext, or that obtain and batch size b; all these parameters depend also on the data hXipk encrypted under the public collective key dataset size. As shown in Section 5.2, the DA packing from their respective owners. In the latter case, spin- approach incurs a higher computation complexity but is dle enables both secure data storage and computa- embarrassingly parallel and can be more time-efficient tion outsourcing to always-available untrusted cloud than RBA depending on the available threads. The ac- providers. It distributes the workload among multi- tivation function is the only operation that requires ple data providers and is still able to rely on effi- ciphertext-ciphertext multiplications; its complexity de- cient multiparty homomorphic-encryption operations, pends logarithmically on the approximation degree. We e.g., DBootstrap(·). We note that operating on en- empirically study the link between the approximation crypted input data affects the complexity of map, as all degree and the training accuracy in Section 7.2. spin- the multiplication operations (Protocol 2) would hap- dle’s other steps and protocols only involve lightweight pen between ciphertexts, instead of between the cleart- operations, i.e., ciphertexts additions and multiplica- ext inputs and ciphertexts. tions with plaintext values. Model Release. By default, the trained model in spin- dle is kept secret from any entity, enabling privacy- preserving predictions on (private) evaluation-data in- 7.2 Empirical Evaluation put by the querier and offering end-to-end model confi- dentiality. If required by the application setting, spin- We implemented spindle in Go [46]. Our implementa- dle can also reveal the trained model to the querier or tion builds on top of Lattigo [85], an open-source Go to a third party. This is collectively enabled by the DPs, library for lattice-based cryptography, and Onet [96], who perform a DKeySwitch(·). an open-source Go library for building decentralized systems. The communication between data providers (DPs) is done through TCP with secure channels (us- 7 System Evaluation ing TLS). We evaluate our prototype on an emulated realistic network, with a bandwidth of 1 Gbps between We first analyze the theoretical complexity of spindle every two nodes, using Mininet [86]. We deploy spindle before moving to the empirical evaluation of its proto- on 5 Linux machines with Intel Xeon E5-2680 v3 CPUs type and its comparison with existing solutions. running at 2.5GHz with 24 threads on 12 cores and 256 Giga Bytes RAM, on which we evenly distribute the DPs. We first provide spindle’s cryptographic opera- 7.1 Theoretical Analysis tions micro-benchmarks before assessing spindle accu- racy and performance by testing it on multiple publicly- We refer to Table 4a (Appendices E.1 and E.2) for the available datasets: CalCOFI [20] for linear regression, full complexity analysis of spindle’s protocols. We dis- BCW [10], PIMA [101] and ESR [37] for logistic re- cuss here its main outcomes. gression, and MNIST [70] for multinomial regression Communication Complexity. spindle’s communi- (see Appendix E.3 for details on the datasets). We then cation complexity depends linearly on the number of show spindle’s scalability by using randomly generated data providers |S|, iterations (g, m) and the ciphertext (larger) datasets with up to 8,192 features and 4 million size |ct|. In map, the only communication between the data samples. Our evaluation shows spindle practical- DPs is due to the DBootstrap(·), which requires two ity for large-dimensional datasets, making it suitable for rounds of communication of one ciphertext (ct) between demanding learning tasks such as the training on imag- the |S| DPs (i.e., 2 · (|S| − 1) · |ct|). In combine and re- ing or genomic datasets [11, 36, 71]. duce, the DPs exchange one ciphertext in respectively We employ two sets of security parameters (SP), one and two rounds. Finally, the prediction requires both ensuring 128-bit security: sp1: (N = 214 , Q = the exchange of one ciphertext between a DP and the 2438 , η = 3.2, number of levels L = 9, scale ∆ = 234 , querier and one DKeySwitch(·) operation, i.e., 2 cipher- degree of the approximated activation function d = 5) texts are sent per DP. and sp2: (N = 213 , Q = 2218 , η = 3.2, L = 6, ∆ = Computation Complexity. spindle’s most intensive 230 , d = 3). sp2 is sufficient for linear regression and computational part is map; its complexity depends lin- for specific logistic regression models that accept a low-
You can also read