Deliverable 2.1 Report on Qualitative Crowdsourced and Open Data Filtering Methodology
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Ref. Ares(2018)3483820 - 30/06/2018
Deliverable 2.1
Report on Qualitative Crowdsourced and
Open Data Filtering Methodology
This project has received funding from the European Union’s Horizon 2020 Research and Innovation
Programme under Grant Agreement No. 780121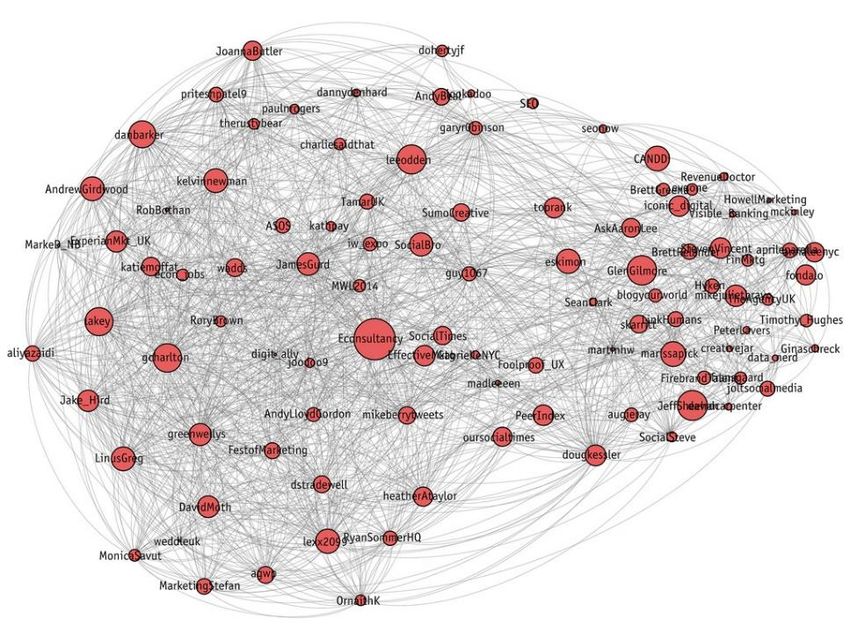
PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Copyright
© Copyright 2018 The PTwist Consortium
Consisting of:
• ARISTOTELIO PANEPISTIMIO THESSALONIKIS
• FACHHOCHSCHULE ZENTRALSCHWEIZ - HOCHSCHULE LUZERN
• NUROGAMES GMBH
• BETTER FUTURE FACTORY BV
• ALMERYS
• EOLAS S.L.
• DIKTYO MESOGEIOS SOS
• STICHTING BLUECITY
• TEKNOLOJI ARASTIRMA GELISTIRME ENDUSTRIYEL URUNLER BILISIM TEKNOLOJILERI SANAYI VE
TICARET ANONIM TICARET
This document may not be copied, reproduced, or modified in whole or in part for any purpose without
written permission from the PTwist Consortium. In addition, an acknowledgement of the authors of the
document and all applicable portions of the copyright notice must be clearly referenced.
All rights reserved.
This document may change without notice.
1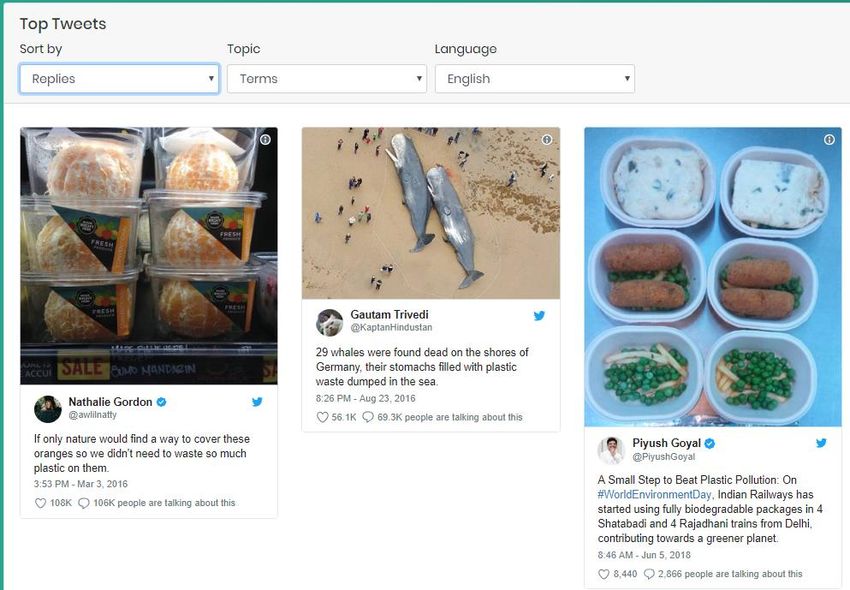
PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Document Classification
Title Report on Qualitative Crowdsourced and Open Data Filtering Methodology
Deliverable D2.1
Type R: Report
Work Package WP2 – Pilots Requirements and Data Modelling
Partners AUTH
Authors Ilias Dimitriadis
Dissemination Level PU (Public)
Abstract
This document describes the developed topic detection filtering methodology, based on the data collected
by social media and open data sources. It includes analysis of the requirements as described in the PTwist
project proposal and the overall system design for delivering high quality content. Moreover, it includes a
detailed evaluation of the whole process, followed by specific examples and charts.
Version Control
Version Description Name Date
1.0 Initial draft Ilias Dimitriadis 11 Jun 2018
1.1 Added Primitive Filtering section Ilias Dimitriadis 18 Jun 2018
2.0 Total update of document Ilias Dimitriadis 25 Jun 2018
2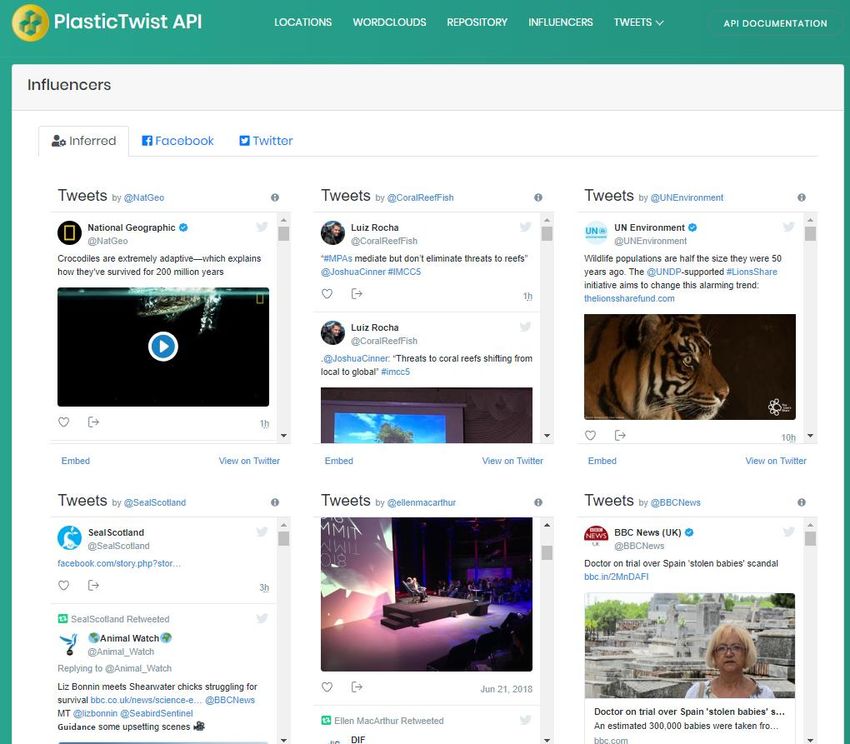
PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Table of Contents
1. Executive Summary ....................................................................................................................................... 5
2. Introduction ................................................................................................................................................... 6
3. Primitive Filtering .......................................................................................................................................... 8
3.1. Social Media Sources .............................................................................................................................. 8
3.1.1. Facebook.......................................................................................................................................... 9
3.1.2. Twitter ........................................................................................................................................... 10
3.1.3. Flickr............................................................................................................................................... 11
3.2. Open Data Sources ............................................................................................................................... 11
3.2.1. Precious Plastics ............................................................................................................................ 11
3.2.2. Thingiverse..................................................................................................................................... 12
4. Dynamic Content Filtering ........................................................................................................................... 13
4.1. Identifying Content in Twitter .............................................................................................................. 13
4.1.1. First evaluation of the collected data ............................................................................................ 17
4.1.2. Profanity Filtering .......................................................................................................................... 19
4.1.3. Filtering data from specific Twitter users ...................................................................................... 20
4.1.4. Filtering data from specific Facebook Pages ................................................................................. 21
4.1.5. Filtering data from Thingiverse and Flickr ..................................................................................... 22
5. Data Streams & User Filtering ..................................................................................................................... 23
5.1. Identifying Influential Users ................................................................................................................. 23
5.1.1. Evaluation of the Influencer filtering process ............................................................................... 25
5.2. Selecting high quality content .............................................................................................................. 26
5.2.1. Selecting top tweets ...................................................................................................................... 27
5.2.2. Selecting top URLs ......................................................................................................................... 29
5.2.3. Filtering content to produce tag clouds ........................................................................................ 29
5.2.4. Filtering Content to produce location heatmaps .......................................................................... 31
5.2.5. Topic extraction ............................................................................................................................. 32
6. Conclusions and Future Work ..................................................................................................................... 34
7. References ................................................................................................................................................... 35
3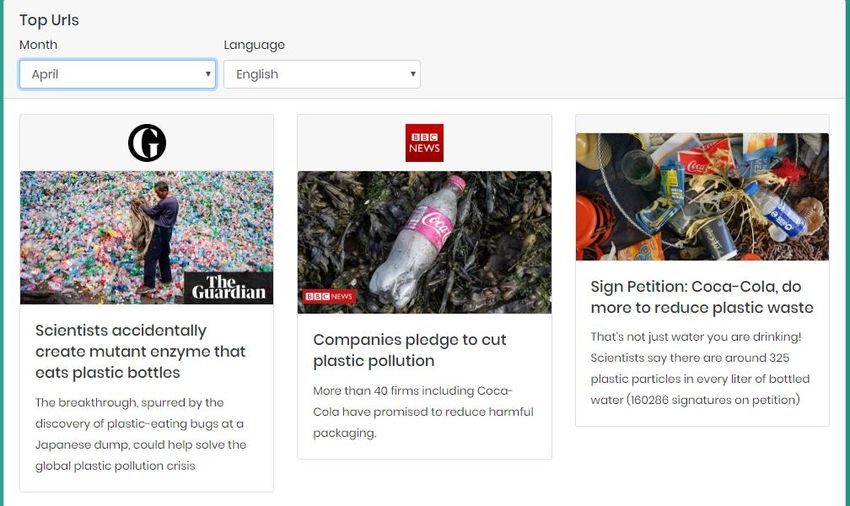
PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Table of Figures
Figure 1: PTwist architecture ............................................................................................................................. 6
Figure 2: Social Network Statistics .................................................................................................................... 8
Figure 3: Facebook users ................................................................................................................................... 9
Figure 4: Twitter active users .......................................................................................................................... 10
Figure 5: Twitter users’ age distribution ......................................................................................................... 11
Figure 6: Crowdsourcing tool components ..................................................................................................... 12
Figure 7: Twitter JSON object .......................................................................................................................... 15
Figure 8: Database Schema ............................................................................................................................. 16
Figure 9: English Tweets DB............................................................................................................................. 17
Figure 10: Dutch Tweets DB ............................................................................................................................ 17
Figure 11: German Tweets DB ......................................................................................................................... 18
Figure 12: Greek Tweets DB ............................................................................................................................ 18
Figure 13: Bbefore and after updating the keywords ..................................................................................... 19
Figure 14: Updating influential users’ posts .................................................................................................... 21
Figure 15: Thingiverse Db schema ................................................................................................................... 22
Figure 16 Open data repository example ........................................................................................................ 22
Figure 17: Sample Image of the 100 most influential users in a social network ............................................. 23
Figure 18: Twitter data to MongoDB flow ....................................................................................................... 24
Figure 19: Nodes and Edges in JSON document .............................................................................................. 24
Figure 20: NetShield pseudo-algorithm........................................................................................................... 25
Figure 21: Influencer Detection Demo ............................................................................................................ 26
Figure 22: Top Tweets Demo ........................................................................................................................... 27
Figure 23: Top tweets favourite count ............................................................................................................ 28
Figure 24: Top tweets replies count ................................................................................................................ 28
Figure 25: Top URLs Demo .............................................................................................................................. 29
Figure 26: JSON schema for wordcount .......................................................................................................... 30
Figure 27 Tag cloud Demo ............................................................................................................................... 30
Figure 28: Location heatmap ........................................................................................................................... 31
Figure 29: LDA topic modelling Demo ............................................................................................................. 33
4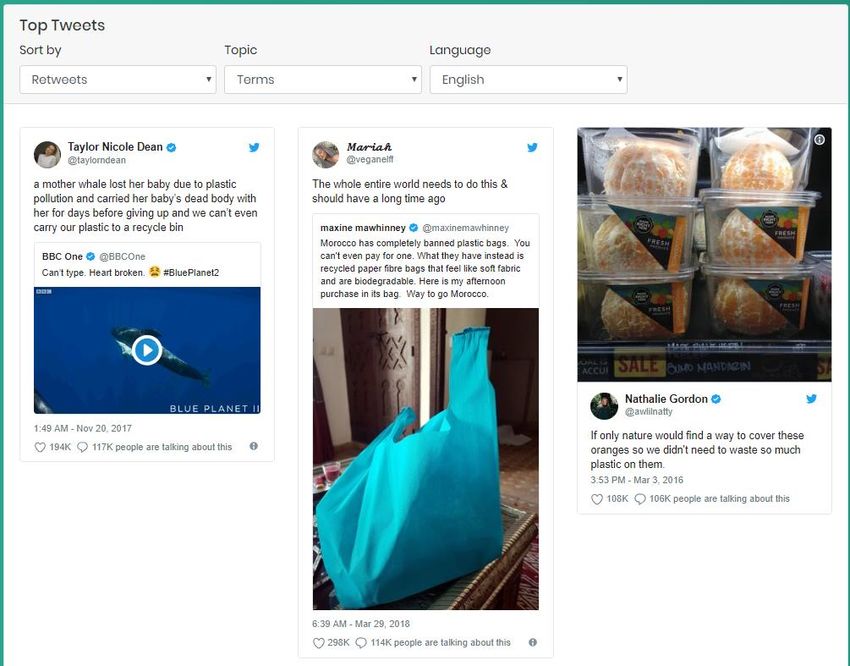
PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
1. Executive Summary
This document presents the data filtering methodology that has been used up to now, during the process of
the Crowdsourced Data Collection and Analysis as described in Task 2.1 of the PTwist official proposal. The
whole filtering process consists of three main categories:
1. Primitive Filtering, in charge of identifying the Social media sources which will be used for the
collection of data.
2. Dynamic content filtering, in charge of identifying terms related to plastic and plastics reuse.
3. Data streams & User filtering, in charge of:
a. Identifying and detecting influential – expert - users regarding plastic re-use thematology.
b. Filtering incoming data in order to produce high quality content.
c. Updating the keywords used to collect data.
Apart from the whole filtering process, the deliverable also provides a detailed evaluation of the filtering
methodology. This part refers to specific examples regarding each of the filtering phase as mentioned above,
except for the primitive filtering phase.
Considering the three-layer approach of the PTwist platform, the Data Filtering is under the responsibility of
the Crowdsourcing Component. Crowdsourcing will be used as a plastic topics insightful barometer, able to
detect new trends, identify interesting content, spot influential users and generally raise awareness regarding
the problem of plastic overuse. The crowdsourcing tool as a whole will be presented in month 10 of the
project.
5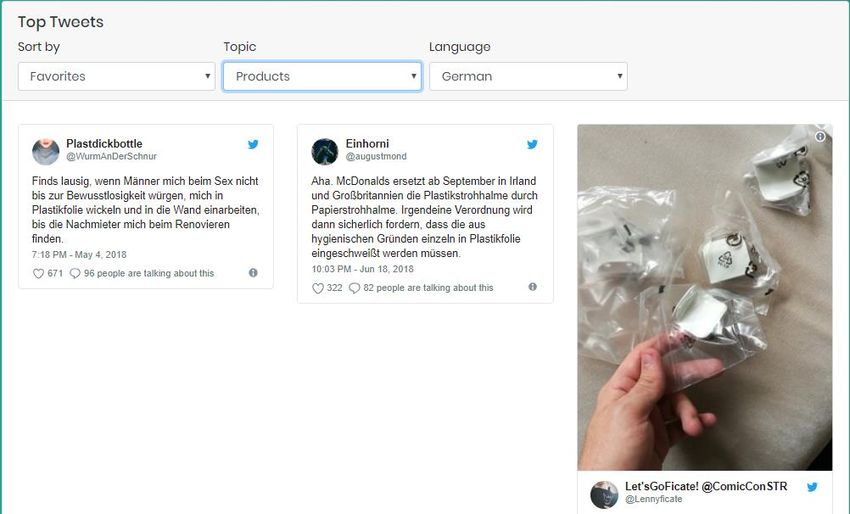
PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
2. Introduction
As a reminder, the PTwist architecture is composed of three different layers, the Application Layer, the
Processing Middleware Layer and the Peer to Peer Blockchain Layer. This deliverable refers to parts of the
first two Layers, as presented in Figure 1.
Figure 1: PTwist architecture
The Plastics crowdsourced topic observatory and the Open data & plastics designs collection are built upon
the intelligence that has been extracted by data collected using Social Media or Open Data sources.
• The first filtering phase as described in section 3, focuses on the data sources that will be used,
explaining the reasons behind the final selection.
• The second filtering stage as described in section 4, presents the initial set of terms which will be
used to collect relative content. It also presents a detailed evaluation of the data that have been
collected up to now, using this methodology.
• In order to make sure that the content of both components is reliable and of high quality, the data
collected in raw format must be filtered and processed. This process takes place in the Middleware
layer, which is responsible for all the processing of the data produced in the PTwist platform. The
third filtering stage as described in section 5 presents:
6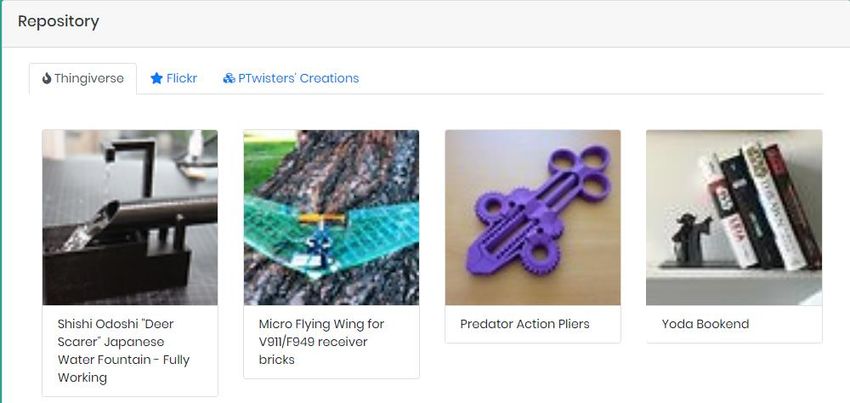
PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
❖ The methodology behind the discovery of influential users, i.e. the algorithms responsible
for filtering the whole set of users that make plastic related posts, to detect the ones who
are considered experts in their field (in our case Plastic re-use, plastic pollution, etc.)
❖ The process behind selecting content based on its popularity among the social network
users.
❖ the methodology behind the iterative process of updating the filters used to collect data
Finally, the conclusion and next steps (section 6) recapitulates what is presented, how it is linked with the
work engaged in work package two (WP2) and the plan for the next steps.
7
PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
3. Primitive Filtering
This section refers to the data accessibility of Social Media and Open Data sources, their advantages and
disadvantages and concludes with the final selection of the sources that will be used throughout the PTwist
Project.
3.1. Social Media Sources
The crowdsourcing tool will be built upon the intelligence extracted by posts of users in Social Networks.
However, very few of the popular Social Networks allow users – developers to have access on data, even if
these are public posts. Figure 2 , depicts the ranking of the most popular social networks based on the number
of active users.
Figure 2: Social Network Statistics
8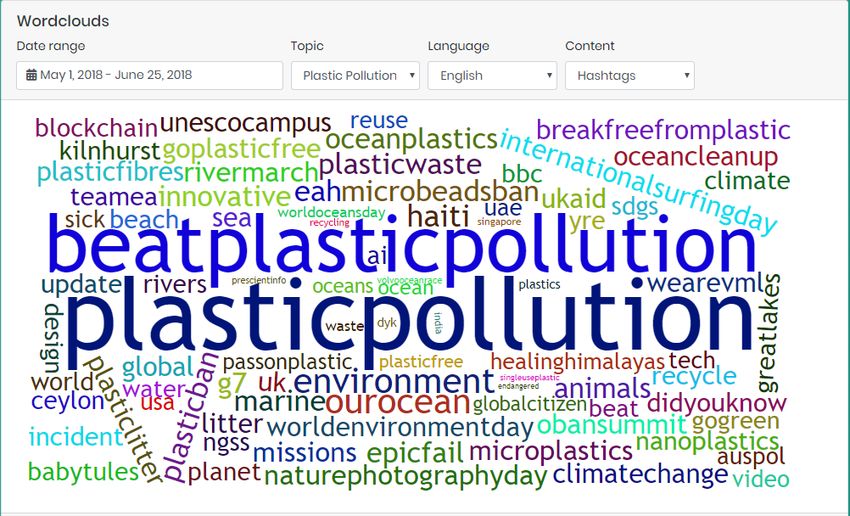
PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Most of the Social Networks in the list above, are either not related with the scope of the PTwist project or
do not offer an official API which provides access to publicly shared posts or images. Such examples are the
following:
▪ Instagram [1] : Although access to Instagram’s public posts would be really valuable, the official
Instagram API [2] does not allow other users, except for the one that created the post, to retrieve
this data
▪ Pinterest [3]: Pinterest could be used as a pool of plastic re-use ideas, because of the creative nature
of most of its users. Although the version 1 of the official Pinterest API allowed users/developers to
search for and collect publicly published posts, the latest version 2 of the Pinterest API [4] does not
give the opportunity to search for a post by providing a certain “pin” (pin is a tag for each image
posted in Pinterest)
▪ Tumblr [5] : Tumblr is a microblogging and social networking website, where each user can have
his/her own blog. Tumblr could be used as a source for opinions and ideas regarding plastic. It does
offer an open API [6] but it is quite restricted. Although it allows the user/developer to make
1000calls/hour or 5000calls/day using certain tags as query terms, it only returns a maximum of 20
results which remain the same after each call. Collecting data that refer to the same 20 accounts
would produce a biased dataset. Moreover, after searching manually for topics related to plastic
reuse – recycle thematic, it proved out that Tumblr is not quite popular for posting such content
Therefore, the PTwist crowdsourcing tool will offer information and knowledge that has been collected by
analyzing data on the following social networks:
• Facebook
• Twitter
• Flickr
3.1.1. Facebook
Facebook [7] is the most popular social network globally with the highest user engagement worldwide, Figure
3 . More than 500 Terabytes of data are stored in a daily basis, showing that there is actually tons of
information on any possible subject.
Figure 3: Facebook users
9PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
However, its official API [8] does not give you the ability to search by a specific term, even the public posts
containing this term are not discoverable. It allows access only on publicly open Facebook pages. Moreover,
it has a very strict Rate Limit as well (200calls / user), which makes data collection an ongoing challenge. In
the PTwist project, data are collected from certain Facebook pages that have been provided as input by the
pilot partners. Further info regarding these specific pages can be found in section 4.
3.1.2. Twitter
Although Twitter [9] is not included in the top ten Social networks worldwide (based on the number of users)
it still remains the most popular one for social media research, both in academia and in industry. This does
not mean that the number of daily active users is low, on the contrary, during the 1st quarter of 2018 the
number of monthly active users was around 336 Million, Figure 4.
Figure 4: Twitter active users
Twitter is unique in the sense that the Twitter Official API [10] , provides almost 100% coverage of its data.
Another important fact, for Twitter is the age distribution of its users. As presented in Figure 5, the vast
majority of Twitter’s users are between the ages of 18 – 64, a rather more mature audience than that offered
by other social networks.
10PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Figure 5: Twitter users’ age distribution
In the PTwist project, Twitter will play the role of the main data source for the crowdsourcing tool. More
information regarding data that have been collected using a term filtering method is provided in section 4.
3.1.3. Flickr
Flickr [11] is a photo sharing platform and social network where users upload photos for others to see.
Although it is not the most popular photo sharing network, it still holds a community of 120Million users.
Flickr also offers an official API [12], which provides access to all the publicly shared images on the platform.
Flickr API will provide access to images that have been described with certain tags relevant to plastic related
terms. These images will be used in the open data and plastic design collection.
3.2. Open Data Sources
Data collected from such sources will frame the content of the open data and plastic design collection
repository. Since it will actually provide access to plastic reuse ideas, 3d printer designs, etc. the available
data sources are limited.
3.2.1. Precious Plastics
Precious Plastic [13] is a global community of hundreds of people working towards a solution to plastic
pollution. Knowledge, tools and techniques are shared online, for free. PTwist will offer access to this
knowledge by inter-linking the open data repository with the one provided by precious plastic.
11PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
3.2.2. Thingiverse
Thingiverse [14] is a thriving design community for discovering, making, and sharing 3D printable things and
the world's largest 3D printing community. Thousands of 3d printing designs are available over their open
API [15] . PTwist offers direct access to Thingiverse database, including designs that will be implemented by
PTwist users and pilots in a specific Thingiverse group.
Figure 6: Crowdsourcing tool components
12PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
4. Dynamic Content Filtering
This section describes in detail the process of filtering of data that are going to be used in the crowdsourcing
tool, based on their content. PTwist thematic focuses on plastic waste, plastic recycle, plastic reuse, etc. as
described in the official PTwist proposal. Collecting data from various sources, implies the use of specific
filters so that the content of the collected data remains as close to the “plastic” thematic as possible.
4.1. Identifying Content in Twitter
Although the primitive goal of Social Networks, in this case Twitter, was to strengthen the social interactions
between their users, within time it has differentiated. Twitter can now be considered as a mighty real time
human-powered sensor and how could anyone stand for the opposite, since there are 336 million active
monthly users. Its content is updated incessantly and can affect opinions and behaviours; it can be used as a
prediction tool and the real-time information that derives from microblogs like Twitter are really useful for
different kinds of applications. In this case, it will be used as a topic observatory for plastic.
Twitter allows users to search for specific keywords or user accounts. Since PTwist focuses on plastic, the
pilot partners provided AUTH with a list of specific keywords and a list of certain user accounts that have
been classified as experts. The multidisciplinary nature of the project, meaning that each pilot focuses on
plastic using different perspectives, allows the creation of a very wide and focused list of keywords. Each pilot
has contributed in the creation of that list, which is then translated to the native language of each pilot in
order to collect data that reflect trends and interesting topics in each pilot’s country. These keywords are
then classified using a taxonomy provided by the pilot partners, offering an initial set of different topics –
thematic. This taxonomy and the keywords for each class is presented below:
English Dutch German Greek Groups
plastic plastic Plastik πλαστικό General terms
single use plastic Einwegplastik πλαστικό μιας General terms
χρήσης
reuse hergebruik Wiederverwendung επαναχρησιμοποίηση General terms
reduce verminderen Reduktion μείωση General terms
recycle recycleren rezyklieren ανακύκλωση General terms
upcycling upcycling upcyclen upcycling General terms
downcycling downcycling General terms
waste afval Abfall απόβλητα General terms
litter zwerfafval Abfall σκουπίδια / General terms
απορρίμματα
plastic soup plastic soep Plastiksuppe πλαστική σούπα General terms
zero-waste zero-waste Null-Abfall μηδενικά απόβλητα General terms
no-waste afvalvrij χωρίς απόβλητα General terms
plastic free plastic vrij frei von Plastik χωρίς πλαστικό General terms
virgin plastics virgin plastics καθαρό/ καινούριο/ General terms
πρωτογενές πλαστικό
deposit fee statiegeld ohne Inhaltsstoffe τέλος ταφής General terms
recycling fee τέλος ανακύκλωσης General terms
deposit return σύστημα General terms
system επιστροφής,
13PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
συλλογής / σύστημα
εγγυοδοσίας
pollution vervuiling Umweltverschmutzung ρύπανση General terms
packaging συσκευασία General terms
Eco-design Ökodesign General terms
End-of-waste General terms
Microplastic Mikroplastik General terms
"Unrecyclable" Nichtrezyklierbar General terms
Jetsam Strandgut General terms
single-use Einwegprodukt General terms
products
Bag Tüte General terms
Plastic tax Plastiksteuer General terms
Bio-based Biobasierte General terms
packaging Verpackung
Recyclability Rezyklierbarkeit General terms
Waste recovery General terms
Anthropogenic General terms
Litter
Incineration General terms
Trash Müll σκουπίδια General terms
Table 1: General Terms
English Dutch German Greek Groups
Straws Rietje Strohhalme Καλαμάκια Product
plastic cup Plastic beker Plastiktassen Κύπελλα / Ποτήρια Product
plastic bottle plastic fles Plastikflasche Μπουκάλι Product
plastic cap plastic dop Plastikdeckel Καπάκι Product
Wrapping Verpakking Verpackung Περιτύλιγμα Product
Foil Folie Folie Αλουμινόχαρτο Product
Filament Filament Filament Νήμα Product
plastic bag plastieken zak Plastiktüte πλαστικές σακούλες Product
Sachet Zakje Beutel Φακελάκι Product
Table 2: Products
English Dutch German Greek Groups
Shredder Vermaler Reisswolf Τεμαχιστής Machines
Extruder Extruder Extruder Machines
Ultimaker Ultimaker Ultimaker Machines
Τρισδιάστατος Machines
3D printer 3D-Drucker εκτυπωτής
Container Container Container Περιέκτης Machines
Table 3: Machines
14PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
English Dutch German Greek Groups
Granulation Granuleren Granulation Κοκκοποίηση Process
Molding Spuitgieten Formen Καλούπι Process
Injection Injectie Injektion Έγχυση Process
Table 4: Processes
English Dutch German Greek Groups
Compostable Composteerbaar compostierbar Κομποστοποιήσιμο Innovations
Biodegradable biologisch biologisch abbaubar Βιοαποικοδομήσιμο Innovations
afbreekbaar
Coating Coating Beschichtung Επικάλυψη Innovations
Bioplastics Bioplastic biologischer Βιοπλαστικά Innovations
Kunststoff
Biobased Biobased biobasiert Biobased Innovations
Sea-weed Zeewierverpakking Seegrasverpackung Συσκευασία από Innovations
packaging φύκια
Meelmotlarwe Innovations
Pyrolyse Innovations
Table 5: Innovations
Twitter’s Streaming API has been used to collect all tweets that contain any of the keywords. However, as it
has already been mentioned, since there are four different languages an extra filtering parameter must be
taken into account. After making a call to Twitter Streaming API each response is in JSON format; each
response is actually a single tweet, packed together with multiple type of information as presented in Figure
7: Twitter JSON object.
Figure 7: Twitter JSON object
15PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
The “text” field of the JSON document is actually the textual content of each tweet. If any of the keywords
match any of the words in this field, the tweet is collected. The second part of filtering process has to do with
the language of the tweet. The language of the tweet is described in the “lang” field. For each of the
languages, there is a different Mongo Db [16] Database with five different collections, each one referring to
a different group of keywords. If the content of “lang” is equal to any of the following languages [el, en, nl,
de] each collected tweet is stored in the Database and then redirected and stored to the collection in charge
of each keyword as shown in Figure 8 .
Figure 8: Database Schema
16PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
4.1.1. First evaluation of the collected data
Using the process described above, AUTH has started collecting and filtering data on 12th March 2018. After
two months, a total of 12.5 Million tweets had been collected, of which more than 90% were English. A short
presentation with data statistics is presented below:
Tweets - English DB
8161 695577
271234
2186228
9018546
Innovations Machines Processes
Products General terms
Figure 9: English Tweets DB
Tweets - Dutch DB
1543 8200 1573
19993
97585
Innovations Machines Processes
Products General terms
Figure 10: Dutch Tweets DB
17PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Tweets - German DB
58
10535
18636
57642
17492
Innovations Machines Processes Products General terms
Figure 11: German Tweets DB
Tweets -Greek DB
53 163
13579
22256
0
Innovations Machines Processes Products General terms
Figure 12: Greek Tweets DB
18PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
By applying some simple techniques to get an initial input for plastic-related crowd’s standing, AUTH
produced some basic tag clouds that revealed some problems regarding the terms used to collect these data.
The main problem was that some of the terms were quite generic; for example, the term “bag” did not cover
just the plastic thematic but returned tweets that could refer to fashion. For this reason, all the tweets that
had been stored until that moment, were filtered out so that each tweet contained the word “plastic” AND
the keyword that had already been proposed. Initially all the tweets that had been collected were filtered
out and once this filtering process finished, all the keywords were updated accordingly. After applying this
filter, updating the terms and three months of collecting data, the dataset was reduced to a total of
approximately 1.5 Million tweets. The following Figure (Figure 13 depicts the difference regarding the
number of collected tweets before and after the filtering process.
Figure 13: Bbefore and after updating the keywords
4.1.2. Profanity Filtering
A large percentage of the content shared in Twitter may be noisy, spam or offensive. As such, in order to
ensure the quality of the final delivered content the use of a profanity filtered is considered necessary.
Twitter itself does not provide any automatic filtering, except for the cases when other users flag a certain
post as possibly offensive. Moreover, in the JSON document of each tweet there is the sensitive field, which
is actually activated by the user himself and thus cannot be considered as a reliable indicator of inappropriate
content.
In our initial evaluation of the collected data we did not notice any abusive content, except for some swearing
language. This is mainly due to the fact that the plastic thematic does not offer a fertile ground for adult
content. However, a typical text filter has been used to filter the dataset from tweets with inappropriate
words included in their text. After detecting such tweets, the second step is identifying the user that posted
the tweet. All the users that have been identified as possibly “malicious” are blacklisted and are then ignored
by the Twitter crawler.
19PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
4.1.3. Filtering data from specific Twitter users
Apart from collecting streaming tweets, AUTH has collected data for a number of users individually using
Twitter’s Search API which allows the collection of the last 3600 tweets for each specified account. This initial
set of users was also selected by the pilot partners and can be found below:
Account Type Account Type
Supporter van Schoon Government PlasticWhale Social
Program Enterprise
Nedvang Government TheOceanCleanUp Social
Program Enterprise
PlasticsHeroes Government Ioniqa Industry
Program
Beach Cleanup NGO GreenWavePlastics Industry
Searious Business NGO Qualitive Circular Polymers Industry
PlasticOceanFoundation NGO Renewi Industry
PlasticSoupFoundation NGO Coolrec Industry
PlasticSoupSurfers NGO Van Gansewinkel Industry
WasteFreeOceans NGO LogicWaste Industry
PreciousPlastics NGO Eastman Chemical Company Industry
WASTED NGO RDM Makerspace Fablab
Recycled Park NGO De Waag Society Fablab
Zwerfie NGO Bouwkeet Fablab
BetterFutureFactory Social Stadslab Rotterdam Fablab
Enterprise
Refil Social Makerversity Fablab
Enterprise
PerpetualPlasticProject Social Mediamatic Fablab
Enterprise
NewMarble Social The Green Village Fablab
Enterprise
Dopper Social PreciousPlasticsGreece NGO
Enterprise
Plastic Circle Social EllenMcArthurFoundation Thought
Enterprise Leader
#dHubs Social
Enterprise
Biofutura Social
Enterprise
Milgro Social
Enterprise
Van Plestik Social
Enterprise
Community Plastics Social
Enterprise
GreatBubbleBarrier Social
Enterprise
Table 6: Initial set of users
20PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
These data were not further filtered out, because they will then be used to infer interesting topics that may
be related to plastic. However, since it is important to track the impact of the posts published by influential
users to other users, a method for updating the most recent posts has been developed (see Figure 14).
Figure 14: Updating influential users’ posts
An iterative process makes sure that the impact of each post is tracked. For example, a post published by
National Geographic may have been collected in the same hour that it had been posted and did not have
enough time to get spread along the Twitter user pool. As a result, the number of people that added this post
to their favourites (or Likes in Facebook) up to the time of the collection could be quite small. A casual
evaluation of the post would lead to improper conclusions (e.g. that the post did not “influence” many
people). Using the methodology described above, we make sure that the impact of all posts is updated, thus
every post is evaluated accordingly.
4.1.4. Filtering data from specific Facebook Pages
Using Facebook’s Graph API, AUTH also collected data from the Facebook pages described in Table 6 (if
available). Similarly to the data collected from Twitter for these specific users, the data did not pass any
filtering process at this point as they will be used later on in the extraction of plastic related topics. The
iterative update process described in Figure 13 is applied in these data as well.
21PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
4.1.5. Filtering data from Thingiverse and Flickr
AUTH has used the Thingiverse API and the Flickr API to develop an open data repository which will be
accessed via the PTwist Crowdsourcing platform. Both APIs return data in JSON format [Figure 15].
Figure 15: Thingiverse Db schema
Regarding Thingiverse, no filtering has yet been applied since Thingiverse is a repository of open designs with
free license. All the designs can be accessed via the PTwist platform. Up to now the demo version of the
crowdsourced tool displays information for the top-30 designs (see Figure 16), sorted by the number of
downloads (number of downloads is included as an attribute in the JSON document which describes each
Design).
Figure 16 Open data repository example
In relation to Flickr, up to now no filtering process has taken place. A detailed description of the future plans
regarding this task is included in Section 6.
22PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
5. Data Streams & User Filtering
This section describes the main filtering methods that have been implemented up to this point. The first part
refers to the filtering of users whose tweets has been collected by the Twitter crawler and can be identified
as experts – influencers. The second part presents the methodology used to designate posts / tweets that
have attracted people’s attention, more specifically the filtering process which is used to select high quality
posts. The third part is about the methodology behind the iterative process of updating the already known
keywords, i.e. a filtering process that detects new emerging hashtags – keywords.
5.1. Identifying Influential Users
This part is about detecting influential users in the Twitter dataset that has been collected up to this moment.
Influential users – experts are expected to be the ones that will diffuse information regarding plastic, more
efficiently and will share content of higher quality in comparison with other users. Identifying influencers
(see Fig. 17) has attracted the interest of multiple researchers since Social Networks dominance started
affecting the old-fashioned marketing strategies.
Figure 17: Sample Image of the 100 most influential users in a social network
Twitter, is based on a social-networking model, in which users can choose who to follow or interact with (via
retweets, mentions or replies). Based on that notion we can think of Twitter as a large graph G(U,E) where
U stands for the whole set of users (nodes) and E all the possible interactions between users (edges). Our
goal is to use a filtering methodology capable of detecting the users that diffuse better the plastic related
information throughout the network. In this case, the graph will consist of all the users that have posted a
tweet regarding plastic and have been collected by Twitter Crawler. Every retweet, mention or reply to a
certain user will create an edge between the author user and the retweet-er, mention-er accordingly. For
example, let’s have user A post a tweet regarding plastic reuse in Rotterdam. If users B, C and D retweet the
original post of user A, a small graph of 4 nodes will be created, where users B, C and D will be connected
directly to user A.
23PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Figure 18: Twitter data to MongoDB flow
As it has already been mentioned, every tweet that fits the criteria described in Section 4 is stored in a
MongoDB database (Fig. 18). Since we store the whole JSON document, as returned by the Twitter Streaming
API, a plethora of information is available regarding each tweet. In the JSON document, the entities field
contains information about the id of the user that has been mentioned, retweeted or replied while in the
user field, we can find the id of the user author (see Figure 19).
Figure 19: Nodes and Edges in JSON document
For the graph creation we use all three entities (if and where available), retweets, mentions and replies. The
dataset that has been collected up to now, regarding tweets of English language related to the terms
presented in Tables 1-5, contains approximately 1.3 Million tweets. Table 7 presents a brief overview of the
Graph generated from all these data.
Number of nodes 629787
Number of edges 994376
Avg degree 3.15
Table 7: Graph of Twitter-data overview
Research regarding identifying influencers has been focused either on approaches based on the topology of
the graph or on approaches that try to identify experts using various specific attributes (for example in our
case number of friends – followers, tweeting activity, retweeting activity, etc.). Most studies are based on
Twitter and Facebook, where user engagement is quite high [17] [18] [19] [20] [21] [22] [23] [24] [25].
24PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Since we are not just interested in nodes with high reputation, the Pagerank [26] algorithm is not quite
suitable for our case. Influence is another case of an epidemic process, where a topic, a hashtag or content
in general is spread as a virus would. Tong et al [27] presented an epidemic immunization approach called
NetShield (see Figure 20) which can be described shortly as an algorithm that gives an answer to a problem
formulated in our case as: Given a graph G of Twitter accounts, find the best x users that are expected to
propagate a tweet or information in general better and faster.
Figure 20: NetShield pseudo-algorithm
NetShield is able to detect the nodes that if isolated, one could immunize the whole network. In other words,
it is able to detect those nodes that are able to spread the virus, i.e. information throughout the whole
network. Specifically, NetShield (a) gives an effective immunization strategy and (b) scales linearly with the
size of the graph (number of edges).
5.1.1. Evaluation of the Influencer filtering process
Focusing on the dataset presented above (English tweets for the three past months), we generated the graph
as described previously and applied the NetShield algorithm for x=100 (top-100 influencers). The whole
process lasted 4 minutes and 19 seconds on a desktop Computer, a statistic that shows the efficiency of this
algorithm. The goal of this process was to filter out the top 100 influential users in a graph that contained
629787 nodes (users) and 994376 edges. A small sample of the top influential users as displayed in the demo
version of the crowdsourcing tool is presented below:
25PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Figure 21: Influencer Detection Demo
The top six accounts regarding the quality of the content and their influence upon other users based on the
NetShield algorithm in our dataset are: (1) National Geographic, (2) CoralReefFish, (3) UNEnvironment, (4)
SealScotland, (5) EllenMacArthur, (6) BBCNews. As someone can notice, all the accounts are top-notch and
validate that the algorithm used produces accurate and reliable results.
5.2. Selecting high quality content
This subsection refers to the work done under the filtering umbrella theme and aims to efficiently track high
quality posts that seem to have an impact on Twitter users.
26PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
5.2.1. Selecting top tweets
The crowdsourcing tool aims to raise awareness on the plastic pollution problem by bringing popular plastic
related content to the surface. The quality of this content can be tracked by filtering out posts, based on
other users’ interactions. In the case of Twitter, interactions refer to the number of times a post has been
retweeted, replied or marked as favourite.
5.2.1.1. Ranking tweets by retweet count
Since all the collected tweets are stored in a Mongo Database, the process of filtering the most retweeted
ones refers to a Database query. In this case the query is described as:
1. From Collection X: Get all tweets, sorted by retweet count
2. Store top k
3. If doubles exist, keep the one with the highest retweet count
4. Return top k – doubles
This process is repeated for all collections (different group of keywords) and for all databases (languages). An
example of the emerging results is presented in the figure below:
Figure 22: Top Tweets Demo
27PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
5.2.1.2. Ranking tweets by favourite count / replies
This process follows the exact methodology of 5.2.1.1 but returns all the tweets sorted by the favourite count
or replies count accordingly. Both statistics are included in the tweet’s JSON document. Figure 23 and Figure
24 depict such an example:
Figure 23: Top tweets favourite count
Figure 24: Top tweets replies count
28PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
5.2.2. Selecting top URLs
Twitter posts very often contain URLs. The expanded URL is also included in the tweet’s JSON document.
URLs are collected monthly for each database (language). The process of filtering out the top URLs is an
iterative process that takes place at the end of every month. For each month we calculate the frequency of
each URL published in the tweets of all collections in the Database. The Map that contains the URLs and their
frequency is then sorted and stored into our Results DB. An example of this selection is shown below:
Figure 25: Top URLs Demo
5.2.3. Filtering content to produce tag clouds
Tag clouds is a novel visual representation of text data; tags are usually single words whose importance is
shown with increased font size and different colour. In the crowdsourcing platform, tag clouds offer the
possibility to the user to visually identify trending terms related to plastic thematic groups (pollution,
innovations, general terms, etc.). The text of each tweet usually includes a number of different entities that
add noise to the tag clouds and therefore needs to be cleaned in order to produce more reliable and
qualitative results. The cleaning (filtering) process consists of the following steps:
• Remove mentions
• Remove hashtags
• Remove punctuation and symbols
• Remove stopwords (words that are too common and do not add any value)
• Remove distinct numbers
• Remove social network’s reserved words (e.g. RT)
• Remove single letter words
• Remove multiple consecutive blank spaces
• Tokenize text
• Calculate the frequency of each word for all the tweets in each collection
• Create a JSON document that includes:
o A word frequency map
29PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
o A timestamp from (from which date)
o A timestamp to (until which date)
o The name of the collection
• Store the JSON document in the Results DB [Figure 26]
Figure 26: JSON schema for wordcount
When a user asks for the tag cloud for a certain period t: “from date1: to date2”, for a certain collection X a
mongo query is executed:
1. From results DB:
2. get all wordclouds of collection X with timestamp in between period t
3. sum all wordclouds
4. return total
The process for creating tag clouds based on hashtags is simpler, since hashtags are stored in a specific field
of the tweet’s JSON document. A sample result of such a process is presented in Figure 27:
Figure 27 Tag cloud Demo
30PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
5.2.4. Filtering Content to produce location heatmaps
Estimating the real location for a Social Network user is a challenge, especially when someone refers to
Twitter which supports only 140 characters and contains such sparse data. Many researches have been
conducted on user geolocation, in other words how to infer the location of users exploiting all source of
information available [28].
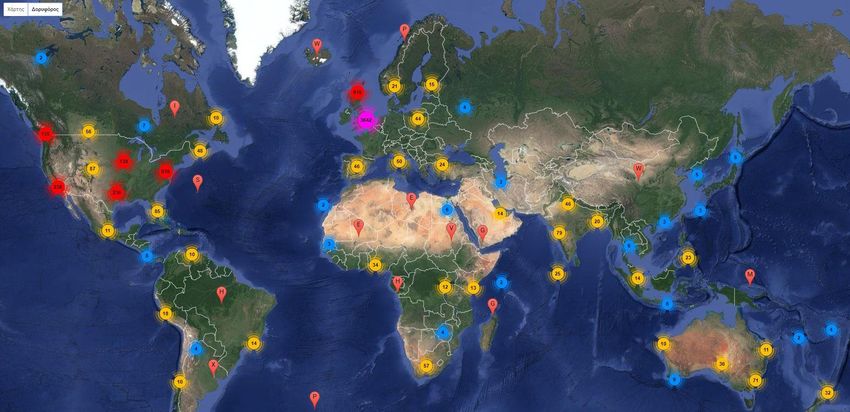
In our case we follow a rather simple location filtering approach:
• Collect tweets from users that share their exact location (100% accurate – only 1-2% of the total
dataset)
• Collect tweets from users that share their exact place (high level accuracy – low granularity – city
level)
• Collect tweets from users that declare their location in their profile (research has shown 50-60%
accuracy on city level)
• Aggregate the total number of tweets collected along with the geospatial information
• Visualize the results
Figure 28: Location heatmap - shows a demo example of this process:
Figure 28: Location heatmap
31PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
5.2.5. Topic extraction
Topic modelling is an unsupervised learning approach used to discover topics based on the content of
documents. In our case, the text of each tweet plays the role of the document. Up to now we have
implemented two different approaches for topic modelling:
• LDA (Latent Dirichlet Allocation): a probabilistic topic modelling method; and
• NMF (non-negative Matrix factorization)
LDA [29] is an unsupervised machine learning technique used for the discovery of latent topic information
from large document collections. It uses a bag of words approach to transform user’s corpus into a vector of
word counts. It uses two probability values: P(word | topics) and P(topics | documents). These values are
calculated based on an initial random assignment, after which they are repeated for each word in each
document, to decide their topic assignment. In an iterative procedure, these probabilities are calculated
multiple times, until the convergence of the algorithm.
NMF [30] on the other hand relies on linear algebra. It is a Linear-algebraic model that factors high-
dimensional vectors into a low-dimensionality representation. Similar to Principal component analysis (PCA),
NMF takes advantage of the fact that the vectors are non-negative.
Both NMF and LDA take a bag of words matrix (no documents * no words) as input. In the bag of words
matrix, documents are represented as rows, while words are represented as columns. Both algorithms also
require the number of topics (k) that must be derived as a parameter. The output produced by the topic
modelling algorithms is then 2 matrices: a document to topics matrix (no documents * k topics) and a topics-
to-words matrix (k topics * no words). Most topic model output only uses the topics to words matrix and
displays the words with the highest weights in a topic.
The whole process can be considered as a two-step process. The first step contains the training of the model,
while the second refers to the evaluation of the results. As an example, in this case we used LDA on the
corpus of the “English terms” collection to train our model and asked for 10 distinct topics. In order to use
these approaches, the text of the tweet needs to be filtered and pre-processed. The filtering steps are
described below:
• Remove mentions
• Remove hashtags
• Remove punctuation and symbols
• Remove stopwords (words that are too common and do not add any value)
• Remove distinct numbers
• Remove social network’s reserved words (e.g. RT)
• Remove single letter words
• Remove multiple consecutive blank spaces
• Tokenize text
• Apply a stemming process (reduce the words in their base root)
A demo example of the produced topics and the words related to them is presented in Figure 29. This demo
is using the PyLDAvis [31] to produce the graphic visualization of the topics.
32PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
Figure 29: LDA topic modelling Demo
33PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
6. Conclusions and Future Work
In this deliverable we report the work done in WP2 with focus on the filtering process that has been used
during the data collection and analysis phase up to this point. Moreover, since this is the first deliverable
regarding the crowdsourcing tool (which is to be delivered by Month 10), some of the filtering methods have
not yet been completed. Future work plans include:
• Extracting high quality content from the users that have been identified as experts by our system and
the pilots and use it to train an LDA model, which will then be used to classify other users.
• Extract topics using topic modelling per location.
• Provide a filtering process for identifying high quality content in Flickr.
• Develop an iterative methodology that will be built upon the intelligence extracted by the already
available high-quality content (top tweets – top URLs) to identify new trends and dynamically update
the keywords used to track tweets of specific content.
34PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
7. References
[1] "instagram," [Online]. Available: https://www.instagram.com/.
[2] "instagram API," instagram API, [Online]. Available: https://www.instagram.com/developer/.
[3] "pinterest," [Online]. Available: pinterest.com.
[4] "pinterest api," [Online]. Available: https://developers.pinterest.com/docs/api/pins/?.
[5] "https://www.tumblr.com/," [Online]. Available: https://www.tumblr.com/.
[6] "https://www.tumblr.com/docs/en/api/v2," [Online]. Available:
https://www.tumblr.com/docs/en/api/v2.
[7] "Facebook," [Online]. Available: www.facebook.com.
[8] "Graph API," [Online]. Available: https://developers.facebook.com/docs/graph-api/.
[9] "Twitter," [Online]. Available: www.twitter.com.
[10] "twitter api," [Online]. Available: https://developer.twitter.com/en/docs.
[11] "Flickr," [Online]. Available: www.flickr.com.
[12] "flickr API," [Online]. Available: https://www.flickr.com/services/api/.
[13] "precious plastic," [Online]. Available: https://preciousplastic.com.
[14] "Thingiverse," [Online]. Available: https://www.thingiverse.com/about/.
[15] "Thingiverse API," [Online]. Available: https://www.thingiverse.com/developers.
[16] "MongoDB," [Online]. Available: https://www.mongodb.com/.
[17] E. Dubois and D. Gaffney, "The multiple facets of influence: Identifying political influentials and
opinion leaders on Twitter," American Behavioral Scientist, vol. 58, pp. 1260-1277, 2014.
[18] W. Chen, S. Cheng, X. He and F. Jiang, "Influencerank: An efficient social influence measurement for
millions of users in microblog," in Cloud and Green Computing (CGC), 2012 Second International
Conference on, 2012.
[19] W. Chen, Y. Wang and S. Yang, "Efficient influence maximization in social networks," in Proceedings of
the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, 2009.
[20] M. Cha, H. Haddadi, F. Benevenuto and P. K. Gummadi, "Measuring user influence in twitter: The
million follower fallacy.," Icwsm, vol. 10, p. 30, 2010.
35PTwist – GA No. 780121 D2.1 – Report on Qualitative Crowdsourced and
H2020 ICT-11-2017 Open Data Filtering Methodology
[21] F. Bonchi, C. Castillo, A. Gionis and A. Jaimes, "Social network analysis and mining for business
applications," ACM Transactions on Intelligent Systems and Technology (TIST), vol. 2, p. 22, 2011.
[22] E. Bakshy, J. M. Hofman, W. A. Mason and D. J. Watts, "Everyone's an influencer: quantifying
influence on twitter," in Proceedings of the fourth ACM international conference on Web search and
data mining, 2011.
[23] K. Lee, J. Mahmud, J. Chen, M. Zhou and J. Nichols, "Who will retweet this?: Automatically identifying
and engaging strangers on twitter to spread information," in Proceedings of the 19th international
conference on Intelligent User Interfaces, 2014.
[24] F. Riquelme and P. González-Cantergiani, "Measuring user influence on Twitter: A survey,"
Information Processing & Management, vol. 52, pp. 949-975, 2016.
[25] T. Rodrigues, F. Benevenuto, M. Cha, K. Gummadi and V. Almeida, "On word-of-mouth based
discovery of the web," in Proceedings of the 2011 ACM SIGCOMM conference on Internet
measurement conference, 2011.
[26] S. Brin and L. Page, "The anatomy of a large-scale hypertextual web search engine," Computer
networks and ISDN systems, vol. 30, pp. 107-117, 1998.
[27] H. Tong, B. A. Prakash, C. Tsourakakis, T. Eliassi-Rad, C. Faloutsos and D. H. Chau, "On the vulnerability
of large graphs," in Data Mining (ICDM), 2010 IEEE 10th International Conference on, 2010.
[28] D. Jurgens, T. Finethy, J. McCorriston, Y. T. Xu and D. Ruths, "Geolocation Prediction in Twitter Using
Social Networks: A Critical Analysis and Review of Current Practice.," ICWSM, vol. 15, pp. 188-197,
2015.
[29] D. M. Blei, A. Y. Ng and M. I. Jordan, "Latent dirichlet allocation," Journal of machine Learning
research, vol. 3, pp. 993-1022, 2003.
[30] A. Cichocki and A.-H. Phan, "Fast local algorithms for large scale nonnegative matrix and tensor
factorizations," IEICE transactions on fundamentals of electronics, communications and computer
sciences, vol. 92, pp. 708-721, 2009.
[31] C. Sievert and K. Shirley, "LDAvis: A method for visualizing and interpreting topics," in Proceedings of
the workshop on interactive language learning, visualization, and interfaces, 2014.
36You can also read

















































